Открытый урок «Feature Engineering на примере классического датасета Титаника»
И снова привет!
В декабре у нас стартует обучение очередной группы «Data scientist», поэтому открытых уроков и прочих активностей становится всё больше. Например, буквально на днях прошёл вебинар под длинным названием «Feature Engineering на примере классического датасета Титаника». Его провёл Александр Сизов — опытный разработчик, кандидат технических наук, эксперт по Machine/Deep learning и участник различных коммерческих международных проектов, связанных с искусственным интеллектом и анализом данных.
Открытый урок занял около полутора часов. В ходе вебинара преподаватель рассказал про подбор признаков, преобразование исходных данных (кодирование, масштабирование), настройку параметров, обучение модели и много чего ещё. В процессе проведения урока участникам показывалась тетрадь Jupyter Notebook. Для работы использовались открытые данные с платформы Kaggle (классический датасет про «Титаник», с которого многие начинают знакомство с Data Science). Ниже предлагаем видео и транскрипт прошедшего мероприятия.
Подбор признаков
Тему выбрали хоть и классическую, но всё же немного мрачноватую. В частности, необходимо было решить задачу бинарной классификации и предсказать по имеющимся данным, выживет пассажир или нет. Сами данные были разбиты на две выборки Training и Test. Ключевая переменная — Survival (выжил/не выжил; 0 = No, 1 = Yes).
Входные тренировочные данные:
- класс билета;
- возраст и пол пассажира;
- семейное положение (есть ли на борту родственники);
- стоимость билета;
- номер каюты;
- порт посадки.
Как видим, типы переменных разные: числовые, текстовые. Из этого калейдоскопа и нужно было сформировать датасет для предстоящего обучения модели.
Резюмируем:
- train.csv — training set — тренировочный набор данных. В них известен ответ — survival — бинарный признак 0 (не выжил)/1 (выжил);
- test.csv — test set — тестовый набор данных. Ответ неизвестен. Это выборка для отправки на платформу kaggle для вычисления метрики качества модели;
- gender_submission.csv — пример формата данных, которые нужно отправить на kaggle.
Алгоритм работы
- Работа проходила поэтапно:
- Анализ данных из train.csv.
- Обработка отсутствующих значений.
- Масштабирование.
- Кодирование категориальных признаков.
- Построение модели и подбор параметров, выбор наилучшей модели на преобразованных данных из train.csv.
- Фиксация метода преобразований и модель.
- Применение тех же самых преобразований на test.csv с помощью pipeline.
- Применение модели на test.csv.
- Сохранение в файл результата применения в таком же формате, как и в gender_submission.csv.
- Отправка результатов на платформу kaggle.
Практическая часть вебинара
Первое, что необходимо было сделать, — это прочитать датасет и вывести наши данные на экран:
Для анализа данных использовалась малоизвестная, но довольно полезная библиотека profiling: pandas_profiling.ProfileReport(df_train)
Подробнее о profiling
Эта библиотека делает всё, что можно сделать априори, не зная подробностей о данных. Например, вывести статистики по данным (сколько переменных и какого они типа, сколько строк, пропущенных значений и т. д.). Мало того, даётся отдельная статистика по каждой переменной с приведением минимума и максимума, графика распределения и других параметров.
Как известно, чтобы сделать хорошую модель, нужно вникнуть в процесс, который мы пытаемся моделировать, и понять, какие признаки являются ключевыми. Причём далеко не всегда в наших данных есть всё, что нужно, а, точнее говоря, почти никогда в них нет всего необходимого, полностью определяющего и детерминирующего наш процесс. Как правило, нам всегда нужно что-либо комбинировать, возможно, добавлять дополнительные признаки, не представленные в датасете (допустим, прогноз погоды). Именно для понимания процесса и нужен анализ данных, который можно сделать с помощью библиотеки profiling.
Отсутствующие значения
Следующий этап — решить проблему отсутствующих значений, ведь в большинстве случаев данные заполнены не полностью.
Существуют следующие варианты решения этой проблемы:
- удалить строки с отсутствующими значениями (нужно учитывать, что можно потерять некоторые важные значения);
- удалить признак (актуально, если данных по нему слишком мало);
- заменить отсутствующие значения на что-либо другое (медиана, среднее…).
Пример нехитрого преобразования с помощью метода fillna, который присваивает значения переменной медианы только тем ячейкам, которые не заполнены:

Кроме того, преподаватель показал примеры использования Imputer и pipeline.
Масштабирование признаков
Работа модели и итоговое решение зависят от масштаба признаков. Дело в том, что не факт, что какой-либо признак, у которого масштаб больше, важнее признака, у которого масштаб меньше. Именно поэтому модели нужно подавать признаки, масштабированные одинаково, то есть имеющие одинаковый вес для модели.
Существуют разные техники масштабирования, однако формат открытого урока позволил подробнее рассмотреть только две из них:

Комбинации признаков
Комбинации существующих признаков с помощью арифметических операций (суммы, умножения, деления) позволяют получать какой-либо признак, делающий модель более эффективной. Не всегда это удаётся, и мы не знаем, какая комбинация даст нужный эффект, однако практика показывает, что пробовать имеет смысл. Применять преобразования признаков удобно с помощью pipeline.
Кодирование
Итак, у нас есть данные разных типов: числовые и текстовые. На текущий момент большинство моделей, существующих на рынке, не могут работать с текстовыми данными. В результате все категориальные признаки (текстовые) должны быть преобразованы в числовое представление, для чего используется кодирование.
Label encoding. Это механизм, реализованный в рамках многих библиотек, который можно вызвать и применить:

Label encoding присваивает каждому уникальному значению какой-то уникальный идентификатор. Минус — мы вносим упорядоченность в некую переменную, которая не была упорядоченной, что не есть хорошо.
OneHotEncoder. Уникальные значения текстовой переменной разворачиваются в виде столбцов, которые добавляются в исходные данные, где каждый столбец — бинарная переменная в виде 0 и 1. Этот подход лишён недостатков Label encoding, но имеет свой минус: если уникальных значений много, мы добавляем слишком большое количество столбцов и в некоторых случаях метод просто неприменим (датасет возрастает слишком сильно).
Обучение модели
После выполнения вышеописанных действий составляется итоговый pipeline с набором всех нужных операций. Теперь достаточно взять исходный датасет и применить итоговый pipeline на этих данных с помощью операции fit_transform: x_train = vec.fit_transform(df_train)
В итоге получаем датасет x_train, который готов для применения в модели. Единственное, что нужно сделать, — отделить значение нашей целевой переменной, чтобы можно было провести обучение.
Далее выбирается модель. В рамках вебинара преподаватель предложил простую логистическую регрессию. Обучение модели происходило с помощью операции fit, в результате чего получилась модель в виде логистической регрессии с определёнными параметрами:
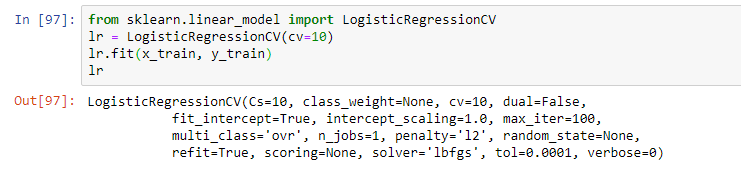
При этом на практике обычно используется несколько моделей, которые кажутся наиболее эффективными. И итоговым решением зачастую является комбинация этих моделей с помощью техник стекинга и прочих подходов к ансамблированию моделей (использованию нескольких моделей в рамках одной гибридной модели).
После обучения модель можно применять на тестовых данных, оценивая её качество в рамках какой-нибудь метрики. В нашем случае качество в рамках accuracy_score было 0,8:

Это значит, что на полученных данных переменная правильно предсказана в 80% случаев. Получив результаты обучения, мы можем либо улучшать модель (если точность не устраивает), либо переходить непосредственно к прогнозу.
На этом была закончена основная тема урока, но преподаватель ещё подробно рассказал об особенностях применения модели в разных задачах и отвечал на вопросы слушателей. Так что если вы не хотите ничего пропустить, посмотрите вебинар полностью, если данная тема вам интересна.
Как всегда ждём ваши комментарии и вопросы, которые вы можете оставить тут или позадавать их Александру, зайдя к нему на день открытых дверей.
