Под капотом VK Teams: с чего начиналось приложение и к чему пришло сейчас

VK Teams — защищенное пользовательское суперприложение для совместной работы сотрудников с любого устройства. Оно помогает компаниям организовывать коммуникацию, совместную работу команд, обмен данными и не только. Но так было не всегда — решение изначально имело небольшую функциональность и создавалось в качестве внутреннего мессенджера для сотрудников внутри VK.
Меня зовут Евгений Макархин. Я архитектор VK Teams. В этой статье я расскажу, как мессенджер VK Teams прошел путь от внутреннего решения до супераппа и как менялась его архитектура.
VK Teams сейчас
Этот инструмент объединяет в едином цифровом пространстве более десяти готовых сервисов: мессенджер, видеоконференции, почту, календарь, диск, задачи, оргструктуру, опросы, профили, боты, мини-приложения для автоматизации HR-процессов и многое другое. Причем их можно дополнять своими решениями, расширяя возможности.
С помощью VK Teams команды могут получить в контуре одного супераппа всё, что им нужно.
VK Teams доступен в двух версиях:
сервис в облаке (software as a service, SaaS);
On-Premises-решение, развертываемое на инфраструктуре клиента.
Причем обе версии продукта востребованы. В самой крупной инсталляции приложения работают около 500 тысяч пользователей. При этом, разрабатывая On-premises инсталляцию, мы ориентируемся как на достаточно небольшие компании в 200 человек, так и на самые крупные корпорации на рынке, имеющие более 700 тысяч сотрудников.
Подробнее о мессенджере
Прежде чем говорить о супераппе, вернемся к тому, с чего всё начиналось — к мессенджеру.
Мессенджер представляет собой сложный «комбайн» из сотен разных функциональностей, подчас даже неочевидных — папки, закрепы, архивы, черновики, метки просмотра и так далее.
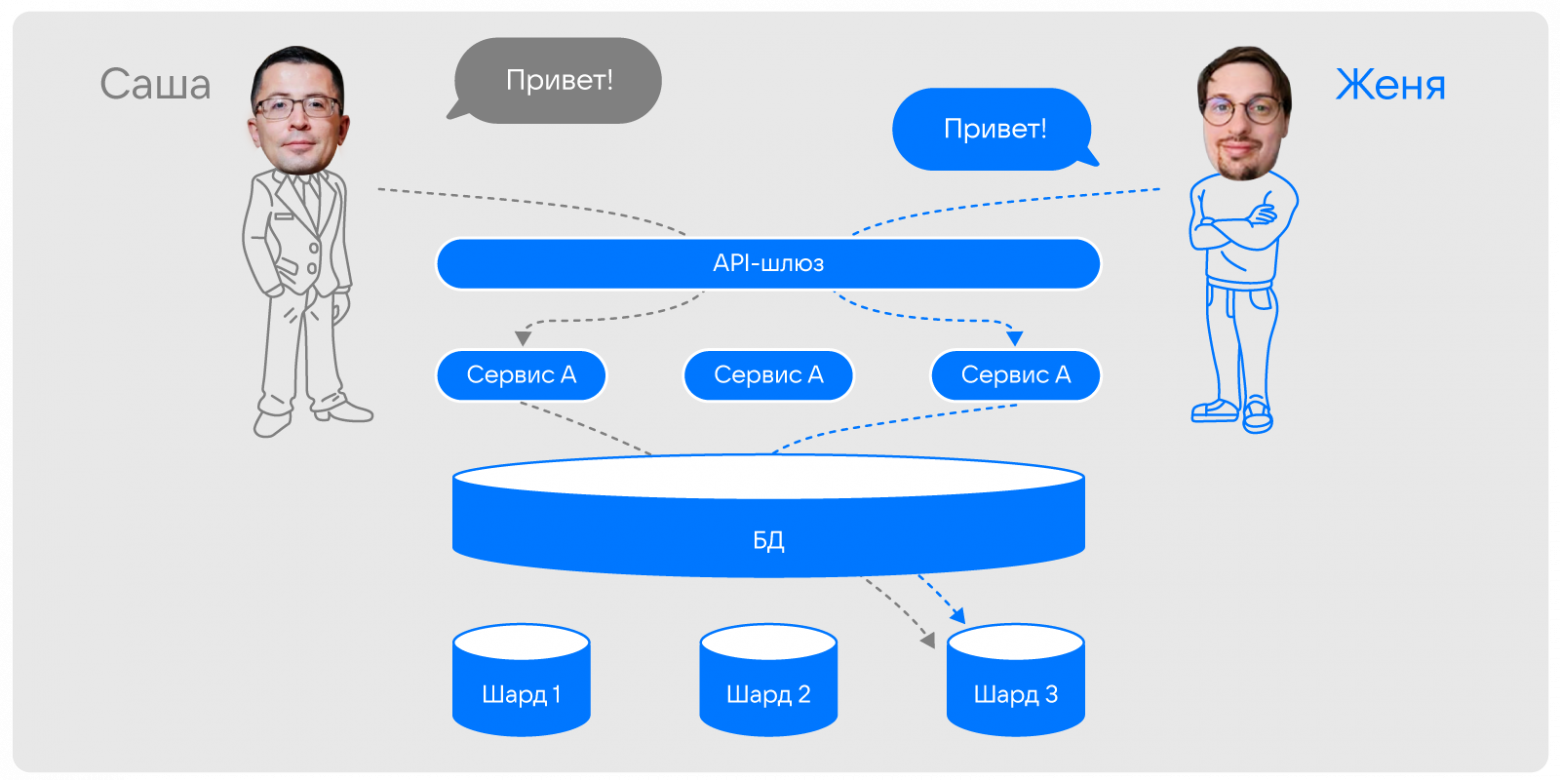
Проектируя систему, мы могли бы пойти по хорошо изученному пути, создавая классическую трехуровневую архитектуру, разделив клиентские приложения, бизнес-логику и базы данных. Ключевой момент тут в обеспечении их горизонтального масштабирования, чтобы справиться с любой нагрузкой. Таким образом у нас был бы слой stateless-сервисов, количество которых можно менять динамически под нагрузку, и один или несколько кластеров СУБД, которая «под капотом» позволяла бы нам масштабировать запись по средствам шардинга.
Причем шардинг — ключевая технология в такой реализации, которая позволяет распределять данные и, как результат, балансировать общую нагрузку.
При этом разделение на шарды не влияет на «слаженность и синхронность» потоков данных — если сообщение отправителя попало в шард №3, то и сообщение получателя в дальнейшем также попадает в шард №3. То есть все переписки в рамках одного чата хранятся на одном шарде — при обращении к чату, он не будет собираться из разных частей, а будет доступен сразу.
Есть и альтернативный вариант проектирования, при котором экземпляр сервиса и экземпляр базы данных (в которой хранятся данные не отдельного сервиса, а всей системы) формируют единую, неделимую «ячейку», компоненты которой зависимы, в том числе совместно масштабируются. В таком случае сервис является не промежуточным звеном, после которого запрос маршрутизируется к нужной БД, а фактически является «ключом» к общей БД. При этом каждая ячейка отвечает исключительно за небольшое подмножество всех данных сервиса.
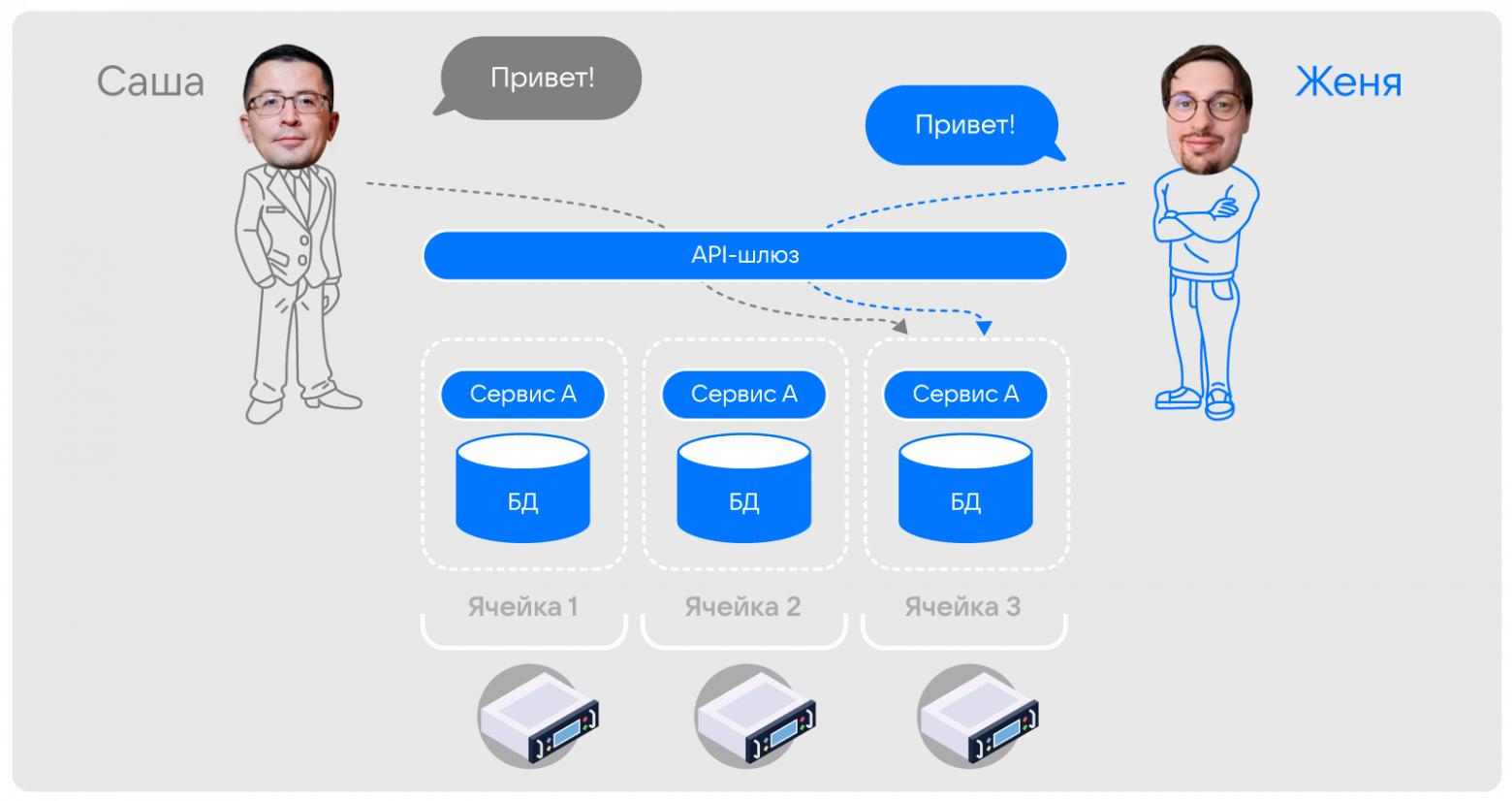
Именно подобным образом организована наша система. Фактически мы решаем задачу шардирования не на уровне БД, а на уровне управления трафиком между сервисами.
Причем для нас не критично, что с каждым сервисом поднимается полноразмерный экземпляр БД, что в других проектах может быть избыточно. Главное, что мы существенно повышаем удобство управления продуктом или системой — при обслуживании нагрузки от миллионов пользователей для нас это приоритетнее.
Примечательно, что изначально мы планировали выделять подобные ячейки на каждый отдельный сервис — например, одну большую ячейку на один сервер или ВМ. Но со временем столкнулись с тем, что поддерживать большие ячейки сложно, поэтому в результате пришли к реализации с множеством ячеек небольшого размера. Причем при большой нагрузке на ячейку и «перегреве» сервера, где развернута ячейка, нам достаточно просто перенести ячейку на другой сервер. Сценариев, при которых нужен решардинг (а это весьма дорогая операция), в таком случае минимум. Отчасти это похоже на принцип работы VShard в Tarantool.
Что под капотом у нашей системы
В момент создания VK Teams еще в качестве внутреннего корпоративного мессенджера (около 10 лет назад), для него было создано самописное хранилище KUST (Customizable Storage). Это Embedded persistent key-value read-optimized data store. Оно чем-то напоминает RocksDB, но оптимизировано под чтение и работу с HDD-дисками, выполняет дамп логов потоково, а не по расписанию.
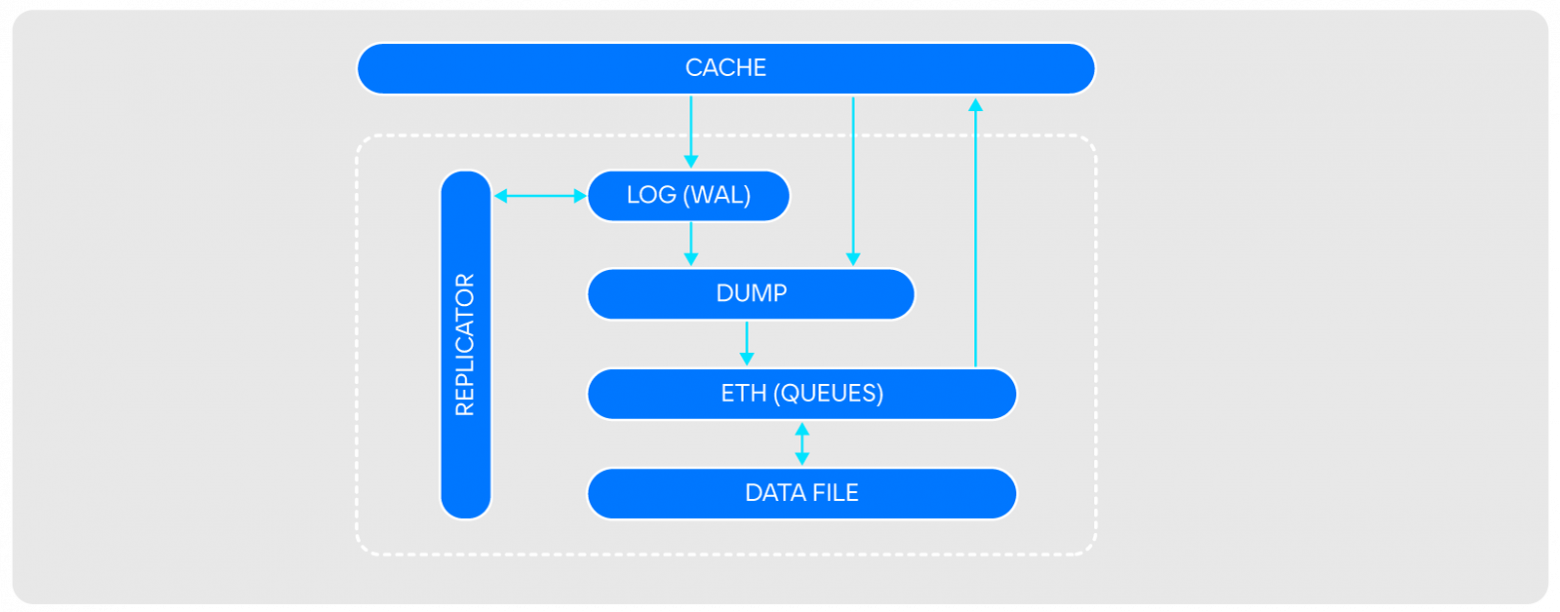
KUST и сейчас позволяет нам надежно хранить терабайты данных, но со смещением фокуса на on-prem нам было важно, чтобы не только мы, но и наши клиенты могли управлять СУБД, находящимися «под капотом». К тому же в ряде сценариев мы хотели повысить скорость и улучшить пользовательский опыт. Поэтому мы начали смотреть в сторону готовых вендерских решений.
Поэтому уже сейчас большинство внутренних сервисов переведено на Tarantool — решение класса Middleware for data, которое сочетает в себе сервер приложений, гибридное хранилище с гибкой схемой данных и мощные средства масштабирования.
Миграция на Tarantool (который также входит в экосистему VK) дала нам возможность без снижения надежности хранения существенно повысить скорость работы хранилища, получить лучшую управляемость, что особенно важно для On-premises-решений, управление которыми в большей степени остается на стороне пользователя.
Базу данных мы выбрали. Следующий вопрос — как обеспечить коммуникацию сервисов.
Для коммуникации сервисов внутри VK Teams мы взяли за основу бинарный протокол обмена сообщениями между сервисами IPROTO (созданный Mail.ru) и добавили к нему контроллер Ctlr, который позволил нам реализовать функционал Service Discovery и обеспечить контроль над потоками данных между сервисами. Так появился IPROS.
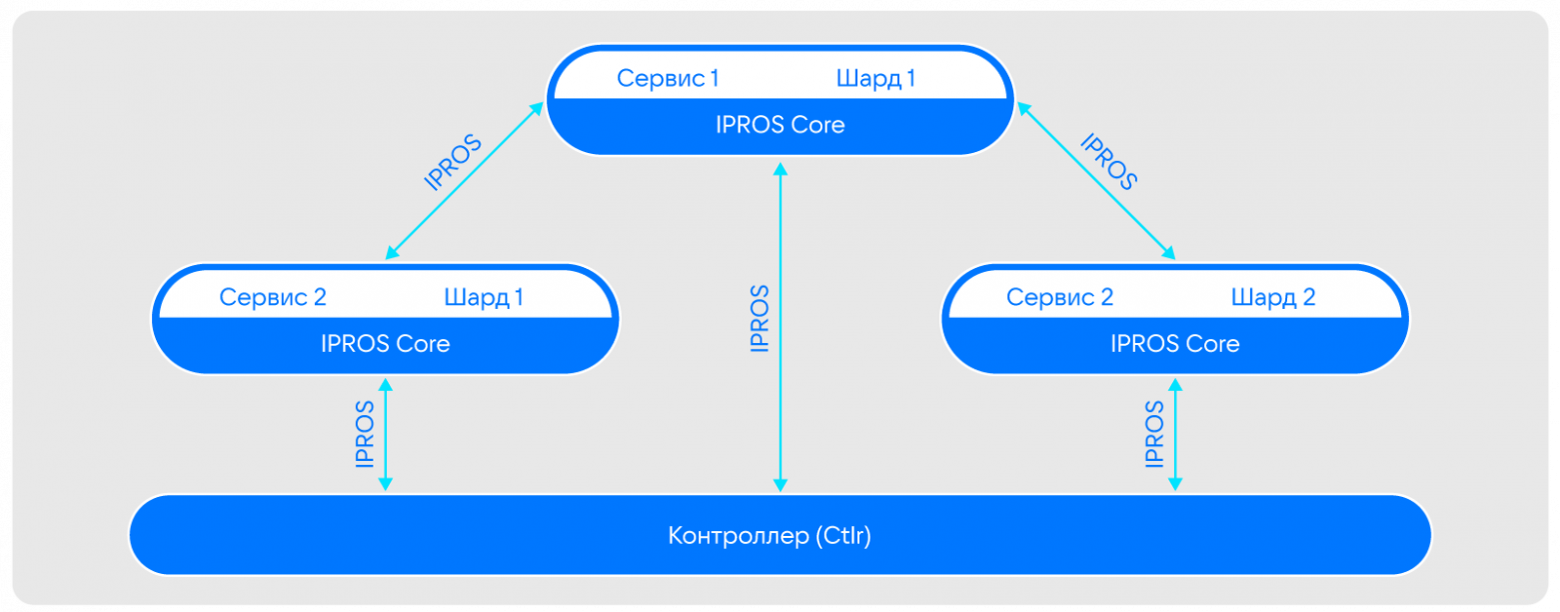
Контроллер хранит разряженную карту шардирования. Его задача:
мониторить состояние всех ячеек и сервисов в них;
управлять ими: менять топологию, разделять, переносить и так далее.
Примечательно, что через контроллер не идет трафик. Поэтому, например, если во время решардинга контроллер станет недоступен, это не скажется на работоспособности всей системы — решардинг завершится и без него, а запросы к старому сервису будут автоматически (этим же старым сервисом) перенаправляться к новому. Таким образом постепенно все сервисы, которым нужны переехавшие данные, узнают о том, что они теперь находятся по новому адресу. Это гарантирует надежность системы.
Теперь об обеспечении отказоустойчивости.
Пара «сервис — БД» неделима и всегда имеет реплику, которая находится в активном состоянии и готова в любой момент взять на себя нагрузку. Такая реализация гарантирует доступность и устойчивость в разных сценариях. Например, при переносе ячейки с одного сервера на другой:
реплика ячейки в фоне переносится на новый сервер (необязательный шаг);
контроллер дает команду flip основной ячейке;
основная ячейка переключает базу в режим Read Only, все входящие запросы блокируются (здесь мы полагаемся на прозрачную политику ретраев, согласно которой, рано или поздно запрос будет обработан);
основная ячейка отправляет во вторичную команду sink с идентификатором лога, который пришел последним;
при получении лога с указанным идентификатором ячейка-реплика на новом сервере переводит свою базу в readwrite, отправляет команду flop в контроллер, и подтверждение исходной ячейке, которая, в свою очередь, тоже отправляет flop в контроллер.
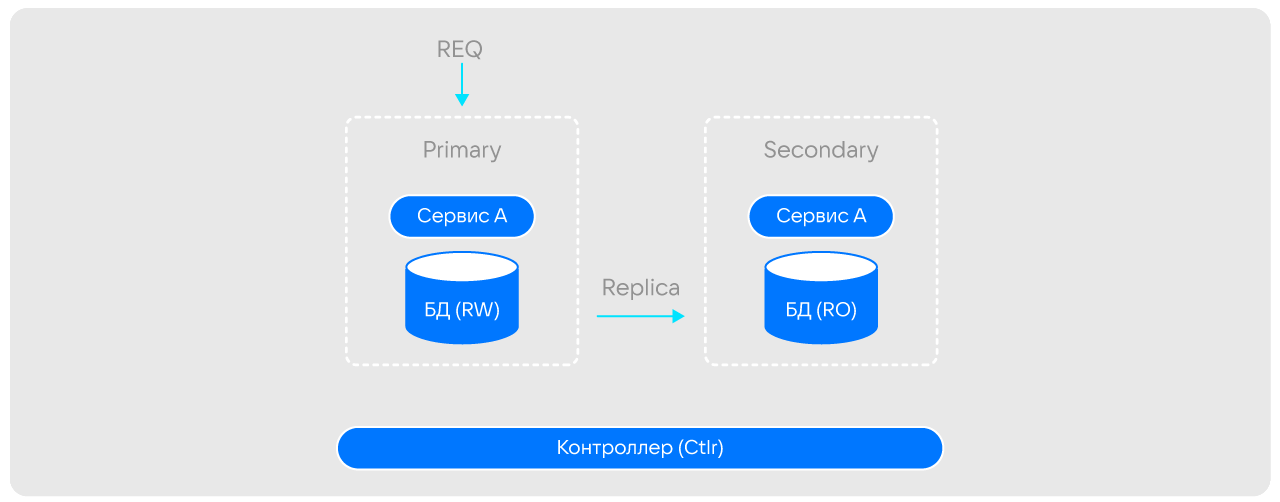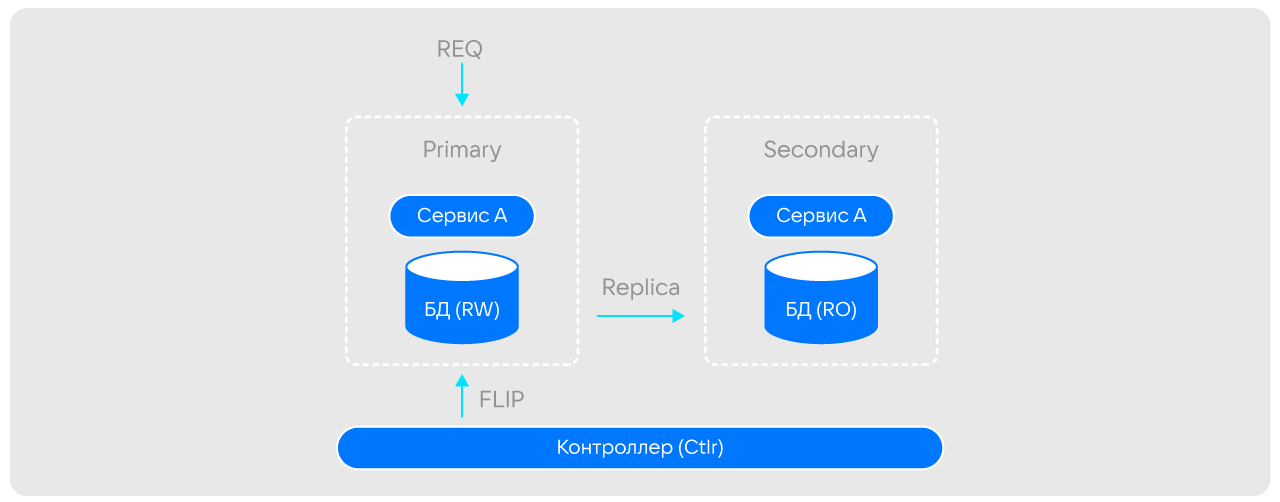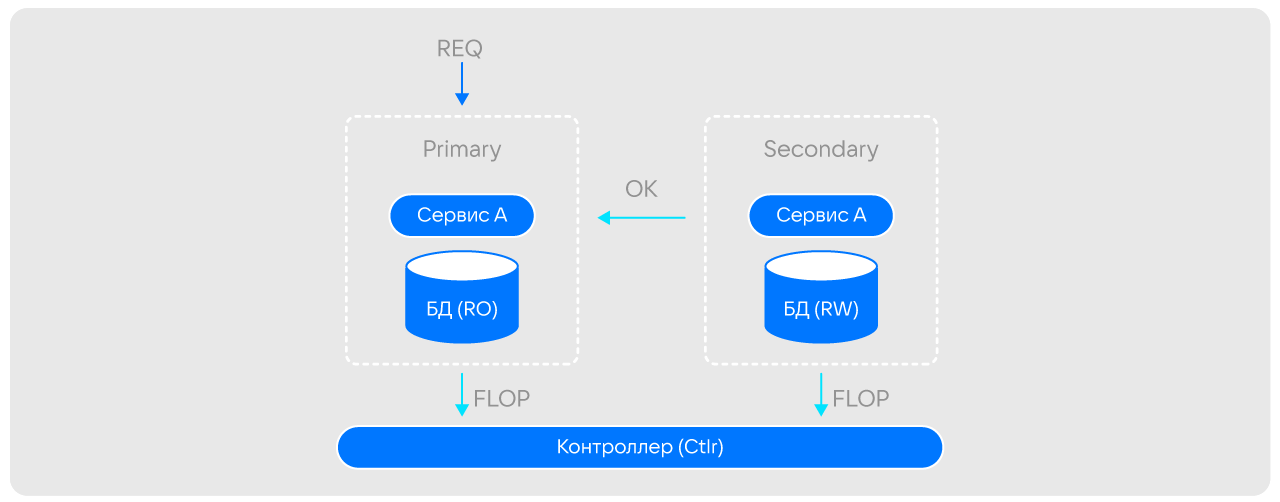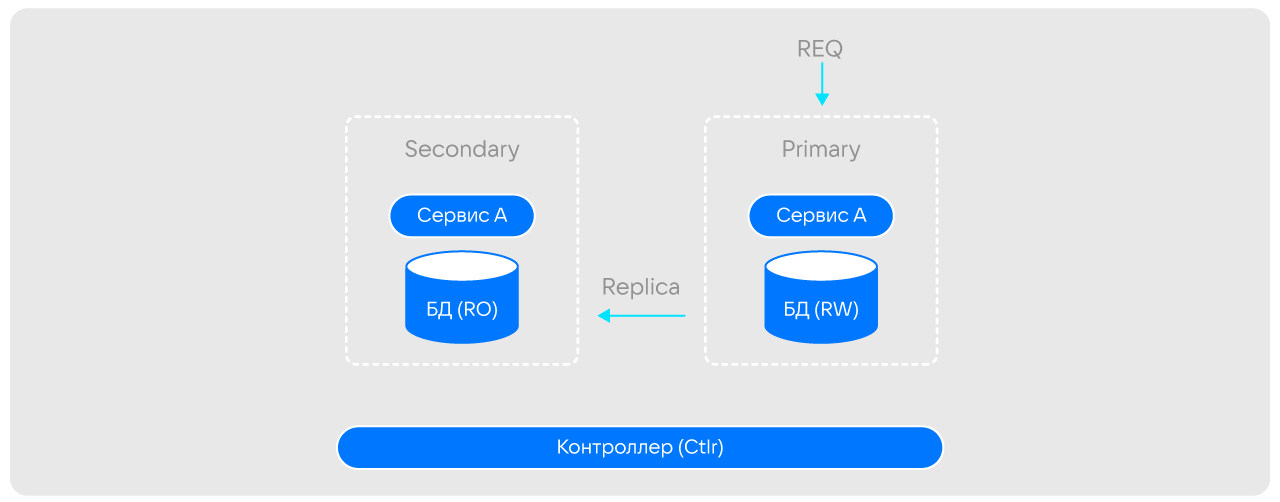
После этого ячейка-реплика остановится основной и начинает принимать все входящие запросы. На весь процесс уходит всего несколько сотен миллисекунд.
Важно, что даже сбой на уровне контроллера не снизит отказоустойчивость системы — если запросы придут в старую ячейку, она их перенаправит в новый главный узел.
Что нам дает работа с ячейками
Работа с ячейками, несмотря на упомянутую избыточность в некоторых моментах, дает нам ряд существенных преимуществ.
Простота управления. Управлять одной сущностью проще. К тому же, в нашей реализации всего одна степень свободы (при необходимости увеличения достаточно выполнить шардирование), что исключает разночтения.
Локализованность контекста и проблем. Всегда известно, куда в каждом конкретном случае поступает запрос. В случае поломки или сбоев, всегда понятно, где локализуется проблема — не надо исследовать весь кластер. Более того, при такой реализации любая ошибка потенциально затрагивает только очень ограниченное количество пользователей или чатов.
Минимизация влияния сетевой инфраструктуры. Сервис и база данных находятся близко друг к другу, что исключает влияние любых сетевых эффектов на доступность или скорость компонентов ячейки.
Повышенная безопасность данных. В связи с физической «развязанностью» системы, при взломе системы злоумышленник теоретически получает доступ только к одной ячейке, которая хранит очень ограниченный набор информации и не имеет доступа ко всем данным. Это уменьшает потенциальный ущерб.
От мессенджера к супераппу
Сейчас наш мессенджер всё также доступен, но уже в качестве отдельного сервиса в рамках супераппа, из окна которого можно, не теряя контекста, обмениваться файлами, назначать встречи, ставить задачи и определять ответственных, делиться событиями и не только.
Архитектура супераппа значительно сложнее — помимо прочего, она включает и сервисы звонков, оргструктуры, почты, календаря и другие.
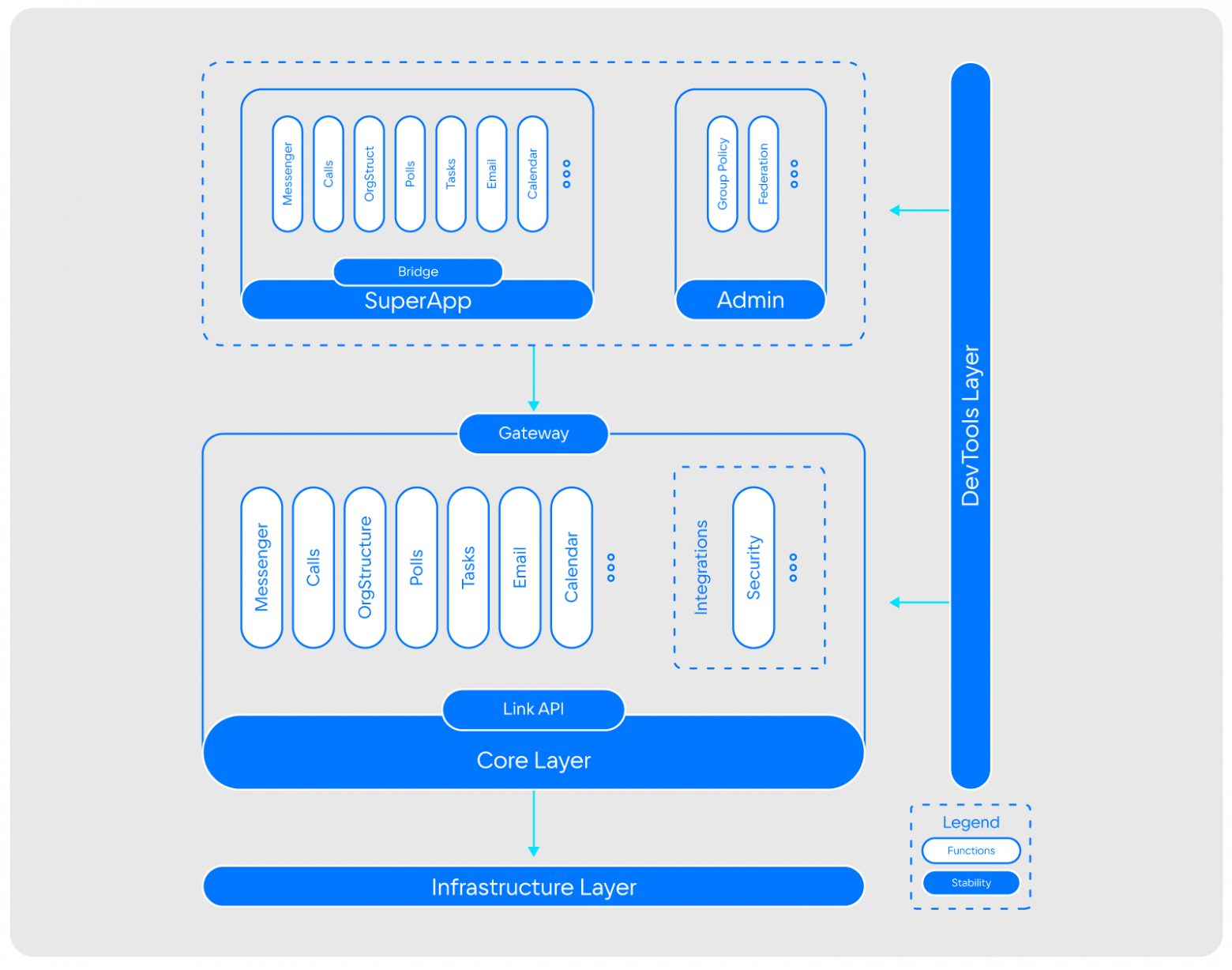
Естественно, при переходе к супераппу, с ростом функциональности решения, изменились пул задач, который нам приходится решать, и архитектура инструмента, особенно в части возможностей интеграции с системами заказчика.
Сейчас мы делаем фокус на модульность и расширяемость при неизменной стабильности и масштабируемости.
Перед изменением архитектуры мы прошли организационные изменения — сделали команды модульными и независимыми, по-новому выстроили коммуникации внутри команд, унифицировали подходы и стек, согласовали общие практики.
Это повлекло и изменения на уровне архитектуры. Так, если раньше мы смотрели исключительно в сторону нагрузки, трафика и отказоустойчивости, то сейчас, наряду с обеспечением упомянутых параметров, в пул задач наших архитекторов также стало входить:
корректное выстраивание доменов;
помощь продактам в корректном распределении бизнес-инициатив по командам;
выстраивание взаимодействия между командами на техническом уровне через API, шины и другие компоненты.
То есть видение архитектора сильно меняется.
Выводы на основе нашего опыта
При построении приложения важна не только закладываемая в него функциональность, но и архитектура, которая во многом предопределяет возможности расширения, интеграции, модернизации, параметры стабильности и отказоустойчивости всей системы. На своем опыте мы убедились, что не всегда стоит идти по общепринятому, типовому пути. Архитектура — это всегда компромиссы, и нужно внимательно смотреть, можно ли с ними мириться в каждом конкретном случае.
Более того, важно понимать, что оптимизация должна затрагивать не только приложение — новые вызовы, требования и возможности должны учитываться и на уровне команд. Так, коммуникации должны меняться (привет закону Конвея), и мы как архитекторы должны иначе смотреть на свою роль.
Отчасти именно совместная адаптация продукта и команды помогли нам пройти путь от внутреннего корпоративного мессенджера до супераппа, которым пользуются сотни команд и миллионы людей.
