Повторная обработка событий, полученных из Kafka

Привет, Хабр.
Недавно я поделился опытом о том, какие параметры мы в команде чаще всего используем для Kafka Producer и Consumer, чтобы приблизиться к гарантированной доставке. В этой статье хочу рассказать, как мы организовали повторную обработку события, полученного из Kafka, в результате временной недоступности внешней системы.
Современные приложения работают в очень сложной среде. Бизнес-логика, обернутая в современный технологический стек, работающая в Docker-образе, который управляется оркестратором вроде Kubernetes или OpenShift, и коммуницирующая с другими приложениями или enterprise-решениями через цепочку физических и виртуальных маршрутизаторов. В таком окружении всегда что-то может сломаться, поэтому повторная обработка событий в случае недоступности одной из внешних систем — важная часть наших бизнес-процессов.
Как было до Kafka
Ранее в проекте мы использовали IBM MQ для асинхронной доставки сообщений. При возникновении какой-либо ошибки в процессе работы сервиса полученное сообщение могло быть помещено в dead-letter-queue (DLQ) для дальнейшего ручного разбора. DLQ создавался рядом с входящей очередью, перекладывание сообщения происходило внутри IBM MQ.
Если ошибка имела временный характер и мы могли это определить (например, ResourceAccessException при HTTP-вызове или MongoTimeoutException при запросе в MongoDb), то в силу вступала стратегия повторных вызовов. Вне зависимости от ветвления логики приложения, исходное сообщение перекладывалось или в системную очередь для отложенной отправки, или в отдельное приложение, которое когда-то давно было сделано для повторной отправки сообщений. При этом в заголовок сообщения записывается номер повторной отправки, который привязан к интервалу задержки или к концу стратегии на уровне приложения. Если мы достигли конца стратегии, но внешняя система все еще недоступна, то сообщение будет помещено в DLQ для ручного разбора.
Поиск решения
Поискав в интернете, можно найти следующее решение. Если коротко, то предлагается завести по топику на каждый интервал задержки и реализовать на стороне приложения Consumer«ы, которые будут вычитывать сообщения с необходимой задержкой.
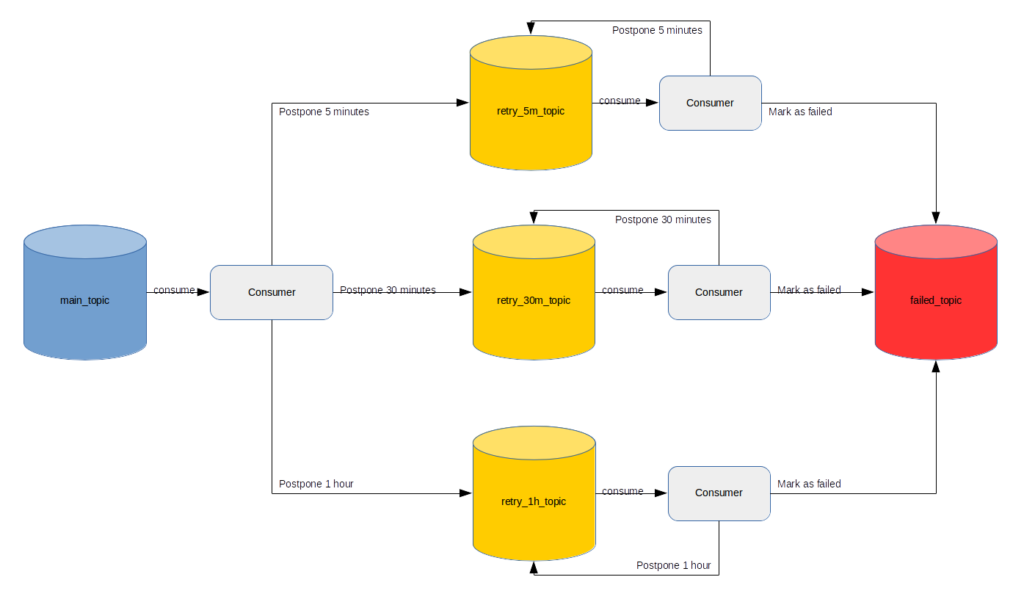
Несмотря на большое количество положительных отзывов, оно кажется мне не совсем удачным. В первую очередь потому, что разработчику, кроме реализации бизнес-требований, придется потратить много времени на реализацию описанного механизма.
Кроме того, если на Kafka-кластере включено управление доступами, то придется потратить какое-то время на заведение топиков и обеспечение необходимых доступов к ним. В дополнение к этому нужно будет подбирать правильный параметр retention.ms для каждого из ретрай-топиков, чтобы сообщения успевали повторно отправляться и не пропадали из него. Реализацию и запрос доступов придется повторять для каждого существующего или нового сервиса.
Давайте теперь посмотрим, какие механизмы для повторной обработки сообщения предоставляет нам spring в целом и spring-kafka в частности. Spring-kafka имеет транзитивную зависимость на spring-retry, который предоставляет абстракции для управления разными BackOffPolicy. Это довольно гибкий инструмент, но его значительным недостатком является хранение сообщений для повторной отправки в памяти приложения. Это значит, что перезапуск приложения из-за обновления или ошибки во время эксплуатации приведет к потере всех сообщений, ожидающих повторной обработки. Так как этот пункт критичен для нашей системы, мы не стали рассматривать его дальше.
Сама spring-kafka предоставляет несколько реализаций ContainerAwareErrorHandler, например SeekToCurrentErrorHandler, с помощью которого можно, не смещая offset в случае возникновения ошибки, обработать сообщение позже. Начиная с версии spring-kafka 2.3 появилась возможность задавать BackOffPolicy.
Этот подход позволяет повторно обрабатываемым сообщениям переживать рестарт приложения, но механизм DLQ по-прежнему отсутствует. Именно этот вариант мы выбрали в начале 2019 года, оптимистично полагая, что DLQ не понадобится (нам повезло и он действительно не понадобился за несколько месяцев эксплуатации приложения с такой системой повторной обработки). Временные ошибки приводили к срабатыванию SeekToCurrentErrorHandler. Остальные ошибки печатались в лог, приводили к смещению offset, и обработка продолжалась со следующим сообщением.
Итоговое решение
Реализация, основанная на SeekToCurrentErrorHandler, подтолкнула нас к разработке собственного механизма для повторной отправки сообщений.
Прежде всего мы хотели использовать уже имеющийся опыт и расширить его в зависимости от логики приложения. Для приложения с линейной логикой оптимальным было бы прекратить считывание новых сообщений в течение небольшого промежутка времени, заданного в рамках стратегии повторных вызовов. Для остальных приложений хотелось иметь единую точку, которая бы обеспечивала выполнение стратегии повторных вызовов. В дополнение эта единая точка должна обладать функциональностью DLQ для обоих подходов.
Сама стратегия повторных вызовов должна храниться в приложении, которое отвечает за получение следующего интервала при возникновении временной ошибки.
Остановка Consumer«a для приложения с линейной логикой
При работе с spring-kafka код для остановки Consumer«a может выглядеть примерно так:
public void pauseListenerContainer(MessageListenerContainer listenerContainer,
Instant retryAt) {
if (nonNull(retryAt) && listenerContainer.isRunning()) {
listenerContainer.stop();
taskScheduler.schedule(() -> listenerContainer.start(), retryAt);
return;
}
// to DLQ
}В примере retryAt — это время, когда нужно заново запустить MessageListenerContainer, если он еще работает. Повторный запуск произойдет в отдельном потоке, запущенном в TaskScheduler, реализацию которого тоже предоставляет spring.
Значение retryAt мы находим следующим способом:
- Ищется значение счетчика повторных вызовов.
- В соответствии со значением счетчика ищется текущий интервал задержки в стратегии повторных вызовов. Стратегия объявляется в самом приложении, для ее хранения мы выбрали формат JSON.
- Найденный в JSON-массиве интервал содержит в себе количество секунд, через которое необходимо будет повторить обработку. Это количество секунд прибавляется к текущему времени, образуя значение для retryAt.
- Если интервал не найден, то значение retryAt равно null и сообщение отправится в DLQ для ручного разбора.
При таком подходе остается только сохранить количество повторных вызовов для каждого сообщения, которое находится сейчас на обработке, например в памяти приложения. Сохранение счетчика попыток в памяти не критично для этого подхода, так как приложение с линейной логикой не может выполнять обработку в целом. В отличие от spring-retry перезапуск приложения приведет не к потере всех сообщений для повторной обработки, а просто к перезапуску стратегии.
Этот подход помогает снять нагрузку с внешней системы, которая может быть недоступна из-за очень большой нагрузки. Другими словами, в дополнение к повторной обработке мы добились реализации паттерна circuit breaker.
В нашем случае порог ошибки равен всего 1, а чтобы минимизировать простой системы из-за временного сетевого перебоя, мы используем очень гранулярную стратегию повторных вызовов с небольшими интервалами задержки. Это может не подойти для всех приложений группы компаний, поэтому соотношение между порогом ошибки и величиной интервала нужно подбирать, опираясь на особенности системы.
Отдельное приложение для обработки сообщений от приложений с недетерминированной логикой
Вот пример кода, отправляющего сообщение в такое приложение (Retryer), которое выполнит повторную отправку в топик DESTINATION при достижении времени RETRY_AT:
public void retry(ConsumerRecord record, String retryToTopic,
Instant retryAt, String counter, String groupId, Exception e) {
Headers headers = ofNullable(record.headers()).orElse(new RecordHeaders());
List arrayOfHeaders =
new ArrayList<>(Arrays.asList(headers.toArray()));
updateHeader(arrayOfHeaders, GROUP_ID, groupId::getBytes);
updateHeader(arrayOfHeaders, DESTINATION, retryToTopic::getBytes);
updateHeader(arrayOfHeaders, ORIGINAL_PARTITION,
() -> Integer.toString(record.partition()).getBytes());
if (nonNull(retryAt)) {
updateHeader(arrayOfHeaders, COUNTER, counter::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "retry"::getBytes);
updateHeader(arrayOfHeaders, RETRY_AT, retryAt.toString()::getBytes);
} else {
updateHeader(arrayOfHeaders, REASON,
ExceptionUtils.getStackTrace(e)::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "backout"::getBytes);
}
ProducerRecord messageToSend =
new ProducerRecord<>(retryTopic, null, null, record.key(), record.value(), arrayOfHeaders);
kafkaTemplate.send(messageToSend);
} Из примера видно, что много информации передается в хедерах. Значение RETRY_AT находится так же, как и для механизма повтора через остановку Consumer«a. Помимо DESTINATION и RETRY_AT мы передаем:
- GROUP_ID, по которому группируем сообщения для ручного анализа и упрощения поиска.
- ORIGINAL_PARTITION, чтобы постараться сохранить тот же Consumer для повторной обработки. Этот параметр может быть равен null, в таком случае новая partition будет получена по ключу record.key () оригинального сообщения.
- Обновленное значение COUNTER, чтобы следовать стратегии повторных вызовов.
- SEND_TO — константа, показывающая, отправить ли сообщение на повторную обработку по достижении RETRY_AT или поместить в DLQ.
- REASON — причина, по которой обработка сообщения была прервана.
Retryer сохраняет сообщения для повторной отправки и ручного разбора в PostgreSQL. По таймеру запускается задача, которая находит сообщения с наступившим RETRY_AT и отправляет их обратно в партицию ORIGINAL_PARTITION топика DESTINATION с ключом record.key ().
После отправки сообщения удаляются из PostgreSQL. Ручной разбор сообщений происходит в простом UI, который взаимодействует с Retryer по REST API. Основными его особенностями являются переотправка или удаление сообщений из DLQ, просмотр информации об ошибке и поиск сообщений, например по имени ошибки.
Так как на наших кластерах включено управление доступом, необходимо дополнительно запрашивать доступы к топику, который слушает Retryer, и дать возможность Retryer«у писать в DESTINATION топик. Это неудобно, но, в отличие от подхода с топиком на интервал, у нас появляется полноценная DLQ и UI для управления ею.
Бывают случаи, когда входящий топик читают несколько разных consumer-групп, приложения которых реализуют разную логику. Повторная обработка сообщения через Retryer для одного из таких приложений приведет к дубликату на другом. Чтобы защититься от этого, мы заводим отдельный топик для повторной обработки. Входящий и retry-топик может читать один и тот же Consumer без каких-либо ограничений.
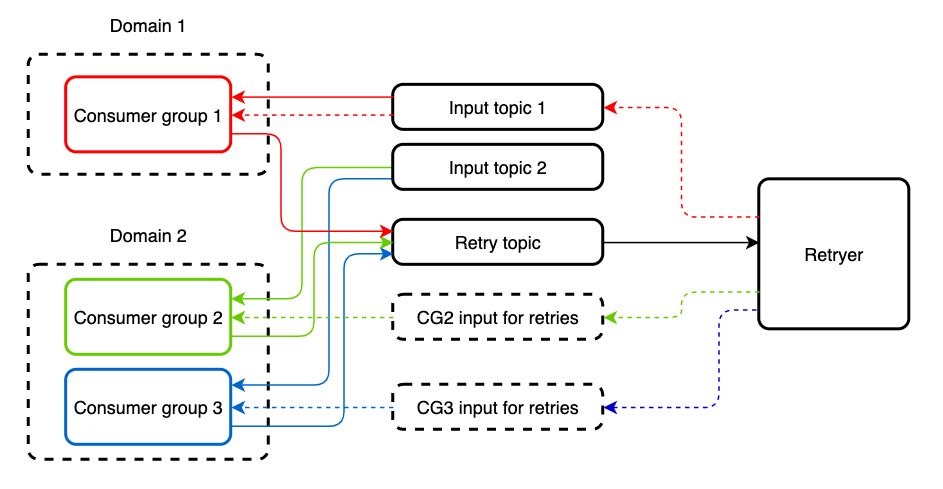
По умолчанию этот подход не предоставляет возможности circuit breaker«a, однако его можно добавить в приложение с помощью spring-cloud-netflix или нового spring cloud circuit breaker, обернув места вызовов внешних сервисов в соответствующие абстракции. Кроме того, появляется возможность выбора стратегии для bulkhead паттерна, что тоже может быть полезно. Например, в spring-cloud-netflix это может быть thread pool или семафор.
Вывод
В результате у нас получилось отдельное приложение, которое позволяет повторить обработку сообщения при временной недоступности какой-либо внешней системы.
Одним из главных преимуществ приложения является то, что им могут пользоваться внешние системы, работающие на том же Kafka-кластере, без значительных доработок на своей стороне! Такому приложению необходимо будет только получить доступ к retry-топику, заполнить несколько Kafka-заголовков и отправить сообщение в Retryer. Не нужно поднимать никакой дополнительной инфраструктуры. А чтобы уменьшить количество перекладываемых сообщений из приложения в Retryer и обратно, мы выделили приложения с линейной логикой и сделали в них повторную обработку через остановку Consumer.
