Подходы к проектированию RESTful API

Автор: Вячеслав Михайлов, Solutions Architect.
В этой статье я поделюсь опытом проектирования RESTful API — на конкретных примерах покажу, как делать хотя бы простые сервисы красиво. Также мы поговорим, что такое API и зачем он нужен, поговорим об основах REST — обсудим, на чем его можно реализовывать; коснемся основных веб-практик, которые зависят и не зависят от этой технологии. Также узнаем, как составлять хорошую документацию, затрачивая на это минимум усилий, и посмотрим, какие существуют способы нумерации версий для RESTful API.
Часть 1. Теория
Итак, как мы все знаем, API — application programming interface (интерфейс программирования приложений), набор правил и механизмов, с помощью которых одно приложение или компонент взаимодействует с другими
Почему хороший API — это важно?
- Простота использования и поддержки. Хороший API просто использовать и поддерживать.
- Хорошая конверсия в среде разработчиков. Если всем нравится ваш API, к вам приходят новые клиенты и пользователи.
- Выше популярность вашего сервиса. Чем больше пользователей API, тем выше популярность вашего сервиса.
- Лучше изоляция компонентов. Чем лучше структура API, тем лучше изоляция компонентов.
- Хорошее впечатление о продукте. API — это как бы UI разработчиков; это то, на что разработчики обращают внимание в первую очередь при встрече с продуктом. Если API кривой, вы как технический эксперт не будете рекомендовать компаниям использовать такой продукт, приобретая что-то стороннее.
Теперь посмотрим, какие бывают виды API.
Виды API по способу реализации:
● Web service APIs
○ XML-RPC and JSON-RPC
○ SOAP
○ REST
● WebSockets APIs
● Library-based APIs
○ Java Script
● Class-based APIs
○ C# API
○ Java
Виды API по категориям применения:
● OS function and routines
○ Access to file system
○ Access to user interface
● Object remoting APIs
○ CORBA
○ .Net remoting
● Hardware APIs
○ Video acceleration (OpenCL…)
○ Hard disk drives
○ PCI bus
○ …
Как мы видим, к Web API относятся XML-RPC и JSON-RPC, SOAP и REST.
RPC (remote procedure call — «удаленный вызов процедур») — понятие очень старое, объединяющие древние, средние и современные протоколы, которые позволяют вызвать метод в другом приложении. XML-RPC — протокол, появившийся в 1998 г. вскоре после появления XML. Изначально он поддерживался Microsoft, но вскоре Microsoft полностью переключилась на SOAP, поэтому в .Net Framework мы не найдем классов для поддержки этого протокола. Несмотря на это, XML-RPC продолжает жить до сих пор в различных языках (особенно в PHP) — видимо, заслужил любовь разработчиков простотой.
SOAP также появился в 1998 г. стараниями Microsoft. Он был анонсирован как революция в мире ПО. Нельзя сказать, что все пошло по плану Microsoft: было огромное количество критики из-за сложности и тяжеловесности протокола. В то же время, были и те, кто считал SOAP настоящим прорывом. Протокол продолжал развиваться и плодиться десятками новых и новых спецификаций, пока в 2003 г. W3C не утвердила в качестве рекомендации SOAP 1.2, который и сейчас — последний. Семейство у SOAP получилось внушительное: WS-Addressing, WS-Enumeration, WS-Eventing, WS-Transfer, WS-Trust, WS-Federation, Web Single Sign-On.
Затем, что закономерно, все же появился действительно простой подход — REST. Аббревиатура REST расшифровывается как representational state transfer — «передача состояния представления» или, лучше сказать, представление данных в удобном для клиента формате. Термин «REST» был введен Роем Филдингом в 2000 г. Основная идея REST в том, что каждое обращение к сервису переводит клиентское приложение в новое состояние. По сути, REST — не протокол и не стандарт, а подход, архитектурный стиль проектирования API.
Каковы принципы REST?
- Клиент-серверная архитектура — без этого REST немыслим.
- Любые данные — ресурс.
- Любой ресурс имеет ID, по которому можно получить данные.
- Ресурсы могут быть связаны между собой — для этого в составе ответа передается либо ID, либо, как чаще рекомендуется, ссылка. Но я пока не дошел до того, чтобы все было настолько хорошо, чтобы можно было легко использовать ссылки.
- Используются стандартные методы HTTP (GET, POST, PUT, DELETE) — т. к. они уже заложены в составе протокола, мы их можем использовать для того, чтобы построить каркас взаимодействия с нашим сервером.
- Сервер не хранит состояние — это значит, сервер не отделяет один вызов от другого, не сохраняет все сессии в памяти. Если у вас есть какое-либо масштабируемое облако, какая-то ферма из серверов, которая реализует ваш сервис, нет необходимости обеспечивать согласованность состояния этих сервисов между всеми узлами, которые у вас есть. Это сильно упрощает масштабирование — при добавлении еще одного узла все прекрасно работает.
Чем REST хорош?
● Он очень прост!
● Мы переиспользуем существующие стандарты, которые в ходу уже очень давно и применяются на многих устройствах.
● REST основывается на HTTP => доступны все плюшки:
○ Кэширование.
○ Масштабирование.
○ Минимум накладных расходов.
○ Стандартные коды ошибок.
● Очень хорошая распространенность (даже IoT-устройства уже умеют работать на HTTP).
Лучшие решения (независимые от технологий)
Какие в современном мире есть лучшие решения, не связанные с конкретной реализацией? Эти решения советую использовать обязательно:
- SSL повсюду — самое важное в вашем сервисе, т. к. без SSL авторизация и аутентификация бессмысленны.
- Документация и версионность сервиса — с первого дня работы.
- Методы POST и PUT должны возвращать обратно объект, который они изменили или создали, — это позволит сократить время обращения к сервису вдвое.
- Поддержка фильтрации, сортировки и постраничного вывода — очень желательно, чтобы это было стандартно и работало «из коробки».
- Поддержка MediaType. MediaType — способ сказать серверу, в каком формате вы хотите получить содержимое. Если вы возьмете какую-либо стандартную реализацию web API и зайдете туда из браузера, API отдаст вам XML, а если зайдете через какой-нибудь Postman, он вернет JSON.
- Prettyprint & gzip. Не минимизируйте запросы и не делайте компакт для JSON (того ответа, который придет от сервера). Накладные расходы на prettyprint —единицы процентов, что видно, если посмотреть, сколько занимают табы по отношению к общему размеру сообщения. Если вы уберете табы и будете присылать все в одну строку, запаритесь с отладкой. Что касается gzip, он дает выигрыш в разы. Т. ч. очень советую использовать и prettyprint, и gzip.
- Используйте только стандартный механизм кэширования (ETag) и Last-Modified (дата последнего изменения) — этих двух параметров серверу достаточно, чтобы клиент понял, что содержимое не требует обновления. Придумывать что-то свое тут не имеет смысла.
- Всегда используйте стандартные коды ошибок HTTP. Иначе вам однажды придется кому-нибудь объяснять, почему вы решили, что ошибку 419 в вашем проекте клиенту нужно трактовать именно так, как вы почему-то придумали. Это неудобно и некрасиво — за это клиент вам спасибо не скажет!
Свойства HTTP-методов
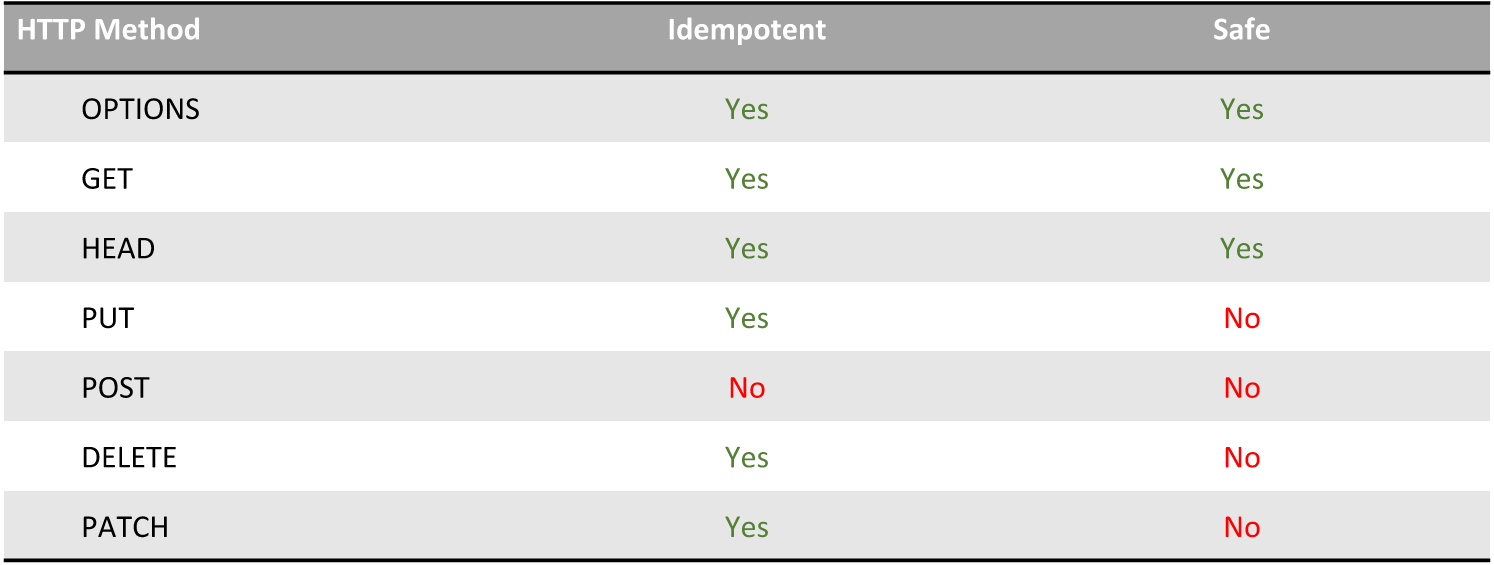
Сегодня мы будем говорить только про GET, POST, PUT, DELETE.
Если говорить вкратце об остальных, представленных в таблице, OPTIONS — получение настроек безопасности, HEAD — получение заголовков без тела сообщения, PATCH — частичное изменение содержимого.
Как вы видите, все методы, кроме POST, представленные в таблице, идемпотентны. Идемпотентность — возможность выполнить одно и то же обращение к сервису несколько раз, при этом ответ каждый раз будет одинаковым. Другими словами, не важно, по какой причине и сколько раз вы выполнили это действие. Допустим, вы выполняли действие по изменению объекта (PUT), и вам пришла ошибка. Вы не знаете, что ее вызвало и в какой момент, вы не знаете, изменился объект или нет. Но, благодаря идемпотентности, вы гарантированно можете выполнить этой действие еще раз, т. ч. клиенты могут быть спокойны за целостность своих данных.
«Safe» же значит, что обращение к серверу не изменяет содержимое. Так, GET может быть вызван много раз, но он не изменит никакого содержимого. Если бы он изменял содержимое, в силу того, что GET может быть закэширован, вам пришлось бы бороться с кэшированием, изобретать какие-нибудь хитрые параметры.
Часть 2. Практика Выбираем технологию
Теперь, когда мы поняли, как работает REST, можем приступить к написанию RESTful API ¬ сервиса, отвечающего принципам REST. Начнем с выбора технологии.
Первый вариант — WCF Services. Все, кто работал с этой технологией, обычно возвращаться к ней больше не хотят — у нее есть серьезные недостатки и мало плюсов:
— webHttpBinding only (а зачем тогда остальные?…).
— Поддерживаются только HTTP Get & POST (и все).
+ Разные форматы XML, JSON, ATOM.
Второй вариант — Web API. В этом случае плюсы очевидны:
+ Очень простой.
+ Открытый исходный код.
+ Все возможности HTTP.
+ Все возможности MVC.
+ Легкий.
+ Тоже поддерживает кучу форматов.
Естественно, мы выбираем Web API. Теперь выберем подходящий хостинг для Web API.
Выбираем хостинг для Web API
Тут есть достаточно вариантов:
● ASP.NET MVC (старый добрый).
● Azure (облачная структура).
● OWIN — Open Web Interface for .NET (свежая разработка от Microsoft).
○ IIS
○ Self-hosted
OWIN — не платформа и не библиотека, а спецификация, которая устраняет сильную связанность веб-приложения с реализацией сервера. Она позволяет запускать приложения на любой платформе, поддерживающей OWIN, без изменений. На самом деле, спецификация очень проста — это просто «словарь» из параметров и их значений. Базовые параметры определены в спецификации.
OWIN сводится к очень простой конструкции:
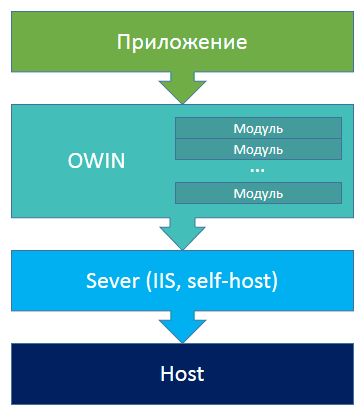
По схеме мы видим, что есть хост, на котором есть сервер, который поддерживает очень простой «словарь», состоящий из перечня «параметр — значение». Все модули, которые подключаются к этому серверу, конфигурируются именно так. Сервер, поддерживающий этот контракт, привязанный к определенной платформе, умеет распознавать все эти параметры и инициализировать инфраструктуру соответствующим образом. Получается, что, если вы пишете сервис, который работает с OWIN, можете свободно, без изменений кода, переносить его между платформами и использовать то же самое на других ОС.
Katana — реализация OWIN от Microsoft. Она позволяет размещать OWIN-сборки в IIS. Вот так она выглядит, очень просто:
[assembly: OwinStartup(typeof (Startup))]
namespace RestApiDemo
{
public class Startup
{
public void Configuration(IAppBuilder app)
{
var config = new HttpConfiguration();
config.MapHttpAttributeRoutes();
app.UseWebApi(config);
}
}
}
Вы указываете, какой класс является у вас Startup. Это простой dll, который поднимается IIS. Вызывается конфигуратор. Этого кода достаточно, чтобы все заработало.
Проектируем интерфейс
Теперь спроектируем интерфейс и посмотрим, как все должно выглядеть и каким правилам соответствовать. Все ресурсы в REST — существительные, то, что можно пощупать и потрогать.
Как пример возьмем простую модель с расписанием движения поездов на станциях. Вот примеры простейших запросов REST:
● Корневые (независимые) сущности API:
○ GET /stations — получить все вокзалы.
○ GET /stations/123 — получить информацию по вокзалу с ID = 123.
○ GET /trains — расписание всех поездов.
● Зависимые (от корневой) сущности:
○ GET /stations/555/departures — поезда, уходящие с вокзала 555.
Далее я еще расскажу про DDD, почему мы делаем именно так.
Контроллер
Итак, у нас есть станции, и теперь нам нужно написать простейший контроллер:
[RoutePrefix("stations")]
public class RailwayStationsController : ApiController
{
[HttpGet]
[Route]
public IEnumerable GetAll()
{
return testData;
}
RailwayStationModel[] testData = /*initialization here*/
}
Это роутинг, построенный на атрибутах. Здесь мы указываем имя контроллера и просим отдать список (в данном случае — случайные тестовые данные).
OData (www.odata.org)
Теперь представьте, что у вас больше данных, чем нужно на клиенте (больше ста тащить вряд ли имеет смысл). При этом писать самому какое-либо разбиение на страницы, конечно, совсем не хочется. Вместо этого есть простой способ — использовать легкую версию OData, которая поддерживается Web API.
[RoutePrefix("stations")]
public class RailwayStationsController : ApiController
{
[HttpGet]
[Route]
[EnableQuery]
public IQueryable GetAll()
{
return testData.AsQueryable();
}
RailwayStationModel[] testData = /*initialization here*/
}
IQueryable позволяет вам использовать несколько простых, но эффективных механизмов фильтрации и управления данными на клиентской стороне. Единственное, что нужно сделать, — подключить OData-сборку из NuGet, указать EnableQuery и возвращать интерфейс iQueryable.
Основное отличие такой облегченной верси от полноценной в том, что здесь нет контроллера, который возвращает метаданные. Полноценная OData немного изменяет ответ (заворачивает в спец. Обертку модель, которую вы собираетесь возвращать) и умеет возвращать связанное дерево объектов, которые вы хотите ей отдать. Также облегченная версия OData не умеет делать штуки вроде join, count и т. д.
Параметры запросов
А вот что можно делать:
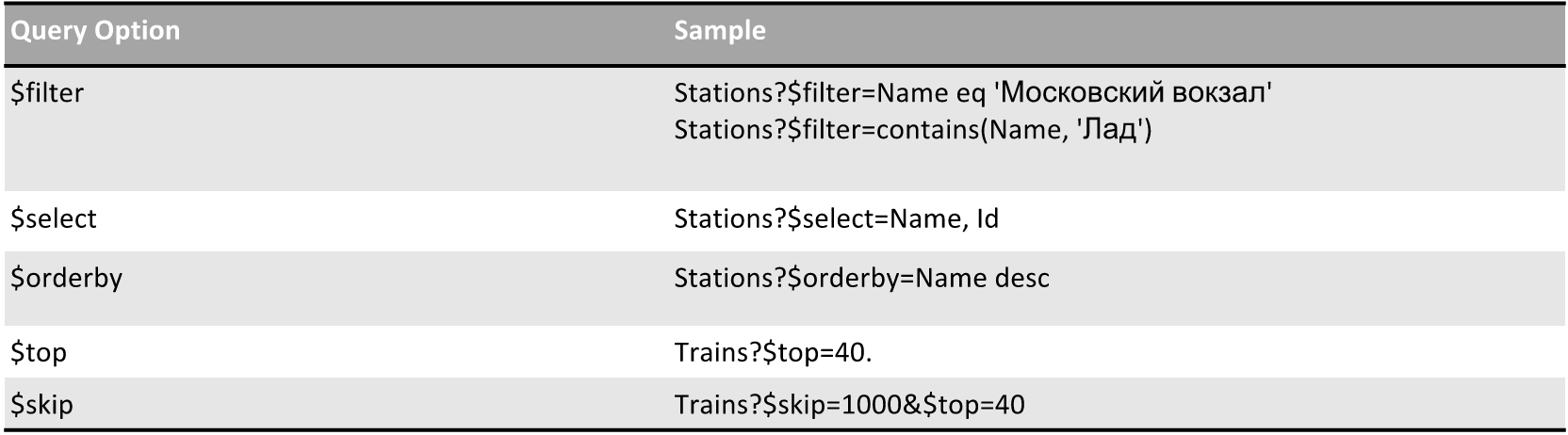
- $filter — фильтр, по имени, например. Все функции можно посмотреть на сайте OData — они очень помогают и позволяют существенно ограничить выборку.
- $select — очень важная штука. Если у вас большая коллекция и все объекты толстые, но при этом вам нужно сформировать какой-то dropdown, в котором нет ничего, кроме ID и имени, которое вы хотите отобразить, — поможет эта функция, которая упростит и ускорит взаимодействие с сервером.
- $orderby — сортировка.
- $top и $skip — ограничение по выборкам.
Этого достаточно, чтобы самому не изобретать велосипеда. Все это умеет стандартная JS-библиотека вроде Breeze.
EnableQuery Attribute
На самом деле OData — такая штука, которой очень легко можно выстрелить себе в ногу. Если у вас в таблице миллионы записей, и вам нужно тянуть их с сервера на клиент, это будет тяжело, а если таких запросов будет много — совсем смертельно.
Именно для таких случаев у атрибута EnableQuery (см. код выше) есть такой набор параметров, с помощью которых очень многое можно ограничить: не давать больше строк, чем надо, не давать делать join, арифметические операции и т. д. При этом писать самому ничего не надо.
- AllowedArithmeticOperators
- AllowedFunctions
- AllowedLogicalOperators
- AllowedOrderByProperties
- AllowedQueryOptions
- EnableConstantParameterization
- EnsureStableOrdering
- HandleNullPropagation
- MaxAnyAllExpressionDepth
- MaxExpansionDepth
- MaxNodeCount
- MaxOrderByNodeCount
- MaxSkip
- MaxTop
- PageSize
Зависимый контроллер
Итак, вот примеры простейших запросов REST:
- GET /stations — получить все вокзалы
- GET /trains — расписание всех поездов
- GET /stations/555/arrivals
- GET /stations/555/departures
Допустим, у нас есть вокзал 555, и мы хотим получить все его отправления и прибытия. Очевидно, что здесь должна использоваться сущность, которая зависит от сущности вокзала. Но как это сделать в контроллерах? Если мы все это будет делать роутинг-атрибутами и складывать в один класс, понятно, что в таком примере, как у нас, проблем нет. Но если у вас будет десяток вложенных сущностей и глубина будет расти еще дальше, все это вырастет в неподдерживаемый формат.
И тут есть простое решение — в роутинг-атрибутах в контроллерах можно делать переменные:
[RoutePrefix("stations/{station}/departures")]
public class TrainsFromController : TrainsController
{
[HttpGet]
[Route]
[EnableQuery]
public IQueryable GetAll(int station)
{
return GetAllTrips().Where(x => x.OriginRailwayStationId == station);
}
}
Соответственно, все зависимые сущности выносите в отдельный контроллер. Сколько их — совершенно неважно, так как они живут отдельно. С точки зрения Web API, они будут восприниматься разными контроллерами — сама система как бы не знает, что они зависимы, несмотря на то, что в URL они выглядят таковыми.
Единственное, возникает проблема — здесь у нас «stations», и до этого был «stations». Если вы в одном месте что-то поменяете, а в другом — ничего не поменяете, ничего работать не будет. Однако тут есть простое решение — использование констант для роутинга:
public static class TrainsFromControllerRoutes
{
public const string BasePrefix =
RailwayStationsControllerRoutes.BasePrefix +
"/{station:int}/departures";
public const string GetById = "{id:int}";
}
Тогда зависимый контроллер будет выглядеть так:
[RoutePrefix(TrainsFromControllerRoutes.BasePrefix)]
public class TrainsFromController : TrainsController
{
[HttpGet]
[Route]
[EnableQuery]
public IQueryable GetAll(int station)
{
return GetAll().Where(x => x.OriginRailwayStationId == station);
}
}
Вы можете делать для зависимых контроллеров простейшие операции — вы просто берете и вычисляете роут сами, и тогда вы не ошибетесь. Кроме того, эти штуки полезно использовать в тестировании. Если вы хотите написать тест и потом хотите этим управлять, а не бегать каждый раз по всем миллионам ваших тестов и исправлять все строки, где указаны эти относительные URL«ы, то вы также можете использовать эти константы. Когда вы их меняете, данные у вас меняются везде. Это очень удобно.
CRUD
Итак, мы с вами обсудили, как могут выглядеть простейшие GET-операции. Все понимают, как сделать единичный GET. Но, кроме него, нам нужно обсудить еще три операции.
● POST — создать новую сущность
○ POST /Stations — JSON-описание сущности целиком. Действие добавляет новую сущность в коллекцию.
○ Возвращает созданную сущность (во-первых, чтобы не было двойных походов к серверу, во-вторых, чтобы, если это нужно, вернуть со стороны сервера параметры, которые посчитались в этом объекте и нужны вам на клиенте).
● PUT — изменить сущность
○ PUT /Stations/12 — Изменить сущность с ID = 12. JSON, который придет в параметре, будет записан поверх.
○ Возвращает измененную сущность. Путь, который был применен много раз, должен приводить систему к одному и тому же состоянию.
● DELETE
○ DELETE /Stations/12 — удалить сущность с ID = 12.
Еще примеры CRUD:
- POST /Stations — добавляем вокзал.
- POST /Stations/1/Departures — добавляем информацию об отправлении с вокзала 1.
- DELETE /Stations/1/Departures/14 — удаляем запись об отправлении с вокзала 1.
- GET /Stations/33/Departures/10/Tickets — список проданных билетов для отправления 10 с вокзала 33.
Важно понимать, что узлы — обязательно какие-то сущности, то, что можно «потрогать» (билет, поезд, факт отправления поезда и т. д.).
Антишаблоны
А вот примеры, как делать не надо:
● GET /Stations/? op=departure&train=11
○ Здесь query string используется не только для передачи данных, но и для действий.
● GET /Stations/DeleteAll
○ Это реальный пример из жизни. Тут мы делаем GET на этот адрес, и он, по идее, должен удалить все сущности из коллекции — в итоге он ведет себя очень непредсказуемо из-за кэширования.
● POST /GetUserActivity
○ На самом деле здесь GET, который записан как POST. POST нужен был из-за параметров запроса в body, но в body у GET нельзя ничего передать — GET можно передать только в query string. GET даже по стандарту не поддерживает body.
● POST /Stations/Create
○ Здесь действие указано в составе URL — это избыточно.
Проектируем API
Допустим, у вас есть API, который вы хотите предложить людям, и есть доменная модель. Как связаны сущности API с доменной моделью? Да никак они не связаны, на самом деле. В этом нет никакой необходимости: то, что вы делаете в API, никак не связано с вашей внутренней доменной моделью.
Может возникнуть вопрос, как проектировать API, если это не CRUD? Для этого мы записываем любые действия как команды на изменения. Мы делаем сохранение, чтение, удаление команды, GET, проверку статуса этой команды. GET из коллекции команд — вы получаете список всех команд, которые вы отправляли для какой-либо конкретной сущности.
Доменная модель
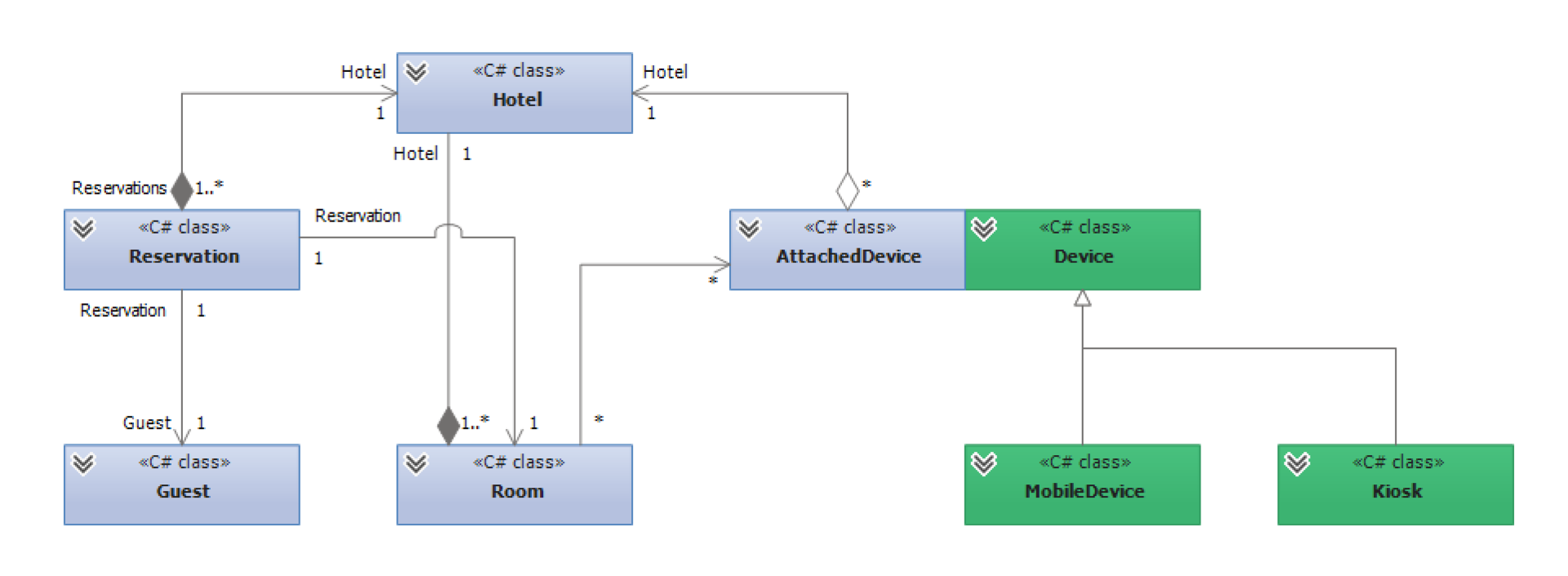
Мы поговорим о связи доменной модели с объектами. В примере у нас есть отель (Hotel), есть бронирования (Reservation), комнаты (Room) и устройства (Device), к ним привязанные. В нашем проекте это позволяло управлять комнатами посредством этих устройств.
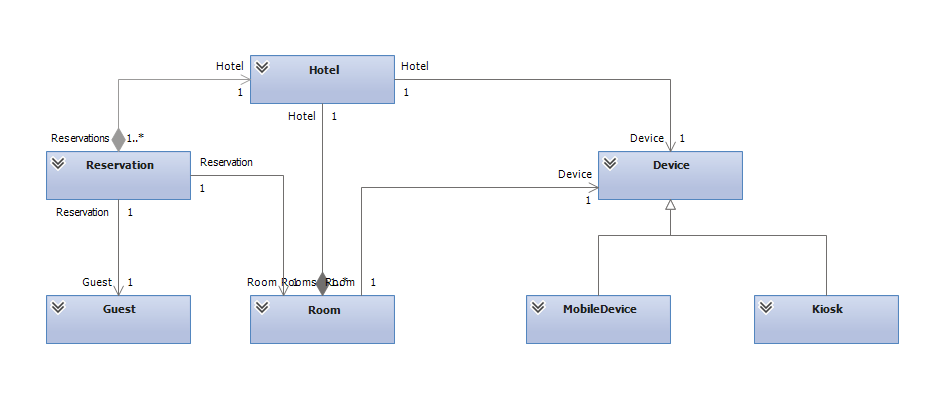
Но вот незадача: устройство — сущность, которая живет своей жизнью, и непонятно, как ее отделять от отеля. Но разделить отель и устройства, на самом деле, очень просто — поможет DDD. В первую очередь, нужно разобраться, где границы доменных областей и где границы сущностей, ответственных за согласованность системы.
Bounded context (BC)
Bounded context (изолированный поддомен) — фактически, наборы объектов, не зависимые друг от друга и имеющие совершенно независимые модели (разные). В примере мы можем взять и растащить отели и устройства на два разных BC — они не связаны между собой, но присутствует дублирование. Возникает дополнительная сущность (AttachedDevice):
Тут у нас разные представления одного и того же устройства, и в этом нет ничего страшного.
В DDD aggregate route — сущность, которая владеет всеми потомками. Это вершина нашего дерева (Hotel); то, за что можно вытянуть все остальное. А AttachedDevice так взять нельзя — его не существует, и он не имеет никакого смысла. Так же и классы Room и Reservation не имеют никакого смысла, будучи оторванными от Hotel. Поэтому доступ ко всем этим классам — исключительно через рутовую сущность, через Hotel, в данном случае. Device же — другой route с самого начала, другое дерево с другим набором полей.
Итак, если вы понимаете, что одна сущность у вас играет в двух разных доменах, просто распилите ее — и это будет всего лишь проекция мастер-сущности. В AttachedDevice будут, например, поля с номером комнаты, а в Device такие поля не нужны.
А вот примеры запросов, как они могут выглядеть в такой доменной модели:
- PUT /hotels/555/rooms/105/attachedDevices — заменить всю коллекцию привязанных устройств на новую.
- POST /hotels/555/rooms/105/attachedDevices — привязать еще одно устройство.
- DELETE /hotels/12 — удалить описание отеля с ID=12.
- POST /hotels/123/reservations — создать новую резервацию в отеле ID=123.
CQRS — Command Query Responsibility Segregation
Я не буду сейчас рассказывать про это архитектуру, но хочу коротко обрисовать, в чем ее принцип действия. Архитектура CQRS основана на разделении потоков данных.

У нас есть один поток, через который пользователь отправляет на сервер команду об изменении домена. Однако не факт, что изменение действительно произойдет, — пользователь не оперирует данными непосредственно. Итак, после того как пользователь посылает команду на изменение сущности, сервер ее обрабатывает и перекладывает в какую-то модель, которая оптимизирована на чтение — UI считывает это.
Такой подход позволит вам следовать принципам REST очень легко. Если есть команда, значит, есть сущность «список команд».
REST without PUT
В простом CRUD-мире PUT — это штука, которая меняет объекты. Но если мы строго следуем принципу CQRS и делаем все через команды, PUT у нас пропадает, т. к. мы не можем менять объекты. Вместо этого можем лишь послать объекту команду на изменение. При этом можно отслеживать статус выполнения, отменять команды (DELETE), легко хранить историю изменений, а пользователь ничего не изменяет, а просто сообщает о намерениях.
Парадигма REST without PUT — пока еще спорная и не до конца проверенная, но для каких-то случаев действительно хорошо применима.
Fine-grained VS coarse-grained
Представьте, что вы делаете большой сервис, большой объект. Тут у вас есть два подхода: fine-grained API и coarse-grained API («мелкозернистый» и «крупнозернистый» API).
Fine-grained API:
- Много маленьких объектов.
- Бизнес-логика уходит на сторону клиента.
- Нужно знать, как связаны объекты.
Сoarse-grained API:
● Создаете больше сущностей.
● Сложно делать локальные изменения, например
○ POST /blogs/{id}/likes.
● Нужно отслеживать состояние на клиенте.
● Большие объекты нельзя сохранить частично.
Для начала советую проектировать fine-grained API: каждый раз, когда вы создаете объект, отправляете его на сервер. На каждое действие на стороне клиента происходит обращение к серверу. Однако с маленькими сущностями работать проще, чем с большими: если вы напишете большую сущность, вам трудно будет потом ее распилить, трудно будет делать небольшие изменения и выдергивать из нее независимые куски. Т. ч. лучше начинать с маленьких сущностей и постепенно их укрупнять.
Нумерация версий
Так уж сложилось, что к контрактам у нас в отрасли очень расслабленное отношение. Почему-то люди считают, что, если они взяли и сделали API, это их API, с которым они могут делать что угодно. Но это не так. Если вы когда-то написали API и отдали его хоть одному контрагенту, все — это версия 1.0. Любые изменения теперь должны приводить к изменению версии. Ведь люди будут привязывать свой код к той версии, которую вы им предоставили.
На прошлом проекте приходилось несколько раз откатывать API назад просто потому, что он был отдан клиенту — мы поменяли коды ошибок, но клиент уже успел привыкнуть к старым кодам.
Какие известны на текущий момент варианты нумерации версий Web API?

Самое простое — указать версию в URL.
Вот готовые варианты, когда самому ничего делать не надо:
Библиотека Climax.Web.Http
Вот один интересный готовый вариант.
Это всего лишь роутинг атрибутов с constraint — если вы делали какие-либо серьезные объекты, наверняка делали constraint. По номеру версии в этом атрибуте ребята просто реализовали constraint. Соответственно, на один и тот же атрибут с разными версиями, но одинаковым именем контроллера вешаете на два разных класса и указываете разные версии. Все работает «из коробки….
● [VersionedRoute («v2/values», Version = 2)]
● config.ConfigureVersioning (
versioningHeaderName: «version», vesioningMediaTypes: null);
● config.ConfigureVersioning (
versioningHeaderName: null,
vesioningMediaTypes: new [] { «application/vnd.model»});
Документация
Есть чудесная open-source-штука, имеющая множество различных применений — Swagger. Мы ее используем со специальным адаптером — Swashbuckle.
Swashbuckle:
httpConfiguration
.EnableSwagger (c => c.SingleApiVersion («v1», «Demo API»)) .EnableSwaggerUi ();
public static void RegisterSwagger (this HttpConfiguration config)
{
config.EnableSwagger (c =>
{
c.SingleApiVersion («v1», «DotNextRZD.PublicAPI»)
.Description («DotNextRZD Public API»)
.TermsOfService («Terms and conditions»)
.Contact (cc => cc
.Name («Vyacheslav Mikhaylov»)
.Url («www.dotnextrzd.com»)
.Email («vmikhaylov@dataart.com»))
.License (lc => lc.Name («License»).Url («tempuri.org/license»));
c.IncludeXmlComme
nts(GetXmlCommentFile());
c.GroupActionsBy(GetControllerGroupingKey);
c.OrderActionGroupsBy(new CustomActionNameComparer());
c.CustomProvider(p => new CustomSwaggerProvider(config, p));
})
.EnableSwaggerUi(
c =>
{
c.InjectStylesheet(Assembly.GetExecutingAssembly(),
"DotNextRZD.PublicApi.Swagger.Styles.SwaggerCustom.css");
});
}
}
Как видите, Swagger вытащил все, что у нас есть, вытащил XML-комментарии.

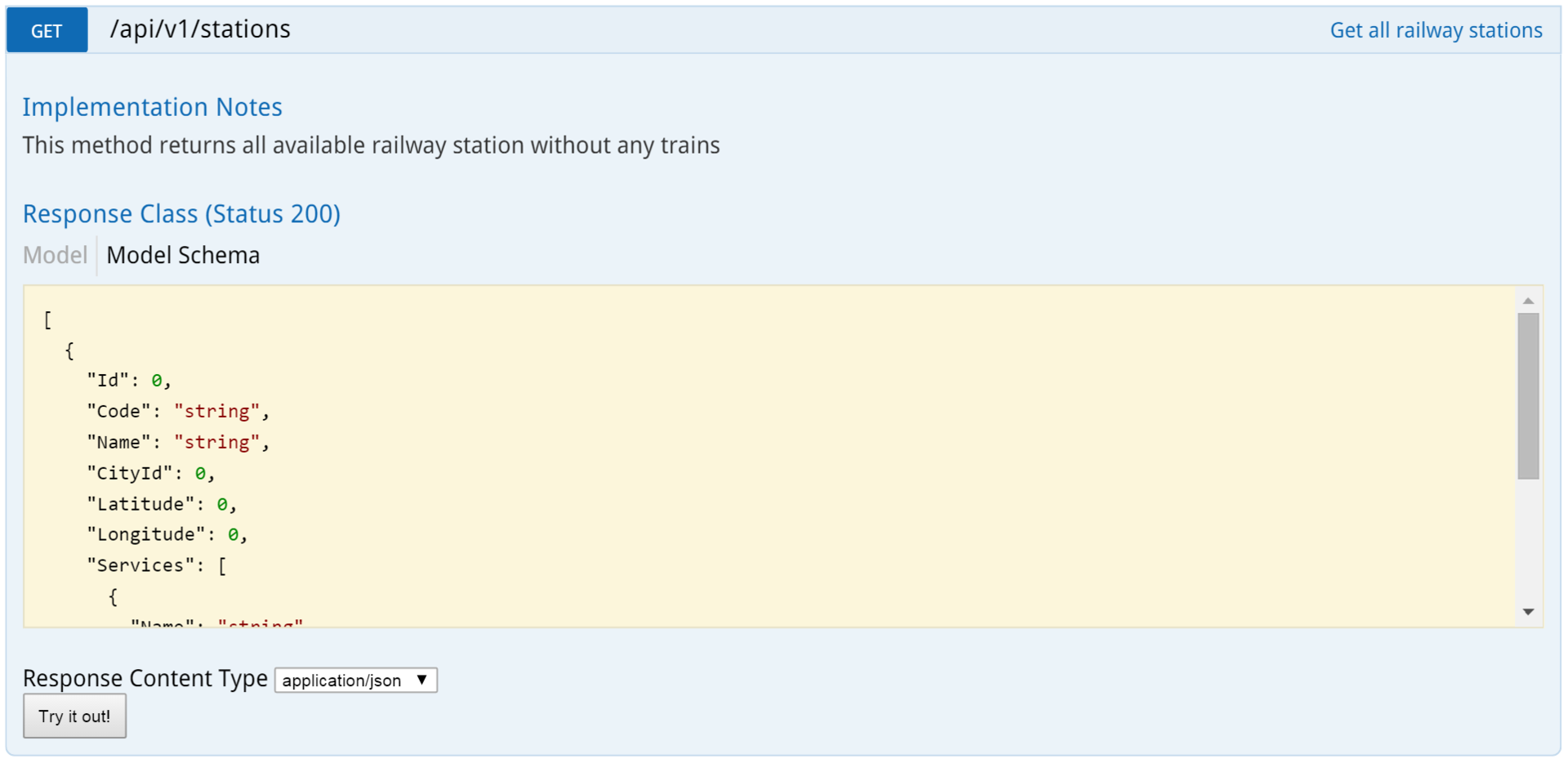
Ниже — полное описание модели GET. Если нажать на кнопку, он ее в самом деле выполнит и вернет результат.
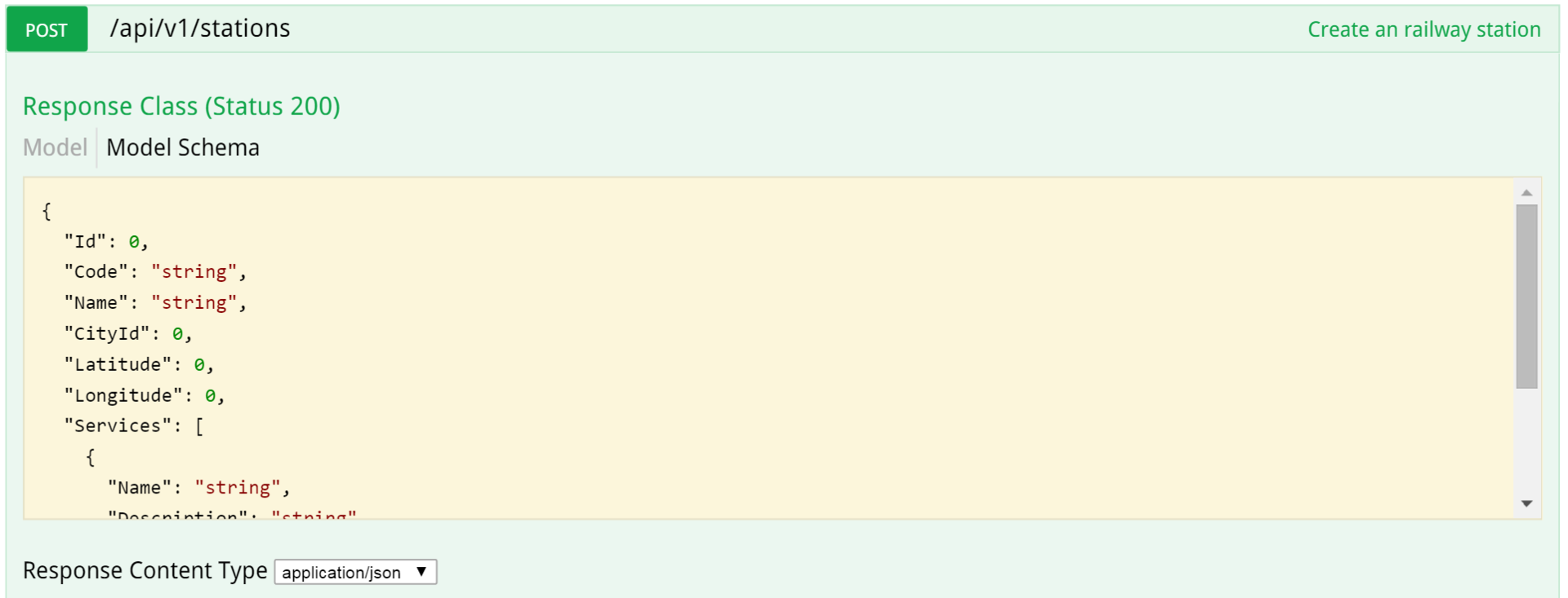
А вот так выглядит документация к POST, первая часть:
Вот вторая часть:
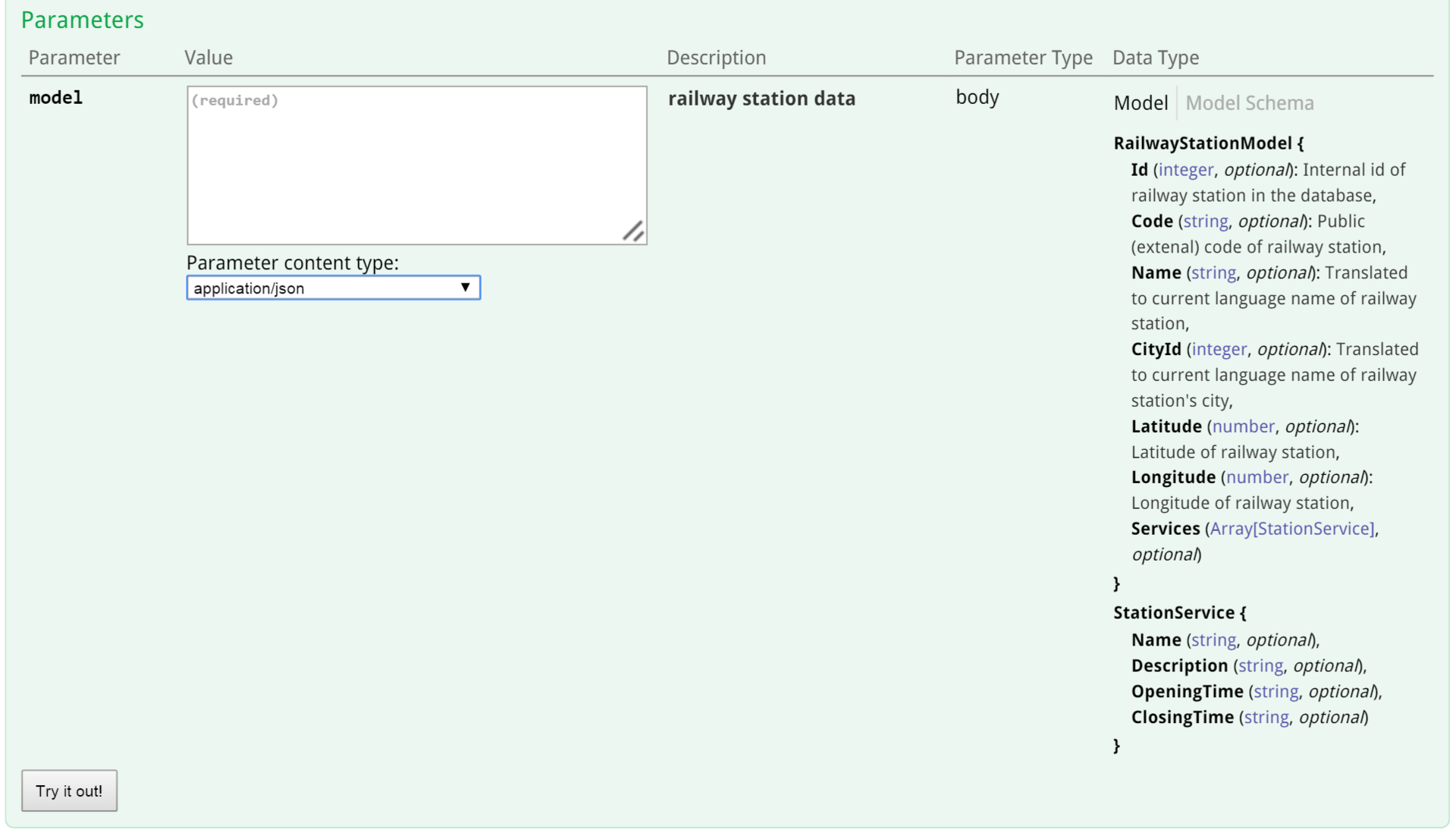
Все, что было написано в XML-комментариях, — здесь.
Источники
