Предсказание горимости территорий методами машинного обучения на основе географических данных

Автор статьи: Ярослав Найчук, выпускник OTUS.
Статья написанна Ярославом на основе выпускного проекта, в котором показано, как методы ML можно применять в самых разных областях.
Добрый день! Сегодня я хотел бы рассказать о том, как с помощью средств машинного обучения можно предсказать горимость регионов. Что же такое горимость? В данной работе она рассматривается как отношение площади гарей за год к площади исследуемого региона.
Целью работы не ставилась идентификация самих выгоревших площадей, напротив, это попытка составить оптимальную модель предсказания, используя простые географические данные региона.
В работе рассмотрены Атырауская, Западно-Казахстанская области Республики Казахстан, а также Астраханская, Саратовская, Волгоградская области и Республика Калмыкия России.
Данные по горимости и некоторые другие географические данные любезно предоставлены авторами данной работы: Шинкаренко С.С., Дорошенко В.В., Берденгалиева А.Н. Динамика площади гарей в зональных ландшафтах юго-востока европейской части России // Известия Российской академии наук. Серия географическая. 2022. Т. 86. № 1. С. 122–133. DOI 10.31857/S2587556622010113.
Какие данные использовались ещё?
Климатические данные. Взяты с сайта https://crudata.uea.ac.uk/cru/data/hrg/
Данные по поголовью скота — https://stat.gov.kz/region/list, https://www.gks.ru/dbscripts/munst/munst.htm
NDVI — Вега-science http://sci-vega.ru/
Loupian E., Burtsev M., Proshin A., Kashnitskii A., Balashov I., Bartalev S., Konstantinova A., Kobets D., Radchenko M., Tolpin V., Uvarov I. 2022. Usage Experience and Capabilities of the VEGA-Science System // Remote Sensing. Vol. 14. No. 1. P. 77. DOI: 10.3390/rs14010077Границы муниципальных образований.
Рассмотрим признаки более детально:
flammability — динамика годовой горимости по регионам. Наша целевая переменная.
NDVI — динамика нормализованного относительного индекса растительности по регионам. Данный признак рассчитан как сумма пикселей со значениями NDVI в пределах региона.
precipitation — динамика кол-ва осадков.
t_max — среднегодовая динамика максимальных суточных температур.
livestock — динамика поголовья скота, представленная в условных единицах.
region — исследуемый район
Что же такое NDVI? NDVI (Normalized Difference Vegetation Index) — нормализованный относительный индекс растительности. Он отражает плотность растительности в определенной точке изображения, которая равна разнице интенсивностей отраженного света в красном и инфракрасном диапазоне, деленной на сумму их интенсивностей. Формула NDVI выглядит так:


Исходя из этого индекса можно сделать предположение, что чем меньше значение NDVI, тем биомасса более склонна к горению. Как видно из рисунка выше, сочные части растения имеют высокий индекс, они более влажные; отмершие или отсохшие части имеют более низкий индекс и более склонны к горению.
Изначально некоторые данные были представлены не в форме табличных данных, а в форме растровых изображений с географической привязкой (GeoTIFF). Для представления данных в нужной форме была использована программа QGIS для работы с геоданными. Расчеты по растрам проводились с помощью инструмента «Калькулятор растров». Далее для расчета статистики по регионам, был использован инструмент «Зональная статистика». На получившийся растр как бы накладывался слой с полигонами муниципальных районов, и для каждого района мы получили годовую статистику. (см. рис)


В итоге проведенных расчетов получается векторный слой со следующей структурой таблицы атрибутов (см рис.).

Каждая строка здесь — это полигон района, а поля »2001»,»2002» и др. — некоторые средние значения на конец года. Эта таблица не совсем подходит для анализа данных, т.к. следует представить каждый год и каждый регион отдельной строкой. Была написана следующая функция на Python, преобразующая данные в нужный вид
def parse_csv(path, col_name, start_index=0):
df = pd.read_csv(path, decimal=',')
list_of_df = []
for i in range(len(df)):
new_df = df.iloc[i,:].to_frame(name=col_name).reset_index()
if col_name == 'flammability':
new_df = df.iloc[i,:].to_frame(name="flammability").reset_index()
new_df['region'] = new_df.iloc[1,1]
new_df['OSM_ID'] = new_df.iloc[0,1]
new_df = new_df.iloc[3:,:]
list_of_df.append(new_df)
else:
new_df['OSM_ID'] = new_df.iloc[0,1]
new_df = new_df.iloc[1:,:]
list_of_df.append(new_df)
df = pd.concat(list_of_df).reset_index()
df = df.rename(columns={"index": "year"})
df = df.drop(['level_0'], axis=1)
return dfВ итоге получаем таблицу следующего вида:
Получившиеся датасеты сцеплялись по полю OSM_ID функцией pd.merge с использованием itertools.
import functools as ft
df = ft.reduce(lambda left, right: pd.merge(left, right, on=['OSM_ID','year']), list_of_data)Также были проведены EDA и предобработка данных, добавились новые признаки.
Значения NDVI и осадков были смещены на год назад. Это сделано потому, что исходные данные отражают информацию на конец года. Пропущенные значения, которые образовывались из-за смещения, были заполнены средним по региону.
Был добавлен новый признак, который отражал динамику количества осадков на начало года, с января по апрель (precip_beggining_y)
Муниципальные районы (категориальная переменная) были переделаны в новые признаки: широта и долгота их географического центра (N — координаты широты, E — координаты долготы)
Целевая переменная была прологарифмирована .
Nan«ы заполним значением »-9999», пропущенные данные присутствуют только в данных по поголовью.
Поля «year» и поля с ненужной информацией были удалены.
Теперь посмотрим на матрицу корреляций признаков
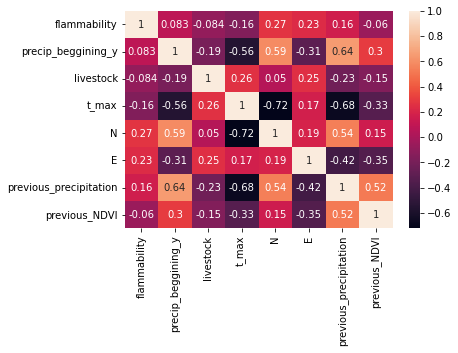
Целевая переменная имеет слабую корреляцию с другими признаками. Также можно заметить, что координаты широты обратно коррелируют с динамикой максимальных суточных температур, что встраивается в картину закона о «Широтной зональности» (когда наблюдается закономерное изменение физико-географических процессов, компонентов и комплексов геосистем от экватора к полюсам).
Посмотрим также распределение целевой переменной.


Здесь более темные цвета отражают большую горимость
Попробуем протестировать классические модели машинного обучения. Для начала оценим линейные модели с регуляризацией и с применением различных scaler«ов. Качество можно увидеть в таблице ниже.
Scaler | R2 | RMSE | MAE | Regressor’s type | Best Alpha |
RobustScaler | 0.151 | 0.870 | 0.706 | RidgeCV | 1.0 |
RobustScaler | 0.150 | 0.870 | 0.706 | LassoCV | 0.001 |
RobustScaler | 0.144 | 0.873 | 0.709 | ElasticNetCV | 0.01 |
StandardScaler | 0.151 | 0.869 | 0.705 | RidgeCV | 1.0 |
StandardScaler | 0.139 | 0.875 | 0.712 | LassoCV | 0.01 |
StandardScaler | 0.145 | 0.873 | 0.709 | ElasticNetCV | 0.01 |
MinMaxScaler | 0.146 | 0.872 | 0.709 | RidgeCV | 1.0 |
MinMaxScaler | 0.151 | 0.870 | 0.706 | LassoCV | 0.0001 |
MinMaxScaler | 0.147 | 0.872 | 0.708 | ElasticNetCV | 0.001 |
SVM со следующей сеткой показал следующие результаты:
param_grid = {
'C': [1, 5, 100, 200, 1000],
'epsilon': [0.01, 0.1, 0.05, 0.0003, 1, 0.2, 5, 10],
'gamma': [0.001, 0.1, 1, 5, 10, 100]
}R2: 0.465
Best params: {'C': 100, 'epsilon': 0.05, 'gamma': 0.1}
CatBoost «из коробки» с разными scaler«ами показал:
Scaler | R2 | RMSE | MAE |
RobustScaler | 0.589 | 0.905 | 0.751 |
StandardScaler | 0.594 | 0.905 | 0.751 |
MinMaxScaler | 0.601 | 0.905 | 0.751 |
LightGBM со значениями по умолчанию RMSE был равен 0.644, а R2: 0.563
После использования библиотек градиентного бустинга, всё же хочется посмотреть на «feature_importance». Здесь мы имеем следующие значения:
previous_NDVI: 24.23previous_precipitation: 20.7precip_beggining_y: 15.91N: 10.7E: 9.82t_max: 9.3livestock: 9.18
Первое место занимает показатель NDVI, смещенный на год назад. Это можно объяснить тем, что на горимость влияет то, насколько много отмершей биомассы накопилось за прошлый год; также немаловажны осадки за прошлый год и осадки на начало года.
Любопытное наблюдение: для модели KNeighborsRegressor для k=7, модель показала результат R-квадрат равный 0.519. Как такая простая модель могла почти догнать градиентный бустинг? Всё объясняется тем, что метод k-ближайших соседей хорошо подходит для решения географических задач, ведь с большой вероятностью можно сказать, что природные условия некоего географического объекта сходны с его соседями.
Заключение: наилучший результат показал CatBoost со значениями по умолчанию и использованием MinMaxScaler«а, с R2 равным 0.601. Отдельного внимания заслуживает метод k-ближайших соседей, как простая и менее ресурсозатратная альтернатива градиентному бустингу (в рамках данной задачи).
В конце статьи хочу порекомендовать всем заинтересованным двухдневный бесплатный интенсив от OTUS, на котором вас ждет глубокое погружение в область рекомендательных систем. Уже в первый день вы изучите наиболее популярные подходы, которые существуют для формирования рекомендаций и реализуете один из них своими руками. Зарегистрироваться на интенсив можно по ссылке ниже.
