Памятка евангелиста PostgreSQL: репликанты против репликации

В продолжение серии публикаций «Памятка евангелиста PostgreSQL...» (1, 2) дорогая редакция снова выходит на связь, на этот раз с обещанным обзором механизмов репликации в PostgreSQL и MySQL. Главным поводом для написания послужила частая критика репликации MySQL. Как это часто бывает, типичная критика представляет из себя забористую смесь из правды, полуправды и евангелизма. Всё это многократно реплицируется разными людьми без особых попыток разобраться в услышанном. А поскольку это довольно обширная тема, я решил вынести разбор в отдельную публикацию.
Итак, в рамках культурного обмена и в преддверии HighLoad++, где наверняка будет как обычно много критики в адрес MySQL, рассмотрим механизмы репликации. Для начала немного скучных базовых вещей для тех, кто ещё не.
Репликация бывает логическая и физическая. Физическая представляет из себя описание изменений на уровне файлов данных (упрощенно: записать такие байты по такому-то смещению на такой-то странице). Логическая же описывает изменения на более высоком уровне без привязки к конкретному представлению данных на диске, и здесь возможны варианты. Можно описывать изменения в терминах строк таблиц, например оператор UPDATE может быть отражён в виде последовательности пар (старые значения, новые значения) для каждой изменённой строки. В MySQL такой тип называется row-based репликация. А можно просто записывать текст всех SQL запросов, модифицирующих данные. Такой тип в MySQL называется statement-based репликация.
Физическую репликацию часто называют бинарной (особенно в PostgreSQL сообществе), что неверно. Формат данных как логической, так и физической репликации может быть как текстовым (то есть человекочитаемым), так и бинарным (требующим обработки для чтения человеком). На практике все форматы как в MySQL, так и PostgreSQL бинарные. Очевидно, что в случае statement-based репликации в MySQL тексты запросов можно прочитать «невооружённым глазом», но вся служебная информация всё равно будет в бинарном виде. Поэтому и журнал, используемый в репликации, называется бинарным независимо от формата репликации.
Особенности логической репликации:
- независимость от формата хранения данных: мастер и слейв могут иметь разные представления данных на диске, разные архитектуры процессора, разные структуры таблиц (при условии совместимости схем), разные конфигурации и расположение файлов данных, разные движки хранения (для MySQL), разные версии сервера, да и вообще мастер и слейв могут быть разными СУБД (и такие решения для «кросс-платформенной» репликации существуют). Эти свойства используют часто, особенно в масштабных проектах. Например, в rolling schema upgrade.
- доступность для чтения: с каждого узла в репликации можно читать данные без всяких ограничений. С физической репликацией это не так просто (см. ниже)
- возможность multi-source: объединение изменений с разных мастеров на одном слейве. Пример использования: агрегация данных с нескольких шардов для построения статистики и отчётов. Та же Wikipedia использует multi-source именно для этих целей
- возможность multi-master: при любой топологии можно иметь более одного доступного на запись сервера, если это необходимо
- частичная репликация: возможность реплицировать только отдельные таблицы или схемы
- компактность: объём передаваемых по сети данных меньше. В отдельных случаях сильно меньше.
Особенности физической репликации:
- проще в конфигурации и использовании: Сама по себе задача побайтового зеркалирования одного сервера на другой гораздо проще логической репликации с её многочисленными сценариями использования и топологиями. Отсюда знаменитое «настроил и забыл» во всех холиворах «MySQL против PostgreSQL».
- низкое потребление ресурсов: Логическое репликация требует дополнительных ресурсов, потому что логическое описание изменений ещё нужно «перевести» в физическое, т.е. понять что конкретно и куда записывать на диск
- требование 100% идентичности узлов: физическая репликация возможно только между абсолютно одинаковыми серверами, вплоть до архитектуры процессора, путей к tablespace файлам, и т.д. Это часто может стать проблемой для масштабных кластеров репликации, т.к. изменение этих факторов влечёт полную остановку кластера.
- никакой записи на слейве: вытекает из предыдущего пункта. Даже временную таблицу создать нельзя.
- чтение со слейва проблематично: чтение со слейва возможно, но не без проблем. См. «Физическая репликация в PostgreSQL» ниже
- ограниченность топологий: никакие multi-source и multi-master невозможны. В лучшем случае каскадная репликация.
- нет частичной репликации: вытекает всё из того же требования 100% идентичности файлов данных
- большие накладные расходы: нужно передавать все изменения в файлах данных (операция с индексами, vacuum и прочую внутреннюю бухгалтерию). А значит нагрузка на сеть выше, чем при логической репликации. Но всё как обычно зависит от количества/типа индексов, нагрузки и прочих факторов.
А ещё репликация может быть синхронной, асинхронной и полусинхронной независимо от формата. Но этот факт имеет небольшое отношение к обсуждаемым здесь вещам, поэтому его оставим за скобками.
Её как таковой нет, по крайней мере встроенной в сам сервер. На то есть архитектурные причины, но это не значит, что она невозможна в принципе. Oracle мог бы сравнительно небольшими усилиями реализовать физическую репликацию для InnoDB, а это уже покрыло бы потребности большинства пользователей. Более сложный подход потребовал бы создания некоторого API, реализовав который альтернативные движки могли бы поддерживать физическую репликацию, но я не думаю, что это когда-нибудь случится.
Но в некоторых случаях физическую репликацию можно реализовать внешними средствами, например с помощью DRBD или аппаратных решений. Плюсы и минусы такого подхода обсуждались неоднократно и подробно.
В контексте сравнения с PostgreSQL нужно отметить, что использование DRBD и подобных решений для физической репликации MySQL больше всего похоже на warm standby в PostgreSQL. Но объём передаваемых по сети данных в DRBD будет выше, потому что DRBD работает на уровне блочного устройства, а значит реплицируются не только записи в REDO log (транзакционный журнал), но и запись в файлы данных и обновления метаинформации файловой системы.
Эта тема и вызывает больше всего волнений. Причём бОльшая часть критики основана на докладе «Асинхронная репликация MySQL без цензуры или почему PostgreSQL завоюет мир» Олега Царёва zabivator, а так же сопутствующей статьи на Хабре.
 Я бы не стал выделять один конкретный доклад, если бы мне не ссылались на него примерно в каждом десятом комментарии к предыдущим статьям. Поэтому приходится отвечать, но я бы хотел подчеркнуть, что идеальных докладов не бывает (у меня лично доклады получаются плохие), и вся критика направлена не на докладчика, а на технические неточности в докладе. Буду рад, если это поможет улучшить его будущие версии.
Я бы не стал выделять один конкретный доклад, если бы мне не ссылались на него примерно в каждом десятом комментарии к предыдущим статьям. Поэтому приходится отвечать, но я бы хотел подчеркнуть, что идеальных докладов не бывает (у меня лично доклады получаются плохие), и вся критика направлена не на докладчика, а на технические неточности в докладе. Буду рад, если это поможет улучшить его будущие версии.
В целом в докладе довольно много технически неточных или просто неверных утверждений, часть из них я адресовал в первой части памятки евангелиста. Но я не хочу утонуть в мелочах, поэтому буду разбирать основные тезисы.
Итак, в MySQL логическая репликация представлена двумя подтипами: statement-based и row-based.
Statement-based — это самый наивный способ организовать репликацию («а давайте просто передавать на слейв SQL команды!»), именно поэтому она появилась в MySQL первой и это было очень давно. Она даже работает до тех пор, пока SQL команды строго детерминированы, т.е. приводят к одним и тем же изменениями независимо от времени выполнения, контекста, триггеров и т.д. Про это написаны тонны статей, я не буду здесь подробно останавливаться.
На мой взгляд, statement-based репликация — это хак и «legacy» в стиле MyISAM. Наверняка кто-то где-то ещё находит ей применение, но по возможности избегайте этого.
 Интересно, что о применении statement-based репликации рассказывает в своём докладе и Олег. Причина — row-based репликация генерировала бы терабайты информации в сутки. Что в общем логично, но как это согласуется с утверждением «PostgreSQL завоюет мир», если в PostgreSQL асинхронной statement-based репликации нет вообще? То есть и PostgreSQL бы генерировал терабайты обновлений в сутки, «бутылочным горлышком» вполне ожидаемо стали бы диск или сеть, и с завоеванием мира пришлось бы подождать.
Интересно, что о применении statement-based репликации рассказывает в своём докладе и Олег. Причина — row-based репликация генерировала бы терабайты информации в сутки. Что в общем логично, но как это согласуется с утверждением «PostgreSQL завоюет мир», если в PostgreSQL асинхронной statement-based репликации нет вообще? То есть и PostgreSQL бы генерировал терабайты обновлений в сутки, «бутылочным горлышком» вполне ожидаемо стали бы диск или сеть, и с завоеванием мира пришлось бы подождать.
Олег обращает внимание, что логическая репликация обычно CPU-bound, то есть упирается в процессор, а физическая — обычно I/O-bound, то есть упирается в сеть/диск. Я не совсем уверен в этом утверждении: CPU-bound нагрузка одним движением руки превращается в элегантную I/O bound как только активный набор данных перестаёт помещаться в память (типичная ситуация для того же Facebook, например). А вместе с этим нивелируется и бОльшая часть разницы между логической и физической репликацией. Но в целом я согласен: логическая репликация требует сравнительно больше ресурсов (и это её главный недостаток), а физическая меньше (и это практически единственное её преимущество).
Причин «тормозить» у репликации может быть много: это не только однопоточность или недостаток процессора, это может быть сеть, диск, неэффективные запросы, неадекватная конфигурация. Главный вред от доклада заключается в том, что он «гребёт всех под одну гребёнку», объясняя все проблемы некой «архитектурной ошибкой MySQL», и оставляя впечатление, что решения у этих проблем нет. Именно поэтому он был с радостью взят на вооружение евангелистами всех мастей. На самом деле я уверен, что 1) большая часть проблем имеет решение и 2) все эти проблемы существуют и в реализациях логической репликации для PostgreSQL, возможно даже в более тяжёлой форме (см. «Логическая репликация для PostgreSQL»).
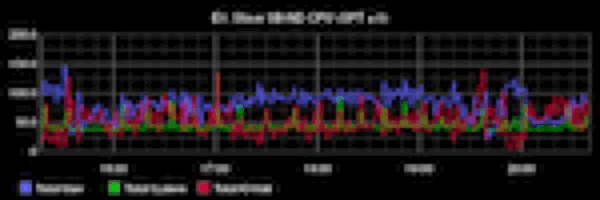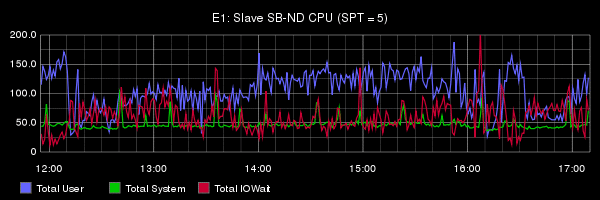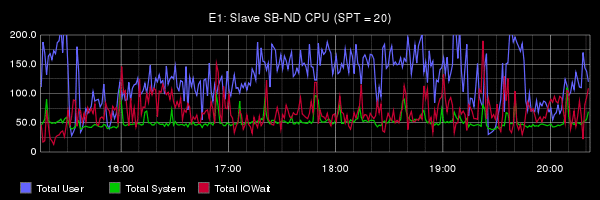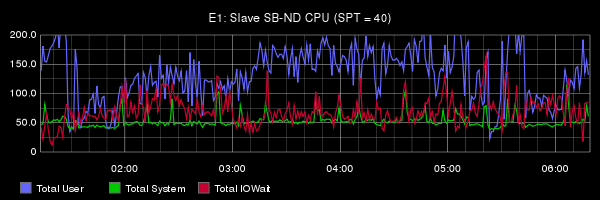 Из доклада Олега очень сложно понять, что на самом деле стало проблемой в его тестах: нет никакой попытки анализа, нет никаких метрик, ни на уровне ОС, ни на уровне сервера. Для сравнения: публикация инженеров из Booking.com на ту же тему, но с подробным анализом и без «евангелистских» выводов. Особенно рекомендую ознакомиться с разделом Under the Hood. Вот так правильно делать и показывать бенчмарки. В докладе Олега на бенчмарки отведено 3 слайда.
Из доклада Олега очень сложно понять, что на самом деле стало проблемой в его тестах: нет никакой попытки анализа, нет никаких метрик, ни на уровне ОС, ни на уровне сервера. Для сравнения: публикация инженеров из Booking.com на ту же тему, но с подробным анализом и без «евангелистских» выводов. Особенно рекомендую ознакомиться с разделом Under the Hood. Вот так правильно делать и показывать бенчмарки. В докладе Олега на бенчмарки отведено 3 слайда.
Я же просто коротко перечислю возможные проблемы и их решение. Предвижу много комментариев в духе «а в слонике всё нормально работает и без всякого шаманства!». Отвечу на них один раз и больше не буду: физическая репликация проще в настройке, чем логическая, но её возможностей хватает далеко не всем. У логической возможностей больше, но есть и недостатки. Здесь описаны способы минимизации недостатков для MySQL.
Если упираемся в диск
Часто для слейва выделяют слабые машины из соображений «ну, это же не основной сервер, сойдёт и этот старый тазик». В старом тазике обычно оказывается слабый диск, в который всё и упирается.
Если диск является узким место при репликации, и использовать что-то мощнее не представляется возможным, нужно снизить дисковую нагрузку.
Во-первых, можно регулировать объём информации, который master записывает в бинарный журнал, а значит пересылается по сети и записывается/читается на слейве. Настройки, которые стоит посмотреть: binlog_rows_query_log_events, binlog_row_image.
Во-вторых, можно отключить бинарный журнал на слейве. Он нужен только в том случае, если слейв сам является мастером (в multi-master топологии или в качестве промежуточного мастера в каскадной репликации). Некоторые держат бинарный журнал включенным для того, чтобы ускорить переключение слейва в режим мастера в случае failover. Но если с производительностью диска проблемы, его можно и нужно отключить.
В-третьих, можно ослабить настройки durability на слейве. Слейв по определению является неактуальной (за счёт асинхронности) и не единственной копией данных, а значит в случае его падения его можно пересоздать либо из бэкапа, либо из мастера, либо из другого слейва. Поэтому нет никакого смысла держать строгие настройки durability, ключевые слова: sync_binlog, innodb_flush_log_at_trx_commit, innodb_doublewrite.
Наконец, общую настройку InnoDB на интенсивную запись никто не отменял. Ключевые слова: innodb_max_dirty_pages_pct, innodb_stats_persistent, innodb_adaptive_flushing, innodb_flush_neighbors, innodb_write_io_threads , innodb_io_capacity, innodb_purge_threads, innodb_log_file_size, innodb_log_buffer_size.
Если ничего не помогает, можно посмотреть в сторону движка TokuDB, который во-первых оптимизирован для интенсивной записи, особенно если данные не умещаются в память, а во-вторых предоставляет возможность организации read-free репликации. Это может решить проблему как в IO-bound, так и в CPU-bound нагрузках.
Если упираемся в процессор
При достаточно интенсивной записи на мастере и отсутствии других узких мест на слейве (сеть, диск), можно упереться в процессор. Тут на помощь приходит параллельная репликация, она же multi-threaded slave (MTS).
В 5.6 MTS был сделан в очень ограниченном виде: параллельно выполнялись только обновления в разные базы (схемы в терминологии PostgreSQL). Но наверняка на свете существует непустое множество пользователей, которым и этого вполне достаточно (привет, хостеры!).
В 5.7 MTS был расширен для параллельного выполнения произвольных обновлений. В ранних дорелизных версиях 5.7 параллельность ограничивалась количеством одновременно зафиксированных транзакций в рамках group commit. Это ограничивало параллельность, особенно для систем с быстрыми дисками, что скорее всего и приводило к недостаточно эффективным результатам у тех, кто эти ранние версии тестировал. Это вполне нормально, для того они и ранние версии, чтобы заинтересованные пользователи могли потестировать и поругать. Но далеко не все пользователи догадываются сделать из этого доклад с выводом «PostgreSQL завоюет мир».
Тем не менее, вот результаты всё тех же sysbench тестов, которые использовал для доклада Олег, но уже на GA релизе 5.7. Что мы видим в сухом остатке: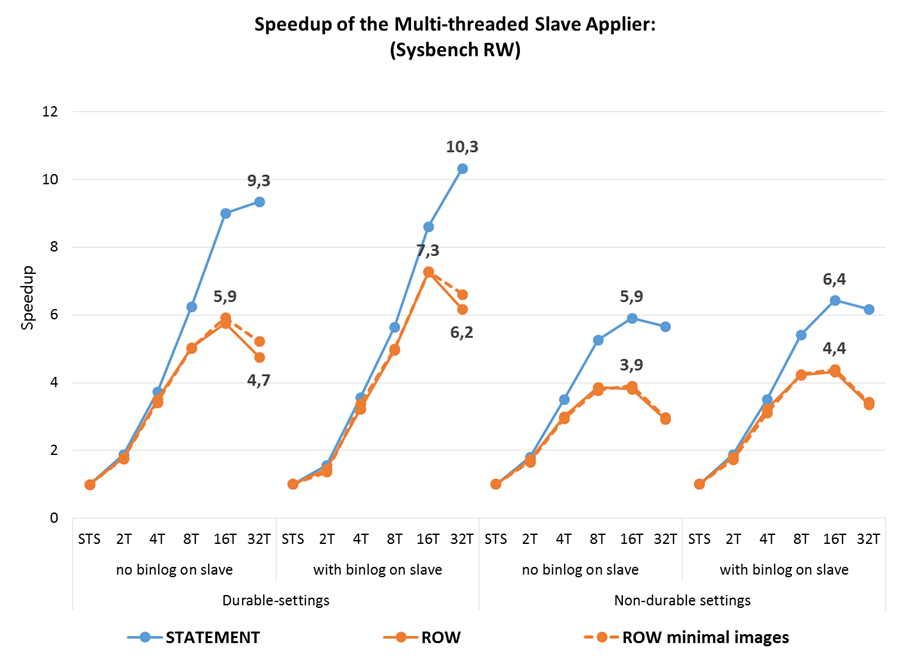
- MTS на слейве достигает 10-кратного увеличения производительности по сравнению с однопоточной репликацией
- использование
slave_parallel_workers=4уже приводит к росту пропускной способности слейва в более чем 3.5 раза - производительность row-based репликации практически всегда выше, чем statement-based. Но MTS оказывает больший эффект на statement-based, что несколько уравнивает оба формата с точки зрения производительности на OLTP нагрузках.
Ещё один важный вывод из тестирования Booking.com: чем меньше размер транзакций, тем большей параллельности можно достичь. До появления group commit в 5.6 разработчики старались сделать транзакции как можно больше, часто без необходимости с точки зрения приложений. Начиная с 5.6 в этом нет необходимости, а для параллельной репликации в 5.7 лучше пересмотреть транзакции и разбить на более мелкие там, где это возможно.
Кроме того, можно подстроить параметры binlog_group_commit_sync_delay и binlog_group_commit_sync_no_delay_count на мастере, что может привести к дополнительной параллельности на слейве даже в случае длинных транзакций.
На этом тему с репликацией в MySQL и популярным докладом я считаю закрытой, переходим к PostgreSQL.
Помимо всех плюсов и минусов физической репликации, перечисленных ранее, реализация в PostgreSQL обладает ещё одним существенным недостатком: совместимость репликации не гарантируется между мажорными релизами PostgreSQL, поскольку не гарантируется совместимость WAL. Это действительно серьёзный недостаток для нагруженных проектов и больших кластеров: требуется остановка мастера, апгрейд, затем полное пересоздание слейвов. Для сравнения: проблемы с репликацией от старых версий к новым в MySQL случаются, но их исправляют и в большинстве случаев это работает, от совместимости никто не отказывается. Что и используется при обновлении масштабных кластеров — плюсы «ущербной» логической репликации.
PostgreSQL предоставляет возможность чтения данных со слейва (т.н. Hot Standby), но с этим всё далеко не так просто, как при логической репликации. Из документации по Hot Standby удалось выяснить, что:
SELECT ... FOR SHARE | UPDATEне поддерживаются, потому что для этого требуется модификация файлов данных- 2PC команды не поддерживаются по тем же причинам
- явное указание «read write» состояние транзакций (
BEGIN READ WRITEи т.д.), LISTEN, UNLISTEN, NOTIFY, обновления sequence не поддерживаются. Что в целом объяснимо, Но это значит, что какие-то приложения придётся переписывать при миграции на Hot Standby, даже если никаких данных они не модифицируют - Даже read-only запросы могут вызывать конфликты с DDL и vacuum операциями на мастере (привет «агрессивным» настройкам vacuum!) В этом случае запросы могут либо задержать репликацию, либо быть принудительно прерваны и есть конфигурационные параметры, которые этим поведением управляют
- слейв можно настроить для предоставления «обратной связи» с мастером (параметр
hot_standby_feedback). Что хорошо, но интересны накладные расходы этого механизма в нагруженных системах.
Кроме того, я обнаружил дивное предостережение в той же документации:
- «Operations on hash indexes are not presently WAL-logged, so replay will not update these indexes» — эээ, а это вообще как? А с физическими бэкапами что?
Есть некоторые особенности с failover, которые пользователю MySQL могут показаться странными, например невозможность возврата к старому мастеру после failover без его пересоздания. Цитирую документацию:
Once failover to the standby occurs, there is only a single server in operation. This is known as a degenerate state. The former standby is now the primary, but the former primary is down and might stay down. To return to normal operation, a standby server must be recreated, either on the former primary system when it comes up, or on a third, possibly new, system.
Есть ещё одна специфическая особенность физической репликации в PostgreSQL. Как я написал выше, накладные расходы по трафику для физической репликации в целом выше, чем в логической. Но в случае с PostgeSQL в WAL записываются (а значит передаются по сети) полные образы обновлённых после checkpoint-ов страниц (full_page_writes). Я легко могу представить нагрузки, где такое поведение может стать катастрофой. Здесь наверняка несколько человек кинутся объяснять мне смысл full_page_writes. Я знаю, просто в InnoDB это реализовано несколько иначе, не через транзакционный журнал.
В остальном физическая репликация в PostgreSQL наверное действительно надёжный и простой в настройке механизм для тех, кому физическая репликация вообще подходит.
Но пользователи PostgreSQL тоже люди и ничто человеческое им не чуждо. Кому-то хочется иногда multi-source. А кому-то multi-master или частичная репликация очень нравится. Наверное, именно поэтому и существует…
Я попытался понять состояние логической репликации в PostgreSQL и что-то приуныл. Встроенной нет, есть куча сторонних решений (кто сказал «разброд»?): Slony-I (кстати, а где Slony-II?), Bucardo, Londiste, BDR, pgpool 1/2, Logical Decoding, и это ещё не считая мёртвых или проприетарных проектов.
У всех какие-то свои проблемы — какие-то выглядят знакомыми (за них часто критикуют репликацию в MySQL), какие-то выглядят странно для пользователя MySQL. Какая-то тотальная беда с репликацией DDL, которые не поддерживаются даже в Logical Decoding (интересно, почему?).
BDR требует пропатченную версию PostgreSQL (кто сказал «форки»?).
У меня есть некоторые сомнения в производительности. Я уверен, что кто-нибудь в комментариях начнёт объяснять, что репликация на триггерах и скриптах на Perl/Python работает быстро, но я в это поверю, только когда увижу сравнительные нагрузочные тесты с MySQL на том же оборудовании.
Logical Decoding выглядит интересно. Но:
- Это не репликация как таковая, а конструктор/фреймворк/API для создания сторонних решений для логической репликации
- Использование Logical Decoding требует записи дополнительной информации в WAL (требуется установить
wal_level=logical). Привет критикам бинарного журнала в MySQL! - Какие-то из сторонних решений уже переехали на Logical Decoding, а какие-то ещё нет.
- Из чтения документации у меня сложилось впечатление, что это аналог row-based репликации в MySQL, только с кучей ограничений: никакой параллельности в принципе, никаких GTID (как делают клонирование слейва и failover/switchover в сложных топологиях?), каскадная репликация не поддерживается.
- Если я правильно понял эти слайды SQL интерфейс в Logical Decoding использует Poll модель для распространения изменений, а протокол для репликации использует Push модель. Если это действительно так, что происходит при временном выпадении слейва из репликации в Push модели, например из-за проблем с сетью?
- Есть поддержка синхронной репликации, что хорошо. Как насчёт полусинхронной репликации, которая более актуальна в высоконагруженных кластерах?
- Можно выбирать избыточность информации с помощью опции
REPLICA IDENTITYдля таблицы. Это некий аналог переменнойbinlog_row_imageв MySQL. Но переменная в MySQL динамическая, её можно устанавливать отдельно для сессии, или даже отдельно для каждого запроса. Можно ли так в PostgreSQL? - Короче говоря, где можно посмотреть доклад «Асинхронная логическая репликация в PostgreSQL без цензуры»?. Я бы с удовольствием почитал и посмотрел.
Как я уже говорил, я ни на что не претендую в плане знания PostgreSQL. Если что-то из этого неверно, или неточно — дайте мне знать в комментариях и я обязательно подправлю. Также было бы интересно получить ответы на вопросы, которые у меня возникали по ходу.
Но моё впечатление в целом: логическая репликация в PostgreSQL находится на ранних стадиях развития. В MySQL логическая репликация существует давно, все её плюсы, минусы и подводные камни хорошо известны, изучены, обсуждены и показаны на разных докладах. Кроме того она сильно изменилась за последние годы.
Поскольку в этой публикации содержится кое-какая критика PostgreSQL, я прогнозирую очередной взрыв комментариев в стиле: «а вот мы с приятелем вдвоём работали на мускуле и всё было плохо, а теперь работаем на слонике и жизнь наладилась». Я верю. Нет, серьёзно. Но я никого не призываю куда-то переходить или что-либо вообще менять.
Статья преследует две цели:
1) ответ на не вполне корректную критику MySQL и
2) попытка систематизировать многочисленные различия между MySQL и PostgreSQL. Такие сравнения требуют огромного труда, но именно этого от меня часто ожидают в комментариях.
В следующей публикации я собираюсь продолжить сравнения, на этот раз в свете производительности.
