Пятничный дебаг: насколько глубока кроличья нора?

Привет, Хабр! Меня зовут Рома, и я системный администратор объектного хранилища Selectel. Когда меня спрашивают, за что я люблю свою работу, на ум приходит множество вещей. Но лучшее в жизни каждого инженера, как по мне, это столкновение с необъяснимым — ошибки и неполадки, находящиеся, казалось бы, на грани невозможного. И расследование таких случаев.
Этот текст — первый в цикле историй про эксплуатацию, дебаг и жизнь в обнимку с консолью и мануалом. Искушенного инженера они вряд ли удивят, но для начинающих могут оказаться полезными. Среди них есть короткие и длинные, линейные и запутанные. Постараюсь рассказывать поэтапно, чтобы вы пережили все с точки зрения участника и построили собственные гипотезы. Заодно поговорим об используемых инструментах и попробуем найти во всем этом какую-нибудь мораль.
Первая история больше философская, чем техническая. Про долгий поиск ошибки сначала в нашем мониторинге, а после — в софте, и все более глубоком погружении в слои абстракций. Бывало у вас такое, что глубина кроличьей норы с каждым шагом казалась все более неизмеримой? Под катом как раз про это.
Предыстория
Во многих продуктах найдется большой и важный компонент. Такой, мимо которого не проскочит ни один запрос и без чего остальная инфраструктура попросту бесполезна. Звучит знакомо? В объектном хранилище на эту роль подходит Swift Account Server — API, который знает все о наших клиентах и их контейнерах.
Недавно нам поступили новые машины — мониторинг намекнул, что неплохо было бы расширить кластер. Начало обычное: инженеры дата-центра смонтировали оборудование и подключили сеть, админы инфраструктуры настроили ОС, базовый софт и прогнали тесты. С нашей стороны оставалось лишь поднять сервисы, проверить связность и настроить кольца.
Обычное дело — настраивай и следи. В планах на вечер мелькает желание доделать и другие задачи, рука исполняет финальный аккорд в bash, а техника начинает бодро перераспределять данные на новые хосты. Grafana расцветает столбиками статистики репликации, пошли первые клиентские запросы, и ничего не предвещает беды. Все было именно так — красиво и литературно.
В этом состоянии мы оставили кластер на несколько часов, чтобы завершилось несколько полных циклов репликации. Это нормальная практика, так как Swift Account Server хранит информацию по каждому клиенту в отдельной базе SQLite и реплицирует их независимо друг от друга. Иногда на это требуется время в зависимости от размера БД и наличия блокировок (например, при интенсивных изменениях).
Спустя некоторое время мы получили алерт о повторяющихся ошибках репликации. В первые два-три раунда после обновления колец они вполне ожидаемы, но здесь точно было что-то не так. В логе проблемной машины обнаружилась неожиданная запись:
Apr 29 12:21:52 acsX account-replicator: ERROR Remote drive not mounted {'device': 'disk001', 'id': 43, 'ip': '10.0.0.41', 'meta': '', 'port': 6002, 'region': 1, 'replication_ip': '10.0.0.41', 'replication_port': 6002, 'weight': 100.0, 'zone': 11, 'index': 2}
Странно. Машины дважды проверены, мониторинг молчит, вот уж чего точно не ожидали.
Проверив примонтированные диски командой df, мы убедились в отсутствии указанного диска и увели боевую нагрузку с этой машины до окончания разбирательств. Конечно, никто не пострадал: репликация этих аккаунтов не была завершена, а значит, в кольце продолжали храниться три оригинальные копии всех данных.
Первый помощник в таких ситуациях — команда dmesg. По ее выводу сразу стало понятно, что дело в некорректной работе одного из NVMe-контроллеров — при поступлении нагрузки файловая система сдалась:
[Fri Apr 29 12:03:53 2022] XFS (nvme0n1p1): metadata I/O error in "xfs_trans_read_buf_map" at daddr 0x18 len 8 error 5
[Fri Apr 29 12:03:53 2022] XFS (nvme0n1p1): xfs_do_force_shutdown(0x1) called from line 325 of file fs/xfs/xfs_trans_buf.c. Return address = 00000000c3501d18
[Fri Apr 29 12:03:53 2022] XFS (nvme0n1p1): I/O Error Detected. Shutting down filesystem
[Fri Apr 29 12:03:53 2022] XFS (nvme0n1p1): Please unmount the filesystem and rectify the problem(s)
Забегая вперед, железная история закончилась хорошо: инженеры эксплуатации нашли ошибку в конфигурации контроллера, перенастроили диски и вернули машины нам после серии расширенных стресс-тестов. Неполадок больше не возникало, машины в строю.
С одной стороны — хорошо, ведь можно приступать к другим задачам. С другой — рукава уже закатаны в предвкушении интересного вечера, а желанный дебаг так и не случился.
Но все было не так просто.
Почему молчал мониторинг?
Для нас как администраторов продукта ключевой проблемой стало именно молчание мониторинга. Небольшой фон ошибок репликации является нормой даже в обычное время, поэтому мы следим только за крупными или длительными всплесками. Другое дело — пропажа целого диска, о таком хочется знать максимально оперативно. Тем более, такая ситуация была давно предусмотрена и отработана.
Недолго думая, я открыл консоль и отправился на передовую дебага с целью победить и починить. Попробуем разобраться, как это было.
Этап 1: легкий путь
Начнем с контекста. Наша типичная конфигурация дисков для Account Server выглядит следующим образом:
- В шасси установлено несколько NVMе-накопителей.
- Каждый накопитель форматируется в XFS и монтируется по пути
/srv/swift/node/disk(где N — номер диска). - В конфигурации Account Server указывается директория с точками монтирования дисков. В нашем случае —
/srv/swift/node.
В процессе работы приложение заполняет диски данными, попутно отслеживая их состояние. Мы, в свою очередь, собираем эту статистику и используем ее для мониторинга — строим графики и отсылаем алерты.
Будем распутывать цепочку событий с конца, при необходимости повторяя каждый шаг вручную. Это помогает наиболее быстро находить ошибки в коде или конфигурации. При работе с комплексными авариями это, впрочем, не так эффективно.
В нашем случае дело лишь в оповещении мониторинга, поэтому поиски следует начать с последнего этапа на пути алерта — AlertManager и его интеграции с Telegram.
Гипотеза 1: алерт был, но не дошел до получателя
Поводов сомневаться в работе самого AlertManager не было, ведь другие алерты доходили до нас исправно. Поэтому сразу сделаем еще один шаг назад и убедимся, что нужный алерт даже не появлялся в Prometheus. История состояний для алертов хранится в специальной синтетической метрике ALERTS:
Видно, что такого алерта не было как минимум на протяжении двух дней. Но, может, он просто некорректно сконфигурирован?
Гипотеза 1.5 (назовем это так): алерта не было, потому что алерт некорректный
Нужный нам алерт формируется на основе метрики acs_diskusage_mounted и срабатывает, когда она принимает нулевое значение. Но на графике видно, что приложение стабильно отчитывалось нам об успешно примонтированных дисках, никаких «нулей» нет:

Очень быстро первые полторы гипотезы с треском провалились, что по-своему радует: глупо было бы ошибиться в таком банальном деле, как настройка алерта. Перед нами оказалась задача, достойная настоящих инженеров. Поэтому пришло время разобраться, как все-таки работает эта магическая метрика и почему ее значение совсем не отражает реальность.
Короче говоря, время читать код!

Этап 2: погружаемся в кроличью нору
Чтобы собрать метрики по дискам Account Server в Prometheus, мы используем собственный экспортер. Тот, в свою очередь, отправляет в приложение запрос /recon/diskusage. В ответе — статистика по используемому месту на каждом диске, а также состояние монтирования дисков.
Вот как это выглядит на одной из тестовых машин:
[
{
"device": "disk001",
"mounted": true,
"size": 5356126208,
"used": 43917312,
"avail": 5312208896
},
{
"device": "disk002",
"mounted": true,
"size": 5356126208,
"used": 45215744,
"avail": 5310910464
}
]Гипотеза 2: ошибка в коде или неверное толкование метрик не дают реальной картины
Логично убедиться в том, что информация, на которую мы опираемся, означает именно то, что мы ожидаем. Чтобы это проверить, следует разобраться с источником данных. Беглым поиском по исходному коду в GitHub найдем основной обработчик запроса:
def get_diskusage(self):
"""get disk utilization statistics"""
devices = []
for entry in os.listdir(self.devices):
if not os.path.isdir(os.path.join(self.devices, entry)):
continue
try:
check_mount(self.devices, entry)
except OSError as err:
devices.append({'device': entry, 'mounted': str(err),
'size': '', 'used': '', 'avail': ''})
except ValueError:
devices.append({'device': entry, 'mounted': False,
'size': '', 'used': '', 'avail': ''})
else:
path = os.path.join(self.devices, entry)
disk = os.statvfs(path)
capacity = disk.f_bsize * disk.f_blocks
available = disk.f_bsize * disk.f_bavail
used = disk.f_bsize * (disk.f_blocks - disk.f_bavail)
devices.append({'device': entry, 'mounted': True,
'size': capacity, 'used': used,
'avail': available})
return devices
Незамысловато. Здесь self.devices — тот самый параметр из конфигурации, в котором указан путь к точкам монтирования дисков. Напомню, что у нас это /srv/swift/node. Условно ситуация выглядит следующим образом:
root@acsX.test:~# df -h -t ext4 -t xfs
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 19G 8.6G 9.4G 48% /
/dev/sdb1 5.0G 42M 5.0G 1% /srv/swift/node/disk001
/dev/sdc1 5.0G 44M 5.0G 1% /srv/swift/node/disk002
root@acsX.test:~# ls -lah /srv/swift/node
total 32K
drwxr-xr-x 10 swift swift 4.0K Jul 20 2020 .
drwxr-xr-x 3 swift swift 4.0K Mar 1 2017 ..
drwxr-xr-x 5 swift swift 51 Apr 29 19:35 disk001
drwxr-xr-x 5 swift swift 51 Apr 29 19:36 disk002
Логика у метода простая: прошлись по дискам, сделали пару проверок и собрали статистику.
Хочется обратить внимание на обработку ошибок — все предусмотренные исключения не помешают нам наполнить список devices, а остальные — наоборот, не дадут добраться до return и проскочат выше по стеку вызовов. Это значит, что все элементы из os.listdir(self.devices) обязательно окажутся в результирующем списке, если они являются директориями. В нашем случае это всегда так.
Отправимся дальше и выясним, как формируется значение поля mounted. Функция check_mount() оказывается оберткой, и, спускаясь глубже по стеку вызовов, мы в конце концов добираемся до сути — ismount_raw():
def ismount_raw(path):
"""
Test whether a path is a mount point. Whereas ismount will catch
any exceptions and just return False, this raw version will not
catch exceptions.
This is code hijacked from C Python 2.6.8, adapted to remove the extra
lstat() system call.
"""
try:
s1 = os.lstat(path)
except os.error as err:
if err.errno == errno.ENOENT:
# It doesn't exist -- so not a mount point :-)
return False
raise
if stat.S_ISLNK(s1.st_mode):
# Some environments (like vagrant-swift-all-in-one) use a symlink at
# the device level but could still provide a stubfile in the target
# to indicate that it should be treated as a mount point for swift's
# purposes.
if os.path.isfile(os.path.join(path, ".ismount")):
return True
# Otherwise, a symlink can never be a mount point
return False
Здесь задача — ответить на простой вопрос: «Является ли указанный путь точкой монтирования?». Так как наш вышестоящий код вызовет ее для каждой директории внутри /srv/swift/node, а значит, по очереди передаст пути к нашим дискам, именно она нам и нужна!
Выше приведена только первая часть метода. Сначала вызывается lstat() — обертка для одноименного системного вызова. Здесь не используется обычный stat(), так как при указании символической ссылки он проследует по ней и вернет информацию о конечном файле, в то время как lstat() в таких случаях вернет информацию о самой ссылке.
Продолжим изучать код:
s2 = os.lstat(os.path.join(path, '..'))
dev1 = s1.st_dev
dev2 = s2.st_dev
if dev1 != dev2:
# path/.. on a different device as path
return True
ino1 = s1.st_ino
ino2 = s2.st_ino
if ino1 == ino2:
# path/.. is the same i-node as path
return True
# Device and inode checks are not properly working inside containerized
# environments, therefore using a workaround to check if there is a
# stubfile placed by an operator
if os.path.isfile(os.path.join(path, ".ismount")):
return True
return False
И вновь ничего необычного: сравниваются номер блочного устройства и inode проверяемой директории и ее директории-родителя, чтобы обнаружить точку монтирования другой ФС.
Задача со звездочкойКак вы думаете, для чего в коде сделана проверка inode? Ждем ваши варианты в комментариях
В конце функции есть проверка на наличие файла .ismount, но к нашей ситуации это не относится. С обработкой ошибок здесь тоже ничего нового — если выскочит Exception, мы в принципе не дойдем до return. Получение ложного ответа кажется практически нереальным. Есть некоторые сомнения, но они выглядят слишком слабыми. В конце концов, комментарий гласит, что код был позаимствован в CPython. Кто мы такие, чтобы не доверять ему?
Так как явных подозрительных участков в коде не видно, будем искать проблему дальше. Попробуем вручную повторить эту логику, воспользовавшись командой stat:
root@acsX:~# stat --printf 'Path: %n \nDevice: %d\nInode: %i\n' /srv/swift/node
Path: /srv/swift/node
Device: 66305
Inode: 2756791
root@acsX:~# stat --printf 'Path: %n \nDevice: %d\nInode: %i\n' /srv/swift/node/disk001
Path: /srv/swift/node/disk001
Device: 66305
Inode: 2731952
Результат ожидаемый: так как файловая система disk001 в данный момент не примонтирована, команды отобразили одинаковые номера блочного устройства и разные inode. Фактически мы только что сделали stat для двух разных директорий внутри одной ФС.
По логике исходного кода функция ismount_raw() в такой ситуации никак не может вернуть True, но ведь именно это она и делает! В любом случае, вторая гипотеза не подтвердилась. Код корректный, а метрика отражает именно то, что мы от нее ждем.
В голове только одна мысль: я явно что-то упускаю. Если результат разный, значит, и входные данные должны различаться. В этот момент появляется желание провести тест внутри интерпретатора Python, и вдруг наступает прозрение — не так давно наши Account Server уехали в Docker.
Само по себе использование Docker, конечно, не кажется проблемой, но, так как мы «пробрасываем» директории дисков с хост-машины, нет полной уверенности в том, что все привычные механики взаимодействия с ФС будут работать. Проверки в коде завязаны на достаточно низкоуровневые вещи уровня файловой системы. А контейнер — это ведь странный черный ящик, у которого свои правила игры?
Повторим те же команды, находясь внутри Docker-окружения:
root@acsX:~# docker exec account-server stat --printf 'Path: %n \nDevice: %d\nInode: %i\n' /srv/swift/node
Path: /srv/swift/node
Device: 64768
Inode: 2756791
root@acsX:~# docker exec account-server stat --printf 'Path: %n \nDevice: %d\nInode: %i\n' /srv/swift/node/disk001
stat: cannot statx '/srv/swift/node/disk001': Input/output error
Судя по ошибке, здесь происходит обращение к проблемному диску, но почему? Как именно это работает и почему поведение отличается от хоста?
Более того, мы проверили код и знаем: если бы в ходе опроса приложения возникала подобная ошибка, метрик по дискам в Prometheus не появилось бы в принципе — ни по «хорошим», ни по «плохим».
Какая-то черепашка недоговаривает. Посмотрим на все поближе.
Этап 3: Дружим с mount namespaces
Первое правило контейнера — никому не говорить, что находится вне контейнера. А для этого используются самые разные технологии, среди которых и linux namespaces.
Если коротко, namespaces — это слой абстракции для перечисляемых ресурсов ядра (PID, пользователи, устройства, точки монтирования), который разделяет их видимость процессами. Отметим, что ограничения на исчисляемый ресурс (CPU, RAM, диск, сеть) накладываются уже другими технологиями, такими как cgroups.
Соответственно, процесс внутри Docker-контейнера имеет собственный mount namespace, причем совсем независимый от глобального. Вся корневая файловая система внутри контейнера выстраивается «с нуля», начиная со сборки overlayfs и заканчивая монтированием volumes.
Увидеть содержимое mount namespace, в котором находится текущий процесс, можно в псевдофайле /proc/mounts. Посмотрим, как будут выглядеть наши диски на хост-машине и внутри контейнера:
root@acsX:~# cat /proc/mounts | grep /srv/swift/node
/dev/nvme0n1p2 /srv/swift/node/disk002 xfs rw,noatime,nodiratime,attr2,discard,nobarrier,inode64,logbufs=8,noquota 0 0
root@acsX:~# docker exec account-server cat /proc/mounts | grep /srv/swift/node
/dev/nvme0n1p1 /srv/swift/node/disk001 xfs rw,noatime,nodiratime,attr2,discard,nobarrier,inode64,logbufs=8,noquota 0 0
/dev/nvme0n1p2 /srv/swift/node/disk002 xfs rw,noatime,nodiratime,attr2,discard,nobarrier,inode64,logbufs=8,noquota 0 0
Из прошлых попыток уже понятно, что «внутри» контейнера точка монтирования все еще активна. Теперь выяснилось, что там известно и про существование /dev/nvme0n1p1. Это кажется интересным именно потому, что, создавая контейнер, мы ничего не говорили про наши физические диски, а лишь указали нужные директории при помощи ключа -v:
root@acsX:~# docker run -v /srv/swift/node/disk001:/srv/swift/node/disk001:rw -v /srv/swift/node/disk002:/srv/swift/node/disk002:rw <...>Гипотеза 3: так как внутри контейнера ведется собственный список точек монтирования, неполадки в хост-системе никак на нем не отразились и мониторинг считал, что диск примонтирован
Разберемся, как именно Docker монтирует директории хост-системы внутрь контейнера. Документация раскрывает этот момент достаточно широко, прямо признаваясь нам, что под капотом не используется никакой уличной магии, лишь классические Linux Bind Mounts.
Говоря простым языком, bind mount — это отражение структуры одной директории в другую. Объясню на примере.
Допустим, у нас есть директория /tmp/data с определенной структурой:
root@test:~# mkdir -p /tmp/data/{first,second,third}
root@test:~# touch /tmp/data/second/file.jpg
root@test:~# tree /tmp/data
/tmp/data
├── first
├── second
│ └── file.jpg
└── third
3 directories, 1 file
Нам необходимо работать с этой же структурой из другого места (например, в изолированной части ФС). Для этого можно воспользоваться bind mount:
root@test:~# mkdir /root/data
root@test:~# mount --bind /tmp/data /root/data
root@test:~# tree /root/data/
/root/data/
├── first
├── second
│ └── file.jpg
└── third
3 directories, 1 file
Видно, что содержимое директории /tmp/data отразилось в /root/data. Мы также можем вносить изменения, и они будут видны по обе стороны:
root@test:~# touch /root/data/first/file.avi
root@test:~# tree /tmp/data/
/tmp/data/
├── first
│ └── file.avi
├── second
│ └── file.jpg
└── third
3 directories, 2 files
С такого ракурса все кажется простым и понятным, но что если отмонтировать оригинальный путь? Сохранится ли bind mount и будет ли он работать? Проведем расширенный эксперимент.
Для начала найдем себе блочное устройство. За неимением лишних дисков сделаем его на базе простого файла:
# Создадим пустой файл размером 1GB
root@test:~# dd if=/dev/zero of=/tmp/1g_disk.img bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 6.42928 s, 167 MB/s
# Создадим внутри него файловую систему XFS
root@test:~# mkfs.xfs /tmp/1g_disk.img
meta-data=/tmp/1g_disk.img isize=512 agcount=4, agsize=65536 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=0
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
# Добавим в систему loop device на базе нашего файла
root@test:~# modprobe loop && losetup --find --show /tmp/1g_disk.img
/dev/loop0
# Смонтируем новое устройство в систему
root@test:~# mkdir /mnt/1g_disk
root@test:~# mount /dev/loop0 /mnt/1g_disk
root@test:~# cat /proc/mounts | grep /mnt/1g_disk
/dev/loop0 /mnt/1g_disk xfs rw,relatime,attr2,inode64,noquota 0 0
# Повторим эксперимент с bind mount
root@test:~# mkdir /root/1g_disk
root@test:~# mount --bind /mnt/1g_disk /root/1g_disk
# Создадим файл по новому пути
root@test:~# touch /mnt/1g_disk/test
# Убедимся, что наши изменения видны по оригинальному пути
root@test:~# ls /root/1g_disk/
test
Мы уже видели, что все изменения отражаются в обеих директориях. Но как все-таки выглядит bind mount для системы и что будет, если размонтировать оригинальный путь?
# Проверим точки монтирования
root@test:~# cat /proc/self/mountinfo | grep 1g_disk
137 27 7:0 / /mnt/1g_disk rw,relatime shared:91 - xfs /dev/loop0 rw,attr2,inode64,noquota
202 27 7:0 / /root/1g_disk rw,relatime shared:91 - xfs /dev/loop0 rw,attr2,inode64,noquota
# Размонтируем оригинальный путь
root@test:~# umount /mnt/1g_disk
# Снова проверим точки монтирования
root@test:~# cat /proc/self/mountinfo | grep /mnt/1g_disk
202 27 7:0 / /root/1g_disk rw,relatime shared:91 - xfs /dev/loop0 rw,attr2,inode64,noquota
# Убедимся, что по новому пути данные все еще доступны
root@test:~# ls /root/1g_disk/
test
Кажется, вот и наш ответ: bind mount отображается как полноценная и независимая точка монтирования. Размонтировав оригинальный путь, мы никак не повлияли на bind mount, который продолжил работать, как ни в чем не бывало.
Можно сделать вывод, что полная хронология событий выглядела так:
- При поступлении нагрузки приложение начало активную запись на диск.
- В работе NVME-контроллера возникла ошибка, драйвер ФС споткнулся и принял решение о том, что дальше так работать не получится.
- Такие низкоуровневые процессы происходят вне namespaces, вследствие чего проблемный диск был размонтирован только в хост-системе, не затронув bind mount внутри контейнера.
- Мониторинг, фактически работающий внутри контейнера, продолжал отчитываться о примонтированном диске, и мы не получили важный алерт.
Третья гипотеза оказалась верна. Софт в контейнере попросту не «видит» размонтированный диск.
Или нет?
Возвращаемся к реальности
Интересно вышло, не правда ли? И код почитали, и man изучили, и даже в консоли поигрались — азартно и познавательно. Отличный способ здорово провести время и полностью оправдать свою специализацию. Помните, я что-то говорил про кроличью нору?
Иногда следует вовремя остановиться и посмотреть на свой путь. Вот, например, в этом расследовании каждый следующий шаг все больше отдаляется от реальности.
Это могло быть не так заметно по мере прочтения (и, поверьте, было совсем не заметно по ходу дела), но последний эксперимент был проведен уже совсем в лабораторных условиях. Главная особенность, которая осталась без внимания, — ошибка файловой системы, из-за которой и возникла исходная проблема.
Что уж говорить про выводы. Можно ли считать их достаточными? Что на самом деле показал эксперимент: особенности работы технологии или способность выполнить команды так, чтобы получить схожий с желаемым результат? На самом ли деле проблема обнаружена или мы лишь углубились в потемки интересной технологии, забыв об изначальной задаче?
Радость от найденного бага, а иногда и сам процесс поиска нередко затмевают сознание и заставляют игнорировать важные мелочи. Особенно если они промелькнули в самом начале, еще на этапе выстраивания гипотез.
В «больших» расследованиях мы периодически возвращаемся к началу и перепроверяем не только свои идеи, но и входные данные. Их неверная интерпретация сильно влияет на конечный результат. Опыт говорит лишь о том, что это неизбежно. Так как железная проблема была исправлена и часть расследования проводилась постфактум, мы расслабились и попали именно в эту ловушку.
Самые внимательные из вас могли заметить важную деталь. В статье приведены «чистые» логи без фонового шума, но помогло ли это читателю увидеть главный факт, который сразу мог привести нас к ответам?
Помните одну из первых гипотез? Ту самую, где мы еще на начали разбирать по винтикам файловую систему контейнера, а просто смотрели на метрику и фантазировали:
Назовем это гипотезой 1.5: алерта не было, потому что алерт некорректный
Ответ был дан еще тогда. Просто зачем-то я все усложнил.
Как все было на самом деле
В начале статьи я приводил красивую строку из лога:
Apr 29 12:21:52 acsX account-replicator: ERROR Remote drive not mounted {'device': 'disk001', 'id': 43, 'ip': '10.0.0.41', 'meta': '', 'port': 6002, 'region': 1, 'replication_ip': '10.0.0.41', 'replication_port': 6002, 'weight': 100.0, 'zone': 11, 'index': 2}
В реальности записей было намного больше. Основная часть сообщала об ошибках открытия файла БД и прочих факторах сломанного IO. Из-за этого указанная выше строчка просто-напросто была пропущена.
Софт ведь честно писал, что диск не смонтирован. Точно такой же софт в контейнере, как и тот, который мы опрашиваем для получения мониторинговых метрик. Я этого не заметил и сделал немного иной вывод. Вы уже знаете, что было дальше.
Проверив код, я убедился, что под капотом у этой ошибки находится та же самая проверка и вызов ismount_raw(). Получается, что в одном контейнере код отчитывается о примонтированном диске, а в другом — нет? И это притом, что мы только что доказали, что внутри контейнера диск должен выглядеть примонтированным.
Абсолютная случайность помогла пролить свет на эту загадку. В ходе одного из экспериментов я снова нарисовал график по нашей метрике, но на этот раз с уточнением конкретного хоста и диска:

Вот так номер! Вместо того, чтобы принять нулевое значение, нужная нам метрика попросту исчезла. Так как условие алерта этого не предполагает, наш мониторинг не сработал.
Я мог заметить это еще в начале при визуальном контроле метрик, используя stacked graph. Это выглядело бы примерно так:
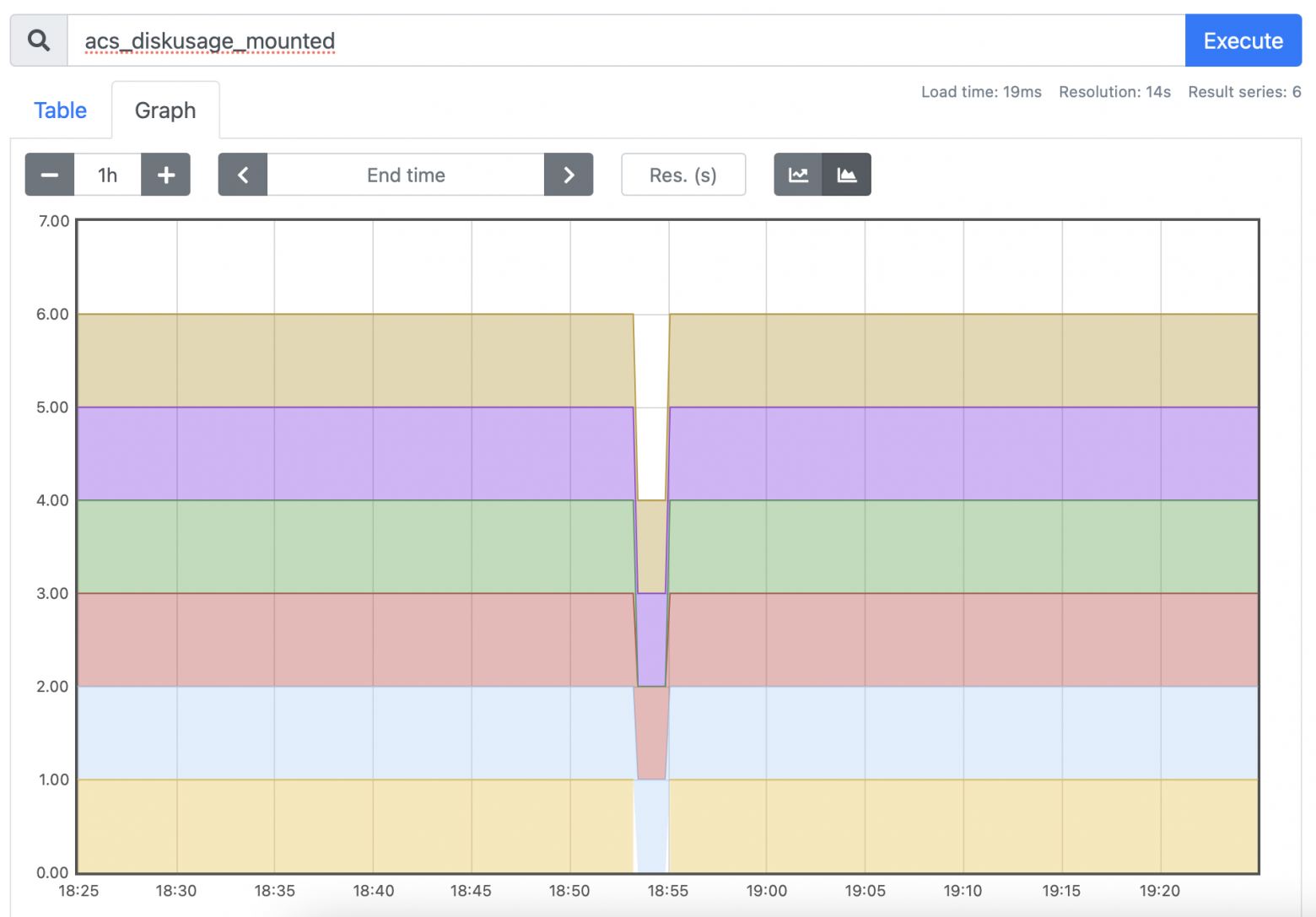
Один маленький переключатель, а сколько времени можно было бы сэкономить! Конечно, польза от полученных знаний никуда не денется, но выходит, все это время настоящий вопрос был другой: почему исчезла метрика?
От безысходности в голову приходит мысль, что мы столкнулись с некорректной логикой работы экспортера, который не формирует метрику для дисков с mounted: false. Проверка была быстрой — кода там совсем мало. Кроме этого, она была неудачной — код там очень простой и не содержит ошибок.
Последний лучик надежды погас, все другие варианты исключены, а каждый шаг проверен. Или нет?
Почему все было именно так
Самое время вспомнить темные пятна этой истории, вернуться назад и переосмыслить прошлые результаты.
В процессе анализа кода на Python меня не покидала мысль о том, что невозможное — невозможно:
Есть некоторые сомнения, но они выглядят слишком слабыми.
Одна из строк кода выделялась среди остальных и вызывала сильные подозрения по поводу того, что результат ее выполнения всегда будет соответствовать ожиданиям. Тем не менее, на том этапе проверка казалась слишком затратной, а вероятность — не очень высокой. Но других идей нет, а отступать некуда.
Гипотеза 4: <секретная>
Ну, а как еще? Иначе я раскрою все карты! Однако внимательный читатель мог заметить еще одно важное несоответствие и догадаться, откуда ноги растут.
Чтобы проверить эту гипотезу, нам потребуется провести наиболее честный эксперимент. Хватит играться с контейнерами и читать мануал, давайте воссоздадим ситуацию максимально достоверно.
Как это сделать? Изначально было три пути:
- Идти сверху, просто повторив особенности окружения. Не прокатило, экспериментов с Docker оказалось мало.
- Идти снизу, запустив тесты на таком же железе, с теми же ошибками в конфигурации дисков. Не прокатит. По словам инженеров, несмотря на явную ошибку в конфигурации, проблема не носила обязательный характер. Да и кто мне разрешит?
- Идти сбоку, повторив поведение файловой системы. Пробуем.
Конечно, логичнее всего было бы воспроизвести те симптомы, с которыми мы непосредственно столкнулись. Если вспомнить вывод dmesg, там была строчка:
[Fri Apr 29 12:03:53 2022] XFS (nvme0n1p1): xfs_do_force_shutdown(0x1) called from line 325 of file fs/xfs/xfs_trans_buf.c. Return address = 00000000c3501d18
Предположим, что именно с этого все и началось, а значит, теперь наша задача — выполнить xfs_do_force_shutdown любой ценой.
Надежных способов это провернуть совсем немного. Я сразу исключил варианты, в которых мы искажаем общение между драйвером XFS и блочным устройством, так как они были очень ненадежны. Ввиду стойкости файловой системы и хитрости кэша в ядре я мог бы очень долго добиваться необходимого поведения.
Был и другой вариант: попытаться точечно исказить метаданные на блочном устройстве, вызвав схожую с нашей ошибку. Интерес почти уже взял верх, но я быстро остыл, вспомнив что точно такой же азарт уже заводил меня в глубокие дебри. Нужно что-то попроще. Должен быть способ действительно вызвать нужную функцию внутри драйвера ФС, а не подгонять внешние условия в надежде на ее исполнение.
Я начал с изучения самой функции xfs_do_force_shutdown(), чтобы лучше понять ее работу, а заодно найти способы повторить поведение. Она находится в файле fs/xfs/xfs_fsops.c, и комментарий сразу говорит, что это именно наш случай:
/*
* Force a shutdown of the filesystem instantly while keeping the filesystem
* consistent. We don't do an unmount here; just shutdown the shop, make sure
* that absolutely nothing persistent happens to this filesystem after this
* point.
*/
Конечно, никаким Docker такое не провернешь. Функция, казалось бы, вызывается совсем нечасто, но в fs/xfs/xfs_mount.h нашелся приятный макрос:
#define xfs_force_shutdown(m,f) \
xfs_do_force_shutdown(m, f, __FILE__, __LINE__)
В основном он используется в низкоуровневых функциях, которые прибегают к нему при возникновении серьезных ошибок. Нашел даже ту часть кода, в которой случилась наша беда, но ничего из этого не помогало легко воспроизвести проблему.
В конце концов, я обнаружил еще один вызов. И на этот раз не где-то глубоко внутри, а в самом настоящем ioctl-интерфейсе нашего драйвера (xfs/fs/xfs_ioctl.c):
case XFS_IOC_GOINGDOWN: {
uint32_t in;
if (!capable(CAP_SYS_ADMIN))
return -EPERM;
if (get_user(in, (uint32_t __user *)arg))
return -EFAULT;
return xfs_fs_goingdown(mp, in);
}
В функции xfs_fs_goingdown() как раз вызывается наш макрос, а это означало победу, ведь вызвать ioctl совсем несложно. Осталось написать код! Мануал к команде XFS_IOC_GOINGDOWN содержит немного подробностей и описание аргументов, но, в целом, здесь и так все достаточно просто.
#include
#include
#include
#include
#include
#include
int main(int argc, char *argv[]) {
if (argc < 2) {
fprintf(stderr, "usage: %s [flush|noflush]\n", argv[0]);
exit(EX_USAGE);
} else if (argc > 3) {
fprintf(stderr, "too many arguments\n");
exit(EX_USAGE);
}
char *filesystem = argv[1];
int mode = XFS_FSOP_GOING_FLAGS_DEFAULT;
if (argc == 3) {
if (strcmp(argv[2], "flush") == 0) {
mode = XFS_FSOP_GOING_FLAGS_LOGFLUSH;
} else if (strcmp(argv[2], "noflush") == 0) {
mode = XFS_FSOP_GOING_FLAGS_NOLOGFLUSH;
}
}
fprintf(stdout, "Opening filesystem %s...\n", filesystem);
int fd = open(filesystem, O_RDONLY);
if (fd < 0) {
perror("Failed to open filesystem");
exit(EX_OSERR);
}
fprintf(stdout, "Calling ioctl(%d, %lu, 0x%.8x)...\n", fd, XFS_IOC_GOINGDOWN,
mode);
int ret = ioctl(fd, XFS_IOC_GOINGDOWN, &mode);
if (ret != 0) {
perror("Failed to call ioctl");
exit(EX_OSERR);
}
close(fd);
fprintf(stdout, "Done.\n");
return 0;
}
Незамысловатый код вызовет ioctl() с нужной командой и дело в шляпе! Для сборки, если использовать Debian, понадобится совсем немного: gcc, libc6-dev и xfslibs-dev.
Вопрос для знающихВ мануалах можно найти упоминание
xfsctlкак предпочтительного способа взаимодействия с XFS. Я не использовал его в коде выше, чтобы не вносить новые сущности, хотя обычно стремлюсь следовать рекомендациям, особенно тем, которых не понимаю.На поверку
xfsctlоказался самым обычным макросом, и у меня нет идей, почему мне следует выбрать именно его или чемioctlможет быть хуже. Если у кого-то из читателей есть мнение на этот счет, буду рад увидеть его в комментариях.
Хочется поскорее запустить код и увидеть результат. А чтобы эксперимент вышел максимально достоверным, проведем его на одной из тестовых машин, где все окружение аналогично боевому:
root@acsX.test:~# gcc -s /usr/local/src/xfs_shutdown/xfs_shutdown.c -o /usr/local/bin/xfs_shutdown
root@acsX.test:~# /usr/local/bin/xfs_shutdown /srv/swift/node/disk002 noflush
Opening filesystem /srv/swift/node/disk002...
Calling ioctl(3, 2147768445, 0x00000002)...
Done.
Кажется, сработало! Проверим наши диски, как мы уже делали это ранее:
root@acsX.test:~# df -h -t ext4 -t xfs
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 19G 8.4G 9.6G 47% /
/dev/sdb1 5.0G 42M 5.0G 1% /srv/swift/node/disk001
/dev/sdc1 5.0G 44M 5.0G 1% /srv/swift/node/disk002
root@acsX.test:~# stat /srv/swift/node/disk002
stat: cannot statx '/srv/swift/node/disk002': Input/output error
Очень похоже на правду! Все точки монтирования остались на месте, притом что файловая система «погашена» и больше не отвечает на запросы. Попытка вызова stat приводит к уже знакомой нам ошибке IO.
Одна из вещей, которые мы не проверяли в момент проблемы — реальный ответ приложения на запрос /recon/diskusage, на базе которого формируются наши метрики. В тот момент это не казалось логичным, и я изучал проблему скорее вширь, чем в глубину. Не заглядывая в Prometheus, сделаем такой запрос сейчас:
root@acsX.test:~# curl 127.0.0.1:6002/recon/diskusage 2>/dev/null | jq .
[
{
"device": "disk001",
"mounted": true,
"size": 5356126208,
"used": 43991040,
"avail": 5312135168
}
]
Бинго! Доверие к экспортеру окончательно восстановлено, ведь сам Account Server не возвращает никакой информации по проблемному диску, будто его просто нет. Осталось разобраться почему.
Настоящая причина
Вернемся немного назад — в ту часть, где я выдвигаю секретную гипотезу и намекаю на важную пасхалку (она, кстати, проскочила уже дважды).
Что вызвало у меня (хоть и слабые) подозрения? Метод get_diskusage():
def get_diskusage(self):
"""get disk utilization statistics"""
devices = []
for entry in os.listdir(self.devices):
if not os.path.isdir(os.path.join(self.devices, entry)):
continue
try:
check_mount(self.devices, entry)
except OSError as err:
devices.append({'device': entry, 'mounted': str(err),
'size': '', 'used': '', 'avail': ''})
except ValueError:
devices.append({'device': entry, 'mounted': False,
'size': '', 'used': '', 'avail': ''})
else:
path = os.path.join(self.devices, entry)
disk = os.statvfs(path)
capacity = disk.f_bsize * disk.f_blocks
available = disk.f_bsize * disk.f_bavail
used = disk.f_bsize * (disk.f_blocks - disk.f_bavail)
devices.append({'device': entry, 'mounted': True,
'size': capacity, 'used': used,
'avail': available})
return devices
В процессе анализа этого кода я сделал вывод, что «потерять» диск не выйдет — либо мы получаем информацию по всем дискам, либо происходит ошибка и результата нет совсем. Конечно, я обратил внимание на continue в самом начале, но эта ветка выполнится, только если мы имеем дело не с директорией, что, казалось, точно не наш случай. Но сомнения все-таки закрались.
Попробуем повторить ту часть кода, где происходит проверка нашего пути на тестовой машине со «сломанной» файловой системой:
root@acsX.test:~# python -c 'import os; print os.path.isdir("/srv/swift/node/disk002")'
False
Вот так просто. Не в экспортере дело и даже не в параметрах алерта. Не в Docker с namespaces и не в OpenStack Swift. Все дело в Python, который молча возвращает False в случае возникновения системной ошибки (например, IOError). Код «считает», что никаких проблем нет, просто наш путь директорией не является, и продолжает работу.
Та самая «пасхалка», о которой я упоминал выше — это ошибка при вызове stat, вот такая:
root@acsX:~# docker exec account-server stat --printf 'Path: %n \nDevice: %d\nInode: %i\n' /srv/swift/node/disk001
stat: cannot statx '/srv/swift/node/disk001': Input/output error
Ведь это говорит нам, что в Python обязательно должно возникнуть исключение. Только было совсем не очевидно, что оно до нас не дойдет, а обработается в глубине стандартной библиотеки. Тем более, что документация ничего на этот счет не говорила:
