Предотвращаем утечки памяти в Go, ч. 1. Ошибки бизнес-логики

Можно любить Go за многое: за простоту и строгость, за горутины и каналы, за реализацию параллельного и асинхронного программирования, за продвинутый планировщик, за аллокатор с большим количеством оптимизаций, за высокую производительность.
Но, по сообщениям некоторых пользователей, у программ, написанных на Go, течёт память. Issue-трекер языка Go на github по запросам »high memory usage»,»memory leak»,»out of memory» выдаёт сотни и тысячи тикетов. А в самом популярном вопросе на stackoverflow по словосочетанию «golang memory» автор пытается разобраться, почему потребление оперативной памяти в рантайме в 4 раза превышает количество реально сделанных аллокаций. Обращения, в которых люди рапортуют о перерасходе оперативной памяти в Go, стали массовым явлением.
Что же это — утечки памяти, вызванные программистскими ошибками, или ожидаемое поведение рантайма языка? Мы попытаемся разобраться в причинах этого явления и сформулировать общие рекомендации, которые помогут в отладке проблем с потреблением памяти.
Привет, Хабр, меня зовут Виталий Исаев, я бэкенд-разработчик в компании МойОфис. Более пяти лет мы используем Go в качестве основного языка для разработки бэкенда корпоративной почтовой системы Mailion, о которой мы ранее неоднократно рассказывали (1, 2, 3, 4, 5). За это время у нас накопился большой опыт эксплуатации сервисов, написанных на Go. Приходилось нам сталкиваться и с повышенным потреблением оперативной памяти. Сегодня мы начнём долгий рассказ об этом неприятном явлении.
Утечки памяти — проблема или нет?
Программисты с бэкграундом в языках с ручным управлением памятью удивились бы подобной постановке вопроса. Но в некоторых случаях перерасход оперативной памяти является компромиссом, на который можно пойти, чтобы выиграть в производительности. Например, в Java реализован специальный no-op Epsilon GC: его можно включать в программах, для которых критично время отклика, но совсем не критична аварийная остановка из-за исчерпания памяти. А в языках, в которых автоматическое управление памятью базируется на подсчёте ссылок, а GC отвечает лишь за зачистку объектов с циклическими ссылками, иногда принято совсем отключать сборку мусора. К примеру, в написанном на Python бэкенде Instagram (по решению суда социальная сеть Instagram признана экстремистской и запрещена на территории РФ) GC не работает, благодаря чему удаётся сэкономить не только CPU, но и, как ни странно, память. Ну, а если приложение утечёт из-за циклических ссылок, его переподнимет uWSGI или другой процесс-супервизор. Также GC отключён и в одном из бекендов Wargaming.
Но всё же эти примеры являются скорее исключением из правил. В большинстве случаев повышенное потребление оперативной памяти создаёт серьёзные проблемы. Когда операционная система сталкивается с подобным поведением программы, у неё есть несколько вариантов действий.
Прежде всего, ОС может начать активно перемещать страницы адресного пространства процесса из RAM в SWAP. У процесса появляется иллюзия большого количества памяти, которую он продолжает потреблять с не меньшей интенсивностью. Однако в связи с тем, что современные SSD (не говоря уже об HDD) на несколько порядков медленнее, чем RAM, это приводит к тому, что время отклика процесса становится совершенно неадекватным. По этой причине многие и отключают SWAP в продакшене.
Если SWAP отключен, либо если его не хватает, неизбежно наступает момент, когда ОС начинает принудительно останавливать наиболее ресурсоёмкие процессы. В этом ей помогает OOM Killer. Он использует специальные эвристики, чтобы выбрать самый «плохой» процесс, который нужно остановить —, но иногда он промахивается. Известны весёлые истории про то, как OОМ Killer убивал sshd, после чего админ на сервер зайти уже не мог.
Ну, а самое неприятное: для остановки процесса OOM Killer использует SIGKILL — сигнал, который невозможно обработать. Поэтому принудительная остановка, выполненная ООМ Killer’ом — это не graceful stop, а авария.
Аварийная остановка процесса
Последствия аварийной остановки весьма разнообразны. Иногда они ограничиваются локальным состоянием процесса. Например, stateful-приложение из-за аварии может не успеть сбросить на диск какие-нибудь буферы, в результате чего нарушится целостность данных. Но куда критичнее то, что аварийная остановка локального процесса может негативно повлиять на другие процессы, работающие на совсем других серверах.
К примеру, в классической трёхзвенной архитектуре бэкенд может использовать кэш для того, чтобы снизить нагрузку на базу данных. Однако в этом случае аварийное падение бэкенда из-за OOM и его дальнейшая работа с холодным кэшем вызовет повышенную нагрузку на СУБД, с которой она не справится и упадёт.
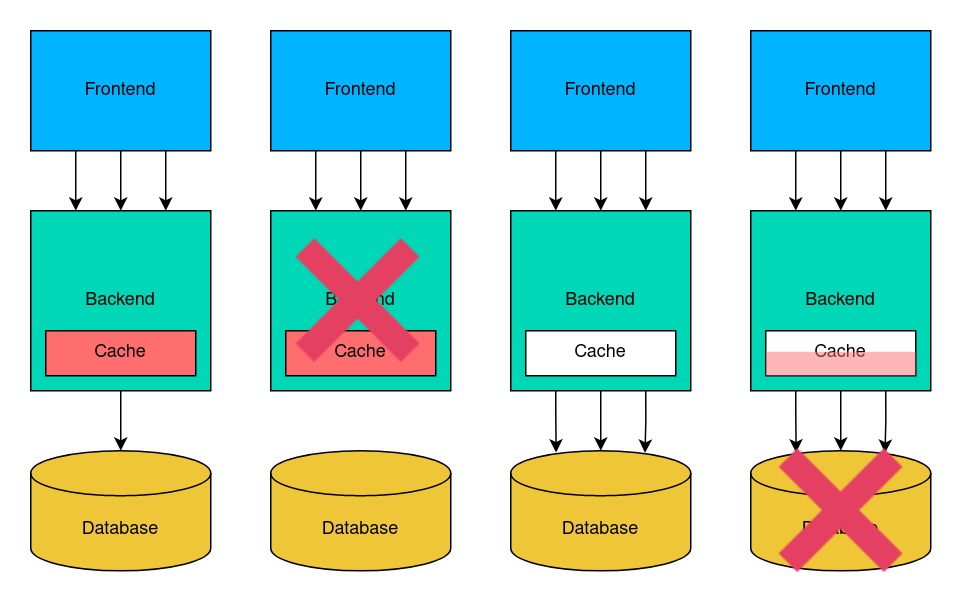 Рис. 1. Аварийная остановка бэкенда вызывает повышенную нагрузку на СУБД.
Рис. 1. Аварийная остановка бэкенда вызывает повышенную нагрузку на СУБД.
Рассмотренная проблема холодных кэшей является частным случаем каскадного сбоя, вызванного циклом положительной обратной связи. Такая ситуация может произойти в любом распределённом бэкенде. Сначала на одном из инстансов сервиса накапливаются какие-то ошибки, либо падает пропускная способность, либо он аварийно останавливается, например, из-за утечки памяти. Нагрузка перераспределяется по соседним инстансам. Если она окажется для них слишком велика, они тоже выходят из строя. Теряя целые слои бизнес-логики, система приходит в состояние, из которого очень тяжело выйти без потерь.
Близкий по смыслу пример можно подобрать из мира распределённых баз данных, которые, кстати, в последние годы всё чаще пишутся на Go. Одна из главных проблем систем подобного класса — реализация распределённых транзакций. Существует классический алгоритм 2PC, печально известный своей низкой отказоустойчивостью. В первой фазе алгоритма координатор транзакции запрашивает у ведомых узлов готовность закоммитить транзакцию. Если все ответили согласием, то координатор отправляет им команду на коммит, и только после этого её данные становятся видны всем остальным транзакциям. Проблема в том, что при аварийной остановке координатора ведомые узлы, пообещавшие закоммитить транзакцию, оказываются в зависшем состоянии, а данные на них блокируются. Если координатор не восстановится, то придётся вызывать админа, чтобы он руками докатывал или откатывал транзакции на ведомых узлах.
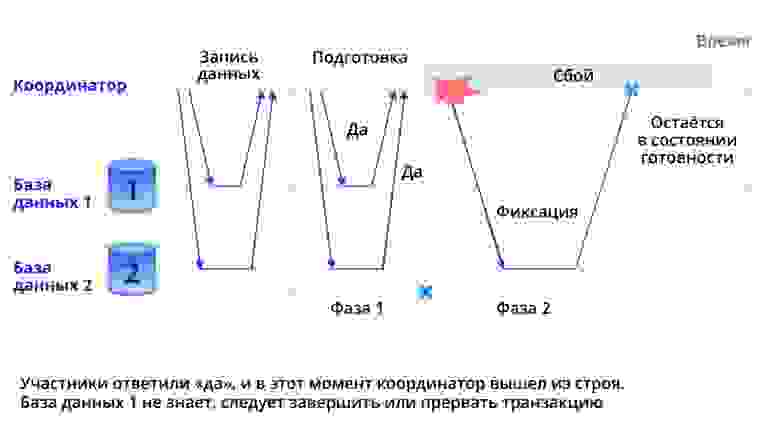 Рис. 2. Последствия аварийной остановки координатора распределённой транзакции по протоколу двух-фазного коммита. Источник: Клеппман М. Высоконагруженные приложения. Программирование, масштабирование, поддержка. СПб., 2018, 640 с.
Рис. 2. Последствия аварийной остановки координатора распределённой транзакции по протоколу двух-фазного коммита. Источник: Клеппман М. Высоконагруженные приложения. Программирование, масштабирование, поддержка. СПб., 2018, 640 с.
Из приведённых примеров видно, что в серьёзной бэкенд-разработке аварийных отказов следует избегать, и в первую очередь нужно бороться с одной из главных их причин — утечками памяти.
Мониторинг
Анализ проблемы высокого потребления памяти начинается с правильно построенного мониторинга. Рекомендуется обратить внимание на следующие источники отладочной информации:
Профилировщик из стандартной библиотеки языка Go. Содержит информацию о работающих горутинах и выполненных аллокациях памяти.
Структура runtime.MemStats содержит внутреннюю статистику системы управления памятью в Go.
Статистика процесса операционной системы. Как минимум, нужно следить за размером виртуального адресного пространства (VMS) и количеством реально потреблённой оперативной памяти (RSS). Для извлечения этих метрик можно использовать эту библиотеку.
Также потребуется развернуть ПО для визуализации данных, чтобы следить за динамикой показателей. Начать можно с опенсорсного решения на основе InfluxDB и Grafana, но стоит принять во внимание и более мощные SaaS продукты, например Instana (ранее известный как Stackimpact) и Google Cloud Profiler.
Основной критерий проблем с памятью — монотонный рост значения RSS. Если RSS, достигая предельных значений, на графике отвесно сбрасывается до нуля, скорее всего, это признак работы OOM Killer. Логи OOM Killer можно вывести с помощью следующей команды:
journalctl -k | grep -i oomПричины высокого потребления памяти
Повышенное потребление оперативной памяти в Go может быть вызвано двумя группами причин. К первой относятся программистские ошибки. Вторая связана с неизвестными широкому кругу разработчиков особенностями рантайма Go, однако они не являются ошибками в прямом смысле этого слова. Сегодня мы сосредоточимся на первой группе.
Ошибки бизнес-логики
Утечка горутин
Утечка горутин является наиболее распространённой причиной повышенного потребления памяти в Go. Во-первых, страницы стека горутин аллоцируются на хипе (по этой причине бесконечная рекурсия приводит в Go не к ошибке переполнения стека, а к ООМ). Во-вторых, если горутина утекает, то утекают и переменные, находящиеся в её области видимости. Причём часто эти утечки могут быть скрыты от программиста за фасадом из фреймворков и библиотек.
Одна из самых распространённых ошибок в популярном RPC-фреймворке gRPC случается тогда, когда программист забывает отменить контекст, который использовался для конструирования стрима:
func sayHelloToServer(client pb.GreeterClient) (pb.GreeterResponse, error) {
ctx := context.Background()
// контекст не отменяется -> стрим утекает
resp, err := client.SayHello(ctx, &pb.HelloRequest{Name: "world"})
if err != nil {
return nil, errors.Wrap(err, "make request")
}
return resp, nil
}Если контекст не отменить, то стрим утекает — точнее, утекает ассоциированная со стримом горутина, скрытая глубоко внутри фреймворка, а также многие служебные объекты, которые находятся в скоупе этой горутины. Поэтому при первом признаке утечки памяти необходимо идти именно в профилировщик горутин, и только потом переходить к следующим пунктам.
Накопление состояния в долгоживущих объектах
Порой нам приходится использовать глобальные переменные либо переменные, время жизни которых сопоставимо со временем жизни приложения. Понятно, что такие объекты никогда не будут собраны GC, поэтому нужно очень внимательно относиться к их внутреннему стейту и не допускать его разрастания.
Иногда к ошибкам подобного класса приводят опасные операции со слайсами. Представим, что у нас есть слайс указателей. Нам нужно сделать из него укороченный слайс, но чтобы не заниматься копированием, мы просто изменяем длину старого слайса:
s := []*int{new(int), new(int)}
s = s[:1]Но после такой операции в нижележащем массиве остаётся не-nil указатель, который продолжает адресовать некоторую область памяти на хипе. Поэтому она остаётся недоступной для GC, и получается утечка.
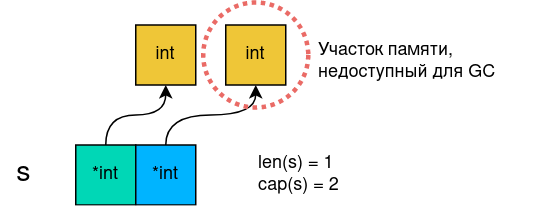 Рис. 3. Несмотря на уменьшение длины слайса, указатель, который хранится в нижележащем массиве, продолжает адресовать память.
Рис. 3. Несмотря на уменьшение длины слайса, указатель, который хранится в нижележащем массиве, продолжает адресовать память.
Проблемы такого рода можно попытаться разобрать с помощью профилировщика хипа.
Cgo
Лет 5 назад, когда в Go было мало нативных библиотек, часто приходилось линковаться с библиотеками на C, например, с ImageMagick или OpenSSL, да и сейчас это нередко приходится делать. Важно понимать, что применение Cgo выталкивает нас в область unsafe-кода, цена ошибки в котором значительно возрастает. Все аллокации, которые делаются в Cgo, не обслуживаются Go аллокатором. Поэтому они не доступны и сборщику мусора Go. Программист самостоятельно отвечает за время жизни любого объекта, аллоцированного в Cgo, либо переданного в Cgo из Go.
Написание Cgo кода требует большой внимательности, от которой Go нас отучает. Наиболее распространённые ошибки — это висячие указатели (когда память освобождается слишком рано) и собственно утечки памяти (когда она освобождается слишком поздно или вообще не освобождается). По этой причине стоит с самого начала продумать способ подсчёта памяти, выделяемой на стороне Cgo, ведь рантайм Go не сможет предоставить статистику Cgo аллокаций — об этом должен позаботиться сам программист. Отказ от учёта аллокаций в Cgo катастрофически снижает возможности дебага утечек памяти. Правильно построенный учёт, напротив, позволяет всегда быть уверенным в том, что операционной системе возвращается ровно то количество памяти, которое ранее было выделено.
Так или иначе, при известных мерах безопасности двухуровневая конструкция, в которой данные перегоняются между Go и Cgo (рис. 4, слева), считается более-менее устойчивой. Однако в своей практике вы можете столкнуться с библиотеками, которые потребуют от вас работать c Go из Go через прослойку в виде Cgo (рис. 4, справа). Я бы рекомендовал избегать этих конструкций, потому что это почти гарантированная утечка памяти, — только если вы не эксперт в C.
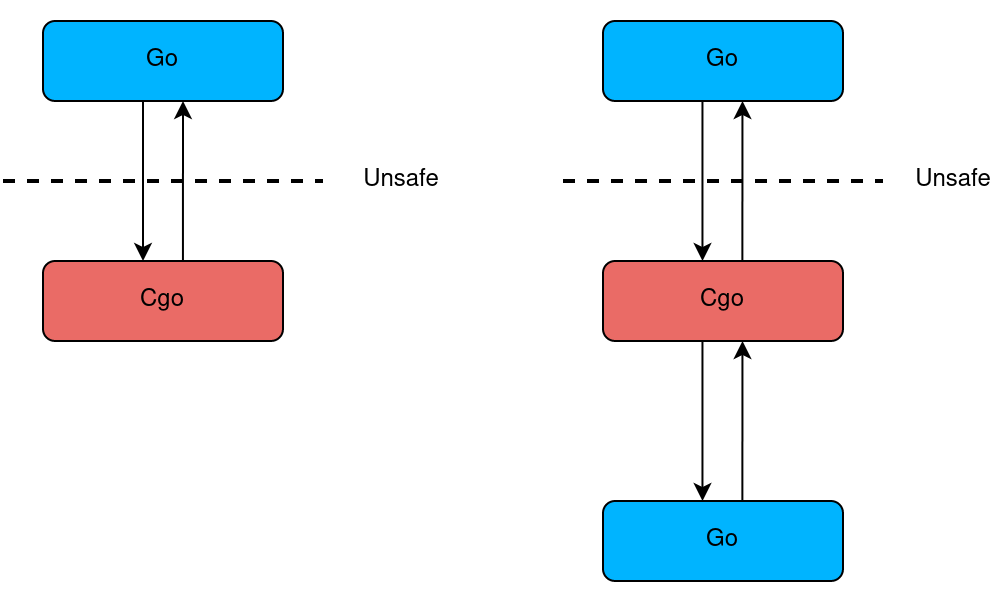 Рис. 4. Разные варианты использования Cgo.
Рис. 4. Разные варианты использования Cgo.
Ещё одна довольно неожиданная проблема связана с фрагментацией виртуального адресного пространства процесса. В данном цикле статей мы будем много говорить о фрагментации памяти — это старая проблема, хорошо известная программистам на С. Но она обретает новое измерение именно в контексте Cgo. О ней подробно рассказывал Олег Герасимов на конференции GopherCon 2019.
Как мы уже упомянули выше, в Go приложении, использующем Cgo, действуют два аллокатора, которые по очереди запрашивают у ОС новые и новые фрагменты памяти, в результате чего адресное пространство процесса начинает напоминать «слоёный пирог». Оказывается, что в такой ситуации второй аллокатор —, а в данном случае это был аллокатор из stdlib C++ — по каким-то причинам не может вернуть неиспользуемую память операционной системе. Снаружи это выглядит как утечка памяти: в течение всего времени жизни процесса его RSS соответствует пиковому уровню и никогда не снижается. Точных причин этого явления авторам исследования установить не удалось, однако они заметили, что память начинает освобождаться, если вместо стандартного аллокатора С++ использовать TCMalloc.
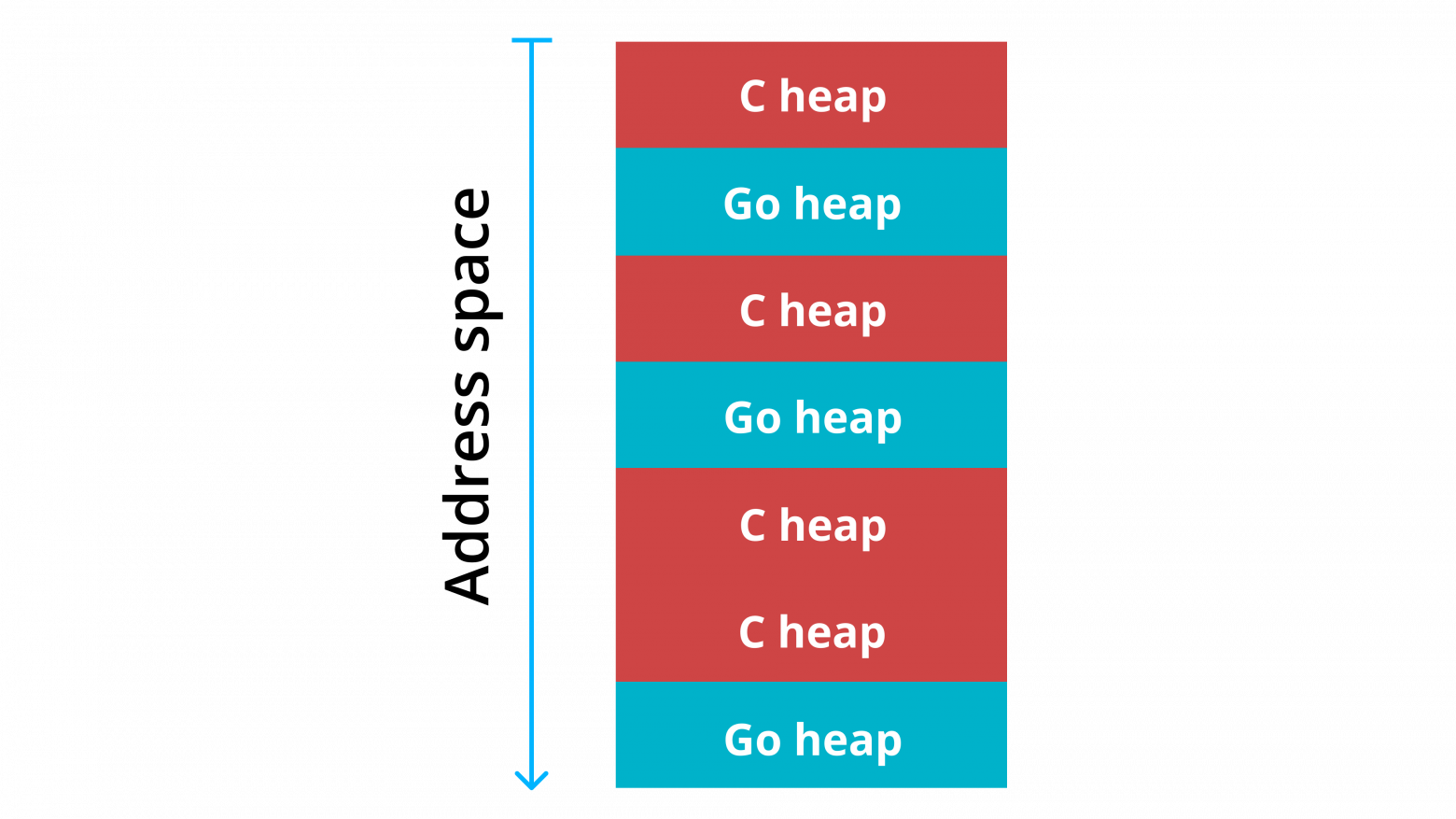 Рис. 5. Фрагментация виртуального адресного пространства процесса, использующего Cgo. Источник: Олег Герасимов. Опыт разработки Go-приложения с сgo. GopherCon Russia 2019. https://www.youtube.com/watch? v=bdx8W_gxS3E
Рис. 5. Фрагментация виртуального адресного пространства процесса, использующего Cgo. Источник: Олег Герасимов. Опыт разработки Go-приложения с сgo. GopherCon Russia 2019. https://www.youtube.com/watch? v=bdx8W_gxS3E
Поэтому, если вы собираетесь всерьёз использовать Cgo, приготовьтесь изучить TCMalloc, jemalloc, Valgrind, GDB и им подобные инструменты.
sync.Pool
Тип sync.Pool был введён специально для того, чтобы переиспользовать короткоживущие объекты и тем самым снизить нагрузку на GC. Чаще всего требуется переиспользовать буферы. Пул буферов может потребоваться для реализации низкоуровневых серверов: буфер извлекается из пула в начале обработки клиентского запроса и возвращается в пул в конце. Внутри пула буфер живёт своей жизнью: может быть, его извлекут для обработки другого запроса, а может быть, его соберёт GC — это заранее неизвестно. Но очень важно помнить о том, что sync.Pool эффективен, только если в нём хранятся объекты одинаковых размеров. Если же они разные, то есть вероятность, что переиспользоваться будут легкие объекты, а тяжёлые будут лежать в памяти в виде бесполезного груза, и снаружи это будет выглядеть как утечка.
type bufferPool struct {
pool sync.Pool
}
func newBufferPool() *bufferPool {
return &bufferPool{
pool: sync.Pool{
New: func() interface{} {
return new(bytes.Buffer)
},
},
}
}
func (p *bufferPool) get() *bytes.Buffer {
return p.pool.Get().(*bytes.Buffer)
}
func (p *bufferPool) put(b *bytes.Buffer) {
// при возвращении пула в буфер не проверяется его размер;
// это может привести к утечке памяти
p.pool.Put(b)
}(Источник кода: https://github.com/grpc/grpc-go/blob/v1.38.0/internal/transport/transport.go#L46)
Такое поведение sync.Pool было обнаружено ещё в 2017 г. В этом тикете идёт обсуждение того, что имеющаяся документация к sync.Pool провоцирует разработчиков на его неправильное применение. Одно из наиболее интересных предложений заключалось в том, чтобы вообще удалить документацию и тем самым затруднить разработчикам использование sync.Pool. Но с тех пор так ничего и не изменилось. Поэтому при применении пулов требуется проявлять большую осторожность, чтобы эта оптимизация не превратилась в очередной источник проблем.
Заключение
В статье мы детально разобрали явление повышенного потребления оперативной памяти программами, написанными на Go, сделав акценты на реакции операционной системы и на том, какие катастрофичные последствия может иметь эта проблема для распределённых бэкендов и stateful-сервисов.
Также мы рассмотрели основные ошибки бизнес-логики приложения на Go, которые могут приводить к повышенному потреблению оперативной памяти: утечки горутин, утечки аллокаций (в том числе накопление состояния в долгоживущих объектах), ошибки при работе с Cgo и неправильное применение sync.Pool.
Однако если все потенциально проблемные места в бизнес-логике проверены, ошибок не найдено, а RSS продолжает расти, и программа продолжает падать из-за OOM, к сожалению, это означает, что в игру вступил рантайм языка Go. Чтобы устранить утечку памяти, придётся детально проанализировать поведение рантайма в контексте отдельно взятого приложения, работающего под определённой нагрузкой. О том, как это сделать, мы расскажем в следующей статье.
Так или иначе, проблему повышенного потребления памяти всегда можно решить либо экстенсивным (покупка дополнительных объёмов RAM), либо интенсивным (поиск и устранение проблем приложения и рантайма) способом. Если вы предпочитаете второй, приглашаем вас на работу в МойОфис: у нас постоянно открыты вакансии для разработчиков.
Полезные ссылки:
