Платформа как сервис в Авито: как это устроено
Привет, Хабр! Меня зовут Александр Лукьянченко, я тимлид команды, которая занимается платформой в Авито. В этой статье я расскажу о проблемах, которые возникали у нас при построении платформы для инженеров и том, какие технические решения мы использовали, чтобы эти проблемы устранить. Текст охватывает ту часть наших наработок, которые потенциально можно переиспользовать другим компаниям.

Что такое платформа и зачем она нужна
Для начала о том, что же такое платформа и как определить, является ли набор инструментов платформой. По сути это набор хорошо проработанных решений, позволяющий продуктовой разработке не тратить много времени на рутинные задачи и низкоуровневые инструменты. Они могут быть реализованы хорошо сразу для всей компании централизованно.
Платформа в Авито нужна как минимум для трёх вещей: снижения оверхеда на интеграцию с инфраструктурой, для переиспользования лучших инженерных практик и возможности централизованного контроля технологий и решений.
Снижение оверхэда на интеграцию с инфраструктурой. Если мы вводим новые инфраструктурные решения, со всеми этими инструментами нужно уметь интегрироваться. Каждому инженеру из продуктовой команды нужно изучить соответствующий тулинг, чтобы полноценно овладеть технологией и эффективно её использовать. Хорошим примером может быть введение новой системы deploy, внедрение service mesh решения. Инструменты становятся необходимыми для корректного функционирования системы, но для их грамотного использования нужно хорошо погрузиться в детали реализации.
Переиспользование лучших практик. Внедрить новый подход или технологию на большую компанию сложно, если нет единой платформы. Придётся сходить во все команды и рассказать, почему старая практика менее эффективна и удобна, составить план перехода. Затем предстоит долгий путь внедрения.
Возможность централизованно контролировать технологии и решения. Когда компания растёт, в ней рождается большое количество решений, которые закрывают одну и ту же проблему. Если у вас есть единая платформа, то большинство общих задач может быть решено там, это экономит время и силы разработчиков. В то же время хорошо контролирует «зоопарк».
Прежде чем мы нырнем в подробности и поговорим про PaaS, обрисую немного особенности нашей системы. Мы не используем облачные провайдеры, всё железо у нас своё. Почти все решения open source: начиная от основы облака, заканчивая инструментами вокруг него.
Краткая эволюция платформы
Давайте посмотрим, как была устроена платформа четыре года назад, к чему мы пришли и над чем работаем сейчас.
Инфраструктура состоит из множества инструментов, у каждого из которых свой интерфейс. С каждым из интерфейсов инженеры должны уметь интегрироваться и собирать их в единое целое, чтобы эффективно использовать. Вот схема с инструментами, которыми мы пользуемся в повседневной работе:
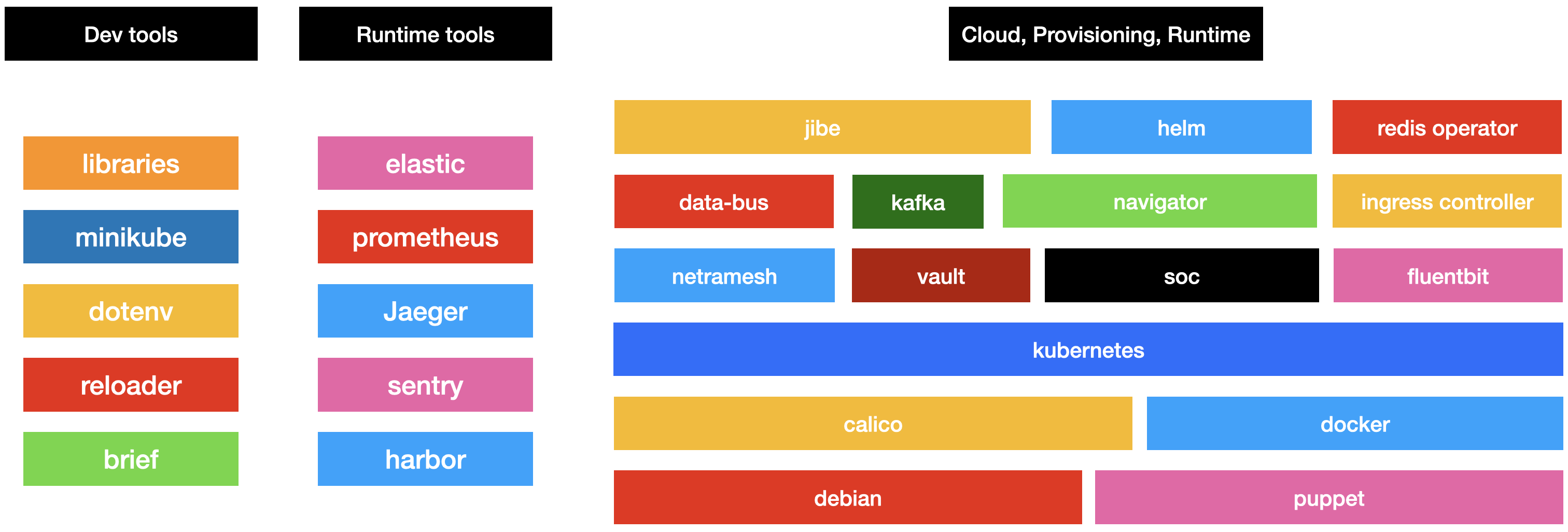
Когда мы начинали строить централизованную платформу в Авито, то взяли в виде оркестратора Kubernetes. Он был установлен «как есть», и в нетронутом виде поставлялся в продуктовые команды для разворачивания stateless частей Авито. Чтобы ограничивать его использование и доступные разным инженерам и внешним компонентам фичи, мы использовали стандартный механизм RBAC. Далее вся инфраструктура обрастала вокруг оркестратора. Мы автоматизировали явные бутылочные горлышки, которые могли, например, пайплайны для деплоя сервисов в CI.
Но в итоге разработчики использовали низкоуровневые интерфейсы: Helm для деплоя, kubectl для работы с Kubernetes. По сути, они были своего рода администраторами системы, потому что полноценно занимались всем циклом от разработки до деплоя в продакшн с эксплуатацией.
Спустя два года развития мы поняли, что для наиболее правильного использования всех инструментов с иллюстрации выше разработчикам нужно потратить достаточно большое количество времени. Для тех, кто ранее не был с ними знаком, это могут быть недели изучения. С ростом компании, когда инженеров становилось всё больше, мы увидели что это начало становиться проблемой. Специалист, которого мы находили снаружи, не всегда знал всё множество технологий, которые у нас используются, и в итоге онбординг был долгим.
Вот для контекста небольшая часть вопросов, которые приходили в саппорт платформы:
- Почему у меня нет метрик в staging?
- Как положить секрет в Vault?
- Какие ресурсы поставить в deployment?
- Сервис упал, куда смотреть?
- Как прокинуть хост наружу?
- Что, опять переезжаем в новый кластер?
- Почему у меня upgrade failed waiting for a condition?
- Как подключить PostgreSQL к сервису?
Часть вопросов повторялась, другая их часть — острые углы, с которыми столкнулся отдельный разработчик. Каждый из вопросов отнимал не только время платформенной команды на то, чтобы разрулить и сделать какую-то вещь удобной, но и время, которое тратили продуктовые разработчики для того, чтобы решить бизнес-задачу.
Чтобы решить проблему, мы изменили курс развития платформы, и пришли к концепции PaaS — платформа как сервис. По сути это эволюция того, что мы делали, но она немного отличается от использования низкоуровневых инструментов.
Есть много разных реализаций PaaS, но все они вкладывают своё понимание того, что же такое платформа как сервис. Вот несколько важных поинтов, которые вкладываем в это понятие мы:
Максимальная автоматизация. Мы автоматизируем все рутинные операции, которые можем.
Построение продукта, который закрывает реальные потребности разработчиков. Мы смотрим на платформу не как на инфраструктуру, которая состоит из множества кубиков, которые нужно складывать воедино, а как на продукт, который удовлетворяет потребности и закрывает пользовательские боли. Мы ведём PaaS как продукт для разработчиков внутри большого продукта Авито.
Низкий порог входа и максимальная концентрация на скорости доставки фич. Когда в компанию приходят новые разработчики, им нужно много времени для адаптации. Поэтому PaaS подразумевает низкий порог входа и простое взаимодействие со всеми компонентами.
Нулевой оверхэд интеграции с инфраструктурой. Интеграции, которые нужно проводить со стороны разработки, должны быть автоматизированы со стороны платформы. Это возможно не всегда, но большинство случаев платформа закрывает.
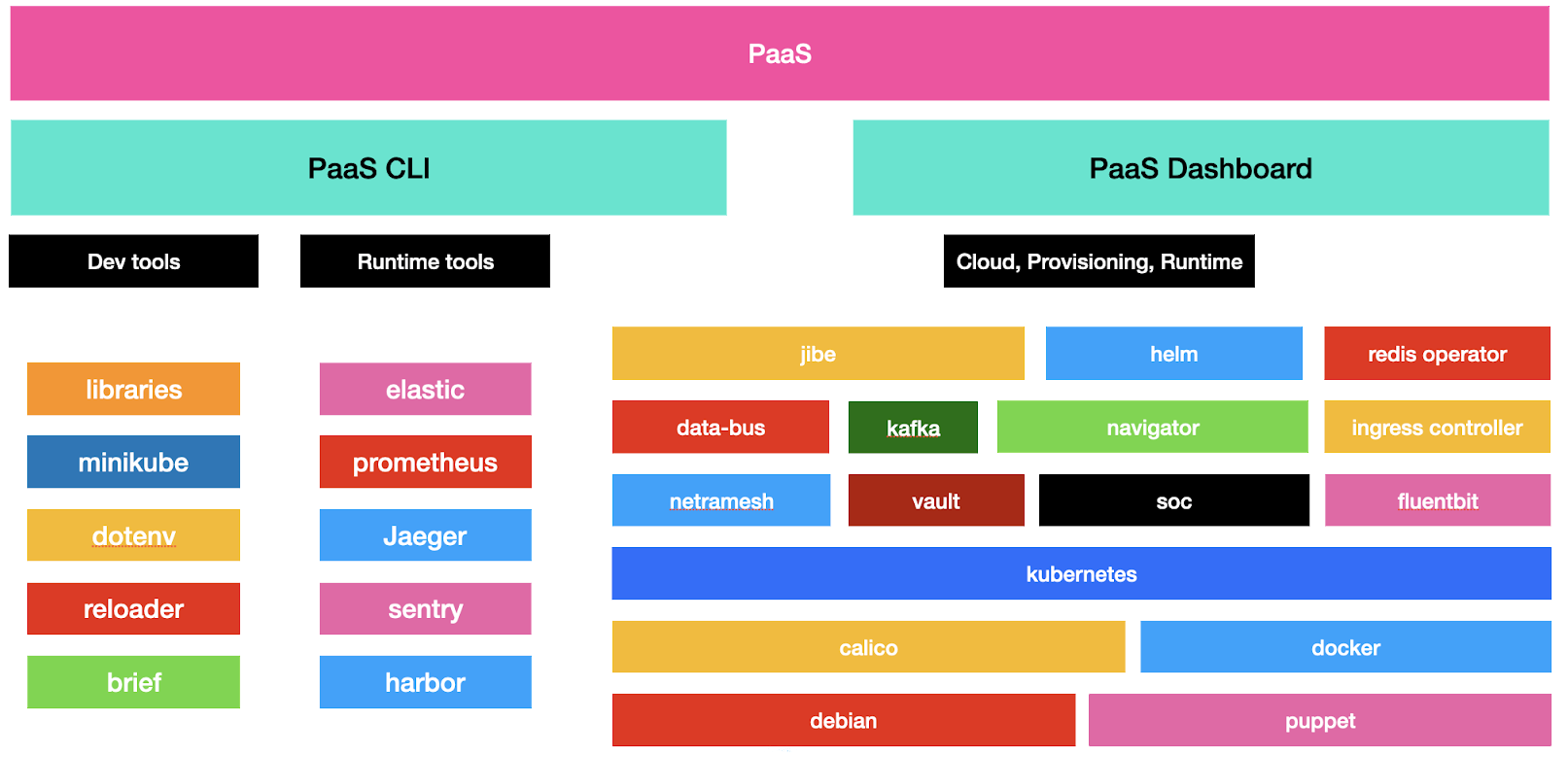
Если смотреть на текущую платформу со стороны пользователя, то в ней есть два основных интерфейса: командная утилита Авито и PaaS dashboard. Разные настройки и инструменты, которые были раньше, инкапсулированы и скрыты за красивой крышкой этих двух интерфейсов.
Командная утилита Авито позволяет делать практически все действия, которые есть в платформе, от создания сервиса до его эксплуатации и выкатки. PaaS dashboard — это инструмент визуализации. Он дублирует некоторые фичи Авито-утилиты, позволяет посмотреть дополнительную информацию, о которой мы поговорим ниже.
PaaS Dashboard — главная страница одного из сервисов
Проблемы и технические решения
В технической части я буду рассказывать про проблемы и боли, а потом про их решения. Пойдём по следующему жизненному циклу разработки:
- Создание сервиса.
- Разработка.
- Тестирование.
- Доставка сервиса.
- Эксплуатация сервиса.
Этапы с первого по третий по сути формируют готовый к релизу продукт. Четвёртый и пятый пункты уже ближе к операционной части.
Создание сервисов
Какие тут есть боли? Простая операция: зашли в Bitbucket или GitLab, и создали репозиторий. Потом зарегистрировались в системе учёта, создали порядка десяти различных ресурсов: CI, Sentry, Grafana, Kibana, прописали правила внешней балансировки и ещё зашли в несколько наших внутренних систем и получили готовый сервис.
Кажется, что процесс — не проблема, потратил 20 минут, и готово. Но на самом деле это моральный барьер, который встаёт перед разработчиком, когда нужно создать новый сервис. Плюс, создавая сервис руками, легко забыть про один из ресурсов.
Чтобы решить эту боль, мы автоматизировали процесс сведением всего в одну команду под названием avito service create. Она проводит пользователя через специальный wizard, спрашивает, какой нужен шаблон, задаёт ещё пару вопросов, и автоматически создаёт сервис со всеми нужными ресурсами.
В итоге пользователь получает репозиторий, полностью готовые CI-пайплайны, все нужные observability-ресурсы, политики и настройки доступа извне. Опыт создания сервисов сильно улучшается.
Разработка сервисов
Здесь уже больше движимых частей, чем в создании сервисов. Давайте посмотрим на основные.
Первое — это структура сервисов. Если дать всем разработчикам возможность пилить сервисы с нуля, мы получим реализации, которые будут отличаться практически во всем. Несмотря на то, что паттерны и подходы будут использоваться примерно одинаковые, выглядеть все сервисы будут по-разному. Будут отличаться даже базовые штуки вида метрик, логов, интерфейсов. Мы получим долгий вход: когда разработчик захочет что-то закоммитить в чужой сервис, это станет настоящей проблемой. Нужно будет разобраться, осознать, как правильно сделать изменения, и только потом сделать pull request. Это долго и болезненно.
Очевидное решение — унификация структуры. Мы сделали единую структуру для каждой технологии, шаблон, в котором есть поддержка всех основных инструментов. В шаблоне есть метрики, логи, хелсчеки, поддержка автогенерации кода, RPC-взаимодействия и асинхронного взаимодействия. Такие вещи автоматизированы под каждую из технологий, которые мы используем в Авито. Бонусом унификация позволяет контролировать «зоопарк» и распространять только технологии, которые уже опробованы в компании.
Следующий момент — это конфигурация сервисов. Тут у нас был достаточно длинный эволюционной путь. Начинали мы со стандартных plain Kubernetes-манифестов, которые разработчики писали сами. Мы загружали их в специальной репозиторий, и с помощью администраторов раскатывали в нужное окружение.
Несколько месяцев спустя мы перешли на Helm-чарты. Helm позволяет объединить множество манифестов в единую коробочку, которую удобно деплоить. Через пару лет мы посмотрели на манифесты и увидели, что в каждом репозитории рядом с каждым сервисом есть директория helm, которая занимает примерно 40 килобайт чистого YAML-текста и очень многословное описание для деплоя сервиса.
Когда мы подиффали все helm-директории между сервисами, то узнали, что diff между ними — это несколько строк в большинстве случаев. Так как мы распространяли их вместе с шаблонами, разработчики меняли несколько строк, которые отличают настройку конкретного сервиса, а всё остальное было примерно одинаковым. Получалось, что при изменении одной опции во всех сервисах нужно было делать условные 500 пул реквестов, дожидаться их апрувов, мержа и выкатки. Мы решили, что стоит вынести все движимые части в один манифест, а остальное убрать из сервисов.
Таким манифестом стал app.toml. Это минималистичное описание, в котором есть движимые части, специфичные конкретному сервису.
Огромные манифесты могут автоматически генерироваться на основе app.toml, в нём есть специальная секция engine, движок, с помощью которого мы точно понимаем, какие манифесты нужны этому сервису, и уже можем сгенерить манифест под нужную технологию:
description = "process user info"
kind = "business"
replicas = 1
[engine]
name = "golang"
version = "1.14"
size = "small"
[envs.prod]
replicas = 70Почему app.toml? Формат TOML позволил уйти от вложенной структуры, которая до этого была у нас в YAML. Исчезли манифесты, для которых приходилось пользоваться линейкой, чтобы понять, на сколько табов сдвигать очередную настройку, чтобы она заработала.
С TOML мы решили проблему с окружениями. В Helm мы использовали values файлы. Каждый для своего окружения: values.staging.yaml, values.prod.yaml и values.test.yaml. После внедрения единого манифеста всё это стало не нужно. Теперь в одном файле описаны все настройки для всех окружений, причём это удобно читается и не нужно прыгать по трём файлам для того, чтобы понять как меняется настройка в зависимости от окружения. А всю бизнес-конфигурацию мы начали делать с помощью переменных окружения.
Как мы живём с app.toml? Кто превращает его в реальные манифесты для Kubernetes? Мы сделали выделенный сервис под названием helmgen. Это историческое название, раньше он генерировал Helm-манифесты, а сейчас отдаёт plain Kubernetes-манифесты. Helmgen принимает на вход app.toml, и пропускает через себя все имеющиеся настройки, а на выходе отдаёт готовые к применению в кластер Kubernetes-манифесты, которые выкатываются деплоером.
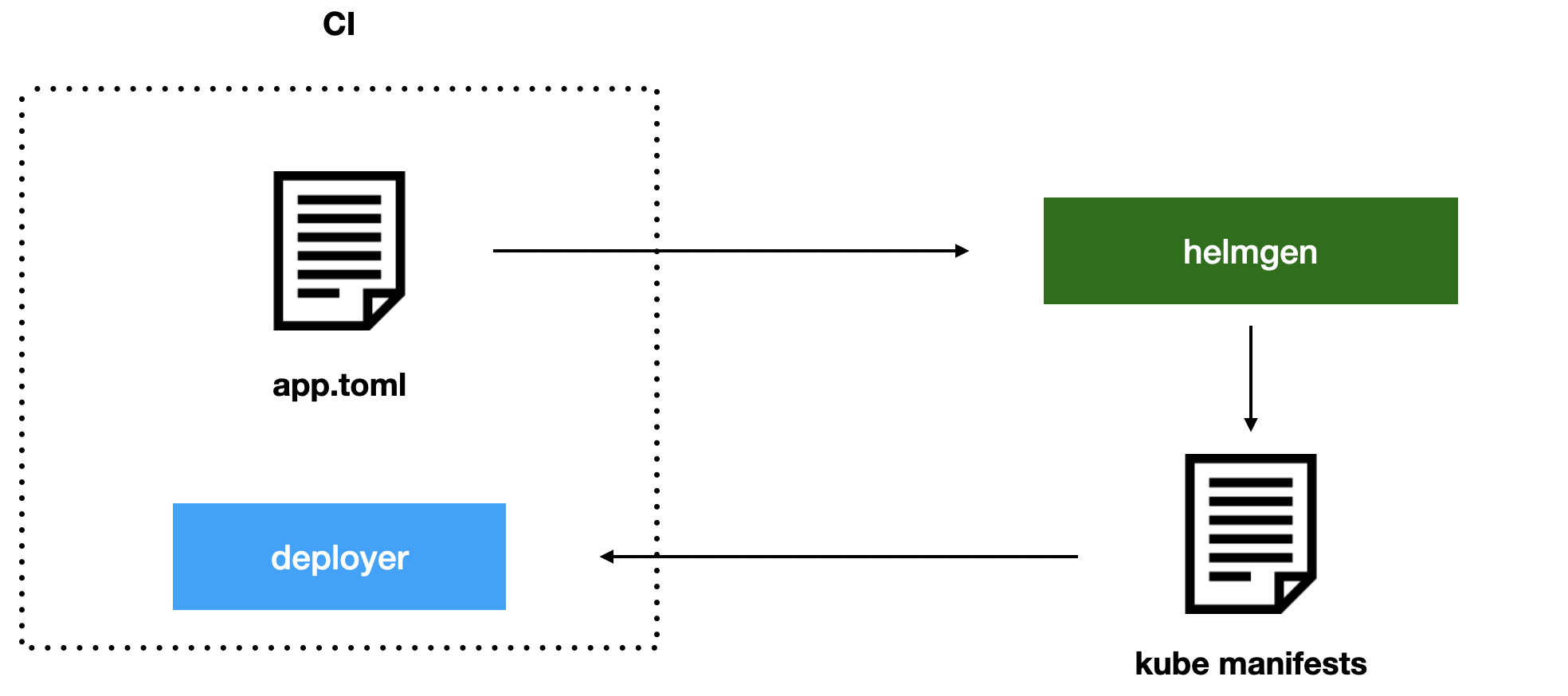
Схема deploy с использованием helmgen для генерации манифестов
Helmgen — это сервис с API, он един для всей платформы. Все новые фичи, которые мы делаем, сразу становятся доступными для всех. То есть, к примеру, если мы захотели подкинуть какую-нибудь новую переменную окружения или добавить новый sidecar, заменить специальные аннотации по всем deployment, эта фича сразу же становится доступна для всех сервисов.
При каждом деплое мы получаем новые манифесты, самые актуальные. Это удобный и гибкий подход, который позволяет сильно упростить платформенную разработку в плане создания манифестов. Единственный неприятный момент — если в сервисе helmgen сделать ошибку, то мы сразу ломаем манифесты всех сервисов, которые будут выкатываться. Поэтому мы покрываем его достаточно мощно тестами, особенно snapshot-тестами, и смотрим, как меняются манифесты после изменения его кода.
Следующая боль разработчиков — это управление секретами. Мы используем Vault. Раньше для подключения интеграции с ним мы использовали готовые helm-манифесты, которые подкидывали в helm-директорию с сервисом с помощью helm chart.
Здесь есть несколько проблем. Во-первых, нужно понимать, как работает Vault. Разбираться, как именно в его древовидной системе разложить ключи по путям, и правильно подключить интеграцию в Helm. Подводных камней в этом процессе хватает, достаточно что-нибудь неправильно скопипастить, и всё развалится. При этом узнать корректность настройки можно только в продакшене: даже если отладить всё в стейджинге, манифесты немного отличаются между окружениями, поэтому полноценно увидеть, что всё разнесло, получится только на финальном этапе.
Как мы с этим боремся? Мы приняли, что секреты — это часть конфигурации. С помощью PaaS Dashboard разработчик вносит key value значение как переменную окружения, авторизуясь через dex в Kubernetes. Далее сервис раскатывается в namespace, который соответствует его имени. Kubernetes namespace для нас security-единица, по которой мы автоматически понимаем, какие секреты нужны сервису. В итоге в рантайме сервис автоматически получает все нужные секреты.
Понять, как всё происходит, проще по картинкам ниже. Мы написали утилиту Vault2env, это небольшой Go-бинарь, который стартует перед каждым сервисом. Когда поднимается сервис, запускается Vault2env. Он поставляется с помощью базового образа, и стартует в самом начале (entrypoint). Vault2env с помощью дефолтного kube-токена идёт в Vault, Vault его авторизует и отдаёт секреты в утилиту:
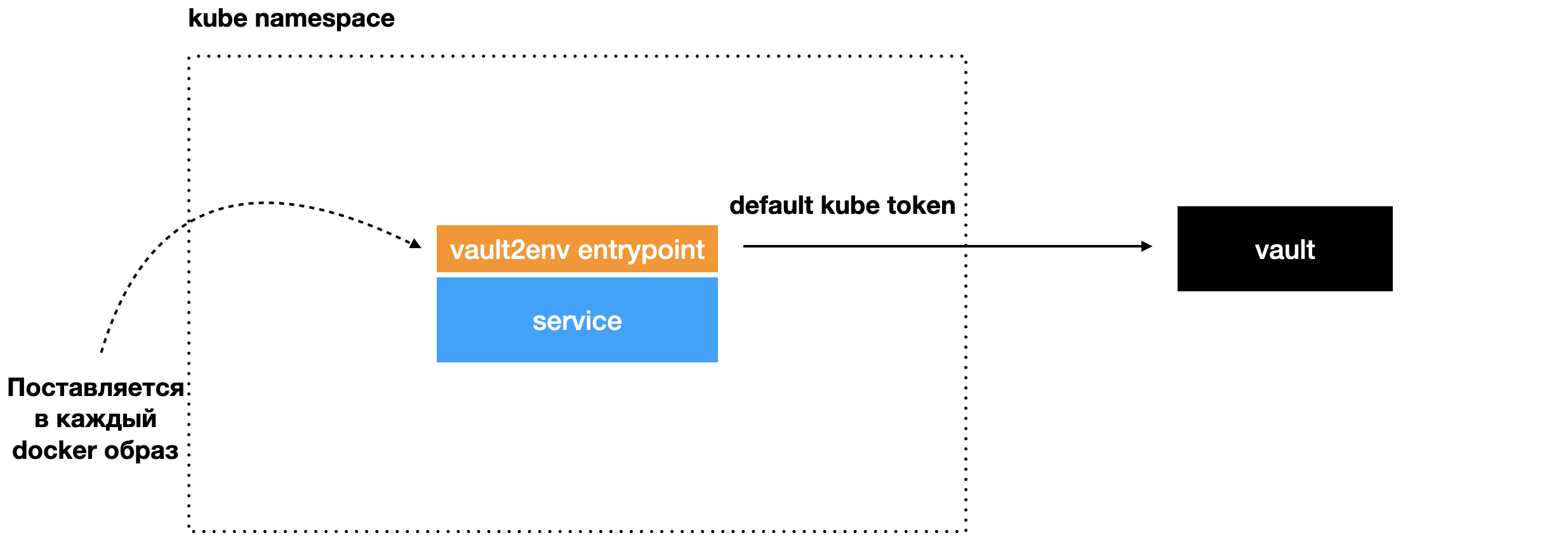
Получает секреты:
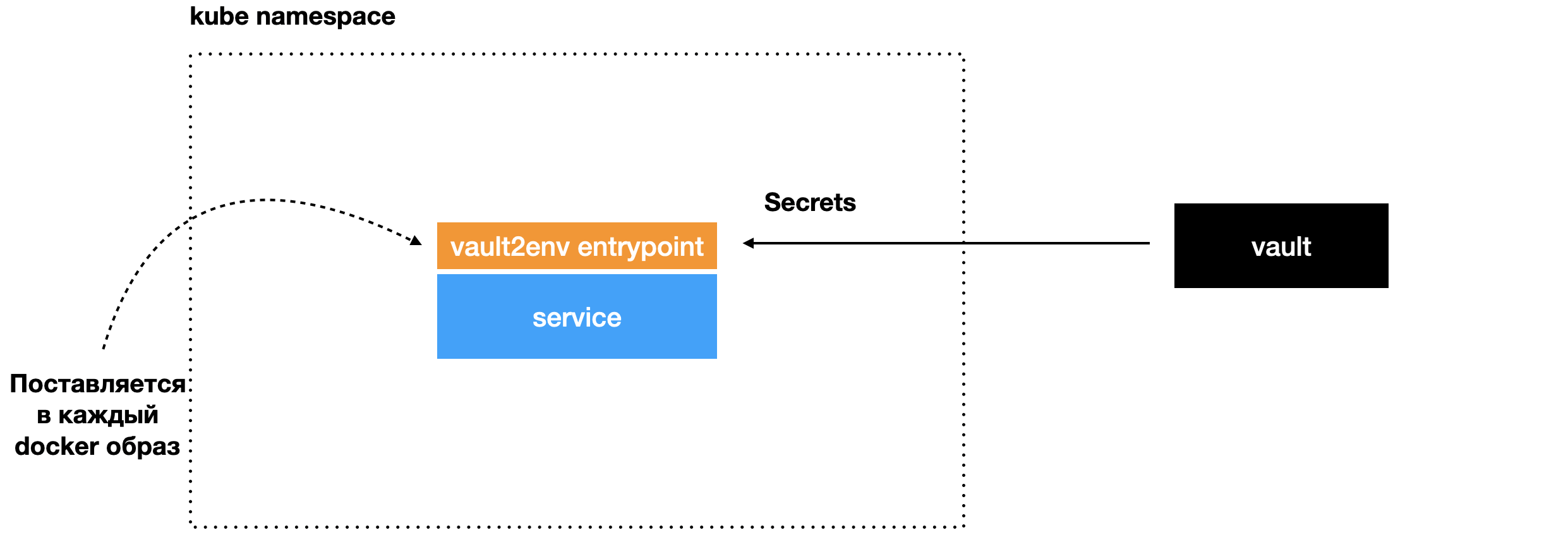
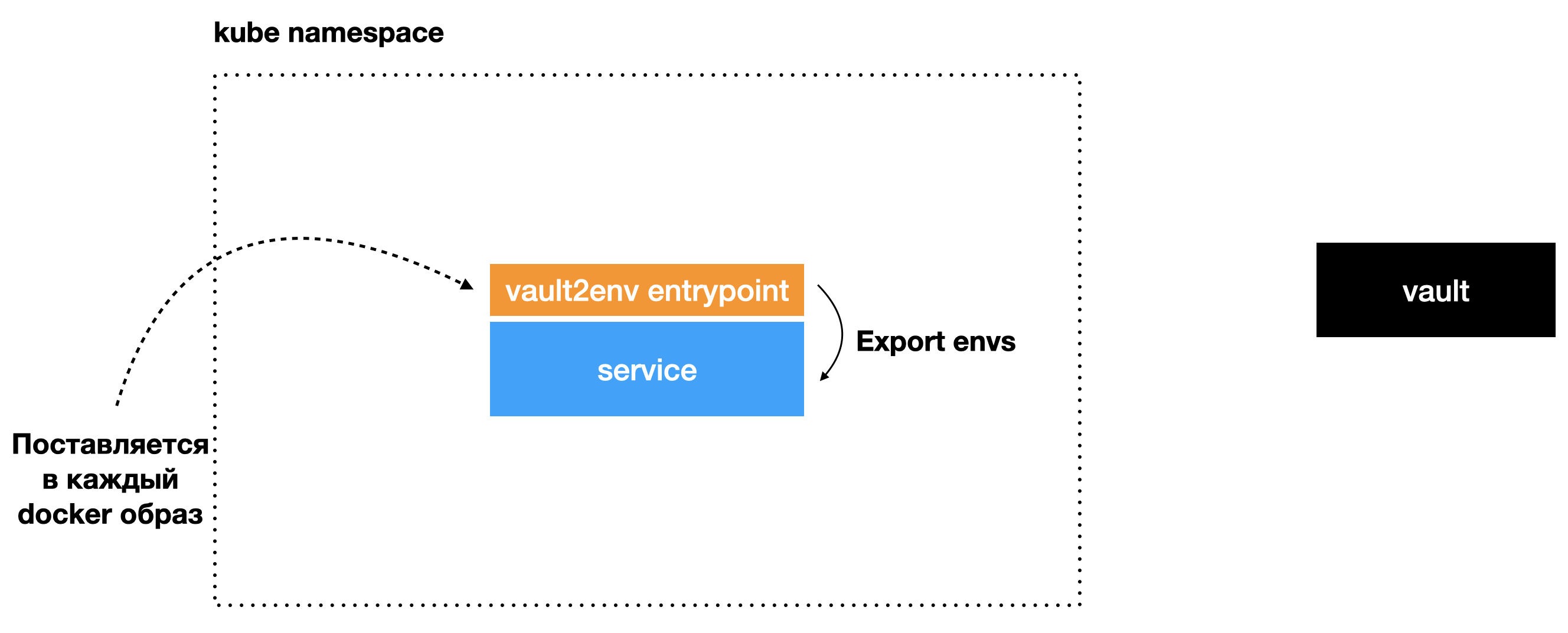
Экспортирует их для сервиса и запускает процесс с сервисом. В результате у сервиса есть все нужные для работы секретные переменные окружения. Разработчик ничего не делает для интеграции, секреты появляются автоматически.
Следующий проблемный момент — это взаимодействие сервисов. При переходе на микросервисную архитектуру получается много сетевого взаимодействия. Нужно везде:
- описывать новых клиентов для подключения к сервисам;
- не забывать обрабатывать разного рода ошибки: dns resolve, подключения, бизнес тайм-ауты;
- использовать circuit breaker библиотеки;
- следить за применением различных паттернов реализации взаимодействия между сервисами;
- прокидывать нужные хедеры;
- следить за тем, что тайм-ауты, которые мы выставляем на походы из сервиса в сервис, соответствуют нефункциональным требованиям сервисов. Не должно быть такого, что мы поставили тайм-аут в 200 миллисекунд, когда сервис, в который мы идём, в свою базу данных идёт секунду.
Чтобы решить эти задачи на уровне платформы, мы вводим двусторонние контракты с клиентской и серверной стороны, и на основе этих контрактов автогенерируем код. Автосгенерированный код поддерживает все необходимые паттерны из коробки.
service "summer"
rpc sum (SumIn) SumOut `A sum method`
message SumIn {
a int `A first number`
b int `A second number`
}
message SumOut {
sum int `A sum of the numbers`
info string `Additional info`
}Для реализации этого подхода мы используем свой небольшой формат описания под названием Brief. Он является подмножеством таких популярных форматов, как protobuf или Thrift, и может использовать их в качестве имплементации там, где нужно. Вот минималистичный пример, с помощью которого мы можем генерировать необходимый нам код для сервера и клиентов с нужной реализацией под капотом:

Слева контракт со стороны клиента, справа — описание сервера
Сами контракты — это те же самые brief-схемы.
Рассмотрим пример. Есть сервис summer, его полная схема расположена на иллюстрации справа. Он имеет RPC-вызов sum, который принимает на вход a и b для суммирования и возвращает сумму. А уже контракт со стороны клиента описывает точно такой же манифест, за исключением того, что он описывает только те методы и поля в структурах, которые ему необходимы. На картинке есть поле info справа, но его нет слева, в описании контракта со стороны клиента. Таким образом, мы чётко декларируем, что не используем это поле, и в автогенерированный код оно не попадает. Соответственно, со стороны сервера мы можем точно знать, что это поле не используется, и просто удалить его, если ни один из клиентов на поле не завязался, даже по факту нарушая обратную совместимость.
С помощью единой команды через avito утилиту, вызывая avito service codegen, мы получаем готовый клиент со всеми реализованными паттернами вида circuit breakers, установленными таймаутами (которые, конечно, всё равно необходимо тюнить), context propagation и прочими штуками. В итоге взаимодействие между сервисами идёт с помощью внутреннего протокола, разработчик особо о нём не задумывается.
С асинхронным взаимодействием подход такой же. Сервисы общаются ивентами, которые явно декларируются с помощью тех же самых манифестов. Здесь немного другой синтаксис: есть ключевое слово schema, с помощью которого мы декларируем, какими ивентами сервисы общаются асинхронно:
schema "service.create" ServiceCreate `Создание сервиса`
message ServiceCreate {
serviceId int
userId int
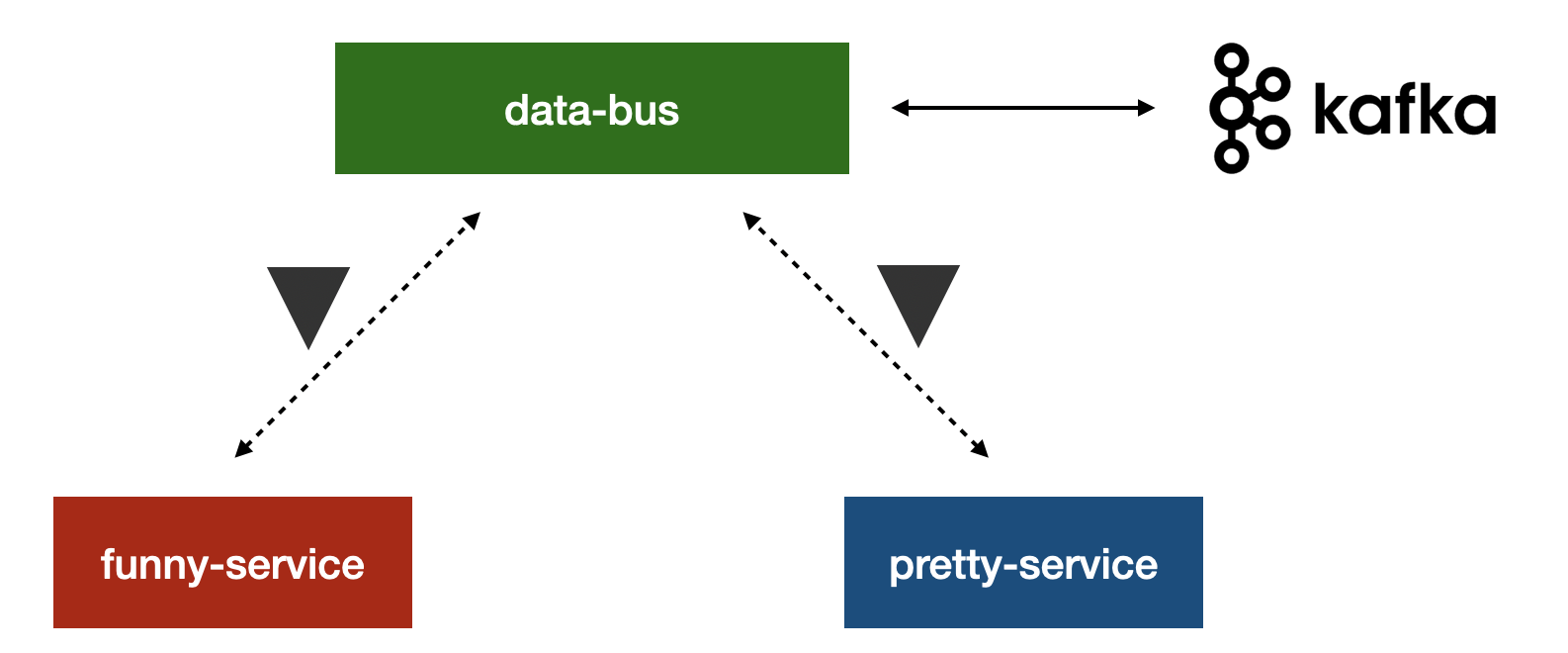
}Если смотреть, как это выглядит архитектурно, то у нас есть единый сервис, с которым все взаимодействуют по специальному протоколу и написанному клиенту. Он называется data-bus и позволяет делать все необходимые вещи с ивентами между сервисами. Под собой data-bus инкапсулирует хранилище, в качестве которого мы используем Kafka. В итоге, как и в RPC-взаимодействии, сервисы автоматом получают интеграцию с сервисом шины данных, генерируя код из brief схем.Сам data-bus необходим для простой и гарантированно проверенной интеграции с системой асинхронного обмена событиями.
Тестирование сервисов
Перетекаем из разработки в сторону доставки сервиса пользователям. Перед тем, как доставить сервис, его нужно протестировать. С тестами всё не очень гладко, когда мы начинаем использовать микросервисную архитектуру.
Если мы начинаем мигрировать подходы, которые использовали для тестирования в монолите, это приводит обычно к не очень хорошим результатам. Обычно у нас есть большое количество e2e-тестов, которые покрывают вообще весь проект, в нашем случае весь Авито, различными сценариями. При каждом изменении в любом микросервисе проверять все сценарии накладно и мы, по сути, лишаемся главного преимущества микросервисов — независимости разработки. Тем не менее, мы хотим тестировать всё те же кейсы и получать прогнозируемое качество изменений.
В микросервисной архитектуре мы стараемся покрывать всё в первую очередь юнит-тестами. End-to-end тесты оставляем только на бизнес-критичные пути.
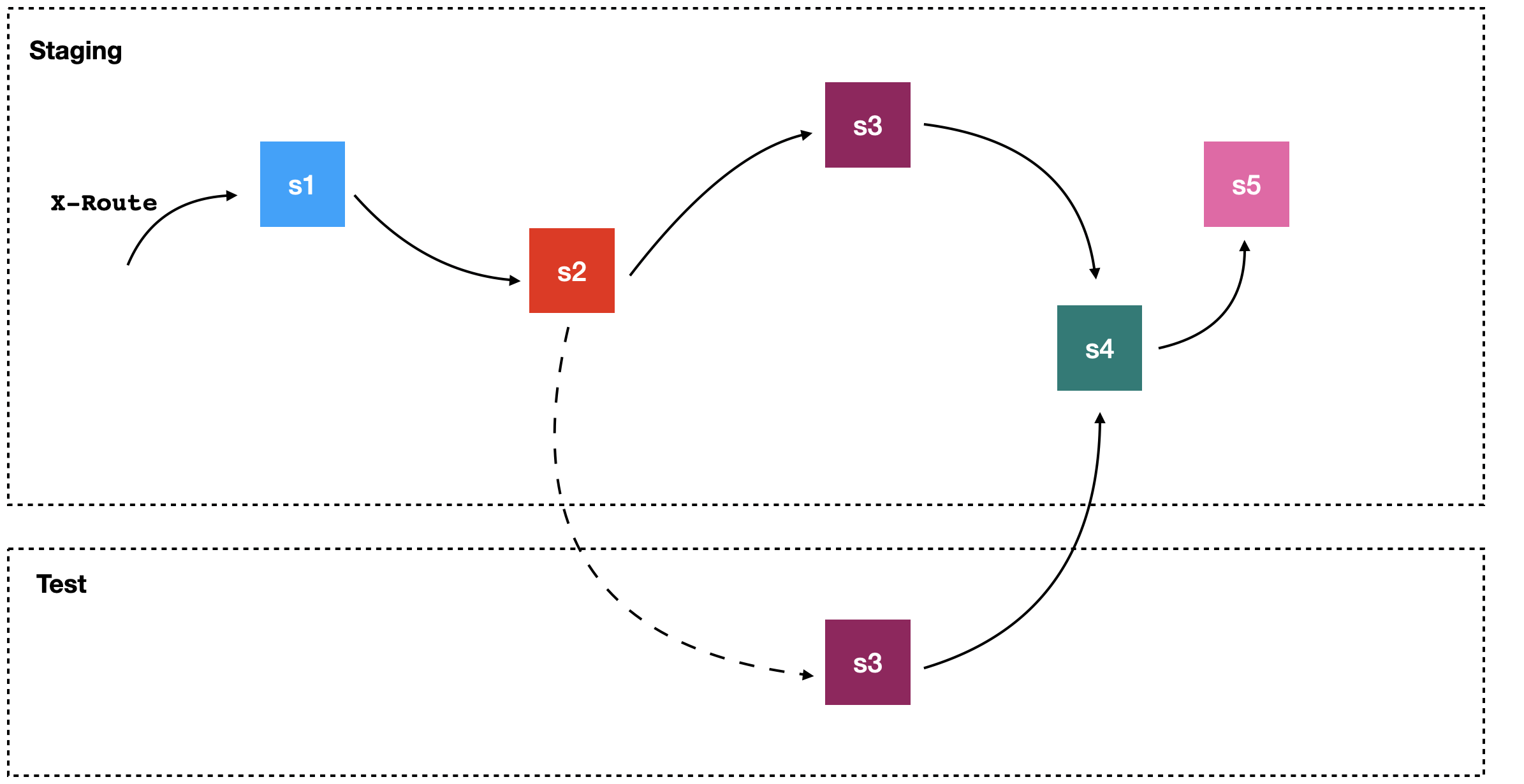
Для e2e-тестов мы внедряем новый подход. Представим, что есть цепочка взаимодействия, в ней участвует пять сервисов. Нам нужно протестировать изменения только сервиса s3, как мы можем это сделать? Мы разворачиваем его в отдельном тестовом окружении, и далее есть два варианта. Первый — поднять пять сервисов рядом, изолированно, и протестировать. Этот вариант чреват тем, что будет использоваться много ресурсов и стабильность тестов будет низкой. Второй вариант — в стейджинг-окружении, где уже всё развернуто, задеплоить сервис s3, и проверить интеграцию.
Со вторым вариантом поначалу всё хорошо. Но когда так начинают действовать все разработчики, стейджинг-окружение превращается в хаос. Понять, почему падают определённые тесты практически невозможно: все разработчики работают в одной среде и по сути отлаживают там все новые фичи как в dev-песочнице.
Чтобы решить эту проблему, мы используем динамический роутинг с имплементацией с помощью service mesh. Когда мы хотим протестировать сервис s3, то на уровне сети на все запросы end-to-end сценария добавляем header X-Route. Этот header говорит о том, что если сейчас мы хотим сходить в сервис s3, то это будет не настоящий стабильный сервис s3, а его тестовая копия. Таким образом мы полноценно тестируем новую версию без изменения и слома стейджинга. Делаем это с помощью решения netramesh.
Доставка сервисов
В доставке сервисов тоже было несколько важных изменений, к которым мы пришли со временем. Как я говорил выше, мы долго использовали инструмент Helm. Он хороший, но у него достаточно плохой user experience в работе с обратной связью о deploy. Разработчику неудобно узнавать, почему что-то упало, что происходит в данный момент, как гарантированно откатиться на нужную версию. Мы жили с этим, обложившись дополнительным инструментарием.
Но однажды появилась задача, которая обязала нас держать в пределах одного окружения несколько кластеров. С Helm мы не могли достичь транзакционности деплоев. Если сервис выкатывается в определённое окружение, то он должен быть в одной версии полностью по всей системе, во всех кластерах. Helm такое не умеет и реализовать поверх него это достаточно сложно.
Поэтому мы решили взглянуть на весь процесс деплоя сверху и увидели, что по факту уже применяем готовые манифесты, которые генерит инструмент helmgen. От Helm мы использовали только небольшую прослойку, по сути kubectl apply с ожиданием готовности сервиса, но не использовали шаблонизацию. Качество rollback и удобство утилиты нас также не очень устраивали. Поэтому мы поменяли подход к деплою.
Мы пришли к написанию утилиты под названием Jibe. К сожалению, она ещё не заопенсоршена, но давайте посмотрим, в чём её кардинальное отличие от прошлых инструментов.
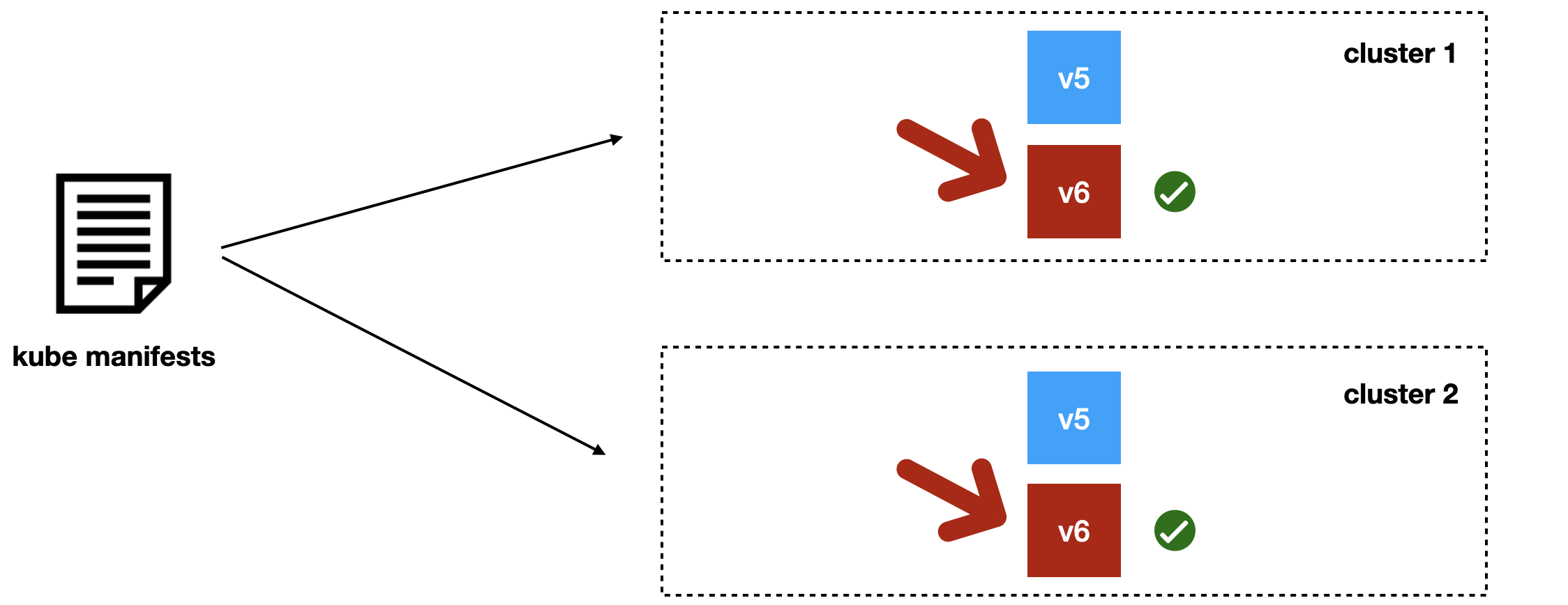
Допустим, мы хотим разложить новую версию сервиса для двух кластеров.
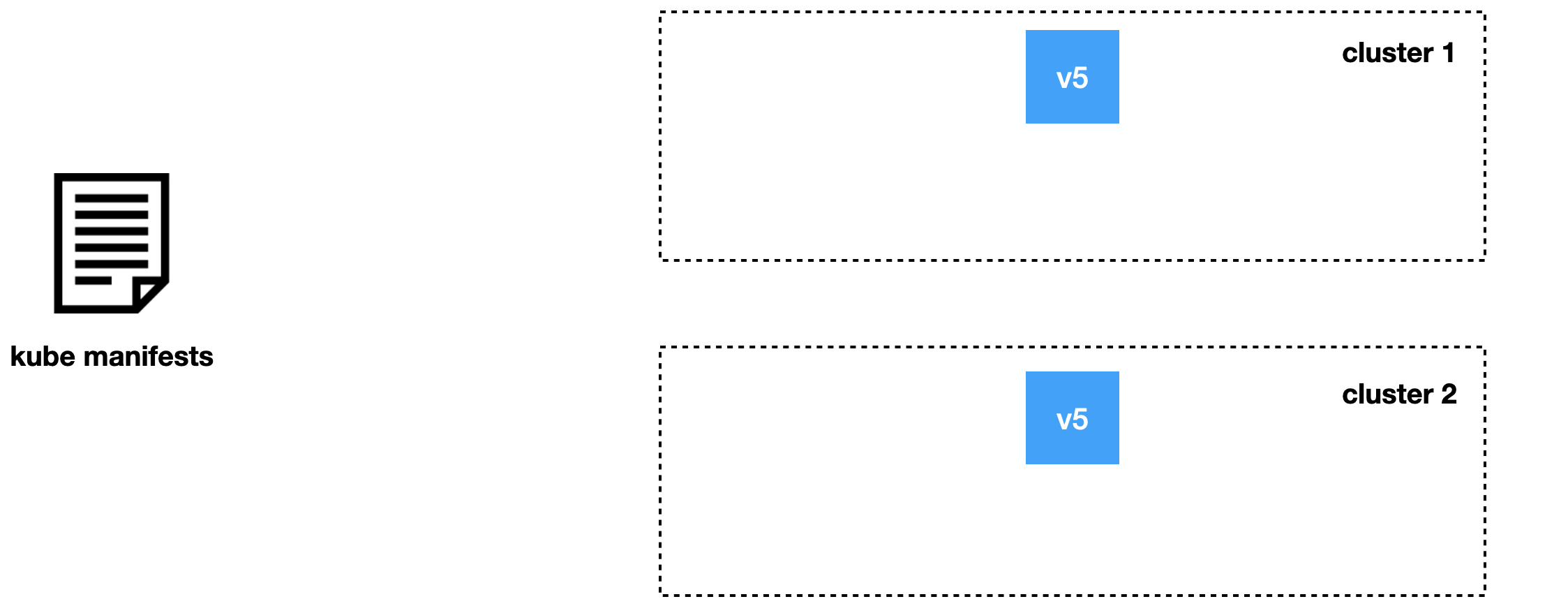
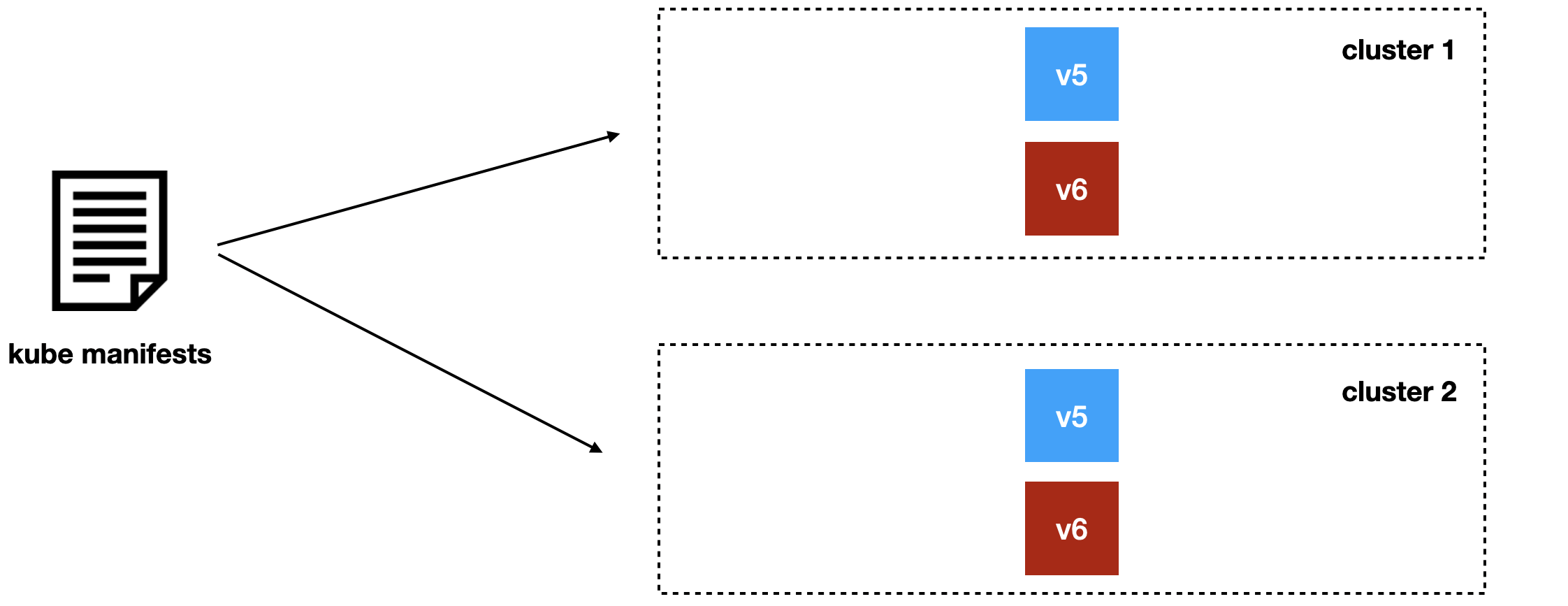
В отличие от старого подхода, с Jibe мы не заменяем предыдущую версию, а деплоим рядом новую. Например, v6 рядом с версией v5, и дожидаемся, когда во всех кластерах новая версия приходит в состояние ready.
Когда трафик по-прежнему полностью идёт на v5, но версия v6 уже готова, мы переключаем во всех кластерах трафик на новую версию и дожидаемся, когда всё станет окей.
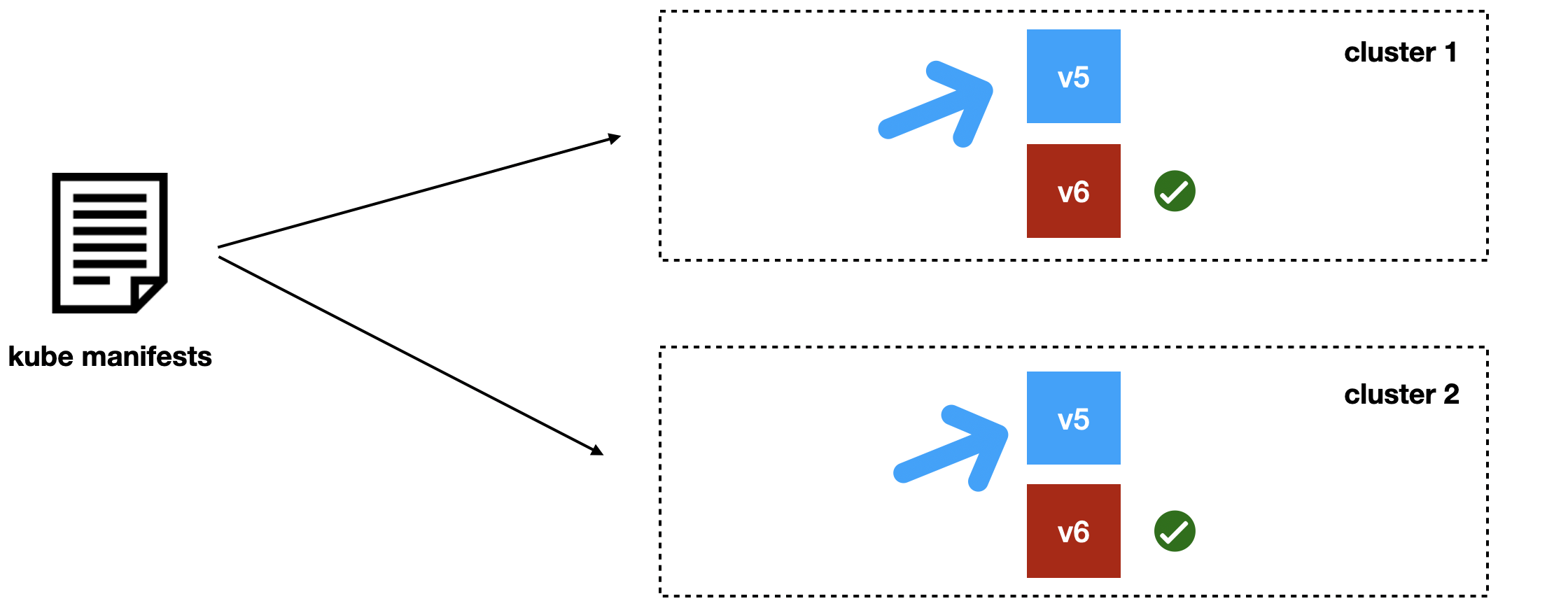
После этого тушим предыдущую версию.
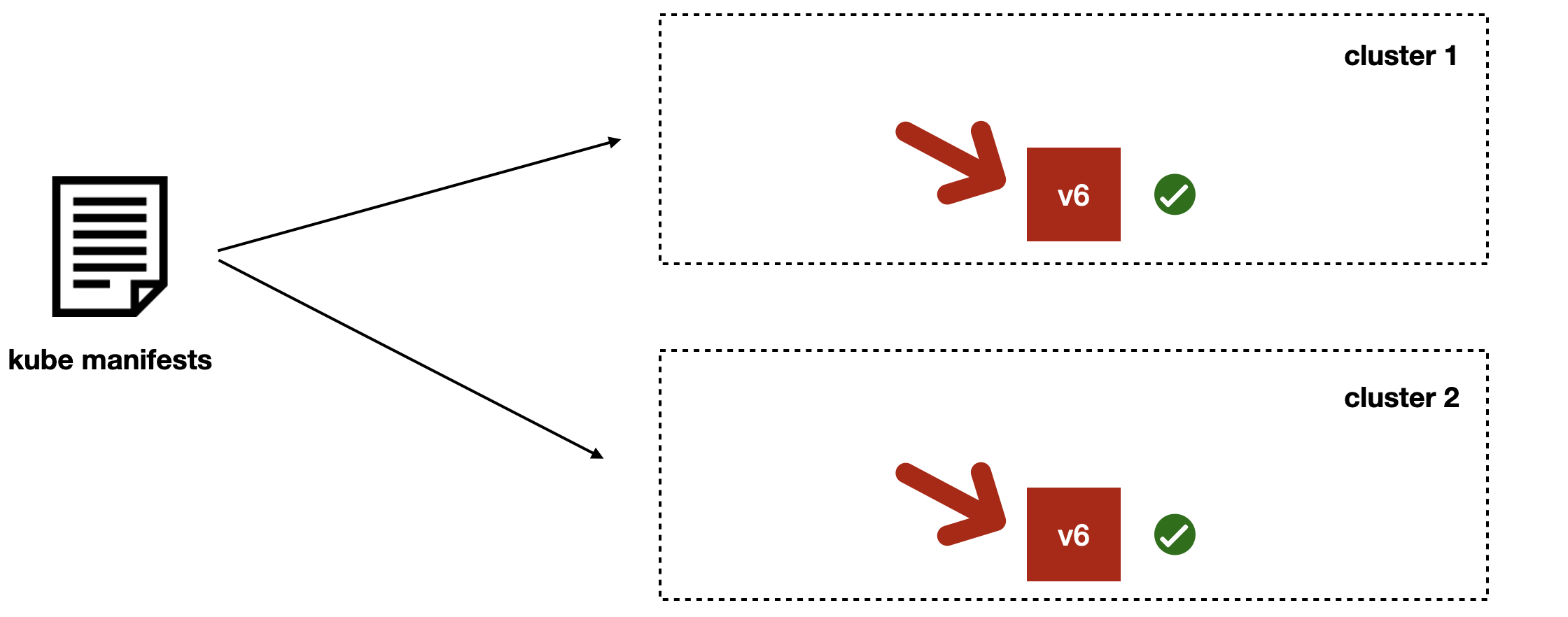
Таким образом мы достигаем транзакционности деплоев даже по нескольким Kubernetes-кластерам.
Единственный тонкий момент в том, что если в момент переключения балансировки что-то пойдёт не так, то мы получим на время неконсистентное состояние. Но мы к этому готовы: у нас есть дополнительный асинхронный компонент, который eventually восстановит справедливость, и трафик будет идти в новую версию v6.
Если смотреть высокоуровнево, Jibe даёт:
- Multistage deploy — деплой, который происходит в несколько фаз. Есть фазы init, баз данных, application, фаза балансировки. С возможностью кастомизации до любого набора.
- Deploy с ручным контролем. Каждой из фаз мы можем управлять вручную. Это дало нам возможность использовать такие подходы, как canary deployment и blue-green deployment. С Helm это достаточно проблематично сделать.
- Гарантию консистентности релизов между кластерами. Это помогло решить проблему с мультикластерным окружением.
Эксплуатация сервисов
В эксплуатации сервисов достаточно много интересных проблем, которые мы решали со стороны платформы.
Первая — это управление ресурсами. Возьмём для примера потребление CPU. На левом графике ниже можно увидеть, что использование ресурсов где-то колеблется в пике на 30–40% от общего объёма в кластерах, тогда как requests, то есть запрошенные ресурсы в кластерах, выходят практически в 100%.
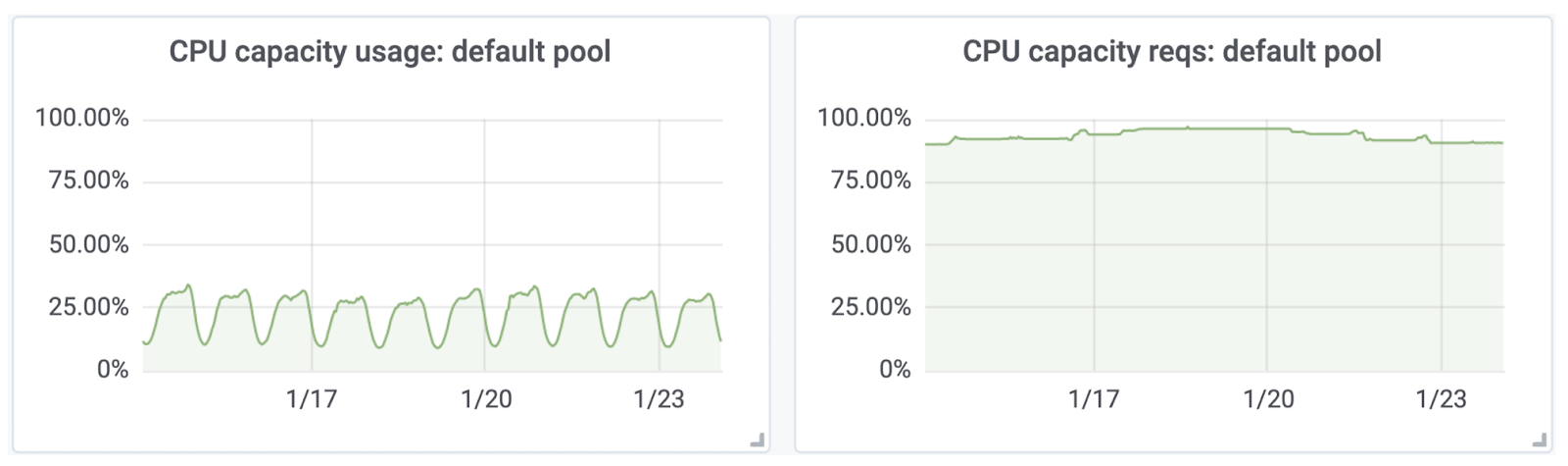
Это проблема, потому что разработчикам сложно определить и запланировать нужное количество ресурсов. Даже если они это делают качественно в начале, то со временем поддерживать ресурсы в актуальном состоянии становится сложно. В итоге мы получаем неэффективное использование ресурсов и даже деградации в продакшене из-за плохого шедулинга со стороны Kubernetes, шумных соседей и внезапных оверкоммитов. С этим надо бороться.
Чтобы побороть проблему с ресурсами, мы используем механизм VPA — Vertical Pod Autoscaling. По каждому из сервисов у нас есть очень ценная для этой задачи историческая статистика потребления ресурсов. Сервисы постоянно в продакшене, и мы можем посмотреть потребление за последнее время. Мы берём эту статистику и применяем к ней специальную функцию, которая смотрит на тренд и 95-й перцентиль использования. Затем функция генерирует для каждого контейнера необходимые requests по CPU и памяти для Kubernetes. В итоге ресурсы полностью вычисляются на основе статистики.
Есть, конечно же, корнер-кейсы для новых сервисов, для которых мы не знаем будущее использование ресурсов. Поэтому для резких всплесков и спайков мы выдаём большие лимиты и всегда поддерживаем запас на нодах, чтобы сервисы могли использовать дополнительные ресурсы.
В итоге мы получили запросы ресурсов, которые соответствуют потреблению и предсказуемый шедулинг. Этот подход действительно работает, и избавляет нас от большого количества головной боли.
В Kubernetes мы рулим CPU и памятью, но есть и другие параметры, например, сетевая утилизация.
На графике ниже — два гигабитных интерфейса. На одной ноде утилизация в топе 400 Мбит/с, на другой — 800 Мбит/с. Естественно, те сервисы, которые находятся на ноде с 800 Мбит/с утилизацией, начинают потихонечку деградировать. Нативная поддержка в Kubernetes есть только у CPU и памяти, с сетевой утилизацией напрямую работать нельзя. К сожалению, она не зависит напрямую от других ресурсов, то есть её нельзя хорошо корректировать с помощью процессора и памяти. В итоге мы получаем такую же проблему, как со стандартными ресурсами.
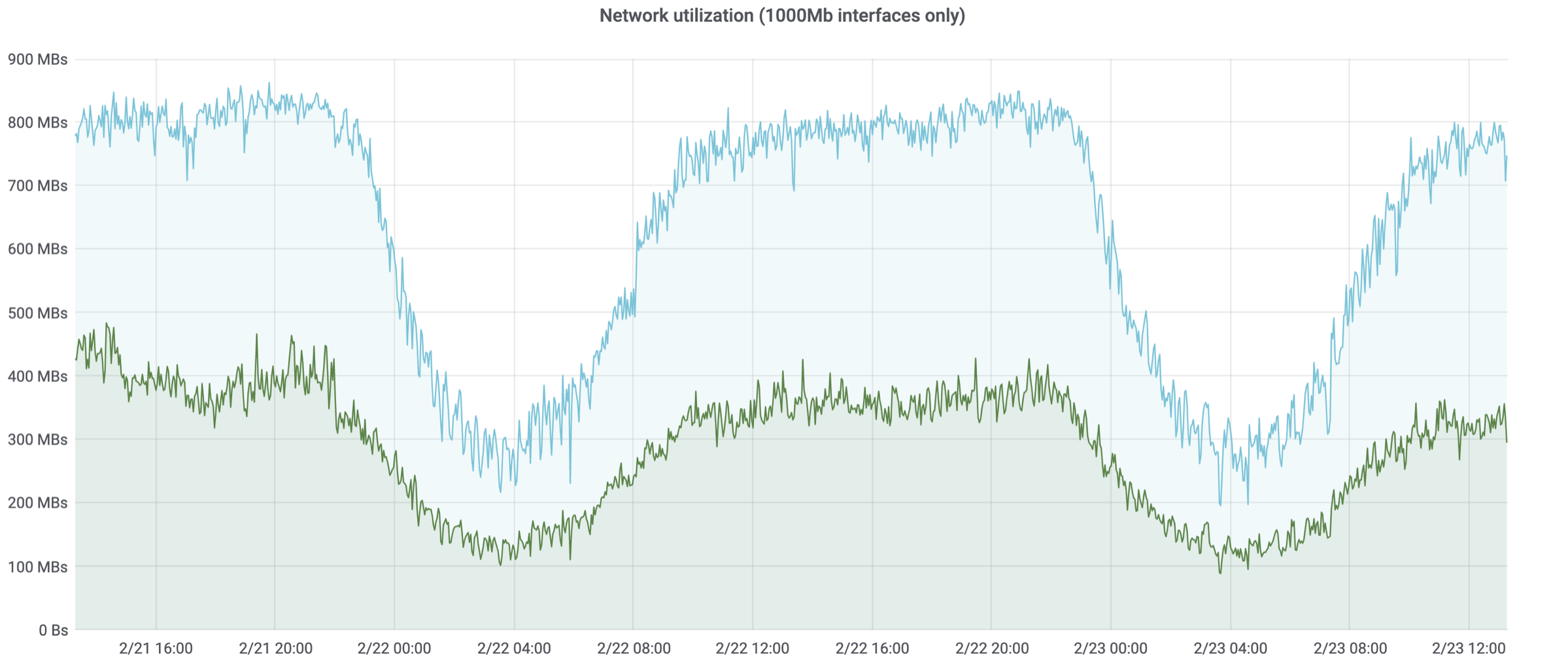
Чтобы решить её, мы вводим extended-ресурсы, то есть расширенные ресурсы, по сути такие же, как и стандартные. В случае с сетевой утилизацией, avito.ru/netutil, и заполняем его тем же самым подходом, что и память и процессорное время. В итоге получаем решение проблемы и под сеть.
Но это тоже не конец. Когда идёт много деплоев в одно время, в пике выкатываются десятки сервисов, и Kubernetes не всегда с первого раза принимает верные решения. Как следствие, мы получаем неконсистентное распределение по сервисам: одни ноды содержат большое количество подов и утилизированы сильно, а другие ноды отдыхают. Чтобы решить эту проблему, мы запускаем специальный инструмент descheduler, который позволяет автоматом переселять поды с одной на другую.
Высокая утилизация одной ноды:
Под автоматически переселён:
Алгоритм работы descheduler достаточно простой. Он проходит по всем физическим нодам в кластере и смотрит на их системные метрики — CPU, память, network util. Там, где ресурсы высокоутилизированные, descheduler автоматом находит соответствующие поды и удаляет их. Дальше уже Kubernetes с помощью стандартного механизма шедулинга сам находит подходящую ноду со второго раза (или с третьего :)). Для избежания зацикливания есть механизм rate limiting переселения подов.
Следующий момент — это runtime-конфигурация. Когда мы хотим сходить из одного сервиса в другой, нам нужно знать, как его найти. Первая проблема здесь — хардкод в конфигурации сервиса, в app.toml. Кто-то, например, поставил поход через ingress controller, потом туда кто-то добавил fqdn, кто-то пошёл случайно в staging из продакшена. Получается хаос и боль, особенно если мы решили переезжать из одного кластера в другой и все эти url изменяются.
Мы пришли к тому, что такие настройки можно также вынести на уровень платформы. Теперь мы явно декларируем в app.toml все зависимости, которые есть у сервиса. Разработчики описывают имена сервисов, далее helmgen автоматом на уровне платформы генерирует переменные окружения и заполняет их значениями, которые необходимы сервису в проде, в стейджинге и даже локально, и правильно проставляет значения.

В итоге разработчик не указывает вообще никаких url, система делает это автоматически. Более того, здесь есть ещё один слой магии — автогенерируемые клиенты. Они автоматически формируют подключение из переменных окружений и сразу же подключаются к нужным сервисам. В итоге не требуется даже знать, какие в реальности url необходимы. И в случае необходимости изменения подхода discovery, можно сделать изменение в одном месте системы.
Следующая достаточно большая тема — это сетевое взаимодействие и observability, то есть наблюдаемость системы. Разработчики обращаются в платформенную команду с такими частотными вопросами:
- Почему происходят connection timeouts?
- Почему сеть какая-то нестабильная?
- Почему вдруг у меня запрос улетел в мёртвый instance, а не зароутился автоматом в здоровый?
Часть этих вопросов мы закрываем с помощью Navigator service mesh. Он собирает унифицированные метрики по всем взаимодействиям в системе, и в результате мы полноценно понимаем, как сервисы взаимодействуют между собой. Дополнительно мы внедряем между всеми сервисами на уровне сети такие подходы, как outlier detection и connect retries. Разработчик даже о них может не знать, они просто делают взаимодействие между сервисами более предсказуемым для него.
Выглядит это таким образом:
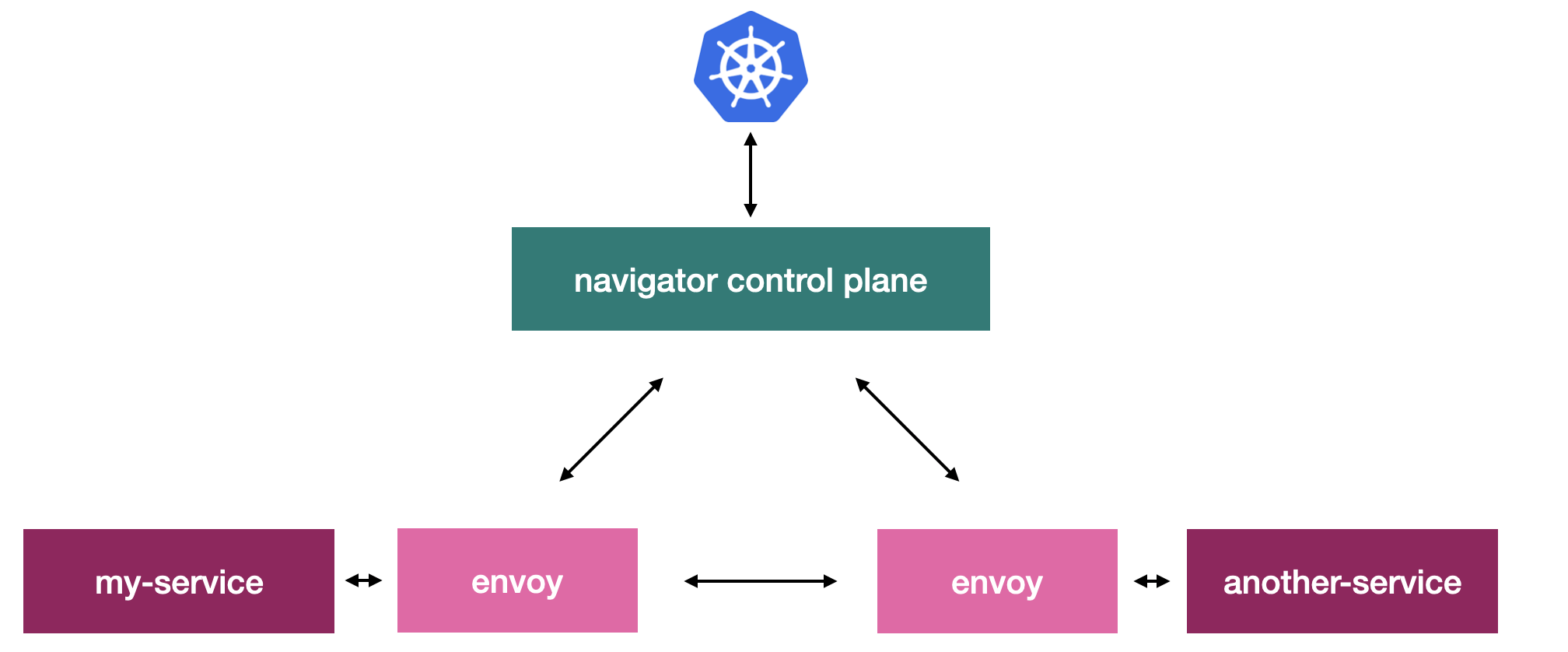
Все сервисы общаются не напрямую, а с помощью envoy proxy, который как раз контролирует Navigator. С помощью Prometheus мы автоматически скрейпим все эндпойнты envoy прокси, которые находятся рядом с каждым сервисом, и получаем в унифицированном виде всю информацию о взаимодействиях. В интерфейсе можно посмотреть данные по RPS, request time, утилизации сети между сервисами и много других дополнительных метрик.
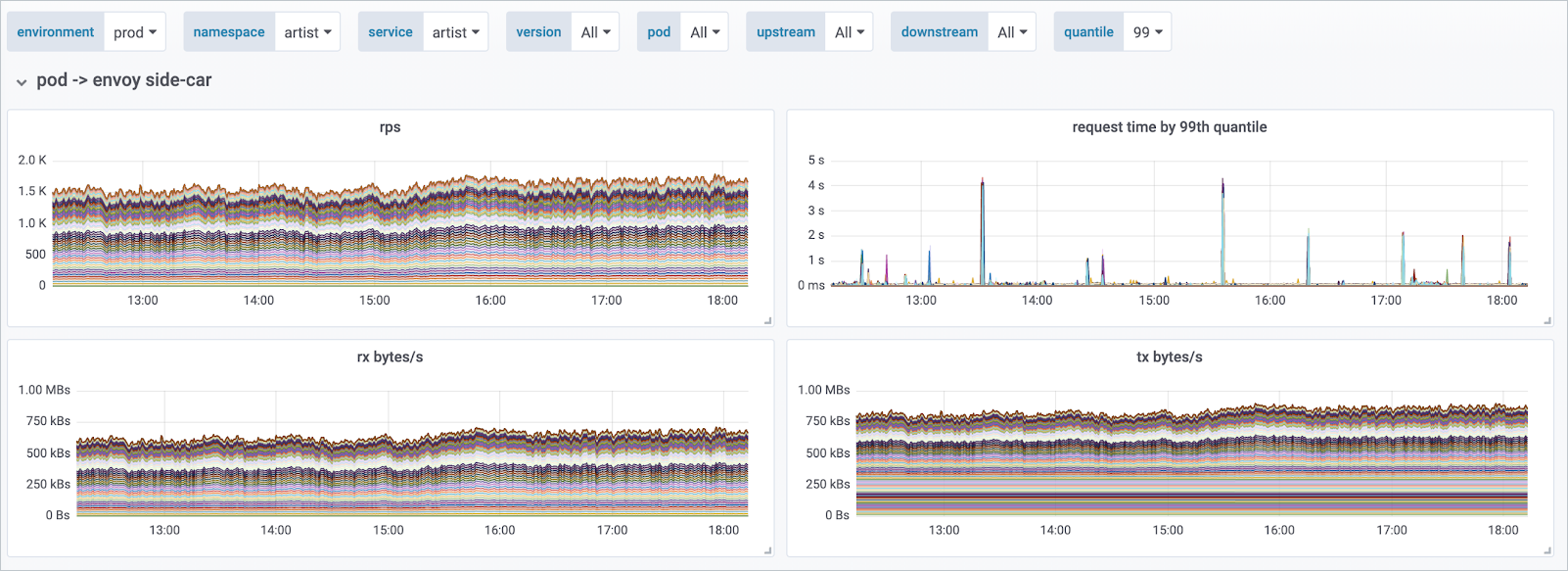
Основные метрики в Grafana
Тем же методом мы получаем трейсы по тому, как проходил запрос. Посмотреть пример можно на скриншоте ниже. Там скрыта sensitive-информация, но видно, что с помощью Jaeger UI (насыщенном информацией из service mesh) можно быстро понимать, как происходило взаимодействие, какой сервис вносит наибольшую задержку по latency.
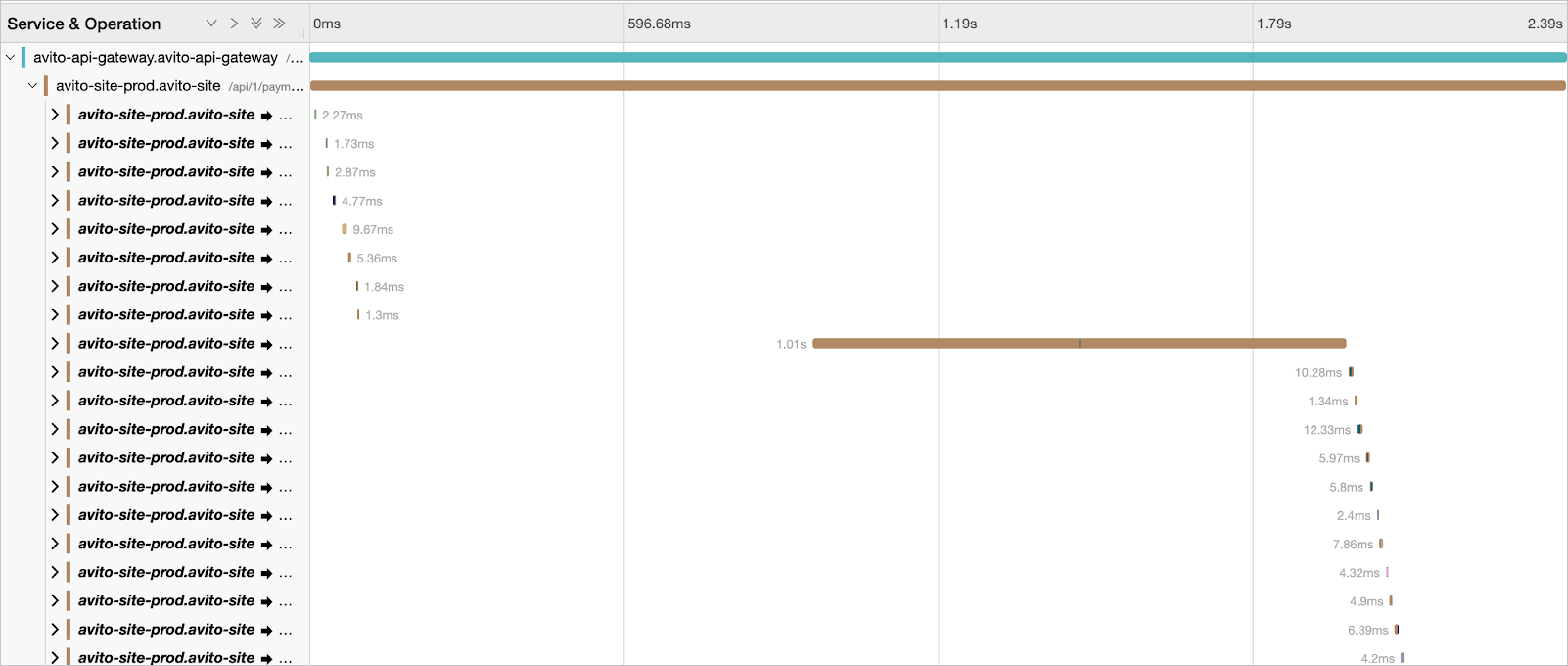
Помимо разматывания деградаций и проблем, есть часть вопросов по организации сервисов в платформе:
- Как найти ответственного за сервис?
- Как понять, кто потребитель?
- Какой API у сервиса?
Чтобы на них ответить, мы внедрили PaaS Dashboard, который уже частично рассмотрели в начале статьи. Это frontend часть, которая позволяет посмотреть различные данные по всем сервисам в одном месте. В ней можно посмотреть, кому принадлежит сервис, основные метрики, как связана сейчас работа сервиса с инфраструктурой, деградируют ли физические ноды, на которых находится сервис, автоматически подсветить проблемы в Sentry, или происходящие бизнес-ошибки. Плюс скоррелировать, например, деплои, посмотрев общий лог по всей системе.
Также можно посмотреть API сервиса и те фичи, которые используют его клиенты.
Вот ещё один скриншот:
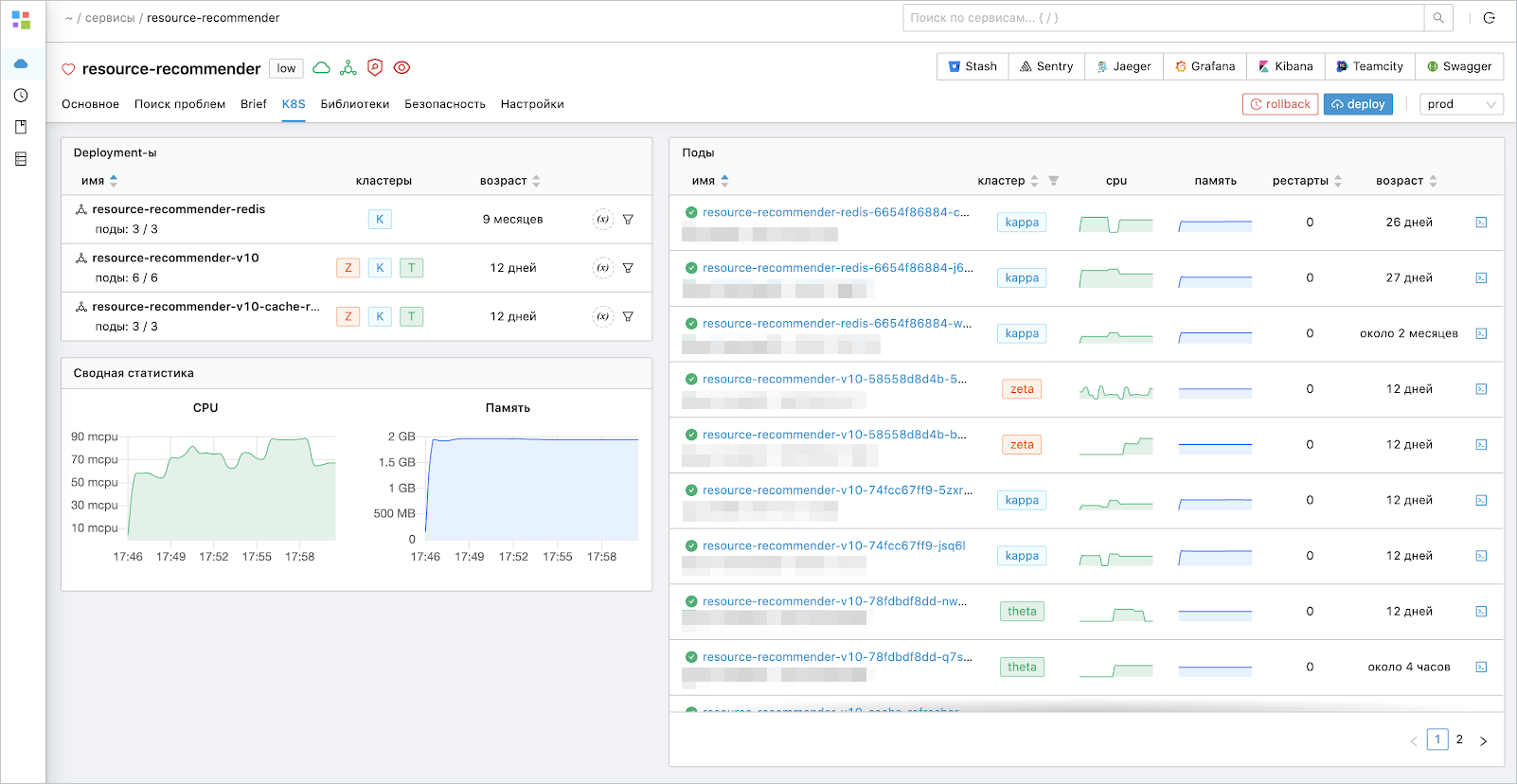
Тут можно видеть, что мы выносим в него в том числе Kubernetes-информацию, чтобы было проще ориентирова
