Отзыв на книгу Growing Object-Oriented Software, Guided by Tests
Цель статьи — показать, как использование моков может навредить коду и насколько проще этот же код становится если от моков избавиться. Второстепенная цель — выделить советы из книги, которые личне мне кажутся разумными и те, которые, наоборот, приносят больше вреда, чем пользы. В книге довольно много и тех и других.
Версия на английском: ссылка.
Хорошие части
Начнем с хороших вещей. Большая их часть находится в первых двух секциях книги.
Авторы определяют цель автоматического тестирования как создание «сетки безопасности» (safety net), которая помогает выявлять регрессиии в коде. На мой взгляд, это действительно ниболее важное преимущество, которое дает нам наличие тестов. Safety net помогает достичь уверенности в том, что код работает как положено, что, в свою очередь, позволяет быстро добавлять новый функционал и рефакторить уже имеющийся. Команда становится намного более продуктивной если она уверена, что изменения, вносимые в код, не приводят к поломкам.
Книга также описывает важность настройки deployment environment на ранних стадиях. Это должно стать первоочередной задачей любого нового проекта, т.к. позволяет выявлять потенциальные интеграционные ошибки на ранних стадиях, до того как написано существенное количество кода.
Для этого авторы предлагают начинать со строительства «ходячего скелета» (walking skeleton) — наипростейшей версии приложения, которая в то же время в своей реализации затрагивает все слои приложения. К примеру, если это веб-приложение, скелет может показать простую HTML страницу, которая запрашивает строку из реальной базы данных. Этот скелет должен быть покрыт end-to-end тестом, с которого начнется создание набора тестов (test suite).
Эта техника также позволяет сфокусироваться на развертывании deployment pipeline без уделения повышенного внимания архитектуре приложения.
Книга предлагает двухуровневый цикл TDD:

Другими словами, начинать каждую новую функциональность с end-to-end теста и прокладывать себе путь к успешному прохождению этого теста через обычный цикл red-green-refactor.
End-to-end здесь выступают больше как измерение прогресса. Какие-то из этих тестов могут находиться в «красном» состоянии, т.к. фича еще не реализована, это нормально. Юнит тесты в то же время выступают как сетка безопасности и должны быть зелеными всё время.
Важно чтобы end-to-end тесты затрагивали как можно больше внешних систем, это поможет выявлять интеграционные ошибки. В то же время, авторы признают, что какие-то внешние системы придется заменять на заглушки в любом случае. Вопрос, что включать в end-to-end тесты, должет решаться для каждого проекта отдельно, тут нет универсального ответа.
Книга предлагает расширить классический 3х-шаговый цикл TDD, добавив к нему четвертый шаг: делать сообщение об ошибке более понятным.
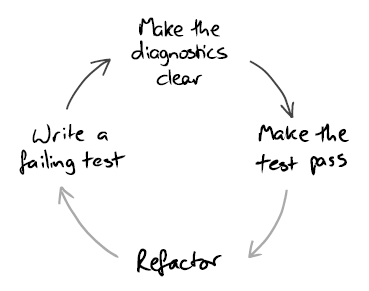
Это поможет убедиться, что если тест падает, вы сможете понять что с ним не так просто взглянув на сообщение об ошибке, не запуская дебагер.
Авторы рекомендуют разрабатывать приложение «вертикальным образом» (end to end) с самого начала. Не тратьте слишком много времени на шлифование архитектуры, начните с какого-то запроса, приходящего извне (к примеру, из UI) и обработайте этот запрос полностью, включая все слои приложения (UI, логика, БД) с минимально возможным количеством кода. Другими словами, не выстраивайте архитектуру заранее.
Еще один отличный совет — тестировать поведение, а не методы. Очень часто это не одно и то же, т.к. единица поведения может затрагивать несколько методов или даже классов.
Другой интересный моммент — рекомендация делать тестируемую систему (system under test, SUT) контексто-независимой:
«Ни один объект не должен иметь представления о системе, в которой он запущен».
Это по сути концепция изоляции модели предметной области (domain model isolation). Доменные классы не должны зависеть от внешних систем. В идеале вы должны иметь возможность полностью вырвать их из текущего окружения и запустить без каких-либо дополнительных усилий. Кроме очевидного преимущества, связанного с лучшей тестируемостью кода, этот метод позволяет упростить ваш код, т.к. вы способны фокусироваться на предметной области не обращая внимание на аспекты, не относящиеся к вашему домену (БД, сеть и т.д.).
Книга является первоисточников довольно известного правила «Замещайте только типы, которыми вы владеете» («Only mock types that you own»). Иными словами, используйте моки только для типов, которые вы написали сами. Иначе вы не сможете гарантировать, что ваши моки корректно моделируют поведение этих типов.
Интересно, что в течение книги авторы сами пару раз нарушают это правило и используют моки для типов из внешних библиотек. Те типы довольно просты, так что там действительно нет особого смысла создавать собственные обертки над ними.
Плохие части
Несмотря на множество ценных советов, книга также дает потенциально вредные рекомендации, и таких рекомендаций довольно много.
Авторы являются сторонниками mockist подхода к юнит тестированию (более подробно о различиях здесь: mockist vs classicist) даже когда речь идет о коммуникации между индивидуальными объектами внутри доменной модели. На мой взгляд, это наибольший недостаток книги, все остальные — следствие из него.
Чтобы обосновать свой подход, авторы приводят определение ООП, данное Аланом Кеем (Alan Kay):
«Главная идея — обмен сообщениями. Ключ к созданию хорошего и расширяемого приложения состоит в дизайне того, как различные его модули коммуницируют друг с другом, а не в том, как они устроены внутри.»
Они затем заключают, что взаимодействия между объектами — это то, на чем вы должны фокусироваться в первую очередь при юнит тестировании. По этой логике, коммуникация между классами — это то, что в итоге делает систему такой, какая она есть.
В этой точке зрения есть две проблемы. Во-первых, определение ООП, данное Аланом Кеем, здесь неуместно. Оно довольно расплывчиво чтобы делать на его основе такие далеко идущие выводы и имеет мало общего с современными ООП языками.
Вот еще одна известная цитата от него:
«Я придумал фразу «объектно-ориентированный», и я не имел ввиду С++».
И конечно, вы можете спокойно заменить здесь С++ на C# или Java.
Вторая проблема с таким подходом заключается в том, что отдельные классы слишком малы (fine-grained) чтобы рассматривать их как независимые коммуникаторы. То, как они общаются между собой, меняется часто и имеет мало общего с конечным результатом, который мы в итоге должны проверять в тестах. Паттерн коммуникации между объектами — это деталь реализации (implementation detail) и становится частью API только когда коммуникация пересекает границы системы: когда ваша доменная модель начинает общаться с внешними сервисами. К сожалению, книга не делает этих различий.
Недостатки подхода, предложенного книгой, становятся очевидными если вы посмотрите на код проекта из 3й главы. Фокус на коммуникациями между объектами не только приводит к хрупким тестам из-за их завязанности на детали имплементации, но и также приводит к переусложненному дизайну с циклическими зависимостями, header интерфейсами и чрезмерным количеством слоев абстракций.
В остальной части статьи, я собираюсь показать как проект из книги может быть модифицирован и какой эффект это имеет на юнит тесты.
Оригинальная кодовая база написана на Java, модифицированная версия — на C#. Я переписал проект полностью, включая юнит тесты, end-to-end тесты, UI и эмулятор для XMPP сервера.
Проект
Прежде чем окунуться в код, давайте посмотрим на предметную область. Проект из книги — Auction Sniper. Бот, который учавствует в аукционах от имени пользователя. Вот его интерфейс:
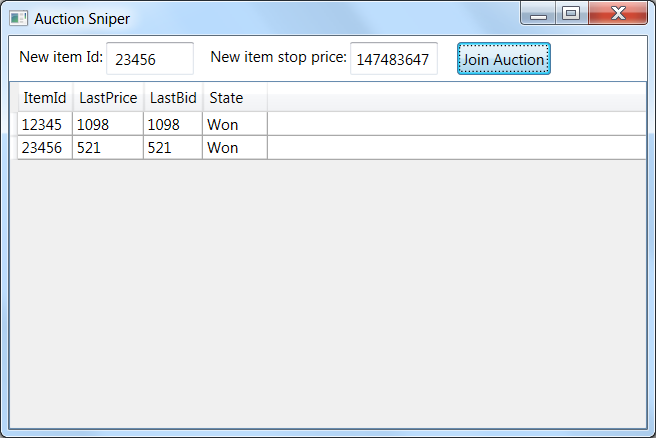
Item Id — идентификатор предмета, который в данный момент продается. Stop Price — максимальная цена, которую вы как пользователь готовы заплатить за него. Last Price — последняя цена, которую вы или другие участники аукциона предложили за этот предмет. Last Bid — последняя цена, которую сделали вы. State — состояние аукциона. На скриншоте выше вы можете видеть, что приложение выиграло оба предмета, вот почему обе цены одинаковы в обоих случаях: они пришли от вашего приложения.
Каждая строка в списке представляет отдельного агента, который слушает сообщения приходящие от сервера и реагирует на них посылая команды в ответ. Бизнес правила можно суммировать следующей картинкой:
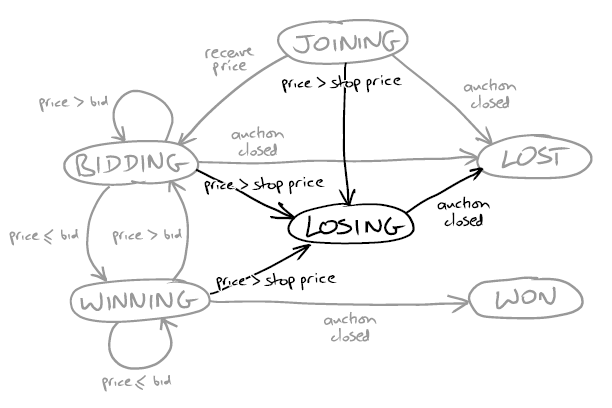
Каждый агент (они также называются Auction Sniper) начинает с верха картинки, в состоянии Joining. Он затем ждет пока сервер пришлет событие с текущим состоянием аукциона — последняя цена, имя пользователя сделавшего ставку и минимальное увеличение цены необходимое для того, чтобы перебить последнюю ставку. Этот тип события называется Price.
Если требуемая ставка меньше чем стоп цена, которую пользователь установил для предмета, приложение отправляет свою ставку (bid) и переходит в состояние Bidding. Если новое Price событие показывает, что наша ставка лидирует, Sniper ничего не предпринимает и переходит в состояние Winning. Наконец, второе событие посылаемое сервером — это Close событие. Когда оно приходит, приложение смотрит в каком статусе оно сейчас находится для этого предмета. Если в Winning, то переходит в Won, все остальные статусы переходят в Lost.
То есть по сути мы имеем бота, который посылает команды серверу и поддерживает внутреннюю state machine.
Давайте посмотрим на архитектуру приложение, предложенного книгой. Вот ее диаграмма (кликните чтобы увеличить):
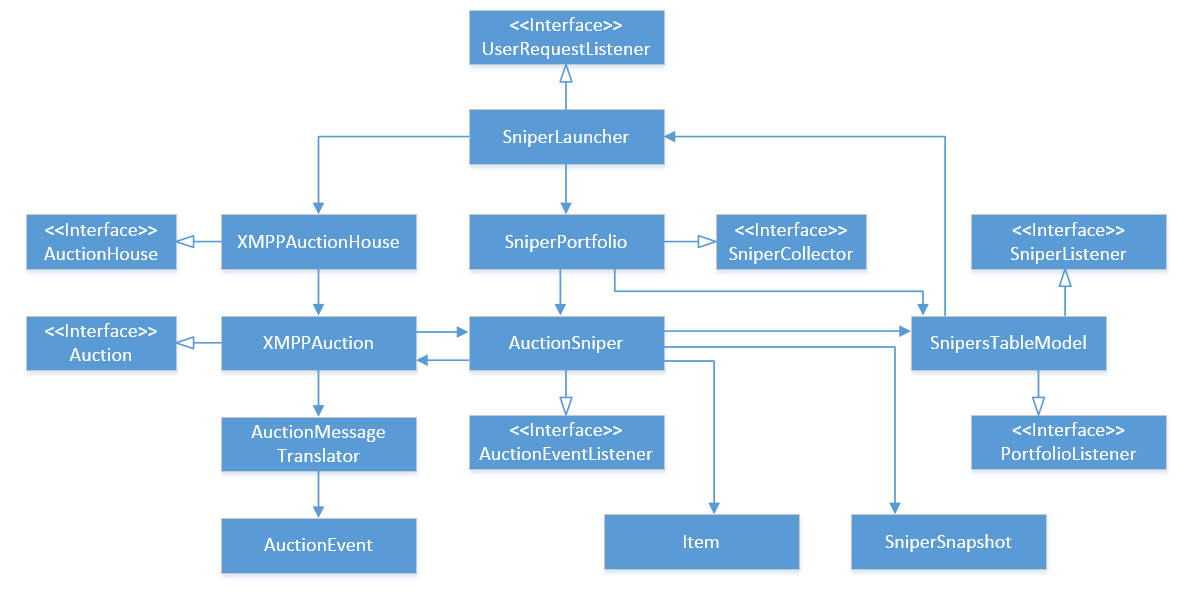
Если вы считаете, что она переусложнена сверх меры для такой простой задачи, это потому что так и есть. Итак, какие проблемы мы видим здесь?
Самое первое замечание, бросающееся в глаза, — большое количество header интерфейсов. Этот термин обозначает интерфейс, который полностью копирует единственный класс имплементирующий этот интерфейс. К примеру, XMPPAuction один к одному соотносится с Auction интерфейсом, AcutionSniper — с AuctionEventListener и так далее. Интерфейсы с единственной имплементацией не являются абстракцией и считаются дизайном «с запашком» (design smell).
Ниже та же диаграмма без интерфейсов. Я убрал их чтобы структура диаграммы стала более понятной.
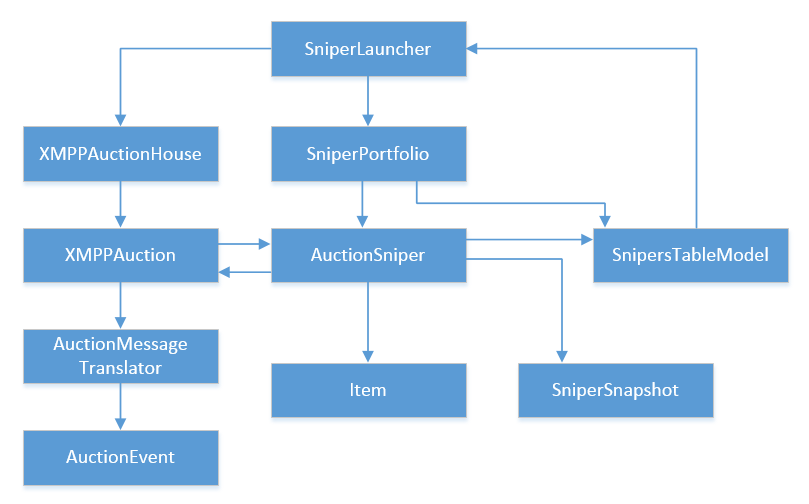
Вторая проблема здесь — циклические зависимости. Наиболее очевидная из них — между XMPPAuction и AuctionSniper, но она не единственная. К примеру, AuctionSniper ссылается на SnipersTableModel, который в свою очередь ссылается на SniperLauncher и так далее пока связь не приходит обратно к AuctionSniper.
Циклические зависимости в коде нагружают наш мозг когда мы пытаемся прочесть и понять этот код. Причина в том, что с подобными зависимостями вы не знаете с чего начать. Чтобы понять назначение одного из классов, вам необходимо поместить в голове целый граф классов, циклически связанных друг с другом.
Даже после того как я полностью переписал код проекта, мне приходилось довольно часто обращаться к диаграммам чтобы понять как различные классы и интерфейсы относятся друг к другу. Мы, люди, хорошо понимаем иерархии, с циклическими графами у нас часто возникают сложности. Scott Wlaschin написал отличную статью на эту тему: Cyclic dependencies are evil.
Третья проблема — отсутствие изоляции доменной модели. Вот как архитектура выглядит с точки зрения DDD:

Классы посередине составляют доменную модель. В то же время, они коммуницируют с сервером аукциона (слева) и с UI (справа). К примеру, SniperLauncher общается с XMPPAuctionHouse, AuctionSniper — с XMPPAcution и SnipersTableModel.
Конечно, они делают это используя интерфейсы, а не реальные классы, но, опять же, добавление в модель header интерфейсов не значит, что вы автоматически начинаете следовать Dependency Inversion принципам.
В идеале доменная модель должна быть самодостаточной, классы внутри нее не должны разговаривать с классами из внешнего мира, ни используя конкретные имплементации, ни их интерфейсы. Надлежащая изоляция означает, что доменная модель может быть протестирована используя функциональный подход без привлечения моков.
Все эти недостатки — это обычное следствие из ситуации, когда разработчики фокусируются на тестировании взаимодействий между классами внутри доменной модели, а не их публичного API. Подобный подход приводит к созданию header интерфейсов, т.к. иначе становится невозможным «замОчить» соседние классы, к большому количеству циклических зависимостей и доменным классами напрямую общающимся с внешним миром.
Давайте теперь взглянем на сами юнит тесты. Вот пример одного из них:
@Test public void reportsLostIfAuctionClosesWhenBidding() {
allowingSniperBidding();
ignoringAuction();
context.checking(new Expectations() {{
atLeast(1).of(sniperListener).sniperStateChanged(
new SniperSnapshot(ITEM_ID, 123, 168, LOST));
when(sniperState.is("bidding”));
}});
sniper.currentPrice(123, 45, PriceSource.FromOtherBidder);
sniper.auctionClosed();
}
Во-первых, этот тест фокусируется на коммуникациях между классами, что приводит к необходимости создавать и поддерживать значительное количество кода, связанного с созданием моков, но это здесь не самое главное. Главный недостаток здесь в том, что этот тест содержит информацию о деталях имплементации тестируемого объекта. Оператор when здесь означает, что тест знает о внутреннем состоянии системы и имитирует это состояние для того чтобы протестировать его.
Вот еще один пример:
private final Mockery context = new Mockery();
private final SniperLauncher launcher =
new SniperLauncher(auctionHouse, sniperCollector);
private final States auctionState =
context.states("auction state”).startsAs("not joined”);
@Test public void
addsNewSniperToCollectorAndThenJoinsAuction() {
final Item item = new Item("item 123”, 456);
context.checking(new Expectations() {{
allowing(auctionHouse).auctionFor(item); will(returnValue(auction));
oneOf(auction).addAuctionEventListener(with(sniperForItem(item)));
when(auctionState.is("not joined”));
oneOf(sniperCollector).addSniper(with(sniperForItem(item)));
when(auctionState.is("not joined”));
one(auction).join(); then(auctionState.is("joined”));
}});
launcher.joinAuction(item);
}
Этот код — четкий пример утечки знаний о деталях имплементации системы. Тест в этом примере реализует полноценную state машину для проверки того, что тестируемый класс вызывает методы своих соседей в конкретно этом порядке (последние три строчки):
public class SniperLauncher implements UserRequestListener {
public void joinAuction(Item item) {
Auction auction = auctionHouse.auctionFor(item);
AuctionSniper sniper = new AuctionSniper(item, auction);
auction.addAuctionEventListener(sniper); // These
collector.addSniper(sniper); // three
auction.join(); // lines
}
}
Из-за высокой связанности с внутренностями тестируемой системы, тесты вроде этого очень хрупки. Любой нетривиальный рефакторинг приведет к их падению незавимисо от того, сломал этот рефакторинг что-либо или нет. Это в свою очередь существенно снижает их ценность, т.к. тесты часто выдают ложные срабатывания и из-за этого перестают восприниматься как часть надежной safety net.
Полный исходный код проекта из книги можно найти здесь: ссылка.
Альтернативная имплементация без использования моков
Всё вышесказанное — довольно серьезные заявления, и, очевидно, мне нужно подкрепить их альтернативным решением. Полный исходный код этого альтернативного решение можно найти здесь.
Для того, чтобы понять как проект может быть имплементирован с надлежащей изоляцией доменной области, без циклических зависимостей и без чрезмерного количества ненужных абстракций, давайте посмотрим на функции приложения. Оно принимает события от сервера и реагирует на них некоторыми командами, поддерживая внутреннюю state машину:

И это по сути всё. В реальности, это практически идеальная функциональная (functional programming) архитектура, и нам ничего не мешает имплементировать ее как таковую.
Вот как выгладит диаграмма альтернативного решения:

Давайте рассмотрим несколько важных отличий. Во-первых, доменная модель полностью изолирована от внешнего мира. Классы в ней не говорят напрямую с view моделью или с XMPP Server, все ссылки направлены к доменным классам, а не наоборот.
Всё общение с внешним миром, будь то сервер или UI, отдано слою Application Services, роль которого в нашем случае выполняет AuctionSniperViewModel. Она выступает как щит, защищающий доменную модель от нежелательного влияния внешнего мира: фильтрует входящие события и интерпретирует выходящие команды.
Во-вторых, доменная модель не содержит циклических зависимостей. Структура классов здесь древовидная, а это означает, что потенциальный новый разработчик имеет четкое место с которого он может начать читать этот код. Он может начать с литьев дерева и переходить выше по дереву шаг за шагом, без необходимости размещать всю диаграмму классов в его голове единовременно. Код из конкретно этого проекта довольно прост, конечно, так что я уверен вы не имели бы проблем с чтением его даже в случае наличия циклических зависимостей. Тем не менее, в более сложных сценариях четкая древовидная структура — большой плюс в плане простоты и читаемости.
Кстати, известный DDD паттерн — Aggregate — нацелен на решение конкретно этой проблемы. Группируя несколько сущностей в единый агрегат, мы уменьшаем количество связей в доменной модели и таким образом делаем код проще.
Третий важный момент здесь — это то, что альтернативная версия не содержит интерфейсов. Это одно из преимуществ наличия полностью изолированной доменной модели: вам просто не нужно привносить в код интерфейсы если они не представляют реальную абстракцию. В данном примере, у нас нет таких абстракций.
Классы в новой имплементации четко разделены по их назначению. Они либо содержат бизнес знание (business knowledge) — это классы внутри доменной модели, — либо общаются с внешним миром — классы вне доменной модели, —, но никогда и то и другое вместе. Подобное разделение обязанностей позволяет нам фокусироваться на одной проблеме в каждый момент времени: мы либо думаем о доменной логике, либо решаем как реагировать на стимулы от UI и сервера аукционов.
Опять же, это упрощает код, а значит делает его более поддерживаемым. Вот как выглядит наиболее важная часть слоя Application Services:
_chat.MessageReceived += ChatMessageRecieved;
private void ChatMessageRecieved(string message)
{
AuctionEvent ev = AuctionEvent.From(message);
AuctionCommand command = _auctionSniper.Process(ev);
if (command != AuctionCommand.None())
{
_chat.SendMessage(command.ToString());
}
}
Здесь мы получаем строку от сервера аукционов, трансформируем ее в event (валидация включена в этот шаг), передаем его снайперу и если результирущая команда не None, посылаем ее обратно серверу. Как можете видеть, отсутствие бизнес-логики делает слой Application Services тривиальным.
Тесты без моков
Другое преимущество изолированной доменной модели — это возможность протестировать ее используя функциональный подход. Мы можем рассматривать каждую часть поведения в изоляции друг от друга и проверять конечный результат, который она генерирует, без уделения внимания тому, как именно этот результат был достигнут.
К примеру, следующий тест проверяет как Sniper, только что присоединившийся к аукциону, реагирует на получение события Close:
[Fact]
public void Joining_sniper_loses_when_auction_closes()
{
var sniper = new AuctionSniper("”, 200);
AuctionCommand command = sniper.Process(AuctionEvent.Close());
command.ShouldEqual(AuctionCommand.None());
sniper.StateShouldBe(SniperState.Lost, 0, 0);
}
Он проверяет, что результирующая команда пуста, что означает sniper не предпринимает никаких действий, и что состояние становится Lost после этого.
Вот еще пример:
[Fact]
public void Sniper_bids_when_price_event_with_a_different_bidder_arrives()
{
var sniper = new AuctionSniper("”, 200);
AuctionCommand command = sniper.Process(AuctionEvent.Price(1, 2, "some bidder”));
command.ShouldEqual(AuctionCommand.Bid(3));
sniper.StateShouldBe(SniperState.Bidding, 1, 3);
}
Этот тест проверяет, что снайпер отправляет заявку когда текущая цена и минимальный инкремент меньше чем установленный ценовой предел.
Единственное место, где моки могут потенциально быть оправданы — при тестировании слоя Application Services, который коммуницирует с внешними системами. Но эта часть покрыта end-to-end тестами, так что в данном конкретном случае в этом нет необходимости. Кстати, end-to-end тесты в книге великолепны, я не нашел ничего что можно было бы в них изменить или улучшить.
Исходный код альтернативной имплементации можно найти здесь.
Заключение
Фокус на коммуникациях между отдельными классами приводит к хрупким тестам, а также к ущербу самой архитектуре проекта.
Чтобы избежать этих недостатков:
- Не создавайте header интерфейсов для доменных классов.
- Минимизируйте количество циклических зависимостей в коде.
- Изолируйте доменную модель: не позволяйте доменным классам коммуницировать с внешним миром.
- Уменьшайте количество ненужных абстракций.
- Делайте упор на провеке состояния и конечного результата при тестировании доменной модели, не коммуникациях между классами.
Pluralsight курс
У меня только что вышел новый курс на Pluralsight на тему прагматичного юнит тестирования. В нем я попытался рассказать о практиках построения юнит тестов, приводящих к наилучшему результату с наименьшими усилиями. Гайдлайны из статьи выше стали частью этого курса и рассмотрены в нем детально, с приведением множества примеров.
У меня также есть несколько десятков триальных кодов, которые дают неограниченный доступ к Pluralsight сроком на 30 дней (ко всей библиотеке, не только моему курсу). Если кому-то нужен — пишите в личку, с удовольствием поделюсь.
Ссылка на курс: Building a Pragmatic Unit Test Suite.
