Передаём файл между изолированными виртуальными машинами без регистрации и СМС
В интернете кто-то неправ
Не далее пяти дней назад на хабре появилась новость под заголовком «В Apple M1 нашли уязвимость M1RACLES — возможна быстрая скрытая передача данных между приложениями». В одном предложении суть формулируется так: в Apple M1 нашли регистр, который кто угодно может читать и писать из непривилегированного режима. Значит, это можно использовать для обмена данными в обход механизмов межпроцессного взаимодействия, предоставленных ОС. Однако, сам автор эту особенность значимой уязвимостью не считает, о чём пишет в разъяснительном комментарии:
So what’s the point of this website?
Poking fun at how ridiculous infosec clickbait vulnerability reporting has become lately. Just because it has a flashy website or it makes the news doesn’t mean you need to care.If you’ve read all the way to here, congratulations! You’re one of the rare people who doesn’t just retweet based on the page title:-)
But how are journalists supposed to know which bugs are bad and which bugs aren’t?
Talk to people. In particular, talk to people other than the people who discovered the bug. The latter may or may not be honest about the real impact.If you hear the words «covert channel»… it’s probably overhyped. Most of these come from paper mills who are endlessly recycling the same concept with approximately zero practical security impact. The titles are usually clickbait, and sometimes downright deceptive.
В комментариях к этой публикации развязалась умеренно оживлённая дискуссия о статусе находки: всё-таки серьёзная уязвимость или пустяк? Наряду с @SergeyMaxи @wataru я обратил внимание, что каналов скрытого обмена и так существует предостаточно просто потому, что исполняющая клиентский софт или виртуальные машины аппаратура является разделяемой средой, грамотная модуляция состояний которой делает возможным произвольный обмен данными вне зависимости от инвариантов нижележащей ОС или гипервизора. Противоположной точки зрения придерживаются почтенные господа @creker и @adjachenko, утверждая, что доселе известные побочные каналы качественно уступают возможностям M1RACLES.
Эта заметка является наглядной иллюстрацией к моему утверждению о легкодоступности скрытых каналов обмена. Я собрал простой PoC из ~500 строк на C++, при помощи которого был успешно отправлен файл из одной виртуальной машины в другую на том же физическом хосте. Далее я кратко описываю его устройство, пределы применимости, и привожу выводы и мнение самого автора M1RACLES в конце.
Я не являюсь специалистом по информационной безопасности, поэтому чрезмерно полагаться на мои собственные выводы в конце статьи не следует.
Передача
Повторю ключевой тезис для прозрачности: в общем случае, полная информационная изоляция исполняемых на едином аппаратном узле сред невозможна, потому что общая среда исполнения является разделяемым ресурсом, модуляция состояний которого может использоваться для построения каналов обмена данными. Гипервизоры, MMU, ОС, и прочие информационные барьеры могут лишь затруднить скрытый обмен данными, но не предотвратить его.
В случае M1RACLES, Apple случайно положила подходящий аппаратный ресурс на самое видное место. В других платформах общих регистров может не быть, но остаются другие средства. Сегодня мы сфокусируемся на вычислительных ресурсах процессора; любознательный читатель может в качестве факультатива слегка модифицировать код PoC, чтобы вместо процессорного времени модуляции подвергались, скажем, температура видеокарты, задержка доступа к файловой системе или RAM (забиванием кэша), и т.п.
Известная теория обработки сигналов предлагает метод кодовой модуляции, широко применяемый для широкополосной передачи через зашумлённую среду. Кодовая модуляция позволяет получателю вытянуть полезный сигнал из-под шумовой полки, если известна кодирующая последовательность; для остальных же наблюдателей (включая приёмники с другой кодирующей последовательностью) сигнал будет выглядеть как шум. Единая среда может поддерживать теоретически неограниченное количество передатчиков с разными кодирующими последовательностями при условии их достаточного различия.
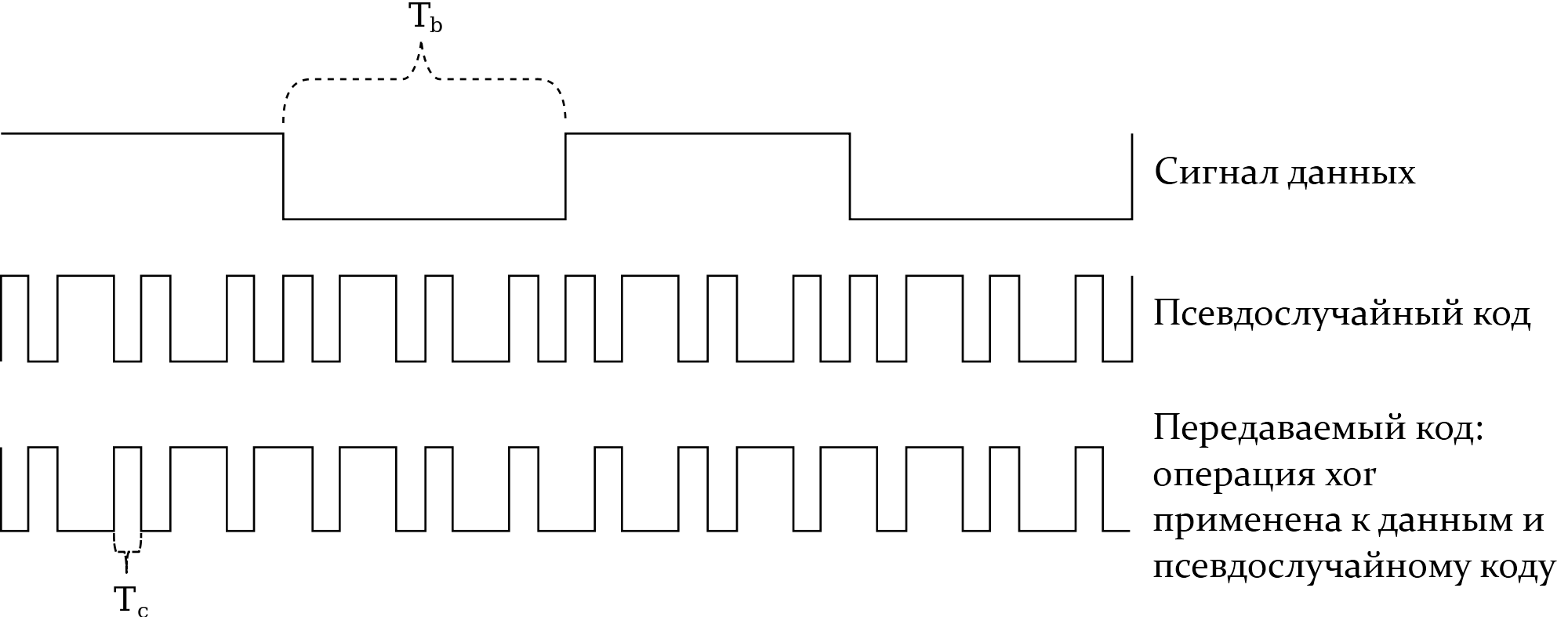 Автор: Ivajkin Timofej (translated from the english wiki) — en.wikipedia.org, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php? curid=15444663
Автор: Ivajkin Timofej (translated from the english wiki) — en.wikipedia.org, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php? curid=15444663Мы будем передавать высокие уровни кодирующего сигнала повышая нагрузку на процессор, и наоборот:
void drivePHY(const bool level, const std::chrono::nanoseconds duration)
{
static auto deadline = std::chrono::steady_clock::now();
deadline += duration; // Используем абсолютное время для предотвращения дрейфа фазы сигнала
if (level) // Передаём высокий уровень высокой нагрузкой
{
std::atomic finish = false;
const auto loop = [&finish]() {
while (!finish) { }
};
static const auto thread_count = std::max(1, std::thread::hardware_concurrency());
std::vector pool;
for (auto i = 0U; i < (thread_count - 1); i++)
{
pool.emplace_back(loop);
}
while (std::chrono::steady_clock::now() < deadline) { }
finish = true;
for (auto& t : pool)
{
t.join();
}
}
else // Низкий уровень -- низкой нагрузкой
{
std::this_thread::sleep_for(deadline - std::chrono::steady_clock::now());
}
} В примере мы нагружаем все ядра, что весьма расточительно. Можно нагружать лишь одно ядро, если ОС предоставляет API для задания CPU core affinity (macOS, насколько мне известно, не предоставляет), но это создаст трудности в преодолении барьеров виртуализации, потому что одно ядро внутри гипервизора может отображаться на другое физическое ядро хоста. Однако, если API для affinity есть, и нет нужды пробрасывать канал передачи между изолированными виртуальными средами, можно сделать так:
#include // -lpthread
cpu_set_t cpuset{};
CPU_ZERO(&cpuset);
CPU_SET(0, &cpuset);
pthread_setaffinity_np(pthread_self(), sizeof(cpu_set_t), &cpuset); Как уже сказано, один бит передаётся прямым или инверсным кодом:
constexpr std::chrono::nanoseconds ChipPeriod{16'000'000}; // ок. 1...100 мс
std::bitset CDMACode("..."); // код пропущен
void emitBit(const bool value)
{
for (auto i = 0U; i < CDMACode.size(); i++)
{
const bool bit = value ^ !CDMACode[i];
drivePHY(bit, ChipPeriod);
}
} Пакеты будем разделять девятью (или больше) нулевыми битами, а перед байтом данных будем отправлять один высокий бит, чтобы отличать его от разделителя пакетов (здесь есть простор для оптимизации):
void emitByte(const std::uint8_t data)
{
emitBit(1); // Стартовый бит
auto i = 8U; // Старший бит идёт первым
while (i --> 0)
{
emitBit((static_cast(data) & (1ULL << i)) != 0U);
}
}
void emitFrameDelimiter()
{
for (auto i = 0U; i < 20; i++) // не менее 9 нулевых битов
{
emitBit(0);
}
}
Для обнаружения ошибок в конце каждого пакета добавим два байта обыкновенной CRC-16-CCITT:
void emitPacket(const std::vector& data)
{
emitFrameDelimiter();
std::uint16_t crc = CRCInitial;
for (auto v : data)
{
emitByte(v);
crc = crcAdd(crc, v);
}
emitByte(static_cast(crc >> 8U));
emitByte(static_cast(crc >> 0U));
emitFrameDelimiter();
} Здесь у кого-то может возникнуть идея использовать традиционные коды Хэмминга для коррекции ошибок передачи, но у нас будет возможность разменивать пропускную способность канала на вероятность корректной передачи подстройкой длины кодирующей последовательности — сам метод кодового разделения уже предоставляет средства коррекции ошибок на битовом уровне.
Приём
Если сигнал передаётся модуляцией нагрузки процессора, то на принимающей стороне мы можем оценить состояние среды передачи измеряя скорость каких-либо вычислений в быстром цикле. Например, можно инкрементировать счётчики. Создаваемые передатчиком флуктуации доступного процессорного времени затем извлекаются фильтром высоких частот, давая на выходе (сильно зашумлённый) сигнал:
bool readPHY()
{
static auto deadline = std::chrono::steady_clock::now(); // См. заметку о дрейфе фазы
deadline += SampleDuration;
const auto started_at = std::chrono::steady_clock::now();
std::vector counters;
const auto loop = [&counters](std::uint32_t index) {
auto& cnt = counters.at(index);
while (std::chrono::steady_clock::now() < deadline)
{
cnt++;
}
};
static const auto thread_count = std::max(1, std::thread::hardware_concurrency());
if (thread_count > 1)
{
counters.resize(thread_count, 0);
std::vector pool;
for (auto i = 0U; i < thread_count; i++)
{
pool.emplace_back(loop, i);
}
for (auto& t : pool)
{
t.join();
}
}
else
{
counters.push_back(0);
loop(0);
}
const double elapsed_ns =
std::chrono::duration_cast(std::chrono::steady_clock::now() - started_at).count();
const double rate = double(std::accumulate(std::begin(counters), std::end(counters), 0)) / elapsed_ns;
static double rate_average = rate;
rate_average += (rate - rate_average) / PHYAveragingFactor;
return rate < rate_average; // Просадка производительности если передатчик нагрузил ЦП
} Обратите внимание, что конкретно эта реализация загружает все ядра процессора работой, что, конечно, чрезвычайно расточительно. Для передачи данных в пределах одной ОС (т.е., не пересекая границы виртуализированных сред) можно ограничиться одним ядром, как уже было показано выше.
Снова хочу отметить, что вместо модуляции загрузки ЦП можно управлять чем угодно ещё. Например, можно загружать диск или забивать кэш процессора холодными данными из памяти. Единственное требование заключается в получении на выходе (зашумлённого) двоичного сигнала, который можно семплировать с достаточно высокой фиксированной частотой.
Полученный зашумлённый сигнал с удалённым постоянным смещением мы направляем в CDMA коррелятор, как я изобразил на схеме:
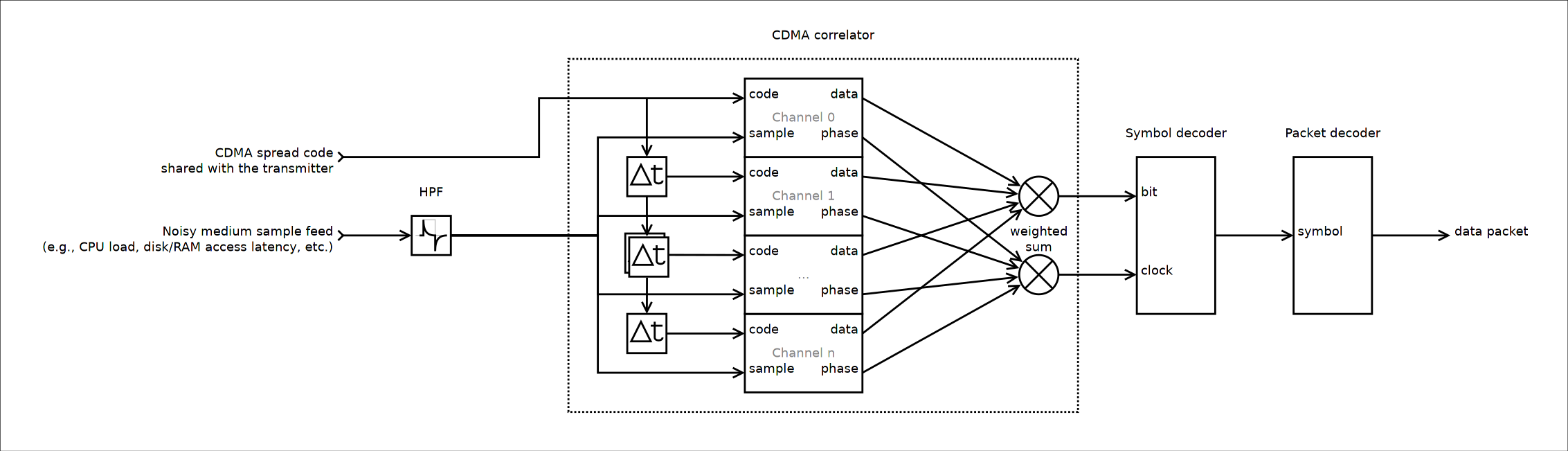 Принципиальная схема приёмного тракта
Принципиальная схема приёмного трактаКоррелятор направляет полученную последовательность выборок состояния среды передачи в массив каналов. Каждый канал имеет общую кодирующую последовательность, но смещение в пределах последовательности у каждого канала своё. Каждая полученная выборка сравнивается с кодирующей последовательностью канала; затем, в конце периода последовательности подсчитывается количество совпадений, которое определяется шумом в канале передачи и фазовым сдвигом относительно кодирующей последовательности передатчика. Итоговый сигнал извлекается взвешенным суммированием выхода каждого канала, где вес определяется корреляцией локальной кодирующей последовательности канала с полученным сигналом.
Аналогичным образом извлекается информация о фазе сигнала: на выходе каждого канала мы имеем пилообразный сигнал, представляющий фазу кодирующей последовательности текущего канала. Подсчитанная аналогично предыдущему случаю взвешенная сумма представляет очищенный от шума тактирующий сигнал, на основании которого дальнейшая логика приёмного тракта защёлкивает принятые биты данных.
Практические системы здесь обычно включают фазовую автоподстройку частоты для синхронизации длительности периода кодирующей последовательности между передатчиком и приёмником. Мы этого делать не станем в угоду простоте реализации. Вместо этого, состояние среды передачи будет семплироваться с утроенной частотой; соответственно, количество каналов коррелятора будет равно длине кодирующей последовательности, умноженной на три.
Знакомый с обработкой сигналов в телекомах читатель сейчас понимающе позёвывает, ведь похожие принципы используются во многих распространённых приложениях, от GPS до сотовых сетей. Для сравнения, типичная архитектура приёмного тракта GPS приёмника выглядит примерно так (каналы Qx на схеме можно проигнорировать, поскольку квадратурное разложение в нашей среде смысла не имеет):
 Схема из «Principles of GNSS, inertial, and multisensor integrated navigation systems», P.D. Groves, 2-е изд.
Схема из «Principles of GNSS, inertial, and multisensor integrated navigation systems», P.D. Groves, 2-е изд.Использование достаточно длинной кодирующей последовательности позволяет установить канал связи с произвольно низкой вероятностью ошибок поверх произвольно зашумлённой среды. Впрочем, зависимость между скоростью и шумовым порогом, разумеется, является фундаментальной для телекомов вообще.
Прямое применение кодов Хэмминга здесь вряд ли оправданно, потому что условия, при которых могут возникать битовые инверсии сигнала, неизбежно приведут к искажениям тактового сигнала, из чего последуют пропуски либо спонтанное защёлкивание бит, что сделает коды Хэмминга неэффективными. Более совершенные методы коррекции ошибок вроде кодов Рида-Соломона или LDPC представляют интерес, но их реализация несколько выходит за рамки этого эксперимента ввиду сравнительно высокой сложности.
Полученные на выходе коррелятора биты декодируются в пакеты тривиальной логикой, зеркалирующей логику передатчика, что я привёл выше. Здесь её код я показывать не буду, вместо этого рекомендую сразу пройти на гитхаб и увидеть всё сразу:
https://github.com/pavel-kirienko/cpu-load-side-channel
Результат
Процесс передачи файла с одной виртуалки на другую я записал на видео:
Условия здесь были далеки от идеальных, потому что в фоне на хосте виртуализации работал ffmpeg (записывающий это видео в 4K в реальном времени на процессоре), браузер с ~30 вкладками и музыкой, вечно голодная до ресурсов плазма с виджетами и обычный набор каждодневного софта на моей рабочей станции. Я привожу это в качестве дополнительной иллюстрации (очевидного) факта, что устойчивость канала к шуму является лишь вопросом минимальной скорости передачи.
Последняя может вызвать у читателя здравое недоумение: на видео, тактовый период кодирующей последовательности был равен 16 мс, и её длина 1023 бит, т.е., передача одного бита занимала примерно 16 секунд, давая скорость около 0.06 бит в секунду. Передача семибайтового файла с CRC и разделителями заняла почти полчаса. Много ли можно дел наворотить на такой-то скорости?
Если сравнивать с M1RACLES (скорость передачи более 8 Mb/s), то нет. Если сравнивать с популярным предположением по-умолчанию об информационной изоляции виртуализированных сред (скорость передачи 0 b/s), то да.
Преодоление барьеров виртуализации сильно зашумляет канал, что требует использования более длинной кодирующей последовательности. Также увеличивается временной джиттер, что требует и увеличения продолжительности тактового периода. Процессы же в пределах одной ОС могут коммуницировать на скорости более одного бита в секунду, в чем легко убедиться на практике, поменяв параметры ChipPeriod и CDMACodeLength в PoC (я экспериментировал на Manjaro с ядром 5.4 на Intel Core i7 990X @ 4 GHz).
Поддержание канала в текущей реализации требует постоянной полной загрузки процессора (или хотя бы одного его ядра) процессом-приёмником, что может стать серьёзным ограничением. Это, вероятно, можно обойти использованием более сложных схем модуляции, либо модуляцией состояний других системных ресурсов; например, загрузки диска или кэша процессора. Желающие поэкспериментировать приглашаются поделиться результатами.
Также было бы интересно поэкспериментировать с передачей за пределы изолированных систем (airgapped networks), о чём писал Mordechai Guri и многие до него. Для этого можно подвергать модуляции шум системы охлаждения, температуру её выхлопа, ЭМИ, светодиоды на клавиатуре, и вообще всё, что имеет видимые внешние проявления.
Выводы
Я опубликовал заметку в /r/netsec об этом эксперименте, где в комментариях отметился Hector Martin, автор M1RACLES. Моя изначальная позиция была следующая: побочные каналы присутствуют всегда и в любой системе; M1RACLES лишь добавляет ещё один, а значит, это ничего кардинально не меняет. Если считать его уязвимостью, это делает любую систему в принципе уязвимой по-умолчанию, ведь побочные каналы устранить невозможно; значит, сам термин «уязвимость» применимо к компьютерным системам теряет информационную нагрузку.
Вероятно, сведущему в инфобезе человеку такой взгляд на вещи покажется наивным, я мало знаком с этой областью. Hector Martin скорректировал мои заблуждения, указав на то, что уязвимость как абсолютная метрика бессмысленна, всегда необходимо учитывать контекст. В этом смысле, наличие высокоскоростного канала скрытого обмена несколько расширяет множество реализуемых атак, следовательно, M1RACLES является вполне реальной уязвимостью, пусть и по-прежнему крайне малой значимости. Ниже релевантная часть его комментария для полноты:
We already know all systems are vulnerable to certain side-channel attacks. In particular, all systems with shared resources have side channels. Those side channels are easy to turn into covert channels, as you did. The bandwidth, and the severity, is proportional to how closely coupled the security domains are (as you found out, where the VM boundary reduces your performance). As the severity gets higher, you go from 1 bit per second covert channels, to megabytes per second covert channels, to actually being able to steal data from noncooperative entities (actual dangerous side channels) under increasingly less demanding circumstances.
[…]
So M1RACLES is interesting because it is not a side channel — so it poses no danger of leaking data from unwitting processes — but it is a highly efficient covert channel, which does matter under a very small but not nonexistent set of attack scenarios. Does it add covert channel capability where none existed prior? No. But that doesn’t mean it’s not a vulnerability; as I said, we don’t qualify systems on some kind of absolute «vulnerable/not vulnerable» scale. We look at individual issues and then figure out how they affect the overall security of the system under certain attack scenarios.
Заодно он жёстко раскритиковал работу Mordechai Guri, указав на околонулевую дельту его публикаций. Однако, это я не берусь комментировать, поскольку в инфобезе не ориентируюсь. Для меня это всё представляет интерес лишь в контексте технической реализации обработки сигналов, нежели значения для отрасли.
Финальные выводы я сделал следующие:
ОС и гипервизоры не являются средствами информационной изоляции и не в состоянии предотвратить межпроцессный обмен данными.
Однако, скрытый межпроцессный обмен серьёзной угрозой не является.
M1RACLES количественно улучшает доселе существующие возможности скрытого обмена, но итоговый эффект остаётся незначительным.

