Открытый вебинар «Как не нужно писать на Python»
Всем привет! В рамках нашего курса «Разработчик Python» мы провели ещё один открытый урок на тему «Как не нужно писать на Python». Занятие вёл преподаватель и создатель курса Станислав Ступников, имеющий большой опыт промышленной и научной разработки. Рассматривались антипаттерны программирования, bad practice и прочее зло, о котором нужно знать и которого следует избегать в процессе написания кода.
В процессе проведения открытого урока преподаватель показывал слайды, сгенерированные с Jupyter Notebook.
Было ещё много чего интересного, поэтому лучше посмотрите видео, т.к. пересказ всё же кортковат.
Подробности смотрите в видео и кратком изложении. Внимание: некоторые примеры кода не рекомендуется запускать на своём компьютере!
В процессе проведения открытого урока преподаватель показывал слайды, сгенерированные с Jupyter Notebook.
Итак, начнём!
Так как же не стоит писать на Python?
В целях удобства подачи материала был подготовлен список приёмов, которые не стоит применять в процессе программирования. Каждый пример сопровождался наглядным образцом кода (доступен для свободного просмотра в видео). Вкратце опишем основные антипаттерны:
- Diaper pattern. Речь шла о так называемом паттерне «подгузника», под которым обычно подразумевается слишком широкий try-except. Например, вы вызываете функцию, которая является обёрткой к чему-нибудь, допустим, оборачивает клиентскую либу для какой-то базы. В хорошем случае (система маленькая) всё будет нормально в 99% случаев, но если система большая, то вероятности возникновения проблемы умножаются не самым хорошим образом. В итоге постоянно что-то падает или ломается.
- Antiglobalism. Всем известно, что глобальные переменные неэффективны, кроме каких-нибудь исключительных случаев. Гораздо лучше всё передавать в виде атрибутов функции и т. д., и т. п., добиваясь нужных результатов. Однако некоторым приходит в голову «отличная идея» — использовать изменяемые объекты. Она заключается в том, чтобы передавать в функции не глобальные переменные, а изменяемые объекты, после чего изменять их внутри и потом ничего назад не возвращать. Это же так круто!) По сути, кусочек шаблона программирования из языка С, перенесённый в мир Python.
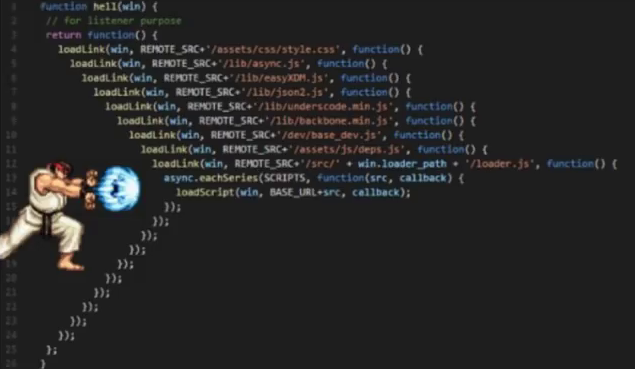
- Stairway to Heaven. Как вы уже догадались, это «лестница в небо». Лучше всего данную проблему характеризует простая картинка:
- Javatar. Ошибки этого плана часто делают те программисты, которые по тем либо иным причинам перешли с Java на Python. Естественно, они приходят со своим уставом, поэтому массово нарушают правила разработки Python. Это и появление безумных отступов, и CamelCase, и стремление создать побольше классов… В итоге структура кода усложняется. Там, где можно было бы обойтись скриптом размером в 300 строк, мы видим 10–20 файлов.
- Overengineering. Очень часто вторая итерация какого-нибудь проекта либо никогда не завершается либо реализуется слишком сложным способом. Такое бывает, если вы хотите переписать уже существующий, но имеющий недостатки код, сделав его идеальным. При этом забываете о том, что лучшее — враг хорошего. В результате программист попадает в стандартную ловушку переинжиниринга, когда реализация становится более дорогой, тяжёлой и громоздкой, чем это необходимо для решения поставленных задач. И в самом деле: должны ли семейные седаны развивать скорость до 350 км/ч, а смартфоны, мода на которые меняется ежегодно, работать в течение 100 лет?
- Oneliner. Очередная актуальная проблема — «однострочники». Речь о программистах, которые с завидным усердием пытаются всё запихнуть в одну строку, этажей эдак в пять)). Из-за избыточной сложности кода и особенностей реализации машинорегулярных выражений в Python такие скрипты иногда «залипают» на парсинге, поэтому для устранения проблемы приходится использовать специальный модуль.
- Copy-on-Read. Это не столько ошибка, сколько особенность программирования на Python. Многим знаком подход Copy-On-Write. Его идея заключается в том, что при чтении какой-либо области данных используется общая копия, а при изменении создаётся новая копия, то есть речь идёт об оптимизации процессов производительности. Если говорить о Python, то в некоторых случаях мы не просто читаем массив из элементов, а обращаемся ко всем нижележащим структурам, которые находятся в памяти, то есть «перезаписываем» память, меняя её. Таким образом вместо Copy-On-Write у нас получается Copy-on-Read, когда мы как будто бы читаем память, однако на самом деле нам приходится копировать дочерним процессом эту информацию из родительского пространства к себе, от чего становится грустно, так как подход по оптимизации не работает, а потребление вырастает.
- There is no fork. Fork — клонирование появления нового процесса. Проблема связана со спецификой работы с Unix-системами и неочевидностями некоторых структур данных, которые скрыты в имплементации. Под «форкнутым» процессом понимается процесс, который запускается в тот момент, когда тред захватил лог в очереди, чтобы в него что-нибудь положить. То есть возникший новый процесс тоже хочет кое-что записать, но для этого ему нужно захватить лог из этой самой очереди, но он не может этого сделать, так как лог уже захвачен. В результате мы получаем блокировку. Всё это лишь в очередной раз подтверждает то, что не стоит программировать, не зная особенностей имплементации среды, в которой работаете и инструментов, которые используете.
Было ещё много чего интересного, поэтому лучше посмотрите видео, т.к. пересказ всё же кортковат.
Как всегда, ждём вопросы, комментарии и пожелания тут или на дне открытых дверей.
