Поднимаем упрощенную провайдерскую сеть дома
 Изначально эта статья была дневником по лабораторной работе, которую я придумал сам для себя. Постепенно мне начало казаться, что данная информация может быть полезна кому-то еще. Поэтому я постарался преобразовать заметку в более-менее приличный вид, добавить описание некоторых команд и технологий.В статье рассматривается построение простейшей сети с несколькими провайдерами и клиентами, в частности, такие технологии, как NAT, OSPF, BGP, MPLS VPN. Многое, естественно, будет не учтено. Например в статье почти нет описания проблем безопасности, т.к. на эту тему можно говорить бесконечно, а текст и так получается довольно объемным. QoS тоже оставлен в стороне, т.к. в лабораторных условиях его особо не проверишь.
Изначально эта статья была дневником по лабораторной работе, которую я придумал сам для себя. Постепенно мне начало казаться, что данная информация может быть полезна кому-то еще. Поэтому я постарался преобразовать заметку в более-менее приличный вид, добавить описание некоторых команд и технологий.В статье рассматривается построение простейшей сети с несколькими провайдерами и клиентами, в частности, такие технологии, как NAT, OSPF, BGP, MPLS VPN. Многое, естественно, будет не учтено. Например в статье почти нет описания проблем безопасности, т.к. на эту тему можно говорить бесконечно, а текст и так получается довольно объемным. QoS тоже оставлен в стороне, т.к. в лабораторных условиях его особо не проверишь.
По поводу целевой аудитории. Совсем новичкам в сетях статья, боюсь, будет непонятна. Людям, обладающим знаниями хотя бы на уровне CCNP — неинтересна. Поэтому я примерно ориентируюсь на сертификацию CCNA R&S.Лабораторная построена на эмуляторе Cisco IOU. По поводу его установки и использования написано уже много чего, так что повторяться не буду.
Используются образы i86bi_linux-adventerprisek9-ms.152–4.M1 и i86bi_linux_l2-ipbasek9-ms.jan24–2013-B
Определимся с топологией и IP-адресацией.
После некоторых раздумий я решил сделать такую схему:  Теперь осталось придумать легенду:
Теперь осталось придумать легенду:
AS1234 — крупный провайдер ISP1. Владеет сетью 50.0.0.0/16. AS67 — провайдер ISP2. Владеет сетью 100.0.0.0/16. Нужен для внесения дополнительной сложности в топологию. AS812 — клиент Customer1. Владеет блоком PI-адресов IPv4 175.0.0.0/24, но внутри своей сети использует исключительно IPv6. AS65000 — клиент Customer2. Получает от провайдера блок адресов 50.0.109.0/24. Внутри сети использует приватные адреса из подсети 192.168.109.0/24. AS65000 — приватная. AS1114 — клиент Customer3. Владеет блоком PI-адресов 150.0.0.0/24. Их же и использует для внутренних нод. Для простоты на p2p линках между маршрутизаторами в разных AS будем использовать адреса вида 200.0.xy.0/24, где x, y — номера маршрутизаторов, x>y.p2p линки внутри провайдеров также будут иметь маску /24 (понятно, что это расточительство, но так будет значительно проще настраивать маршрутизацию) и вид 50.0.xy.0 (100.0.xy.0 для AS67), где x, y — номера маршрутизаторов, x>y.
Первоначальная настройкаБазовая конфигурация Для начала зальем на все маршрутизаторы примерно одинаковую конфигурацию (пример для R2): enable configure terminal Включаем aaa и настраиваем возможность заходить на маршрутизатор удаленно с локальными реквизитами: aaa new-model aaa authentication login default local username cisco privilege 15 secret cisco no ip domain-lookup Прописываем все необходимое для ssh v1.99 и разрешаем только его в параметрах линии: ip domain-name isp1.com hostname R2 crypto key generate rsa modulus 2048 line console 0 exec-timeout 0 line vty 0 4 transport input ssh exec-timeout 0 На каждом маршрутизаторе создадим несколько loopback’ов. lo0 для протоколов маршрутизации, остальные для имитации клиентских подключений, чтобы RIB не выглядела слишком маленькой. Понятно, что если провайдер владеет подсетью 50.0.0.0/16, он не имеет никакого права анонсировать, например, подсеть 2.0.0.0/24, но для наглядности мы сделаем допущение, что такая ситуация возможна: interface loopback 0 ip address 2.2.2.2 255.255.255.255 interface loopback 1 ip address 2.0.0.2 255.255.255.0 interface loopback 2 ip address 2.0.1.2 255.255.255.0 interface loopback 3 ip address 2.0.2.2 255.255.255.0 interface loopback 4 ip address 2.0.3.2 255.255.255.0 Присвоим адреса и отключим CDP на тех интерфейсах, которые смотрят не на соседний по AS маршрутизатор: interface ethernet 0/0 ip address 200.0.62.2 255.255.255.0 no cdp enable no shutdown interface ethernet 0/1 ip address 50.0.32.2 255.255.255.0 no shutdown interface ethernet 0/2 ip address 200.0.72.2 255.255.255.0 no cdp enable no shutdown interface ethernet 0/3 ip address 50.0.52.2 255.255.255.0 no shutdown
end
write
Теперь необходимо настроить наших клиентов.HSRP, Stateful NAT
Начнем с AS65000. Из нее подсеть 192.168.109.0/24 будет транслироваться в блок адресов 50.0.109.0/24, выданный провайдером. При этом автономная система подключена к одному ISP через два маршрутизатора, поэтому для обеспечения избыточности на них необходимо будет настроить HSRP. В связи с этим при использовании обычного NAT может возникнуть проблема ассиметричного роутинга: Приватный адрес транслируется в публичный на одном из маршрутизаторов.
Ответ приходит на второй маршрутизатор.
У второго маршрутизатора правило трансляции для данного пакета отсутствует, так что он просто отбросит пакет.
Для решения данной проблемы официальный сайт Cisco предлагает использовать Stateful NAT.
 Для начала настроим HSRP (конфиг на R10).У больших компаний редко бывает всего один VLAN, так что все настройки будем делать на сабинтерфейсе для 109 VLAN’а:
Для начала настроим HSRP (конфиг на R10).У больших компаний редко бывает всего один VLAN, так что все настройки будем делать на сабинтерфейсе для 109 VLAN’а:
Создаем HSRP группу:
R10(config)#interface ethernet 0/1.109 R10(config-subif)#encapsulation dot1Q 109 R10(config-subif)#ip address 192.168.109.10 255.255.255.0 R10(config-subif)#standby 109 ip 192.168.109.109 R10(config-subif)#standby 109 preempt R10(config-subif)#standby 109 name SNAT Сконфигурируем ACL и NAT pool для Stateful NAT точно так же, как и для обычного (длина маски 25, а не 24, т.к. решено было оставить половину подсети для других нужд, здесь не рассматриваемых): R10(config)#ip access-list standard SNAT_INSIDE R10(config-std-nacl)#permit 192.168.109.0 0.0.0.255 R10(config)#ip nat pool SNAT_OUTSIDE 50.0.109.1 50.0.109.126 prefix-length 25 Настроим непосредственно Stateful NAT: R10(config)#ip nat stateful id 109 R10(config-ipnat-snat)#redundancy SNAT R10(config-ipnat-snat-red)#protocol udp R10(config-ipnat-snat-red)#mapping-id 109 R10(config)#ip nat inside source list SNAT_INSIDE pool SNAT_OUTSIDE mapping-id 109 overload И включим его на интерфейсах: R10(config)#interface ethernet 0/0 R10(config-if)#ip nat outside
R10(config)#interface ethernet 0/1.109 R10(config-subif)#ip nat inside На eth 0/2 применим для того, чтобы в случае, если пакет придет на R10, а R5 не будет доступен, адрес все-таки транслировался и доходил до места назначения: R10(config)#interface ethernet 0/2 R10(config-if)#ip nat outside Можно сделать по другому — применить не ip nat outside на eth0/2 маршрутизатора R10, а ip nat inside на eth0/1 маршрутизатора R9. Результат будет абсолютно одинаковым, главное — понимать, зачем это делается и как работает.На R9 конфигурация аналогичная.
Конфигурация SW13 не приводится ввиду ее простоты. Интерфейсы, смотрящие на маршрутизаторы сделаем транками с инкапсуляцией в 109 VLAN. Также настроим интерфейс в 109 VLAN’e для проверки нашего решения.
После этого можно для теста поднять маршрутизацию на роутерах R3, R4, R5, R9 и R10 таким образом, чтобы пинг пошел по данному пути: 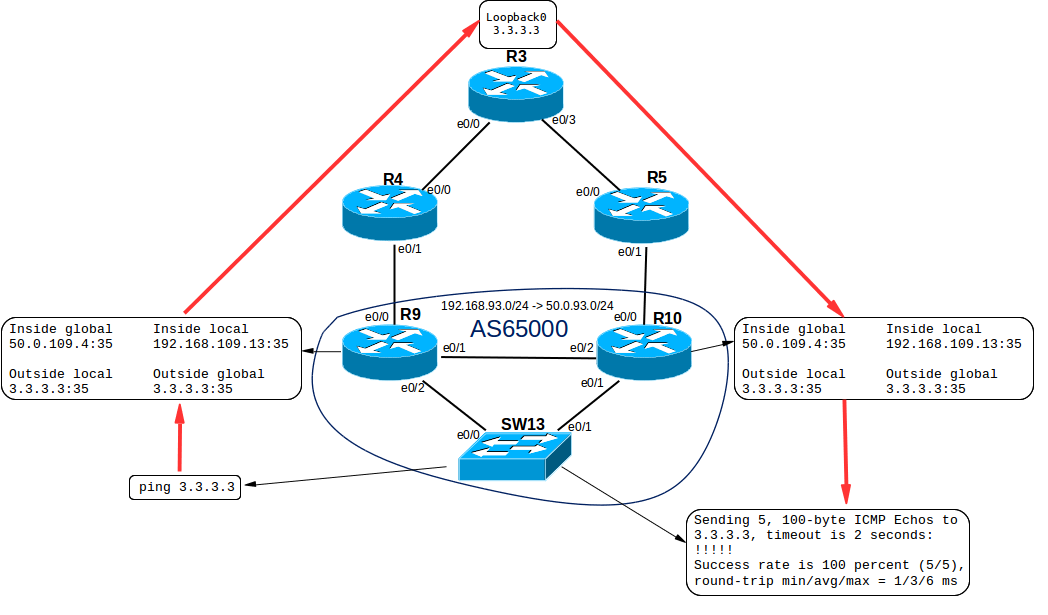
SW13#ping 3.3.3.3 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 3.3.3.3, timeout is 2 seconds: !!! Success rate is 100 percent (5/5), round-trip min/avg/max = ⅓/6 ms R9#sh ip nat translations Pro Inside global Inside local Outside local Outside global icmp 50.0.109.4:35 192.168.109.13:35 3.3.3.3:35 3.3.3.3:35 --- 50.0.109.4 192.168.109.13 --- --- R10#sh ip nat translations Pro Inside global Inside local Outside local Outside global icmp 50.0.109.4:35 192.168.109.13:35 3.3.3.3:35 3.3.3.3:35 --- 50.0.109.4 192.168.109.13 --- --- Как мы видим, информация синхронизировалась между двумя HSRP маршрутизаторами, и при ассиметричном роутинге пинг прошел обратно через тот маршрутизатор, который не осуществлял прямую трансляцию адреса.IPv6, NAT-PT Теперь обратимся к AS812. Напомним, что местные инженеры активно внедряют инновации, поэтому вся внутренняя сеть построена на протоколе IPv6. Тем не менее провайдер, к которому подключена данная компания даже не слышал про существование IPv6, поэтому придется использовать на пограничном маршрутизаторе NAT-PT (Protocol Translation).Данная технология, как это понятно из названия, позволяет осуществлять трансляцию из одного сетевого протокола в другой, и, соответственно, общаться хостам, поддерживающим только IPv6 или только IPv4, друг с другом.
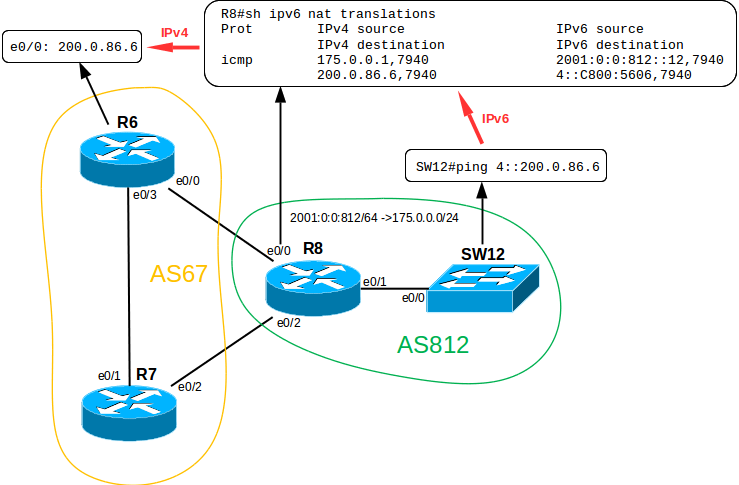 Если мы попробуем сделать это без трансляции, то получим примерно такое сообщение:
Если мы попробуем сделать это без трансляции, то получим примерно такое сообщение:
SW12#ping 200.0.86.6 % Unrecognized host or address, or protocol not running. Определимся с адресацией: предположим, что используется одна большая подсеть 2001:0:0:812::/64Тогда адрес интерфейса eth0/1 на R8 будет 2001:0:0:812::8/64.
Включаем маршрутизацию пакетов IPv6:
R8(config)#ipv6 unicast-routing Задаем IPv6 адрес: R8(config)#interface ethernet 0/1 R8(config-if)#ipv6 address 2001:0:0:812::8/64 Включаем NAT на интерфейсах: R8(config)#interface range eth 0/0–2 R8(config-if-range)#ipv6 nat Создаем пул IPv4, в который будут транслироваться наши внутренние IPv6 адреса: R8(config)#ipv6 nat v6v4 pool 6TO4 175.0.0.1 175.0.0.254 prefix-length 24 ACL, содержащий префикс, при вводе которого перед IPv4 адресом, мы сообщим маршрутизатору, что нам необходима трансляция: R8(config)#ipv6 access-list v6LIST R8(config-ipv6-acl)#permit ipv6 any 4::/96 Применяем этот ACL: R8(config)#ipv6 nat prefix 4::/96 v4-mapped v6LIST И, собственно, включаем NAT-PT: R8(config)#ipv6 nat v6v4 source list v6LIST pool 6TO4 overload Обратите внимание, что длина префикса составляет 96 бит. Если учесть, что суммарная длина IPv6 адреса 128 бит, получаем в остатке 32 бита, что равно длине IPv4 адреса.Проверяем. Временно создадим на R6 и на R8 необходимые маршруты и попробуем пропинговать R6 с коммутатора SW12:
SW12#ping 4::200.0.86.6 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 4:: C800:5606, timeout is 2 seconds: !!! Success rate is 100 percent (5/5), round-trip min/avg/max = 1/⅓ ms Как мы видим, технология работает. Для того, чтобы выделенная подсеть 175.0.0.0/24 не пропадала зря (все-таки крайне глупо покупать PI-адреса и использовать их только для динамического NAT’a) можно было бы сконфигурировать статические трансляции v6v4 и v4v6, чтобы, например, внутренний сервер имеющий адрес IPv6 был доступен из внешней сети по IPv4 адресу. Тем не менее этого мы делать не будем.Больше, в данный момент, у клиентов настраивать особо нечего, так что можно перейти к настройке маршрутизации.
OSPF, настройка маршрутизации внутри автономной системы
Начнем с IGP, в частности с протокола OSPF. EIGRP рассматривать не будем, т.к. на таких небольших сетях принципиальных отличий в конфигурации немного.В сети провайдера ISP1 все роутеры кроме R1 соединены по принципу «каждый с каждым». Так как R1 подключен только одним линком, имеет смысл вынести его в отдельную totally stubby area (т.е. отдавать R1 только маршрут по умолчанию на R3).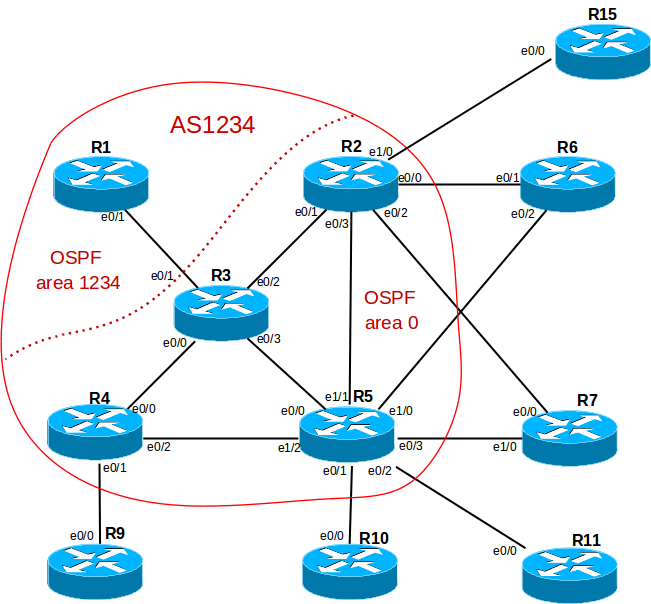 Приведем пример настройки OSPF на R3:
Приведем пример настройки OSPF на R3:
R3(config)#router ospf 1234 R3(config-router)#router-id 3.3.3.3 По умолчанию запретим всем интерфейсам участвовать в OSPF процессе, а затем включим только нужные (конкретно на R3 данные команды не имеют абсолютно никакого смысла, т.к. все его интерфейсы будут задействованы): R3(config-router)#passive-interface default R3(config-router)#no passive interface e0/1 R3(config-router)#no passive interface e0/2 R3(config-router)#no passive interface e0/3 R3(config-router)#no passive interface e0/4 Следующая команда дает возможность при изменении карты сети запускать процесс SPF только частично, для отдельной ветви дерева, что в больших сетях может несколько уменьшить время сходимости топологии: R3(config-router)#ispf Добавляем сеть в тупиковый регион и конфигурируем сам регион: R3(config-router)#network 50.0.31.0 0.0.0.255 area 1234 R3(config-router)#area 1234 stub no-summary Добавляем подсети из магистрального региона: R3(config-router)#network 50.0.32.0 0.0.0.255 area 0 R3(config-router)#network 50.0.43.0 0.0.0.255 area 0 R3(config-router)#network 50.0.53.0 0.0.0.255 area 0 Можно, конечно, анонсировать и так: R3(config-router)#network 50.0.0.0 0.0.255.255 area 0 но: Есть шанс случайно захватить лишнюю подсеть; При удалении одной из суммаризованных подсетей могут возникнуть проблемы; Это в принципе дает меньше контроля над ситуацией и повышает риск ошибки. Также можно объявлять принадлежность подсети к процессу ospf непосредственно на интерфейсе (и это единственный путь в IPv6), но используемый мной способ банально быстрее (на мой взгляд), да и нагляднее, когда вся конфигурация, связанная с определенным протоколом хранится в одном месте.Сети с loopback’ов добавим командой redistribute connected. Делать это надо аккуратно, потому что всегда есть риск объявить что-то, что объявлять бы не хотелось. Поэтому воспользуемся route-map’ом, чтобы установить четкие ограничения:
R3(config)#ip access-list standard REDISTRIBUTE_CONNECTED R3(config-std-nacl)#permit host 3.3.3.3 R3(config-std-nacl)#permit 3.0.0.3 0.0.0.255 R3(config-std-nacl)#permit 3.0.1.3 0.0.0.255 R3(config-std-nacl)#permit 3.0.2.3 0.0.0.255 R3(config-std-nacl)#permit 3.0.3.3 0.0.0.255 R3(config)#route-map REDISTRIBUTE_CONNECTED R3(config-route-map)#match ip address REDISTRIBUTE_CONNECTED
R3(config-router)#redistribute connected route-map REDISTRIBUTE_CONNECTED subnets Вообще route-map — крайне гибкая и удобная технология, которая позволяет творить с подсетями практически все что угодно: суммаризовать, вешать различные теги, метки, менять всевозможные параметры, пути следования пакетов, etc. В секции про настройку BGP я затрону route-map’ы чуть более детально.Остановимся подробнее на том, чем еще выделяется команда redistribute:
R5(config)#do sh ip route ----------------------------------------------------------------- 3.0.0.0/8 is variably subnetted, 5 subnets, 2 masks O E2 3.0.0.0/24 [110/20] via 50.0.53.3, 00:19:17, Ethernet0/0 O E2 3.0.1.0/24 [110/20] via 50.0.53.3, 00:19:07, Ethernet0/0 O E2 3.0.2.0/24 [110/20] via 50.0.53.3, 00:19:07, Ethernet0/0 O E2 3.0.3.0/24 [110/20] via 50.0.53.3, 00:19:07, Ethernet0/0 O E2 3.3.3.3/32 [110/20] via 50.0.53.3, 00:19:37, Ethernet0/0 ----------------------------------------------------------------- O 50.0.32.0/24 [110/20] via 50.0.53.3, 00:21:43, Ethernet0/0 O 50.0.43.0/24 [110/20] via 50.0.53.3, 00:21:43, Ethernet0/0 Если мы внимательно посмотрим на таблицу маршрутизации, то увидим, что подсети, созданные командой redistribute connected помечены, как внешние для этой AS маршруты, в отличие от тех, которые добавлены командой network. Соответственно R3 становится ASBR (Autonomous System Boundary Router), хотя по факту им не является.Также при типе маршрута E2 (а данная метка ставится по умолчанию) метрика не будет пересчитываться, как это обычно происходит в процессе SPF (то есть при увеличении длины пути до подсети стоимость линков учитываться не будет).
Избежать этого можно так:
R3(config-router)#redistribute connected route-map REDISTRIBUTE_CONNECTED subnets metric-type 1 Вернемся к R1. После конфигурации area 1234 как totally stubby в таблице маршрутизации мы увидим только один маршрут, пришедший по OSPF. Как и ожидалось — это default gateway: R1(config-router)#do sh ip route -------------------------------------------------------------- Gateway of last resort is 50.0.31.3 to network 0.0.0.0
O*IA 0.0.0.0/0 [110/11] via 50.0.31.3, 00:00:00, Ethernet0/1 ------------------------------------------------------------- Все остальные маршрутизаторы в лабораторной настраиваются примерно одинаково, так что нет смысла заострять на них внимание.BGP, настройка маршрутизации между автономными системами Недавно на собеседовании в одном крупном и известном интеграторе мне задали вопрос: «Зачем вообще нужны IGP, когда у нас есть iBGP?». Ответ про ужасную скорость сходимости протокола по сравнению с IGP, необходимость топологии full-mesh (или Route Reflector), повышенные требования к ресурсам каждого маршрутизатора в топологии их не удовлетворил.Только выйдя из переговорной я вспомнил, что BGP не будет помещать в RIB маршруты, для которых next-hop недоступен.
Соответственно, без IGP с внутренних маршрутизаторов мы не сможем достучаться до next-hop (который, как правило, является адресом eBGP пира, не присоединенного непосредственно) и маршрутизации у нас не получится. Думаю, что от меня хотели услышать именно это. К слову, должность мне все-таки предложили, но это уже совсем другая история.
Теперь еще немного про отношения соседства. Вообще-то, по-хорошему, стоило бы устанавливать отношения между eBGP пирами с помощью их loopback-адресов. Тем не менее, у нас нет в этом острой необходимости. Каждый маршрутизатор соединен с каждым не более чем одним линком, соответственно на отказоустойчивость это не повлияет.
Для того, чтобы достучаться до соседнего loopback для eBGP пиров нам бы потребовались следующие действия:
Static route на loopback соседа;
redistribute static в OSPF (можно обойтись без этого, если на всех iBGP пирах делать команду next-hop self, но мне как-то не очень нравится так делать);
Команда neighbor n.n.n.n ebgp-multihop 2 для того, чтобы увеличить ttl служебных BGP пакетов (по умолчанию равен 1);
Команда neighbor n.n.n.n update-source lo0.
Чтобы сократить конфигурацию будем использовать: loopback адреса для коммуникации между iBGP пирами (это действительно имеет смысл, т.к. даже при падении одного из линков TCP-сессия останется живой благодаря избыточным соединениям);
адреса на физических интерфейсах для eBGP пиров
.Настроим BGP в автономной системе 1234.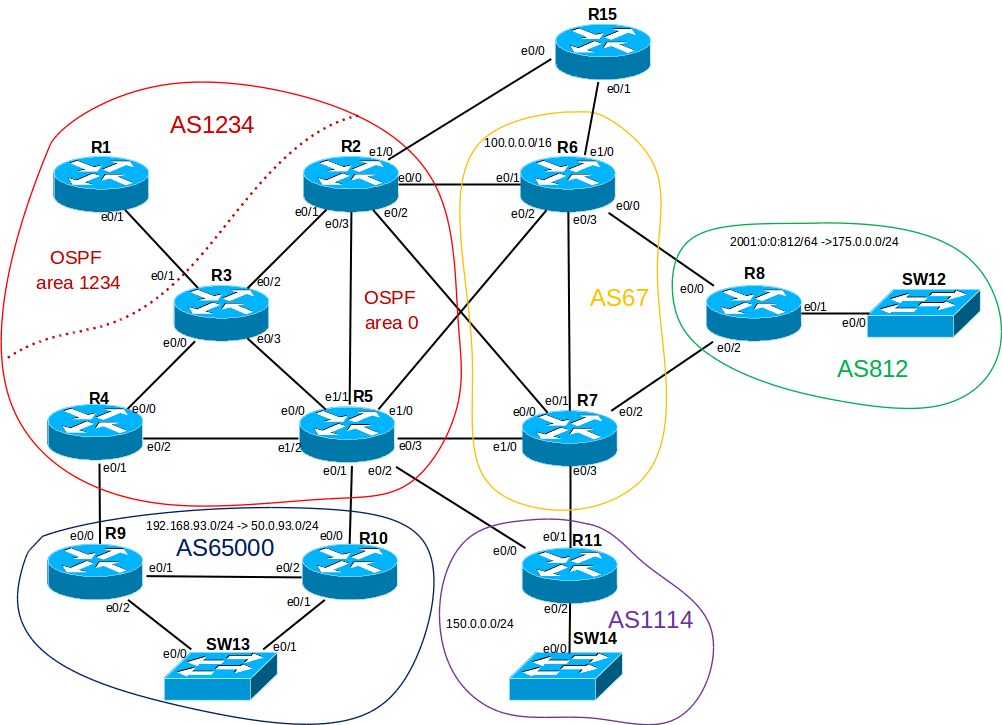 Для начала небольшой чек-лист: prefix-list, фильтрующий приватные сети;
prefix-list, фильтрующий p2p-линки;
prefix-list, фильтрующий адреса на lo0;
prefix-list, фильтрующий адреса, анонсируемые соседней AS;
route-map для соседа;
route-map для анонса connected сетей (если вдруг мы не захотим анонсировать их командой network);
непосредственно конфигурация BGP;
Атрибут community использовать не будем. В данном случае сеть небольшая, пиринговых войн не предвидится, DDOS получить неоткуда, поэтому путаницы от community, на мой взгляд, будет больше, чем пользы.Зачем вообще мы делаем фильтрацию? Затем, что если клиент неадекватен и вдруг решит анонсировать все, что ему захочется (в нашем случае AS65000 попробует поступить именно так), провайдер ОБЯЗАН пресечь данные действия со своей стороны.
Для начала небольшой чек-лист: prefix-list, фильтрующий приватные сети;
prefix-list, фильтрующий p2p-линки;
prefix-list, фильтрующий адреса на lo0;
prefix-list, фильтрующий адреса, анонсируемые соседней AS;
route-map для соседа;
route-map для анонса connected сетей (если вдруг мы не захотим анонсировать их командой network);
непосредственно конфигурация BGP;
Атрибут community использовать не будем. В данном случае сеть небольшая, пиринговых войн не предвидится, DDOS получить неоткуда, поэтому путаницы от community, на мой взгляд, будет больше, чем пользы.Зачем вообще мы делаем фильтрацию? Затем, что если клиент неадекватен и вдруг решит анонсировать все, что ему захочется (в нашем случае AS65000 попробует поступить именно так), провайдер ОБЯЗАН пресечь данные действия со своей стороны.
Пойдем по списку. Для примера будем настраивать R4:
1) Т.к. это всего лишь лабораторная, будем фильтровать не все сети, а только 3 самых известных (существует еще куча зарезервированных под разные нужды префиксов, например 127.0.0.0/8):
R4(config)#ip prefix-list PRIVATE_IP permit 10.0.0.0/8 le 32 R4(config)#ip prefix-list PRIVATE_IP permit 172.16.0.0/12 le 32 R4(config)#ip prefix-list PRIVATE_IP permit 192.168.0.0/16 le 32 2) p2p линки между маршрутизаторами внутри автономной системы, на мой взгляд, информация, которую незачем оглашать, так что лучше оставим ее внутри AS: R4(config)#ip prefix-list P2P permit 50.0.31.0/24 le 32 R4(config)#ip prefix-list P2P permit 50.0.32.0/24 le 32 R4(config)#ip prefix-list P2P permit 50.0.43.0/24 le 32 R4(config)#ip prefix-list P2P permit 50.0.52.0/24 le 32 R4(config)#ip prefix-list P2P permit 50.0.53.0/24 le 32 R4(config)#ip prefix-list P2P permit 50.0.54.0/24 le 32 3) Наши lo0 адреса также не должны маршрутизироваться, т.к. таким образом мы можем навредить реальному хосту 1.1.1.1, или, например, сделать недоступным DNS-сервер google с адресом 8.8.8.8 (на самом деле не можем, уже давно все провайдеры фильтруют сети с маской /25 и больше). R4(config)#ip prefix-list LOOPBACK permit 1.1.1.1/32 R4(config)#ip prefix-list LOOPBACK permit 2.2.2.2/32 R4(config)#ip prefix-list LOOPBACK permit 3.3.3.3/32 R4(config)#ip prefix-list LOOPBACK permit 4.4.4.4/32 R4(config)#ip prefix-list LOOPBACK permit 5.5.5.5/32 4) Наша соседняя AS65000 транзитной не является, следовательно не может анонсировать ничего, кроме выданной ей подсети 50.0.109.0/24. Проконтролируем это: R4(config)#ip prefix-list ADVERTISED permit 50.0.109.0/24 le 32 На этом закончим с фильтрацией. Я никогда (на момент написания этой части статьи) не работал в ISP, но у меня есть очень сильное подозрение, что у них в BGP фильтруется в несколько раз больше маршрутов, и цели для этого могут быть самыми разными.5) Пришло время настроить route-map. Так как в префикс листах мы писали «permit», сейчас мы будем писать «deny».
Фильтрация исходящего трафика:
R4(config)#route-map AS65000_OUT deny 10 R4(config-route-map)#match ip address prefix-list LOOPBACK R4(config-route-map)#match ip address prefix-list P2P R4(config-route-map)#match ip address prefix-list PRIVATE_IP
R4(config)#route-map AS65000_OUT permit 20 Фильтрация входящего трафика: R4(config)#route-map AS65000_IN R4(config-route-map)#match ip address prefix-list ADVERTISED
R4(config)#route-map AS65000_IN deny 20 6) На R4 будем добавлять connected сети 4.0.0.0/24 — 4.0.3.0/24 суммаризованными в одну подсеть 4.0.0.0/22. Сделать это можно несколькими способами, покажем один из них: R4(config)#ip access-list standard REDISTRIBUTE_CONNECTED R4(config-std-nacl)#permit 4.0.0.0 0.0.3.255
R4(config)#route-map REDISTRIBUTE_CONNECTED R4(config-route-map)#match ip address REDISTRIBUTE_CONNECTED
R4(config-route-map)#router bgp 1234 R4(config-router)#redistribute connected route-map REDISTRIBUTE_CONNECTED На этом этапе мы получаем такой вывод #sh ip bgp: R4(config-router)#do sh ip bgp ------------------------------------------------------------------- Network Next Hop Metric LocPrf Weight Path *> 4.0.0.0/24 0.0.0.0 0 32768? *> 4.0.1.0/24 0.0.0.0 0 32768? *> 4.0.2.0/24 0.0.0.0 0 32768? *> 4.0.3.0/24 0.0.0.0 0 32768? Теперь делаем R4(config-router)#aggregate-address 4.0.0.0 255.255.252.0 summary-only и видим следующий вывод: R4(config-router)#do sh ip bgp ------------------------------------------------------------------- Network Next Hop Metric LocPrf Weight Path s> 4.0.0.0/24 0.0.0.0 0 32768? *> 4.0.0.0/22 0.0.0.0 32768 i s> 4.0.1.0/24 0.0.0.0 0 32768? s> 4.0.2.0/24 0.0.0.0 0 32768? s> 4.0.3.0/24 0.0.0.0 0 32768? Все маршруты, кроме суммарного, помечены буквой «s» — suppressed, что значит подавленные. Анонсироваться они не будут. Если бы мы по каким то причинам ввели команду aggregate-address без ключевого слова summary-only, то анонсировались бы и суммаризованная подсеть, и каждая из /24 по отдельности.7) Пришло время непосредственной настройки процесса BGP, установления соседских отношений и конфигурации прочих параметров, описывающих общий характер работы протокола:
R4(config)#router bgp 1234 R4(config-router)#bgp router-id 4.4.4.4
R4(config-router)#neighbor 3.3.3.3 remote-as 1234 R4(config-router)#neighbor 3.3.3.3 update-source lo0
R4(config-router)#neighbor 5.5.5.5 remote-as 1234 R4(config-router)#neighbor 5.5.5.5 update-source lo0
R4(config-router)#neighbor 200.0.94.9 remote-as 65000 Применим ранее сконфигурированные route-map на соседа: R4(config-router)#neighbor 200.0.94.9 route-map AS65000_IN in R4(config-router)#neighbor 200.0.94.9 route-map AS65000_OUT out Теперь настало время настроить R3.
Пропустим все пункты про фильтрацию, т.к. у R3 нет eBGP пиров. Вместо этого сконфигурируем R3 как Route Reflector. Дело в том, что iBGP пиры при получении маршрута не отправляют его дальше. Таким образом у нас обязательно должна быть full-mesh топология, чтобы, например, R4 мог получить маршруты с R2.
Посмотрев на нашу топологию можно заметить, что до full-mesh она немного не дотягивает. Поэтому придется использовать Route Reflector, чтобы все iBGP пиры выучили все iBGP маршруты.
Так как соседей у нас целых 3, имеет смысл конфигурировать их с помощью peer-group:
R3(config-router)#neighbor LOCAL peer-group R3(config-router)#neighbor LOCAL remote-as 1234
R3(config-router)#neighbor 2.2.2.2 peer-group LOCAL R3(config-router)#neighbor 4.4.4.4 peer-group LOCAL R3(config-router)#neighbor 5.5.5.5 peer-group LOCAL
R3(config-router)#neighbor LOCAL update-source lo0 Настроим номер группы для Route Reflector (следует уделять этому особое внимание, если кластеров планируется сделать несколько): R3(config-router)#bgp cluster-id 1 И сделаем всех наших соседей клиентами: R3(config-router)#neighbor LOCAL route-reflector-client Обратите внимание, что на самих клиентах настраивать ничего не нужно, достаточно указать RR-соседа как обычный iBGP пир.Также покажем на R3 второй способ суммаризации подсетей.
Создаем суммарный маршрут на null 0 (напомним, что если маршрута нет в RIB, BGP не будет анонсировать его):
R3(config)#ip route 3.0.0.0 255.255.252.0 null 0 И просто добавляем его в BGP: R3(config-router)#network 3.0.0.0 mask 255.255.252.0 Как мы видим, суммаризованная сеть присутствует в таблице BGP и анонсируется. Также мы уже получили от R4 его суммаризованную сеть 4.0.0.0/22: R3(config-router)#do sh ip bgp ------------------------------------------------------------------- Network Next Hop Metric LocPrf Weight Path *> 3.0.0.0/22 0.0.0.0 0 32768 i *>i 4.0.0.0/22 4.4.4.4 0 100 0 i Какой способ суммаризации лучше — судить не мне, но тот, который мы применяли на R4 однозначно гибче в настройке, поэтому я предпочитаю использовать именно его.Как мы помним R1 соединен только с R3 и не использует BGP, так что на R3 нам надо анонсировать и сеть 50.0.254.0/24 с R1, чтобы она тоже была доступна. Сделаем это самым простым образом:
R3(config-router)#network 50.0.254.0 mask 255.255.255.0 Казалось бы все должно пройти отлично, маршрут анонсируется, но посмотрим на R4: R4(config-router)#do sh ip bgp Network Next Hop Metric LocPrf Weight Path ------------------------------------------------------------------- r>i 50.0.254.0/24 50.0.31.1 20 100 0 i ------------------------------------------------------------------- Мы поймали RIB-failure. На самом деле абсолютно ничего страшного не случилось. Есть несколько причин по которым может появиться RIB-failure. В данном случае это произошло потому, что в RIB на R4 уже есть маршрут с лучшей AD (полученный через OSPF) до данного префикса. Будет ли этот маршрут анонсироваться в другие AS? Ответ — да, будет, волноваться не о чем.Например на R9 (если предположить, что BGP там уже настроен):
R9(config)#do sh ip bgp --------------------------------------------------------------------- Network Next Hop Metric LocPrf Weight Path *> 3.0.0.0/22 200.0.94.4 0 1234 i *> 4.0.0.0/22 200.0.94.4 0 0 1234 i *> 50.0.109.0/24 0.0.0.0 0 32768 i *> 50.0.254.0/24 200.0.94.4 0 1234 i --------------------------------------------------------------------- Кстати говоря, раз уж получилось так, что BGP на R9 уже работает, попробуем чисто ради интереса проанонсировать серую подсеть 192.168.109.0/24 и посмотреть, отработает ли фильтрация на R4: R4#debug ip bgp 200.0.94.9 updates R9(config-router)#network 192.168.109.0 mask 255.255.255.0 R4# *Nov 28 22:13:31.004: BGP (0): 200.0.94.9 rcvd UPDATE w/ attr: nexthop 200.0.94.9, origin i, metric 0, merged path 65000, AS_PATH *Nov 28 22:13:31.004: BGP (0): 200.0.94.9 rcvd 192.168.109.0/24 — DENIED due to: route-map; Как мы видим, R4 попытался получить обновление, но route-map отработал как надо.К слову, на R9 и R10 ничего фильтровать не будем, переложим эти заботы на провайдера. Предположим, что местные инженеры не обладают достаточной квалификацией (на самом деле мне просто лень, к тому же я обещал, что AS65000 особой адекватностью отличаться не будет).
На R5 и R2 добавим еще одну необходимую нам команду в стандартную конфигурацию BGP:
R5(config-router)#neighbor 200.0.115.11 remove-private-as Таким образом мы уберем из анонса приватную AS. Посмотрим, как теперь будет выглядеть путь к подсети 50.0.109.0/24 (префикс из приватной AS 65000) для маршрутизатора R11: R11(config-router)#do sh ip bgp --------------------------------------------------------------------- Network Next Hop Metric LocPrf Weight Path *> 3.0.0.0/22 200.0.115.5 0 1234 i *> 4.0.0.0/22 200.0.115.5 0 1234 i *> 5.0.0.0/24 200.0.115.5 0 0 1234 i *> 5.0.1.0/24 200.0.115.5 0 0 1234 i *> 5.0.2.0/24 200.0.115.5 0 0 1234 i *> 5.0.3.0/24 200.0.115.5 0 0 1234 i *> 50.0.109.0/24 200.0.115.5 0 1234 i *> 50.0.254.0/24 200.0.115.5 0 1234 i --------------------------------------------------------------------- В столбце path для интересующего нас префикса указана только одна AS — 1234, следовательно наша задумка удалась, и приватная AS65000 не отображается.Кстати говоря, фильтрация на R11 просто жизненно необходима. Дело в том, что AS1114 подключена сразу к двум ISP, но транзитной не является (судя по вики такие AS называются многоинтерфейсными). Поэтому, если вдруг какой-то трафик, не относящийся к этой AS пройдет через нее, плохо будет всем:
провайдерам, т.к. каналы скорее всего имеют не очень большую пропускную способность, следовательно часть пакетов будет теряться; компании владеющей AS, т.к. ее аплинки будут забиты чужим, абсолютно неинтересным ей трафиком. Как делать фильтрацию на R11 показывать не буду, концептуально этот процесс не отличается от уже описанного. Скажу только, что там будет присутствовать такая команда: R11(config)#ip prefix-list OUTBOUND permit 150.0.0.0/24 le 32 Немного по поводу того, почему везде используются префикс-листы, а не ACL: Одним префикс-листом мы можем отфильтровать сразу все подсети данной сети (например команда чуть выше фильтрует не только /24 маску, но и всевозможные /25, /26, etc…); Я смутно помню, как читал статью, где рассказывалось, что у prefix-list древовидная структура в отличие от ACL, соответственно маршрутизатору требуется несколько меньше ресурсов для лукапа (возможно неправда, полагаюсь на память, статью найти не могу). Честно говоря, мне очень надоело полноценно конфигурировать BGP на каждом маршрутизаторе, так что на всех остальных настройки будут такими, чтобы поднялось и маршрутизировало (предупреждаю на случай, если где-то в дальнейшем это всплывет).При полностью настроенной маршрутизации sh ip bgp на R8 выглядит так:
sh ip bgp R8(config-router)#do sh ip bgp ------------------------------------------------------------------------ Network Next Hop Metric LocPrf Weight Path * 2.0.0.0/24 200.0.87.7 0 67 1234 i *> 200.0.86.6 0 67 1234 i * 2.0.1.0/24 200.0.87.7 0 67 1234 i *> 200.0.86.6 0 67 1234 i * 2.0.2.0/24 200.0.87.7 0 67 1234 i *> 200.0.86.6 0 67 1234 i * 2.0.3.0/24 200.0.87.7 0 67 1234 i *> 200.0.86.6 0 67 1234 i * 3.0.0.0/22 200.0.87.7 0 67 1234 i *> 200.0.86.6 0 67 1234 i * 4.0.0.0/22 200.0.87.7 0 67 1234 i *> 200.0.86.6 0 67 1234 i * 5.0.0.0/24 200.0.87.7 0 67 1234 i *> 200.0.86.6 0 67 1234 i * 5.0.1.0/24 200.0.87.7 0 67 1234 i *> 200.0.86.6 0 67 1234 i * 5.0.2.0/24 200.0.87.7 0 67 1234 i *> 200.0.86.6 0 67 1234 i * 5.0.3.0/24 200.0.87.7 0 67 1234 i *> 200.0.86.6 0 67 1234 i * 6.0.0.0/24 200.0.87.7 0 67 i *> 200.0.86.6 0 0 67 i * 6.0.1.0/24 200.0.87.7 0 67 i *> 200.0.86.6 0 0 67 i * 6.0.2.0/24 200.0.87.7 0 67 i *> 200.0.86.6 0 0 67 i * 6.0.3.0/24 200.0.87.7 0 67 i *> 200.0.86.6 0 0 67 i * 7.0.0.0/24 200.0.87.7 0 0 67 i *> 200.0.86.6 0 67 i * 7.0.1.0/24 200.0.87.7 0 0 67 i *> 200.0.86.6 0 67 i * 7.0.2.0/24 200.0.87.7 0 0 67 i *> 200.0.86.6 0 67 i * 7.0.3.0/24 200.0.87.7 0 0 67 i *> 200.0.86.6 0 67 i * 50.0.109.0/24 200.0.87.7 0 67 1234 i *> 200.0.86.6 0 67 1234 i * 50.0.254.0/24 200.0.87.7 0 67 1234 i *> 200.0.86.6 0 67 1234 i * 100.0.0.0/16 200.0.87.7 0 0 67 i *> 200.0.86.6 0 67 i * 150.0.0.0/24 200.0.87.7 0 67 1114 i *> 200.0.86.6 0 67 1114 i *> 175.0.0.0/24 0.0.0.0 0 32768 i Как мы видим, R8 держит на себе два местных full view (был бы настоящий интернет — был бы настоящий full view).Проверяя связность я был несколько удивлен этим:
SW12#ping 4::3.0.0.3 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 4::300:3, timeout is 2 seconds: !.!.! Success rate is 60 percent (3/5), round-trip min/avg/max = ½/4 ms Описание и решение здесь.Я пошел на крайние меры и выключил CEF на R8 (никогда так не делайте). Ситуация исправилась:
SW12#ping 4::3.0.0.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 4::300:3, timeout is 2 seconds:
!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/⅓ ms
MPLS VPN
Про MPLS будет сказано не так много, как хотелось бы. Мы просто настроим его и попробуем запустить L2 и L3 VPN. Для этих целей задействуем ранее остававшийся в стороне маршрутизатор R15.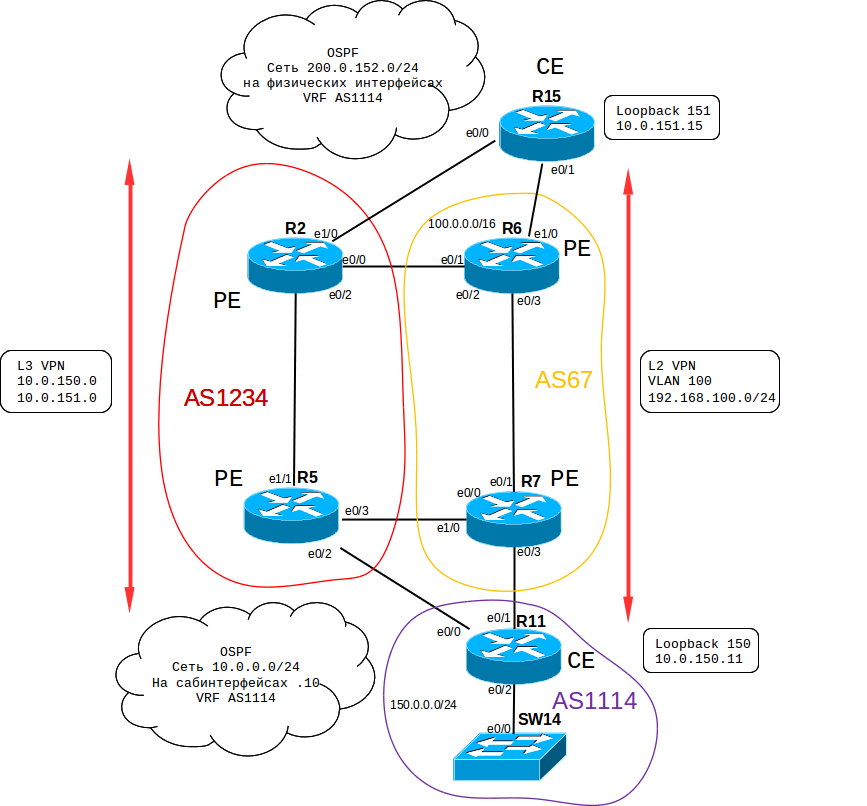 Для начала базовые (самые базовые, только чтобы заработало) настройки MPLS на маршрутизаторах (в AS67 у нас нет P (Provider) устройств, только PE (Provider Edge), чего вполне достаточно для демонстрации VPN). Конфигурацию покажу только на одной стороне (R7 и R11), на другой все то же самое: Включаем MPLS на интерфесах, на которых работает OSPF:
Для начала базовые (самые базовые, только чтобы заработало) настройки MPLS на маршрутизаторах (в AS67 у нас нет P (Provider) устройств, только PE (Provider Edge), чего вполне достаточно для демонстрации VPN). Конфигурацию покажу только на одной стороне (R7 и R11), на другой все то же самое: Включаем MPLS на интерфесах, на которых работает OSPF:
R7(config)#router ospf 67 R7(config-router)#mpls ldp autoconfig
R7(config)#mpls ldp router-id loopback 0 Настраиваем диапазон используемых меток: R7(config)#mpls label range 700 799 Включаем MPLS глобально: R7(config)#mpls ip Тут про MPLS VPN написано лучше, чем у меня, но я все-таки повторю процесс настройки.Через AS67 мы пробросим L2VPN R11 ↔ R15 Для начала надо сконфигурировать VLAN для проброса на R11 и R15: R11(config)#bridge irb R11(config)#bridge 100 protocol ieee R11(config)#bridge 100 bridge ip R11(config)#bridge 100 route ip
R11(config)#int bvi 100 R11(config-if)#ip address 192.168.100.11 255.255.255.0
R11(config)#int eth0/2.100 R11(config-subif)#encapsulation dot1Q 100 R11(config-subif)#bridge-group 100
R11(config)#int eth 0/1.100 R11(config-subif)#encapsulation dot1Q 100 R11(config-subif)#bridge-group 100 А теперь ввести всего несколько команд на PE: R7(config)#int eth 0/3.100 R7(config-subif)#encapsulation dot1Q 100 R7(config-subif)#xconnect 6.6.6.6 100 encapsulation mpls R7(config-subif)#mpls ip Все, L2 связность между VLAN 100 за R11 и R15 поднята. Проверим: SW14#ping 192.168.100.15 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 192.168.100.15, timeout is 2 seconds: !!! Success rate is 100 percent (5/5), round-trip min/avg/max = ½/8 ms Через AS1234 мы пробросим L3VPN R11 ↔ R15 Настройки, в целом, несколько сложнее чем для L2 VPN, но, по большому счету, ничего особого в них нет: Настраиваем L3VPN только на PE и CE (Customer Edge) маршрутизаторах (трогать P не требуется).
Для проверки маршрутизации создадим приватную подсеть 10.0.150.0/24 на R11 и сеть 10.0.151.0/24 на R15. Наша задача — получить рабочий пинг с Loopback 150 на R11 до Loopback 151 на R15.
Во-первых, необходимо настроить стык PE-CE:
Использовать будем подсеть 10.0.0.0/24 (сконфигурируем на сабинтерфейсах, т.к. в дальнейшем мы привяжем их к VRF, и после этого, если поднимать на физике, понадобится более глобально перенастраивать BGP и переносить соседа в данный VRF).
На CE все просто:
R11(config)#router ospf 150 R11(config-router)#network 10.0.0.5 0.0.0.255 area 0 R11(config-router)#network 10.0.150.0 0.0.0.255 area 0 А на PE нам потребуется создавать отдельный клиентский VRF (виртуальная сущность, имитирующая отдельный маршрутизатор с собственной таблицей маршрутизации, интерфейсами, etc…): R5(config)#ip vrf AS1114 R5(config-vrf)#rd 1234:1 R5(config-vrf)#route-target export 1234:1 R5(config-vrf)#route-target import 1234:1 Также есть необходимость подкрутить BGP: R5(config-router)#address-family vpnv4 R5(config-router-af)#neighbor 2.2.2.2 activate R5(config-router-af)#neighbor 2.2.2.2 send-community both R5(config-router-af)#exit-address-family Теперь на PE создадим процесс OSPF в клиентском VRF: R5(config)#router ospf 150 vrf AS1114 увидим это: *Nov 29 13:29:51.725: %OSPF-4-NORTRID: OSPF process 150 failed to allocate unique router-id and cannot start и присвоим процессу router-id: R5(config-router)#router-id 10.0.0.5 Добавляем необходимую нам сеть: R5(config-router)#network 10.0.0.0 0.0.0.255 area 0 и связываем BGP с OSPF: R5(config)#router bgp 1234 R5(config-router)#address-family ipv4 vrf AS1114 R5(config-router-af)#redistribute ospf 150 R5(config-router-af)#exit-address-family
R5(config)#router ospf 150 vrf AS1114 R5(config-router)#redistribute bgp 1234 subnets Привязываем интерфейс к VRF: R5(config-subif)#ip vrf forwarding AS1114 И видим, что надо пересоздать ip-адрес на интерфейсе: % Interface Ethernet0/2.10 IPv4 disabled and address (es) removed due to enabling VRF AS1114
R5(config-subif)#ip add 10.0.0.5 255.255.255.0 Теперь то же самое на другой паре PE-CE. Единственное отличие — на R15 нет BGP, так что мы можем не создавать сабинтерфейсы для разных VRF, а делать все в одном физическом. В текущей конфигурации это будет работать.Когда все будет готово, можем посмотреть RIB на R15:
R15(config)#do sh ip route ospf ----------------------------------------------------------------------- O E2 10.0.150.11/32 [110/11] via 200.0.152.2, 00:02:26, Ethernet0/0 O E2 200.0.115.0/24 [110/1] via 200.0.152.2, 00:02:26, Ethernet0/0 ----------------------------------------------------------------------- Мы видим, что маршруты через L3 VPN поднялись и доступны: R15(config)#do ping 10.0.150.11 source 10.0.151.15 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 10.0.150.11, timeout is 2 seconds: Packet sent with a source address of 10.0.151.15 !!! Success rate is 100 percent (5/5), round-trip min/avg/max = ½/5 ms Loopback адрес на R11 пингуется с R15 (и наоборот), значит цель достигнута.Кстати говоря, шифровать трафик здесь необходимо. Я попробовал зайти telnet’ом с R11 на R15 и с помощью Wireshark на линке R2 ↔ R5 легко нашел пару логин/пароль и все введенные конфигурационные команды.
Конфигурация BGP на R5 в данный момент выглядит таким образом:
sh run | sec bgp R5(config-subif)#do sh run | sec bgp router bgp 1234 bgp router-id 5.5.5.5 bgp log-neighbor-changes neighbor 2.2.2.2 remote-as 1234 neighbor 2.2.2.2 update-source Loopback0 neighbor 3.3.3.3 remote-as 1234 neighbor 3.3.3.3 update-source Loopback0 neighbor 4.4.4.4 remote-as 1234 neighbor 4.4.4.4 update-source Loopback0 neighbor 200.0.65.6 remote-as 67 neighbor 200.0.75.7 remote-as 67 neighbor 200.0.105.10 remote-as 65000 neighbor 200.0.115.11 remote-as 1114 ! address-family ipv4 network 5.0.0.0 mask 255.255.255.0 network 5.0.1.0 mask 255.255.255.0 network 5.0.2.0 mask 255.255.255.0 network 5.0.3.0 mask 255.255.255.0 neighbor 2.2.2.2 activate neighbor 3.3.3.3 activate neighbor 4.4.4.4 activate neighbor 200.0.65.6 activate neighbor 200.0.65.6 remove-private-as neighbor 200.0.75.7 activate neighbor 200.0.75.7 remove-private-as neighbor 200.0.105.10 activate neighbor 200.0.105.10 route-map AS65000_IN in neighbor 200.0.105.10 route-map AS65000_OUT out neighbor 200.0.115.11 activate neighbor 200.0.115.11 remove-private-as neighbor 200.0.115.11 route-map AS1114_IN in neighbor 200.0.115.11 route-map AS1114_OUT out exit-address-family ! address-family vpnv4 neighbor 2.2.2.2 activate neighbor 2.2.2.2 send-community both exit-address-family ! address-family ipv4 vrf AS1114 redistribute ospf 150 exit-address-family На этом закончим с MPLS и со статьей в целом.
