PostgreSQL: пример использования диапазонного типа данных при расчете коэффициента возраст-стаж в ОСАГО
В этой статье рассматриваются преимущества такого редко используемого и, на мой взгляд, незаслуженно обойденного вниманием типа данных, как диапазон. Мы сначала спроектируем структуру базы для хранения коэффициента возраст-стаж при расчете стоимости полиса ОСАГО в рамках привычной многим MySQL. Затем перепроектируем под PostgreSQL и посмотрим, как выглядят sql запросы в обоих случаях. И в финале сравним, какие преимущества дает нам использование диапазонов.
Заметка адресована как пользователям MySQL, так и пользователям PostgreSQL, которые не работали с таким типом данных в своей практике. Если в вашей предметной области есть работа с диапазонами величин, то этот пост точно для вас.
Коэффициент страховых тарифов
Для начала немного погрузимся в предметную область. Схема расчета регламентируется документом «Указание Банка России от 19 сентября 2014 г. № 3384-У». При расчете стоимости полиса берется определенная сумма, называемая «Базовый тариф», и умножается на несколько различных коэффициентов, которые могут как повышать конечную стоимость полиса, так и понижать ее. Один из них — коэффициент страховых тарифов в зависимости от возраста и стажа водителя (КВС). Зависимость представлена в таблице:

Здесь мы видим диапазоны чисел по входным критериям (стаж и возраст), что располагает к использованию диапазонного типа данных. Но представим, что у нас в качестве РСУБД идет MySQL и что этот тип нам недоступен. Как будет выглядеть база? Спроектируем!
Структура базы для mysql
Сразу же в голову приходят два варианта реализации:
использование одной таблицы, в строках которой хранятся все варианты связок возраст-стаж-коэффициент;
использование трех таблиц, две из которых хранят диапазоны (одна для возраста, другая для стажа), а третья содержит связь возраст-стаж и значение коэффициента.
Рассмотрим оба этих варианта и заполним таблицы данными. Но для начала зададим граничные условия. Судя по википедии, самая старшая живая жительница планеты Люсиль Рандонлет в 2022 году дожила до 118 (Список старейших людей в мире). Права на управление можно получить с 16 лет. Потенциально водительский стаж Люсиль мог бы составлять 102 года. Для заполнения базы данными будем исходить из расчета: возраст от 16 до 118 лет, стаж вождения от 0 до 102 лет.
Теперь создадим нужные таблицы для обоих вариантов.
Одна таблица
Структура таблицы:

create or replace table kvs
(
age int not null comment 'Возраст',
experience int not null comment 'Стаж',
value decimal(4, 2) not null comment 'Значение КВС',
primary key (age, experience)
) comment 'Коэффициент Возраст-Стаж';Производим вставку данных. В результате получаем 9314 записи:
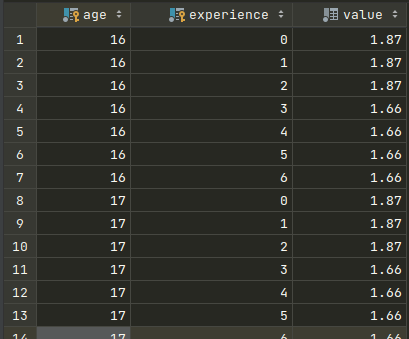
Составной индекс по полям age-experience убережет нас от ошибочной вставки дублей при будущих изменениях коэффициента. Запрос на получение коэффициента для водителя 23 лет и стажем вождения 3 года в этом случае будет иметь вид:
SELECT value FROM kvs WHERE age = 22 AND experience = 3Такой запрос достаточно простой, уникальный индекс не позволит вставить дубли, но из-за большого количества записей работать с такой таблицей может оказаться очень неудобно.
Три таблицы
Структура таблицы:

create table kvs_age_range
(
`id` integer not null AUTO_INCREMENT,
`from` integer not null comment "Начало диапазона",
`to` integer not null comment "Окончание диапазона",
primary key (id)
) comment 'Диапазоны возраста';
create table kvs_experience_range
(
`id` integer not null AUTO_INCREMENT,
`from` integer not null comment "Начало диапазона",
`to` integer not null comment "Окончание диапазона",
primary key (id)
) comment 'Диапазоны стажа';
create table kvs_value
(
age_id int not null,
experience_id int not null,
value decimal(4, 2) null comment 'Значение КВС',
constraint kvs_value_age_id_experience_id_uindex
unique (age_id, experience_id),
constraint kvs_age_id___fk
foreign key (age_id) references kvs_age_range (id)
on delete cascade,
constraint kvs_experience_id___fk
foreign key (experience_id) references kvs_experience_range (id)
) comment 'Величина КВС';Производим вставку данных:

Количество записей сократилось, но сам запрос получения значения КСВ усложнился:
SELECT value FROM kvs_value AS v
INNER JOIN kvs_age_range AS age ON v.age_id = age.id
INNER JOIN kvs_experience_range AS experience ON v.experience_id = experience.id
WHERE
(age.`from` <= 22 AND age.`to` >= 22)
AND
(experience.`from` <= 3 AND experience.`to` >= 3)Запрос значительно усложнился, контроля дублей нет (можно вставить пересекающиеся диапазоны), визуально работать с данными сложнее т.к. требуется переключать внимание между таблицами.
Структура базы для PostgreSQL
Для PostgreSQL воспользуемся схемой с одной таблицей:
create table if not exists kvs
(
age int4range not null,
experience int4range not null,
value numeric(4, 2),
exclude using gist (age WITH &&, experience WITH &&)
);
comment on table kvs is 'Коэффициент Возраст-Стаж';
comment on column kvs.age is 'Диапазоны возраста';
comment on column kvs.value is 'Величина КВС';(О конструкции EXCLUDE USING GIST см. чуть ниже.) Производим вставку данных:

Синтаксис вставки диапазонов:
INSERT INTO kvs VALUES ('[16,21]', '[0,0]', 1.87)Как видим, в этом случае получается 50 записей (их можно сократить до 20, предлагаю подумать и написать в комментариях как это сделать). Ограничение-исключения EXCLUDE USING GIST убережет нас от ошибочной вставки пересекающихся диапазонов. Например, если мы попытаемся добавить новый коэффициент для возраста 16–30 и стажа 5–6 лет, то получим ошибку:

Запрос на получение коэффициента имеет вид:
SELECT value FROM kvs WHERE age @> 22 AND experience @> 3Запрос получился простой, схема обеспечивает контроль непересечения вставляемых диапазонов, работать с такой таблицей визуально удобнее ведь она похожа на таблицу полученную нами в ТЗ.
Сравнение вариантов
Как вы уже могли убедиться, при использовании диапазонного типа данных у нас получается минимальное количество строк, простой запрос и контроль «непересечения» диапазонов. Для большей наглядности я сделал сводную таблицу:
Запрос | Контроль «непересечения» | Визуальное удобство работы | |
Одна таблица | простой | да | среднее |
Три таблицы | сложный | нет | сложное |
Таблица с диапазонами | простой | да | простое |
Надеюсь, что вы убедились в силе использования данного механизма и примените его в своей практике. Он может быть использован, например, в системах бронирования номеров или при составлении расписания. Прошу вас поделиться в комментариях своим опытом использования диапазонного типа данных. Для каких кейсов вы использовали диапазоны?
