PostgreSQL, что в логе твоем?
 Слепцы ощупывают различные аспекты слона
Слепцы ощупывают различные аспекты слона
Наверняка, многие из вас пользуются explain.tensor.ru — нашим сервисом визуализации PostgreSQL-планов или уже даже развернули его на своей площадке. Но визуализация конкретного плана — это лишь небольшая помощь разработчику, поэтому в «Тензоре» мы создали сервис, который позволяет увидеть сразу многие аспекты работы сервера:
медленные или гигантские запросы
возникающие блокировки и ошибки
частоту и результаты проходов
[auto]VACUUM/ANALYZE
И сегодня мы, наконец, готовы представить вам демо-режим этого сервиса, куда вы самостоятельно можете загрузить лог своего PostgreSQL-сервера и наглядно увидеть, чем он у вас занимается.
Что и как можно анализировать, вы можете узнать в серии моих лекций.
В качестве примера мы подключили сюда несколько своих серверов, данные с которых собираются в онлайн-режиме.
Проблемные запросы
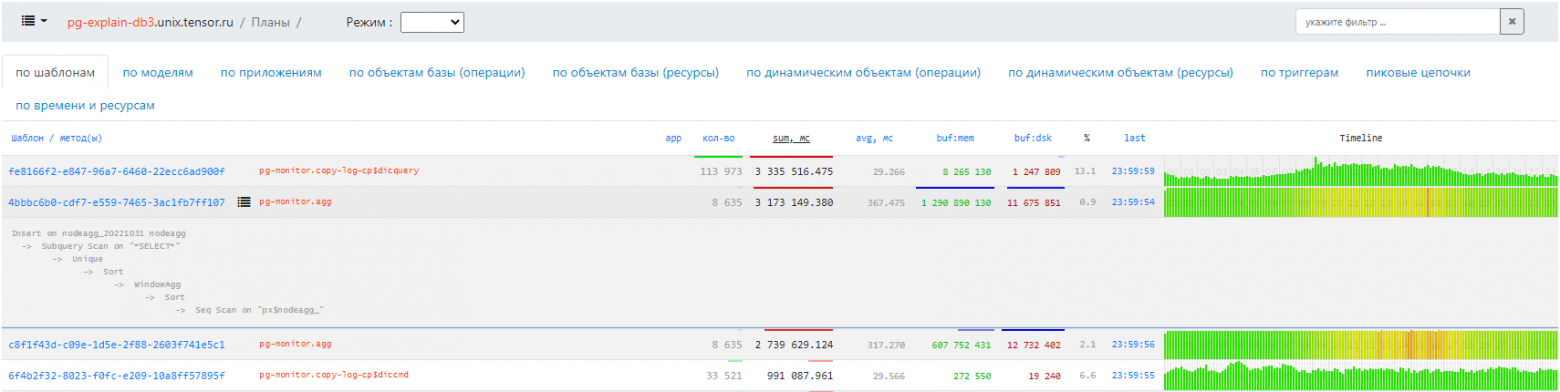 Проблемные запросы по шаблонам
Проблемные запросы по шаблонам
Чтобы включить сброс анализа выполняемых запросов прямо из активной сессии можно воспользоваться такой конструкцией:
SET log_min_duration_statement = '1ms'; -- пишем в лог все запросы дольше 1ms
LOAD 'auto_explain'; -- загружаем модуль auto_explain
SET auto_explain.log_min_duration = '1ms'; -- снимаем план, если дольше 1ms
SET auto_explain.log_analyze = 'on'; -- план пишем как EXPLAIN (ANALYZE, BUFFERS)
SET auto_explain.log_buffers = 'on';
SET auto_explain.log_timing = 'on';
SET auto_explain.log_triggers = 'on'; -- и триггеры тоже
SET track_io_timing = 'on'; -- выводить в план время IO-операцийНо лучше все-таки установить нужные параметры auto_explain прямо в конфиге сервера.
По шаблонам
Очищаем все планы от переменных составляющих, агрегируем — и видим не только «кто самое слабое звено», но и подробное распределение запросов с такими планами во времени:
 Тепловая карта распределения длительности запросов по шаблону
Тепловая карта распределения длительности запросов по шаблону
По моделям
Очищаем планы еще сильнее, сводя все к моделям доступа в определенные таблицы — и получаем кластерный анализ планов:
 Кластер планов запросов
Кластер планов запросов
По приложениям
Берем из application_name название того, кто делал запрос — и узнаем, кому мы обязаны наибольшей нагрузкой в течение дня:
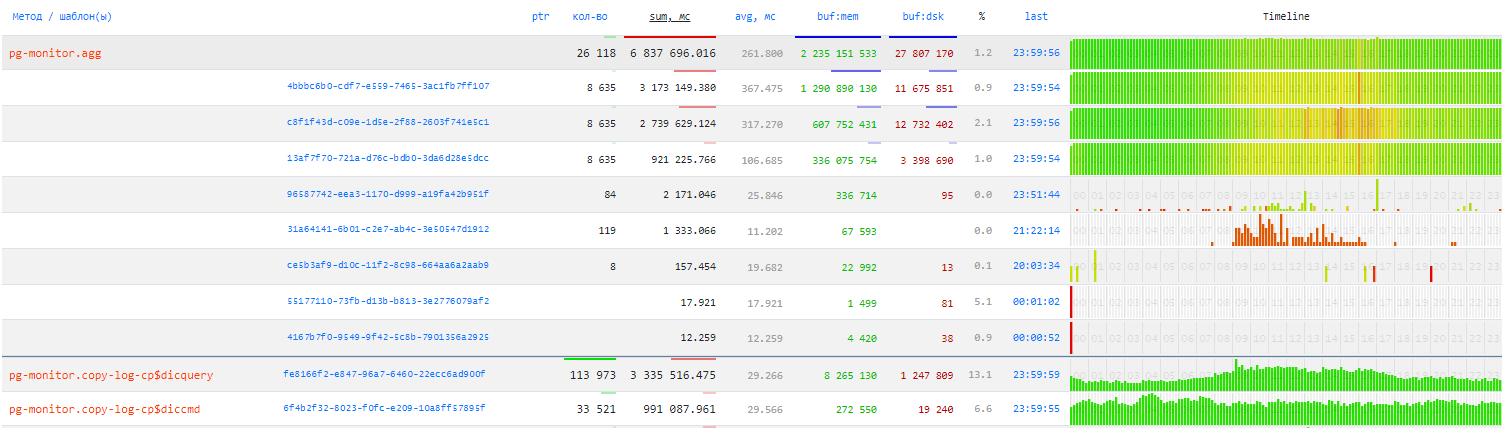 Проблемные запросы по приложениям
Проблемные запросы по приложениям
По объектам
Хотите узнать, при чтении из какой таблицы отбрасывалось максимум записей? На каких узлах плана потрачено больше всего времени? Тогда вам сюда:
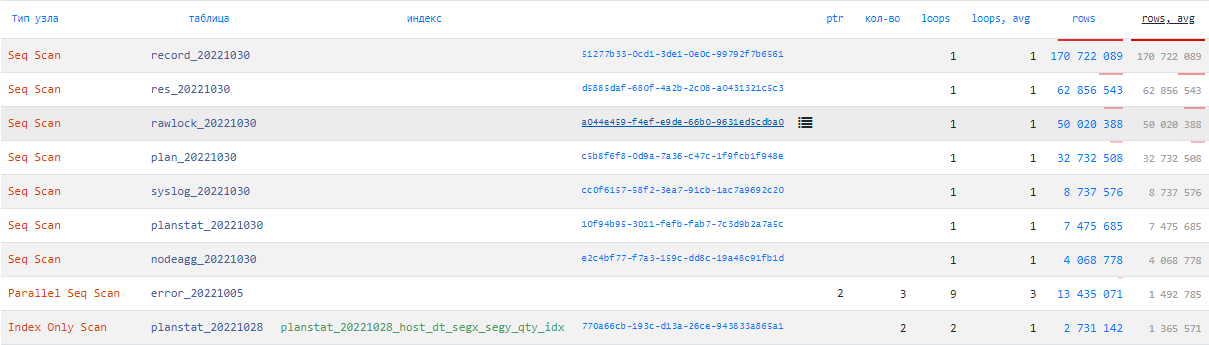 Статистика по объектам БД
Статистика по объектам БД
По триггерам
Возможно, у вас большая часть логики (а заодно и производительности) в базе скрывается внутри триггеров — welcome:
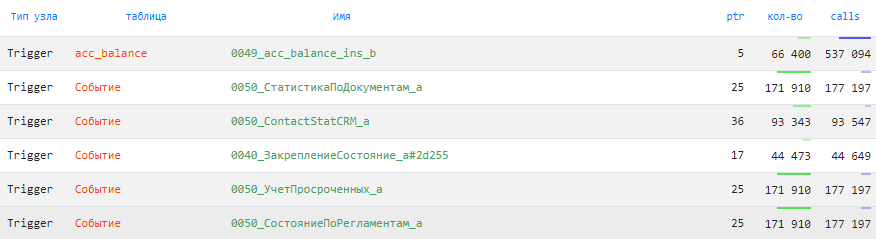 Статистика вызовов триггеров
Статистика вызовов триггеров
По времени и ресурсам
Здесь вы можете увидеть топ самых «прожорливых» запросов за сутки.
Мегазапросы
В статье PostgreSQL Antipatterns: «слишком много золота» я уже рассказывал, почему запросы с огромными списками параметров в теле — это плохо. И большие resultset’ы — тоже не очень хорошо.
Вот тут мы их и ловим — все, которые гонят больше 1MB трафика в ту или другую сторону.
Блокировки
Кто, где, когда, на чем споткнулся и попал на ожидание блокировки или на deadlock? Вот они все здесь:
 Сводка по блокировкам
Сводка по блокировкам
А вот здесь — статья «DBA: кто скрывается за блокировкой», которая поможет понять, что тут вообще происходило.
Блокировки — это нормально. Ненормально, когда они слишком велики — то есть превышают deadlock_timeout при включенном log_lock_waits.
Ошибки
Из лога мы получаем все ошибки (FATAL/ERROR/WARNING), а дальше — расклассифицируем по кучкам:
 Классы ошибок
Классы ошибок
Что выводить в лог, указывают параметры log_min_messages и log_min_error_statement.
Системные действия
Не слишком ли часто бегает autovacuum? Может, он цепляет секции, которые не должен бы? Прочитайте «DBA: Ночной Дозор», чтобы увидеть пример, как использовать мониторинг системных действий для снижения нагрузки на базу.
 Статистика autovacuum
Статистика autovacuum
Настроить необходимую «чувствительность» лога поможет параметр log_autovacuum_min_duration.
Offline-режим
На сладкое.
Чтобы все это увидеть по собственному серверу — добавьте его в качестве offline-источника и загрузите лог PostgreSQL (демо-ограничение 100MB):
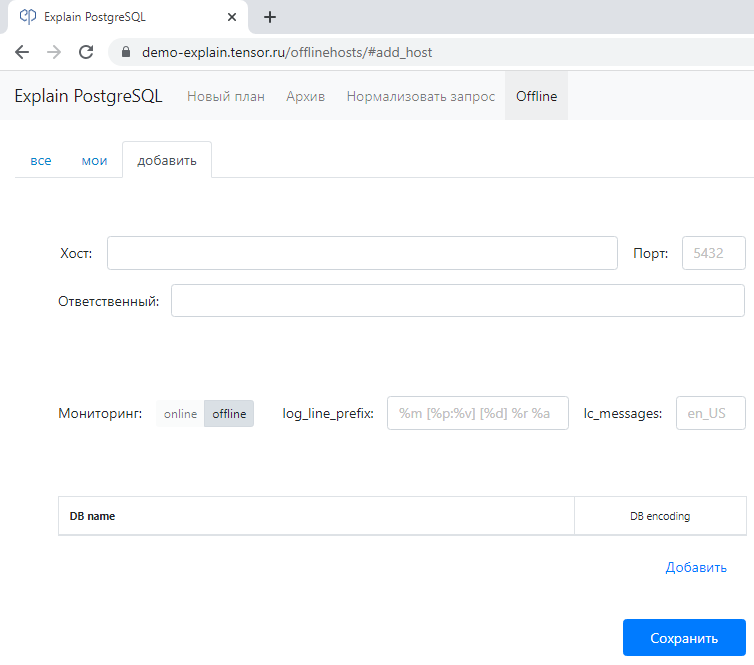 Добавление offline-сервера
Добавление offline-сервера
Для корректного разбора лога вам понадобится указать значения log_line_prefix и lc_messages и кодировки развернутых баз:
SHOW log_line_prefix;
SHOW lc_messages;
SELECT datname, pg_encoding_to_char(encoding) FROM pg_database;Если вы хотите развернуть такой же сервис у себя или предложить, как его усовершенствовать — пишите в комментах, в личку или на kilor@tensor.ru.
