PostgreSQL 15: Часть 5 или Коммитфест 2022-03
Эта статья о мартовском коммитфесте завершает серию о принятых изменениях в PostgreSQL 15.
Предыдущие статьи посвящены первым четырем коммитфестам: 2021–07, 2021–09, 2021–11, 2022–01.
На момент публикации уже доступна вторая бета-версия PostgreSQL 15. Все приведенные ниже примеры легко попробовать самостоятельно.
Содержание
Команды SQL
MERGE
Поддержка стандарта SQL/JSON
COPY: заголовок в первой строке данных
CLUSTER для секционированных таблиц
range_agg для мультидиапазонов
Мониторинг
Перенос статистики в общую память
range_agg для мультидиапазонов
pg_stat_statements и JIT
Производительность
recursive_worktable_factor: управление размером рабочей таблицы в рекурсивных запросах
Оптимизация GROUP BY
Более эффективное управление памятью при сортировке строк
Индексы GiST: баланс между скоростью поиска и скоростью построения индекса методом сортировки
Условие выполнения для монотонно возрастающих/убывающих оконных функций
Оптимизация заморозки версий строк
Оптимизация работы с вложенными транзакциями
postgres_fdw: параллельная фиксация транзакций на внешних серверах
Репликация и резервное копирование
pg_basebackup --target
pg_basebackup --compress
wal_compression = zstd
Модули архивации WAL
Нежурналируемые последовательности
Предвыборка WAL при восстановлении
pg_rewind: параметр --config-file
Расширение pg_walinspect ― SQL-интерфейс к содержимому WAL
pg_waldump: новые фильтры
Монопольный режим резервного копирования окончательно удален
Логическая репликация
Фильтрация строк в публикации
Фильтрация столбцов в публикации
Отключение подписки после ошибки
Пропуск транзакции для разрешения конфликта
Безопасность
Права доступа к конфигурационным параметрам
Представления с правами вызывающего
Обычная роль больше не имеет ADMIN OPTION для самой себя
Системное администрирование
ICU на уровне кластера и базы данных
Отслеживание версий правил сортировки для баз данных
pg_upgrade: каталог для временных файлов
pg_upgrade: сохранение имен файлов баз данных, табличных пространств и отношений
CREATE DATABASE с журналированием в WAL
Представление pg_ident_file_mappings
Прекращена поддержка второй версии Python
Клиентские приложения
psql: показывать результаты всех запросов
Команды SQL
MERGE
commit: 7103ebb7
Долгожданная команда SQL, с непростой историей реализации, наконец-то попала в 15-ю версию!
Команда предназначена для изменения строк в таблице. Одной командой в зависимости от условий можно добавлять, изменять или удалять строки.
Сначала изменяемая таблица (её называют целевой) соединяется с источником (таблицей или подзапросом) по указанному условию соединения. Для каждой строки целевой таблицы, попавшей в результат соединения, можно указать что с ней делать.
Создадим две таблицы с одинаковой структурой и наполнением.
CREATE TABLE source_table (id int primary key, descr text);
CREATE TABLE target_table (LIKE source_table INCLUDING ALL);
INSERT INTO source_table VALUES
(0, 'Ноль'),
(1, 'Один'),
(2, 'Два');
INSERT INTO target_table SELECT * FROM source_table;
SELECT * FROM target_table ORDER BY id;
id | descr
----+-------
0 | Ноль
1 | Один
2 | Два
(3 rows)
Для строк результата соединения, найденных как в целевой таблице, так и в источнике, проставляется логический признак MATCHED, который можно использовать в команде MERGE.
Для примера, в целевой таблице изменим описание у всех строк.
UPDATE target_table SET descr = '';
Для проверки содержимого обеих таблиц будем использовать вот такой запрос с полным внешним соединением. Первые два столбца относятся к исходной таблице, следующие два к целевой:
SELECT s.*, t.*
FROM source_table s
FULL OUTER JOIN target_table t ON (t.id=s.id);
id | descr | id | descr
----+-------+----+-------
0 | Ноль | 0 |
1 | Один | 1 |
2 | Два | 2 |
(3 rows)
Синхронизируем измененные строки с таблицей source_table.
В команде MERGE указываем целевую таблицу, источник и условие соединения. А также действие для строк в целевой таблице, которым нашлось соответствие (MATCHED) в источнике. В данном случае это изменение столбца descr. Дописывать к UPDATE фразы FROM и WHERE не нужно, т.к всегда обновляется текущая строка целевой таблицы.
MERGE INTO target_table t
USING source_table s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET descr = s.descr;
MERGE 3
SELECT s.*, t.*
FROM source_table s
FULL OUTER JOIN target_table t ON (t.id=s.id);
id | descr | id | descr
----+-------+----+-------
0 | Ноль | 0 | Ноль
1 | Один | 1 | Один
2 | Два | 2 | Два
(3 rows)
Посмотрим на план выполнения запроса:
EXPLAIN (costs off)
MERGE INTO target_table t
USING source_table s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET descr = s.descr;
QUERY PLAN
----------------------------------------------
Merge on target_table t
-> Hash Join
Hash Cond: (t.id = s.id)
-> Seq Scan on target_table t
-> Hash
-> Seq Scan on source_table s
Способ соединения выбирает планировщик: соединение слиянием, вложенными циклами или, как в нашем случае, хеш-соединение.
Заметим, что такой же результат можно получить и без MERGE. Нужно воспользоваться фразой FROM команды UPDATE:
UPDATE target_table t
SET descr = s.descr
FROM source_table s
WHERE t.id = s.id;
Теперь будем обрабатывать строки источника не найденные в целевой таблице. Для этого сначала удалим строку из целевой таблицы.
DELETE FROM target_table WHERE id = 0;
SELECT s.*, t.*
FROM source_table s
FULL OUTER JOIN target_table t ON (t.id=s.id);
id | descr | id | descr
----+-------+----+-------
0 | Ноль | |
1 | Один | 1 | Один
2 | Два | 2 | Два
(3 rows)
К предыдущей команде MERGE нужно добавить еще одно действие с условием NOT MATCHED. А в качестве действия укажем команду INSERT, в которой опять же не нужно указывать таблицу:
MERGE INTO target_table t
USING source_table s
ON t.id = s.id
WHEN NOT MATCHED THEN
INSERT (id, descr) VALUES (s.id, s.descr)
WHEN MATCHED THEN
UPDATE SET descr = s.descr;
MERGE 3
Условия WHEN обрабатываются сверху-вниз для каждой строки результата соединения. Первое подходящее ― выполняется, остальные игнорируются.
Убедимся, что данные синхронизированы:
SELECT s.*, t.*
FROM source_table s
FULL OUTER JOIN target_table t ON (t.id=s.id);
id | descr | id | descr
----+-------+----+-------
0 | Ноль | 0 | Ноль
1 | Один | 1 | Один
2 | Два | 2 | Два
(3 rows)
Посмотрим на план предыдущей команды MERGE:
EXPLAIN (costs off)
MERGE INTO target_table t
USING source_table s
ON t.id = s.id
WHEN NOT MATCHED THEN
INSERT (id, descr) VALUES (s.id, s.descr)
WHEN MATCHED THEN
UPDATE SET descr = s.descr;
QUERY PLAN
----------------------------------------------
Merge on target_table t
-> Hash Left Join
Hash Cond: (s.id = t.id)
-> Seq Scan on source_table s
-> Hash
-> Seq Scan on target_table t
Теперь используется внешнее левое хеш-соединение. Внешнее левое соединение необходимо для того, чтобы добавить в результат соединения строки из источника, отсутствующие в целевой таблице. Мы их обрабатываем по условию WHEN NOT MATCHED.
Заметим, опять же, что синхронизации таблиц в этой ситуации можно было бы добиться другой командой:
INSERT INTO target_table
SELECT * FROM source_table s
ON CONFLICT (id) DO UPDATE SET descr = EXCLUDED.descr;
INSERT 0 3
Однако принцип действия у них разный. INSERT… ON CONFLICT пытается добавить строки, и если вставка не проходит, например из-за ограничения уникальности, то можно изменить существующую строку. А MERGE сначала соединяет источник с целевой таблицей и проставляет для каждой строки соединения признак [NOT] MATCHED, которым можно воспользоваться для выполнения обновления, удаления или вставки строк в целевой таблице.
Но что если нам нужно обработать строки, которые есть только в целевой таблице?
INSERT INTO target_table VALUES (3, 'Три');
SELECT s.*, t.*
FROM source_table s
FULL OUTER JOIN target_table t ON (t.id=s.id);
id | descr | id | descr
----+-------+----+-------
0 | Ноль | 0 | Ноль
1 | Один | 1 | Один
2 | Два | 2 | Два
| | 3 | Три
(4 rows)
Предположим, что мы хотели бы удалить такие, «лишние» строки.
В MS SQL Server для таких случаев есть специальное условие MATCHED BY SOURCE. В PostgreSQL оно не поддерживается, но мы для целей примера воспользуемся возможностью использовать запрос в качестве источника. А запрос будет таким:
SELECT coalesce(s.id,t.id) full_id, s.*
FROM source_table s
FULL OUTER JOIN target_table t ON t.id = s.id;
full_id | id | descr
---------+----+-------
0 | 0 | Ноль
1 | 1 | Один
2 | 2 | Два
3 | |
(4 rows)
В запросе выполняется полное внешнее соединение, вычисляемый столбец full_id ― комбинация всех возможных id из обеих таблиц. Если full_id заполнен, а s.id нет, то это как раз строки, отсутствующие в источнике и мы хотим их удалить.
Теперь можно записать команду MERGE так:
MERGE INTO target_table t
USING (
SELECT coalesce(s.id,t.id) full_id, s.*
FROM source_table s
FULL OUTER JOIN target_table t ON t.id = s.id
) s
ON t.id = s.full_id
WHEN NOT MATCHED THEN
INSERT (id, descr) VALUES (s.id, s.descr)
WHEN MATCHED AND s.id IS NULL THEN
DELETE
WHEN MATCHED THEN
UPDATE SET descr = s.descr;
MERGE 4
Обратите внимание, что в условие можно включать дополнительные логические выражения: WHEN MATCHED AND s.id IS NULL. А удаление строки свелось к одному слову DELETE.
Проверяем:
SELECT s.*, t.*
FROM source_table s
FULL OUTER JOIN target_table t ON (t.id=s.id);
id | descr | id | descr
----+-------+----+-------
0 | Ноль | 0 | Ноль
1 | Один | 1 | Один
2 | Два | 2 | Два
(3 rows)
Сколько строк и как именно было обработано командой MERGE?
Подробный ответ на этот вопрос покажет план выполнения запроса (надо отметить, что фраза RETURNING для MERGE не поддерживается).
EXPLAIN (analyze, costs off, timing off, summary off)
MERGE INTO target_table t
USING (
SELECT coalesce(s.id,t.id) full_id, s.*
FROM source_table s
FULL OUTER JOIN target_table t ON t.id = s.id
) s
ON t.id = s.full_id
WHEN NOT MATCHED THEN
INSERT (id, descr) VALUES (s.id, s.descr)
WHEN MATCHED AND s.id IS NULL THEN
DELETE
WHEN MATCHED THEN
UPDATE SET descr = s.descr;
QUERY PLAN
------------------------------------------------------------------------------
Merge on target_table t (actual rows=0 loops=1)
Tuples Inserted: 0
Tuples Updated: 3
Tuples Deleted: 0
Tuples Skipped: 0
-> Hash Left Join (actual rows=3 loops=1)
Hash Cond: (COALESCE(s.id, t_1.id) = t.id)
-> Hash Full Join (actual rows=3 loops=1)
Hash Cond: (s.id = t_1.id)
-> Seq Scan on source_table s (actual rows=3 loops=1)
-> Hash (actual rows=3 loops=1)
Buckets: 2048 Batches: 1 Memory Usage: 17kB
-> Seq Scan on target_table t_1 (actual rows=3 loops=1)
-> Hash (actual rows=3 loops=1)
Buckets: 2048 Batches: 1 Memory Usage: 17kB
-> Seq Scan on target_table t (actual rows=3 loops=1)
Видим что обновляются все строки, но зачем? Ведь значения descr одинаковые в источнике и приемнике.
Уточним в последней ветке WHEN условие для обновления строк.
EXPLAIN (analyze, costs off, timing off, summary off)
MERGE INTO target_table t
USING (
SELECT coalesce(s.id,t.id) full_id, s.*
FROM source_table s
FULL OUTER JOIN target_table t ON t.id = s.id
) s
ON t.id = s.full_id
WHEN NOT MATCHED THEN
INSERT (id, descr) VALUES (s.id, s.descr)
WHEN MATCHED AND s.id IS NULL THEN
DELETE
WHEN MATCHED AND t.descr IS DISTINCT FROM s.descr THEN
UPDATE SET descr = s.descr;
QUERY PLAN
------------------------------------------------------------------------------
Merge on target_table t (actual rows=0 loops=1)
Tuples Inserted: 0
Tuples Updated: 0
Tuples Deleted: 0
Tuples Skipped: 3
-> Hash Left Join (actual rows=3 loops=1)
Hash Cond: (COALESCE(s.id, t_1.id) = t.id)
-> Hash Full Join (actual rows=3 loops=1)
Hash Cond: (s.id = t_1.id)
-> Seq Scan on source_table s (actual rows=3 loops=1)
-> Hash (actual rows=3 loops=1)
Buckets: 2048 Batches: 1 Memory Usage: 17kB
-> Seq Scan on target_table t_1 (actual rows=3 loops=1)
-> Hash (actual rows=3 loops=1)
Buckets: 2048 Batches: 1 Memory Usage: 17kB
-> Seq Scan on target_table t (actual rows=3 loops=1)
Теперь лишних обновлений не делается, что может быть очень существенным на больших объемах почти одинаковых данных.
Подводя итоги.
- Реализация MERGE в PostgreSQL еще один важный шаг в сторону соответствия стандарту SQL.
- Наличие MERGE может упростить переход на PostgreSQL с других СУБД, где команда поддерживается давно.
- Функциональность MERGE шире, чем у существующей команды INSERT… ON CONFLICT. Эти две команды не всегда взаимозаменяемы.
За дополнительными подробностями реализации стоит обратиться к документации на команду MERGE.
Описание от depesz.
Поддержка стандарта SQL/JSON
commit: a6baa4ba, f79b803d, f4fb45d1, 33a37760, 1a36bc9d, 606948b0, 49082c2c, 4e34747c, fadb48b0
Большое количество коммитов лишь частично передает огромный объем проделанной работы по включению в PostgreSQL поддержки стандарта SQL/JSON. Еще в 12-й версии появился специальный язык путей JSONPATH для доступа к отдельным частям JSON. А теперь появились стандартизированные функции для работы с JSON. Всё вместе позволяет комбинировать работу с JSON и реляционными данными в одной СУБД.
Хороший обзор принятых патчей представлен в статье Олега Бартунова, идейного вдохновителя и одного из авторов проекта.
А теперь несколько примеров на демо-базе.
Для формирования значения JSON есть несколько функций-конструкторов. Они позволяют в том числе получить JSON из реляционных данных:
SELECT JSON_OBJECT('id': passenger_id, 'name': passenger_name RETURNING jsonb)
FROM tickets t
WHERE t.book_ref = '000010';
json_object
-----------------------------------------------------
{"id": "5722 837257", "name": "ALEKSANDR SOKOLOV"}
{"id": "0564 044306", "name": "LYUDMILA BOGDANOVA"}
Более сложный пример. Мы хотим бронирования и входящие в них билеты хранить как одно значение JSON в отдельной таблице. Билетов в одном бронировании может быть несколько, JSON_ARRAY добавит их в виде массива. Для простоты, ограничимся одним бронированием:
CREATE TABLE bookings_json AS
SELECT b.book_ref,
JSON_OBJECT(
'book_ref': b.book_ref,
'book_date': b.book_date,
'total_amount': b.total_amount,
'tickets': JSON_ARRAY(
SELECT JSON_OBJECT(
'ticket_no': ticket_no,
'passenger': JSON_OBJECT('id':passenger_id, 'name': passenger_name)
)
FROM tickets t
WHERE t.book_ref = b.book_ref
)
RETURNING jsonb
) data
FROM bookings b
WHERE b.book_ref = '000010';
Вот что получилось:
SELECT book_ref, jsonb_pretty(data) FROM bookings_json;
book_ref | jsonb_pretty
----------+-----------------------------------------------
000010 | { +
| "tickets": [ +
| { +
| "passenger": { +
| "id": "5722 837257", +
| "name": "ALEKSANDR SOKOLOV" +
| }, +
| "ticket_no": "0005432295359" +
| }, +
| { +
| "passenger": { +
| "id": "0564 044306", +
| "name": "LYUDMILA BOGDANOVA" +
| }, +
| "ticket_no": "0005432295360" +
| } +
| ], +
| "book_ref": "000010", +
| "book_date": "2017-01-08T19:45:00+03:00",+
| "total_amount": 50900.00 +
| }
Кроме конструкторов JSON_OBJECT, JSON_ARRAY есть и другие: JSON, JSON_ARRAYAGG, JSON_OBJECTAGG.
Описание функций-конструкторов от depesz.
С помощью различных предикатов можно проверить тип значения JSON в столбце data:
SELECT data IS JSON AS is_json,
data IS JSON WITH UNIQUE KEYS AS is_unique_keys,
data IS JSON ARRAY AS is_json_array,
data IS JSON OBJECT AS is_json_object,
data IS JSON SCALAR AS is_json_scalar
FROM bookings_json\gx
-[ RECORD 1 ]--+--
is_json | t
is_unique_keys | t
is_json_array | f
is_json_object | t
is_json_scalar | f
Описание предикатов от depesz.
Можно получить список билетов, входящих в бронирование:
SELECT book_ref,
JSON_QUERY(data, '$.tickets[$i].ticket_no' PASSING g.x as i)
FROM bookings_json, generate_series(0,1) AS g(x);
book_ref | json_query
----------+-----------------
000010 | "0005432295359"
000010 | "0005432295360"
Вторым параметром в функции JSON_QUERY указан путь на языке JSONPATH к массиву билетов. В этот путь можно передать параметр (PASSING) для доступа к отдельным элементам массива.
А вот так можно проверить наличия ключа в JSON и получить его значение:
SELECT JSON_EXISTS(data, '$.book_ref') book_ref_exists,
JSON_VALUE(data, '$.book_ref') book_ref_value
FROM bookings_json;
book_ref_exists | book_ref_value
-----------------+----------------
t | 000010
Эти функции можно использовать для создания ограничений целостности для таблицы. Например. Требуется, чтобы в JSON присутствовал ключ book_date, а значение ключа book_ref совпадало со значением столбца book_ref.
ALTER TABLE bookings_json
ADD CONSTRAINT chk_book_ref CHECK (JSON_VALUE(data, '$.book_ref') = book_ref),
ADD CONSTRAINT chk_book_date CHECK (JSON_EXISTS(data, '$.book_date'));
INSERT INTO bookings_json
VALUES ('_12345', JSON_OBJECT('book_ref': '123456'));
ERROR: new row for relation "bookings_json" violates check constraint "chk_book_date"
DETAIL: Failing row contains (_12345, {"book_ref": "123456"}).
INSERT INTO bookings_json
VALUES ('_12345', JSON_OBJECT('book_ref': '123456', 'book_date': now()));
ERROR: new row for relation "bookings_json" violates check constraint "chk_book_ref"
DETAIL: Failing row contains (_12345, {"book_ref": "123456", "book_date": "2022-06-15T19:05:28.33306+0...).
INSERT INTO bookings_json
VALUES ('_12345', JSON_OBJECT('book_ref': '_12345', 'book_date': now()));
INSERT 0 1
Теперь в таблицу попадут только удовлетворяющие ограничениям записи.
Описание функций JSON_QUERY, JSON_EXISTS, JSON_VALUE от depesz.
А теперь посмотрим как значение JSON можно привести к реляционному виду:
SELECT b.book_ref, jt.*
FROM bookings_json b,
JSON_TABLE(b.data,
'$[*]'
COLUMNS (
book_date date PATH '$.book_date',
total_amount numeric(18,2) PATH '$.total_amount',
NESTED PATH '$.tickets[*]'
COLUMNS (
ticket_no text PATH '$.ticket_no',
passenger_id text PATH '$.passenger.id',
passenger_name text PATH '$.passenger.name'
)
)
) jt;
book_ref | book_date | total_amount | ticket_no | passenger_id | passenger_name
----------+------------+--------------+---------------+--------------+--------------------
000010 | 2017-01-08 | 50900.00 | 0005432295359 | 5722 837257 | ALEKSANDR SOKOLOV
000010 | 2017-01-08 | 50900.00 | 0005432295360 | 0564 044306 | LYUDMILA BOGDANOVA
_12345 | 2022-06-15 | | | |
(3 rows)
Описание JSON_TABLE от depesz.
Здесь показана лишь часть того, что умеют новые функции SQL/JSON. Их возможности гораздо шире. Полное описание можно найти в документации, которую оформили отдельным коммитом (первый в вышеперечисленном списке).
Описание документации на SQL/JSON от depesz.
COPY: заголовок в первой строке данных
commit: 43f33dc0, 072132f0
До 15-й версии команда COPY поддерживала строку заголовка с названиями столбцов только для формата csv. В 15-й версии добавили поддержку и для текстового формата:
COPY (SELECT * FROM bookings LIMIT 3) TO stdout (header);
book_ref book_date total_amount
000004 2016-08-13 15:40:00+03 55800.00
00000F 2017-07-05 03:12:00+03 265700.00
000010 2017-01-08 19:45:00+03 50900.00
Строка заголовка поддерживается и при загрузке:
COPY bookings FROM stdout (header match);
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself, or an EOF signal.
>> book_ref book_date total_amount
>> _12345 2022-05-24 1000
>> \.
COPY 1
Указание header вместе с match заставит выполнить проверку имен столбцов в строке заголовка с именами столбцов в таблице. При несовпадении получим весьма информативную ошибку:
COPY bookings FROM stdout (header match);
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself, or an EOF signal.
>> book_id book_date total_amount
>> _12345 2022-05-24 1000
>> \.
ERROR: column name mismatch in header line field 1: got "book_id", expected "book_ref"
CONTEXT: COPY bookings, line 1: "book_id book_date total_amount"
Описание от depesz.
CLUSTER для секционированных таблиц
commit: cfdd03f4
VACUUM FULL для секционированных таблиц можно делать начиная с 10-й версии. Теперь для таких таблиц поддерживается схожая по функциональности команда CLUSTER.
range_agg для мультидиапазонов
commit: ae1619b
Функция range_agg поддерживает не только диапазонные, но и появившиеся в 14-й версии мультидиапазонные типы данных:
\df range_agg
List of functions
Schema | Name | Result data type | Argument data types | Type
------------+-----------+------------------+---------------------+------
pg_catalog | range_agg | anymultirange | anymultirange | agg
pg_catalog | range_agg | anymultirange | anyrange | agg
Мониторинг
Перенос статистики в общую память
commit: 5891c7a8, b3abca68
В текущей архитектуре сбора статистики отдельный процесс ― коллектор статистики ― собирает информацию от всех обслуживающих процессов и раз в полсекунды сбрасывает ее на диск во временные файлы, которые могут достигать десятков мегабайт.
Бороться с дисковым вводом/выводом можно переносом каталога stats_temp_directory в оперативную память. Тем не менее, такая архитектура сильно ограничивает добавление новых полезных счетчиков.
В 15-й версии сбор статистики перенесен в общую память. Обслуживающие процессы раз в секунду (задается при сборке) сами записывают информацию о проделанной работе. При аккуратном выключении сервера, статистика из общей памяти записывается в каталог pg_stat и сохраняется после следующего запуска. В случае сбоя сервера, статистика сбрасывается. Здесь всё осталось как и раньше.
Что изменилось? Больше нет процесса stats collector, ведь процессы сами записывают статистику. Да и само понятие «коллектор статистики» заменено на «система кумулятивной статистики» (Cumulative Statistics System). Кроме того, больше нет параметра stats_temp_directory, статистику больше не надо записывать во временные файлы. А согласованностью данных при чтении статистики можно управлять параметром stats_fetch_consistency.
Из большого количества коммитов связанных с этой работой выделены два. Первый ― непосредственно перенос статистики в общую память, второй ― обновление документации.
explain показывает ввод/вывод для временных файлов
commit: efb0ef90, 76cbf7ed
Включим track_io_timing и выполним запрос в 14-й версии:
14=# SET track_io_timing = on;
14=# EXPLAIN (analyze, buffers, costs off)
SELECT count(*) FROM generate_series(1,1000000);
QUERY PLAN
-------------------------------------------------------------------------------------------
Aggregate (actual time=206.451..206.452 rows=1 loops=1)
Buffers: temp read=1709 written=1709
-> Function Scan on generate_series (actual time=92.500..164.520 rows=1000000 loops=1)
Buffers: temp read=1709 written=1709
Planning Time: 0.052 ms
Execution Time: 208.279 ms
Статистика ввода/вывода не появилась. Да и откуда ей взяться, ведь к таблицам мы не обращались.
Однако:
15=# SET track_io_timing = on;
15=# EXPLAIN (analyze, buffers, costs off)
SELECT count(*) FROM generate_series(1,1000000);
QUERY PLAN
-------------------------------------------------------------------------------------------
Aggregate (actual time=182.130..182.132 rows=1 loops=1)
Buffers: temp read=1709 written=1709
I/O Timings: temp read=2.573 write=9.350
-> Function Scan on generate_series (actual time=82.422..143.206 rows=1000000 loops=1)
Buffers: temp read=1709 written=1709
I/O Timings: temp read=2.573 write=9.350
Planning Time: 0.045 ms
Execution Time: 183.608 ms
Ввод/вывод появился. Строки с I/O Timings относятся к временным файлам, которые до первого коммита в вывод EXPLAIN не включались.
Второй коммит добавляет столбцы temp_blk_read_time и temp_blk_write_time в pg_stat_statements для тех же целей.
pg_stat_statements и JIT
commit: 57d6aea0
В pg_stat_statements новые столбцы, собирающие информацию о работе JIT:
\d pg_stat_statements
View "public.pg_stat_statements"
Column | Type | Collation | Nullable | Default
------------------------+------------------+-----------+----------+---------
...
jit_functions | bigint | | |
jit_generation_time | double precision | | |
jit_inlining_count | bigint | | |
jit_inlining_time | double precision | | |
jit_optimization_count | bigint | | |
jit_optimization_time | double precision | | |
jit_emission_count | bigint | | |
jit_emission_time | double precision | | |
Теперь будет проще оценить влияние JIT на выполнение запросов.
Производительность
recursive_worktable_factor: управление размером рабочей таблицы в рекурсивных запросах
commit: 0bd7af08
Рекурсивные запросы, как известно, состоят из двух частей. Первая часть инициализирует рабочую таблицу. Вторая часть выполняется рекурсивно, обновляя содержимое рабочей таблицы на каждой итерации.
Но как планировщику понять сколько итераций будет выполнено и какое количество строк будет в рабочей таблице на каждой итерации? От ответа на эти два вопроса зависит насколько оптимальный план будет выбран.
Ответы до 15-й версии жестко зашиты в коде. Очень сложно придумать алгоритм для вычисления этих значений, поэтому предполагается, что будет выполнено 10 итераций, а средний размер рабочей таблицы на каждой итерации в среднем в 10 раз больше начальной таблицы, после выполнения нерекурсивной части.
Однако такое предположение для ряда запросов может быть ошибочным. Для запросов с малым количеством итераций рабочая таблица будет меньше, а для обхода большого количества узлов в графовых аналитических запросах наоборот больше. Ошибка же в расчете кардинальности часто приводит к выбору неправильного плана.
В 15-й версии количество итераций по-прежнему предполагается 10, но вторую десятку вынесли в конфигурационный параметр recursive_worktable_factor, по умолчанию равный также 10. Это дает возможность управлять оценкой кардинальности в рекурсивных запросах.
Посмотрим на план простейшего рекурсивного запроса:
EXPLAIN WITH RECURSIVE t(n) AS (
SELECT 1
UNION ALL
SELECT n+1 FROM t WHERE n < 1000
)
SELECT * FROM t;
QUERY PLAN
-------------------------------------------------------------------------
CTE Scan on t (cost=2.95..3.57 rows=31 width=4)
CTE t
-> Recursive Union (cost=0.00..2.95 rows=31 width=4)
-> Result (cost=0.00..0.01 rows=1 width=4)
-> WorkTable Scan on t t_1 (cost=0.00..0.23 rows=3 width=4)
Filter: (n < 1000)
Здесь усредненная оценка количества строк в рабочей таблице (узел WorkTable Scan) равна 3, а общее число строк рекурсивного запроса (узел Recursive Union) оценивается в 10 раз больше ― 31.
Но мы знаем точно, что этот рекурсивный запрос выполнит 1000 итераций и вернет 1000 строк, что превышает оценку примерно в 30 раз. Воспользуемся новым параметром для уточнения оценки:
SET recursive_worktable_factor = 300; -- 10*30
EXPLAIN WITH RECURSIVE t(n) AS (
SELECT 1
UNION ALL
SELECT n+1 FROM t WHERE n < 1000
)
SELECT * FROM t;
QUERY PLAN
---------------------------------------------------------------------------
CTE Scan on t (cost=90.03..110.05 rows=1001 width=4)
CTE t
-> Recursive Union (cost=0.00..90.03 rows=1001 width=4)
-> Result (cost=0.00..0.01 rows=1 width=4)
-> WorkTable Scan on t t_1 (cost=0.00..7.00 rows=100 width=4)
Filter: (n < 1000)
Теперь общая оценка кардинальности рекурсивного запроса стала точной, правда за счет избыточного увеличения среднего размера рабочей таблицы. Тем не менее, уменьшая или увеличивая значение recursive_worktable_factor можно влиять на оценку кардинальности узла WorkTable Scan, что в свою очередь влияет на оценку кардинальности узла Recursive Union.
Оптимизация GROUP BY
commit: db0d67db
От перемены мест слагаемых сумма не меняется. И от переставления столбцов в списке GROUP BY результат не меняется, а вот производительность выполнения запроса измениться может!
Пример запроса к таблице ticket_flights, у которой есть индекс по столбцам ticket_no, flight_id:
\d ticket_flights
Table "bookings.ticket_flights"
Column | Type | Collation | Nullable | Default
-----------------+-----------------------+-----------+----------+---------
ticket_no | character(13) | | not null |
flight_id | integer | | not null |
fare_conditions | character varying(10) | | not null |
amount | numeric(10,2) | | not null |
Indexes:
"ticket_flights_pkey" PRIMARY KEY, btree (ticket_no, flight_id)
...
Если в предложении GROUP BY поменять столбцы индекса местами, то планировщик «не видит» индекс, выбирая полное сканирование таблицы:
14=# EXPLAIN (analyze, costs off, timing off)
SELECT flight_id,ticket_no, count(*)
FROM ticket_flights
GROUP BY flight_id,ticket_no;
QUERY PLAN
----------------------------------------------------------------
HashAggregate (actual rows=8391852 loops=1)
Group Key: flight_id, ticket_no
Batches: 745 Memory Usage: 4409kB Disk Usage: 384560kB
-> Seq Scan on ticket_flights (actual rows=8391852 loops=1)
Planning Time: 0.154 ms
Execution Time: 5622.852 ms
Стоит лишь поменять местами столбцы в GROUP BY и планировщик понимает, что сканирование только индекса предпочтительнее:
14=# EXPLAIN (analyze, costs off, timing off)
SELECT flight_id,ticket_no, count(*)
FROM ticket_flights
GROUP BY ticket_no,flight_id;
QUERY PLAN
-------------------------------------------------------------------------------------------------
GroupAggregate (actual rows=8391852 loops=1)
Group Key: ticket_no, flight_id
-> Index Only Scan using ticket_flights_pkey on ticket_flights (actual rows=8391852 loops=1)
Heap Fetches: 0
Planning Time: 0.161 ms
Execution Time: 2342.767 ms
В 15-й версии планировщик научился находить более оптимальный план при любом расположении столбцов:
15=# EXPLAIN (analyze, costs off, timing off)
SELECT flight_id,ticket_no, count(*)
FROM ticket_flights
GROUP BY flight_id,ticket_no;
QUERY PLAN
-------------------------------------------------------------------------------------------------
GroupAggregate (actual rows=8391852 loops=1)
Group Key: ticket_no, flight_id
-> Index Only Scan using ticket_flights_pkey on ticket_flights (actual rows=8391852 loops=1)
Heap Fetches: 0
Planning Time: 0.221 ms
Execution Time: 2302.012 ms
Впрочем оптимизацию можно отключить новым параметром enable_group_by_reordering.
Более эффективное управление памятью при сортировке строк
commit: 40af10b5
Увидеть оптимизацию можно на таком примере:
14=# SET max_parallel_workers_per_gather = 0;
14=# EXPLAIN (analyze, costs off, timing off, summary off)
SELECT * FROM bookings
WHERE total_amount > 300000
ORDER BY total_amount;
QUERY PLAN
--------------------------------------------------------
Sort (actual rows=45623 loops=1)
Sort Key: total_amount
Sort Method: external merge Disk: 1480kB
-> Seq Scan on bookings (actual rows=45623 loops=1)
Filter: (total_amount > '300000'::numeric)
Rows Removed by Filter: 2065487
В 14-й версии для сортировки используется метод external merge с записью на диск.
Тот же запрос, на тех же данных в 15-й версии будет использовать более эффективный метод quicksort:
QUERY PLAN
--------------------------------------------------------
Sort (actual rows=45623 loops=1)
Sort Key: total_amount
Sort Method: quicksort Memory: 3969kB
-> Seq Scan on bookings (actual rows=45623 loops=1)
Filter: (total_amount > '300000'::numeric)
Rows Removed by Filter: 2065487
Конечно, можно и в 14-й версии получить quicksort, увеличив work_mem. Но именно в этом и состоит оптимизация ― при одинаковом объеме work_mem память расходуется эффективнее, что позволяет выбрать более быстрый способ сортировки.
Индексы GiST: баланс между скоростью поиска и скоростью построения индекса методом сортировки
commit: f1ea98a7
В предыдущей, 14-й версии патч Андрея Бородина научил PostgreSQL строить GiST-индексы быстрее (по столбцам с типом данных point) за счет предварительной сортировки значений в Z-порядке. Да, скорость увеличилась, но в результате охватывающие прямоугольники могли сильно накладываться друг на друга. Примерно так:
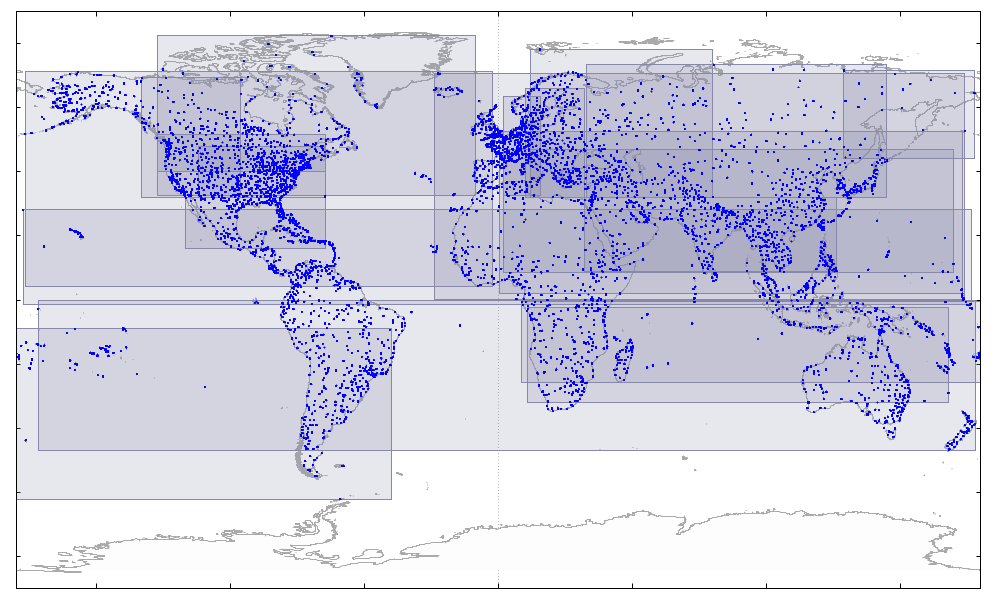
А это плохо для производительности — при поиске придется просматривать лишние страницы. Теперь индекс строится лучше, пересечений стало гораздо меньше:
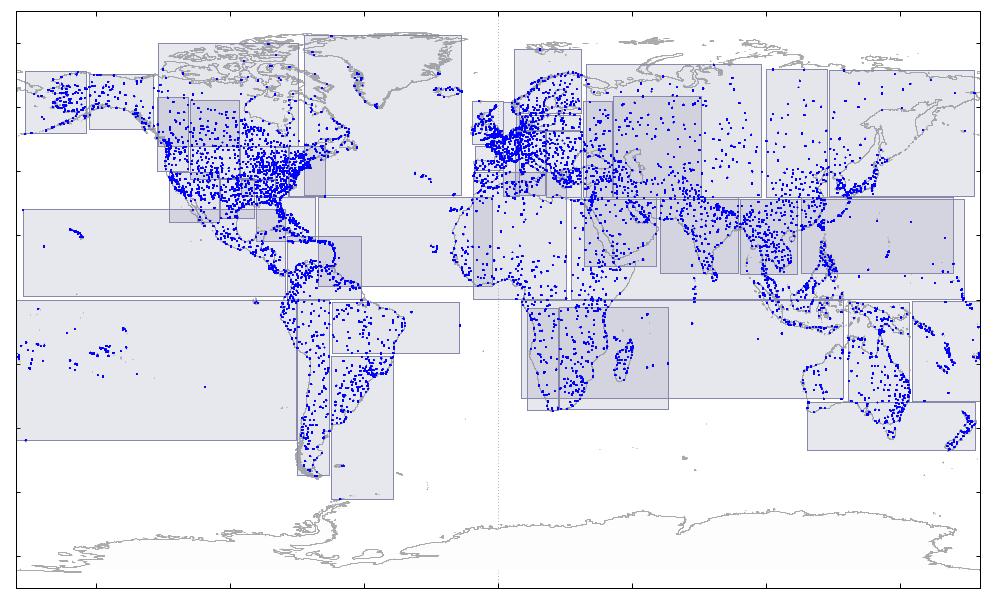
А вот так — еще чуть лучше — выглядит тот же индекс, построенный по старинке, медленно и без сортировки:
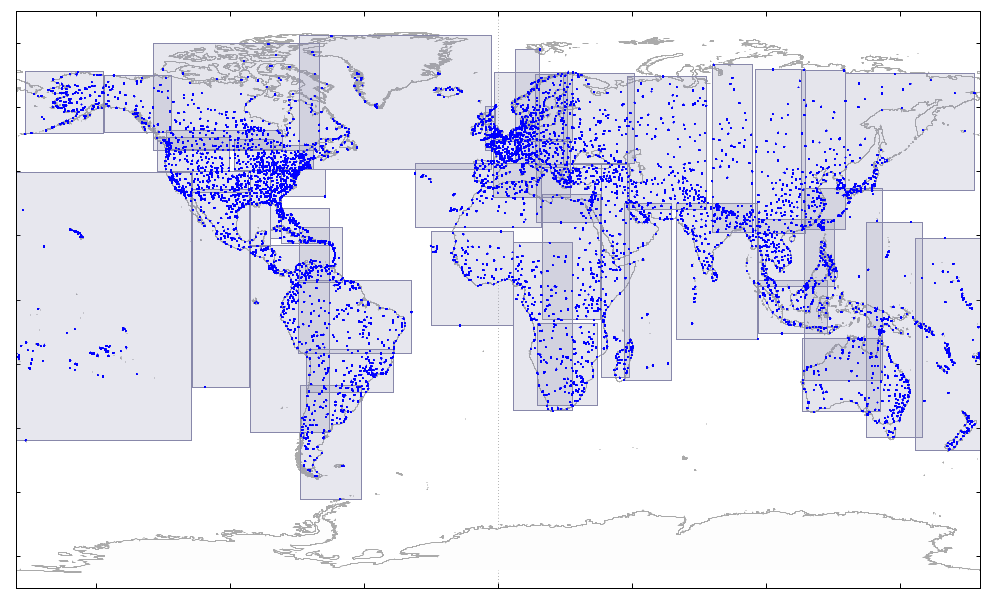
Подробнее о проблеме выбора между скоростью построения индекса и скоростью его использования Андрей рассказал в своем докладе на PGConf.Russia 2022.
Условие выполнения для монотонно возрастающих/убывающих оконных функций
commit: 9d9c02cc
Как найти 5 последних бронирований в таблице bookings? В PostgreSQL это очень простой и эффектно выполняющийся запрос:
14=# CREATE INDEX ON bookings(book_date);
14=# SET jit=off;
14=# EXPLAIN (analyze, costs off)
SELECT * FROM bookings ORDER BY book_date DESC LIMIT 5;
QUERY PLAN
-------------------------------------------------------------------------------------------------
Limit (actual time=0.016..0.022 rows=5 loops=1)
-> Index Scan Backward using book_date on bookings (actual time=0.015..0.020 rows=5 loops=1)
Planning Time: 0.086 ms
Execution Time: 0.037 ms
Главное, чтобы столбец book_date был проиндексирован, что и было предварительно сделано.
Фраза LIMIT доступна не во всех СУБД. В более общем виде запрос можно переписать с оконной функцией row_number:
14=# EXPLAIN (analyze, costs off)
SELECT * FROM (
SELECT *, row_number() OVER (ORDER BY book_date desc) row_num
FROM bookings
) t WHERE row_num <= 5;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------
Subquery Scan on t (actual time=0.037..1737.146 rows=5 loops=1)
Filter: (t.row_num <= 5)
Rows Removed by Filter: 2111105
-> WindowAgg (actual time=0.036..1661.209 rows=2111110 loops=1)
-> Index Scan Backward using book_date on bookings (actual time=0.018..1011.011 rows=2111110 loops=1)
Planning Time: 0.118 ms
Execution Time: 1737.174 ms
Однако производительность резко падает. Оконная функция row_number ничего не знает о том, что после получения пятой строки дальше выполнение запроса можно не продолжать. Поэтому узел WindowAgg честно получает все 2 с лишним миллиона записей и передает их узлу Subquery Scan. А узел Subquery Scan честно перебирает все полученные записи и применяет к ним фильтр (t.row_num
Вот как выполняется этот запрос в 15-й версии:
15=# EXPLAIN (analyze, costs off)
SELECT * FROM (
SELECT *, row_number() OVER (ORDER BY book_date desc) row_num
FROM bookings
) t WHERE row_num <= 5;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
WindowAgg (actual time=0.037..0.041 rows=5 loops=1)
Run Condition: (row_number() OVER (?) <= 5)
-> Index Scan Backward using bookings_book_date_idx on bookings (actual time=0.018..0.026 rows=8 loops=1)
Planning Time: 0.107 ms
Execution Time: 0.069 ms
Узла Subquery Scan нет вообще, а узел WindowAgg понимает, что после получения 5-й строки нужно прекращать выполнение. Это видно по появившемуся в 15-й версии условию Run Condition. Производительность практически не отличается от варианта с LIMIT.
Как этого добились? Для функции row_number добавлена вспомогательная функция для планировщика, которая сообщает планировщику о том, что результат функции будет монотонно возрастать. А планировщик, в свою очередь, использует особый фильтр Run Condition. Как только условие в Run Condition перестанет быть истинным, выполнение узла WindowAgg прекращается.
Для демонстрации специально подобран запрос с максимальным эффектом от оптимизации. Если бы у оконной функции использовалась фраза PARTITION BY или в запросе было бы несколько оконных функций, эффективность была бы ниже.
Такие же вспомогательные функции были добавлены не только для row_number, но и для rank (), dense_rank (), count (*) и count (expr).
Оптимизация заморозки версий строк
commit: 44fa8488, 872770fd, 05023a23, 0b018fab, f3c15cbe
Благодаря очередным оптимизациям и рефакторингу кода, обычная очистка в некоторых случаях научилась продвигать значение relfrozenxid для таблиц. А это значит, что у последующей заморозки будет меньше работы.
Увидеть оптимизацию можно на таком примере. Добавим в таблицу одну строку отдельной транзакцией и запустим обычную очистку:
CREATE TABLE t (id integer);
INSERT INTO t VALUES (1);
VACUUM VERBOSE t;
INFO: vacuuming "demo.bookings.t"
INFO: finished vacuuming "demo.bookings.t": index scans: 0
pages: 0 removed, 1 remain, 1 scanned (100.00% of total)
tuples: 0 removed, 1 remain, 0 are dead but not yet removable
removable cutoff: 942, older by 0 xids when operation ended
new relfrozenxid: 941, which is 1 xids ahead of previous value
index scan not needed: 0 pages from table (0.00% of total) had 0 dead item identifiers removed
avg read rate: 79.923 MB/s, avg write rate: 79.923 MB/s
buffer usage: 5 hits, 4 misses, 4 dirtied
WAL usage: 5 records, 4 full page images, 33167 bytes
system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
VACUUM
Обратите внимание на строку, начинающуюся с «new relfrozenxid:». По ней видно, что значение relfrozenxid для таблицы продвинулось на 1. В предыдущих версиях сервера продвижения не будет.
Кроме того, в предыдущих версиях нам пришлось бы получать значение relfrozenxid отдельным запросом к таблице pg_class. Теперь VACUUM VERBOSE, как и запись в журнал при срабатывании log_autovacuum_min_duration, содержит информацию об изменении relfrozenxid.
Оптимизация работы с вложенными транзакциями
commit: 06f5295a
Существенно оптимизирована работа с большим количеством вложенных транзакций (SAVEPOINT). В каждом сеансе теперь кешируется номер начальной транзакции. Что позволяет существенно реже запрашивать информацию о полном списке вложенных транзакций из буферов SLRU, за которые может возникать конкуренция (событие ожидания SubtransSLRULock в pg_stat_activity).
postgres_fdw: параллельная фиксация транзакций на внешних серверах
commit:04e706d4
При фиксации транзакции, в которой участвуют несколько внешних серверов подключенных по postgres_fdw, удаленные транзакции могут завершаться асинхронно, а не последовательно одна за другой.
Для этого при создании внешнего сервера нужно включить новый параметр parallel_commit:
CREATE SERVER srv_1
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
...
parallel_commit true
);
Асинхронная фиксация может выполняться быстрее в тех случаях, когда в одну транзакцию попадают изменения на многих внешних серверах с включенным parallel_commit.
© Habrahabr.ru
