Patroni Failure Stories or How to crash your PostgreSQL cluster. Алексей Лесовский

Основная цель Patroni — это обеспечение High Availability для PostgreSQL. Но Patroni — это лишь template, а не готовый инструмент (что, в общем, и сказано в документации). На первый взгляд, настроив Patroni в тестовой лабе, можно увидеть, какой это прекрасный инструмент и как он легко обрабатывает наши попытки развалить кластер. Однако на практике в производственной среде, не всегда всё происходит так красиво и элегантно, как в тестовой лабе.

Расскажу немного про себя. Я начинал системным администратором. Работал в веб-разработке. С 2014-го года работаю в Data Egret. Компания занимается консалтингом в сфере Postgres. И мы обслуживаем именно Postgres, и каждый день работаем с Postgres, поэтому у нас есть разная экспертиза, связанная с эксплуатацией.
И в конце 2018-го года мы начали потихоньку использовать Patroni. И накопился какой-то определенный опыт. Мы как-то диагностировали его, тюнили, пришли к своим best practices. И в этом докладе я буду о них рассказывать.
Помимо Postgres я люблю Linux. Люблю в нем ковыряться и исследовать, люблю собирать ядра. Люблю виртуализацию, контейнеры, докер, Kubernetes. Меня это все интересует, потому что сказываются старые админские привычки. Люблю разбираться с мониторингами. И люблю postgres«овые вещи, связанные с админством, т. е. репликация, резервное копирование. И в свободное время пишу на Go. Не являюсь software engineer, просто для себя пишу на Go. И мне это доставляет удовольствие.

- Я думаю, многие из вас знают, что в Postgres нет HA (High Availability) из коробки. Чтобы получить HA, нужно что-то поставить, настроить, приложить усилия и получить это.
- Есть несколько инструментов и Patroni — это один из них, который решает HA довольно-таки круто и очень хорошо. Но поставив это все в тестовой лабе и запустив, мы можем посмотреть, что это все работает, мы можем воспроизводить какие-то проблемы, посмотреть, как Patroni их обслуживает. И увидим, что все это прекрасно работает.
- Но на практике мы сталкивались с разными проблемами. И про эти проблемы я буду рассказывать.
- Расскажу, как мы это диагностировали, что подкручивали — помогло ли это нам или не помогло.

- Я не буду рассказывать, как установить Patroni, потому что можно нагуглить в интернете, можно посмотреть файлы конфигурации, чтобы понять, как это все запускается, как настраивается. Можно разобраться в схемах, архитектурах, найдя информацию об этом в интернете.
- Не буду рассказывать про чужой опыт. Буду рассказывать только про те проблемы, с которыми столкнулись именно мы.
- И не буду рассказывать про проблемы, которые за пределами Patroni и PostgreSQL. Если, например, проблемы, связанные с балансировкой, когда у нас кластер развалился, я про это рассказывать не буду.

И небольшой disclaimer перед тем, как начать наш доклад.
Все эти проблемы, с которыми мы столкнулись, они были у нас в первые 6–7–8 месяцев эксплуатации. Со временем мы пришли к своим внутренним best practices. И проблемы у нас исчезли. Поэтому доклад заявлялся где-то полгода назад, когда это все было свежо в голове и я это все прекрасно помнил.
По ходу подготовки доклада я уже поднимал старые постмортемы, смотрел логи. И часть деталей могла забыться, либо часть каких-то деталей могли быть не доисследована в ходе разбора проблем, поэтому в каких-то моментах может показаться, что проблемы рассмотрены не полностью, либо есть какой-то недостаток информации. И поэтому прошу меня за этот момент извинить.

Что такое Patroni?
- Это шаблон для построения HA. Так написано в документации. И с моей точки зрения, это очень правильное уточнение. Patroni — это не серебрянная пуля, которая решит все ваши проблемы, т. е. нужно приложить усилие, чтобы оно начало работать и приносить пользу.
- Это агентская служба, которая устанавливается на каждом сервисе с базой данной, и которая является своего рода init-системой для вашего Postgres. Она запускает Postgres, останавливает, перезапускает, меняет конфигурацию и меняет топологию вашего кластера.
- Соответственно, чтобы хранить состояние кластера, его текущее представление, как он выглядит, нужно какое-то хранилище. И с этой точки зрения Patroni пошел по пути хранения state во внешней системе. Это система распределенного хранилища конфигурации. Это могут быть Etcd, Consul, ZooKeeper, либо kubernetes«кий Etcd, т. е. какой-то из этих вариантов.
- И одной из особенностей Patroni — это то, что автофайловер вы получаете из коробки, только его настроив. Если взять для сравнения Repmgr, то файловер там идет в комплекте. С Repmgr мы получаем switchover, но если хотим автофайловер, то его нужно дополнительно настроить. В Patroni уже есть автофайловер из коробки.
- И есть много еще других вещей. Например, обслуживание конфигураций, наливка новых реплик, резервное копирование и т. д. Но это за пределами доклада, про это я рассказывать не буду.

И небольшой итог — это то, что основная задача Patroni — это хорошо и надежно делать автофайловер, чтобы кластер у нас оставался работоспособным и приложение не замечало изменений в топологии кластера.

Но когда мы начинаем использовать Patroni, наша система становится чуть сложнее. Если раньше у нас был Postgres, то при использовании Patroni мы получаем сам Patroni, мы получаем DCS, где хранится state. И все это должно как-то работать. Поэтому, что может сломаться?
Может сломаться:
- Может сломаться Postgres. Это может быть мастер или реплика, что-то из них может выйти из строя.
- Может сломаться сам Patroni.
- Может сломаться DCS, где хранится state.
- И может сломаться сеть.
Все эти моменты я буду рассматривать в докладе.

Я буду рассматривать случаи по мере их усложнения, не с точки зрения, того что кейс затрагивает много компонентов. А с точки зрения субъективных ощущений, что этот кейс был для меня сложный, его было сложно разбирать… и наоборот, какой-то кейс был легкий и его было легко разбирать.

И первый случай самый простой. Это тот случай, когда мы взяли кластер баз данных и на этом же кластере развернули наше хранилище DCS. Это самая распространенная ошибка. Это ошибка построения архитектур, т. е. совмещение разных компонентов в одном месте.
Итак, произошел файловер, идем разбираться с тем, что произошло.

И здесь нас интересует, когда произошел файловер. Т. е. нас интересует вот этот момент времени, когда произошло изменение состояния кластера.
Но файловер не всегда одномоментный, т. е. он не занимает какую-то единицу времени, он может затянуться. Он может быть продолжительным во времени.
Поэтому у него есть время начала и время завершения, т. е. это продолжительное событие. И мы делим все события на три интервала: у нас есть время до файловера, во время файловера и после файловера. Т. е. мы рассматриваем все события в этой временной шкале.

И первым делом, когда произошел файловер, мы ищем причину, что произошло, что стало причиной того, что привело к файловеру.
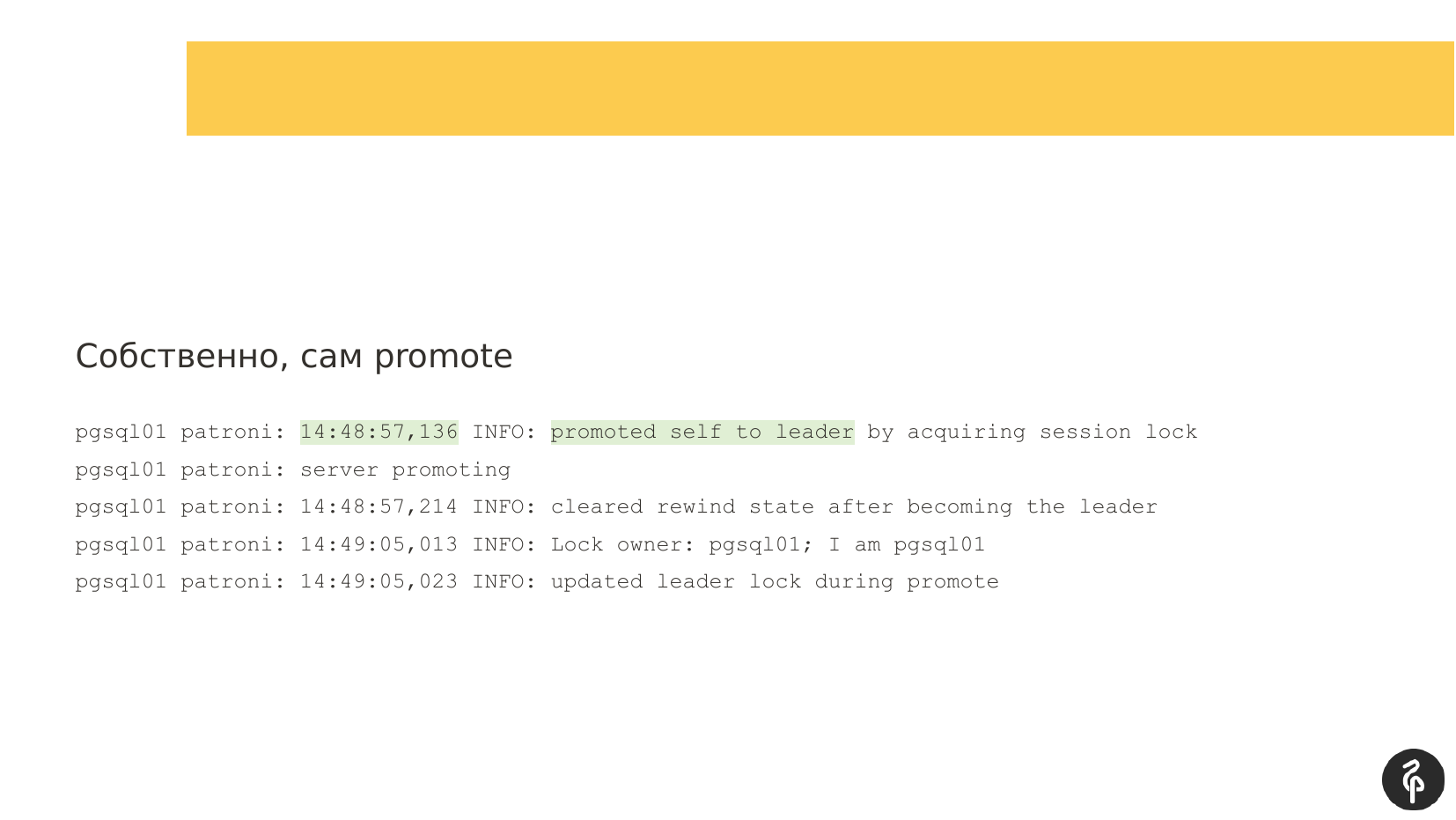
Если мы посмотрим на логи, то это будут классические логи Patroni. Он в них нам сообщает, что сервер стал мастером, и роль мастера перешла на этот узел. Тут это подсвечено.

Дальше нам нужно понять, почему произошел файловер, т. е. какие произошли события, которые заставили роль мастера переехать с одного узла на другой. И в данном случае здесь все просто. У нас есть ошибка взаимодействия с системой хранения. Мастер понял, что он не может работать с DCS, т. е. возникла какая-то проблема с взаимодействием. И он говорит, что не может быть больше мастером и слагает с себя полномочия. Вот эта строчка «demoted self» говорит именно об этом.

Если посмотреть на события, которые предшествовали файловеру, то мы там можем увидеть те самые причины, которые послужили проблемой для продолжения работы мастера.
Если посмотреть на логи Patroni, то мы увидим, что у нас есть масса всяких ошибок, тайм-аутов, т. е. агент Patroni не может работать с DCS. В данном случае это Consul agent, с которым идет общение по порту 8500.
И проблема здесь заключается в том, что Patroni и база данных запущены на одном хосте. И на этом же узле были запущены Consul-сервера. Создав нагрузку на сервере, мы создали проблемы и для серверов Consul. Они не смогли нормально общаться.

Через какое-то время, когда нагрузка спала, наш Patroni смог снова общаться с агентами. Нормальная работа возобновилось. И тот же самый сервер Pgdb-2 снова стал мастером. Т. е. был небольшой флип, из-за которого узел сложил с себя полномочия мастера, а потом снова их на себя взял, т. е. все вернулось, как было.

И это можно расценивать как ложную сработку, либо можно расценивать, что Patroni сделал все правильно. Т. е. он понял, что не может поддерживать состояние кластера и снял с себя полномочия.
И здесь проблема возникла из-за того, что Consul-сервера находятся на том же оборудовании, что и базы. Соответственно, любая нагрузка: будь то нагрузка на диски или процессоры, она также влияет на взаимодействие с кластером Consul.

И мы решили, что это не должно жить вместе, мы выделили отдельный кластер для Consul. И Patroni работал уже c отдельным Consul’ом, т. е. был отдельно кластер Postgres, отдельно кластер Consul. Это базовая инструкция, как нужно все эти вещи разносить и держать, чтобы оно не жило вместе.
Как вариант можно покрутить параметры ttl, loop_wait, retry_timeout, т. е. попытаться за счет увеличения этих параметров пережить эти кратковременные пики нагрузки. Но это не самый подходящий вариант, потому что вот эта нагрузка может быть продолжительной по времени. И мы просто выйдем за вот эти лимиты этих параметров. И это может не совсем помочь.

Первая проблема, как вы поняли, простая. Мы взяли и DCS положили вместе с базой, получили проблему.

Вторая проблема похожа на первую. Она похожа тем, что у нас снова есть проблемы взаимодействия с системой DCS.

Если мы посмотрим на логи, то мы увидим, что у нас снова ошибка коммуникации. И Patroni говорит, что я не могу взаимодействовать с DCS, поэтому текущий мастер переходит в режим реплики.
Старый мастер становится репликой, здесь Patroni отрабатывает, как и положено. Он запускает pg_rewind, чтобы отмотать журнал транзакции и потом подключиться к новому мастеру, и уже догнать новый мастер. Тут Patroni отрабатывает, как ему и положено.

Здесь мы должны найти то место, которое предшествовало файловеру, т. е. те ошибки, которые послужили причиной, почему у нас файловер произошел. И в этом плане с логами Patroni довольно удобно работать. Он с определенным интервалом пишет одни и те же сообщения. И если мы начинаем проматывать эти логи быстро, то мы по логам увидим, что логи поменялись, значит, какие-то проблемы начались. Мы быстро возвращаемся на это место, смотрим, что происходит.
И в нормальной ситуации логи выглядят примерно так. Проверяется владелец блокировки. И если владелец, допустим, поменялся, то могут наступить какие-то события, на которые Patroni должен отреагировать. Но в данном случае у нас все в порядке. Мы ищем то место, когда начались ошибки.

И промотав до того места, когда ошибки начали появляться, мы видим, что у нас произошел автофайловер. И раз у нас ошибки были связаны с взаимодействием с DCS и в нашем случае мы использовали Consul, мы заодно смотрим и в логи Consul, что происходило там.
Примерно сопоставив время файловера и время в логах Consul, мы видим, что у нас соседи по Consul-кластеру начали сомневаться в существовании других участников Consul-кластера.

И если еще посмотреть на логи других Consul-агентов, то там тоже видно, что там какой-то сетевой коллапс происходит. И все участники Consul-кластера сомневаются в существовании друг друга. И это послужило толчком к файловеру.
Если посмотреть, что происходило до этих ошибок, то можно увидеть, что есть всякие ошибки, например, deadline, RPC falled, т. е. явно какая-то проблема при взаимодействии участников Consul-кластера между собой.

Самый простой ответ — это чинить сеть. Но мне, стоя на трибуне, легко об этом заявлять. Но обстоятельства складываются так, что не всегда заказчик может себе позволить чинить сеть. Он может жить в ДЦ и может не иметь возможностей чинить сеть, влиять на оборудование. И поэтому нужны какие-то другие варианты.

Варианты есть:
- Самый простой вариант, который написан, по-моему, даже в документации, это отключить Consul-проверки, т. е. просто передать пустой массив. И мы говорим Consul-агенту не использовать никаких проверок. За счет этих проверок мы можем игнорировать эти сетевые штормы и не инициировать файловер.
- Другой вариант — это перепроверить raft_multiplier. Это параметр самого Consul-сервера. По умолчанию он выставлен в значение 5. Это значение рекомендовано по документации для staging окружений. По сути это влияет на частоту обмена сообщениями между участниками Consul сети. По сути, этот параметр влияет на скорости служебного общения между участниками Consul-кластера. И для production его уже рекомендуется уменьшать чтобы узлы чаще обменивались сообщениями.
- Другой вариант, который мы стали использовать, это увеличение приоритета Consul процессов среди прочих процессов для планировщика процессов операционной системы. Есть такой параметр «nice», он как раз определяет приоритет процессов который учитывается планировщиком ОС при планировании. Мы взяли и Consul-агентам уменьшили значение nice, т.е. повысили приоритет, чтобы операционная система давала Consul процессам больше времени на работу и на исполнение своего кода. В нашем случае это решило нашу проблему.
- Другой вариант — это не использовать Consul. У меня есть товарищ, который большой сторонник Etcd. И мы с ним регулярно спорим, что лучше Etcd или Consul. Но в плане, что лучше, мы обычно с ним сходимся во мнении, что у Consul есть агент, который должен быть запущен на каждом узле с базой данных. Т. е. взаимодействие Patroni с Consul-кластером идет через этот агент. И вот этот агент становится узким местом. Если с агентом что-то происходит, то Patroni уже не может работать с Consul-кластером. И это является проблемой. В плане Etcd никакого агента нет. Patroni может напрямую работать со списком Etcd-серверов и уже общаться с ними. В этом плане, если вы используете у себя в компании Etcd, то Etcd будет, наверное, лучшим выбором, чем Consul. Но мы у наших заказчиков всегда ограничены тем, что выбрал и использует у себя клиент. И у нас по большей части Consul у всех клиентов.
- И последний пункт — это пересмотреть значения параметров. Мы можем поднять эти параметры в большую сторону в надежде, что наши кратковременные сетевые проблемы будут короткими и не попадут за интервал этих параметров. Таким образом мы можем уменьшить агрессивность Patroni на выполнение автофайловера, если какие-то сетевые проблемы возникают.
Я думаю, многие, кто используют Patroni, знакомы с этой командой.
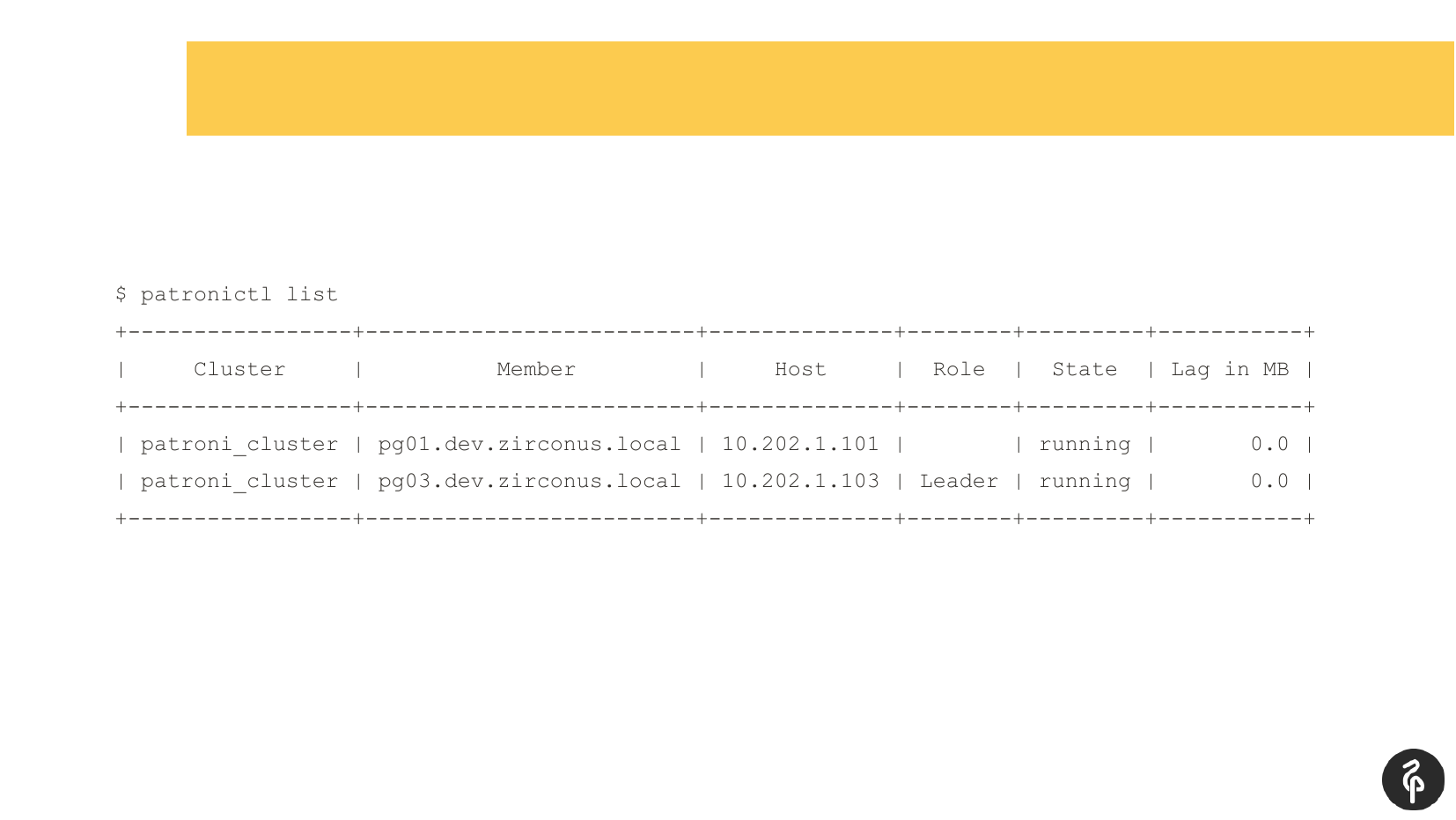
Эта команда показывает текущее состояние кластера. И на первый взгляд эта картина может показаться нормальной. У нас есть мастер, у нас есть реплика, лага репликации никакого нет. Но эта картина нормальная ровно до тех пор, пока мы не знаем, что в этом кластере должно быть три узла, а не два.

Соответственно, произошел автофайловер. И после этого автофайловера у нас реплика пропала. Нам нужно выяснить почему она пропала и вернуть ее обратно, восстановить. И мы снова идем в логи и смотрим, почему у нас произошел автофайловер.

В данном случае вторая реплика стала мастером. Здесь все в порядке.

И нам нужно смотреть уже на реплику, которая отвалилась и которая не в кластере. Мы открываем логи Patroni и смотрим, что у нас в процессе подключения к кластеру возникла проблема на стадии pg_rewind. Чтобы подключиться к кластеру нужно отмотать журнал транзакции, запросить нужный журнал транзакции с мастера и по нему догнать мастера.
В данном случае у нас нет журнала транзакций и реплика не может запуститься. Соответственно, мы Postgres останавливаем с ошибкой. И поэтому ее нет в кластере.

Надо понять, почему ее нет в кластере и почему не оказалось логов. Мы идем на новый мастер и смотрим, что у него в логах. Оказывается, когда делался pg_rewind произошел checkpoint. И часть старых журналов транзакции просто была переименована. Когда старый мастер попытался подключиться к новому мастеру и запросить эти логи, они уже были переименованы, их просто не было.

Я сравнивал timestamps, когда происходили эти события. И там разница буквально в 150 миллисекунд, т. е. в 369 миллисекунд завершился checkpoint, были переименованы WAL-сегменты. И буквально в 517 спустя 150 миллисекунд запустился rewind на старой реплике. Т. е. буквально 150 миллисекунд нам хватило, чтобы реплика не смогла подключиться и заработать.

Какие есть варианты?
Мы использовали изначально слоты репликации. Нам казалось, что это хорошо. Хотя на первом этапе эксплуатации мы слоты отключали. Нам казалось, что, если слоты будут копить много WAL-сегментов, мы можем уронить мастер. Он упадет. Мы помучались какое-то время без слотов. И поняли, что нам слоты нужны, мы вернули слоты.
Но тут есть проблема, что, когда мастер переходит в реплику, он удаляет слоты и вместе со слотами удаляет WAL-сегменты. И чтобы исключить появление этой проблемы, мы решили поднять параметр wal_keep_segments. Он по умолчанию 8 сегментов. Мы подняли до 1 000 и посмотрели, сколько у нас свободного места. И мы 16 гигабайт подарили на wal_keep_segments. Т. е. при переключении у нас всегда на всех узлах есть запас в 16 гигабайтов журналов транзакций.
И плюс — это еще актуально для продолжительных maintenance задач. Допустим, нам надо обновить одну из реплик. И мы хотим ее выключить. Нам нужно обновить софт, может быть, операционную систему, еще что-то. И когда мы выключаем реплику, для этой реплики также удаляется слот. И если мы используем маленький wal_keep_segments, то при продолжительном отсутствии реплики, журналы транзакций проиграются. Мы поднимем реплику, она запросит те журналы транзакции, где она остановилась, но на мастере их может не оказаться. И реплика тоже не сможет подключиться. Поэтому мы держим большой запас журналов.

У нас есть production-база. Там уже работают проекты.
Произошел файловер. Мы зашли и посмотрели — все в порядке, реплики на месте, лага репликации нет. Ошибок по журналам тоже нет, все в порядке.
Продуктовая команда говорит, что вроде бы как должны быть какие-то данные, но мы их по одному источнику видим, а в базе мы их не видим. И надо понять, что с ними произошло.

Понятно, что pg_rewind их затер. Мы сразу это поняли, но пошли смотреть, что происходило.

В логах мы всегда можем найти, когда произошел файловер, кто стал мастером и можем определить, кто был старым мастером и когда он захотел стать репликой, т. е. нам нужны вот эти логи, чтобы выяснить тот объем журналов транзакций, который был потерян.
Наш старый мастер перезагрузился. И в автозапуске был прописан Patroni. Запустился Patroni. Он следом запустил Postgres. Точнее перед запуском Postgres’а и перед тем как сделать его репликой, Patroni запустил процесс pg_rewind. Соответственно, он стер часть журналов транзакций, скачал новые и подключился. Здесь Patroni отработал шикарно, т. е. как и положено. Кластер у нас восстановился. У нас было 3 ноды, после файловера 3 ноды — все круто.

Мы потеряли часть данных. И нам нужно понять, сколько мы потеряли. Мы ищем как раз тот момент, когда у нас происходил rewind. Мы можем найти это по таким записям в журнале. Запустился rewind, что-то там сделал и завершился.

Нам нужно найти ту позицию в журнале транзакций, на которой остановился старый мастер. В данном случае — это вот эта отметка. И нам нужна вторая отметка, т. е. то расстояние, на которое отличается старый мастер от нового.
Мы берем обычный pg_wal_lsn_diff и сравниваем эти две отметки. И в данном случае мы получаем 17 мегабайт. Много это или мало каждый для себя решает сам. Потому что для кого-то 17 мегабайт — это немного, для кого-то это много и недопустимо. Тут уже каждый для себя индивидуально определяет в соответствие с потребностями бизнеса.

Но что мы выяснили для себя?
Во-первых, мы для себя должны решить — всегда ли нам нужен автозапуск Patroni после перезагрузки системы? Чаще бывает так, что мы должны зайти на старый мастер, посмотреть, как далеко он уехал. Возможно, проинспектировать сегменты журнала транзакций, посмотреть, что там. И понять — можем ли мы эти данные потерять или нам нужно в standalone-режиме запустить старый мастер, чтобы вытащить эти данные.
И только уже после этого должны принять решения, что мы можем эти данные отбросить или мы можем их восстановить, подключить вот этот узел в качестве реплики в наш кластер.
Помимо этого, есть параметр «maximum_lag_on_failover». По умолчанию, если мне не изменяет память, этот параметр имеет значение 1 мегабайт.
Как он работает? Если наша реплика отстает на 1 мегабайт данных по лагу репликации, то эта реплика не принимает участия в выборах. И если вдруг происходит файловер, Patroni смотрит, какие реплики отстают. Если они отстают на большое количество журналов транзакций, они не могут стать мастером. Это очень хорошая защитная функция, которая позволяет не потерять много данных.
Но тут есть проблема в том, что лаг репликации в кластере Patroni и DCS обновляется с определенным интервалом. По-моему, 30 секунд значение ttl по умолчанию.
Соответственно, может быть ситуация, когда лаг репликации для реплик в DCS один, а на самом деле может быть совершенно другой лаг или вообще лага может не быть, т. е. эта штука не realtime. И она не всегда отражает реальную картину. И делать на ней навороченную логику не стоит.
И риск потеряшек всегда остается. И в худшем случае одна формула, а в среднем случае другая формула. Т. е. мы, когда планируем внедрение Patroni и оцениваем, сколько данных мы можем потерять, мы должны закладываться на эти формулы и примерно представлять, сколько данных мы можем потерять.
И хорошая новость есть. Когда старый мастер уехал вперед, он может уехать вперед за счет каких-то фоновых процессов. Т. е. какой-то был автовакуум, он написал данные, сохранил их в журнал транзакции. И эти данные мы можем запросто игнорировать и потерять. В этом нет никакой проблемы.

И вот так выглядят логи в случае, если выставлен maximum_lag_on_failover и произошел файловер, и нужно выбрать нового мастера. Реплика оценивает себя как неспособную принимать участие в выборах. И она отказывается от участия в гонке за лидера. И она ждет, когда будет выбран новый мастер, чтобы потом к нему подключиться. Это дополнительная мера от потери данных.


Здесь у нас продуктовая команда написала, что их продукт испытывает проблемы при работе с Postgres. При этом на сам мастер нельзя зайти, потому что он недоступен по SSH. И автофайловер тоже не происходит.
Этот хост отправили принудительно в перезагрузку. Из-за перезагрузки произошел автофайловер, хотя можно было сделать и ручной автофайловер, как я сейчас понимаю. И после перезагрузки мы уже идем смотреть, что у нас было с текущим мастером.
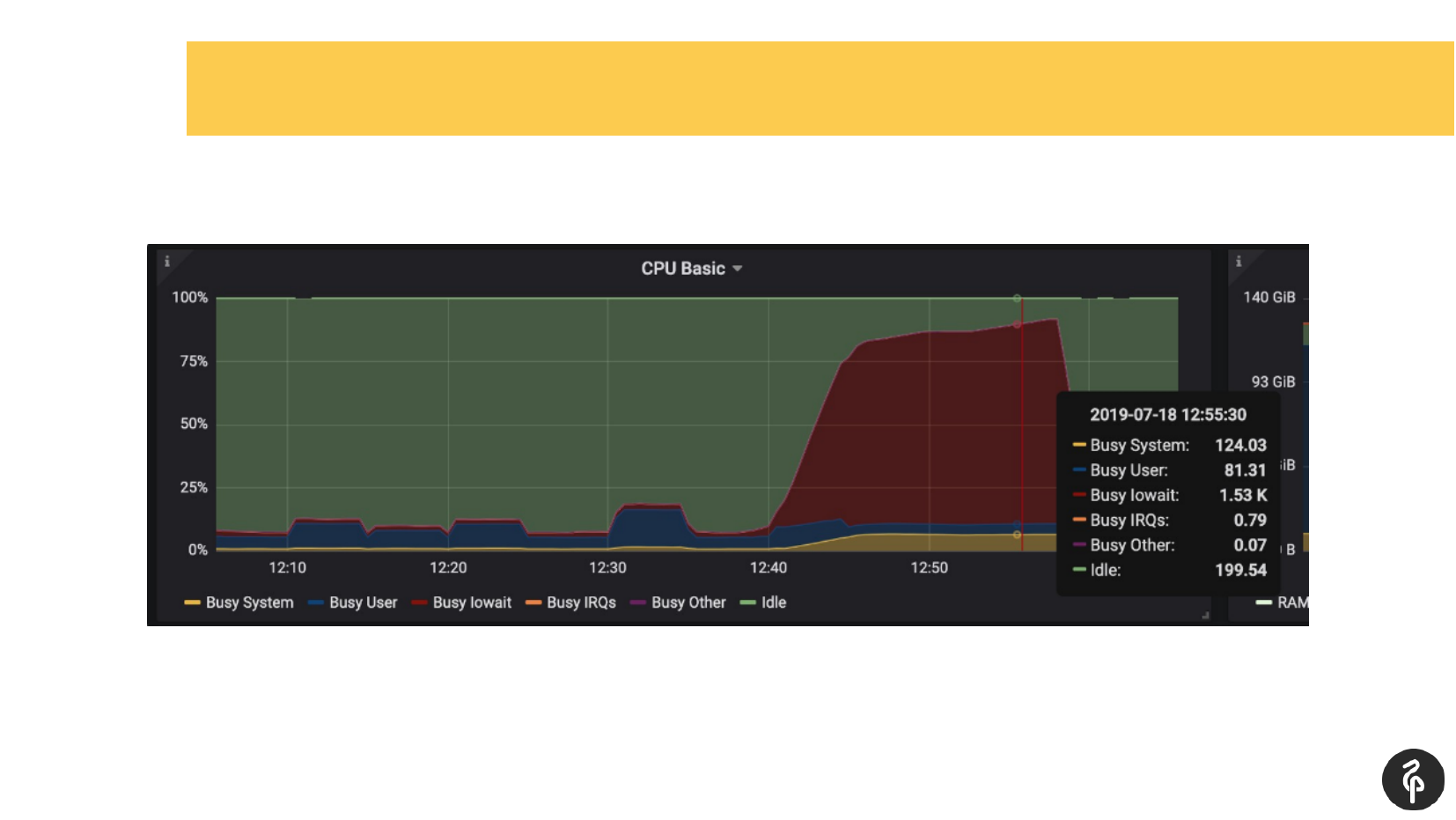
При этом мы заранее знали, что у нас проблемы были с дисками, т. е. мы уже по мониторингу знали, где копать и что искать.

Мы залезли в postgres«овый лог, начали смотреть, что там происходит. Мы увидели коммиты, которые длятся там по одной-две-три секунды, что совсем не нормально. Мы увидели, что у нас автовакуум запускается очень долго и странно. И мы увидели временные файлы на диске. Т. е. это все показатели проблем с дисками.

Мы заглянули в системный dmesg (в лог ядерных сообщений). И увидели, что у нас у нас есть проблемы с одним из дисков. Дисковая подсистемная представляла собой software Raid. Мы посмотрели /proc/mdstat и увидели, что у нас не хватает одного диска. Т. е. тут Raid из 8 дисков, у нас одного не хватает. Если внимательно поразглядывать слайд, то в выводе можно увидеть, что у нас там sde отсутствует. У нас, условно говоря, выпал диск. Это стриггерировало дисковые проблемы, и приложения тоже испытали проблемы при работе с кластером Postgres.

И в данном случае Patroni нам никак не помог бы, потому что у Patroni нет задачи отслеживать состояние сервера, состояние диска. И мы должны такие ситуации отслеживать внешним мониторингом. Мы во внешний мониторинг добавили мониторинг дисков оперативно.
И была такая мысль –, а мог бы нам помочь фенсинг, либо софт watchdog? Мы подумали, что вряд ли бы он нам помог в этом случае, потому что во время проблем Patroni продолжал взаимодействовать с кластером DCS и не видел никакой проблемы. Т. е. с точки зрения DCS и Patroni с кластером было все хорошо, хотя по факту были проблемы с диском, были проблемы с доступностью базы.
На мой взгляд, это одна из самых странных проблем, которую я исследовал очень долго, очень много логов перечитал, перековырял и назвал ее кластер-симулянтом.

Проблема заключалась в том, что старый мастер не мог стать нормальной репликой, т. е. Patroni его запускал, Patroni показывал, что этот узел присутствует как реплика, но в то же время он не был нормальной репликой. Сейчас вы увидите, почему. Это у меня сохранилось с разбора той проблемы.

И с чего все началось? Началось, как и в предыдущей проблеме, с дисковых тормозов. У нас были коммиты по секунде, по две.

Были обрывы соединений, т. е. клиенты рвались.

Были блокировки разной тяжести.

И, соответственно, дисковая подсистема не очень отзывчивая.

И самое загадочное для меня — это прилетевший immediate shutdown request. У Postgres есть три режима выключения:
- Это graceful, когда мы ждем, когда все клиенты отключатся самостоятельно.
- Есть fast, когда мы заставляем клиентов отключиться, потому что мы идем на выключение.
- И immediate. В данном случае immediate даже не сообщает клиентам, что нужно отключаться, он просто выключается без предупреждения. А всем клиентам уже операционной системой отправляется сообщение RST (TCP-сообщение, что соединение прервано и клиенту больше нечего ловить).
Кто послал этот сигнал? Фоновые процессы Postgres друг другу такие сигналы не посылают, т. е. это kill-9. Они друг другу такое не шлют, они на такое только реагируют, т. е. это экстренный перезапуск Postgres. Кто его послал, я не знаю.
Я посмотрел по команде «last» и я увидел одного человека, кто тоже залогинил этот сервер вместе с нами, но я постеснялся задавать вопрос. Возможно, это был kill -9. Я бы в логах увидел kill -9, т.к. Postgres пишет, что принял kill -9, но я не увидел этого в логах.

Разбираясь дальше, я увидел, что Patroni не писал в лог довольно долго — 54 секунды. И если сравнить два timestamp, тут примерно 54 секунды не было сообщений.
И за это время произошел автофайловер. Patroni тут снова отработал прекрасно. У нас старый мастер был недоступен, что-то с ним происходило. И начались выборы нового мастера. Здесь все отработалось хорошо. У нас pgsql01 стал новым лидером.

У нас есть реплика, которая стала мастером. И есть вторая реплика. И со второй репликой как раз были проблемы. Она пыталась переконфигурироваться. Как я понимаю, она пыталась поменять recovery.conf, перезапустить Postgres и подключиться к новому мастеру. Она каждые 10 секунд пишет сообщения, что она пытается, но у нее не получается.

И во время этих попыток на старый мастер прилетает immediate-shutdown сигнал. Мастер перезапускается. И также recovery прекращается, потому что старый мастер уходит в перезагрузку. Т. е. реплика не может к нему подключиться, потому что он в режиме выключения.

В какой-то момент она заработала, но репликация при этом не запустилась.
У меня есть единственная гипотеза, что в recovery.conf был адрес старого мастера. И когда появился новый мастер, то вторая реплика по-прежнему пыталась подключиться к старому мастеру.

Когда Patroni запустился на второй реплике, узел запустился, но не смог подключиться по репликации. И образовался лаг репликации, который выглядел примерно так. Т. е. все три узла были на месте, но второй узел отставал.

При этом, если посмотреть на логи, которые писались, можно было увидеть, что репликация не может запуститься, потому что журналы транзакций отличаются. И те журналы транзакций, которые предлагает мастер, которые указаны в recovery.conf, просто не подходят нашему текущему узлу.

И здесь я допустил ошибку. Мне надо было прийти посмотреть, что там в recovery.conf, чтобы проверить свою гипотезу, что мы подключаемся не к тому мастеру. Но я тогда только-только разбирался с этим и мне это в голову не пришло, либо я увидел, что реплика отстает и ее придется переналивать, т. е. я как-то спустя рукава отработал. Это был мой косяк.

Через 30 минут уже пришел админ, т. е. я перезапустил Patroni на реплике. Я уже на ней крест поставил, я думал, что ее придется переналивать. И подумал — перезапущу Patroni, может быть, получится что-нибудь хорошее. Запустился recovery. И база даже открылась, она была готова принимать соединения.

Репликация запустилась. Но через минуту она отвалилась с ошибкой, что ей не подходит журналы транзакций.

Я подумал, что еще раз перезапущу. Я перезапустил еще раз Patroni, причем я не перезапускал Postgres, а перезапускал именно Patroni в надежде, что он магическим образом запустит базу.

Репликация снова запустилась, но отметки в журнале транзакций отличались
