«Под капотом» СХД Huawei: фирменные технологии, которых нет у других
Представленные на рынке системы хранения данных, в основной своей массе, мало чем отличаются друг от друга, ведь многие вендоры заказывают оборудование едва ли не у одних и тех же ODM-производителей. У нас же почти все свое, начиная от шасси и заканчивая контроллерами, технологиями типа RAID 2.0+ и софтом.

Под катом немного деталей про то, что такого необычного может быть в каждом из узлов системы хранения данных.
Что интересного на уровне модуля
Конструкционно все современные СХД от любого производителя выглядят одинаково: во фронтальную часть стального коробчатого шасси устанавливаются контроллеры, в тыльную — интерфейсные модули. Есть еще блоки питания и вентиляции. Казалось бы, все привычно и стандартно. Но на самом деле мы внедрили в эту парадигму много всего интересного.
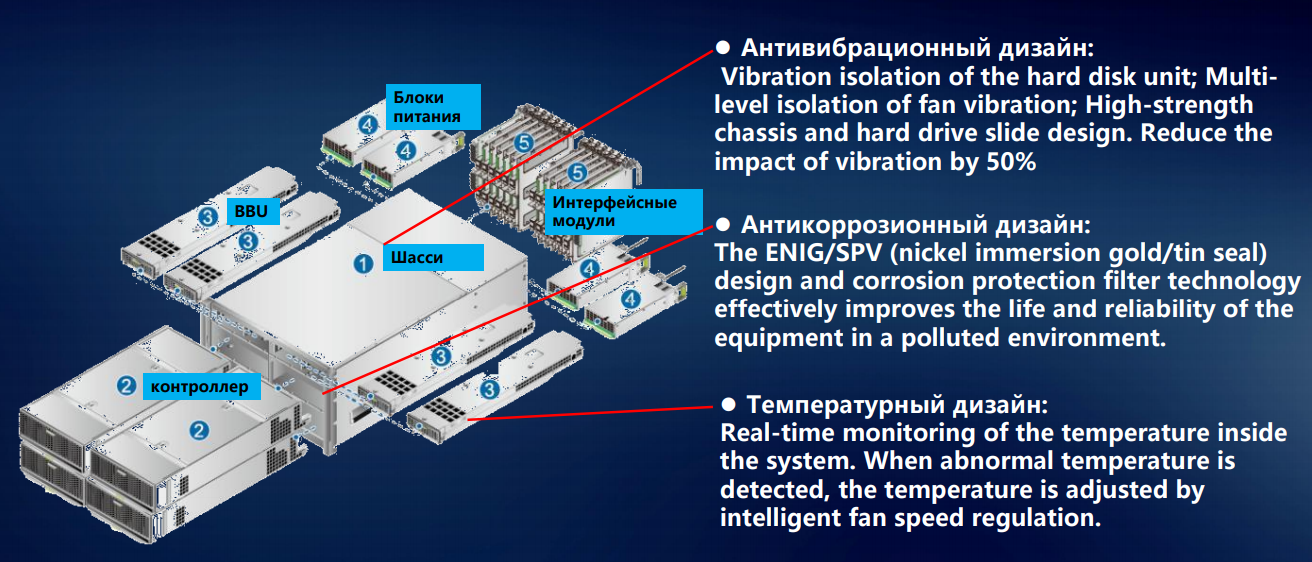
Начнем с монтажа элементов системы хранения в шасси. Магнитных 3,5-дюймовых дисков в СХД становится меньше, начинают преобладать гибридные системы и all-flash. Но даже несколько дисковых накопителей с частотой вращения шпинделя до 15 тысяч оборотов в минуту создают вибрацию, которую нельзя не учитывать. У нас на этот случай выработан целый свод рекомендаций — как распределять по дисковым полкам магнитные накопители с различными параметрами.
Пусть даже на какие-то доли процентов, но на надежность это влияет. А в масштабе крупного ЦОДа доли процентов на один накопитель превращаются в ощутимые показатели отказов и сбоев. Чтобы вибрация отдельных дисков в меньшей степени передавалась через жесткую конструкцию шасси, салазки под диски мы оборудуем резиновыми или металлическими демпферами. Чтобы нейтрализовать еще один источник вибрации в СХД — модули вентиляции — ставим двунаправленные вентиляторы, а все вращающиеся элементы изолируем от корпуса шасси.
Для шпиндельных накопителей минимальная тряска — уже проблема: головки начинают сбиваться, производительность существенно падает. SSD — другое дело, вибрации они не боятся. Но надежная фиксация компонентов по-прежнему важна. Взять процесс доставки: ящик могут уронить или небрежно швырнуть, поставить боком или вверх тормашками. Поэтому у нас все компоненты СХД закрепляются строго в трех измерениях. Это исключает возможность их смещения при транспортировке, предохраняет разъемы от выскакивания из гнезд при случайном ударе.

Когда-то давно мы начинали с разработки вычислительной техники для телеком-индустрии, где стандарты работоспособности по температуре и влажности традиционно высоки. И мы перенесли их и на другие направления: металлические детали СХД не окисляются даже при повышенной влажности — за счет применения никелирования и оцинковки.
Тепловой дизайн наших СХД разрабатывался с упором на равномерность распределения температуры по шасси — чтобы не допустить ни перегрева, ни слишком сильного охлаждения какого-либо угла дисковой полки. Иначе не избежать физической деформации — пусть даже незначительной, но все-таки нарушающей геометрию и способной привести к сокращению срока работы оборудования. Таким образом выигрываются какие-то доли процента, но на общую надежность системы это все-таки влияет.
Полупроводниковые тонкости
Важные компоненты СХД мы дублируем: если что-то выйдет из строя — всегда есть подстраховка. К примеру, модули питания у младших моделей работают по схеме 1+1, у более солидных — 2+1 и даже 3+1.

Контроллеры, которых в системе хранения как минимум два (одноконтроллерные системы мы не поставляем) тоже резервируются. В СХД 6800-й и более старших серий резервирование производится по схеме 3+1, в младших моделях — 1+1.
Зарезервирован даже модуль управления (management board), который непосредственно на работу системы не влияет, а нужен только для изменения конфигурации и мониторинга. Кроме того, любые интерфейсные платы расширения для СХД у нас продаются только парами, чтобы у клиента имелся резерв.
Все компоненты — БП, вентиляторы, контроллеры, менеджмент-модули и т.п. — оснащены микроконтроллерами, способными реагировать на определенные ситуации. Например, если вентилятор начинает сам по себе сбавлять обороты, на управляющий модуль посылается сигнал тревоги. В результате заказчик имеет полную картину состояния СХД — и может при необходимости заменить некоторые компоненты самостоятельно, не дожидаясь прибытия нашего сервисного инженера. А если политика безопасности заказчика позволяет, мы настраиваем контроллеры так, чтобы они передавали информацию о состоянии железа в нашу техподдержку.
Свои чипы лучше и понятнее
Мы — единственная компания, разрабатывающая собственные процессоры, чипы и контроллеры твердотельных накопителей для своих СХД.

Так, в некоторых моделях в качестве основного процессора системы хранения (Storage Controller Chip) мы используем не классический Intel x86, а ARM-процессор HiSilicon, нашего дочернего предприятия. Дело в том, что ARM-архитектура в СХД — для расчета тех же RAID и дедупликации — показывает себя лучше, чем стандартная х86-я.
Наша особая гордость — чипы для SSD-контроллеров. И если серверы у нас могут комплектоваться полупроводниковыми накопителями сторонних производителей (Intel, Samsung, Toshiba и др.), то в системы хранения данных мы устанавливаем только SSD собственной разработки.

Микроконтроллер модуля ввода-вывода (smart I/O чип) в системах хранения — тоже разработка HiSilicon, как и Smart Management Chip для удаленного управления хранилищами. Использование собственных микросхем помогает нам лучше понимать, что происходит в каждый момент времени с каждой ячейкой памяти. Именно это позволило нам свести к минимуму задержки при обращении к данным в тех же СХД Dorado.

Для магнитных дисков с точки зрения надежности чрезвычайно важен постоянный мониторинг. В наших СХД поддерживается система DHA (Disk Health Analyzer): диск сам непрерывно фиксирует, что с ним происходит, насколько хорошо он себя чувствует. Благодаря накоплению статистики и построению умных предиктивных моделей удается предсказать переход накопителя в критическое состояние за 2–3 месяца, а не за 5–10 дней. Диск еще «живой», данные на нем в полной безопасности –, но заказчик уже готов его заменить при первых признаках возможного сбоя.
RAID 2.0+
Отказоустойчивый дизайн в СХД мы продумали и на уровне системы. Наша технология Smart Matrix представляет собой надстройку поверх PCIe — эта шина, на основе которой реализованы межконтроллерные соединения, особенно хорошо подходит для SSD.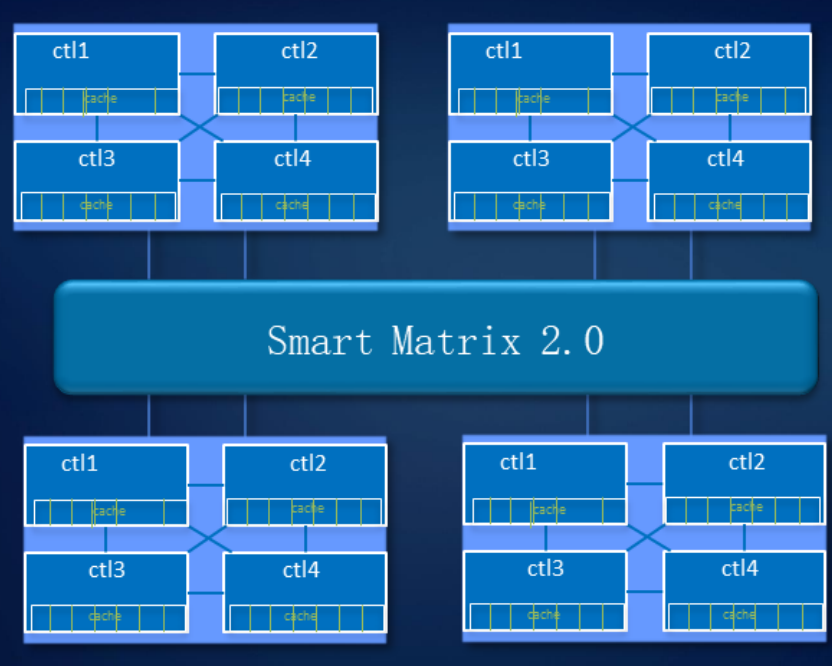
Smart Matrix обеспечивает, в частности, 4-контроллерный full mesh в нашем СХД Ocean Store 6800 v5. Для того чтобы каждый контроллер имел доступ ко всем дискам в системе, мы разработали особый SAS-бэкэнд. Кэш, естественно, зеркалируется между всеми активными в данный момент контроллерами.

Когда происходит сбой контроллера, сервисы с него быстро переключаются на контроллер зеркала, а оставшиеся контроллеры восстанавливают взаимосвязь, чтобы зазеркалить друг друга. В то же время данные, записанные в кэш-память, имеют зеркальный резерв для обеспечения надежности системы.

Система выдерживает отказ трех контроллеров. Как показано на рисунке, при отказе элемента управления A данные кэша контроллера B будут выбирать контроллер C или D для зеркального отображения кэша. Когда выходит из строя контроллер D, контроллеры B и C делают зеркальное отображение кэша.

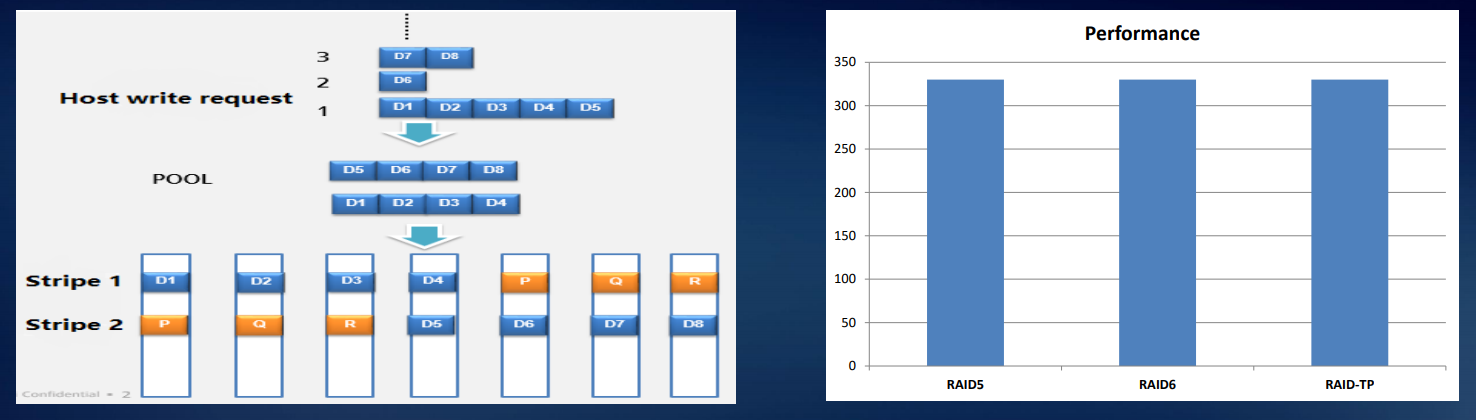
Система распределения данных RAID 2.0 — стандарт для наших СХД: виртуализация на уровне дисков давно пришла на смену безыскусному поблоковому копированию содержимого с одного носителя на другой. Все диски группируются в блоки, те объединяются в более крупные конгломераты двухуровневой структуры, а уже поверх ее верхнего уровня строятся логические тома, из которых составляются RAID-массивы.

Основное преимущество такого подхода — сокращенное время перестроения массива (rebuild). Кроме того, в случае выхода из строя диска перестроение производится не на стоявший все это время «под паром» (hot spare) диск, а на свободное место во всех используемых дисках. На рисунке ниже в качестве примера показаны девять жестких дисков RAID5. Когда жесткий диск 1 вышел из строя, данные CKG0 и CKG1 повреждены. Система выбирает CK для реконструкции случайным образом.

Нормальная скорость восстановления RAID составляет 30 МБ / с, поэтому для восстановления данных объемом 1 ТБ требуется 10 часов. RAID 2.0+ сокращает это время до 30 минут.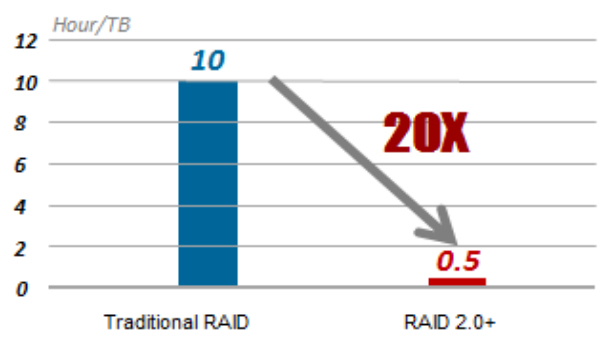
Нашим разработчикам удалось добиться равномерного распределения нагрузки между всеми шпиндельными накопителями и SSD в составе системы. Это позволяет раскрыть потенциал гибридных СХД гораздо лучше, чем привычное использование твердотельных накопителей в роли кэша.

В системах класса Dorado мы реализовали так называемся RAID-TP, массив с тройной четностью. Такая система продолжит работать при одновременном выходе из строя любых трех дисков. Это повышает надежность по сравнению с RAID 6 на два десятичных порядка, с RAID 5 — на три.
RAID-TP мы рекомендуем для особо критичных данных, тем более что благодаря RAID 2.0 и высокоскоростным flash-накопителям на производительность это особого влияния не оказывает. Просто нужно больше свободного пространства для резервирования.

Как правило, системы all-flash используют для СУБД с маленькими блоками данных и высоким IOPS. Последнее не очень хорошо для SSD: быстро исчерпывается запас прочности ячеек памяти NAND. В нашей реализации система сперва собирает в кэше накопителя сравнительно крупный блок данных, а затем целиком записывает его в ячейки. Это позволяет снизить нагрузку на диски, а также в более щадящем режиме вести «сборку мусора» и высвобождение места на SSD.
Шесть девяток
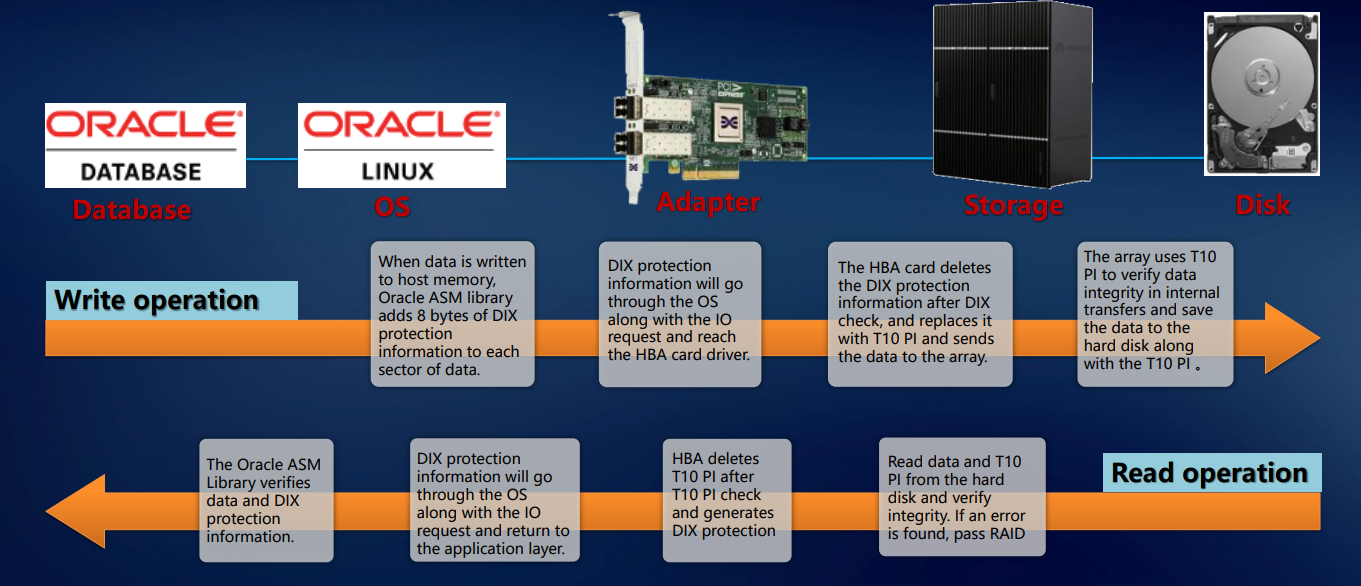
Перечисленное выше позволяет говорить об отказоустойчивости наших систем на уровне всего решения. Проверка реализуется на уровне приложения (например, СУБД Oracle), операционной системы, адаптера, СХД — и так вплоть до диска. Такой подход гарантирует, что ровно тот блок данных, который пришел на внешние порты, безо всяких повреждений и потерь будет записан на внутренние диски системы. Это подразумевает enterprise-уровень.
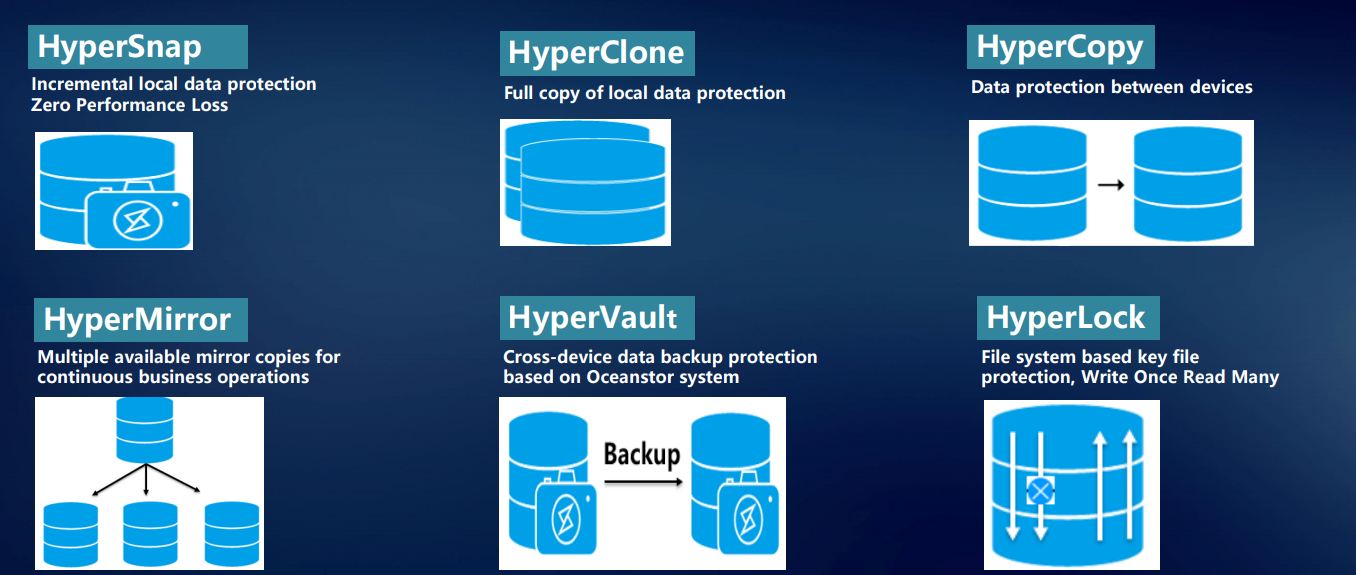
Для надежного хранения данных, их защиты и восстановления, а также быстрого доступа к ним мы разработали целый ряд фирменных технологий.

HyperMetro — наверное, самая интересная разработка последних полутора лет. Готовое решение на базе наших систем хранения для построения отказоустойчивого метро-кластера внедряется на уровне контроллера, никаких дополнительных шлюзов или серверов, кроме арбитра, оно не требует. Реализуется просто лицензией: две CХД Huawei плюс лицензия — и это работает.

Технология HyperSnap обеспечивает непрерывную защиту данных без потери производительности. Система поддерживает RoW. Для предотвращения потери данных на СХД в каждый конкретный момент используется множество технологий: различные снэпшоты, клоны, копии.
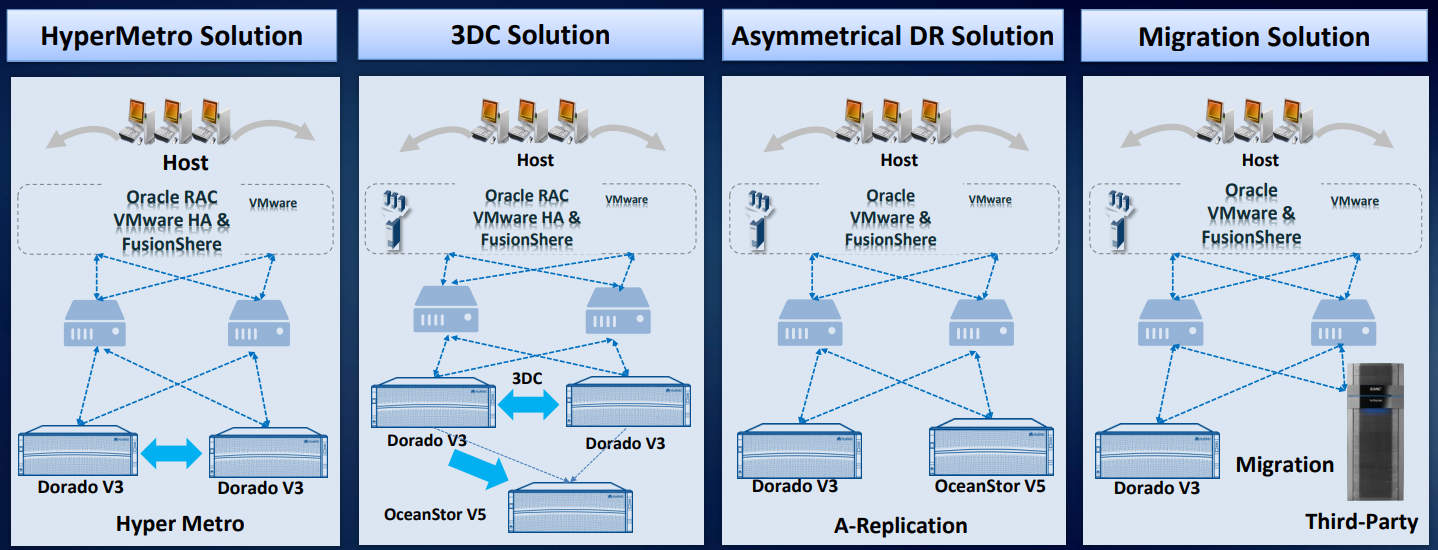
На основе наших СХД разработано и проверено на практике как минимум четыре решения для аварийного восстановления данных.
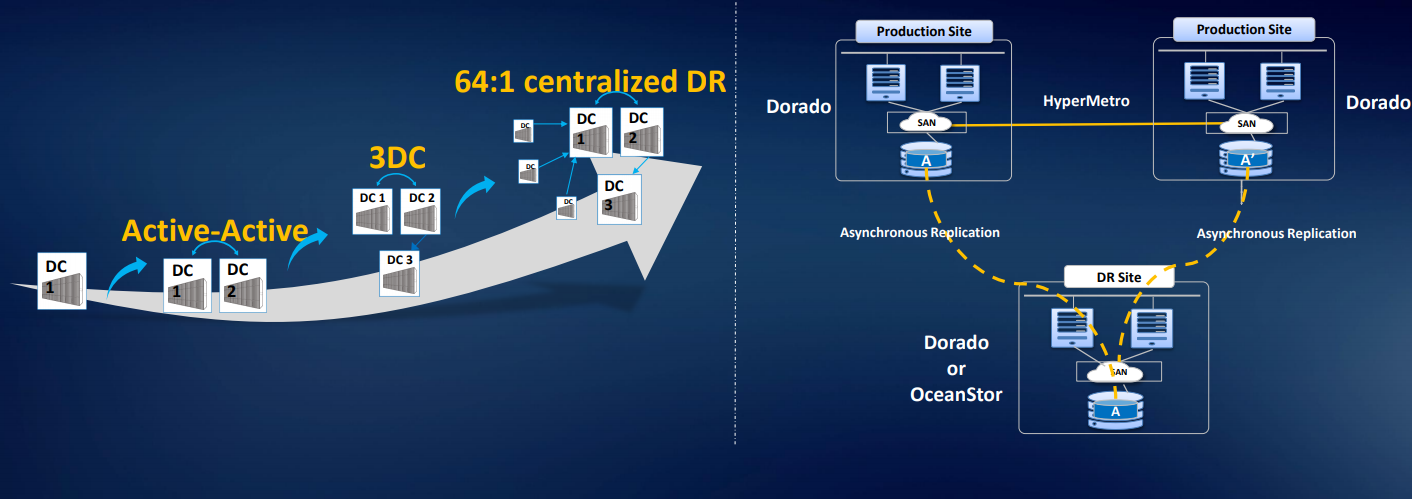
Еще у нас есть решение для трех дата-центров 3DC Ring DR Solution: два ЦОДа в кластере, на третий идет репликация. Можем организовать организована асинхронную репликацию или миграцию со сторонних массивов. Имеется лицензия smart virtualization, благодаря чему можно использовать тома с большинства стандартных массивов с доступом по FC: Hitachi, DELL EMC, HPE и т.д. Решение реально отработанное, аналоги на рынке встречаются, но стоят дороже. Есть примеры использования в России.
В итоге на уровне всего решения можно получить надежность шесть девяток, а на уровне локальной СХД — пять девяток. В общем, мы старались.
Автор: Владимир Свинаренко, старший менеджер по IT-решениям Huawei Enterprise в России
