Построение графов для чайников: пошаговый гайд
Ранее мы публиковали пост, где с помощью графов проводили анализ сообществ в Точках кипения из разных городов России. Теперь хотим рассказать, как строить такие графы и проводить их анализ.

Под катом — пошаговая инструкция для тех, кто давно хотел разобраться с визуализацией графов и ждал подходящего случая.
1. Выбор гипотезы
Если попытаться визуализировать хотя бы что-то, бездумно загрузив данные в программу построения графов, результат вас не порадует. Поэтому сначала сформулируйте для себя, что хотите узнать с помощью графов, и придумайте жизнеспособную гипотезу.
Для этого разберитесь, какие данные у вас уже есть, что из них можно представить «объектами», а что — «связями» между ними. Обычно объектов значительно меньше, чем связей — можно таким образом проверять себя.
Наш тестовый пример мы готовили совместно с командой Точки кипения из Томска. Соответственно, все данные для анализа по мероприятиям и их участникам у нас будут именно оттуда. Нам стало интересно, сформировалось ли из участников этих мероприятий сообщество и как оно выглядит с точки зрения принадлежности участников к бизнесу, университетам и власти.
Мы предположили, что люди, которые посетили одно и то же мероприятие, связаны друг с другом. Причем чем чаще они присутствовали на мероприятиях совместно, тем сильнее связь.
Во втором случае мы решили узнать, как соотносится принадлежность участников к одному из «нетов» (наших ключевых направлений) с интересующими их сквозными технологиями. Равномерно ли распределение, есть ли «горячие темы»? Для этого анализа мы взяли данные по участникам мероприятий из 200 томских технологических компаний.
В принципе, даже таких первичных формулировок гипотез достаточно, чтобы перейти ко второму шагу.
2. Подготовка данных
Теперь, когда вы определились с тем, что хотите узнать, возьмите весь массив данных, посмотрите, какая информация об «объектах» хранится, выкиньте все лишнее и добавьте недостающее. Если данные распределены по нескольким источникам, предварительно соберите все в одну кучу, убрав дубли.
Поясню на примере. У нас были данные об участниках 650 мероприятий. Это, условно говоря, 650 эксель-таблиц с ~23000 записей в них, содержащих поля «Leader ID», «Должность», «Организация». Для постройки графа достаточно одного уникального идентификатора (тут, к счастью, такой есть — это Leader ID) и признака, привязывающего каждого участника к одной из трех рассматриваемых сфер: власти, бизнесу или университетам. И этой информации у нас еще нет.
Чтобы получить ее, можно пойти напролом: в каждом из 650 файлов убрать лишние столбцы и добавить новое поле, заполнить его значениями для каждой строки, например:»1» для власти,»2» для бизнеса и »3» для образования и науки. А можно сначала объединить все 650 файлов в один большой список, убрать дубли и только после этого добавлять новые значения. В первом случае такая работа займет 1–2 месяца. Во втором — 1–2 недели.
Вообще при добавлении новых атрибутов старайтесь предварительно группировать данные. Например, можно отсортировать участников по компаниям/организациям и скопом выставлять признак.
Готовим данные дальше. Для их загрузки в большинство программ визуализации потребуется создать два файла: один — с перечнем вершин, второй — со списком ребер.
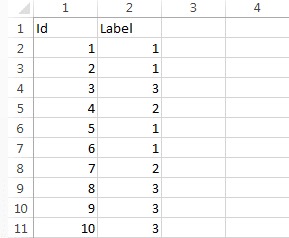
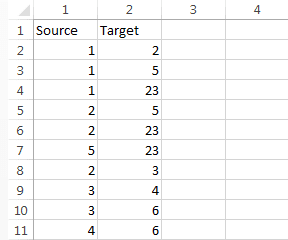
Файл вершин в нашем случае содержал два столбца: Id — номер вершины и Label — тип. Файл ребер содержал также два столбца: Source — id начальной вершины, Target — id конечной вершины.
Как превратить данные о том, что участники 1, 2, 5 и 23 посетили одно мероприятие, в ребра? Необходимо создать шесть строк и отметить связь каждого участника с каждым: 1 и 2, 1 и 5, 1 и 23, 2 и 5, 2 и 23, 5 и 23.
Во втором нашем примере таблицы выглядели так:
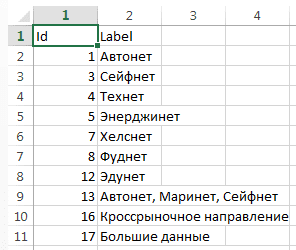
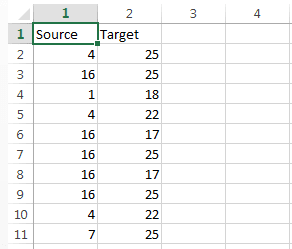
В качестве вершин перечислены как рынки, так и сквозные технологии. Если, скажем, представитель компании, относящейся к рынку «Технет» (ID=4), посетил мероприятие по теме «Большие данные и ИИ» (ID=17), в таблицу ребер заносим ребро (строку), соединяющее эти вершины (Source=4, Target=17).
Этап подготовки данных — это самая трудоемкая часть процесса, но наберитесь терпения.
3. Визуализация графа
Итак, таблицы с данными подготовлены, можно искать средство для их представления в виде графа. Для визуализации мы использовали программу Gephi — мощный опенсорсный инструмент, способный обрабатывать графы с сотнями тысяч вершин и связей. Скачать его можно с официального сайта.
Скриншоты я буду делать со второго проекта, в котором было небольшое число вершин и связей, чтобы все было максимально понятно.
Первым делом нам надо загрузить таблицы с вершинами и ребрами. Для этого выбираем пункт «Импортировать из CSV» из меню раздела «Лаборатория данных».
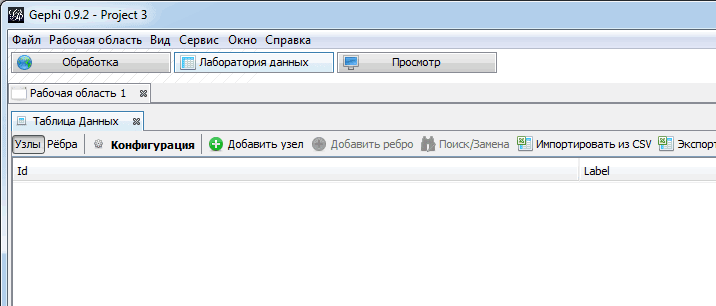
Сначала грузим файл с вершинами. На первом экране формы указываем, что импортируем именно вершины, и проверяем, чтобы программа правильно определила кодировку подписей.
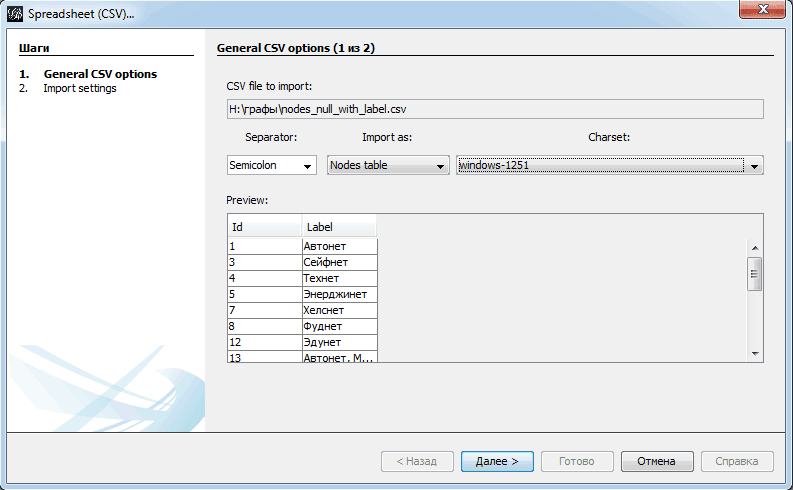
На третьей форме «Отчет об импорте» важно указать тип графа. У нас он не ориентирован.
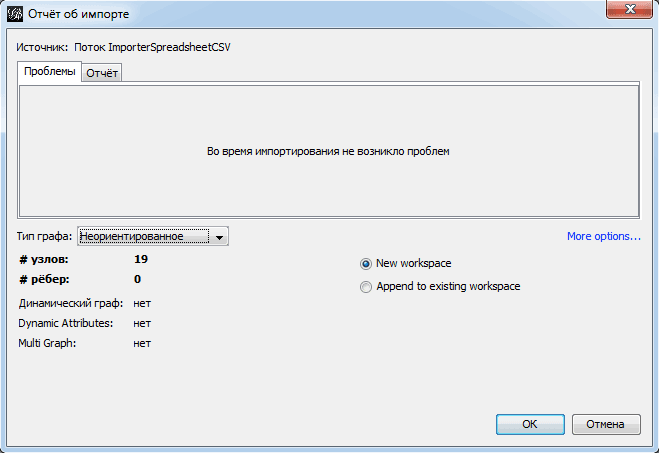
Похожим образом грузим ребра. В первом окне указываем, что это файл с ребрами, и также проверяем кодировку.
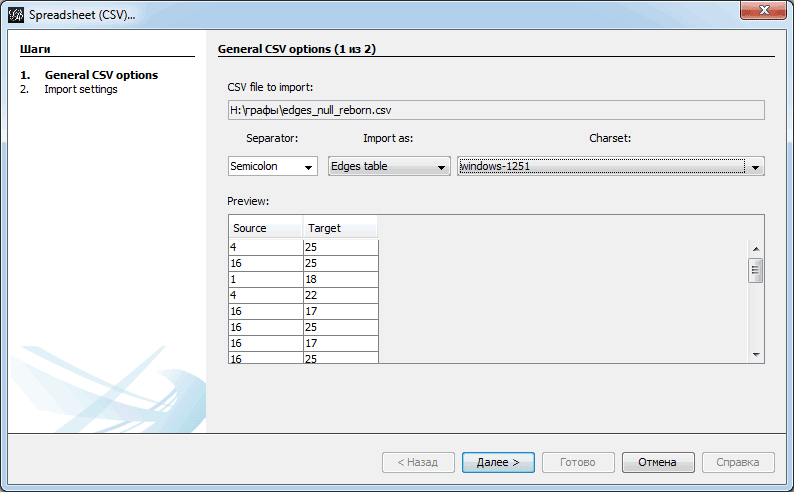
Важный момент ждет нас в третьем окне «Отчет об импорте». Тут важно указать не только то, что граф не ориентирован, но и подгрузить ребра в то же рабочее пространство, что и вершины. Поэтому выбираем пункт «Append to existing workplace».

В результате перед нами предстанет граф примерно вот в таком виде (закладка «Обработка»):
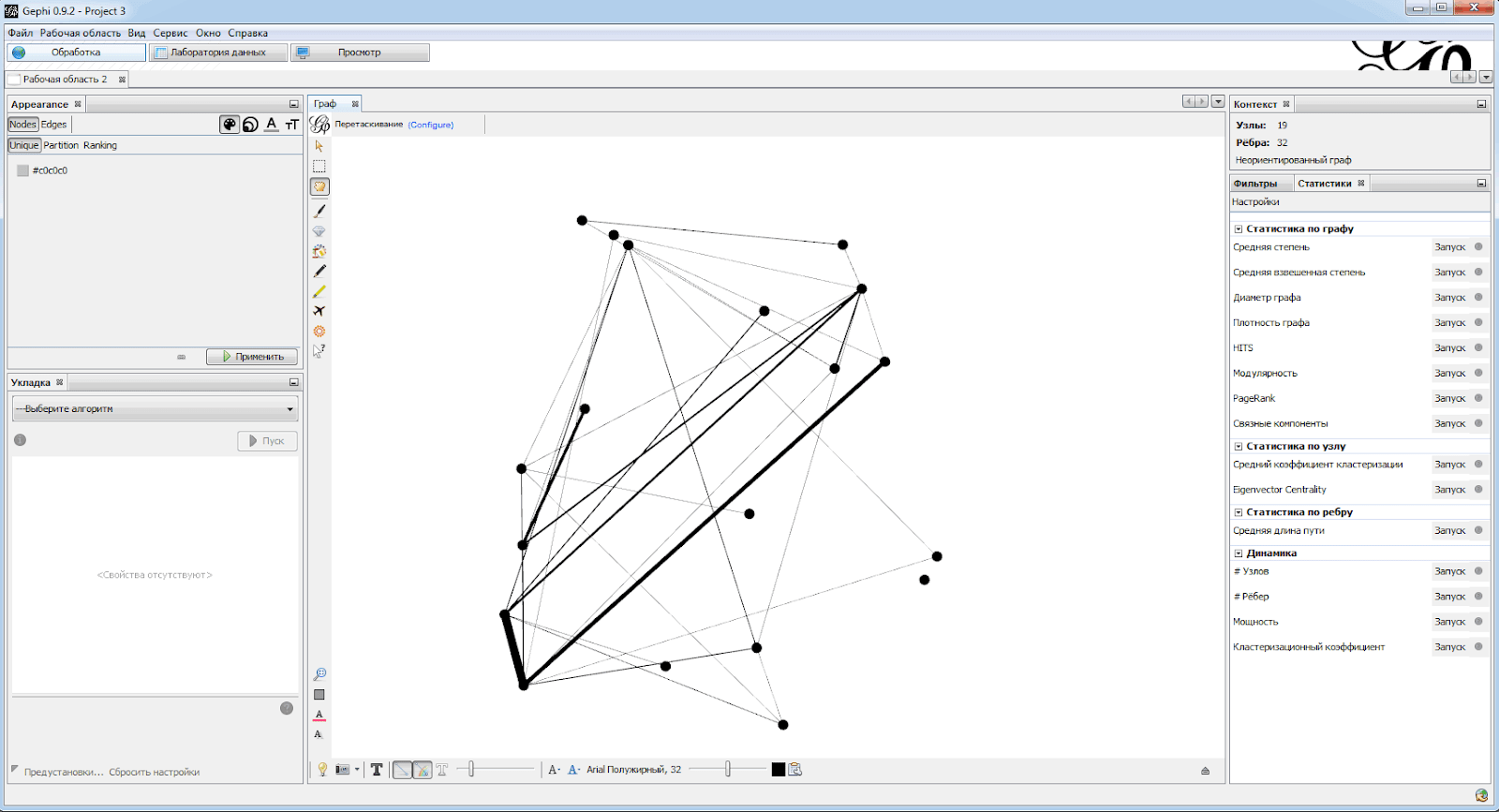
Итак, ребра имеют разную толщину в зависимости от количества связей между вершинами. Посмотреть, какой вес стал у каждого ребра, можно на закладке «Лаборатория данных» в свойствах ребер в столбце Weight.
Что здесь плохо: все вершины имеют один размер и расположены абсолютно произвольно. На закладке «Обработка» мы это исправим. Сначала в верхнем левом окне выбираем Nodes и жмем на пиктограммку с кругами («Размер»). Далее выбираем пункт Ranking — он позволяет задать размер вершины в зависимости от какого-либо параметра. У нас есть возможность выбрать только один параметр — Degree (степень), который показывает, сколько ребер выходят из вершины. Выбираем минимальный и максимальный размер кружочка и жмем кнопку «Применить». Здесь же, если выбрать другие пиктограммки, можно настроить цвет маркера вершины и цвет ребер. Теперь граф уже более нагляден.

Следующее, что нужно сделать, — распутать граф. Это можно сделать вручную, двигая вершины, а можно использовать алгоритмы укладки, которые реализованы в Gephi.
Чего мы добиваемся правильной укладкой? Максимальной наглядности. Чем меньше на графе наложений вершин и ребер, чем меньше пересечений ребер, тем лучше. Также неплохо было бы, чтобы смежные вершины были расположены поближе друг к другу, а несмежные —подальше друг от друга. Ну и все было распределено по видимой области, а не сжато в одну кучу.
Как это сделать в Gephi? Левое нижнее окно «Укладка» содержит самые популярные алгоритмы укладки, построенные на силовых аналогиях. Представьте, что вершины — это заряженные шарики, который отталкиваются друг от друга, но при этом некоторые скреплены чем-то, похожим на пружинки. Если задать соответствующие силы и «отпустить» граф, вершины разбегутся на максимально допустимые пружинками расстояния.
Наиболее равномерную картину дает алгоритм Фрюхтермана и Рейнгольда. Выберите Fruchterman Reingold из выпадающего меню и задайте размер области построения. Нажмите кнопку «Исполнить». Получится что-то вроде этого:
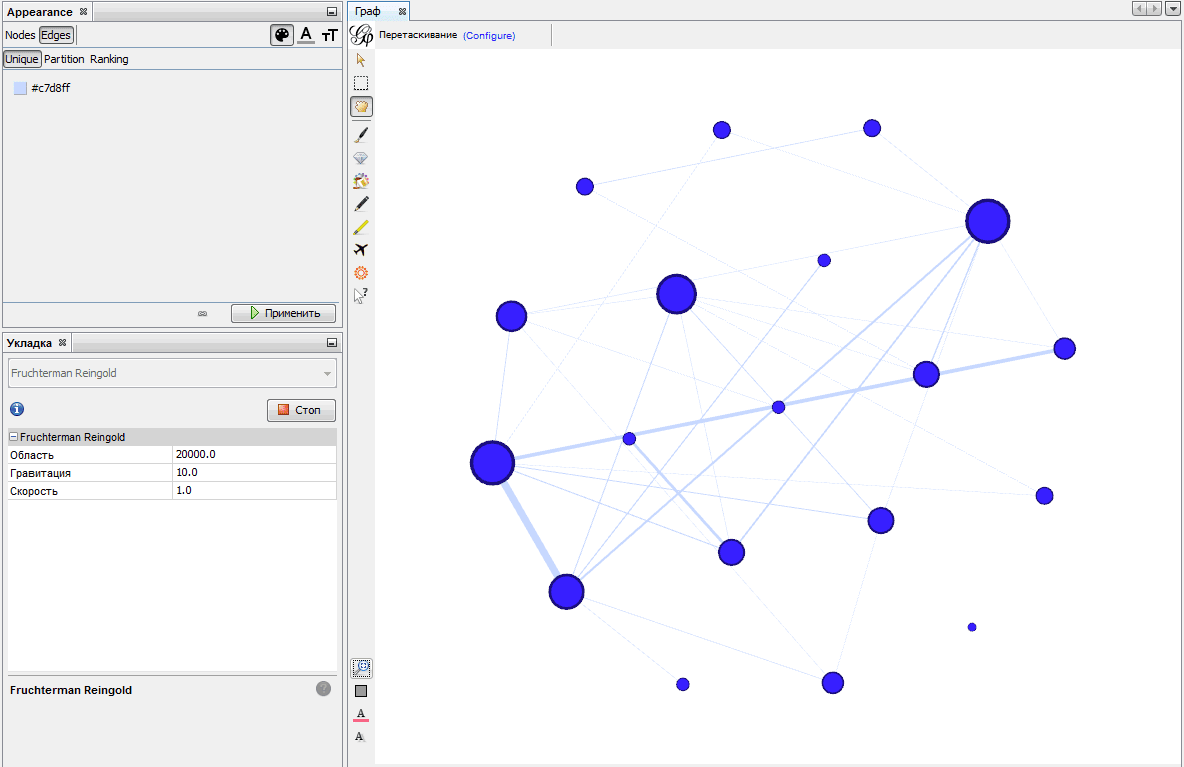
Можно помочь алгоритму и, не останавливая его, поперетаскивать некоторые вершины, стараясь распутать граф. Но помните, что здесь нет кнопки «Отменить», вернуться к прежнему расположению вершин уже не удастся. Поэтому сохраняйте новые версии проекта перед каждым рискованным изменением.
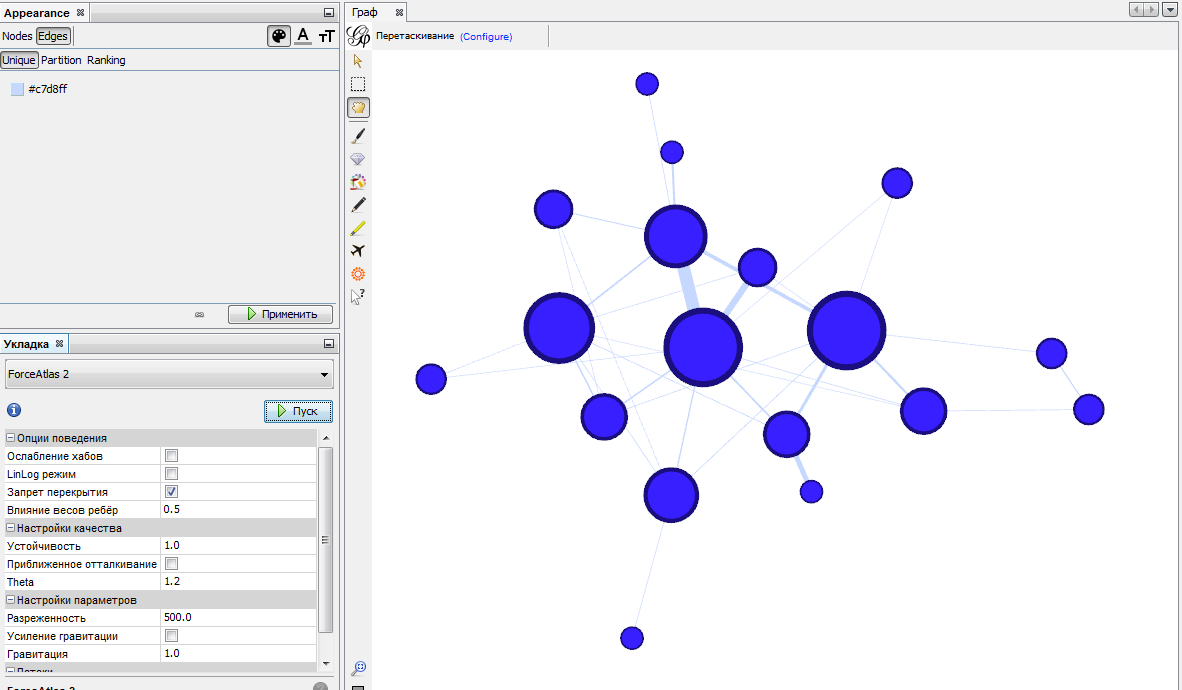
Еще один полезный алгоритм — Force Atlas 2. Он представляет граф в виде металлических колец, связанных между собой пружинами. Деформированные пружины приводят систему в движение, она колеблется и в конце концов принимает устойчивое положение. Этот алгоритм хорош для визуализаций, подчеркивающих структуру группы и выделяющих подмножества с высокой степенью взаимодействия.
Этот алгоритм имеет большое количество настроек. Рассмотрим наиболее важные. «Запрет перекрытия» запрещает вершинам перекрывать друг друга. Разреженность увеличивает расстояние между вершинами, делая граф более читаемым. Также более воздушным граф делает уменьшение влияния весов ребер на взаимное расположение вершин.
Поигравшись с настройками, получим такой граф:
Получив граф в том виде, который вас устраивает, переходите к финальной обработке. Это закладка «Просмотр». Здесь мы можем задать, например, отрисовку графа кривыми ребрами, которая минимизирует наложение вершин на чужие ребра. Можем включить подписи вершин, задав размер и цвет шрифта. Наконец, поменять фон подложки. Например, так:
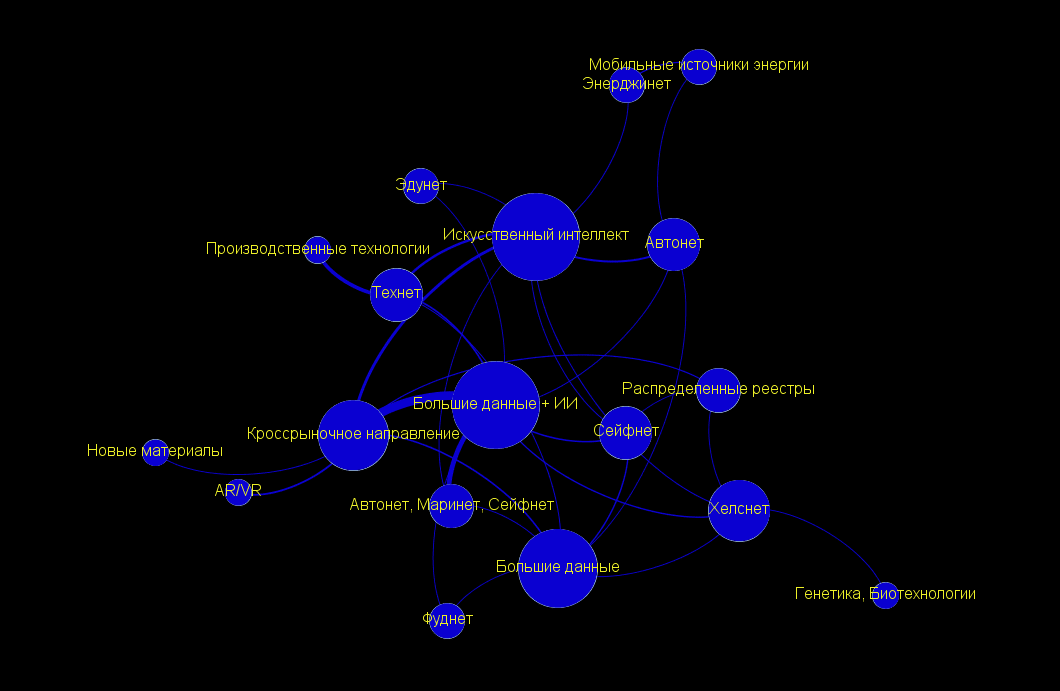
Для того чтобы сохранить получившийся рисунок, нажмите на надпись «Экспорт SVG/PDF/PNG в левом нижнем углу окна. Также отдельно не забудьте сохранить сам проект через верхнее меню «Файл» — «Сохранить проект».
В нашем случае принципиально было выделить взаимосвязь сквозных технологий с рынками НТИ, для чего мы вручную выстроили все рынки в одну линию в центре и разместили все остальное сверху и снизу. Получился вот такой граф. Все-таки для решения конкретных задач без ручной расстановки вершин обойтись не удалось.
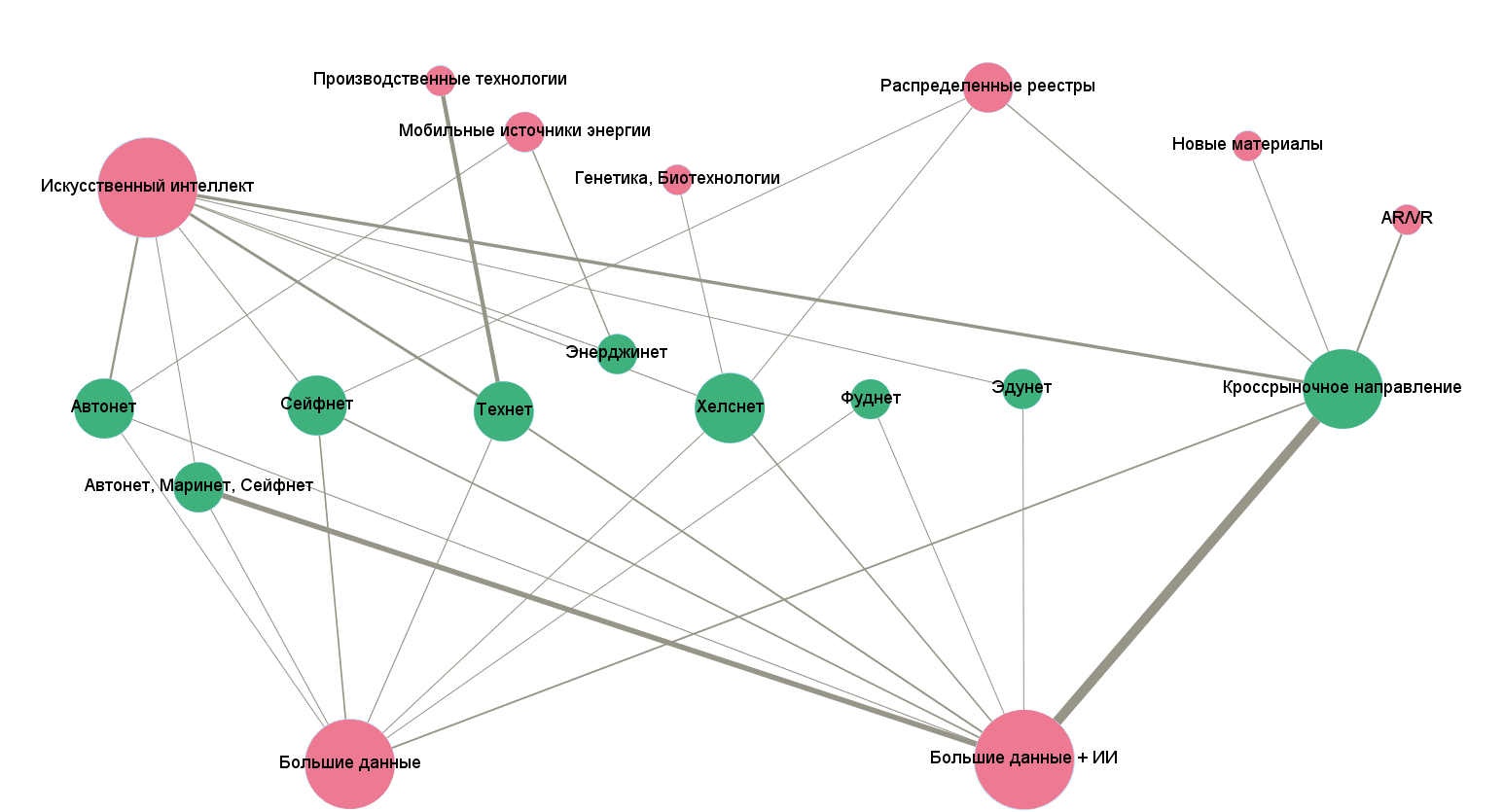
Вы, наверное, думаете, как нам удалось раскрасить вершины в разный цвет? Есть одна хитрость. Можно перейти в закладку «Лаборатория данных», создать там новый столбец в вершинах, назвав его «Market». И заполнить для каждой вершины значениями: 1 если это рынок НТИ, 0 — если сквозная технология. Затем достаточно перейти в «Обработку», выбрать пиктограммку в виде палитры, Nodes — Partition, а в качестве разделителя — наш новый атрибут Market.
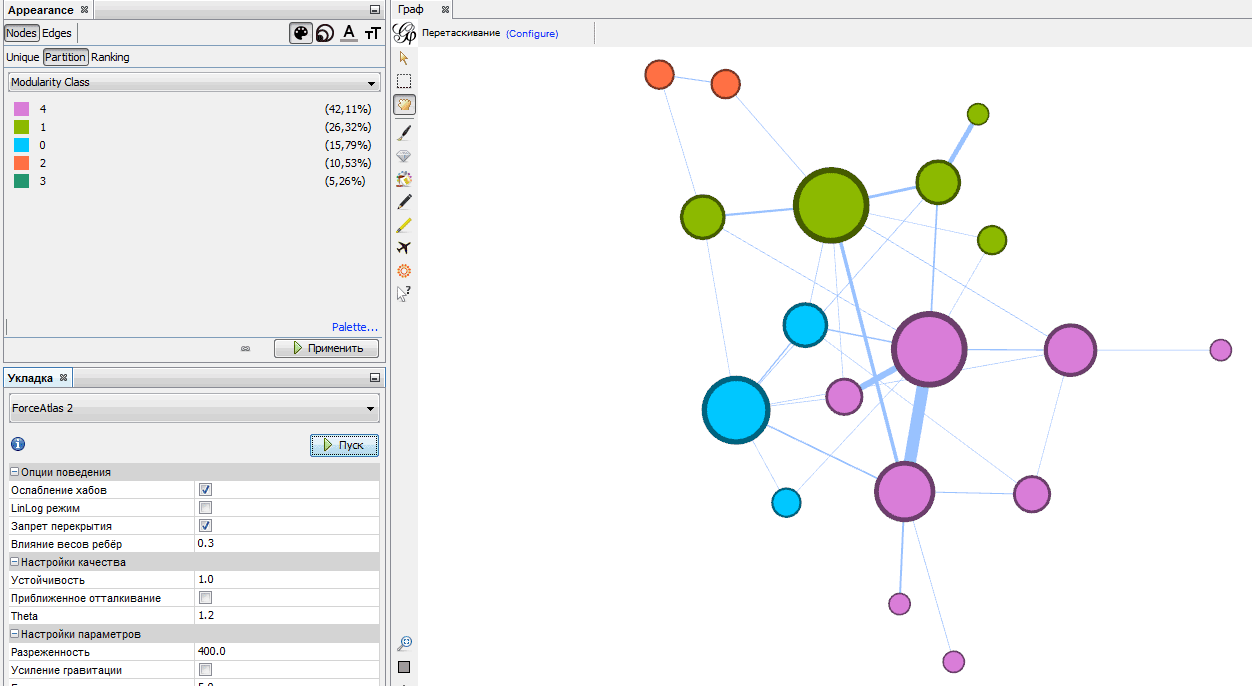
Для более сложных построений, когда требуется выделить кластеры и закрасить их разными цветами, в Gephi используется богатый арсенал статистических расчетов, результаты которых можно использовать для раздельной окраски. Находятся эти расчеты в правом столбце вкладки «Обработка».

Например, нажав кнопку «Запуск» возле расчета «Модулярность», вы узнаете оценку уровня кластеризации вашего графа. Если после этого выставить цвет вершин в зависимости от Modularity Class, появится симпатичная картинка наподобие такой:
Если вы хотите еще больше узнать о возможностях Gephi, стоит почитать руководство по работе с программой от Мартина Гранджина http://www.martingrandjean.ch/gephi-introduction/.
4. Анализ результата
Итак, вы получили итоговую визуализацию графа. Что она вам дает? Во-первых, это красиво, ее можно вставить в презентацию, показать знакомым или сделать заставкой на рабочем столе. Во-вторых, по ней вы можете понять, насколько сложной и многокластерной структурой является рассматриваемая вами предметная область. В-третьих, обратите внимание на самые крупные вершины и на самые жирные связи. Это особенные элементы, на которых все держится.
Так, построив граф экспертного сообщества, посещающего мероприятия в Точке кипения, мы сразу обнаружили участников, которые с наибольшей вероятностью выполняют роль суперконнекторов. Они являлись «вершинами», через которые кластеры объединялись в единое целое. А во втором случае мы увидели, как выглядит концентрация специалистов из томских компаний с точки зрения их принадлежности к рынку и сквозной цифровой технологии, на которую они делают ставку. Это косвенно говорит об уровне технологических компетенций и экспертизы региона.
Помощь графов в понимании окружающей действительности реально велика, так что не поленитесь и попробуйте создать собственную визуализацию данных. Это совсем не сложно, но порой трудозатратно.
