Практические истории из наших SRE-будней. Часть 4

Это уже четвёртая в общей сложности, но первая в 2021-м году подборка занятных случаев из нашей практики эксплуатации разнообразной инфраструктуры. Она затронет такие технологии, как ClickHouse вместе с ZooKeeper (в их контексте также напомню про недавно описанную нами аварию), MySQL (да, снова будем обновлять эту СУБД), DNS в Kubernetes (любимая многими тема, но здесь всё дело в сторонней утилите…). Поехали!
История №1. Жил-был нажимательный дом и был у него друг — смотритель зоопарка
У одного из клиентов есть большая база аналитической статистики в ClickHouse версии 20.1.2.4. Три кластера: stage, резервный кластер и основной. На основном настроен TTL: полгода данные хранятся на SSD, после чего перемещаются на HDD. Больше ничего необычного: три шарда по две реплики и ZooKeeper-кластер. Stage не сильно отличается от основного: только данные хранятся меньше и вместо HDD используется отдельная директория на SSD.
Чуть меньше года назад нам понадобилось добавить несколько полей в одну из таблиц. Это довольно частая операция и ничего не предвещало беды, но внезапно при добавлении полей на stage-кластере мы столкнулись со странными ошибками:
executeQuery: Code: 450, e.displayText() = DB::Exception: No such volume 'hu, 02 Apr 2020 07:43:45 GMT\0%2Fclickhouse' for given storage policy. (version 20.1.2.4 (official build)) (from 0.0.0.0:0) (in query: /* ddl_entry=query-0000002740 */ ALTER TABLE loadtest.stat_rpl ADD COLUMN IF NOT EXISTS `stream_path` String ) Поиск похожих проблем и дебаг ничего не дали и мы пошли в Telegram-чат, где нам посоветовали только сделать issue. Оказалось, что проблема давно решена и достаточно просто обновиться. Ок, обновляемся на том же stage-кластере…, но вот незадача: после обновления на абсолютно любую версию сервер ClickHouse просто не запускается с ошибками:
2020.04.10 16:46:04.323697 [ 1 ] {} Application: Caught exception while loading metadata: Code: 62, e.displayText() = DB::Exception: Empty query, Stack trace (when copying this message, always include the lines below): А если обновляться на более новую версию, то с такими:
2020.04.10 16:49:40.116410 [ 6785 ] {} Application: DB::Exception: Existing table metadata in ZooKeeper differs in TTL. Stored in ZooKeeper: , local: mdate + toIntervalMonth(6) TO VOLUME 'old_data_volume': Cannot attach table `database`.`table_rpl` from metadata file /var/lib/clickhouse/metadata/database/table_rpl.sql from query ATTACH TABLE table_rpl (`mdate` Date) ENGINE = ReplicatedMergeTree('/clickhouse/tables/database/{shard}/table_rpl', '{replica}') PARTITION BY mdate ORDER BY mdate TTL mdate + toIntervalDay(7) TO VOLUME 'old_data_volume' SETTINGS storage_policy = 'main_policy', index_granularity = 8192 Опять провели отладку, проверив, что метаданные в ZooKeeper совпадают. Было вообще не очень понятно, что же ему не нравится. Снова пришли в чат — снова делаем issue.
Пока мы дожидались решения нашей проблемы, пошли в обход: просто почистили stage и резервный кластеры, создали их заново — ошибки пропали. К счастью, на основном кластере ALTER выполнился. (Предположительно дело было в разном [на какой-то момент] порядке обновления двух кластеров: к сожалению, восстановить точную очерёдность сейчас уже сложно.)Однако оставалась проблема с обновлением ClickHouse. Если stage и резервный кластеры еще можно было обновить с потерей всех данных, то для основной БД такой вариант недопустим (на тот момент в ней хранилось 8 ТБ данных за 2 года).
Наступил 2021 год. Задача по обновлению сама себя не сделает, а в issue на GitHub… свищет ветер, катаются перекати-поле и иногда приходят несчастные люди с похожей проблемой. В общем, понадобился особый план по обновлению основного кластера.
Во-первых, для начала проверим, не изменилось ли что-нибудь (а вдруг!). Для этого обновляем один из узлов…, но нет, не запускается. Пробуем разные версии — безрезультатно. И тогда продумываем разные варианты обновления — вплоть до удаления всех метаданных из ZK.
Попробуем воспроизвести проблемы на stage: откатываем версию ClickHouse до 20.1.2.4, удаляем все данные, пересоздаем базы, таблицы, делаем TTL (как в основном кластере), запускаем clickhouse-copier, чтобы наполнить кластер. Обновляем — о, воспроизводится! Кластер не запускается.
Это уже что-то — попробуем собрать побольше информации:
смотрим debug-логи в CH;
смотрим debug-логи в ZK;
под лупой проверяем метаданные в ZK — может, мы что-то упускаем?…
Через несколько часов и несколько циклов пересоздания кластера приходит интересная идея:, а как вообще выглядят метаданные в резервном кластере? На тот момент там была более новая версия ClickHouse (20.1.9.54).
Итак, метаданные в версии 20.1.9.54:
[zk: localhost:2181(CONNECTED) 2] get /clickhouse/tables/DATABASE/1/TABLE/metadata
metadata format version: 1
date column:
sampling expression:
index granularity: 8192
mode: 0
sign column:
primary key: mdate
data format version: 1
partition key: mdate
ttl: mdate + toIntervalDay(3)
granularity bytes: 10485760… и метаданные в версии 20.1.2.4:
metadata format version: 1
date column:
sampling expression:
index granularity: 8192
mode: 0
sign column:
primary key: mdate
data format version: 1
partition key: mdate
move ttl: mdate + toIntervalDay(7) TO VOLUME 'old_data_volume'
granularity bytes: 10485760В одном случае какой-то move ttl, а в другом — просто ttl. Что будет, если переименовать их прямо в ZooKeeper?
/usr/share/zookeeper/bin/zkCli.sh set /clickhouse/tables/DATABASE/1/stat_rpl/metadata "ttl: mdate + toIntervalDay(7) TO VOLUME 'old_data_volume'"Всё сломается. Потому что ZK заменил вообще всё:
[zk: localhost:2181(CONNECTED) 2] get /clickhouse/tables/DATABASE/1/TABLE/metadata
ttl: mdate + toIntervalDay(7) TO VOLUME 'old_data_volume'Зато можно вот так:
/usr/share/zookeeper/bin/zkCli.sh set /clickhouse/tables/DATABASE/1/stat_rpl/metadata "`cat ./test_metadata`"… где test_metadata — файл со всем содержимым ZooKeeper-узла. Главное не забыть добавить новую пустую строку с пробелом в конце файла и сохранить порядок строк таким же, как был, иначе ClickHouse просто не запустится.
# cat ./test_metadata
metadata format version: 1
date column:
sampling expression:
index granularity: 8192
mode: 0
sign column:
primary key: mdate
data format version: 1
partition key: mdate
ttl: mdate + toIntervalDay(7) TO VOLUME 'old_data_volume'
granularity bytes: 10485760Меняем метаданные для всех шардов, обновляем ClickHouse. Ура, все работает!
В нашем случае был написан простой Python-скрипт с использованием библиотеки kazoo. Он «прошелся» по метаданным всех баз и шардов и заменил все необходимое. И мы успешно обновили все кластеры CliсkHouse. Альтернативным вариантом рассматривалось пересоздание вообще всех таблиц в полусотне баз с удалением данных в Zookeeper, но это заняло бы куда больше времени — с простоем и без гарантии, что вообще поможет.
История №2. Крадущееся обновление на MySQL 8, затаившийся ru_RU.cp1251
Очередной поучительный случай о том, как одна незаметная, незначительная деталь всё меняет. На сей раз эта деталь кроится в созданных вами MySQL-таблицах и может самым грубым образом повлиять на процесс обновления версии СУБД.
Благодаря совместным с клиентом усилиями мы смогли снизить нагрузку на базу, в связи с чем решили переехать на менее мощные серверы. А раз уж такой переезд, то не грех и обновить кластер MySQL: с версии 5.7 до 8. Мы уже однажды описывали процесс такой миграции в деталях, но на сей раз и схема, и последствия будут иными.
Тот факт, что в MySQL возможна репликация между этими версиями, навел нас на мысль, что новые экземпляры мы поднимем сразу на 8-й версии, а для переключения без простоя соединим их с основным кластером репликацией. Останется лишь в нужный момент переключить endpoints в Kubernetes и снять репликацию со старых экземпляров.

Но прежде всего требовалось проверить, готов ли наш MySQL к обновлению. Чтобы выяснить это, на текущих инсталляциях запускаем обыкновенный mysqlcheck:
mysqlcheck -u root -p --all-databases --check-upgradeИ нет никаких проблем! Однако помните, что mysqlcheck не показывает всего, что может быть не так. Потому мы проверяем ещё и через mysql-shell:
mysqlsh -- util check-for-server-upgrade { --user=root --host=127.0.0.1 --port=3306 } --config-path=/etc/mysql/my.cnfОна указала нам нам всего на пару проблем, связанных с обновлением на 8 версию:
1. Наличие полей с character set utf8. Как мы уже знаем из документации или прошлой статьи, в 5.7 данный алиас указывает на 3-байтовую версию utf8mb3, а начиная с 8 версии будет указывать на 4-байтовую utf8mb4.
storage.pf.server_ip - column's default
character set: utf8
storage.pf.page - column's default character
set: utf82. Параметры конфига, что удалены из 8-й версии MySQL:
query_cache_size - is set and will be removed
query_cache_type - is set and will be removedИсправив проблемы с кодировкой и отметив себе задачу удалить лишние параметры на новых серверах, мы начали подготавливать бэкапы текущих баз (с помощью xtrabackup) и переносить их на новые серверы. Предварительно устанавливаем пакет с MySQL 8 на новые инстансы и очищаем директорию /var/lib/mysql.
На текущем мастере MySQL:
sudo xtrabackup --user=root --password= --stream=xbstream --backup --target-dir=./temp --parallel=8 --use-memory=4G | ssh "xbstream -x -C /var/lib/mysql/" На будущем мастере:
innobackupex --apply-log /var/lib/mysql/Также перенесли конфиг с предыдущего кластера, изменив параметры для InnoDB в соответствии с новыми ресурсами и убрав те лишние, что обнаружили при проверке через mysql-shell.На этом, казалось бы, новый экземпляр готов. Запускаем MySQL-сервер, но там нас ждёт:
2021-02-09T12:18:44.271004Z 2 [ERROR] [MY-013140] [Server] Invalid utf8 character string: 'C0E2F2'
2021-02-09T12:18:44.271720Z 2 [ERROR] [MY-013140] [Server] Invalid utf8 character string: 'C2E8F8'
2021-02-09T12:18:44.272412Z 2 [ERROR] [MY-013140] [Server] Invalid utf8 character string: 'C2EBE0'
2021-02-09T12:18:48.620133Z 2 [ERROR] [MY-013140] [Server] Invalid utf8 character string: 'D1EEE1'
2021-02-09T12:18:51.255768Z 2 [ERROR] [MY-013140] [Server] Invalid utf8 character string: 'C2F0E5'
2021-02-09T12:18:51.256603Z 2 [ERROR] [MY-013140] [Server] Invalid utf8 character string: 'C2F0E5'…неудача!
Не сомневаясь, что мы уже проверили всё, ещё раз запускаем проверки на старых инсталляциях. А дополнительно делаем запросы на таблицы и поля, которые могут иметь старую кодировку:
SELECT table_schema, table_name, column_name, character_set_name, collation_name FROM information_schema.columns WHERE character_set_name='utf8' ORDER BY table_schema, table_name,ordinal_position;И видим, что ничего (кроме системных/служебных таблиц) не содержит старый character set. Однако вспоминаем, что в те времена, когда клиент к нам только пришел, у него мелькала и кодировка cp1251. Может быть, не все поля были конвертированы? Делаем аналогичный запрос на поиск cp1251, но ничего не находим.
Не придумав, как ещё можно отыскать проблемное место на старых экземплярах, решаемся на последний вариант: запуск нового mysqld через strace — в надежде найти то место, где он находит эти символы.
strace -s 2048 -qq -ff -o trace.txt mysqld(В команде мы сразу разделяем все child«ы mysqld на разные файлы.)
Далее с помощью обычного grep«а находим место, где происходит вызов ошибки:
close(1424) = 0
write(2, "2021-02-09T12:18:51.256603Z 2 [ERROR] [MY-013140] [Server] Invalid utf8 character string: 'C2F0E5'\n", 99) = 99… и, прокрутив trace немного вверх, обнаруживаем, что ошибка появилась сразу после взаимодействия с файлом, который описывает формат таблицы:
openat(AT_FDCWD, "./sess/tremendous_nutcracker.frm", O_RDONLY) = 1424Возвращаемся к старым инсталляциям MySQL и делаем запрос:
mysql> show create table sess.tremendous_nutcracker;
В полях COMMENT наблюдается странная картина в виде нераспознанных символов. И тут начинает захватывать любопытство: с помощью утилиты mysqlfrm смотрим внутрь .frm-файла, чтобы узнать, что же это за символы:
mysqlfrm --diagnostic -vv /var/lib/mysql/sess/tremendous_nutcracker.frmНаходим для примера одно из полей и видим hex:
'charset': 224,
'charset_low': 0,
'comment': '\xc2\xe8\xf8\xeb\xe8\xf1\xf2',
'comment_length': 7,
'default': None,С помощью первого найденного в Google декодировщика, поигравшись с форматами, обнаруживаем:
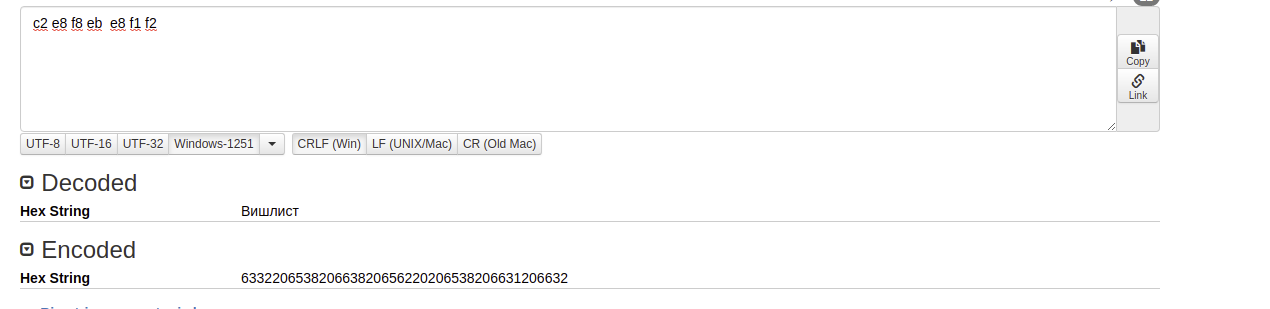
Этот комментарий был написан задолго до того, как клиент пришел к нам. В его базе было обилие полей с русскоязычной кодировкой под Windows. Таким витиеватым способом мы нашли ещё одно место, откуда она не была удалена/конвертирована во время перехода на UTF-8.Схожим образом мы нашли все остальные таблицы с проблемной кодировкой в комментариях и ALTER«нули их. После этого новый экземпляр MySQL со свежим дампом благополучно запустился на версии MySQL 8 и был подключён в качестве реплики к старому кластеру без особых проблем.
А мы лишь в который раз убедились, что даже при чётком плане и большом опыте обновлений всегда может найтись новое узкое/проблемное место, к чему надо быть готовыми.
История №3. Битва Cloudflare с Kubernetes за домен
Порой возникает необходимость автоматического создания и поддержания в актуальном состоянии DNS-записей для сервисов в Kubernetes. Эту проблему помогает решить external-dns.
Он поддерживает множество DNS-провайдеров и позволяет создавать A-записи для IP-адресов сервисов простым добавлением аннотации external-dns.alpha.kubernetes.io/hostname=my.domain.com на сервис. Всю рутинную работу берет на себя external-dns: имея доступ в API Kubernetes, он подписывается на появление и изменения сервисов, а когда замечает нужную аннотацию на одном из них — создает (или меняет) ресурсные записи в доменной зоне посредством API облачного DNS-хостинга.
Также он время от времени сверяет список записей в DNS со списком сервисов с аннотациями, поддерживая зону в актуальном состоянии. Чтобы отделить записи, управляемые external-dns, от прочих существующих, используются TXT-записи для хранения метаинформации.
Всё это очень удобно, когда требуется для LoadBalancer«ов или просто ClusterIP-сервисов автоматически назначить нужное доменное имя прямо при деплое приложения. Однако, как и у любого другого софта, у external-dns есть свои нюансы, незнание которых может привести к курьёзным моментам. Об одном из таких и пойдет речь.
Мы успешно развернули external-dns в кластере одного из клиентов. Домен располагался в CloudFlare, external-dns работал и все было прекрасно… до определенного момента. Внезапно начали поступать жалобы, что один из сервисов (MongoDB) вдруг перестает быть доступным извне: при попытке соединения на нужный порт LoadBalancer«а по доменному имени клиент получал Connection refused.
Однако при попытке воспроизвести проблему её нет. Просим клиента «проверить еще раз» — получаем благодарность и расходимся. Но ненадолго, т.к. ситуация повторяется с завидной регулярностью. Садимся диагностировать:
домен резолвится правильно;
порт открыт, соединение проходит;
следим за состоянием LoadBalancer«а в AWS, проверяем саму MongoDB, логи, состояние pod«а, пробы, endpoint«ы сервиса — всё отлично!
Но как же так?
При повторной диагностике через некоторое время наконец-то видим неладное. Домен внезапно меняет IP-адреса и начинает резолвиться в совершенно другие! Не веря своим глазам, делаем resolve домена в цикле. Проблема подтверждается: в произвольное время адреса изменяются, но через неопределенный период снова восстанавливаются.
Для дальнейшего расследования надо сделать важное примечание. Проблемный домен службы — mongodb-lb.kube.domain.com. Именно он управляется external-dns. В то же время домен *.kube.domain.com ссылается на LoadBalancer ingress-контроллера.
Теперь продолжим troubleshooting. Из наблюдаемых симптомов мы делаем вывод, что что-то или кто-то удаляет наши записи, из-за чего домен начинает резолвиться в адрес балансера ingress-контроллера. Смотрим логи pod«а external-dns:
$ kubectl -n external-dns logs -f external-dns-5fb479676c-l8jb4
time="2021-01-27T17:23:11Z" level=info msg="Changing record." action=CREATE record=mongodb-lb.stage.kube.domain.com ttl=10 type=A zone=869c042132d42d398394354306799a5a
time="2021-01-27T17:23:20Z" level=info msg="Changing record." action=CREATE record=mongodb-lb.stage.kube.domain.com ttl=10 type=TXT zone=869c042132d42d398394354306799a5a
time="2021-01-27T17:25:19Z" level=info msg="Changing record." action=CREATE record=mongodb-lb.stage.kube.domain.com ttl=10 type=A zone=869c042132d42d398394354306799a5a
time="2021-01-27T17:25:28Z" level=info msg="Changing record." action=CREATE record=mongodb-lb.stage.kube.domain.com ttl=10 type=TXT zone=869c042132d42d398394354306799a5a
time="2021-01-27T17:27:20Z" level=info msg="Changing record." action=CREATE record=mongodb-lb.stage.kube.domain.com ttl=10 type=A zone=869c042132d42d398394354306799a5a
time="2021-01-27T17:27:28Z" level=info msg="Changing record." action=CREATE record=mongodb-lb.stage.kube.domain.com ttl=10 type=TXT zone=869c042132d42d398394354306799a5aПочему он постоянно создает записи. Кто их удаляет?
Следствие оказалось недолгим. Мы вспомнили про второй кластер клиента — production, в который задеплоен точно такой же по конфигурации external-dns. Посмотрели, подумали, проверили его логи… Да, это именно production-кластер, не обнаруживая у себя сервисов с нужными аннотациями, просто брал и выносил из DNS-зоны все записи, управляемые external-dns!
Исправить это элементарно: достаточно воспользоваться ключом --txt-owner-id:
для staging сделать
--txt-owner-id=staging,для production —
--txt-owner-id=production.
После этого конфликты прекратятся.
Так мы и поступили — проблемы решились, а Cloudflare вздохнул с облегчением.
Deployment для выката external-dns может выглядеть приблизительно так:
---
apiVersion: v1
data:
CF_API_EMAIL: email_in_base64
CF_API_KEY: api_key_in_base_64
kind: Secret
metadata:
name: external-dns
namespace: external-dns
type: Opaque
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: external-dns
namespace: external-dns
spec:
progressDeadlineSeconds: 600
replicas: 1
selector:
matchLabels:
app: external-dns
strategy:
type: Recreate
template:
metadata:
labels:
app: external-dns
spec:
containers:
- args:
- --source=service
- --domain-filter=domain.wildcard.com
- --provider=cloudflare
- --txt-owner-id=production
envFrom:
- secretRef:
name: external-dns
image: registry.opensource.zalan.do/teapot/external-dns:v0.7.6
imagePullPolicy: Always
name: appВместо заключения
Пусть этот опыт окажется полезным (а может, хотя бы просто иинтересным) нашим коллегам из других компаний. А уж в чем нет никаких сомнений — вскоре мы столкнёмся с новыми неожиданными ситуациями, так что нам будет чем пополнить эту копилку публичных Ops/SRE-кейсов. До встречи!
P.S.
Читайте также в нашем блоге:
«Практические истории из наших SRE-будней. Часть 3» (миграция Linux-сервера, Kubernetes-оператор ClickHouse, реплика PostgreSQL, обновление CockroachDB);
«Практические истории из наших SRE-будней. Часть 2» (Kafka и Docker, ClickHouse и MTU, перегретый Kubernetes, pg_repack для PostgreSQL);
»6 практических историй из наших SRE-будней» (Golang и HTTP/2, symfony и Sentry, RabbitMQ и прокси, GIN в PostgreSQL, S3 и nginx, DDoS и user-agent).
