Платформа автоматизированного реагирования на инциденты ИБ
Представьте себе обычный ситуационный центр по ИБ в крупной компании. В идеальном мире софт детектирует подозрительную активность, и команда «белых хакеров» начинает стучать руками по клавиатуре. И так происходит раз в месяц.
В реальном мире это сотни ложноположительных срабатываний и усталые сотрудники поддержки. Они вынуждены разбираться с каждым инцидентом, когда пользователь забыл пароль, не может скачать игру с торрента, очередной порнофильм в формате *.exe, смотреть за сбоями Сети и вообще расследовать множество ситуаций.
SIEM-системы помогают систематизировать и коррелировать события от источников. И генерируют срабатывания, с каждым из которых нужно разбираться. Из этих «каждых» большая часть — ложные. Можно подойти к вопросу и с другой стороны, заведя скрипты на обработку тревог. Каждый раз, когда что-то срабатывает, хорошо было бы иметь не просто причину тревоги, а потом лезть за разными данными в четыре-пять систем, а сразу автоматически собирать весь диагноз.
Мы сделали такую надстройку, и это очень помогло снизить нагрузку на операторов. Потому что сразу запускаются скрипты сбора информации, и если есть типовые действия — они сразу же предпринимаются. То есть, если завести систему «в такой ситуации делаем так и так», то карточка будет открываться для оператора с уже проработанной ситуацией.
Что не так с SIEM-системами?
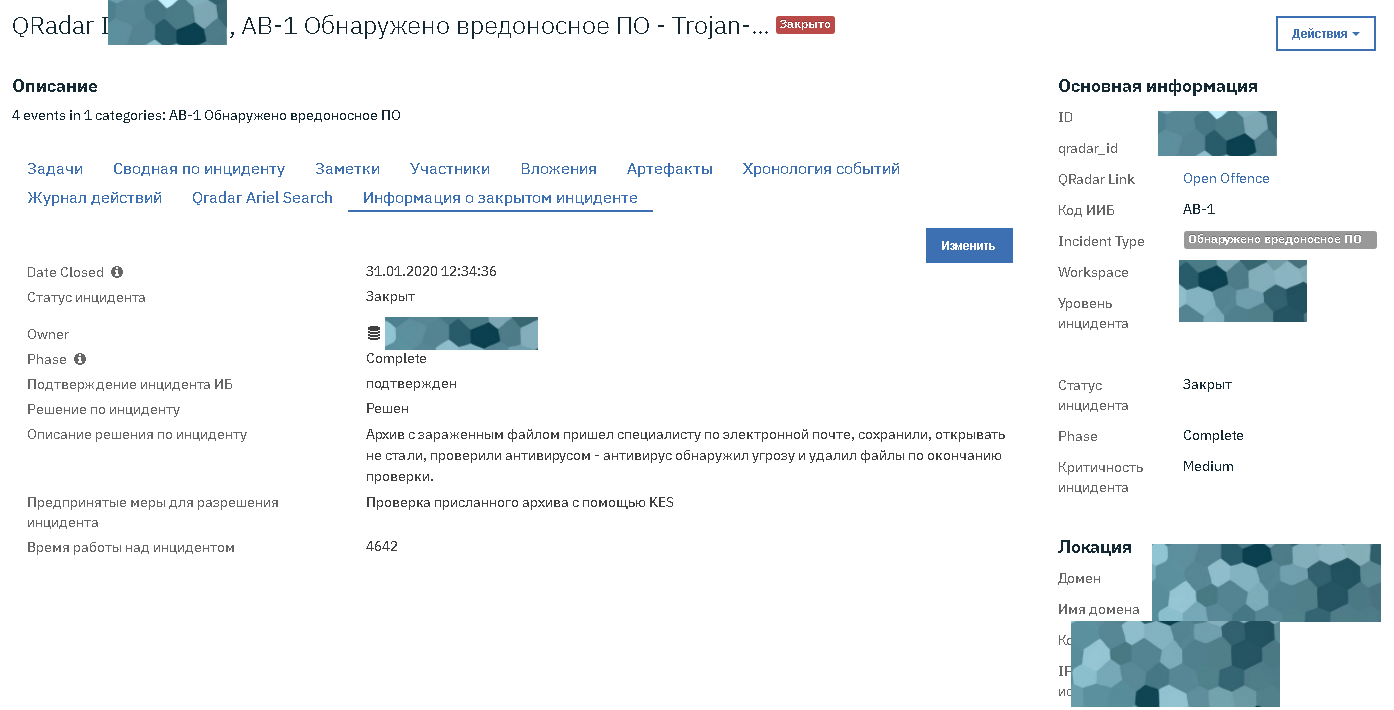
Список оффенсов сильно перегружен сырыми данными. В нашу платформу передаётся карточка конкретного инцидента для наполнения.
У типовых случаев есть типовые блок-схемы реакции.
Вот, например, анализ данных сообщает про ошибки аутентификации юзера:
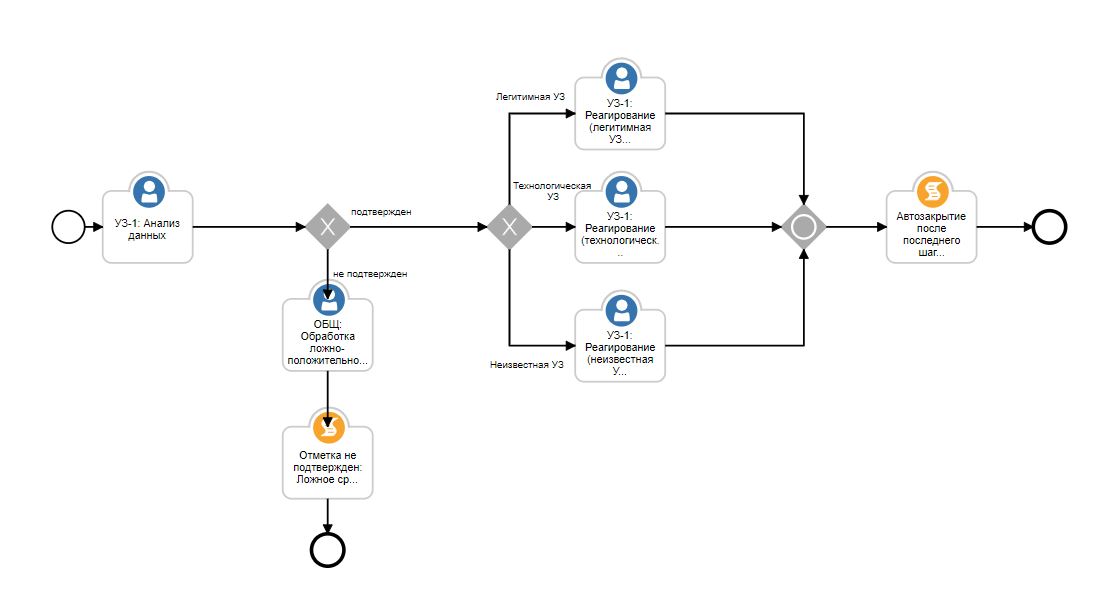
Есть критерии ложного срабатывания: например, два раза попробовал — с третьего зашёл. Юзеру просто приходит письмо про то, что пароль надо набирать внимательнее, тикет закрывается. Если он попробовал пять-шесть раз, то уже начинает собираться детальная информация: что было дальше, что было до этого и так далее. Если он залогинился с 10-го раза, а потом пошёл в базу знаний и запустил закачку 10 файлов, то может быть настройка «заблокировать доступ к базе знаний до конца разбирательства и оповестить оператора». Скорее всего, если пользователь не злонамеренный, в этом случае ИТ-отдел автоматически получит письмо с деталями. Возможно, научат пользователя вводить пароль правильно или помогут его поменять.
Если активность более опасная, уровня «открыли исполняемый файл в почте, а потом что-то начало расползаться по Сети», то может автоматически блокироваться целый сегмент или подсеть. Да, такое может делать и SIEM самостоятельно, но без тонкой настройки, пожалуй, подобные меры — предел автоматизации.
Опять же в идеальном мире оператор имеет доступ ко всем системам и сразу знает, что делать. В реальном мире ему часто нужно найти ответственного, чтобы что-то уточнить. И он ещё и в отпуске или на совещании. Поэтому ещё одна важная часть — в блок-схеме реакции должны сразу находиться ответственные за конкретные участки систем и отделы. То есть нужно не искать руками сотовый этого сотрудника, имя его начальника и его телефон, а сразу видеть их в открытой карточке.
Что мы сделали
- Выявили, какие бывают инциденты безопасности (тревоги), и на первые три десятка самых частых сделали блок-схемы реакции.
- Посмотрели, что делают операторы руками (какую информацию собирают и как на основе неё принимают решения), и написали интеграцию к разным подсистемам, делающую то же самое.
- Автоматизировали то, что можно автоматизировать в блок-схемах. Это перечень действий или запросов: к кому обратиться, какой скрипт выполнить, кого оповестить.
- Добавили интеграции с системой учёта активов, то есть среди прочего получили конкретных ответственных за каждый актив.
- Добавили автозакрытие тикетов.
- Добавили проверку показаний пользователя (часто бывает, что они говорят одно, а делают другое).
- Добавили возможность писать свои скрипты реакции.
- Сделали GUI для блок-схем.
У одного из наших крупных заказчиков — SIEM QRadar. Хорошая система выявления угроз, на каждый инцидент есть действия и шаги, но при этом нельзя дать перечень работ для человека-оператора. Когда речь идёт про профессионала суперкласса, это и не нужно. Когда речь идёт про оператора первой линии, очень важно дать ему инструкции, что и как делать, и он сможет закрывать большую часть типовых инцидентов на уровне крутого специалиста.
То есть мы вынесли все заведомо скучные события на первую линию и добавили в скрипты критерии, которые отделяют скучные от нескучных. Всё нетипичное, как и раньше, падает на профи.
Кейсы на компании в несколько десятков тысяч рабочих мест и со своими серверными мощностями в нескольких ЦОДах прорабатывались и прописывались в итоге около года (там тяжёлые взаимоотношения между подразделениями, что затрудняло интеграцию в разные системы). Зато теперь у любой подзадачи в карточке есть конкретный ответственный, и он всегда актуален.
О простоте для операторов можно судить по тому, что при внедрении сначала система была раскатана на регионы, а потом, спустя пару недель, стала высылаться официальная документация. Так за это время люди уже начали уверенно закрывать инциденты.
С чего началось?
Есть SIEM, но непонятно, что постоянно происходит. Точнее, QRadar генерирует очень много событий, они падают в отдел ИБ, а там просто нет рук всё разбирать правильно и детально. В итоге отчёты просто просматриваются поверхностно. Польза от SIEM при таком подходе не очень высокая.
Есть система управления активами.
Есть сервера для сканирования Сети, очень хорошо настроенные.
Отчёт собирался отличный, но на него устало смотрели и откладывали.
Заказчик захотел, чтобы то, что они купили, начало давать результат.
Мы поставили сверху сервис деск для безопасников (фактически тикет-система, как в обычной поддержке), визуализацию аналитики данных и написали на базе IBM Resilient описанную платформу автоматизации + добавили типовые реакции. Resilient поставляется голая, это просто фреймворк. Мы взяли за основу правила корреляции из QRadar и доработали под юзкейсы планы реагирования.
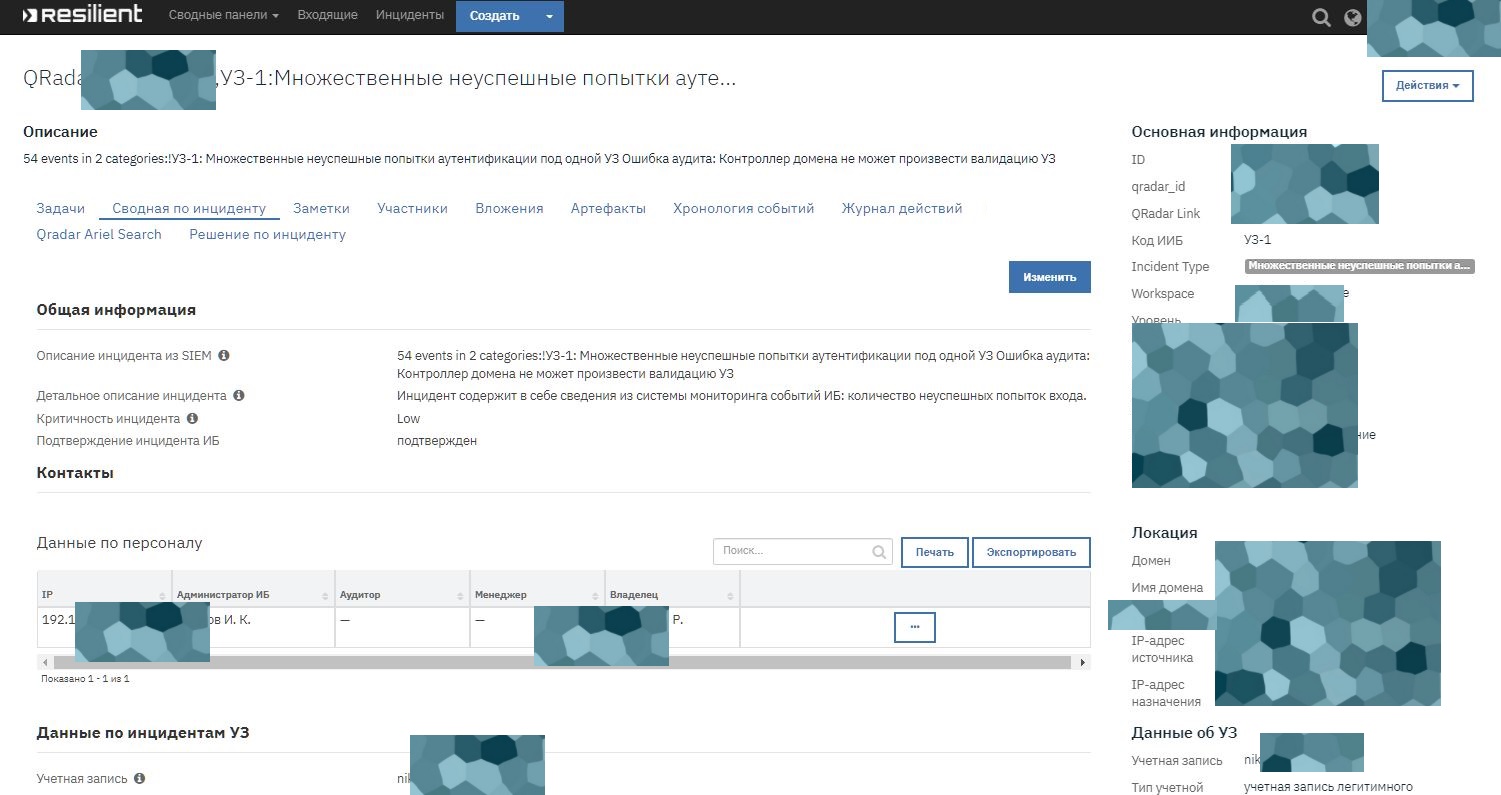
Несколько месяцев делали русификацию всего и провешивали правильные связки по API. Как только мы закончили, вендор выпустил русификацию, и мы немного загрустили.
Около месяца обучали и знакомили с документацией (в частности, как рисовать новые блок-схемы для карточек). Чем дальше учили, тем больше простых случаев стало: сначала писались огромные скрипты действий, а потом получилось, что они стали своего рода библиотекой типовых случаев. И можно было ссылаться на них почти при любой реакции.
Сравнение реакции
Инцидент «Повторное вирусное заражение одинаковым вредоносным ПО за короткий промежуток времени». То есть вирус детектируется на рабочих станциях, но нужен персонал, чтобы понять, откуда он туда попадает. Источник заражения активен.
Классика:
- Произошло повторное вирусное заражение хоста 192.168.10.5 одним и тем же вредоносным ПО за короткий промежутки времени, в SIEM пришли события, и сработало соответствующее правило.
- Оператор проверяет статус антивирусной защиты на хосте через систему управления АВЗ.
- Проверяет актуальность баз через систему управления АВЗ.
- Просматривает описание вируса через систему управления АВЗ или иные источники.
- Определяет критичность инцидента.
- Ищет данные об ответственных лицах в различных справочниках/CMDB-системах.
- Информирует ответственных лиц о факте вирусного заражения.
- Если сканирование данного хоста по каким-либо причинам не проводилось ранее, то оператор инициирует процедуру сканирования данного узла.
- Оператор выпускает отчёт/просматривает статистику по данному хосту в системах анализа защищённости.
- Заполняет заявку в системе Service Desk по результатам расследования для устранения последствий вирусного заражения.
- Заполняет заявку в системе Service Desk по результатам расследования для устранения уязвимости, из-за которой данный хост был заражён.
- Ждёт, когда заявки в Service Desk будут закрыты, после чего проверяет их исполнение.
- Заполняет карточку инцидента и закрывает инцидент.
- Отчитывается руководству о результатах своей работы.
- Аналитик собирает статистику по инцидентам для анализа эффективности процесса реагирования.
На нашей платформе:
- Произошло повторное вирусное заражение хоста 192.168.10.5 одним и тем же вредоносным ПО за короткий промежуток времени, в SIEM пришли события, и сработало соответствующее правило.
- Оператор просматривает карточку инцидента, в которую уже загрузилась информация о данном хосте, статусе средства антивирусной защиты и его логах, имеющихся на хосте уязвимостях, связанных инцидентах и лицах, ответственных за данный хост.
- Оператор выполняет действия по плейбуку, при этом часть действий выполняется автоматически: определение критичности инцидента исходя из критичности хоста и других параметров, информирование ответственных лиц, отправка заявки в Service Desk для устранения последствий вирусного заражения и заявки для устранения уязвимости, из-за которой данный хост был заражён.
- Статус выполнения заявок в Service Desk автоматически проверяется и фиксируется в карточке инцидента, как и все остальные параметры.
- Оператор закрывает инцидент.
- Вся необходимая отчётность для руководства и аналитиков формируется автоматически.
Результаты
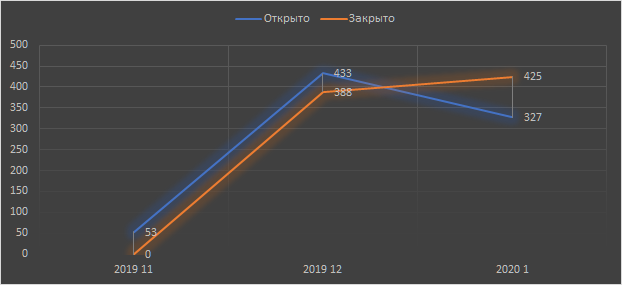
Стало чуть быстрее. Но главное не в этом, а в том, что можно рассортировать задачи на «справится оператор первой линии» и «нужен спец». То есть в среднем решение каждого тикета стало существенно дешевле, а система — масштабируемее.

Кроме множества ложных срабатываний, нашлось много дубликатов, которые оказалось удобно выявлять системой.

Карточки выглядят не как набор непонятных данных из отчёта, а как «Вася сделал на таком-то хосте то-то. Это плохо. За хост отвечает Петя. Вот что точно случилось. Надо подойти к Пете и сказать, что компьютер Васи из рабочей зоны нельзя использовать для показа презентаций на конференциях».
Ещё одна важная вещь во всём этом — на основе сбора первичных данных стало можно давать приоритеты тикетам. То есть главные потенциальные угрозы всплывают наверх и требуют внимания сразу, а не в порядке живой очереди.
Автоматизация на стыке с ИТ-тикетами дала возможность не только собирать всю информацию по инциденту, но и сразу ставить тикеты ИТ-отделу. Если нужно поменять какие-то настройки на маршрутизаторе, то теперь тикет у ИТ генерируется автоматически, например. Что удивительно, начали всплывать случаи «забыли сменить учётку в сервисе, и он пытается месяц подконнектиться». ИТ не видят таких ситуаций или игнорят в инфраструктуре. А тут ИБ говорит — сервис не может залогиниться. И ставят тикет.
Благодаря типизации карточек реакции инциденты стали решаться типовыми способами. Раньше каждый решался творчески: разные люди делали разные действия.
В итоге получился такой хороший воркфлоу, как в современных CRM. Инцидент проходит по воронке. Ещё одна проблема решилась на последней стадии: раньше люди иногда закрывали тикет просто потому, что он надоел. То есть плохо прописывали результат. А теперь нужно доказать системе, что это ложное срабатывание. То есть закрывать-то можно, как раньше, но видно, что, кто и при каких условиях сделал, и вскрыть косяки гораздо легче. Не просто «юзер не смог запустить файл», а «принёс на флешке игру, хотел поставить — ещё раз объяснили правила жизни». И уже понятно, что случилось.
Универсальность
Сейчас в проде — пара интеграций (одна — очень крупная с QRadar и системой управления активами, ещё одна — поменьше). Возможна связка с любой SIEM по стандартным API, но, конечно, интеграция требует времени на коннекторы, доработку напильником и прописывание правил реакции для людей. Тем не менее это очень помогает реально реагировать на инциденты безопасности и делать это относительно быстро и относительно дёшево. Вероятно, что лет через 10 так будут уметь и сами SIEM-системы, но пока наша надстройка хорошо себя показала.
Если хотите пощупать такое у нас или обсудить, как это может выглядеть у вас, — вот моя почта AAMatveev@technoserv.com.
