Первая бесплатная модель перевода с русского на китайский язык и обратно

Представляю вашему вниманию, первую бесплатную offline модель по переводу с русского языка на китайский и обратно.
Ранее, я писал, как можно достаточно легко обучить свою модель по машинному переводу на примере перевода с английского на русский.
В этот раз я решил, реализовать, модель перевода с китайского языка, так как давно хотел и о чем заявлял в комментариях к предыдущей своей статье.
С прошлой статьей, вы можете познакомится здесь: https://habr.com/ru/post/689580/
Введение
Тема машинного перевода всегда была достаточно актуальной, и остается таковой и сейчас. Для обучения модели машинного перевода, требуется большое количество параллельных текстов. Если параллельных текстов с с английским языком достаточно много, то с другими языками вроде китайского, все намного сложнее, и найти большое количество текстов достаточно сложно.
Существенный прорыв в этом вопросе был произведен после выхода корпуса CCMatriх. https://opus.nlpl.eu/CCMatrix.php
В котором было просканировано 1197 битекстов, на 90 различных языках мира.
На текущий момент появились модели вроде facebook/nllb-200-distilled-600M, способные переводить сразу с 200 различных языков, однако после проведенного мною анализа, показали, что такие модели переводят достаточно плохо, и в реальной работе для перевода текстов их использовать практически невозможно. Кроме того, лицензия модели cc-by-nc-4.0, не позволяет её использовать в коммерческих целях.
Данные для обучения
Для обучения своей модели машинного перевода я использовать большое количество параллельных корпусов текстов, с сайта https://opus.nlpl.eu/
В качестве данных для обучения я использовал список корпусов текстов: UNPC_v1_0_ru-zh, CCMatrix_v1_ru-zh, MultiUN_v1_ru-zh, LinguaTools-WikiTitles_v2014_ru-zh, News-Commentary_v16_ru-zh, WikiMatrix_v1_ru-zh, Tanzil_v1_ru-zh, MultiParaCrawl_v9b_ru-zh, bible-uedin_v1_ru-zh, TED2020_v1_ru-zh, infopankki_v1_ru-zh, tico-19_v2020–10–28_ru-zh,
QED_v2.0a_ru-zh, NeuLab-TedTalks_v1_ru-zh,
PHP_v1_ru-zh, wikimedia_v20210402_ru-zh, ELRC-wikipedia_health_v1_ru-zh, Ubuntu_v14.10_ru-zh, EUbookshop_v2_ru-zh
В общем итоге корпус получился размеров в 35 млн парных предложений и переводов.
Обучение
Обучение производилось полностью на основе инструкции из прошлой статьи https://habr.com/ru/post/689580/
В итоге получилось две модели машинного перевода, которые можно использовать в переводчике Argos Translate.
Первая модель translate-ru_zh-1_7.argosmodel — необходима для перевода с Русского на Китайский
Вторая модель translate-zh_ru-1_7.argosmodel — необходима для перевода с Китайского на Русский
Код для использования модели в Python:
import pathlib
import argostranslate.package
import argostranslate.translate
package_path = pathlib.Path("translate-zh_ru-1_7.argosmodel")
argostranslate.package.install_from_path(package_path)
from_code = 'zh'
to_code = 'ru'
translatedText = argostranslate.translate.translate("吃一些软的法国面包。", from_code, to_code)
print(translatedText)
#Съесть мягкий французский хлеб.В этот раз, я решил так же обучить модель, с более популярной архитектурой, которую бы разработчики могли использовать в своих проектах. За основу я взял архитектуру mbart50, с предобученными весами.
Данная модель специально создавалась для решения задач машинного перевода, предобученные веса модели уже обучены на задаче и с использованием текстов на 50 различных языках мира.
Для машинного перевода, я не стал обучать модель mbart50 с нуля, а взял уже предобученные веса, и использовал метод дообучения (fine-tune)
Изначально в модели присутствовали токены от 50 различных языков, мне же необходима была только пара Русский и Китайский, в результате чего, я перед обучение сжал модель, путем удаления лишних слов на слоях эмбеддингов и на последнем слое нейросети, в результате количество токенов в словаре уменьшилось с 250 тысяч, до 45 тысяч. Модель при этом похудела с 2.3 гигабайт до 1.6 гигабайт, немного больше чем на 30%, без изменения качества и скорости её работы. Обучать такую модель стало немного проще.
Код такого сжатия я опубликовал здесь.
Для дообучения модели я использовал инструкцию с сайта от huggingface
https://huggingface.co/docs/transformers/training
Модель mbart я обучал переводить сразу с китайского на русский и обратно. В результате одну модель можно использовать для перевода с русского на китайский, так и с китайского на русский язык. Что в свою очередь позволяет использовать одну модель, для задачи перефразирования. Путем перевода текста сначала с русского на китайский, а затем обратно. В результате мы можем получим перефразированную версию одного и того же текста.
Пример кода функции перефразирования:
from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
model = MBartForConditionalGeneration.from_pretrained("joefox/mbart-large-ru-zh-ru-many-to-many-mmt")
tokenizer = MBart50TokenizerFast.from_pretrained("joefox/mbart-large-ru-zh-ru-many-to-many-mmt")
def text_paraphrase(src_text):
# translate Russian to Chinese
tokenizer.src_lang = "ru_RU"
encoded_ru = tokenizer(src_text, return_tensors="pt")
generated_tokens = model.generate(
**encoded_ru,
forced_bos_token_id=tokenizer.lang_code_to_id["zh_CN"]
)
result = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# translate Chinese to Russian
tokenizer.src_lang = "zh_CN"
encoded_zh = tokenizer(result, return_tensors="pt")
generated_tokens = model.generate(
**encoded_zh,
forced_bos_token_id=tokenizer.lang_code_to_id["ru_RU"]
)
tgt_text = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
return tgt_text
result = text_paraprase("Съешь ещё этих мягких французских булок.")
print(result)
#Ешьте французский хлеб.Оценка результатов
Для оценки результатов, мне пришлось самостоятельно подготовить новый корпус китайско-русских переводов. За основу я взял исходных корпус, который используется для оценки моделей opus, это корпус текстов newstest. Но так как в этом корпусе отсутствует пара переводов zh-ru. Я собрал свой корпус, на основе имеющихся. Для этого я взял все новости переведенные с китайского на английский, и с английского на русский, и нашел среди них пересекающие идентичные новости. Результате у меня получился, очень хороший русско-китайский корпус, на котором можно оценивать качество перевода с русского на китайский и обратно. Я решил поделится данным корпусом со всеми, и его теперь можно скачать здесь newstest-2017–2019-ru_zh
Я произвел оценку качества перевода различных моделей на опубликованном датасете newstest-2017–2019-ru_zh, и сравнил производительность.
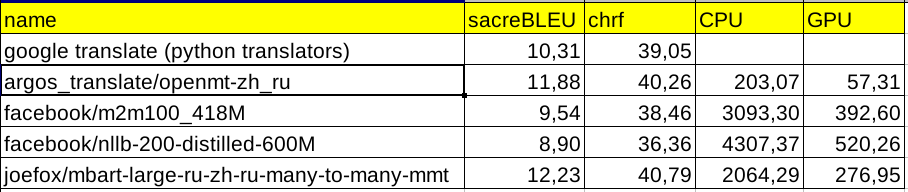
В колонке CPU и GPU представлено время перевода одного предложения данной моделью без использования батчей, в миллисекундах.
Для полной наглядности, я взял для сравнения еще две известные мультиязычные модели машинного перевода m2m100_418M и nllb-200-ditilled-600M, а также прогнал перевод датасета через переводчик Google Translate, с помощью библиотеки Python — translators. Однако я заметил, что в браузере Google Translate переводит более качественно, чем через библиотеку translators.
По полученным метрикам, самой быстрой моделью на CPU оказалась модель обученная для argos_translate, причем по качеству она существенно обгоняет как переводчик от Google Translate, так и модели m2m100_418M и nllb-200-ditilled-600M.
Самой качественной моделью оказалась моя модель joefox/mbart-large-ru-zh-ru-many-to-many-mmt, показав метрику sacreBLEU 12.23 в задаче машинного перевода с китайского на русский язык.
Выводы
Пока модели не включили в официальный репозиторий Argos Translate вы можете скачать их с Yandex диска и использовать либо в приложении Argos Translate, либо в python.
translate-ru_zh-1_7.argosmodel
translate-zh_ru-1_7.argosmodel
Модель mbart выложена на huggingface joefox/mbart-large-ru-zh-ru-many-to-many-mmt с примерами её использования.
Я выкладываю модели в общий доступ, надеюсь, что они вам пригодятся.
Также мне хотелось бы продолжить работу по улучшению моделей перевода с русского на китайский и обратно. Поэтому если у вас есть идеи, как улучшить качество данных моделей. Может быть вы знаете, где можно найти большое количество Русско-Китайских параллельных корпусов текстов в интернете, присылайте любую информацию в личку или в комментарии. Буду очень рад любым идеям.
Кроме того, вы можете самостоятельно обучать свою модель, и использовать датасет newstest-2017–2019-ru_zh, для оценки качества и сравнения с моей моделью.
