Практика использования Spark SQL или как не наступить на грабли
Если вы работаете с SQL, то вам это будет нужно очень скоро. Apache Spark — это один из инструментов, входящих в экосистему Hadoop, который обрабатывает данные в оперативной памяти. Одним из его расширений является Spark SQL, позволяющий выполнять SQL-запросы над данными. Spark SQL удобно использовать для работы посредством SQL-запросов с большими объемами данных и в системах с высокой нагрузкой.
Ниже вы найдёте некоторые нехитрые приёмы по работе со Spark SQL:
- Как с помощью сбора статистики и использования хинтов оптимизировать план выполнения запроса.
- Как, оставаясь в рамках SQL, эффективно обрабатывать соединения по ключам с неравномерным распределением значений (skewed joins).
- Как организовать broadcast join таблицы, если её размер слишком велик.
- Как средствами Spark SQL понять, сколько приложение Spark реально использовало памяти и ядер кластера в развёртке по времени.
Сейчас на рынке есть много аналитиков и разработчиков, владеющих SQL. Это язык, понятный всем сторонам процесса разработки. Аналитик формулирует, какие данные из каких таблиц нужно извлечь и соединить заданным образом. Разработчик дорабатывает, при необходимости разбивает на этапы и оптимизирует поступившие SQL-запросы, затем формирует из них потоки ETL по регулярной загрузке данных. С ростом потребностей бизнеса эпоха хранилищ данных на миллионы строк сменяется эпохой озёр данных на миллиарды строк. Бизнес развивает свои экосистемы и ставит задачи по переводу хранилищных сущностей в облака. Там данные ждут обработчики machine learning и data science. ETL-разработчики переквалифицируются в дата-инженеров и самый простой путь для них — с помощью знакомого языка SQL, используя мощности Spark, загружать миллиарды строк в озеро данных. Если у разработчика на входе имеются сотни SQL-запросов, которые нужно материализовать в облачные сущности и ограничено время на разработку, то простейший метод — использовать Spark SQL, настраивать запросы силами самого SQL и только в случае неприемлемой скорости загрузки прибегать к кодированию на Spark.
Spark SQL помогает в обработке данных многим компаниям из Global 100. При простоте разработки Spark SQL даёт на выходе высокую производительность, если использовать его правильно. Spark SQL можно использовать в различных ETL процессах при обработке и загрузке данных. Альтернативами Spark SQL при работе с данными можно назвать использование Impala SQL или Hive (c обработкой SQL-запросов в mapreduce). Если же выходить за рамки SQL, то альтернатива — использование в Spark языка DSL. Не приходится сомневаться в перспективности языка SQL, существующего десятилетия и имеющего миллионы пользователей. Немалые перспективы развития имеет и Spark SQL. Например, с новыми версиями Spark появляется возможность использовать новые оптимизационные хинты, способы обработки данных становятся эффективнее. Spark развивается от версии к версии в погоне за повышением эффективности обработки данных и интеграцией с DeepLearning. Меняются в сторону улучшения подходы: RDD, DataFrame, DataSet. Тем самым, изучение и применение Spark SQL — актуально и многообещающе. Для компаний же использование Spark SQL ведёт в конечном итоге к накоплению знаний о клиентах, их обработке и построении новых бизнесов на новых знаниях.
Для более тонкой настройки загрузки данных посредством Spark потребуется выйти за рамки Spark SQL и использовать, например, DSL.
Уточним, что речь в статье идёт о работе с версией Apache Spark 2.3, загрузка данных осуществляется из Hadoop в Hadoop, управление ресурсами осуществляется посредством Yarn, используется операционная система Linux, а также СУБД Hive с сохранением данных в hdfs в формате parquet.
Код приложения, запускающего переданный ему в качестве параметра файл с командой SQL полностью приводить не будем, напишем лишь, что в приложении нужно открыть переданный файл, загрузить его содержимое в переменную sqlStr и вызвать:
SparkSession spark = SparkSession
.builder()
.appName("")
.enableHiveSupport()
.getOrCreate();
Dataset sql = spark.sql(sqlStr);
Получится приложение *.jar, которому можно передавать в качестве параметра файл с командой SQL и выполнять его посредством spark-submit:
spark-submit --class <…sqlrunner> --name --queue --executor-cores 1 --executor-memory 1g --driver-cores 1 --driver-memory 1g --num-executors 1 --master yarn --deploy-mode cluster sqlFile=<…sql>;
При этом в передаваемом файле sqlFile можно указывать команды SQL, например:
insert overwrite table target_scheme.target_table
select s.* from source_scheme.source_table s;Сбор и просмотр статистики для Spark, хинт BROADCAST
Как известно, одной из наиболее сложных операций для Spark является соединение (join) таблиц или датасетов. При этом в Spark существуют различные алгоритмы реализации join-ов: SortMergeJoin, BroadcastHashJoin, CartesianProduct и др. Чтобы помочь Spark автоматически понять, большие или маленькие таблицы он соединяет и какой тип соединения оптимален, нужно собрать статистику по этим таблицам. Для этого посредством spark-submit вызываем команду вида:
ANALYZE TABLE scheme_name.table_name COMPUTE STATISTICS;
Эту команду сбора статистики мы можем передать вышеописанному модулю sqlrunner.jar в качестве параметра вместо команды SQL. Для выполнения этой команды требуются права на чтение и запись в таблицу, по которой собирается статистика.
Проверить, что статистика собрана, можно в среде hive командой вида:
show create table scheme_name.table_name;
Нужно посмотреть, появились ли в конце описания в блоке TBLPROPERTIES свойства 'spark.sql.statistics.numRows' и 'spark.sql.statistics.totalSize':
CREATE EXTERNAL TABLE `scheme_name.table_name`(
…
TBLPROPERTIES (
…
'spark.sql.statistics.numRows'='363852167',
'spark.sql.statistics.totalSize'='82589603650',
…
Таким образом, целесообразно иметь собранную статистику по таблицам-источникам, по используемым в расчётах промежуточным таблицам, а также по таблицам витрин, которые тоже могут быть использованы в соединениях в пользовательских запросах.
Теперь скажем пару слов о том, что такое broadcast в Spark. При присоединении маленькой таблицы к большому датасету часто оказывается целесообразным не распределять маленькую таблицу на различные ноды по ключам соединения в виде порций данных, а поместить её целиком на все ноды кластера, использующиеся в приложении. При этом говорят, что осуществляется broadcast маленькой таблицы на все ноды и тип присоединения маленькой таблицы к основному массиву данных — broadcast join.
Зачастую, broadcast join нужен в Spark SQL в тех случаях, когда в реляционных базах данных требуется nested loop join. Особенно необходим broadcast при неравномерной статистике распределения данных в участвующих в соединении ключах, например, при присоединении маленького справочника валют к большой таблице проводок, в которой 99% строк относится к рублям.
Для того, чтобы указать Spark, что надо сделать broadcast какой-то небольшой таблицы или датасета (до ~1Gb), можно в SQL-запросе указывать хинт /*+ BROADCAST (t)*/, где t — алиас таблицы или датасета.
insert overwrite table target_scheme.target_table
select /*+ BROADCAST(t) */ big.field1,
big.field2,
t.field3
from source_scheme.big_table as big
left join source_scheme.small_table as t
on big.field1 = t.field1;
В том числе, если по какой-то таблице статистика не собрана или мы имеем дело с подзапросом, результат которого формируется «на лету» и Spark заранее не знает, большой ли он, то хинт /*+ BROADCAST (t)*/ особенно целесообразен, если в таблице или подзапросе мало данных.
Если broadcast какого-то подзапроса завершается позже чем, через 5 минут с начала выполнения запроса, то стоит вызывать spark-submit с нижеприведённым параметром (здесь 36000 — время в секундах), потому как выделенных по умолчанию 5 минут может не хватить:
--conf spark.sql.broadcastTimeout=36000
Например, такой параметр пригодится в нижеприведённом запросе, где делается broadcast результата подзапроса /*+ BROADCAST (small) */, который становится готов не с самого начала работы запроса, а на более поздних этапах:
select /*+ BROADCAST(small) */
big.field3, small.field1, small.field2
from source_scheme.big_table as big
inner join (select t1.field1, t2.field2
from source_scheme.table1 as t1
inner join source_scheme.table2 as t2
on t1.field1 = t2.field1) small
on big.field2 = small.field2;
Убедиться, что хинт учтён оптимизатором и broadcast реально осуществлён можно, посмотрев в Yarn по ссылке в столбце Tracking UI у соответствующего приложения Spark план выполнения запроса на закладке SQL:

Отметим, что в Spark SQL есть и другие хинты, в т.ч. с версии 2.4 появляются хинты /*+ COALESCE (n) */, где n — количество партиций, на которые будет разбит результат, и /* + REPARTITION (n) */, где n — количество партиций при repartition.
Обход SKEWED JOIN явным указанием SKEWED ключей
Рассмотрим две таблицы:
- Таблица A, имеющая поле AID
- Таблица B, имеющая поле BID
Требуется выполнить соединение этих таблиц по ключам A.AID = B.BID:
select A.*, B.* from A inner join B on A.AID = B.BID;
Рассмотрим случай, когда значения ключей, которые встречаются в одной из таблиц, распределены неравномерно.
Пусть в таблице B на значения ключей BID 4089, 4107, 4468 и 6802 приходится в сумме 70% строк, в то время как на миллион прочих значений ключей BID приходится лишь оставшиеся 30% строк.
При этом будем считать, что в таблице A значения ключей AID распределены более-менее равномерно, при этом значения 4089, 4107, 4468 и 6802 встречаются по одному разу.
В таком случае это соединение таблиц называется skewed join, т.е. «перекошенное соединение», а слишком частые ключи называются skewed keys.
По умолчанию задача соединения двух таблиц, выполненная посредством spark-submit, будет разбита на 200 партиций. Изменить эту настройку по умолчанию можно, задав другое значение конфигурации spark.sql.shuffle.partitions, например:
--conf spark.sql.shuffle.partitions=1000
Как Spark будет обрабатывать skewed join?
Spark без подсказки не знает, что данные распределены неравномерно, и распределит задачу соединения таблиц так: большинство значений ключей попадёт в «лёгкие» партиции, которые быстро обработают небольшой объём данных; при этом обработка skewed keys попадёт в «тяжёлые» партиции.
Картинки ниже показывают пример такого случая: 999 из 1000 партиций отработали быстро, выдав небольшое количество итоговых строк, а одна партиция, в которую попали почти все данные, работала несколько часов.
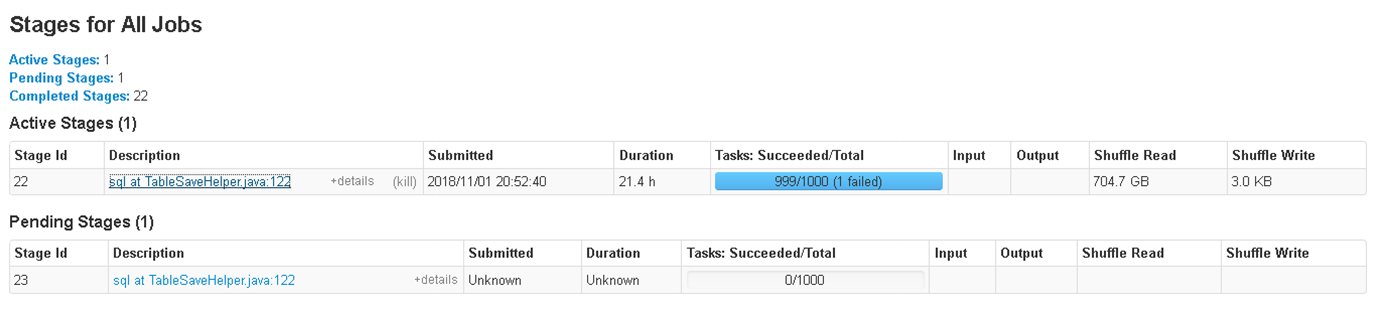

Как сделать распределение соединяемых данных по партициям более равномерным?
Как вариант, нужно соединять таблицы не по одному ключу A.AID = B.BID, а по паре ключей, при этом распределение данных по паре ключей сделать уже более равномерным.
Сделаем допущение, что в таблице B имеется также числовое поле BID2, данные в котором распределены равномерно (в отличие от BID). Если такового равномерно распределенного числового поля нет, то его можно сгенерировать работающей в hive и spark функцией hash () из конкатенации других полей. В таком случае функция hash () выдаст равномерно распределённые данные.
Нижеприведённый работающий под spark запрос решает задачу. Этот запрос целесообразно применить вместо «select A.*, B.* from A inner join B on A.AID = B.BID;»
В секции with приведён пример вышеописанных данных для таблиц A и B. Имеет место перекошенность данных в ключе BID. Формируется подзапрос ANTISKEW, в котором перекошенные значения ключей 4089, 4107, 4468 и 6802 размножены до 10 экземпляров каждое. Данные из таблицы А соединяются с подзапросом ANTISKEW, тем самым сформировав в массиве A_ для ключей AID, равных 4089, 4107, 4468 и 6802, по 10 экземпляров с различными значениями ANTISKEWKEY от 0 до 9. При этом для прочих значений AID в массиве A_ будет по одному экземпляру с ANTISKEWKEY = 0. Далее массив A_ соединяется с таблицей B не только по условию A_.AID = B.BID, но и по второй паре ключей. А именно, для перекошенных значений ключей BID многочисленные записи из таблицы B соединятся с одним из значений ANTISKEWKEY от 0 до 9 в зависимости от остатка от деления BID2 на 10. Неперекошенные значения BID соединятся один к одному с ANTISKEWKEY = 0. Тем самым будет достигнуто более равномерное распределение перекошенных ключей BID по партициям — они пойдут не в одну, а в 10 партиций.
with A as (select 4089 AID union all select 4468 AID union all select 6802 AID union all
select 5 AID union all select 8 AID union all select 14 AID),
B as (select 4089 BID, 1 BID2 union all
select 4089 BID, 2 BID2 union all
select 4089 BID, 3 BID2 union all
select 4107 BID, 4 BID2 union all
select 4107 BID, 5 BID2 union all
select 4107 BID, 6 BID2 union all
select 4468 BID, 7 BID2 union all
select 4468 BID, 8 BID2 union all
select 4468 BID, 9 BID2 union all
select 6802 BID, 10 BID2 union all
select 6802 BID, 11 BID2 union all
select 6802 BID, 12 BID2 union all
select 1 BID, 13 BID2 union all
select 2 BID, 14 BID2 union all
select 3 BID, 15 BID2 union all
select 4 BID, 16 BID2 union all
select 5 BID, 17 BID2 union all
select 6 BID, 18 BID2 union all
select 7 BID, 19 BID2 union all
select 8 BID, 20 BID2 union all
select 9 BID, 21 BID2 union all
select 10 BID, 22 BID2 union all
select 11 BID, 23 BID2 union all
select 12 BID, 24 BID2 union all
select 13 BID, 25 BID2 union all
select 14 BID, 26 BID2 union all
select 15 BID, 27 BID2)
select A_.*, B.*
from (select A.*, coalesce(ANTISKEW.ANTISKEWKEY, 0) ANTISKEWKEY
from A
left join (select Y.ID, Z.ANTISKEWKEY
from (select 4089 ID union all
select 4107 ID union all
select 4468 ID union all
select 6802 ID) Y
cross join (select 0 ANTISKEWKEY union all
select 1 ANTISKEWKEY union all
select 2 ANTISKEWKEY union all
select 3 ANTISKEWKEY union all
select 4 ANTISKEWKEY union all
select 5 ANTISKEWKEY union all
select 6 ANTISKEWKEY union all
select 7 ANTISKEWKEY union all
select 8 ANTISKEWKEY union all
select 9 ANTISKEWKEY) Z) ANTISKEW
on A.AID = ANTISKEW.ID) A_
inner join B
on A_.AID = B.BID
and A_.ANTISKEWKEY = case when A_.AID in (4089, 4107, 4468, 6802) then B.BID2%10 else 0 end;
Для ещё более равномерного распределения данных нужно подбирать в подзапросе ANTISKEW, на сколько именно партиций хочется разбить каждый ключ. Описанный метод требует знания статистики — по каким перекошенным ключам сколько процентов строк следует ожидать.
Партиционирование помогает сделать BROADCAST
Ниже описан способ, как в Spark SQL делать broadcast join вместо shuffle join в случае, если размер меньшей таблицы слишком велик для broadcast.
Допустим, нужно соединить таблицу big_table (100Gb)
create table big_table(
id decimal(18,0),
key1 decimal(18,0)
) stored as parquet;
с таблицей small_table (4Gb)
create table small_table(
id decimal(18,0),
key2 decimal(18,0)
) stored as parquet;
При этом предполагается, что размер таблицы small_table слишком велик, чтобы сделать её broadcast, о чём выдаётся ошибка.
Целью является заполнить результирующую таблицу:
truncate table result_table;
insert into table result_table
select big_table.id,
big_table.key1,
small_table.key2
from big_table
left join small_table
on big_table.id = small_table.id;
Соединение по ключу id при этом предполагается нормально распределённым.
Сделаем обе соединяемые таблицы партиционированными:
create table big_table(
id decimal(18,0),
key1 decimal(18,0)
) partitioned by (part_mod decimal(6,0)) stored as parquet;
create table small_table(
id decimal(18,0),
key2 decimal(18,0)
) partitioned by (part_mod decimal(6,0)) stored as parquet;
При заполнении обеих партиционированных таблиц big_table и small_table ключ партиционирования part_mod сделаем равным остатку от деления id на 4:
part_mod = id%4;
Заведём псевдотаблицу, смотрящую своим location на одну партицию big_table (part_mod = 0):
create table big_table_0(
id decimal(18,0),
key1 decimal(18,0)
) stored as parquet location '…/big_table/part_mod=0';
Также заведём псевдотаблицу, смотрящую своим location на одну партицию small_table (part_mod = 0):
create table small_table_0(
id decimal(18,0),
key1 decimal(18,0)
) stored as parquet location '…/small_table/part_mod=0';
Теперь мы можем записать в результирующую таблицу одну четверть требуемых данных из соединения вышеописанных псевдотаблиц.
При этом проверено, что хинт BROADCAST успешно срабатывает:
truncate table result_table;
insert into table result_table
select /*+ BROADCAST(small_table_0)*/ big_table_0.id,
big_table_0.key1,
small_table_0.key2
from big_table_0
left join small_table_0
on big_table.id = small_table.id;
Следующими тремя шагами мы можем аналогично дописать в результирующую таблицу оставшиеся три четверти данных с part_mod = 1, part_mod = 2, part_mod = 3.
Итоговая продолжительность загрузки результирующей таблицы «методом поэтапного broadcast партиций» обычно получается на одинаковых ресурсах меньше, чем методом shuffle join. Однако такой метод требует, чтобы таблицы с исходными данными были заранее партиционированы одинаковым образом, т.е. по остатку от деления id на какое-либо число, по которому соединяемся. Если id не целочисленное, то можно брать остаток от деления hash (id) на какое-либо число. Особенно легко организовать, чтобы заранее партиционированными были промежуточные (стейджинговые) таблицы, дизайн которых находится на усмотрении разработчика.
Мониторинг ресурсов
Как известно, при работе с озером данных важно правильно выделять ресурсы задачам по загрузке данных. В противном случае имеются риски падения задачи от нехватки ресурсов, слишком длительного выполнения задачи, либо неоправданно высокого выделения ресурсов в ущерб другим задачам.
Как правильно выделять ресурсы — отдельная тема. В этой же статье мы поговорим о том, как понять:
- Сколько ресурсов выделил Yarn на задачу или группу задач в развёртке по времени.
- Сколько ресурсов реально использовал Spark на задачу из числа выделенных ему менеджером ресурсов Yarn в развёртке по времени.
Сразу отметим, что существуют специализированные способы мониторинга ресурсов, например, Graphite/Grafana, однако они требуют настройки. Ниже будет показан способ, как получить результаты «на коленке», с помощью командной строки, Spark SQL и логов Spark.
Сначала опишем первый вид мониторинга («мониторинг yarn»).
Командой вида
while [ ! -f complete.flg ]; do for app in $(yarn application -list -appStates RUNNING | grep | awk '{print $1}'); do ( command1 () { date +"%Y-%m-%d %H:%M:%S"; }; command2 () { yarn application -status $app; }; x="|""|$(command1) $(command2)"; echo $x >> app.txt; ) & done; wait; done
осуществляется следующее. В период работы мониторинга, когда установлен флаг в виде файла complete.flg, в цикле по списку находящихся в статусе RUNNING приложений Yarn, имеющих в названии шаблон , в текстовый файл app.txt дозаписывается результат вызова команды yarn application –status $app. Таким образом, в текстовом файле app.txt для каждого момента мониторинга содержится информация о затраченных за время работы каждого приложения мегабайт*секундах (MB-seconds) и ядро*секундах (vcore-seconds) накопительным итогом. По окончании работы мониторинга ставится флаг завершения complete.flg и итоговый файл app.txt переносится в hdfs в текстовую таблицу yarn_monitoring:
CREATE EXTERNAL TABLE IF NOT EXISTS scheme_name.yarn_monitoring(
loading_date string,
loading_id string,
txt string
)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='|',
'serialization.format'='|')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'…/yarn_monitoring';
Строки в этой таблице имеют вид:
2020-02-18|2235599|2020-02-18 01:00:44 Application Report : Application-Id : application_1580486634374_3632578 Application-Name : Application-Type : SPARK User : Queue : Start-Time : 1581976835176 Finish-Time : 0 Progress : 10% State : RUNNING Final-State : UNDEFINED Tracking-URL : RPC Port : 0 AM Host : Aggregate Resource Allocation : 18663 MB-seconds, 9 vcore-seconds Log Aggregation Status : NOT_START Diagnostics :
Затем можно на том же Spark SQL написать запрос к этой текстовой таблице, в котором распарсить значения показателей использованных ресурсов (MB-seconds, vcore-seconds) на каждый момент осуществления мониторинга. Далее в этом запросе можно визуализировать эти показатели в виде графиков в формате векторной графики *.svg:
…
13:47:48
Результат запроса можно сохранить в файл *.svg и посмотреть в браузере. Пример картинки с результатами мониторинга ресурсов, использованных группой наблюдаемых приложений Yarn, приведен ниже. Красным цветом показана динамика использованной памяти, синим цветом — динамика использованных процессорных ядер:

На основании такой визуализации можно принимать решения об изменении расписания выполнения определённых приложений Yarn с целью более равномерного использования ресурсов в течение суток.
Теперь опишем второй вид мониторинга («мониторинг spark»).
Итак, интересна ситуация, когда Yarn выделил задаче Spark, например, 200 ядер и не отдаёт эти ресурсы другим задачам. При этом в реальности 199 из 200 ядер уже не используются в приложении Spark, а работу реально продолжает только одно ядро. Этот вид мониторинга среди прочего нацелен на поиск таких ситуаций.
Считаем, что подвергаемые мониторингу приложения Spark вызываются из некого управляющего механизма. В случае Сбербанка это, например, Oozie или Informatica BDM. Таким образом, управляющий механизм может по завершению работы приложения Spark скопировать его лог в hdfs и запустить маленькое приложение на Spark SQL по парсингу этого лога (или группы логов) и визуализации динамики реально использовавшихся Spark ядер в формате *.svg.
Итак, с помощью команды нижеприведённого вида мы:
- Сохраняем в переменную $app идентификатор приложения в yarn, например, «application_1576046768499_16691»
- С помощью команды command1 записываем в файл $app».txt» строку-заголовок со статусом завершившегося приложения Spark
- С помощью команды «yarn logs -applicationId $app«дозаписываем в файл $app».txt» полученный из Yarn лог завершившегося приложения Spark
- Переносим сформированный файл $app».txt» со статусом и логом в hdfs
'app=$(grep "(state: FINISHED)" /tmp/'' | grep -o "application_[^ ]*" | tee /tmp/applicationid_''.txt); command1 () { yarn application -status $app; }; x="''|''|$app|0|$(command1)"; echo $x > "/tmp/"$app".txt"; yarn logs -applicationId $app | nl -ba -s"|" | sed "s/^/''|''|"$app"|/" >> "/tmp/"$app".txt"; hdfs dfs -copyFromLocal -f "/tmp/"$app".txt" …/spark_monitoring; rm "/tmp/"$app".txt"'
В результате в hdfs получаем строки вида
2019-12-13|1227125|application_1576046768499_16691|0|Application Report : Application-Id : application_1576046768499_16691 Application-Name : Application-Type : SPARK User : Queue : Start-Time : 1576229137128 Finish-Time : 1576229189406 Progress : 100% State : FINISHED Final-State : SUCCEEDED Tracking-URL : http://...sbrf.ru:18089/history/application_1576046768499_16691/1 RPC Port : 0 AM Host : … Aggregate Resource Allocation : 93763306 MB-seconds, 9957 vcore-seconds Log Aggregation Status : NOT_START Diagnostics :
2019-12-13|1227125|application_1576046768499_16691| 1|
2019-12-13|1227125|application_1576046768499_16691| 2|
2019-12-13|1227125|application_1576046768499_16691| 3|Container: container_1576046768499_16691_01_000162 on …sbrf.ru_8041
2019-12-13|1227125|application_1576046768499_16691| 4|===========================================================================================
2019-12-13|1227125|application_1576046768499_16691| 5|LogType:container-localizer-syslog
2019-12-13|1227125|application_1576046768499_16691| 6|Log Upload Time:Fri Dec 13 12:26:32 +0300 2019
2019-12-13|1227125|application_1576046768499_16691| 7|LogLength:0
2019-12-13|1227125|application_1576046768499_16691| 8|Log Contents:
2019-12-13|1227125|application_1576046768499_16691| 9|
…
2019-12-13|1227125|application_1576046768499_16691| 53|19/12/13 12:26:02 INFO executor.Executor: Running task 26.0 in stage 0.0 (TID 19)
…
2019-12-13|1227125|application_1576046768499_16691| 82|19/12/13 12:26:07 INFO executor.Executor: Finished task 26.0 in stage 0.0 (TID 19). 5735 bytes result sent to driver
…
2019-12-13|1227125|application_1576046768499_16691| 84|19/12/13 12:26:07 INFO executor.Executor: Running task 441.0 in stage 0.0 (TID 364)
…
2019-12-13|1227125|application_1576046768499_16691| 102|19/12/13 12:26:08 INFO executor.Executor: Finished task 441.0 in stage 0.0 (TID 364). 5543 bytes result sent to driver
…
При парсинге в логе приложения Spark ищутся события начала использования и высвобождения ядер кластера тем или иным контейнером, т.е. мы ищем время записи в лог событий по шаблонам
INFO executor.Executor: Running task
INFO executor.Executor: Finished task
Таким образом, на любой момент времени известно, сколько процессорных ядер было активно при работе приложения Spark, т.е. начали и еще не завершили свою работу.
Для парсинга собранных в hdfs логов формируется таблица spark_monitoring в текстовом формате:
CREATE EXTERNAL TABLE IF NOT EXISTS scheme_name.spark_monitoring(
loading_date string,
loading_id string,
applicationid string,
rn string,
txt string
)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='|',
'serialization.format'='|')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'…/spark_monitoring';
Как было написано выше, парсинг логов осуществляется силами Spark SQL.Т. е. написан запрос к этой таблице spark_monitoring, который на выходе даёт картинку в формате *.svg с динамикой реального использования ядер кластера приложением Spark.
Результат запроса можно сохранить в файл *.svg и посмотреть в браузере. Пример картинки приведен ниже:
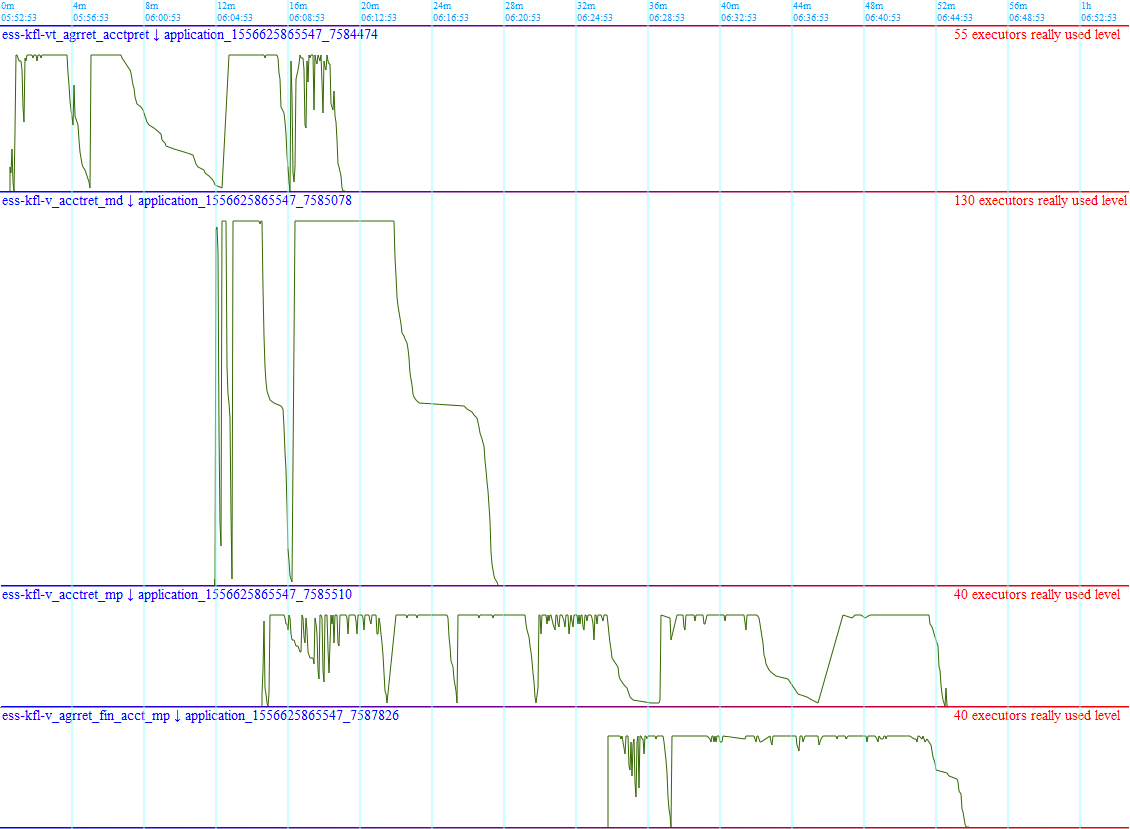
На основании таких графиков можно понять, эффективно ли приложение Spark использует выделенные ему процессорные ядра кластера. Можно смотреть приложения массово. Резкие скачки вверх-вниз, видные на графиках — это переходы между этапами (stages) приложений Spark. Когда заканчивается какой-то этап по чтению или соединению массивов данных и по одному освобождаются все ядра, получается снижение графика к нулю. А вначале выполнения новых этапов идёт резкий рост используемых ядер. Ситуация, когда график притянут к максимуму выделенных ядер и скачки между этапами резкие — это признак оптимального использования ресурсов. Медленные же снижения могут свидетельствовать, например, о skew joins, о которых рассказывалось в этой статье выше.
Автор: Михаил Гричик, эксперт профессионального сообщества Сбербанка SberProfi DWH/BigData.Профессиональное сообщество SberProfi DWH/BigData отвечает за развитие компетенций в таких направлениях, как экосистема Hadoop, Teradata, Oracle DB, GreenPlum, а также BI инструментах Qlik, SAP BO, Tableau и др.
