Поиск четырёхугольников документов на мобильных устройствах

Некоторые из модулей распознавания документов, разработанных нашей компанией, в качестве первого этапа своей работы должны определять расположение объекта на поступающем изображении или в видеопотоке. Сегодняшняя статья посвящена одному из задействованных у нас подходов к решению этой задачи.
Постановка задачи
Для начала определим, какую информацию мы можем использовать в своих целях.
В приложениях достаточно жёстко заданы предполагаемые типы документов. Будем считать, что никто всерьёз не пытается распознать паспорт приложением для банковских карт или наоборот, а значит нам известны, как минимум, пропорции искомого объекта. Также заметим, что абсолютное большинство мобильных девайсов имеет камеры с фиксированным фокусным расстоянием.
Поскольку найденное ещё предстоит распознавать, имеет смысл искать далеко не любое изображение документа. Чтобы не получить на входе фотографию с маленьким кусочком документа в углу наискосок, используем некоторые ограничения и сопроводим их визуализацией, которая помогала бы пользователю получить подходящую компоновку кадра на этапе съёмки.
Конкретно, хотелось бы выполнения следующих условий:
1 — распознаваемый документ должен быть целиком в кадре.
2 — документ должен занимать достаточно большую часть кадра.
Добиться выполнения этих условий можно по-разному. Если напрямую потребовать, чтобы документ занимал не менее X% площади кадра — можно услышать вполне обоснованный скрежет пользовательских зубов, поскольку на глаз весьма затруднительно определить, занимает ли документ, скажем, 80% площади кадра, или только 75%.
Но есть и гораздо более наглядные варианты. Так, можно задать допустимые прямоугольные зоны для каждой из вершин границы документа и предложить пользователю навести камеру таки образом, чтобы в каждой зоне полностью лежала одна сторона документа.
Для пользователя это может выглядеть, например, так: 
Помимо наглядности для пользователя, такой способ накладывает дополнительное полезное нам ограничение на позицию документа: исходя из размеров зон, можно вычислить максимальные возможные углы наклона сторон к осям координат, и, как следствие, диапазон возможных отклонений углов четырёхугольника от 90 градусов. Ну, или же, наоборот, можно задать такие размеры зон, чтобы отклонения этих параметров не превышали некоторых пороговых значений.
С этого места и далее можно наблюдать лавирование между Сциллой и Харибдой любого алгоритма по обработке изображений — скоростью и точностью/качеством работы.
Выделение границ
Прежде всего приведём входное изображение к меньшему размеру, чтобы снизить затраты времени. Мы используем приведение к 320 px по большей стороне как некоторый оптимум, подобранный для конкретных юзкейсов.
Для поиска документа нам потребуются только регионы изображения, соответствующие 4 зонам сторон. В каждом из них будем искать границы, которые могли бы быть краями документа.
Дальнейшие манипуляции будем рассматривать на примере верхнего региона — для остальных действия аналогичны с точностью до поворота на 90 градусов (*).
- Рассчитаем градиент изображения, предварительно подавив высокочастотные шумы фильтром Гаусса. В силу ограничений на расположение документа нас интересуют только ортотропные границы, т.е. направленные преимущественно вдоль одной из осей координат (в случае верхнего региона — вдоль оси ОХ). Для поиска таких границ достаточно производной вдоль оси OY. Проблема в том, что цветное изображение — векторное, и производная его тоже вектор, но в одномерном случае для оценки выраженности границы можно взять какую-нибудь норму этого вектора, в отличие от полного градиента, который рассчитывается намного сложнее, например, по Di Zenzо [1].
Чтобы избежать лишних арифметических операций, воспользуемсянормой, т.е. возьмем модуль производной в каждом канале
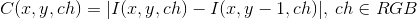
а затем выберем наибольшее из этих значений
получая в результате полутоновое изображение-производную. - Отфильтруем полученное изображение: сначала используем классическое подавление немаксимумов (см. Канни [2]) и получим начальную карту границ, затем подавим порождённые текстурами выбросы. Для этого домножим значение каждого пикселя G (x, y) границ на такой коэффициент k:

где ht — высота региона, а у0, y1 — y-координаты ближайших к текущему граничных пикселей сверху и снизу, либо фейк-значения в случае их отсутствия. - Соберём граничные пиксели в компоненты связности — у них больше возможных параметров отсечения чем у отдельных пикселей. В нашей реализации отбрасываются компоненты, размер или средняя яркость которых меньше пороговых значений.
*Поиск границ (а затем и прямых) в каждом регионе происходит независимо от остальных, а значит — отлично распараллеливается.Поиск прямых
Следующий шаг — извлечение прямых с использованием быстрого преобразования Хафа [3](*). Преобразование Хафа переводит карту границ в матрицу-аккумулятор, каждая ячейка (i, j) которой соответствует параметрически заданной прямой, а локальные максимумы в таком аккумуляторе соответствуют наиболее весомым прямым на карте границ.
Во многих случаях недостаточно одной лучшей прямой — ограничения не защитят нас от случайно попавшего в кадр стола/клавиатуры/всего-чего-угодно более длинного и контрастного, чем наш документ. Однако, хитрый план просто взять несколько наибольших значений в аккумуляторе обречён на провал: каждая прямая в действительности образует в аккумуляторе некоторую максимальную окрестность (см. рисунок ниже), и несколько первых максимумов, скорее всего, будут соответствовать приблизительно одной и той же прямой.
Поскольку наша цель не выяснить с огромной точностью расположение одной прямой, а набрать несколько достаточно разных, нам это не подходит.
А потому в боевой версии алгоритма имеет место такая итерационная процедура:
- Преобразование Хафа над картой границ
- Добавление лучшей прямой к ответу
- Если количество прямых меньше требуемого — затирание найденной прямой на карте границ и возврат к пункту 1
Каждую из полученных прямых снабдим весом — значением из соответствующей ячейки аккумулятора Хафа.
*Под быстрым преобразованием Хафа мы подразумеваем точную быструю реализацию, а не аппроксимацию преобразования.
 a) карта границ |
 b) аккумулятор БПХ |
| Пример работы БПХ. (А вы поняли, какой из прямых соответствует каждый из пиков на аккумуляторе?) |
Комбинаторная схема
После предыдущего шага у нас имеется 4 набора прямых — по одному для каждой стороны документа. Из этих прямых комбинаторным перебором составляем все возможные четырёхугольники, среди которых будем искать наиболее правдоподобный. В качестве начальной оценки С каждого из четырёхугольников возьмём сумму весов прямых, из которых он собран. Все последующие шаги посвящены корректировке этой оценки с учётом эмерджентных характеристик четырёхугольника.
Если прямые в соседних областях не обрываются в точке их пересечения, а продолжаются за неё, то весьма вероятно, что это не угол искомого объекта, а что-то другое. Разумеется, возможен случай, когда граница документа расположена вдоль некоторой прямой фона, и, кроме того, даже у настоящего угла в процессе обработки изображения может уползти несколько пикселей, но в целом это плохой признак. Такое «вылезание» прямых за угол будем штрафовать:

где pi — штраф для i-го угла, представляющий собой сумму интенсивностей первых n пикселей на карте границ за точкой пересечения вдоль прямых, образующих угол. -->
--> 
Пример для левого верхнего угла. Жёлтым обозначены штрафуемые области для горизонтальных прямых.
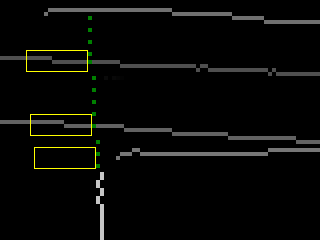
Далее, с использованием известного нам фокусного расстояния, для каждого из четырёхугольников восстановим параллелограмм [4] (единственный с точностью до гомотетии), проективным образом которого является этот четырёхугольник. Сравним соотношение сторон полученного параллелограмма с известным соотношением сторон искомого документа, а его углы — с прямыми углами, которыми документ, вроде бы, должен обладать. За отклонение этих параметров от предполагаемых также введём штрафы:
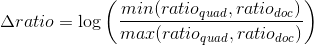
Тогда, если  :
:

где A, B, α, β — оптимизируемые коэффициенты,
Ta, Tr — пороговые значения.
Вот и всё. Четырёхугольник с наибольшим весом принимаем за месторасположение документа на изображении.
Результаты
Тестовая выборка для оценки качества состоит из 6000 фотографий документов на различном фоне и 6000 правильных четырёхугольников соответственно. Начальное разрешение изображений варьируется от 640×480 до 800×600. Тестовое устройство — iPhone 4S (фотографии были получены с него же и ужаты до указанных разрешений снаружи от описанного алгоритма).
Для оценки точности нахождения документа использовалась такая функция ошибки:
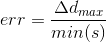
где ∆dmax — максимальное из расстояний между соответствующими углами истинных и найденных четырёхугольников,
min (s) — длина минимальной стороны истинного четырёхугольника.
Опытным путём выяснено, что для достаточно хорошего распознавания символов на обнаруженном документе при зонах сторон, занимающих по 30% от соответствующего размера, значение err должно быть меньше 0.06.
Общее качество работы алгоритма вычислялось как
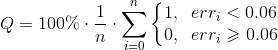
Согласно такой оценке, на тестовой выборке из 6000 изображений четырёхугольники документов находятся с качеством 98.5%.
Среднее время работы алгоритма на iPhone 4S — 0.043с (23.2FPS), из которых:
масштабирование — 0.014с,
поиск краёв — 0.023с,
поиск прямых — 0.005с,
перебор с отсечениями — 0.001с.
Литература
[1] S. Di Zenzo. A note on the gradient of a multi-image.
[2] J. Canny. A computational approach to edge detection.
[3] D.P. Nikolaev et al. Hough transform: underestimated tool in computer vision field.
[4] Z. Zhang. Whiteboard scanning and image enhancement.
