Поиск текстов, не соответствующих тематике и нахождение похожих статей
У меня есть сайт со статьями схожей тематики. На сайте было две проблемы: спамерские сообщения и дубликаты статей, причём дубликаты часто являлись не точными копиями.Данный пост повествует о том, как я решил эти проблемы.
Дано:
общее количество статей 140 000;
количество спама: примерно 5%;
количество не чётких дубликатов: примерно 75%;
Задача: избавиться от спама и дубликатов, а так же не допустить их дальнейшего появления.
Все статьи на моём сайте относятся к одной и той же тематике и, как правило, спамерсие/рекламные сообщения прилично отличаются по содержанию. Я решил вручную отсортировать некоторое количество статей. И на их основе построить классификатор. Для классификации будем считать косинусное расстояние между вектором проверяемой статьи и векторами двух групп (спам/не спам). К какой группе проверяемая статья ближе, к той и будем относить статью.Сначала надо вручную классифицировать статьи. Набросал для этого форму с чекбоксами и собрал за несколько часов 650 статей спама и 2000 не спама.
Все посты очищаются от мусора — шумовых слов, которые не несут полезной нагрузки (причастия, междометия и пр). Для этого я собрал из разных словарей, которые нашёл в интернете, свой словарь шумовых слов.
Чтобы минимизировать количество различных форм одного слова, можно использовать стеммиг Портера. Я взял готовую реализацию на Java отсюда. Спасибо, Edunov
Из слов классифицированных статей, очищенных от шумовых слов и прогнанных через стемминг надо собрать словарь.
Из словаря удалим слова, которые встречаются только в одной статье.
Для каждой классифицированной вручную статьи считаем количество вхождений каждого слова из словаря. Получатся векторы, похожие на следующие: 
Усиливаем в каждом векторе веса слов, считая для них TF-IDF. TF-IDF считается отдельно для каждой группы спам/не спам.
Сначала считаем TF (term frequency — частота слова) для каждой статьи. Это отношение количества вхождений конкретного слова к общему числу слов в статье:

где ni есть число вхождений слова в документ, а в знаменателе — общее число слов в данном документе.
Дальше считаем IDF (inverse document frequency — обратная частота документа). Инверсия частоты, с которой некоторое слово встречается в документах группы (спам/не спам). IDF уменьшает вес слов, которые часто употребляются в группе. Считается для каждой группы.

где
|D| — количество документов в группе;
di⊃ti — количество документов, в которых встречается ti (когда ni≠0).
 Считаем TF-IDF:
Считаем TF-IDF:
Большой вес в TF-IDF получат слова с высокой частотой в пределах конкретного документа и с низкой частотой употреблений в других документах.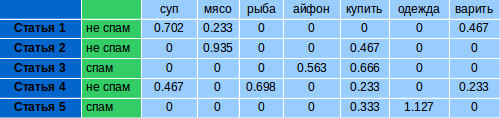
Для каждой группы формируем по одному вектору, считая среднее арифметическое каждого параметра внутри группы: 
Чтобы проверить статью на спам, надо получить для нее количество вхождений слов их словаря. Посчитать для этих слов TF-IDF для спама и не спама. Получится два вектора (на изображении TF-IDF не спам и TF-IDF спам). IDF для расчётов, берём тот, который считали для классифицирующей выборки.
Для каждого вектора считаем косинусное расстояние с векторами для спама и не спама, соответственно. Косинусное расстояние — это мера похожести двух векторов. Скалярное произведение векторов и косинус угла θ между ними связаны следующим соотношением: 
Имея два вектора A и B, получаем косинусное расстояние — cos (θ)
Код на Java public static double cosine (double[] a, double[] b) { double dotProd = 0; double sqA = 0; double sqB = 0; for (int i = 0; i < a.length; i++) { dotProd += a[i] * b[i]; sqA += a[i] * a[i]; sqB += b[i] * b[i]; } return dotProd/(Math.sqrt(sqA)*Math.sqrt(sqB)); } В результате получается диапазон от -1 до 1. -1 означает, что вектора полностью противоположны, 1, что они одинаковы.Какое из полученных значений (для спама и не спама) будет ближе к 1, к той группе и будем относить статью.
При проверке схожести на не спам получилось число 0.87:  на спам — 0.62:
на спам — 0.62:  Следовательно, считаем, что статья — не спам.
Следовательно, считаем, что статья — не спам.
Для тестирования я вручную отобрал ещё 700 записей. Точность результатов была 98%. При этом то, что классифицировалось ошибочно даже мне было сложно отнести к той или иной категории.
После очистки от спама осталось 118 000 статей.Для поиска дубликатов я решил использовать инвертированный индекс (Inverted index). Индекс представляет собой структуру данных, где для каждого слова указывается, в каких документах оно содержится. Соответственно, если у нас есть набор слов, можно легко сделать запрос документов, содержащих эти слова.
Пример с Вики. Допустим, у нас есть следующие документы:
T[0] = «it is what it is» T[1] = «what is it» T[2] = «it is a banana» Для этих документов построим индекс, указав, в каком документе содержится слово: «a»: {2} «banana»: {2} «is»: {0, 1, 2} «it»: {0, 1, 2} «what»: {0, 1} Все слова «what», «is» и «it» находятся в документах 0 и 1: {0,1} ∩ {0,1,2} ∩ {0,1,2} = {0,1} Индекс я сохранял в БД MySQL. Индексирование заняло около 2-х дней.Для поиска похожих статей не надо, чтобы совпадали все слова, поэтому при запросе по индексу получаем все статьи, у которых совпало хотя бы 75% слов. В найденных содержатся похожие дубликаты, а так же другие статьи, которые включают в себя 75% слов изначальной, например, это могут быть очень длинные статьи.
Чтобы отсеять то, что дубликатом не является, надо посчитать косинусное расстояние между исходной и найденными. То, что совпадает больше, чем на 75% считаю дубликатом. Число в 75% выводил эмпирически. Оно позволяет находить достаточно изменённые версии одной и той же статьи.
Пример найденных дубликатов: Вариант 1: Чизкейк со сгущенкой (без выпечки)Ингредиенты:* 450 гр Сметана от 20% жирности* 300 гр печенья
* 100 гр растопленного сливочного масла* 300 гр хорошего сгущенного молока* 10 гр быстрорастворимого желатина* ¾ стакана холодной кипяченой воды
Приготовление: Разборную форму выстелить пергаментной бумагой.Размельченное в мелкую крошку печенье смешать с растопленным маслом. Смесь должна быть не жирной, но и не сухой. Выложить смесь в форму и хорошо уплотнить. Убрать в холодильник на 30 минут.Сметану смешать со сгущенным молоком.Желатин залить ¾ стакана воды и поставить на 10 минут набухать. Затем растопить его на водяной бане так, чтобы он весь растворился.В смесь сгущенки и сметаны осторожно влить желатин, тщательно помешивая. Перелить затем в форму. И убрать в холодильник до полного застывания примерно на 2–3 часа.При застывании можно добавить ягоды свежей клюквы или посыпать тертым шоколадом или орехами.
Приятного аппетита!
Вариант 2: «Чизкейк» без выпечки со сгущенкой
Ингредиенты:
-Сметана от 20% жирности 450 гр
-300 гр печенья (я брала овсяные)-100 гр растопленного сливочного масла-300 гр качественного сгущенного молока-10 гр быстрорастворимого желатина-¾ стакана холодной кипяченой воды
Приготовление:
1). Форму (лучше разъёмную) застелить пергаментной бумагой.2). Печенье измельчить в мелкую крошку и смешать с растопленным маслом. Масса не должна быть жирной, но и не слишком сухой. Уложить массу в форму и хорошо утрамбовать. Поставить в холодильник на полчаса.3). Сметану смешать со сгущенным молоком (можно добавить больше или меньше сгущенки, это уже дело вкуса).4) Желатин залить ¾ стакана воды и оставить на 10 мин. набухать. Затем растопить его на водяной бане так, чтобы он полностью растворился.5) В сметано-сгущенную массу потихоньку ввести желатин, хорошо помешивая. Перелить затем в форму. И отправить в холодильник до полного застывания. У меня застыл быстро. Где-то 2 часа.Я при застывании добавила еще ягоды свежей клюквы — это придало пикантность и кислинку. Можно посыпать тертым шоколадом или орехами.
Полная чистка заняла около 5 часов.Чтобы обновлять индекс для поиска дубликатов, не надо перестраивать уже существующие данные. Индекс достраивается инкрементально.
Из-за ограниченного количества оперативки на сервере у меня нет возможности держать индекс в памяти, поэтому я и держу его MySQL-е, где хранятся сами статьи. Проверка одной статьи, если не грузить всё в память, занимает у программы около 9 сек. Это долго, но т.к. новых статей в сутки появляется лишь несколько десятков, решил не заморачиваться со скоростью, пока этого не потребуется.
