Парсим Википедию для задач NLP в 4 команды
Оказывается для этого достаточно запуcтить всего лишь такой набор команд:
git clone https://github.com/attardi/wikiextractor.git
cd wikiextractor
wget http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2
python3 WikiExtractor.py -o ../data/wiki/ --no-templates --processes 8 ../data/ruwiki-latest-pages-articles.xml.bz2
и потом немного отполировать скриптом для пост-процессинга
python3 process_wikipedia.py
Результат — готовый .csv файл с вашим корпусом.
Понятное дело, что:
http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2можно поменять на нужный вам язык, больше деталей тут [4];- Всю информацию о параметрах
wikiextractorможно найти в мануале (кажется даже официальная дока не обновлялась, в отличие от мана);
Скрипт с пост-процессингом конвертирует вики файлы в такую таблицу:
| idx | article_uuid | sentence | cleaned sentence | cleaned sentence length |
|---|---|---|---|---|
| 0 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Жан I де Шатильон (граф де Пентьевр)Жан I де Ш… | жан i де шатильон граф де пентьевр жан i де ша… | 38 |
| 1 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Находился под охраной Роберта де Вера, графа О… | находился охраной роберта де вера графа оксфор… | 18 |
| 2 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Однако этому воспротивился Генри де Громон, гр… | однако этому воспротивился генри де громон гра… | 14 |
| 3 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Король предложил ему в жёны другую важную особ… | король предложил жёны другую важную особу фили… | 48 |
| 4 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Жан был освобождён и вернулся во Францию в 138… | жан освобождён вернулся францию году свадьба м… | 52 |
article_uuid — псевдо-уникальный ключ, порядок предложений по идее должен сохраниться после такого пре-процессинга.
Пожалуй, на настоящий момент развитие ML-инструментов достигло такого уровня [8], что для построения работающей NLP модели / пайплайна достаточно буквально пары дней. Проблемы возникают только при отсутствии надежных датасетов / готовых эмбеддингов/ готовых языковых моделей. Цель данной статьи — немного облегчить вашу боль, показав, что для обработки всей Википедии (по идее самого популярного корпуса для тренировки эмбеддингов слов в NLP) хватит и пары часов. В конце концов, если достаточно пары дней, чтобы построить простейшую модель, зачем тратить куда больше времени на получение данных для этой модели?
wikiExtractor сохраняет статьи из Вики в виде текста, разделенного
- Берём список всех файлов на выходе;
- Делим файлы на статьи;
- Удаляем все оставшиеся HTML теги и специальные символы;
- С помощью
nltk.sent_tokenizeразделяем на предложения; - Чтобы код не разросся до огромных размеров и остался читаемым, каждой статье присваиваем свой uuid;
В качестве препроцессинга текста просто (можно легко перепилить под себя):
- Удаляем небуквенные символы;
- Удаляем стоп-слова;
Основное применение
Чаще всего на практике в NLP приходится сталкиваться с задачей построения эмбеддингов.
Для ее решения обычно используют один из следующих инструментов: :
- Готовые векторы / эмбеддинги слов [6];
- Внутренние состояния CNN, натренированных на таких задачах как, как определение фальшивых предложений / языковое моделирование / классификация [7];
- Комбинация выше перечисленных методов;
Кроме того, уже много раз было показано [9], что в качестве хорошего бейслайна для эмбеддингов предложений можно взять и просто усредненные (с парой незначительных деталей, которые сейчас опустим) векторы слов.
Другие варианты использования
- Используем случайные предложения из Вики в качестве негативных примеров для triplet loss-а;
- Обучаем энкодеры для предложений с помощью определения фальшивых фраз [10];
Распределение длины предложений для Русской Википедии
Без логарифмов (по оси X значения ограничены числом 20)
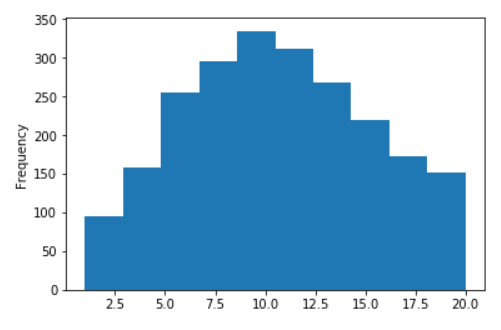
В десятичных логарифмах
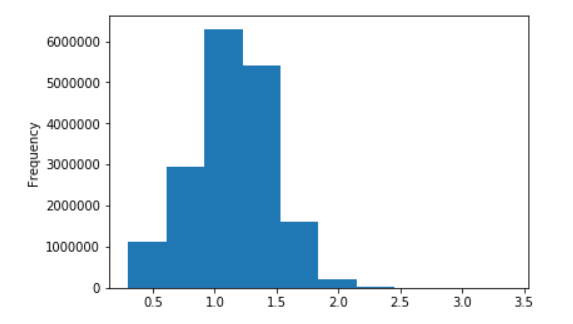
- Fast-text векторы слов, натренированные на Вики;
- Fast-text и Word2Vec модели для русского языка;
- Потрясающая wiki extractor библиотека для питона;
- Официальная страница с ссылками для Вики;
- Наш скрипт для пост-процессинга;
- Основные статьи про эмбеддинги слов: Word2Vec, Fast-Text, тюнинг;
- Несколько текущих SOTA подходов:
- InferSent;
- Generative pre-training CNN;
- ULMFiT;
- Контекстные подходы для представления слов (Elmo);
- Imagenet moment в NLP?
- Бейслайны для эмбеддингов предложений 1, 2, 3, 4;
- Определение фальшивых фраз для энкодера предложений;
