Построение DWH на основе Greenplum
DBA в Southbridge Иван Чувашов подготовил статью о построении DWH на основе Greenplum. Слово Ивану.
Привет, Хабр! Я администратор баз данных с 15-летним опытом. Сегодня хочу рассказать про Data Warehouse на основе Greenplum — как они устроены, как их поднимать и с какими проблемами и нюансами я лично сталкивался в своей практике. Статья написана на основе вебинара. Если вам удобнее, можете посмотреть его запись на Youtube.
Общая информация про Greenplum
Greenplum — это система, которая позволяет строить большие хранилища данных и управлять данными, расположенными в них. Среди open source-решений она самая популярная, и большинство компаний строят DWH, используя Greenplum, либо планируя внедрить её в своих проектах.
Greenplum позволяет распределить данные по нодам и разделять по ним процессы обработки. Это даёт возможность быстрее обрабатывать большое количество данных.
Представим, что у нас есть 100–200 миллиардов строк данных в таблице. И если мы хотим сделать агрегацию по всем записям в таблице, то нам потребуется много времени для получения результата. В Greenplum же, имея 16 нод, мы разобьем эти записи по нодам и выполним отдельно агрегацию на каждой ноде. Таким образом распараллелим наш запрос на 16 процессов. Один процесс равен одной ноде.
Общая структура Greenplum визуально выглядит следующим образом:

Прежде чем будем описывать рисунок, давайте введем понятия, а то запутаемся.
Мастер-нода — это нода кластера Greenplum, управляющая всеми остальными нодами.
Резервная мастер-нода — это реплика мастер-ноды Greenplum. Используется для создания отказоустойчивого решения. Защита от потери данных на мастер-ноде.
Сегмент Greenplum — экземпляр PostgreSQL, поднятый на сервере. На одном сервере может быть несколько сегментов Greenplum.
Есть мастер-нода, которая управляет всеми сегментами кластера Greenplum. Для каждого сегмента можно создать свою реплику на другом сервере. Такая реализация нужна на случай отказа одного из сегментов Greenplum.
Мастер-нода понимает, что один из сегментов вышел из строя, и сама промоутит реплику сегмента до лидера и подключается к ней для выполнения задач. По сути на уровне сегментов реализован высокодоступный кластер.
Однако на уровне мастер-ноды такой сценарий не реализован. Можно сделать физическую репликацию на резервную мастер-ноду, но штатного механизма, который управлял бы этим переключением, нет.
Сейчас Greenplum работает на PostgreSQL 9.4. Теперь разберём конфигурацию кластера и поговорим на практических примерах о некоторых особенностях Greenplum.
Конфигурация кластера
Кластер работает со скоростью самого медленного сервера, поэтому нужно выбирать однородные серверы и равномерно распределять данные по ним. Бывает, что к кластеру подключают один или несколько медленных серверов, и производительность кластера Greenplum резко падает. Так как мастер-нода ждёт ответа от всех сегментов, и только потом выдаёт общий ответ.
Greenplum требовательна к ресурсам: процессу, памяти и чуть в меньшей степени к диску. Так как Greenplum поддерживает сжатие данных на уровне дисковой подсистемы, то чтение данных с диска, загрузка их в память, разархивирование — достаточно дорогие операции. Поэтому минимальные системные требования — это 8 ядер и 16 Гб оперативки на каждый сегмент ноды. Если на сервере несколько сегментов, то число ядер и оперативки нужно кратно увеличивать.
Немного поделюсь личным опытом. Я с Greenplum познакомился ещё в 2020 году. На тот момент я давно администрировал PostgreSQL, но никак не мог понять, как работает Greenplum — мои ожидания не совпадали с реальностью. Первый кластер, который я сконфигурировал, упал сразу при первой же серьёзной нагрузке — пришлось всё собирать заново. Тогда я начал погружаться в тему Greenplum и понял, что я администрирую Greenplum как PostgreSQL, а это разные технологии. Главным для меня открытием было, что Greenplumn — это система с разделяемой оперативной памятью, а PostgreSQL — наоборот с общей памятью. Этим объясняются её особенности работы на сегментах.
Теперь поговорим об отдельных моментах конфигурации Greenplum.
Колоночное хранение данных
В Greenplum можно создать обычную heap-таблицу на 10 миллионов записей. Она будет занимать почти 500 Мб. Если же создать точно такую же колоночную таблицу, то её размер будет уже 101 Мб. Из-за сжатия таблица стала почти в 5 раз меньше. Вот как это выглядит на практике:
Heap-таблицы | Column-таблицы |
|
|
 Column-хранение сжатием данных
Column-хранение сжатием данных
Получается, сжатие уменьшило размер таблицы на диске в пять раз — для больших объемов данных это серьёзный профит. Я встречал базы на 20, 30 и даже 100 Тб — представьте, что их можно сжать в 3–5 раз и оцените, сколько денег это сэкономит компании.
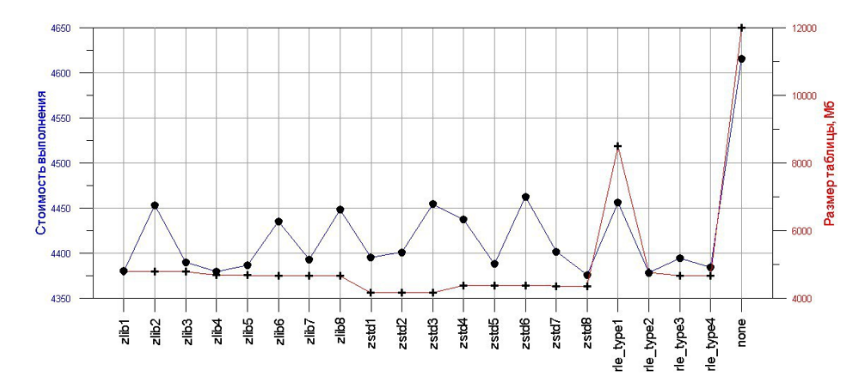
Greenplum поддерживает три типа сжатия: zstd, zlib и rle_type. Я рекомендую zstd — сами разработчики говорят, что он сжимает данные лучше всего. Это особенно хорошо видно на графике, где красная линия — сжатие данных, а синяя — стоимость запроса при использовании разных типов:
 Column-хранение сжатием данных
Column-хранение сжатием данных
Вообще стоимость выполнения запроса — достаточно аморфная величина, особенно для Greenplum. Она позволяет понять, лучше или хуже стал запрос относительно самого себя, но не связана с внешними метриками. Больше стоит смотреть на то, насколько сильно произошло сжатие данных.
Колоночная таблица хранит каждую колонку в отдельном файле. Поэтому получается, что чем больше в таблице колонок — тем больше операций к ней. Мы проводили эксперимент — создали таблицы на 10, 20, 50 и 100 колонок, добавили 20 миллионов записей в них и проанализировали, как выполняются апдейты в этих таблицах. Получилась интересная закономерность:
 Зависимость времени работы операции UPDATE от количества колонок в таблице
Зависимость времени работы операции UPDATE от количества колонок в таблице
Чем больше колонок, тем хуже выполняется запрос, это логично. И разница между максимальным и минимальным значением растет линейно, как и между средним и минимальным.
Причём чем колонок больше, тем серьёзнее разрыв между средним и максимальным выполнением. При 10 колонках разрыв увеличился всего в два раза, а при ста — уже в пять раз.
Ещё одна особенность колоночной таблицы: для неё нельзя создавать первичные ключи и уникальные индексы. Поэтому обеспечить консистентность данных в ней сложно — за данными нужно следить на уровне приложения или скриптов, которые работают с данными.
При этом важно понимать, что если использовать heap-таблицы, Greenplum не станет OLTP-системой. У меня были дискуссии о том, что раз heap-таблицы есть, мы просто переведём все наши 10–15 Тб OLTP в Greenplum и будем наслаждаться жизнью без падения скорости выполнения запросов. Но Greenplum для этого просто не предназначена — она заточена именно под аналитические запросы.
По моему опыту выполнение одного запроса занимает у Greenplum 100 мс. На эту цифру и нужно ориентироваться.
Дистрибуция данных
В Greenplum есть три вида дистрибуции:
DISTRIBUTED RANDOMLY — случайное распределение по сегментам Greenplum. Наши данные шардируются по сегментам, вычисляя хэш таблицы.
DISTRIBUTED by
— распределение по полям таблицы. Зная соединение между таблицами, можем распределить данные на сегментах так, чтобы соединение выполнялось на этой же ноде. Таким образом увеличивается быстродействие запросов, сокращается время на пересылку данных между сегментами. DISTRIBUTED REPLICATED — полная копия данных на каждом сегменте
Greenplum, актуальна для справочников. Например, при формировании отчёта, включающего в себя данные из множества небольших по размеру справочников, можно увеличить быстродействие запроса, разместив дубликаты справочников на каждом сегменте и исключив пересылку данных.
Для сравнения скоростей выполнения запросов мы провели эксперимент — взяли каждый из видов дистрибуции и два типа оптимизатора: ORCA и PostgreSQL. А потом посмотрели, как всё это работает.
Распределение данных случайным образом
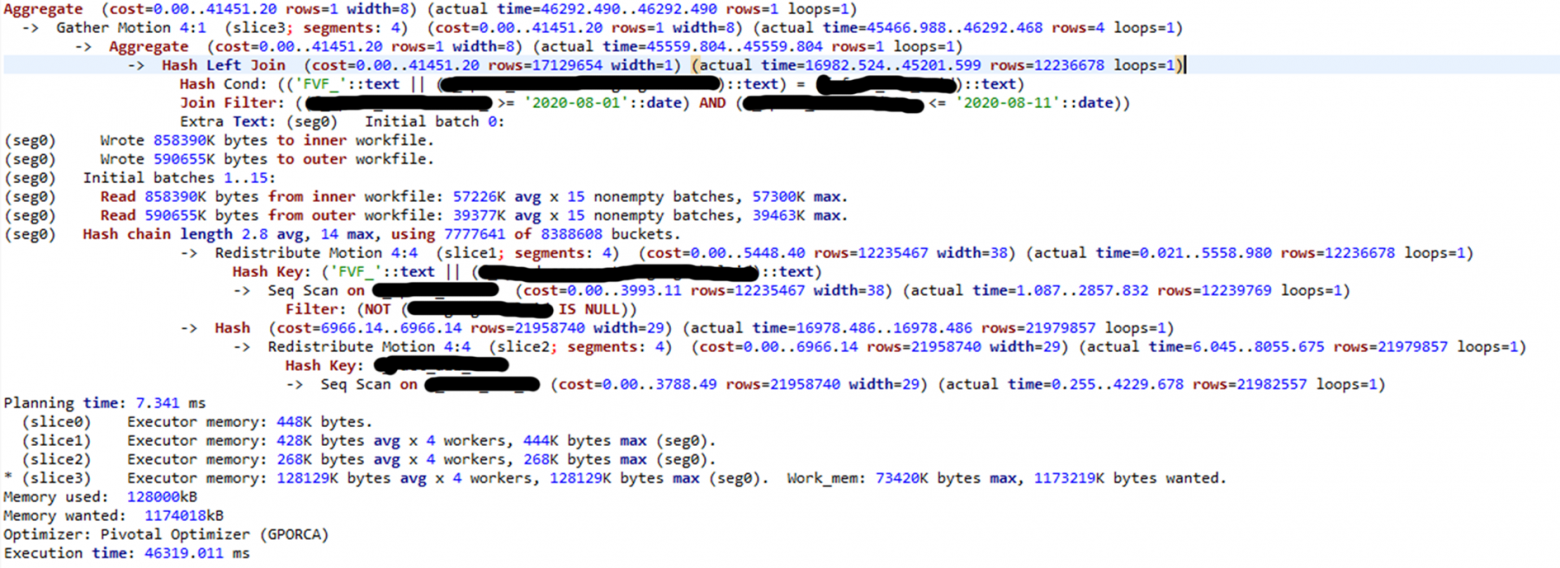
Здесь у нас большая таблица — около миллиарда записей, фильтр по дате, соединение с таблицей с миллионом записей. Вот как это выглядит:
 Оптимизатор GPORCA. Распределение данных случайным образом
Оптимизатор GPORCA. Распределение данных случайным образом
Самое интересное здесь — ключ распределения: добавляется поле FVF. Если бы в PostgreSQL был индекс, он бы не использовался из-за этого условия. Здесь при рандомном распределении появляется Redistribute Motion, то есть пересылка данных по сегментам. На обращение к сегментам ушло достаточно много времени — этого можно избежать, если использовать распределение по полю.
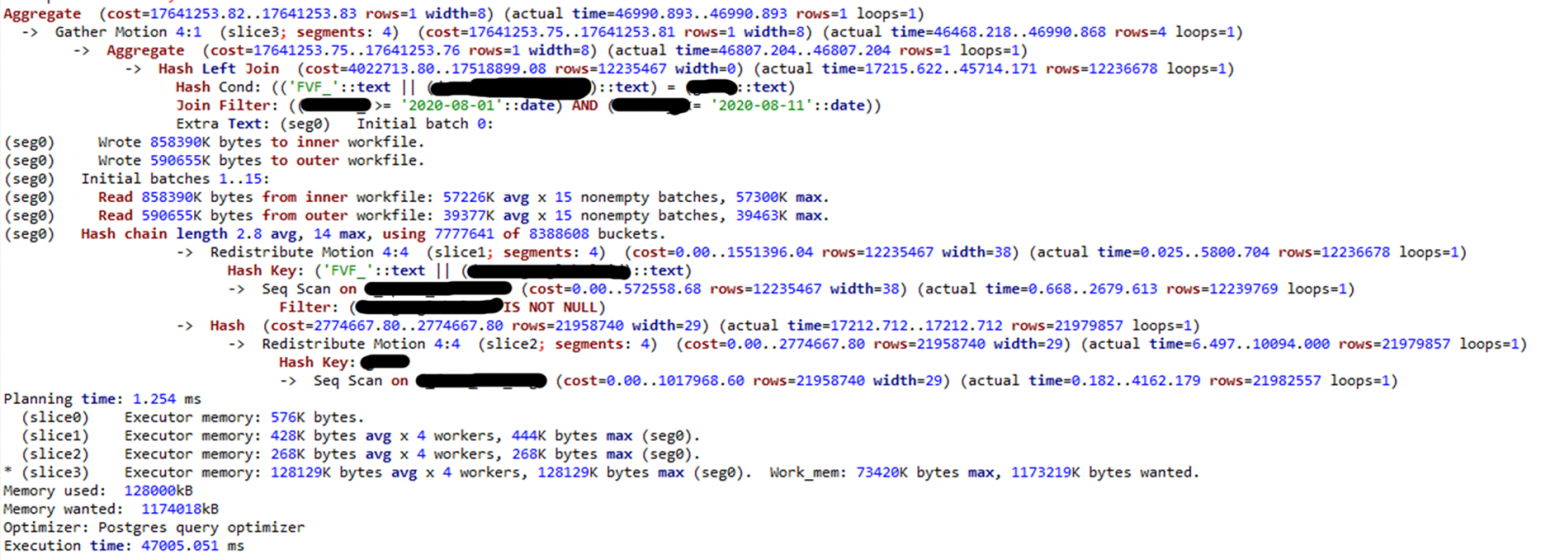
Здесь особенно интересно посмотреть за стоимостью. Наш запрос выполнился всего за 41 тысячу cost. При использовании оптимизатора PostgreSQL картина будет совсем другая:
 Оптимизатор PostgreSQL. Распределение данных случайным образом
Оптимизатор PostgreSQL. Распределение данных случайным образом
Здесь cost 17 миллионов! И при этом ORCA всего на 700 мс быстрее, чем PostgreSQL.
Распределение данных по ключу соединения
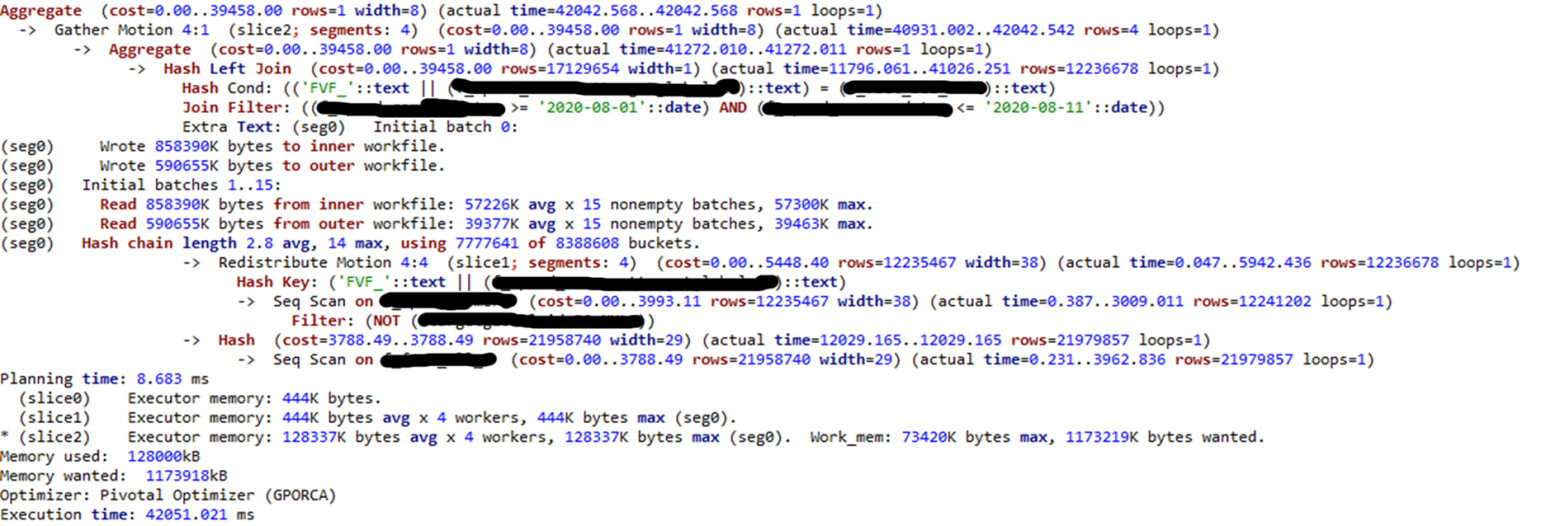
Теперь возьмём распределение по ключу:
 Оптимизатор GPORCA. Распределение данных
по ключу соединения
Оптимизатор GPORCA. Распределение данных
по ключу соединения
Здесь один Redistribute Motion пропал, хотя до хэша он был. То есть, запрос выполняется на сегменте, именно там происходит соединение данных и агрегация результатов.
Примерно ту же ситуацию мы видим с оптимизатором PostgreSQL:
 Оптимизатор PostgreSQL. Распределение данных
по ключу соединения
Оптимизатор PostgreSQL. Распределение данных
по ключу соединения
Полная копия таблицы на каждой ноде
С полной копией у нас вообще пропадает распределение: запрос выполняется в одной ноде, а время падает почти в два раза:
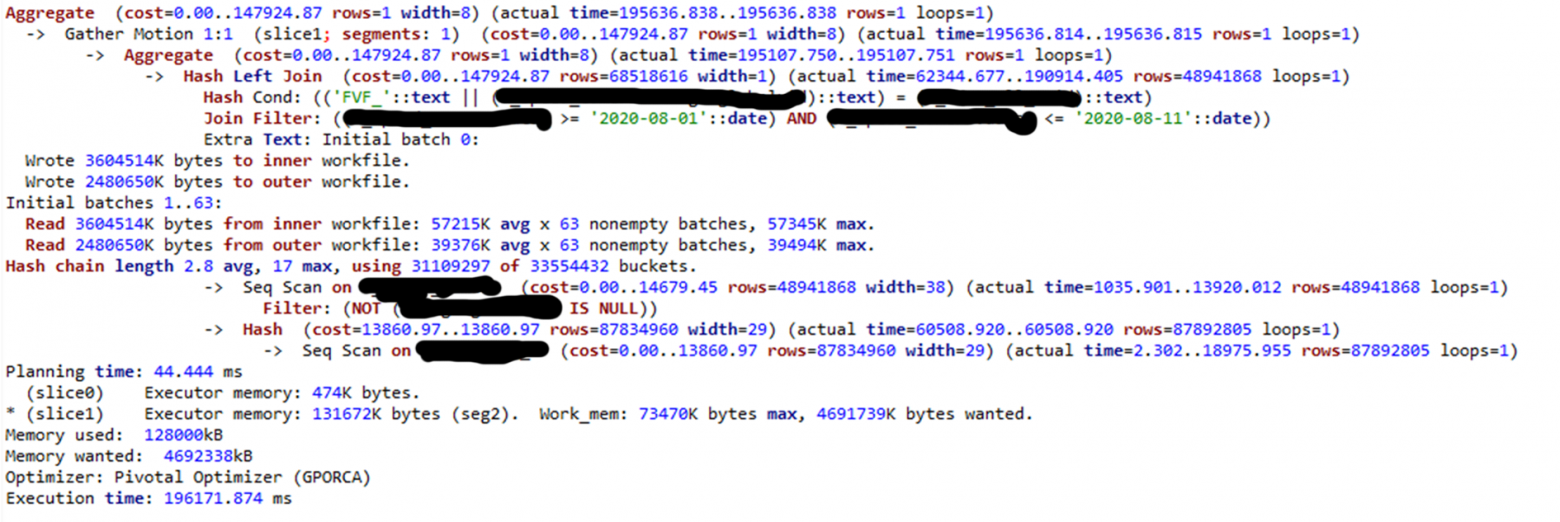 Оптимизатор GPORCA. Полная копия таблицы на каждой ноде
Оптимизатор GPORCA. Полная копия таблицы на каждой ноде
С оптимизатором PostgreSQL чуть похуже — появляются разные виды кэширования, которые используются для выполнения запроса:
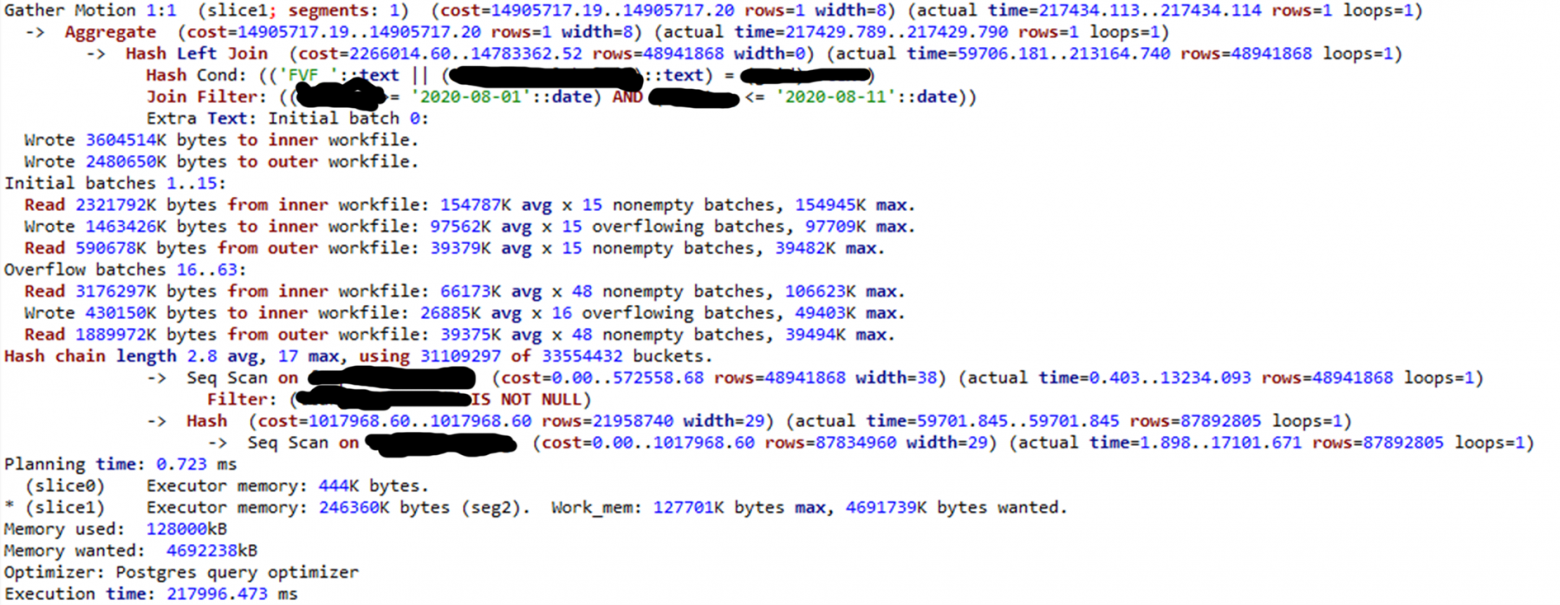 Оптимизатор PostgreSQL. Полная копия таблицы на каждой ноде
Оптимизатор PostgreSQL. Полная копия таблицы на каждой ноде
Получается, что оптимизатор ORCA работает чуть быстрее, чем стандартный оптимизатор PostgreSQL. Но из практики иногда бывает и наоборот. Оптимизатор ORGA работает хуже — все зависит от конкретного кейса и ситуации. Поэтому сложные запросы нужно прогонять на двух оптимизаторах.
Вообще ORCA был запущен давно, ещё в 4 версии Greenplum. Сейчас стало понятно, что оптимизатор PostgreSQL умнее, чем ORCA. И когда все-таки Greenplum перейдет на более старшую мажорную версию PostgreSQL, то ORCA, вероятнее всего, совсем пропадёт.
Ресурсные группы
Если вы только начали использовать Greenplum, включайте ресурсные группы по умолчанию. Когда я строил мой первый кластер, который развалился, я как раз не использовал ресурсные группы. И что бы я ни делал — либо сегмент аварийно завершался, либо запрос долго выполнялся.
Ресурсные группы позволяют управлять группами пользователей и приоритизировать задачи на процессор. Этим можно более гибко управлять: например, ночью отдавать больше приоритета сервисным процессам, а днём — пользовательским, распределяя нагрузку.
Также можно выделять лимиты оперативной памяти или устанавливать очередь на выполнение задач.
Оптимизация
Оптимизатор ORCA часто не подхватывает индексы, ему гораздо проще сделать Seq Scan таблицы, чем воспользоваться индексом. Лучше всего ORGA подхватывает bitmap индексы, а вот с остальными как повезёт — я до сих пор сам не понимаю, от чего это зависит.
При добавлении новых индексов я рекомендую делать analyze, потому что и ORCA, и PostgreSQL могут не увидеть новый индекс и не будут его использовать в запросах. Вообще это ещё одна особенность Greenplum — у неё и analyze, и vacuum по умолчанию отключены.
В Greenplum есть свой тип индексов — bitmap. Он очень производительный, когда поле имеет распределение от 10 до 100 тысяч уникальных значений. Но если порог значений больше или меньше, его производительность деградирует.
Важное замечание: если повысить реплику до лидера, то индекс может побиться и перестать быть валидным — нужно его пересоздавать.
Нагрузочное тестирование
Чтобы перейти к нагрузочному тестированию, нужно ввести три термина:
Справочники — таблицы, которые содержат данные об объектах и связях между ними.
Небольшие запросы — могут возвращать до нескольких сот тысяч данных.
Сложные запросы — аналитические запросы по огромным таблицам с миллиардами строк.
Для нагрузочного тестирования мы взяли 4 виртуальных сервера по 16 ядер и 32 Гб оперативной памяти. Используя JMeter, написали профиль нагрузочного тестирования — запросы выполняются в 10 потоков на кластере Greenplum в течение 30 минут. Теперь будем наращивать на них сегменты и смотреть, насколько изменилось время выполнения одного запроса.
Сначала протестируем справочники:
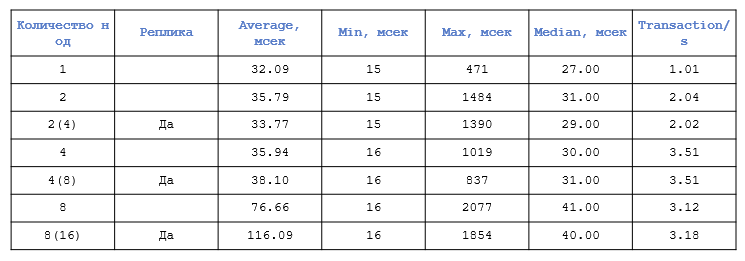 Нагрузочное тестирование. Справочники. Конфигурация: 4 виртуальных сервера: 16 ядер, 32 ГБ
Нагрузочное тестирование. Справочники. Конфигурация: 4 виртуальных сервера: 16 ядер, 32 ГБ
Здесь видно, что первый скачок у нас происходит при появлении второго сегмента — резко возрастает максимальное значение. А дальше оно практически не меняется и находится в пределах погрешности, в районе двух секунд. Такое поведение свойственно как раз OLAP-системам. А среднее время выполнения при этом стабильно остаётся в районе 30 мс.
Но когда сегментов уже 8 или 16, мы видим деградацию среднего времени практически в четыре раза.
Важно понимать, что даже среднее время тут в миллисекундах, поэтому все обрабатывается ещё довольно быстро. Интереснее, если взять не справочники, а небольшие запросы:
 Нагрузочное тестирование. Небольшие запросы. Конфигурация: 4 виртуальных сервера: 16 ядер, 32 ГБ
Нагрузочное тестирование. Небольшие запросы. Конфигурация: 4 виртуальных сервера: 16 ядер, 32 ГБ
Здесь сильно заметно, что на одной сегменте запрос выполнялся 600 мс, а при расширении кластера дошёл до 280 мс. Но на 8 и 16 сегментах мы снова видим некоторую деградацию, хотя максимальное время практически не изменилось.
Сложные запросы дают такую картину:
 Нагрузочное тестирование. Сложные запросы. Конфигурация: 4 виртуальных сервера: 16 ядер, 32 ГБ
Нагрузочное тестирование. Сложные запросы. Конфигурация: 4 виртуальных сервера: 16 ядер, 32 ГБ
На одной сегменте время выполнение совершенно неимоверное. Но с каждым шагом по добавлению сегментов оно уменьшается, даже когда их стало 12. Плюс видно, что минимальное, среднее и максимальное время выполнения запросов друг от друга практически не отличаются. Это связано с особенностью эксперимента.
Выводы после тестирования можно сделать такие:
При запросах на справочники количество сегментов не играет серьезной роли.
Простые запросы хорошо распараллеливаются на нодах, но только до определённого предела.
Сложные запросы распараллеливаются еще лучше, и предел у них есть где-то сильно далеко — мы до него не дошли.
Отказоустойчивость
Посмотрим, как ведёт себя кластер Greenplum, когда один сегмент или вообще сервер выходит из строя. Сначала справочники:
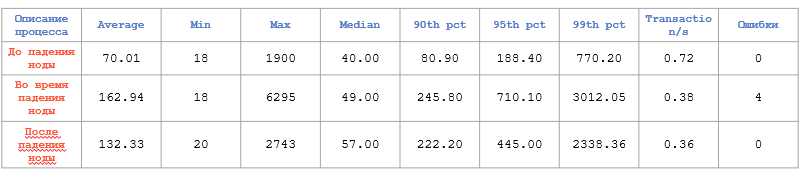 Отказоустойчивость Greenplum. Справочники
Отказоустойчивость Greenplum. Справочники
Здесь сразу видна просадка производительности примерно в два раза, но, учитывая, что время всё равно минимальное, это не так важно.
С небольшими запросами деградация чуть меньше:
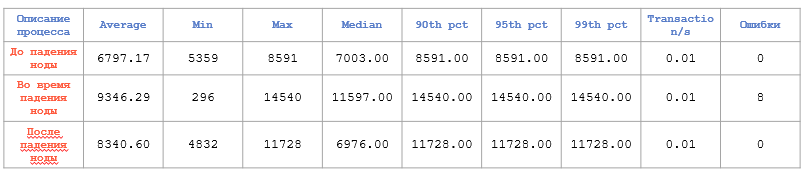 Отказоустойчивость Greenplum. Небольшие запросы
Отказоустойчивость Greenplum. Небольшие запросы
Получается падение производительности примерно на 20%.
А вот со сложными запросами просадка весьма существенная:
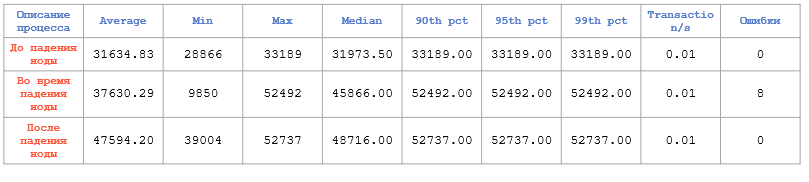 Отказоустойчивость Greenplum. Сложные запросы
Отказоустойчивость Greenplum. Сложные запросы
И это особенно заметно из-за того, что счёт здесь уже идёт на секунды.
Эти цифры помогут нам предположить, что именно будет происходить, если выйдет сегмент из кластера.
Миграция данных
В самом простом варианте для миграции мы можем обращаться к мастер-ноде, пытаться загрузить туда данные, а нода уже распределит всё по сегментам. Но этот вариант плохо подходит, когда нам нужно загрузить большие объемы данных.
Поэтому лучше загружать данные сразу на сегменты. Первый способ — обращаться к внешним таблицам и загружать данные с помощью Foreign data wrapper (postgres_fdw).
Другой вариант — обращаться к самим файлам. То есть использовать файловое хранилище на ноде и загружать файлы оттуда на сегменты. Это делается просто с помощью file://
Еще один вариант — пользоваться утилитой Greenplum для загрузки данных на сегменты. Это утилита (gpfdist|gpfdists)://, и она даёт больше возможностей для манипуляций и управления данными.
Еще один вариант — pxf://. Этот протокол обращается к системам хранилищ объектов (Azure, Google Cloud Storage, Minio, S3), внешним системам Hadoop (HDFS, Hive, HBase) и базам данных SQL с помощью Greenplum Platform Extension Framework (PXF).
И последний — s3://, он обращается к файлам хранилища s3, например, Amazon.
Резервное копирование
Это, пожалуй, самая серьёзная боль Greenplum. Есть стандартные инструменты вроде dump или restore, которые создают логические копии данных — аналогично утилите pg_dump в PostgreSQL. Но нужно понимать, что логическая копия — это всегда очень долго. А системы резервного копирования на основе чего-нибудь физического просто нет.
Замечание: недавнее обновление wal-g позволяет делать резервные копии с кластера Greenplum.
Мы можем сделать физическую резервную копию с сегмента, но никто не обеспечит нам консистентность — пока мы копировали, данные могли поменяться. gpbackup и gprestore можно подключать к s3, но восстановление — всё равно мучительный процесс.
Главное, что нужно помнить о Greenplum
Система Greenplum достаточно требовательна к компьютерным ресурсам (процессор, память, диски).
Greenplum является СУБД с разделяемой памятью, поэтому нужно
использовать ресурсные группы.Гонять запросы нужно на двух оптимизаторах: ORCA и PostgreSQL.
Важно использовать column хранение данных.
Правильно выбирать распределение данных по сегментам кластера Greenplum.
Автоматический failover работает штатно на сегментах. Нет автоматического failover на мастере. Нужно использовать сторонние инструменты.
Резервное копирование реализовано через логическую копию.
