Плохие практики разработки, которые до сих пор встречаю в стартапах

Привет, я Виктор. Двенадцать лет назад я пришел в веб-студию в Самаре. Так начался мой путь в разработке. У нас не было гита, CI/CD, тестовых стендов и много чего еще. Я видел, как это мешало развитию команды и бизнеса. Приходилось на ощупь собирать грабли, открывать для себя хорошие практики и внедрять их. С тех пор успел поработать старшим разработчиком в российском финансовом холдинге и немецком b2b-стартапе. Был тимлидом в фудтех-проекте, СTO в образовательных стартапах для российского и латиноамериканского рынка — и почти везде поначалу натыкался на похожие проблемы. Недавно переехал в Израиль, стал консультировать стартап. И что бы вы думали…
Ниже собрал примеры из практики, как мы стреляем себе и бизнесу в ногу, хотя казалось бы, цель в стартапе — «бежать быстро». И выложил схему, как можно это починить, которой сам обычно пользуюсь. Она и побудила меня написать этот пост. Найти схему можно в конце поста.
Нет Git, разработка ведется на продакшн-сервере
Классическая история, когда проект стартует с одного разработчика. Он что-то делает, заливает по FTP, тестирует и правит прямо на проде. Может быть, где-то и есть репозитории, но они пустуют или не обновляются.
Затем бизнес масштабируется, нанимаются разработчики. И тут случается интересное. Например, как-то раз такой товарищ, работавший один и без гита, затер пару дней моей работы. Благо, я привык пользоваться системой контроля версий в любых проектах и ситуациях. Вопрос, что было бы с его кодом, затри я его… Чтобы продать команде стартапа идею «гит нужен, он даст бэкапы и поможет масштабироваться», я сделал презентацию и выступил на пятничной встрече за пиццей. И помогло. Когда прод упал, а второй разработчик был не на связи, я хотя бы смог понять, что он менял. И относительно быстро исправить ошибку.
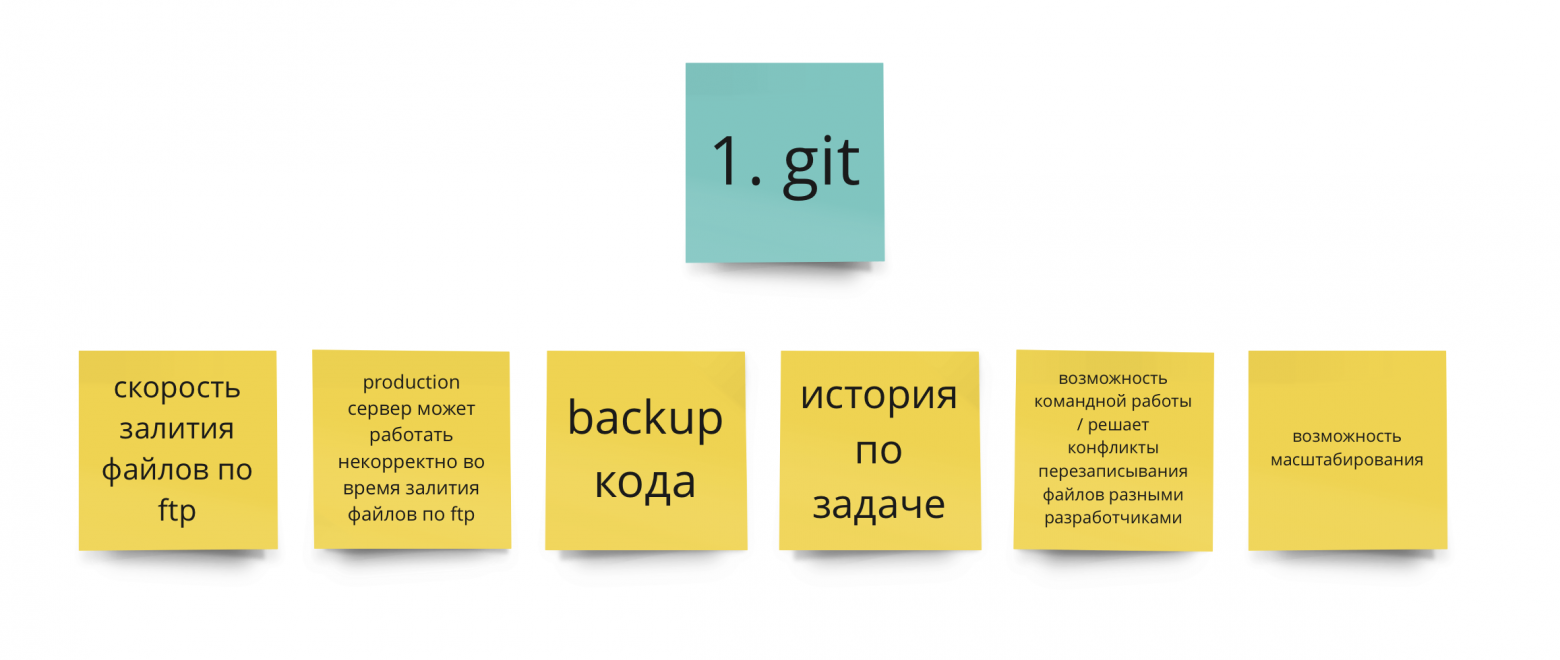 Зачем нужен git?
Зачем нужен git?
Нет код-ревью
Я пришел в проект, где из прошлой команды уже никого не осталось. Встала задача сменить один вид пагинации на другой. Казалось бы, делов, — зайди в функцию и поменяй за 2 минуты. Но замену сделать нельзя, потому что предшественник использовал хитрую схему: копипасту кода, в которую каждый раз вносил какие-то изменения. Итого, у нас 200 вхождений и геморрой с их правкой вручную на 3 дня. Думаю, ревью от любого коллеги эта хитрая копипаста не прошла бы.
Но хорошо, тогда у меня было хотя бы время посидеть, подумать и сделать лучше. Вот пример, когда отсутствие ревью оказалось критичным. Новый проект. CRM, основа всего бизнеса, тормозит. Нужно чинить, менеджмент давит. Разработчик решает проигнорировать стандартные процессы: код-ревью, тестирование, запуск автотестов. Просто сразу пушит в гит и релизит. CRM падает совсем. Оказалось, в условиях стресса, когда «надо прям вот сейчас», человек допустил ошибку в коде. Гораздо безопаснее, если бы коммит посмотрел кто-то еще. Имхо, в критических условиях можно проигнорировать автотесты, если они крутятся долго. Но не стоит игнорировать код-ревью.
Нет CI/CD
На одном проекте, куда я пришел, ребята релизили вручную через git pull. Сайт при этом регулярно падал. Например, как-то раз попросту не сделали установку пакетов. У поддержки, бизнеса и пользователей копились вопросики к команде. После настройки CI/CD ситуация магически исправилась.
В другой раз наличие git и CI/CD сильно помогло нам то самое «релизить быстро». Понадобилась немецкая версия сайта, причем срочно и чисто как лендинг для показа потенциальным инвесторам. Имея автоматизированный процесс развертывания и создания новых тестовых серверов на базе CI/CD, мы быстро обрезали все ненужное, подняли отдельные базы, залили переводы — и вуаля — превратили тестовый стенд в сайт для показа инвесторам.
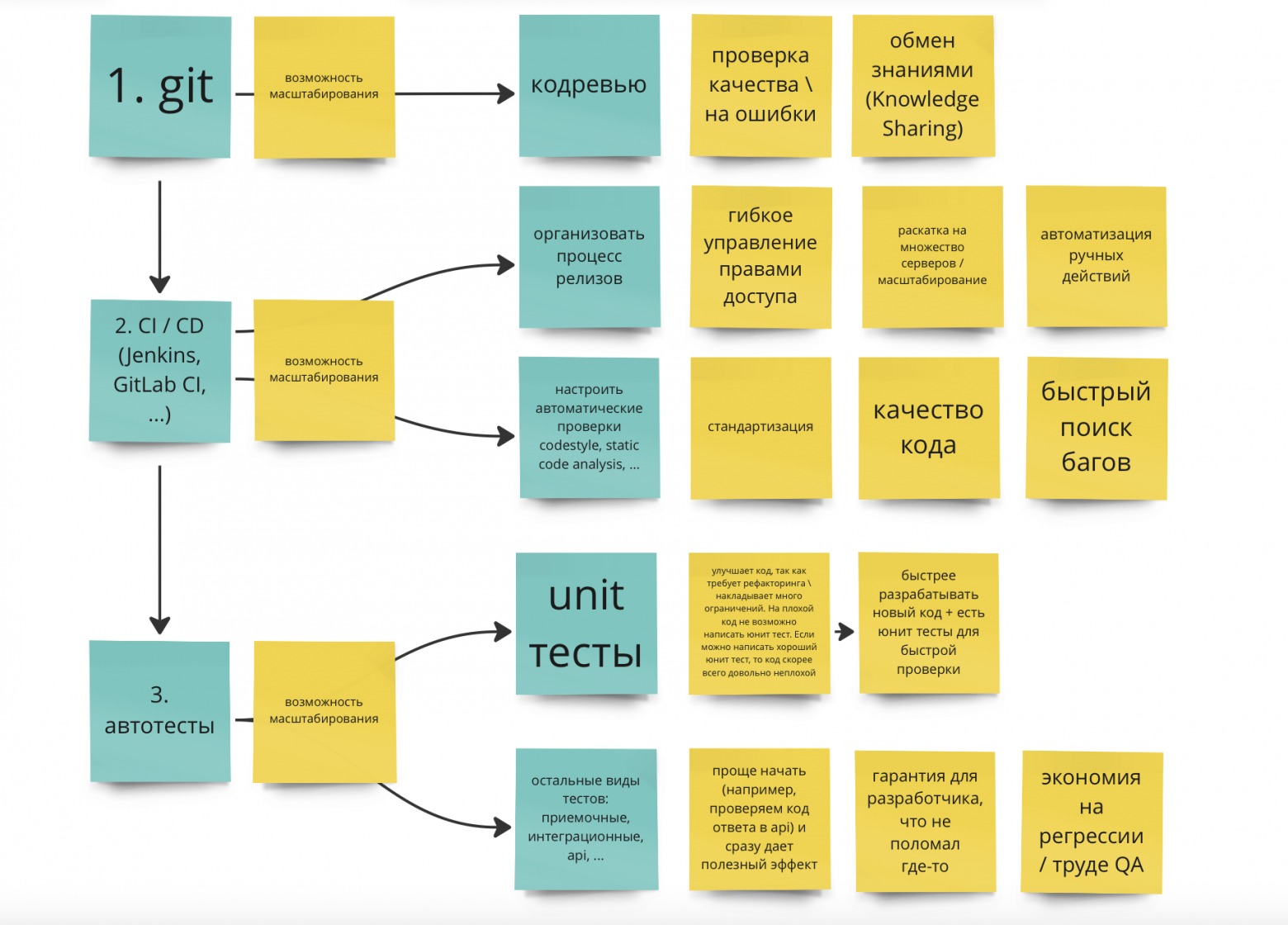 Плюсы от CI / CD
Плюсы от CI / CD
Нет прозрачного процесса постановки задач
Моя «любимая» история — постановка задач методом развести тред на 150 сообщений в чате. Или в личке
.

Как-то у нас был общий чат с колл-центром. И был QA, в задачи которого входило фильтровать информацию в чате, уточнять детали и если действительно всплывал баг — заводить задачу в трекере. Но сотрудники колл‑центра быстро сообразили, что если писать в чат, то им будут по всей форме задавать всякие уточняющие вопросы, просить скриншотов, урлов и других «сложных» вещей. А вот если писать напрямую «тестировщику Жене», он в половине случаев поправит что‑то быстро через админский доступ.
QA был полностью уверен, что делает доброе дело, а на деле из‑за неизвестных другим багов и масштабов ручной работы мы теряли деньги. Все вскрылось после ухода человека из компании. На нас обрушился шквал новой информации и мелких, но противных багов, которые пришлось срочно исправлять.
А как‑то раз удалось такое пресечь. Появилась «важная» задача, интеграция с большим клиентом. Менеджер в обход всех процессов пошел к разработчику ставить задачу голосом: «Не надо даже думать, просто сделай, как я говорю». Благо, команда уже научилась работать по процессам. Обсудили на дейлике, внесли в трекер. Пошли исследовать и задавать вопросы. Оказалось, методом «не думая» мы могли слить всю коммерческую базу.
Нет правила »1 задача=1 ветка в коде»
Мы делали новый большой кусок системы, который уже ждали платящие клиенты. Запуск должен был принести нам много денег. Каждый день задержки, наоборот, эти деньги съедал. Вместе с командой декомпозировал все на отдельные максимально независимые куски, чтобы мы могли зарелизить функционал как можно быстрее, а различные хотелки и доделки пилить уже в процессе.
Создал в трекере 10 задач, но ребята решили делать их в одной ветке. В итоге дедлайн был вчера, но зарелизить мы не можем: в одной из некритичных задач критичный баг, который быстро не исправишь. При этом, если бы не общая ветка, мы без проблем могли бы зарелизить остальные 9 задач — и запустить систему. После разбора команда приняла подход. Но что интересно, когда я переходил в другую команду, нам пришлось проходить подобный «восхитительный» опыт заново.
По мере роста не заводятся автотесты
Некоторые стартапы живут долго. И копят легаси. Сам я пришел к автотестам как раз потому, что мне было сложно тестировать проекты с историей, к которым я присоединялся. Хотелось автопроверок, чтобы быть уверенным, что моя правка ничего не сломает.
Но был в одном проекте разработчик, который вместо покрытия легаси автотестами хотел все «переписать с нуля». Очень хотел. Я дал ему попробовать переписать кусок с нуля. Он зарелизил свои правки и положил некритический функционал сайта. Все переписанное пошло на помойку, потому что вернуть старый код было дешевле, быстрее и проще. И на «контролируемых потерях» узнал что такое, постмортем. А в качестве своего рода урока человек писал автотесты.
Нет мониторинга ошибок
Часто в стартапах есть чаты с ранними или активными пользователями. И вот приходит к тебе поддержка или продакт, говорит, «у пользователя не работает» (а дальше варианты: «то, не знаю что», «вот это, но деталей не знаю» и так далее). Если у тебя работает, пойти и выяснить, что именно и как не работает — адище. Ты получаешь обрезанный скриншот. Или просто повтор в духе «все еще не работает, почините СРОЧНО» — например, от того же пользователя.
Пока мы не подключили систему мониторинга, о том, что лежит сайт, мы узнавали с задержкой минут в 10 в лучшем случае. От пользователей. С мониторингом мы наконец-то стали устранять баги до того, как нам напишут. А бонусом не раз вскрывали по логам критические баги — например, то, что заказ на сайте как бы создается, но в базу не сохраняется.
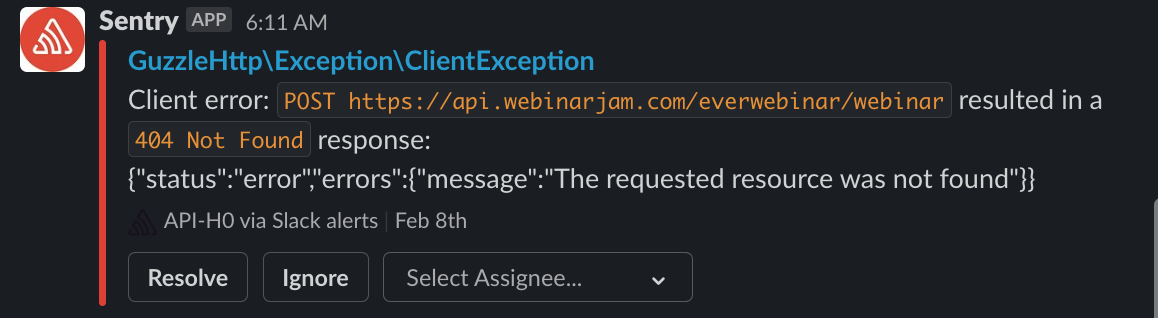 Пример мониторинга ошибок с помощью Sentry
Пример мониторинга ошибок с помощью Sentry
Вместо выводов
Вы спросите — так зачем же ты ешь кактус продолжаешь работать в основном стартапах?! Мне нравится выстраивать процессы из хаоса. За это время я заметил, что у таких проектов две беды. Не ведется работа с людьми. И нет нужной автоматизации. Поэтому остается два пути. Образовывать людей. И внедрять проверенные временем инструменты и практики везде, где только можно: если все совсем плохо, то начать с организации релизов через CI\CD. В рамках этого придется и о git договориться, и код-ревью внедрить. А все вместе послужит хорошей базой для дальнейших улучшений: организации процессов, наладки мониторинга и так далее.
Пройдя оба пути, вы получите совершенно другой уровень скорости и качества разработки. Сам я обычно иду по такой схеме. Если захочется обсудить или дополнить ее в комментариях — буду рад и благодарен. Ну и конечно же делитесь своими историями!
