Планирование аварийного восстановления. Часть первая
Определяем места, где стоит подстелить соломку
 Отказы в работе информационных систем — события, которые невозможно исключить полностью. Вне зависимости от причин случившегося сбоя, в момент его возникновения на системного администратора ложится груз ответственности по оперативному восстановлению работоспособности не только ИТ-систем, но и бизнеса в целом.
Отказы в работе информационных систем — события, которые невозможно исключить полностью. Вне зависимости от причин случившегося сбоя, в момент его возникновения на системного администратора ложится груз ответственности по оперативному восстановлению работоспособности не только ИТ-систем, но и бизнеса в целом.
В цикле из трех коротких статей я постараюсь доступно описать процесс формирования плана аварийного восстановления, который позволяет перевести задачи по восстановлению работоспособности систем в разряд заранее согласованных с руководством мероприятий, имеющих свой график, ресурсы и бюджет.
В первой статье речь пойдет об определении зоны планирования, или поиске тех инфраструктурных элементов, отказ в работе которых негативно влияет на частоту пульса системного администратора. Итак, по порядку:
1. Составляем список критичных пользовательских ИТ-сервисов Цель планирования аварийного восстановления — обеспечить оперативное восстановление работы конечного сервиса, который получает пользователь, а не какой-то конкретной железки или программы. Пользователю не важно, работает или сломан его принтер — ему важно может он отпечатать документы или нет. Жаловаться пользователь будет не на то, что в сервере отказал жесткий диск, а на то, что у него не работает »1С-ка» или «почта».По этой причине первое, что мы делаем — определяем список критичных пользовательских ИТ-сервисов, для которых будем планировать аварийное восстановление. Обычно это:
Электронная почта, Телефонная связь, Система управления предприятием, Совместная работа с документами, Печать документов, Доступ в Интернет, И так далее. По сути, пользовательские сервисы — это те рабочие инструменты, которые покупает бизнес, вкладывая деньги в железо, ПО и зарплаты специалистов и которые критичны для его функционирования. К примеру сервер «Counter Strike», конечно же, является важным элементом в вопросах улучшения рабочего настроения сотрудников, но не критичным для работы бизнеса.2. Определяем точки отказа пользовательских сервисов Если пользователь будет жаловаться на проблемы в каком-то конечном сервисе, то чинить все равно придется конкретный элемент в ИТ-инфраструктуре. Поэтому на данном этапе необходимо обнаружить все системы, приложения и ИТ-сервисы, отказ в работе которых неминуемо приведет к остановке или снижению качества работы критичных пользовательских сервисов. Проще говоря, ваша задача найти все точки отказа.Под точкой отказа мы подразумеваем ту инфраструктурную единицу, о которой мы не можем сказать больше, чем «оно не работает». К примеру, если ваш маршрутизатор модульный, то в нем может отказать как само шасси, так и вставляемые в него модули. Если вашей компетенции достаточно для локализации и замены отказавших блоков в случае сбоя — у вас несколько точек отказа в одном устройства, если нет — то точка отказа одна.
Так, у сервиса «Электронная почта» могут быть следующие точки отказа (включая, но не ограничиваясь):
Серверная ОС, Серверное почтовое приложение, Коммутатор ядра, Электроснабжение, Внешняя зона DNS, Попадание в «черные списки», Кондиционирование серверной. Важно! Не надо исключать из точек отказа сверхнадежное оборудование, с которым «точно ничего не случится». Когда (именно когда, а не если) ваша сверхнадежная СХД потеряет все данные, продолжите ли вы смеяться в цирке или нет, будет зависеть только от вашей готовности к этой ситуации.3. Определяем зависимости точек отказа Сбои в работе некоторых точек отказа могут провоцировать сбои в работе других. К примеру, отказ ИБП приведет к остановке в работе серверов и, как следствие, при восстановлении электроснабжения у вас может не заработать что-то еще. Также и остановка гипервизора может вызвать ошибки в работе виртуальных серверов, размещавшихся на нем. В то же время, отказ клиентского коммутатора не влияет на работу другого оборудования или сервисов, и при его корректной замене все будет работать, как и раньше.Для пользовательского сервиса «Электронная почта» зависимости точек отказа могут выглядеть так:
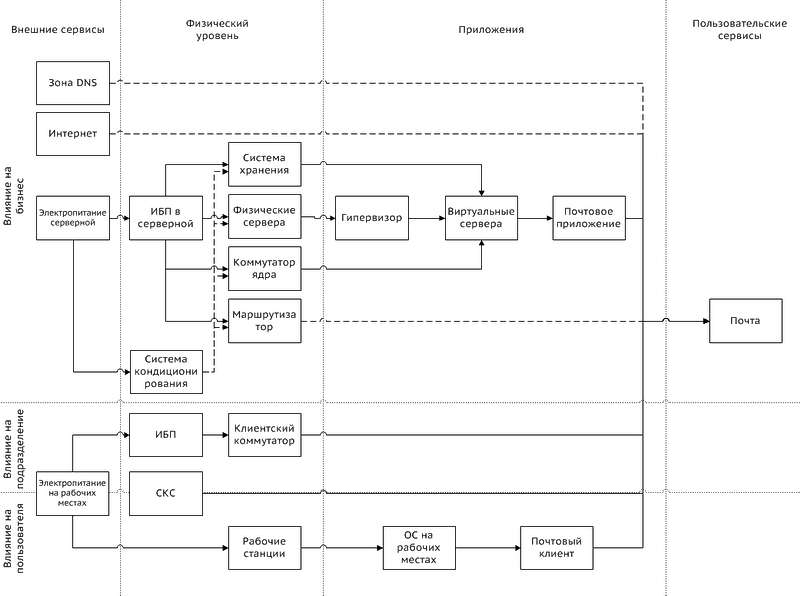 Схема 1. Зависимости точек отказа.
Схема 1. Зависимости точек отказа.
В данную схему необходимо добавить и остальные критичные пользовательские сервисы и соответствующие точки отказа.
Четкое понимание влияния точек отказа друг на друга и на пользовательские сервисы поможет вам при дальнейшем планировании, а именно при составлении процедур локализации точек отказа, определении условий восстановления и факторов риска. Но об этом подробнее в следующей статье.
Хорошего дня!
