Пишем свой плагин для IDEA для поддержки нового языка (часть 2)
Дисклаймер: я не являюсь разработчиком из JetBrains, а жаль, и поэтому в статье и в коде могут быть и скорее всего есть неточности и ошибки.
Часть 1
Введение
Предусловия
Создание основы языкового плагина
Создание PSI-дерева
— Лексер
— Парсер
Аннотаторы
Подсветка скобок
Часть 2
В предыдущей статье был рассмотрен процесс создания каркаса языкового плагина. В качестве примера использовались известные плагины для Java, go, Frege. Также приведены примеры из плагина для языка Monkey, который я разработал пока разбирался, как все работает. Так как у меня не было целью охватить всё, то плагин охватывает некоторое ограниченное подмножество языка. Сам интерпретатор можно найти тут.
Форматирование
Документация, примеры в go-plugin, monkey.
Все как всегда начинается с точки расширения.
Класс должен имплементировать интерфейс
public interface FormattingModelBuilder {
@NotNull
FormattingModel createModel(@NotNull FormattingContext formattingContext);
@Nullable
TextRange getRangeAffectingIndent(PsiFile file, int offset,
ASTNode elementAtOffset) ;
}Наиболее важный — первый метод. Он возвращает модель форматирования, которая в свою очередить строится на блоках форматирования. Для упрощения можно воспользоваться методом FormattingModelProvider.createFormattingModelForPsiFile
Рассмотрим подробнее что такое блок форматирования. В IDEA блок форматирования представлен как интерфейс com.intellij.formatting.Block — это некоторый диапазон текста (часто соответствующий какому-то PSI-элементу), к которому применяются правила форматирования. Блоки форматирования вкладываются друг в друга и образуют дерево.
Исходный код Block
public interface Block {
@NotNull
TextRange getTextRange();
@NotNull
List getSubBlocks();
@Nullable
Wrap getWrap();
@Nullable
Indent getIndent();
@Nullable
Alignment getAlignment();
@Nullable
Spacing getSpacing(@Nullable Block child1, @NotNull Block child2);
@NotNull
ChildAttributes getChildAttributes(final int newChildIndex);
boolean isIncomplete();
boolean isLeaf();
@Nullable
default String getDebugName() {
return null;
}
} Для того чтобы увидеть визуализацию этого дерева, можно воспользоваться инструментом PSI-Viewer (Tools→View PSI Structure, раздел Block Sructure)

Для упрощения реализации можно воспользоваться классом AbstractBlock. При этом вместо метода getSubBlocksон предлагает реализовывать метод buildChildren, который возращает список непосредственных дочерних элементов данного блока.
getSpacing — определяет количество пробелов или перенос строк между указанными дочерними элементами. Для упрощения реализации данной логики можно воспользоваться классом com.intellij.formatting.SpacingBuilder, который предоставляет удобное API для описания правил.
//сильно упрощенный пример из плагина plugin-go
public Spacing getSpacing(@Nullable Block child1, @NotNull Block child2) {
return new SpacingBuilder(settings, GoLanguage.INSTANCE)
.before(COMMA).spaceIf(false)
.after(COMMA).spaceIf(true)
.betweenInside(SEMICOLON, SEMICOLON, FOR_CLAUSE).spaces(1)
.before(SEMICOLON).spaceIf(false)
.after(SEMICOLON).spaceIf(true)
.beforeInside(DOT, IMPORT_SPEC).none()
.afterInside(DOT, IMPORT_SPEC).spaces(1)
//и так далее
.getSpacing(this, child1, child2);
}Если не подходит builder, то можно создать свое описание через com.intellij.formatting.Spacing#createSpacing
getIndent — определяет правила отступа относительно родительского блока
getWrap — нужно ли переносить на другую строчку контент
getAlignment — выравнивание блоков друг относительно друга
getChildIndent — используется AbstractBlock для вычисления getChildAttributes, который возвращает правила для блока, создаваемого после нажатия клавиши Enter.
Structure view
В этом разделе пойдет речь об наполнении вот этой панели:

За это отвечает точка расширения
Класс должен имплементировать интерфейс:
@FunctionalInterface
public interface PsiStructureViewFactory {
@Nullable
StructureViewBuilder getStructureViewBuilder(@NotNull PsiFile psiFile);
}Для реализации StructureViewBuilder можно использовать уже готовые заготовки com.intellij.ide.structureView.TreeBasedStructureViewBuilder, com.intellij.ide.structureView.StructureViewModelBase и com.intellij.ide.structureView.impl.common.PsiTreeElementBase.
Работа с PsiTreeElementBase напоминает работу с блоками форматирования.
Документация. Примеры реализации в plugin-go, Monkey.
Кэши, индексы, stub и goto
Кэши
Начнем с кэшей. IDEA опрашивает многие расширения по нескольку раз. Если расширение выполняет какую-то тяжелую работу, то самое лучшее решение — это закэшировать результат этой работы. IDEA предоставляет много готовых оберток для этого. Например, так вычисляется тип Go выражения в плагине plugin-go:
@Nullable
public static GoType getGoType(@NotNull GoExpression o, @Nullable ResolveState context) {
return RecursionManager.doPreventingRecursion(o, true, () -> {
if (context != null) return unwrapParType(o, context);
return CachedValuesManager.getCachedValue(o, () -> CachedValueProvider.Result
.create(unwrapParType(o, createContextOnElement(o)), PsiModificationTracker.MODIFICATION_COUNT));
});
}
Здесь используется 2 менеджера. Первый — CachedValuesManager, который кэширует результат для psi-элемента, и второй — RecursionManager, который помогает предотвращать бесконечную рекурсию и StackOverflowError. Также есть специализированный кэш com.intellij.psi.impl.source.resolve.ResolveCache, который используется при разрешении (resolving) элементов (про это ниже).
Индексы
 Взято из reddit
Взято из reddit
Документация. Все мы знаем как IDEA любит всё индексировать. Давайте посмотрим, что это такое и как это можно использовать.
Индексы в IDEA предоставляют возможность быстро находить файл с привязанной другой информацией или psi-элемент по выбранному ключу (например, по названию аннотации можно найти все места, где она используется).
Посмотреть существующие индексы можно с помощью плагина Index viewer. О том, как все работает, также можно почитать в статье про Frege.
IDEA поддерживает два вида индексов — File-based и Stub. File-based работает с содержимым файла, Stub работает с Stub-деревом, которое строится на базе Psi-дерева.
File-based индексы.
Пример использования можно посмотреть в плагине haskforce
Начинается все как всегда с подключения точки расширения
Файл должен расширять FileBasedIndexExtension. Получить результаты индексирования можно через
FileBasedIndex.getInstance()Плагин haskforce, например, использует этот тип индекса, чтобы получить все файлы в рамках модуля:
@NotNull
public static Collection getVirtualFilesByModuleName(@NotNull String moduleName, @NotNull GlobalSearchScope searchScope) {
return FileBasedIndex.getInstance()
.getContainingFiles(HASKELL_MODULE_INDEX, moduleName, searchScope);
}
Stub индексы
Этот тип индексов, как мне кажется, используется чаще, так как позволяет искать по PSI-элементам (а точнее по stub, который отображает требуемую часть psi-дерева). Stub используются только для именнованных psi-элементов (которые имплементируют интерфейс PsiNamedElement). О них будет подробнее написано в разделе Reference
Чтобы объявить новый индекс, используется следующая точка расширения:
Класс должен имплементировать StubIndexExtension(или его наследников, например, StringStubIndexExtension).
Пример из плагина для Monkey:
class MonkeyVarNameIndex : StringStubIndexExtension() {
override fun getVersion(): Int {
return super.getVersion() + VERSION
}
override fun getKey(): StubIndexKey {
return KEY
}
companion object {
val KEY: StubIndexKey =
StubIndexKey.createIndexKey("monkey.var.name")
const val VERSION = 0
}
} Примеры в go-plugin, frege.
Теперь нам нужно научить IDEA создавать дерево Stub-ов и записывать необходимые элементы под нужным индексом.
Для каждого типа элементов, который мы хотим сохранить как Stub, мы создаем определение Stub. При этом корнем всех Stub-ов должен быть FileStub.
Пример из плагина для Monkey:
class MonkeyFileStub(file: MonkeyFile?) : PsiFileStubImpl(file)
class MonkeyVarDefinitionStub : NamedStubBase {
constructor(parent: StubElement<*>?, elementType: IStubElementType<*, *>, name: StringRef?) : super(
parent,
elementType,
name
)
constructor(parent: StubElement<*>?, elementType: IStubElementType<*, *>, name: String?) : super(
parent,
elementType,
name
)
}
Примеры из go-plugin (файл, элемент), Frege (файл, элемент)
Следующий шаг — для каждого Stub создать описание типа элемента этого Stub. (Для автоматически генерируемых PSI-элементов с помощь Grammar-Kit плагина описания каждого типа элемента создается автоматически в соответствии с параметрами elementTypeHolderClass и elementTypeClass). ElementType для файла должен расширять IStubFileElementType, для элемента — IStubElementType.
IStubElementType требует реализации следующих методов:
@NotNull
String getExternalId();
void serialize(@NotNull T stub, @NotNull StubOutputStream dataStream) throws IOException;
@NotNull
T deserialize(@NotNull StubInputStream dataStream, P parentStub) throws IOException;
void indexStub(@NotNull T stub, @NotNull IndexSink sink);
PsiT createPsi(@NotNull StubT stub);
@NotNull StubT createStub(@NotNull PsiT psi, StubElement parentStub);
shouldCreateStub(ASTNode node)
Как индексировать Stub указывается в методе indexStub . Например, в Monkey я использовал такую реализацию:
override fun indexStub(stub: S, sink: IndexSink) {
val name = stub.name
if (name != null) {
sink.occurrence(MonkeyVarNameIndex.KEY, name)
}
}Реализацию других методов можно посмотреть в примерах — плагин для Monkey, go-plugin, Frege
Теперь наши stub-ы надо подключить к парсеру. Это делается в 2 шага.
1 шаг: определить свою фабрику типов элементов, для которых мы сделали
IStubElementType, например как
object MonkeyElementTypeFactory {
@JvmStatic
fun factory(name: String): IElementType {
if (name == "VAR_DEFINITION") return MonkeyVarDefinitionStubElementType(name)
throw RuntimeException("Unknown element type: $name")
}
}
и указать в bnf файле, что теперь ее надо использовать для некоторых PSI-элементов:
elementTypeFactory("var_definition")=
"com.github.pyltsin.monkeyplugin.psi.impl.MonkeyElementTypeFactory.factory"Рассмотрим все вместе. В процессе индексации создается StubBasedPsiElementBase, затем с помощью IStubElementType.createStub создается Stub, который сериализуется (serialize) и ссылка на него сохраняется в индекс (indexStub).
Клиентский код, который работает со Stub, полученными из индексов, должен вызывать только те методы, для выполнения которых достаточно сохраненной информации. Поэтому в stub надо включать всю информацию, которая может понадобится в дальнейшем при анализе. Чтобы получить PSI-элемент, можно вызвать метод getNode (), но он дорогой, так как требует парсинга файла.
Пример сохранения информации можно посмотреть в com.intellij.psi.impl.java.stubs.impl.PsiAnnotationStubImpl#getPsiElement, в котором используется текст из ASTNode.
Использование stub индексов
Индексы широко используются для go-to функций. Например, для работы данной панели:
 Упрощенная реализация go-to для символов (Symbols) на основе индекса
Упрощенная реализация go-to для символов (Symbols) на основе индекса
plugin.xml:
MonkeySymbolContributor:
class MonkeySymbolContributor : ChooseByNameContributorEx {
private val myIndexKeys = listOf(MonkeyVarNameIndex.KEY)
override fun processNames(
processor: Processor,
scope: GlobalSearchScope,
filter: IdFilter?
) {
for (key in myIndexKeys) {
ProgressManager.checkCanceled()
StubIndex.getInstance().processAllKeys(
key,
processor,
scope,
filter
)
}
}
override fun processElementsWithName(
name: String,
processor: Processor,
parameters: FindSymbolParameters
) {
for (key in myIndexKeys) {
ProgressManager.checkCanceled()
StubIndex.getInstance().processElements(
key,
name,
parameters.project,
parameters.searchScope,
parameters.idFilter,
MonkeyNamedElement::class.java,
processor
)
}
}
} Многие плагины также используют индексы. Например, Request mapper (на данный момент не поддерживается, так как такая же функциональность появилась в IDEA), который помогает искать точки объявления REST-методов
 Пример работы Request Mapper
Пример работы Request Mapper Пример работы в IDEA (можно ограничить поиск набрав /url)
Пример работы в IDEA (можно ограничить поиск набрав /url)
Под капотом RequestMapper использует такой код:
//JavaAnnotationIndex - обычный Stub index для Java для аннотаций
JavaAnnotationIndex
.getInstance()
.get(annotationName, project, GlobalSearchScope.projectScope(project))
.asSequence()
Ссылки (References)
Документация
На данный момент идет изменение API в этой части, поэтому могут быть неточности.
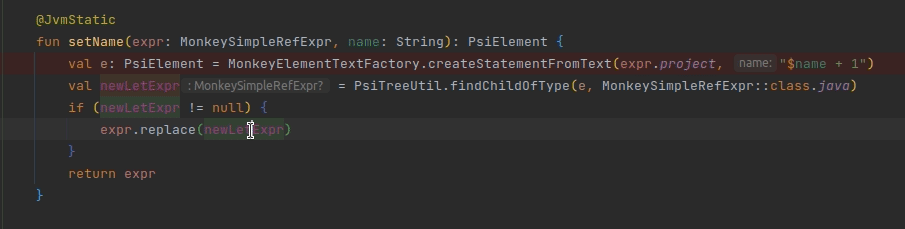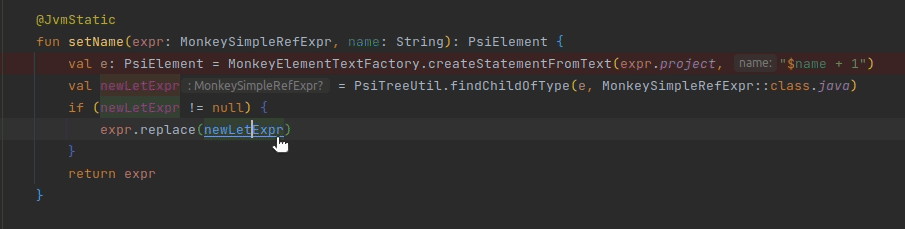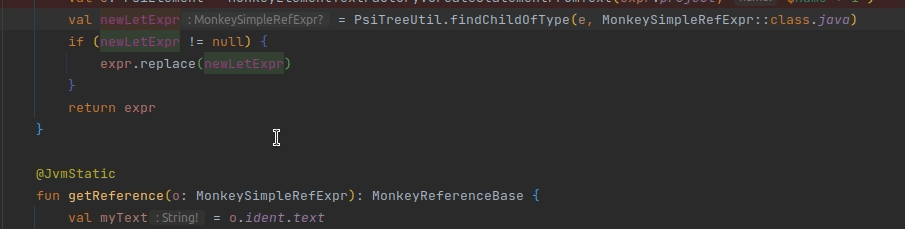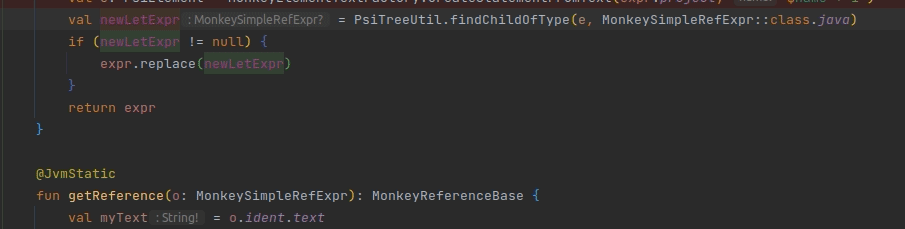
Ссылки создают связи между элементами, так, нажав Ctrl+B, вы перейдете на тот элемент, на который эта ссылка ссылается. Нажав Ctrl+B еще раз, вы увидите все элементы, которые ссылаются на этот элемент.
Элемент, который ссылается, и элемент, на который ссылаются, также могут иметь имя. Только тот элемент, который определяет это имя, должен реализовывать PsiNamedElement (а лучше PsiNameIdentifierOwner, их использование можно посмотреть в разделе Rename)
@JvmStatic
fun setName(expr: MonkeySimpleRefExpr, name: String): PsiElement {
val e: PsiElement = MonkeyElementTextFactory.createStatementFromText(expr.project, "$name + 1")
//newLetExpr должен реализовывать PsiNamedElement
val newLetExpr = PsiTreeUtil.findChildOfType(e, MonkeySimpleRefExpr::class.java)
if (newLetExpr != null) {
expr.replace(newLetExpr) //newLetExpr должен предоставлять ссылку
}
return expr
}Для того чтобы PSI-элемент мог предоставить ссылку, нужно реализовать методы
PsiReference getReference();
//если элемент ссылается на несколько элементов, то
PsiReference @NotNull [] getReferences();
//или новый метод
@Experimental
default @NotNull Iterable getOwnReferences() {
return Collections.emptyList();
}Для упрощения реализации интерфейса PsiReference можно воспользоваться заготовкой PsiReferenceBase. Остается реализовать метод PsiElement resolve() илиResolveResult [] multiResolve(boolean incompleteCode), которые возвращают элементы, на которые ссылаются. При реализации этого метода имеет смысл использовать специализированный кэш:
override fun multiResolve(incompleteCode: Boolean): Array {
return ResolveCache.getInstance(psiElement.project).resolveWithCaching(
this, { referenceBase, _ ->
referenceBase.resolveInner(false)
.map { PsiElementResolveResult(it) }
.toTypedArray()
},
true, false
)
} После реализации данной части IDEA уже сможет предоставлять навигацию к элементу, на который ссылаются и обратно.
Find Usages
Документация. Примеры go-plugin, monkey.
Предоставляет возможность из этого меню:
Точка расширения:
Класс должен реализовать интерфейс FindUsagesProvider.
Rename и другие рефакторинги
Документация
Одним из самых популярных рефакторингов является переименование (Shift+F6)
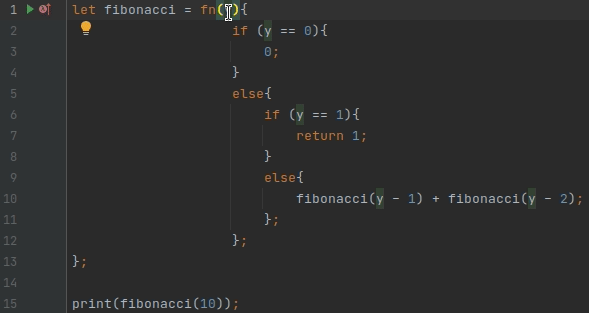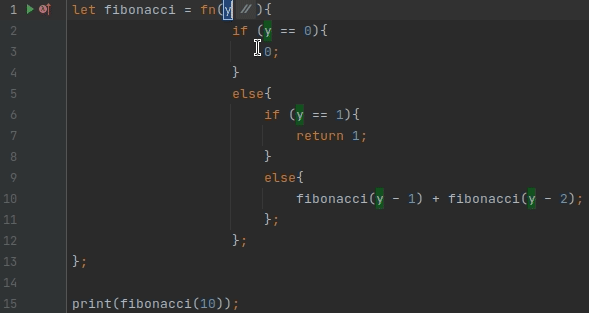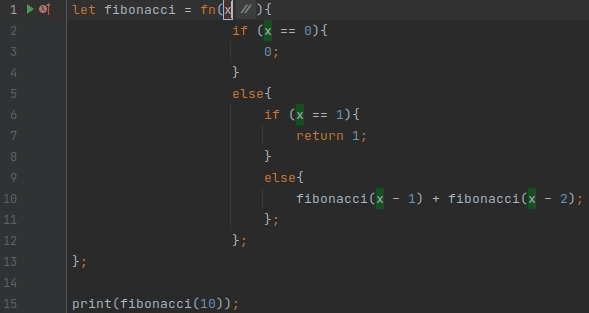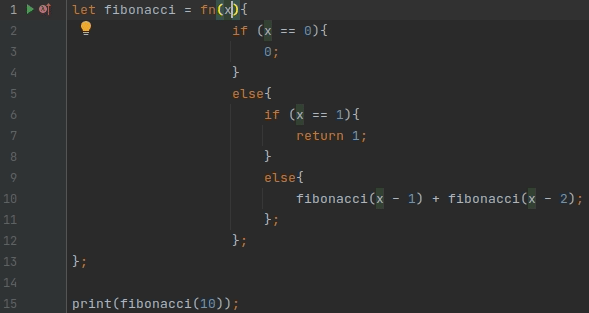
За это отвечают две точки расширения:
renameInputValidator должен реализовывать интерфейс RenameInputValidator
refactoringSupport должен расширять абстрактный класс RefactoringSupportProvider. Данный класс также содержит методы для поддержки других видов рефакторингов. На данный момент нас интересует метод, который указывает, поддерживается ли редактирование на месте.
public boolean isMemberInplaceRenameAvailable(@NotNull PsiElement element, @Nullable PsiElement context) {
return false;
}Теперь требуется реализовать методы переименования. Как уже было сказано до этого, PSI-элемент, который определяет имя, следует реализовывать интерфейс PsiNamedElement.
public interface PsiNamedElement extends PsiElement {
String getName();
PsiElement setName(@NlsSafe @NotNull String name)
throws IncorrectOperationException;
}Нас здесь интересует метод setName. Одним из самых простых способов реализовать этот метод — это создать новый PSI-элемент из текста, например так
private fun createFileFromText(project: Project, text: String): MonkeyFile {
return PsiFileFactory.getInstance(project)
.createFileFromText("A.monkey", MonkeyLanguage.INSTANCE, text) as MonkeyFile
}
И заменить элемент
expr.replace(newLetExpr)Осталось реализовать переименование элементов, которые ссылаются на наш именованный PSI-элемент. Для этого нужно реализовать метод из PsiReference
PsiElement handleElementRename(@NotNull String newElementName)
throws IncorrectOperationException;или воспользоваться готовой реализацией из com.intellij.psi.PsiReferenceBase, если она подходит.
Маркеры (Markers)
IDEA активно использует подсказки в виде маркеров

Примеры go-plugin, Frege, monkey
Точка расширения:
Файл должен реализовывать интерфейс LineMarkerProvider, методы которого возвращают объект LineMarkerInfo . Обратите внимание, что маркеры следует привязывать только к листьям PSI-дерева
Автодополнение
Думаю, все кто работает с IDEA любит, как она работает с подсказками (хотя, конечно, есть случаи, когда она немного тупит). Написать хороший механизм автодополнения очень сложно. Был даже цикл статье про это. Но при этом можно относительно быстро реализовать некоторые подсказки, например, вот такие:
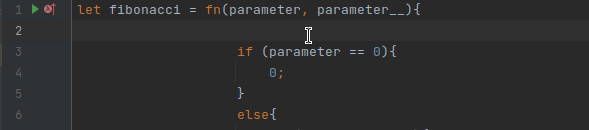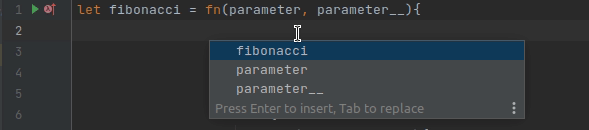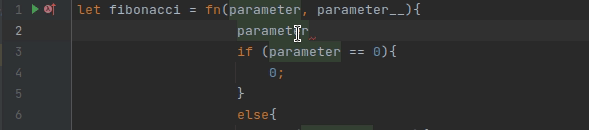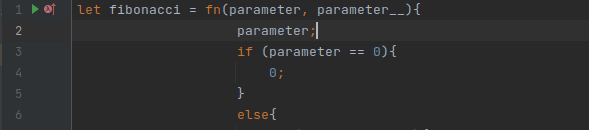
Это делается через реализацию метода PsiReference.getVariants, который должен возвращать все видимые подходящие значения. Фильтрацию по символам выполняет сама IDEA.
Для более сложных кейсов можно воспользоваться точкой расширения:
Класс должен реализовывать абстрактный класс CompletionContributor.
Документация. Примеры реализации go-plugin, frege, monkey (начальная поддержка автодополнения ключевых слов)
Тестирование
Документация. Тестирование frege
В IDEA тесты часто представляют собой несколько файлов с исходным кодом языка, которые показывают состояние ДО и ПОСЛЕ действия. Для тестов обычно используется класс BasePlatformTestCase, а сами тесты выглядят как-то так:
myFixture.configureByFiles("RenameTestData.monkey")
myFixture.renameElementAtCaret("test")
myFixture.checkResultByFile("RenameTestData.monkey", "RenameTestDataAfter.monkey", false)где RenameTestData.monkey и RenameTestDataAfter.monkey — файлы с исходным кодом до и после переименования.
Заключение
На этом рассказ о создании языкового плагина для IDEA закончен. Удачи в настройке своего IDE под себя!
