Поиск идеального поиска: как устроены поисковые эксперименты на Юле
Привет всем!
Меня зовут Маргарита Даминова, вместе с Еленой Бронниковой мы решили обобщить опыт команды продуктовой аналитики Юлы и поделиться им в статье, где расскажем о нашем подходе в области поисковых экспериментов. Ранее в блоге мы уже писали о метриках и индексах, которые мы используем в продукте, чтобы следить за активностью мошенников и оценивать эффективность наших антифрод-фичей. В этой статье расскажем о том, как и зачем мы проводим поисковые эксперименты, какими метриками пользуемся и как влияем на развитие поисковой системы нашего сервиса объявлений.

Как все устроено на Юле
В Юле есть разные продуктовые команды, ответственные за развитие определенной части сервиса. В статье я расскажу о команде Поиска, которая занимается тем, что повышает качество выдачи поисковых запросов и товарных рекомендаций. Чем качественнее поиск, тем проще продавцу и покупателю найти друг друга. Чтобы проверить гипотезы и внести улучшения в эту часть продукта, мы проводим эксперименты.
Поиск в Юле это несколько больше, чем поисковая строка и выдача. Пользователь нашего сервиса может взаимодействовать с объявлениями в трех разделах:
Главная страница. Это первый экран, с которым контактирует пользователь. Главная наполнена рекомендациями, выстроенными на основе интересов;
Категория. Это определенный раздел с объявлениями, объединенными в одну категорию, например, вертикаль Недвижимости;
Текстовый поиск — конкретный поиск по запросу пользователя через поисковую строку. Пользователь может также искать объявления текстовым поиском внутри только одной категорий.
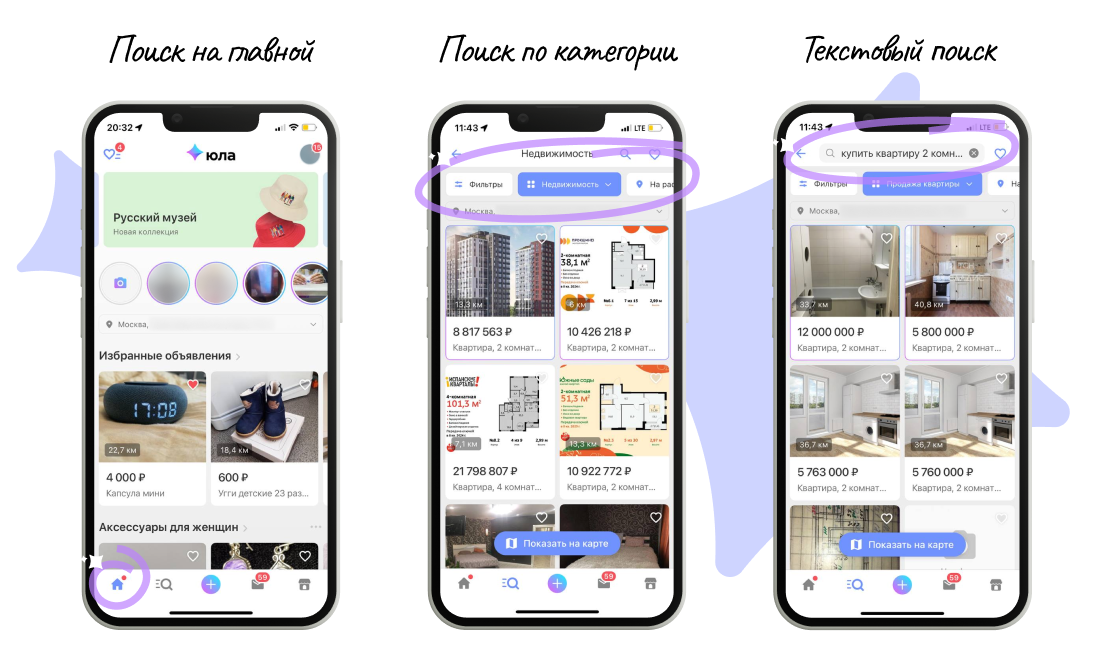
Мы привыкли называть эти разделы типами поиска. У каждого из них есть свои особенности в наполнении выдачи и ранжировании, поэтому эксперименты, как правило, разграничиваются между ними. Это позволяет правильно интерпретировать результаты эксперимента, последовательно внедрять изменения и новые фичи.
Мы проводим эксперименты в поиске, преследуя разные цели. Условно все задачи можно разделить на несколько групп:
Технические улучшения — сюда относятся доработки или улучшения алгоритма поиска, то есть то, что потенциально может нарастить качество поисковой выдачи. Также к этой группе относим все эксперименты, направленные на фикс багов, например, если некорректно работают фильтры или сортировки.
Продуктовые фичи — классные идеи, которые вряд ли повлияют на качество выдачи, но скорее всего улучшат опыт пользователя и увеличат шанс встречи покупателя и продавца на Юле. Хороший пример: возможность пользователя подписываться на поисковые запросы.
Ранжирование поисковой выдачи — эксперименты с моделями ранжирования, цель которых — сделать выдачу наиболее соответствующей интересам пользователя.
Акции и спецпроекты — <что-то на кутёжном>.
Другое: исследовательские эксперименты, тематические подборки с объявлениями на главной странице и прочее.
Разделение на цели — не просто для «галочки». В зависимости от цели эксперимента мы ожидаем разных результатов. К примеру, если он направлен на фикс багов поиска, то, как правило, мы ждем, что целевые метрики не упадут. Если эксперимент связан с новой фичей, то ожидаем значимых улучшений метрик. Наша задача как аналитиков — проверить, сработают ли ожидания на практике и численно оценить изменения целевых метрик.
Целевые метрики в поиске
Основные метрики, на которые мы чаще всего смотрим — показы, просмотры, контакты, сделки, конверсии в полезные действия и метрики качества поиска. Расскажу подробнее.
Показы — это количество событий, когда пользователь увидел объявление в разделе до перехода в карточку самого объявления, то есть клика по нему.
Это самая простая и базовая метрика. В каких случаях она может меняться? Пользователи стали больше или меньше пролистывать ленту, мы увеличили или уменьшили объем выдачи.
Помимо общей метрики «показы» нам необходимо следить за относительными метриками: доля показанных объявлений от всех активных объявлений, количество показов на активное объявление и многие другие. Все эти метрики бывают очень полезны в разных срезах. К примеру, срез «старые и свежие объявления» или же «частные продавцы и профессиональные». Зная более глубокие срезы по метрикам, мы можем отслеживать, что показы распределяются равномерно.
Показы — очень чувствительная метрика, и она в действительности далеко не всегда свидетельствует об успешности фичи. К примеру, мы легко можем вырастить показы, но если пользователи не стали лучше конвертироваться в переходы в объявление, в этом нет большого смысла. В особенности, если мы «забили ленту» не очень релевантным контентом. По этой причине метрику «показы» имеет смысл рассматривать только в совокупности с другими метриками.
Оценивая просмотры, мы можем судить о заинтересованности пользователей. Если пользователь кликнул на объявление, можно сделать вывод, что он заинтересовался. Чаще всего мы хотим видеть рост этой метрики, но увеличение просмотров нужно еще правильно интерпретировать. Может быть, рост числа просмотров означает, что пользователю сложно найти нужный товар: ему приходится делать больше просмотров объявлений прежде, чем он найдет то, что ожидает. Или наоборот. Именно поэтому важно понимать контекст эксперимента.
Контакты — это наша целевая метрика. Больше контактов — выше вероятность сделок между продавцами и покупателями на Юле. Но и с этой метрикой надо быть аккуратным. Большое количество контактов может свидетельствовать о недостаточной или некорректной информации в описании. Чтобы сделать корректные выводы, необходимо исключить возможный спам в чатах и парсинг номеров. Мы можем использовать подтверждающую метрику, похожую по смыслу на «контакты» — это метрика «добавление в избранное». К ней мы обращаемся, чтобы убедиться, что пользователя заинтересовал товар.
Сделки — это метрика, которую мы оцениваем приблизительно. Мы не всегда можем быть уверены, что продажа и покупка состоялись на самом деле. Мы регистрируем события, косвенно подтверждающие этот факт: пользователь снял товар с продажи. Продал ли он на самом деле? Существует действие, которое дает нам подтверждающую информацию: продавец может указать настоящего покупателя при снятии объявления. Разумеется, далеко не во всех сделках это происходит. Зная это, мы выработали подход для определения сделки по последнему контакту перед снятием с продажи. Тот, кто последний проконтактировал с продавцом, наиболее вероятно и является покупателем товара. Эта методика определения покупателя обладает высокой точностью, и мы получаем бОльшее количество известных покупателей для анализа.
За длительный опыт экспериментов (примерно с 2017 года) мы пришли к выводу, что изменение качества поиска не всегда увеличивает спрос. А нам в конечном счете хочется влиять именно на него. Поэтому мы ориентируемся на контакты (как прокси сделок) или же смотрим на метрики качества поиска, которые мы сами разработали.Например, такой метрикой является средняя позиция первого клика.
Средняя позиция первого клика — это позиция объявления в ленте, на которое пришелся первый клик пользователя.
Такая метрика позволяет сделать выводы или предположения о релевантности ленты. Если выдача соответствует тому, что ищет пользователь, то позиция первого клика будет меньше, то есть пользователь кликнет по объявлению раньше. Эта метрика очень полезна в аналитике как раз тем, что она сильно чувствительна к изменениям. Второе ее преимущество — простота для интерпретации. Иногда именно по этой метрике мы отмечаем значимые улучшения раньше, чем в наших целевых метриках, и зачастую этого достаточно. Подержав эксперимент чуть дольше, мы бы увидели эффект и в остальных метриках. Но порой нам достаточно улучшений только в позиции первого клика. К примеру, целью эксперимента были технические улучшения. Допустим, мы хотели улучшить работу фильтров в поиске. Чтобы убедиться, что доработка улучшает качество поиска, мы реализуем АБ-тесты — основной группе пользователей показываем прежнюю логику, а для части включаем обновление. Если мы увидим улучшения в позиции первого клика, то это уже подтвердит, что пользователь встречает объявление, которое его заинтересует, раньше.
В ходе экспериментов команда Поиска придумала дополнительную прокси-метрику качества поиска. В процессе исследования успешных экспериментов выяснилось, что их отличительная особенность состоит в следующем: пользователи, совершающие покупки, просматривают больше интересных им товаров перед принятием окончательного решения. Это натолкнуло на мысль, о введении новой метрики в наши эксперименты.
Разработанная метрика основана на подсчете количества открытий карточки объявлений пользователем в наиболее просматриваемой им подкатегории товаров до совершения покупки. Преимущество этой прокси-метрики качества поиска в том, что она позволяет быстро, без существенных затрат времени на сбор данных, оценить, улучшает ли эксперимент качество поиска пользователем купленного им в итоге товара. Стоит уточнить, что эта метрика не является целевой. Однако зная такую поведенческую особенность большинства «доведенных до финала сделок», бывает полезно посмотреть на то, как себя ведет эта метрика.
Не всегда пустая выдача говорит об отсутствии подходящих объявлений на сервисе. Иногда это может свидетельствовать о недостатках в алгоритме или схеме работы поиска. Поэтому мы следим за количеством пустых и неполных выдач и стремимся их минимизировать, но при этом не снижая релевантность выдачи.
Асессорская оценка изменений командой Поиска — дополнительный метод исследования, но мы применяем его всегда, а зачастую именно он позволяет нам принять окончательное решение о результатах эксперимента. Кратко поделюсь логикой проведения такой оценки.
В специальной системе асессорам подается пара «Поисковый запрос — Объявление», которое попало в выдачу по этому запросу. Специалист поисковой системы (асессор) должен поставить оценку:
3 — если объявление точно отвечает запросу;
2 — если выданное объявление полезно. Например, по запросу пользователя «скутер» в выдачу попадает объявление «ремонт скутеров»;
1 — если выдача, что называется, мимо. Например, по запросу «клетка» пользователь получает «платье в клетку».
По каждому запросу оценивается несколько первых объявлений в выдаче, в нашем случае первые 10. Из полученных оценок по запросу вычисляется метрика DCG (discounted cumulative gain) — взвешенная сумма оценок. Чем ближе объявление к началу выдачи, тем больше вес оценки. Далее считается средняя DCG по всем запросам, обычно оценивается 1000 запросов.
Все показатели, о которых речь шла выше, очень полезно смотреть в различных разбивках или в относительных выражениях. Так аналитик может обнаружить действительно интересные и полезные инсайты. Например, мы смотрим показатели в разбивках по платформам, категориям объявлений, типу продвижения объявлений и типу поиска. Это дает нам более достоверные и полезные интерпретации результатов в экспериментах.
Дизайн экспериментов
С метриками мы определились, теперь немного погрузимся в процесс самого AB-тестирования в поиске. Если кратко, то основной флоу можно описать следующими этапами:
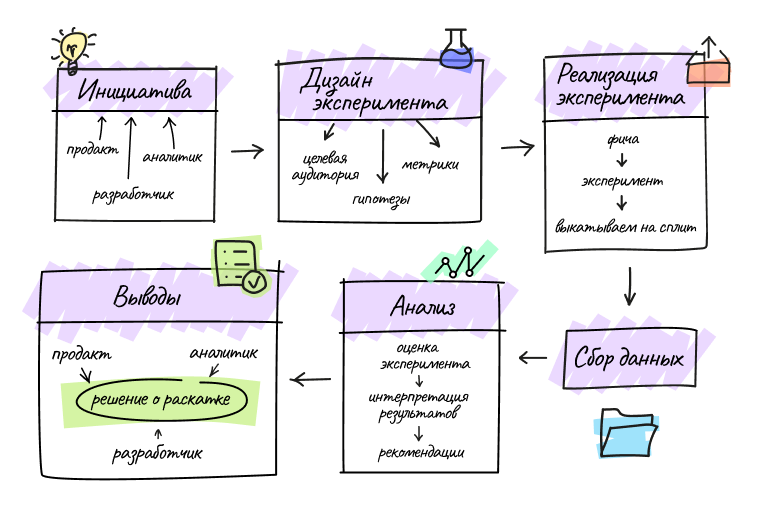 Процесс поискового эксперимента
Процесс поискового эксперимента
Инициатива — стартовая точка процесса AB-тестирования. Чаще всего заказчиком эксперимента является продакт-менеджер, но им может быть любой член команды. Чуть ниже я приведу кейс, в котором команда аналитики стала инициатором. А в результате экспериментов и доработок мы получили новую фичу продукта.
Дизайн эксперимента — на этом этапе обсуждается как будет происходить исследование: какие гипотезы мы выдвигаем для проверки, на каких пользователей запускается эксперимент и какие метрики будут оцениваться.
Реализация — команда Поиска разрабатывает фичу, заводит эксперимент и выкатывает его в продакшн. Затем заказчик включает его через админку на определенный сплит (группа пользователей), который выделили под данный эксперимент.
Сбор данных — эксперимент запущен, теперь мы ждем, чтобы собралось достаточно данных.
Анализ и Выводы — аналитик оценивает эксперимент, интерпретирует результаты и дает рекомендации. На финальном шаге команда продуктовой аналитики и продакт-менеджер формулируют основные выводы эксперимента и принимают решение о раскатке.
Расскажу более детально о каждом этапе применительно к теме поисковых экспериментов. Эксперименты в поиске, как правило, запускаются минимум на 2 недели. Как раз за это время мы получаем достаточно данных, чтобы сделать корректные выводы.
Мы используем разные пространства для запуска экспериментов. Каждое такое пространство разбито на непересекающиеся сплиты. Для поисковых экспериментов их всего восемь. Один из сплитов всегда является контрольным. Разбиение на сплиты в пространстве для поисковых экспериментов происходит по хэшу идентификатора устройства пользователя, или же по-другому его user_uid, с «солью». Соль используется для того, чтобы обеспечить «равенство» сплитов, так как пользователи могут со временем начать себя вести по-разному:

Существует два сценария проведения эксперимента:
⅛ — запускаем на один сплит и сравниваем результаты с контрольным сплитом;
⅞ или по-другому «инверсия» — запускаем на все сплиты, кроме одного и сравниваем его с контрольным.
Стандартным вариантом является первый сценарий. Такой метод используется как основной, поскольку эксперимент на одном сплите позволяет снизить влияние эксперимента на тотал целевых метрик. Второй сценарий чаще используется в качестве дополнительного этапа, чтобы удостовериться в полученных результатах, или чтобы избежать потери от поздно раскатанного успешного эксперимента. Иногда бывает, что мы видим другой эффект при раскатке изменений на ⅞. Связано это с тем, что спрос (или предложение) «размазывается» на всех пользователей.
Итак, эксперимент запущен, данные собраны, аналитику предстоит подвести итоги. При оценке экспериментов мы пользуемся стандартными статистическими критериями:
Отдельно для поисковых экспериментов у нас есть отчет, который позволяет как аналитикам, так и менеджерам быстро посмотреть основные результаты по целевым метрикам в эксперименте. Такое решение удобно для ускорения проведения экспериментов и оценки их результатов.
Аналитика в деле
Я уже упомянула, что аналитики также могут быть инициаторами экспериментов. Толчком для такой инициативы может послужить исследование продукта и поведения пользователей. Поделюсь нашей историей участия аналитиков в развитии продукта, а именно историей зарождения очень важной фичи Юлы — похожие объявления в конце неполных и пустых поисковых выдач.
В апреле 2020 аналитики провели исследование, направленное на изучение особенностей поиска Юлы. Мы хотели выявить точки роста в продукте. Команда проанализировала поведение новых пользователей в зависимости от результатов первой поисковой выдачи и обнаружила интересную закономерность: если первая поисковая выдача не содержит результатов (показываем сообщение — «Ничего не нашлось»), то это отпугивает пользователя. У человека может появиться мысль, что на Юле нет необходимых ему товаров. А это в свою очередь сильно сказывается на дальнейших полезных действиях пользователя. Наше исследование подтвердило, что у тех, чьим первым опытом поиска была нулевая выдача, вероятность вернуться на следующий день в 1.5 раза ниже, а на седьмой день — уже ниже в 1.8 раз. Вероятность контакта и сделки сокращается в 2 и в 3 раза, соответственно.
Уже спустя месяц после обнаружения этой закономерности мы запустили эксперимент: в конец всех выдач стали добавлять объявления, подобранные по алгоритму «похожих». Для выдач, где нашлось много объявлений, это изменение будет незаметным для пользователя, а пустые и неполные выдачи дополнятся похожими. Кстати, неполными называются выдачи, которые занимают меньше одной страницы. Пустыми — те, где по запросу не нашлось ничего.
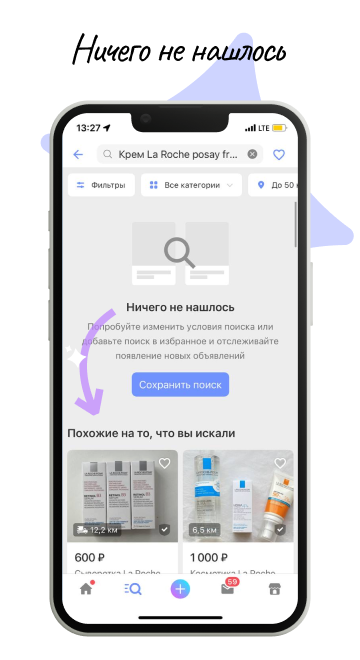 Использование алгоритма «похожие на то, что вы искали»
Использование алгоритма «похожие на то, что вы искали»
В результате эксперимента число пустых и неполных выдач в общем объеме поисковых запросов уменьшилось на 65%. Выросли все продуктовые метрики: контакты в текстовом поиске, покупки после такого контакта и даже покупки в тотале. Наблюдался также рост DAU (Daily Active Users, активные пользователи) и Retention rate (возвращаемость пользователей) Еще одна метрика, которая подтвердила, что что изменения в поиске стали полезными и как минимум не портили выдачу — это рост конверсий из показа в просмотр и в сделку.
 Контакты-Текстовый поиск до эксперимента и в процессе его проведения
Контакты-Текстовый поиск до эксперимента и в процессе его проведения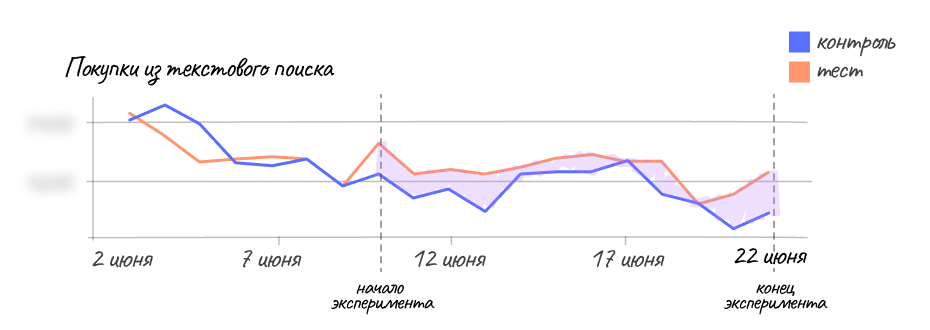 Покупки-Текстовый поиск до эксперимента и в процессе его проведения
Покупки-Текстовый поиск до эксперимента и в процессе его проведения
Аналитика на страже порядка
Я уже упоминала, но хочу обратить внимание еще раз — аналитику супер-важно быть в контексте эксперимента и понимать, на что действительно он может повлиять. Иногда мы находим весьма неожиданные результаты, поэтому стараемся быть бдительными. Ниже я расскажу о паре интересных случаев из нашего опыта экспериментов.
Главная страница Юлы содержит раздел рекомендаций, построенный на основе интересов пользователя. Мы периодически проводим эксперименты с этим блоком, чтобы предлагать пользователю наиболее подходящие ему объявления. Ряд экспериментов был посвящен проверке гипотезы — чем ближе геолокация товара, тем он привлекательнее для пользователя. Для этого мы протестировали различную логику ранжирования объявлений по гео. Основной вывод, который сформулировали по результатам эксперимента: удаленность не является определяющим фактором выбора. Если товар действительно нужен пользователю, то он будет готов рассмотреть и более удаленные варианты.
Помимо прочего наш опыт в экспериментах подтвердил важность погружения аналитика в контекст и задачу. Приведу в пример необычный эффект, который мы отметили в эксперименте, направленном на метрики главной страницы — показатели, основанные на действиях пользователей на главной Юлы. В ходе эксперимента в метриках главной страницы наблюдалось значимое падение. Причем изменения были вызваны исключительно механикой выдачи платных объявлений, объявлений с купленным продвижением. Платные объявления показывались в меньшем объеме в данном эксперименте. Без погружения в цели эксперимента и его специфику, такая аномалия могла привести аналитика к некорректным выводам. В приведенном кейсе на самом деле изменения были вызваны лишь техническими недоработками и не повлекли за собой значимого отклонения метрик.
В поисковых экспериментах особенно важно тесное сотрудничество между разработкой и аналитиками. Мы всегда презентуем выводы не только продуктовой стороне, но и технической команде.
Команда Поиска часто исследует качество поиска, чтобы обнаружить слабые места и предложить улучшения. Одно из таких исследований выявило случаи, в которых из-за платных объявлений нарушаются условия фильтрации и сортировки в поиске, так как объявления с купленным продвижением всегда вставляются на фиксированные позиции в выдаче.
Это очень важная проблема с точки зрения опыта пользователя: он становится негативным, если фильтры и сортировки не применяются так, как пользователь того ожидает. При этом нам было важно не просадить метрики платных объявлений, так как продавцы нам не менее важны.
По итогу эксперимента показы и просмотры платных объявлений снизились на 3% и 5%, соответственно, при этом в контактах и сделках падения не наблюдалось, то есть платные объявления стали получать ту же эффективность, что и до этого, но при более низком количестве показов. Связанно это с тем, что в отфильтрованных выдачах платные объявления были нерелевантными. Вместе с тем мы улучшили метрику качества поиска — позиция первого клика улучшилась в поисках с фильтрами почти на 2%. Эксперимент в результате был признан успешным, так как мы однозначно улучшили пользовательский опыт, при этом не нанесли ущерб продавцам, которые платят и ожидают эффективность своих объявлений.
Заключение
Поисковые эксперименты в Юле запускаются почти с самого начала появления сервиса, за это время у нас сформировался четко выстроенный процесс. В этой статье я поделилась основным флоу, выбором метрик и некоторыми кейсами из нашей практики. Во многих сервисах, особенно в e-commerce, присутствует поиск по товарам или услугам, поэтому надеюсь прочтение материала было полезным для вас. Приходите в комментарии — обсудить и поделиться вашим опытом выстраивания поисковых экспериментов и улучшения Поиска.
