Повышаем производительность поиска с помощью партиционирования индекса в Apache Solr

Полнотекстовый поиск используется в Wrike почти повсеместно. Поиск в шапке страницы дает возможность быстрого доступа к последним задачам с сортировкой по дате обновления, с совпадением по названию. Такой вариант поиска представлен в разделах «Моя работа» и «Панель задач».
Поиск в списке задач работает по всем полям: название, описание, имена файлов вложений, авторы, комментарии, дата изменения. Максимальный приоритет у задач, активность по которым связана с текущим пользователем, с фразовым совпадением в названии, описании или в комментариях.
Упрощенный вариант поиска по названиям используется:
- при расстановке зависимостей для диаграммы Ганта (предшествующая и последующая задачи),
- при добавлении ссылок на задачи по названиям (меншенинг),
- при добавлении подзадач.
В этих разделах используется instant search с неявным wildcard: пользователь последовательно вводит u, up, upd, update, а поисковые запросы принимают вид: u*, up*, upd*, update*.
Кроме того, wildcards можно использовать во всех вариантах поиска.
Таким образом, часто приходят «тяжелые» поисковые запросы, вызывающие многократное чтение индекса, повышенную нагрузку по CPU/IO на серверах и, как следствие, общие задержки в обработке запросов в «часы-пик».
В данной статье мы поделимся своим способом решения проблемы производительности.
Речь пойдет об ускорении поиска при работе с поисковым сервером Apache Solr через партиционирование коллекций. Описанный способ был нами опробован на версиях 4.9.0 и 4.10.2.
Проблема
Некоторые поисковые запросы на сайте занимали десятки секунд, иногда такие задержки приводят к Gateway Timeout у конечных пользователей.
Входные условия
Полнотекстовый поиск реализован на Apache Solr. Работает постоянная индексация. Весь индекс находится в одной коллекции. Размер RAM на серверах позволяет поместить весь индекс в файловый кэш.
Вот так выглядит проблема:
- В ряде случаев единичный поисковый запрос занимает «слишком» много времени
- Проблемные поисковые запросы включают комбинацию из множества полей
- Индекс находится на SSD
- Рекомендации от Apache не помогают
- Схема индекса (schema.xml) фиксирована и есть явный критерий для партиционирования
Дополнительно выясняем:
- Долгие запросы — это запросы с wildcards (типа *q*, *w*, *e*)
- Время полного чтения файлов индекса в оперативку: Tread = Tsearch / N, где Tsearch — время поиска, N — кол-во полей в поисковом запросе
Пример
Пусть есть следующий запрос к Apache Solr:
q = fieldA=q* OR fieldB=q* OR fieldC=q* OR fieldD=q*
Предположим, он занимает N секунд для первого запроса, остальные отработают быстрее, так как часть данных уже в файловом кэше и во внутренних кэшах Apache Solr/Lucene. Выясняем, что простое чтение полного индекса в оперативку занимает N/4 секунд. Очевидно, проблема в размере индекса, с которым приходится работать Solr«у.
Что нам предлагает Apache Solr и SolrCloud?
- Советы по оптимизации от apache
- Настройка кэшей нам не подходит, так как у нас постоянный индексинг, при этом рано или поздно кэши сбрасываются, и получаем долгий запрос.
- filter queries — не работает, Solr все равно читает полный индекс, а фильтрация происходит после.
- Distributed Search, SolrCloud и шардинг. Особенности:
- Сложность поддержки, полной реиндексации при обновлении схемы.
- Непрозрачность подготовки шардов.
- IndexPartitioning — дальше идеи дело не пошло.
Distributed Search мы не рассматриваем, как устаревшую технологию, недостатки которой представлены в описании SolrCloud.
Минусы шардинга на SolrCloud
Документация по SolrCloud предлагает два варианта шардинга — автоматический и «ручной», с использованием команды SPLITSHARD.
При автоматическом режиме заранее задается количество шардов. SolrCloud с помощью ZooKeeper занимается балансировкой загрузки шардов при индексации, шарды для поиска выбираются автоматически. В «ручном» режиме мы сами выбираем время и шард для разделения его на два.
Автоматический режим нам не подходит. У нас есть явный ключ для партиционирования, то есть для роутинга документов по шардам при индексации. Сам роутинг может быть изменен после индексации, когда мы сможем оценить размер шарда. Автоматическая ребалансировка по шардам предполагает, что одна наша партиция может быть разбросана по нескольким шардам, в наихудшем случае, по всем. Нас это не устраивает, если у нас есть настолько большая партиция, что части её находятся на всех шардах, мы бы хотели выделить её в отдельный шард без других партиций.
Ручной режим можно было бы использовать через фоновый сервис, вызывая команду SPLITSHARD автоматически, по достижении лимитов на размер шарда, но процесс это закрытый и не мгновенный.
Вот что можем получить, при падении SPLITSHARD на Solr 4.9.0:
- Сохраняются исходные коллекции.
- Создаются новые (с именами *_shard1_0, *_shard1_1).
- Новые коллекции создаются только на одной ноде, информация не попадает в ZooKeeper.
- Реальной балансировки поисковых запросов не происходит.
- Созданные коллекции надо чистить вручную с диска на том узле, где они были созданы.
Причиной данного фейла был таймаут при взаимодействии Solr и ZooKeeper. Конечно, таких падений хочется либо избежать в продакшне, либо иметь больше контроля для упрощения восстановления.
Решение
Каким же должно быть наше решение?
- Значительное уменьшение объема индекса, с которым будет работать конкретный поисковый запрос.
- Минимум усилий по поддержке.
- Минимум усилий по изменению структуры.
- Партиционирование без даунтайма.
Партиции будем называть коллекциями (в терминологии Apache Solr), так как решение работает через Solr Collections API и в качестве партиций создает коллекции и реплики для них.
Мы заранее оговорили, что можем разбить данные однозначно по ключу (batchId), а также:
- В одну коллекцию могут попадать данные с одним или несколькими batchId.
- В разных коллекциях не могут находиться данные с одинаковым batchId.
Схема поисковой системы до внедрения партиционирования выглядела так: 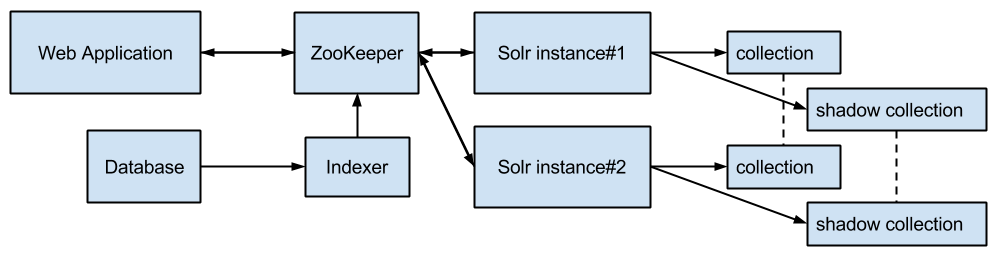
Web Application — выполняет поисковые запросы.
Indexer — сервис выполняющий дельта-индексацию и полную реиндексацию (только в shadow collection), работает в отдельной инфраструктуре для фоновых процессов.
Solr instance#1, instance#2 — два сервера с Apache Solr для обеспечения отказоустойчивости.
collection — два экземпляра индекса, репликация происходит через SolrCloud/ZooKeeper.
shadow collection — два экземпляра индекса для полной реиндексации при изменении схемы индекса, после которой collection и shadow collection меняются местами.
Схема работает следующим образом. Поисковые запросы направляются попеременно на все узлы Apache Solr. Для маршрутизации запросов используется класс LBHttpSolrServer из клиентской библиотеки solrj, скорость запросов с ним выше, чем с CloudSolrServer, но падения узлов приходится отслеживать вручную и перезапрашивать актуальную информацию с ZooKeeper. Запросы на индексацию можно так же выполнять через LBHttpSolrServer/CloudSolrServer/ZooKeeper, либо напрямую на один из узлов Apache Solr, оставляя второй узел менее нагруженным для ускорения поисковых запросов.
Нам требуется разбить рабочие коллекции, исходя из объема данных в партициях, полученных по ключу batchId. Для реализации нашего решения, потребуется еще один сервис, который будет управлять процессом разбиения коллекций. Назовем сервис — менеджер индекса (IndexManager). Функции менеджера:
- мониторинг размера текущих коллекций
- инициация создания новых при превышении лимитов (партиционирование)
- инициация объединения коллекций, если размер их упал ниже заданного лимита (объединение)
- мониторинг и управление процессом реиндексации в новых коллекциях (через команды индексатору)
- переключение рабочих коллекций после завершения индексации в новые и удаление старых
Оценить объем, который будет занимать индекс для одной или нескольких партиций, можно либо косвенно, либо после создания индекса.
Косвенная оценка выглядит так:
Rall — общее количество записей для всех партиций
Vall — общий объем индекса (collection)
Rn — количество записей для партиции N
Vn = Rn⋅Vall / Rall — предполагаемый объем коллекции для партиции N
Коллекция M формируется из партиций 1…k до тех пор пока Ssumm < Slimit, Ssumm — суммарный размер коллекции, Slimit — заданный лимит на размер коллекции.
Схема работы нового сервиса следующая: 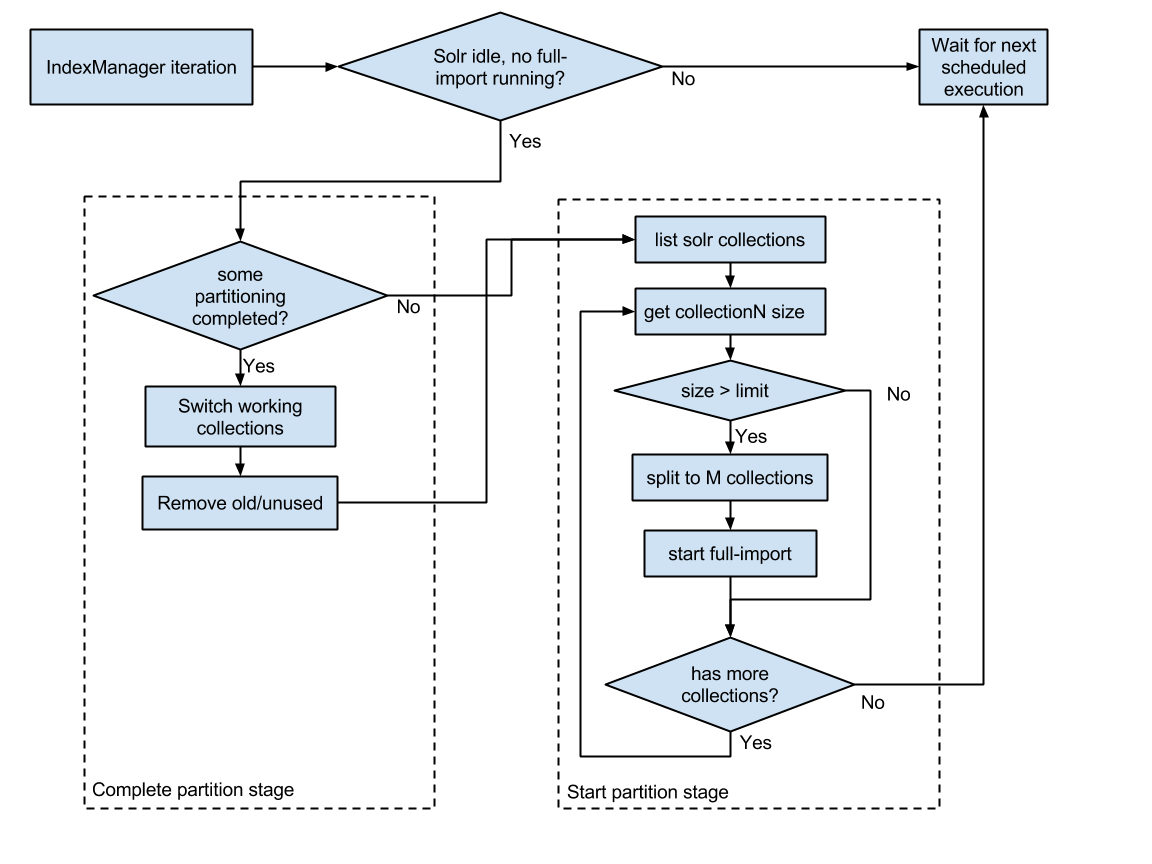
В результате работы IndexManager«a создаются/удаляются коллекции, запускается реиндексация данных в отдельных коллекциях, происходит переключение актуальных коллекций. Связь коллекций и исходных данных (batchId) сохраняется в базе данных.
Схема поисковой системы с партиционированием индексов выглядит так: 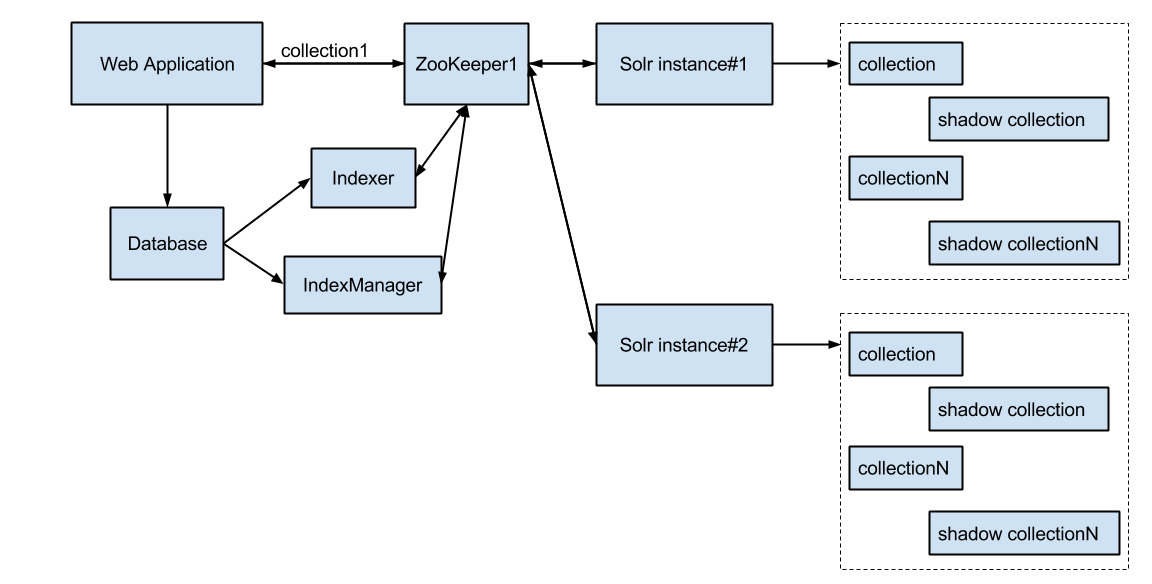
Индекс в этой схеме представляет собой N коллекций и N резервных коллекций на случай изменения в схеме индекса с последующей реиндексацией. Эти N коллекций хранятся на каждом узле Apache Solr, репликация происходит нативными средставами SolrCloud + ZooKeeper.
Ускорение поиска происходит за счет поиска по индексу, ограниченному одной коллекцией. Для этого в поисковый запрос добавляется HTTP-параметр collection (collection=batchId).
После запуска, создания и реиндексации коллекций, получили максимальный размер коллекции 0,1 от исходного и следующее распределение времени выполнения запросов:
| Время выполнения (мс) | До (% от общего кол-ва) | После (% от общего кол-ва) |
|---|---|---|
| >= 10000 | 2,2% | 0 |
| 1000 — 10000 | 3,8% | 0 |
| 500 — 1000 | 4,3% | 0 |
| 100 — 500 | 17,1% | 8,1% |
| 0 — 100 | 72,4% | 91,9% |
Результаты
- Уменьшение объема индекса, участвующего в поиске реализовано через контроль размера коллекций менеджером индекса.
- Минимум усилий по поддержке:
- сервера: одинаковая конфигурация до и после партиционирования. Сервис IndexManager работает в общей инфраструктуре сервисов и отдельного администрирования не требует
- однократное обновление конфигурации в ZooKeeper при изменении схемы индекса
- Минимум усилий по изменению структуры:
- изменение схемы индекса делается один раз для базовых коллекций
- изменение размеров коллекций, добавление новых и удаление лишних после объединения — автоматическое
- Отсутствие даунтайма — любая операция (разбиение, объединение коллекций) до своего завершения не влияет на поисковые индексы и индексацию, после завершения происходит атомарное переключение.
- Значительное ускорение обработки запросов.
