Параллельная сортировка методом пузырька на CUDA
Привет, Хабр. Подумал, кому-нибудь пригодится параллельная сортировка с относительно простой реализацией и высокой производительностью на платформе CUDA. Таковой является сортировка методом пузырька. Под катом приведено объяснение и код, который может пригодиться (а может и нет…). Сразу скажу, что представленная прога является бенчмарком по сравнению производительности на GPU и CPU. Если тебе не жалко, читатель, то скомпилируй ее, пожалуйста, и положи результаты расчета в комменты этой статьи. Это не для науки. Просто интересно =)Чуть-чуть напомнюСуть метода сортировки пузырьком заключается в попарном сравнении элементов и замене их местами в случае выполнения определенного условия, зависящего от направления сортировки. Ниже показаны итерации алгоритма в однопоточном режиме, когда он сортирует возрастающий массив целых чисел по убыванию (каждая строчка — это состояние массива на данный момент) — это таблица 1.В таблице 2 показаны итерации сортировки пузырьком в многопоточном режиме, который реализуется предельно просто: в то время, как один элемент перемещается в сторону, то через 2 перемещения следующий элемент уже тоже может быть отсортирован методом пузырька и начинает двигаться, а еще через 2 — еще один и т.д. Таким образом начинает «всплывать» весь массив, что существенно снижает время на расчет.
Профит
Уже по количеству затраченных действий можно видеть, что параллельная сортировка быстрее. Но это не всегда: при небольших размерах массивов однопоточный режим выполняется быстрее из-за отсутствия проблем с пересылкой данных. Я провел тут немного тестовых расчетов, и вот их результат: 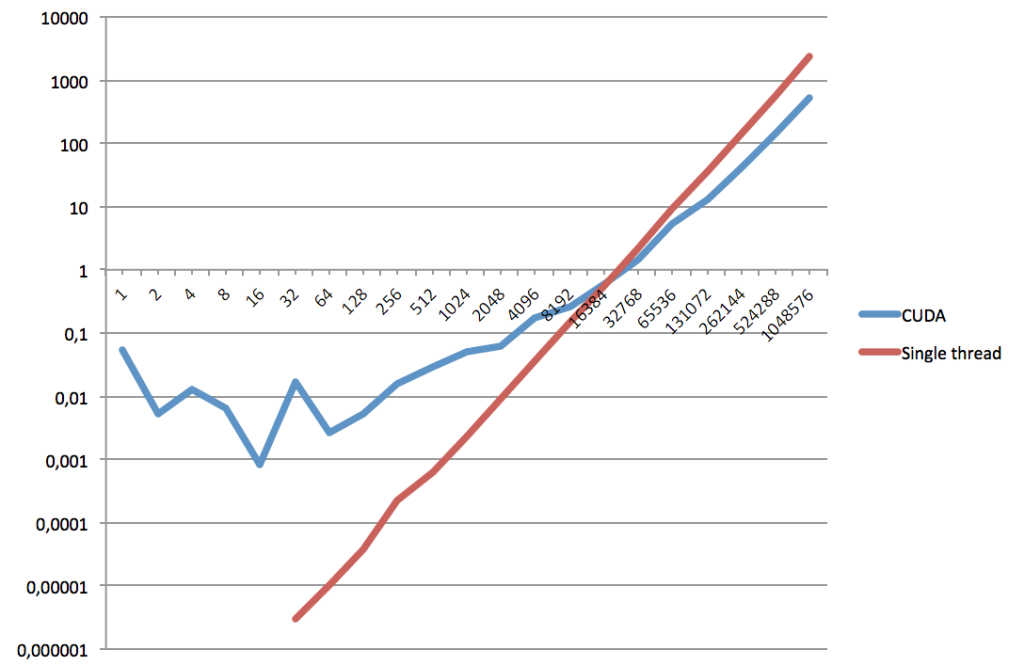 Ось абсцисс — кол-во элементов, ординат — время выполнения в сек.
Реализация
Я привожу код реализации на языке CUDA С, который содержит код, выполняющий сортировку ПО УБЫВАНИЮ на CUDA и CPU (в однопоточном режиме). По сути, это бенчмарк для вашего компа того, как шустро работает сортировка на видеокарте и на проце. Частью этой проги является функция сортировки на видеокарте на платформе CUDA, которую вы можете использовать на здоровье в своих шедеврах элементарным copy’n'past. Код представлен ниже таблиц.Как это компилировать???
Ну, для этого необходимо скачать драйвера для CUDA с сайта Nvidia, установить их, скачать Nvidia Toolkit, установить и Nvidia SDK, тоже установить. К счастью, сейчас все идет уже в одном пакете. Как устанавливать CUDA напишу, если будет спрос, а так просто пожелаю удачи, если ты новичок.Когда все готово и nvidia CUDA работает на твоем компе, то тогда достаточно лишь скомпилировать файл main.cu (или как там его назвал) и запустить прогу, получить результат и выложить его здесь.Уот и все на сейчас, спасибо, что прочитал. До скорого.P.S. Буду супер признателен, если подскажете, как ускорить алгоритм =)Таблица 1: Сортировка пузырьком в однопоточном режиме
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
1
0
2
3
4
5
6
7
8
9
10
11
12
13
14
1
2
0
3
4
5
6
7
8
9
10
11
12
13
14
1
2
3
0
4
5
6
7
8
9
10
11
12
13
14
1
2
3
4
0
5
6
7
8
9
10
11
12
13
14
1
2
3
4
5
0
6
7
8
9
10
11
12
13
14
1
2
3
4
5
6
0
7
8
9
10
11
12
13
14
1
2
3
4
5
6
7
0
8
9
10
11
12
13
14
1
2
3
4
5
6
7
8
0
9
10
11
12
13
14
1
2
3
4
5
6
7
8
9
0
10
11
12
13
14
1
2
3
4
5
6
7
8
9
10
0
11
12
13
14
1
2
3
4
5
6
7
8
9
10
11
0
12
13
14
1
2
3
4
5
6
7
8
9
10
11
12
0
13
14
1
2
3
4
5
6
7
8
9
10
11
12
13
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
1
3
4
5
6
7
8
9
10
11
12
13
14
0
2
3
1
4
5
6
7
8
9
10
11
12
13
14
0
2
3
4
1
5
6
7
8
9
10
11
12
13
14
0
2
3
4
5
1
6
7
8
9
10
11
12
13
14
0
2
3
4
5
6
1
7
8
9
10
11
12
13
14
0
2
3
4
5
6
7
1
8
9
10
11
12
13
14
0
2
3
4
5
6
7
8
1
9
10
11
12
13
14
0
2
3
4
5
6
7
8
9
1
10
11
12
13
14
0
2
3
4
5
6
7
8
9
10
1
11
12
13
14
0
2
3
4
5
6
7
8
9
10
11
1
12
13
14
0
2
3
4
5
6
7
8
9
10
11
12
1
13
14
0
2
3
4
5
6
7
8
9
10
11
12
13
1
14
0
2
3
4
5
6
7
8
9
10
11
12
13
14
1
2
3
4
5
6
7
8
9
10
11
12
13
14
3
2
4
5
6
7
8
9
10
11
12
13
14
1
0
3
4
2
5
6
7
8
9
10
11
12
13
14
1
0
3
4
5
2
6
7
8
9
10
11
12
13
14
1
0
3
4
5
6
2
7
8
9
10
11
12
13
14
1
0
3
4
5
6
7
2
8
9
10
11
12
13
14
1
0
3
4
5
6
7
8
2
9
10
11
12
13
14
1
0
3
4
5
6
7
8
9
2
10
11
12
13
14
1
0
3
4
5
6
7
8
9
10
2
11
12
13
14
1
0
3
4
5
6
7
8
9
10
11
2
12
13
14
1
0
3
4
5
6
7
8
9
10
11
12
2
13
14
1
0
3
4
5
6
7
8
9
10
11
12
13
2
14
1
0
3
4
5
6
7
8
9
10
11
12
13
14
2
1
0
3
4
5
6
7
8
9
10
11
12
13
14
4
3
5
6
7
8
9
10
11
12
13
14
2
1
0
4
5
3
6
7
8
9
10
11
12
13
14
2
1
0
4
5
6
3
7
8
9
10
11
12
13
14
2
1
0
4
5
6
7
3
8
9
10
11
12
13
14
2
1
0
4
5
6
7
8
3
9
10
11
12
13
14
2
1
0
4
5
6
7
8
9
3
10
11
12
13
14
2
1
0
4
5
6
7
8
9
10
3
11
12
13
14
2
1
0
4
5
6
7
8
9
10
11
3
12
13
14
2
1
0
4
5
6
7
8
9
10
11
12
3
13
14
2
1
0
4
5
6
7
8
9
10
11
12
13
3
14
2
1
0
4
5
6
7
8
9
10
11
12
13
14
3
2
1
0
4
5
6
7
8
9
10
11
12
13
14
1
0
5
4
6
7
8
9
10
11
12
13
14
3
2
1
0
5
6
4
7
8
9
10
11
12
13
14
3
2
1
0
5
6
7
4
8
9
10
11
12
13
14
3
2
1
0
5
6
7
8
4
9
10
11
12
13
14
3
2
1
0
5
6
7
8
9
4
10
11
12
13
14
3
2
1
0
5
6
7
8
9
10
4
11
12
13
14
3
2
1
0
5
6
7
8
9
10
11
4
12
13
14
3
2
1
0
5
6
7
8
9
10
11
12
4
13
14
3
2
1
0
5
6
7
8
9
10
11
12
13
4
14
3
2
1
0
5
6
7
8
9
10
11
12
13
14
4
3
2
1
0
5
6
7
8
9
10
11
12
13
14
2
1
0
6
5
7
8
9
10
11
12
13
14
4
3
2
1
0
6
7
5
8
9
10
11
12
13
14
4
3
2
1
0
6
7
8
5
9
10
11
12
13
14
4
3
2
1
0
6
7
8
9
5
10
11
12
13
14
4
3
2
1
0
6
7
8
9
10
5
11
12
13
14
4
3
2
1
0
6
7
8
9
10
11
5
12
13
14
4
3
2
1
0
6
7
8
9
10
11
12
5
13
14
4
3
2
1
0
6
7
8
9
10
11
12
13
5
14
4
3
2
1
0
6
7
8
9
10
11
12
13
14
5
4
3
2
1
0
6
7
8
9
10
11
12
13
14
3
2
1
0
7
6
8
9
10
11
12
13
14
5
4
3
2
1
0
7
8
6
9
10
11
12
13
14
5
4
3
2
1
0
7
8
9
6
10
11
12
13
14
5
4
3
2
1
0
7
8
9
10
6
11
12
13
14
5
4
3
2
1
0
7
8
9
10
11
6
12
13
14
5
4
3
2
1
0
7
8
9
10
11
12
6
13
14
5
4
3
2
1
0
7
8
9
10
11
12
13
6
14
5
4
3
2
1
0
7
8
9
10
11
12
13
14
6
5
4
3
2
1
0
7
8
9
10
11
12
13
14
4
3
2
1
0
8
7
9
10
11
12
13
14
6
5
4
3
2
1
0
8
9
7
10
11
12
13
14
6
5
4
3
2
1
0
8
9
10
7
11
12
13
14
6
5
4
3
2
1
0
8
9
10
11
7
12
13
14
6
5
4
3
2
1
0
8
9
10
11
12
7
13
14
6
5
4
3
2
1
0
8
9
10
11
12
13
7
14
6
5
4
3
2
1
0
8
9
10
11
12
13
14
7
6
5
4
3
2
1
0
8
9
10
11
12
13
14
5
4
3
2
1
0
9
8
10
11
12
13
14
7
6
5
4
3
2
1
0
9
10
8
11
12
13
14
7
6
5
4
3
2
1
0
9
10
11
8
12
13
14
7
6
5
4
3
2
1
0
9
10
11
12
8
13
14
7
6
5
4
3
2
1
0
9
10
11
12
13
8
14
7
6
5
4
3
2
1
0
9
10
11
12
13
14
8
7
6
5
4
3
2
1
0
9
10
11
12
13
14
6
5
4
3
2
1
0
10
9
11
12
13
14
8
7
6
5
4
3
2
1
0
10
11
9
12
13
14
8
7
6
5
4
3
2
1
0
10
11
12
9
13
14
8
7
6
5
4
3
2
1
0
10
11
12
13
9
14
8
7
6
5
4
3
2
1
0
10
11
12
13
14
9
8
7
6
5
4
3
2
1
0
10
11
12
13
14
7
6
5
4
3
2
1
0
11
10
12
13
14
9
8
7
6
5
4
3
2
1
0
11
12
10
13
14
9
8
7
6
5
4
3
2
1
0
11
12
13
10
14
9
8
7
6
5
4
3
2
1
0
11
12
13
14
10
9
8
7
6
5
4
3
2
1
0
11
12
13
14
8
7
6
5
4
3
2
1
0
12
11
13
14
10
9
8
7
6
5
4
3
2
1
0
12
13
11
14
10
9
8
7
6
5
4
3
2
1
0
12
13
14
11
10
9
8
7
6
5
4
3
2
1
0
12
13
14
9
8
7
6
5
4
3
2
1
0
13
12
14
11
10
9
8
7
6
5
4
3
2
1
0
13
14
12
11
10
9
8
7
6
5
4
3
2
1
0
13
14
10
9
8
7
6
5
4
3
2
1
0
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
Таблица 2: Сортировка пузырьком в многопоточном режиме
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
1
0
2
3
4
5
6
7
8
9
10
11
12
13
14
1
2
0
3
4
5
6
7
8
9
10
11
12
13
14
2
1
3
0
4
5
6
7
8
9
10
11
12
13
14
2
3
1
4
0
5
6
7
8
9
10
11
12
13
14
3
2
4
1
5
0
6
7
8
9
10
11
12
13
14
3
4
2
5
1
6
0
7
8
9
10
11
12
13
14
4
3
5
2
6
1
7
0
8
9
10
11
12
13
14
4
5
3
6
2
7
1
8
0
9
10
11
12
13
14
5
4
6
3
7
2
8
1
9
0
10
11
12
13
14
5
6
4
7
3
8
2
9
1
10
0
11
12
13
14
6
5
7
4
8
3
9
2
10
1
11
0
12
13
14
6
7
5
8
4
9
3
10
2
11
1
12
0
13
14
7
6
8
5
9
4
10
3
11
2
12
1
13
0
14
7
8
6
9
5
10
4
11
3
12
2
13
1
14
0
8
7
9
6
10
5
11
4
12
3
13
2
14
1
0
8
9
7
10
6
11
5
12
4
13
3
14
2
1
0
9
8
10
7
11
6
12
5
13
4
14
3
2
1
0
9
10
8
11
7
12
6
13
5
14
4
3
2
1
0
10
9
11
8
12
7
13
6
14
5
4
3
2
1
0
10
11
9
12
8
13
7
14
6
5
4
3
2
1
0
11
10
12
9
13
8
14
7
6
5
4
3
2
1
0
11
12
10
13
9
14
8
7
6
5
4
3
2
1
0
12
11
13
10
14
9
8
7
6
5
4
3
2
1
0
12
13
11
14
10
9
8
7
6
5
4
3
2
1
0
13
12
14
11
10
9
8
7
6
5
4
3
2
1
0
13
14
12
11
10
9
8
7
6
5
4
3
2
1
0
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
Код:
#include
Ось абсцисс — кол-во элементов, ординат — время выполнения в сек.
Реализация
Я привожу код реализации на языке CUDA С, который содержит код, выполняющий сортировку ПО УБЫВАНИЮ на CUDA и CPU (в однопоточном режиме). По сути, это бенчмарк для вашего компа того, как шустро работает сортировка на видеокарте и на проце. Частью этой проги является функция сортировки на видеокарте на платформе CUDA, которую вы можете использовать на здоровье в своих шедеврах элементарным copy’n'past. Код представлен ниже таблиц.Как это компилировать???
Ну, для этого необходимо скачать драйвера для CUDA с сайта Nvidia, установить их, скачать Nvidia Toolkit, установить и Nvidia SDK, тоже установить. К счастью, сейчас все идет уже в одном пакете. Как устанавливать CUDA напишу, если будет спрос, а так просто пожелаю удачи, если ты новичок.Когда все готово и nvidia CUDA работает на твоем компе, то тогда достаточно лишь скомпилировать файл main.cu (или как там его назвал) и запустить прогу, получить результат и выложить его здесь.Уот и все на сейчас, спасибо, что прочитал. До скорого.P.S. Буду супер признателен, если подскажете, как ускорить алгоритм =)Таблица 1: Сортировка пузырьком в однопоточном режиме
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
1
0
2
3
4
5
6
7
8
9
10
11
12
13
14
1
2
0
3
4
5
6
7
8
9
10
11
12
13
14
1
2
3
0
4
5
6
7
8
9
10
11
12
13
14
1
2
3
4
0
5
6
7
8
9
10
11
12
13
14
1
2
3
4
5
0
6
7
8
9
10
11
12
13
14
1
2
3
4
5
6
0
7
8
9
10
11
12
13
14
1
2
3
4
5
6
7
0
8
9
10
11
12
13
14
1
2
3
4
5
6
7
8
0
9
10
11
12
13
14
1
2
3
4
5
6
7
8
9
0
10
11
12
13
14
1
2
3
4
5
6
7
8
9
10
0
11
12
13
14
1
2
3
4
5
6
7
8
9
10
11
0
12
13
14
1
2
3
4
5
6
7
8
9
10
11
12
0
13
14
1
2
3
4
5
6
7
8
9
10
11
12
13
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
1
3
4
5
6
7
8
9
10
11
12
13
14
0
2
3
1
4
5
6
7
8
9
10
11
12
13
14
0
2
3
4
1
5
6
7
8
9
10
11
12
13
14
0
2
3
4
5
1
6
7
8
9
10
11
12
13
14
0
2
3
4
5
6
1
7
8
9
10
11
12
13
14
0
2
3
4
5
6
7
1
8
9
10
11
12
13
14
0
2
3
4
5
6
7
8
1
9
10
11
12
13
14
0
2
3
4
5
6
7
8
9
1
10
11
12
13
14
0
2
3
4
5
6
7
8
9
10
1
11
12
13
14
0
2
3
4
5
6
7
8
9
10
11
1
12
13
14
0
2
3
4
5
6
7
8
9
10
11
12
1
13
14
0
2
3
4
5
6
7
8
9
10
11
12
13
1
14
0
2
3
4
5
6
7
8
9
10
11
12
13
14
1
2
3
4
5
6
7
8
9
10
11
12
13
14
3
2
4
5
6
7
8
9
10
11
12
13
14
1
0
3
4
2
5
6
7
8
9
10
11
12
13
14
1
0
3
4
5
2
6
7
8
9
10
11
12
13
14
1
0
3
4
5
6
2
7
8
9
10
11
12
13
14
1
0
3
4
5
6
7
2
8
9
10
11
12
13
14
1
0
3
4
5
6
7
8
2
9
10
11
12
13
14
1
0
3
4
5
6
7
8
9
2
10
11
12
13
14
1
0
3
4
5
6
7
8
9
10
2
11
12
13
14
1
0
3
4
5
6
7
8
9
10
11
2
12
13
14
1
0
3
4
5
6
7
8
9
10
11
12
2
13
14
1
0
3
4
5
6
7
8
9
10
11
12
13
2
14
1
0
3
4
5
6
7
8
9
10
11
12
13
14
2
1
0
3
4
5
6
7
8
9
10
11
12
13
14
4
3
5
6
7
8
9
10
11
12
13
14
2
1
0
4
5
3
6
7
8
9
10
11
12
13
14
2
1
0
4
5
6
3
7
8
9
10
11
12
13
14
2
1
0
4
5
6
7
3
8
9
10
11
12
13
14
2
1
0
4
5
6
7
8
3
9
10
11
12
13
14
2
1
0
4
5
6
7
8
9
3
10
11
12
13
14
2
1
0
4
5
6
7
8
9
10
3
11
12
13
14
2
1
0
4
5
6
7
8
9
10
11
3
12
13
14
2
1
0
4
5
6
7
8
9
10
11
12
3
13
14
2
1
0
4
5
6
7
8
9
10
11
12
13
3
14
2
1
0
4
5
6
7
8
9
10
11
12
13
14
3
2
1
0
4
5
6
7
8
9
10
11
12
13
14
1
0
5
4
6
7
8
9
10
11
12
13
14
3
2
1
0
5
6
4
7
8
9
10
11
12
13
14
3
2
1
0
5
6
7
4
8
9
10
11
12
13
14
3
2
1
0
5
6
7
8
4
9
10
11
12
13
14
3
2
1
0
5
6
7
8
9
4
10
11
12
13
14
3
2
1
0
5
6
7
8
9
10
4
11
12
13
14
3
2
1
0
5
6
7
8
9
10
11
4
12
13
14
3
2
1
0
5
6
7
8
9
10
11
12
4
13
14
3
2
1
0
5
6
7
8
9
10
11
12
13
4
14
3
2
1
0
5
6
7
8
9
10
11
12
13
14
4
3
2
1
0
5
6
7
8
9
10
11
12
13
14
2
1
0
6
5
7
8
9
10
11
12
13
14
4
3
2
1
0
6
7
5
8
9
10
11
12
13
14
4
3
2
1
0
6
7
8
5
9
10
11
12
13
14
4
3
2
1
0
6
7
8
9
5
10
11
12
13
14
4
3
2
1
0
6
7
8
9
10
5
11
12
13
14
4
3
2
1
0
6
7
8
9
10
11
5
12
13
14
4
3
2
1
0
6
7
8
9
10
11
12
5
13
14
4
3
2
1
0
6
7
8
9
10
11
12
13
5
14
4
3
2
1
0
6
7
8
9
10
11
12
13
14
5
4
3
2
1
0
6
7
8
9
10
11
12
13
14
3
2
1
0
7
6
8
9
10
11
12
13
14
5
4
3
2
1
0
7
8
6
9
10
11
12
13
14
5
4
3
2
1
0
7
8
9
6
10
11
12
13
14
5
4
3
2
1
0
7
8
9
10
6
11
12
13
14
5
4
3
2
1
0
7
8
9
10
11
6
12
13
14
5
4
3
2
1
0
7
8
9
10
11
12
6
13
14
5
4
3
2
1
0
7
8
9
10
11
12
13
6
14
5
4
3
2
1
0
7
8
9
10
11
12
13
14
6
5
4
3
2
1
0
7
8
9
10
11
12
13
14
4
3
2
1
0
8
7
9
10
11
12
13
14
6
5
4
3
2
1
0
8
9
7
10
11
12
13
14
6
5
4
3
2
1
0
8
9
10
7
11
12
13
14
6
5
4
3
2
1
0
8
9
10
11
7
12
13
14
6
5
4
3
2
1
0
8
9
10
11
12
7
13
14
6
5
4
3
2
1
0
8
9
10
11
12
13
7
14
6
5
4
3
2
1
0
8
9
10
11
12
13
14
7
6
5
4
3
2
1
0
8
9
10
11
12
13
14
5
4
3
2
1
0
9
8
10
11
12
13
14
7
6
5
4
3
2
1
0
9
10
8
11
12
13
14
7
6
5
4
3
2
1
0
9
10
11
8
12
13
14
7
6
5
4
3
2
1
0
9
10
11
12
8
13
14
7
6
5
4
3
2
1
0
9
10
11
12
13
8
14
7
6
5
4
3
2
1
0
9
10
11
12
13
14
8
7
6
5
4
3
2
1
0
9
10
11
12
13
14
6
5
4
3
2
1
0
10
9
11
12
13
14
8
7
6
5
4
3
2
1
0
10
11
9
12
13
14
8
7
6
5
4
3
2
1
0
10
11
12
9
13
14
8
7
6
5
4
3
2
1
0
10
11
12
13
9
14
8
7
6
5
4
3
2
1
0
10
11
12
13
14
9
8
7
6
5
4
3
2
1
0
10
11
12
13
14
7
6
5
4
3
2
1
0
11
10
12
13
14
9
8
7
6
5
4
3
2
1
0
11
12
10
13
14
9
8
7
6
5
4
3
2
1
0
11
12
13
10
14
9
8
7
6
5
4
3
2
1
0
11
12
13
14
10
9
8
7
6
5
4
3
2
1
0
11
12
13
14
8
7
6
5
4
3
2
1
0
12
11
13
14
10
9
8
7
6
5
4
3
2
1
0
12
13
11
14
10
9
8
7
6
5
4
3
2
1
0
12
13
14
11
10
9
8
7
6
5
4
3
2
1
0
12
13
14
9
8
7
6
5
4
3
2
1
0
13
12
14
11
10
9
8
7
6
5
4
3
2
1
0
13
14
12
11
10
9
8
7
6
5
4
3
2
1
0
13
14
10
9
8
7
6
5
4
3
2
1
0
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
Таблица 2: Сортировка пузырьком в многопоточном режиме
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
1
0
2
3
4
5
6
7
8
9
10
11
12
13
14
1
2
0
3
4
5
6
7
8
9
10
11
12
13
14
2
1
3
0
4
5
6
7
8
9
10
11
12
13
14
2
3
1
4
0
5
6
7
8
9
10
11
12
13
14
3
2
4
1
5
0
6
7
8
9
10
11
12
13
14
3
4
2
5
1
6
0
7
8
9
10
11
12
13
14
4
3
5
2
6
1
7
0
8
9
10
11
12
13
14
4
5
3
6
2
7
1
8
0
9
10
11
12
13
14
5
4
6
3
7
2
8
1
9
0
10
11
12
13
14
5
6
4
7
3
8
2
9
1
10
0
11
12
13
14
6
5
7
4
8
3
9
2
10
1
11
0
12
13
14
6
7
5
8
4
9
3
10
2
11
1
12
0
13
14
7
6
8
5
9
4
10
3
11
2
12
1
13
0
14
7
8
6
9
5
10
4
11
3
12
2
13
1
14
0
8
7
9
6
10
5
11
4
12
3
13
2
14
1
0
8
9
7
10
6
11
5
12
4
13
3
14
2
1
0
9
8
10
7
11
6
12
5
13
4
14
3
2
1
0
9
10
8
11
7
12
6
13
5
14
4
3
2
1
0
10
9
11
8
12
7
13
6
14
5
4
3
2
1
0
10
11
9
12
8
13
7
14
6
5
4
3
2
1
0
11
10
12
9
13
8
14
7
6
5
4
3
2
1
0
11
12
10
13
9
14
8
7
6
5
4
3
2
1
0
12
11
13
10
14
9
8
7
6
5
4
3
2
1
0
12
13
11
14
10
9
8
7
6
5
4
3
2
1
0
13
12
14
11
10
9
8
7
6
5
4
3
2
1
0
13
14
12
11
10
9
8
7
6
5
4
3
2
1
0
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
Код:
#include
__global__ void bubbleMove (int *array_device, int N, int step){
int idx = blockDim.x * blockIdx.x + threadIdx.x;
if (idx<(N-1)) {
if (step-2>=idx){
if (array_device[idx] void bubleSortCUDA (int *array_host, int N, int blockSize){
int *array_device; cudaMalloc ((void **)&array_device, N * sizeof (int));
for (int i = 0; i < N; i++) array_host[i]=i;
cudaMemcpy(array_device,array_host,N*sizeof(int),cudaMemcpyHostToDevice);
int nblocks = N / blockSize+1;
for (int step = 0; step <= N+N; step++) {
bubbleMove<< void bubleSortCPU (int *array_host, int N){
for (int i = 0; i < N; i++){
for (int j = 0; j < N-i-1; j++) {
if (array_host[j] int checkArray (int *array_host, int N){
int good=1;
for (int i = 0; i < N-1; i++) if (array_host[i] float measureCUDA (int N, int blockSize){
int *array_host = (int *)malloc (N * sizeof (int));
for (int i = 0; i < N; i++) array_host[i]=i;
clock_t start = clock();
bubleSortCUDA(array_host,N,blockSize);
clock_t end = clock();
if (checkArray(array_host,N)==1){
free(array_host);
return (float)(end - start) / CLOCKS_PER_SEC;
}
else {
free(array_host);
return -1;
}
} float measureCPU (int N) {
int *array_host = (int *)malloc (N * sizeof (int));
for (int i = 0; i < N; i++) array_host[i]=i;
clock_t start = clock();
bubleSortCPU(array_host,N);
clock_t end = clock();
if (checkArray(array_host,N)==1){
free(array_host);
return (float)(end - start) / CLOCKS_PER_SEC;
}
else {
free(array_host);
return -1;
}
} int main (int argc, char const *argv[]) {
for (int i = 1; i < 10000000; i*=2) printf("%d %f\t%f\n",i, measureCUDA(i,256),measureCPU (i ));
return 0;
}
