Отказоустойчивая архитектура контентной платформы на 4 Тбит/с — опыт VK Видео
Представьте идеальный мир с бесконечными ресурсами, в котором можно сколько угодно линейно масштабироваться под нагрузку: просто доставлять серверы, диски, видеокарты, как только потребуется больше мощностей. Звучит хорошо? Только оказывается, что когда серверов 5 000 и дисков 100 000, то несколько из них обязательно находятся в состоянии maintenance или repair, куда их привели обстоятельства непреодолимой силы. И главная задача здесь — обеспечить доступность сервиса в условиях постоянных сбоев.
В статье разберём, как построить отказоустойчивую платформу, с какими неочевидными corner cases может столкнуться сервис с UGC-контентом, а ещё — как жить в реальном, а не идеальном мире и оптимизировать железо. Чтобы раздавать 4 Тбит/с можно, конечно, использовать 400 серверов по 10 Гбит/с, но гораздо интереснее грамотно всё потюнить и выжать 100 Гбит/с с Java-сервера.

Рассмотрим отказоустойчивую загрузку, хранение и доставку контента на примере VK Видео — масштабной платформы, которая объединяет видео из ВКонтакте, Одноклассников и VK Клипов, а также видеосвязь в VK Звонках. Это крупнейший видеоресурс в России по аудитории и просмотрам: цифры ниже показывают, что нагрузки у нас действительно высокие. А то, что платформа единая, добавляет проблем — скоро объясню почему.

Далее в статье:
Что значит высокая доступность
Когда речь заходит о доступности сервиса (в смысле availability, а не accessibility), на ум сразу приходят «девятки».
Availability % | Downtime за год |
99% | 3 дня 15 часов 36 минут |
99,9% | 8 часов 46 минут |
99,95% | 4 часа 23 минуты |
99,99% | 52 минут 36 секунд |
99,999% | 5 минут 15 секунд |
99,9999% | 31,6 секунды |
Круто иметь доступность «пять девяток». Это значит, что суммарное время простоя должно не превышать 0,001%, то есть 5 минут и 15 секунд за год.
Но как оценить доступность (или недоступность) системы не постфактум, а исходя из расчётных характеристик её узлов? Это можно сделать через две величины: MTBF (Mean Time Between Failure) — среднее время между отказами; и MTTR (Mean Time To Repair) — среднее время до восстановления работоспособности.
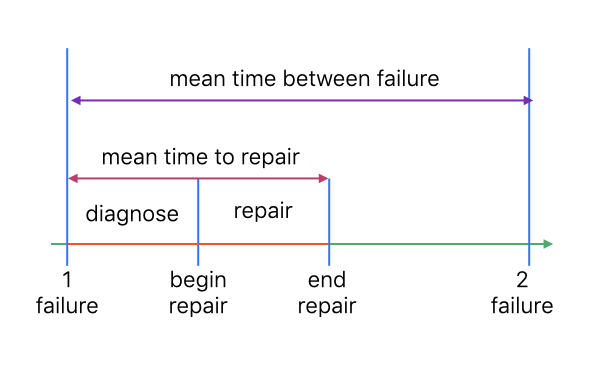
Чтобы доступность была высокой, система должна как можно реже падать, а техническая команда — быстро обнаруживать проблемы с помощью всевозможных мониторингов и тут же их исправлять. То есть availability можно выразить простой формулой:
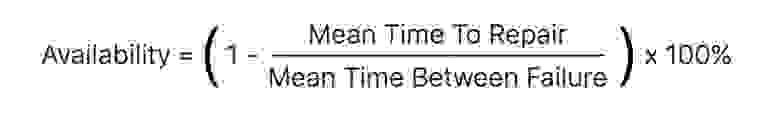
Тогда общую доступность, например, одного сервера можно рассчитать из заявленной надёжности отдельных компонентов. Именно показателями надёжности (и, соответственно, ценой), как правило, и отличаются железки для домашнего и промышленного использования.
Рассмотрим на примере расчёта для сервера с минимальным дублированием (в разных конфигурациях и с более современными комплектующими конкретные значения могут отличаться, но сейчас нас интересуют порядки).
Компоненты сервера | Заявленное MTBF (часов) | Заявленное MTBF (лет) | Вероятность отказа в течение года | Количество компонентов в сервере | Вероятность отказа с учётом дублирования |
Блок питания | 90 000 | 10,27 | 0,0973 | 2 | 0,0000519 |
Системная плата | 300 000 | 34,25 | 0,0292 | 1 | 0,0292 |
Процессор | 1 000 000 | 114,16 | 0,0087 | 1 | 0,00876 |
RAM, модуль | 1 000 000 | 114,16 | 0,0087 | 1 | 0,00876 |
Жёсткий диск | 400 000 | 45,66 | 0,0219 | 2 | 0,0000026 |
Вентилятор | 100 000 | 11,42 | 0,0876 | 2 | 0,0000420 |
Контроллер HDD | 300 000 | 34,25 | 0,0292 | 1 | 0,0292 |
Тогда MTBF сервера будет равно 57 632 часам или 6,579 годам, а вероятность отказа в течение года будет ≈0,152.
Предположим, что MTTR — время восстановления после аварии — равно 2 часам. Оно, кстати, зависит и от мониторингов, и от процессов, а бывает, что и от того, как быстро бегают инженеры в датацентре. Итак, если MTTR = 2, то availability = (1 — 2 / 57632) * 100% = 99,996%. Неплохо, но это уже не «пять девяток» для одного сервера. А сервер стоит в дата-центре, у которого, в свою очередь, есть заявленная доступность.
Уровень | Downtime (часов за год) | Availability % |
Tier I | 28,8 | 99,671 |
Tier II | 22 | 99,741 |
Tier III | 1,6 | 99,982 |
Tier IV | 0,4 | 99,995 |
Доступность сервера умножается на доступность дата-центра — и, допустим, для Tier III уже остаётся 99,978% availability одного сервера в дата-центре. И это мы ещё не начали говорить о нагрузках и многих серверах.
Когда у вас платформа на 5 000 серверов, расположенных в разных дата-центрах, то их одновременная доступность будет всего ≈80%. То есть 20% времени что-то будет не работать.
Наша задача в том, чтобы минимизировать (а лучше — свести на нет) влияние отказов отдельных компонентов и серверов на общую работоспособность сервиса.
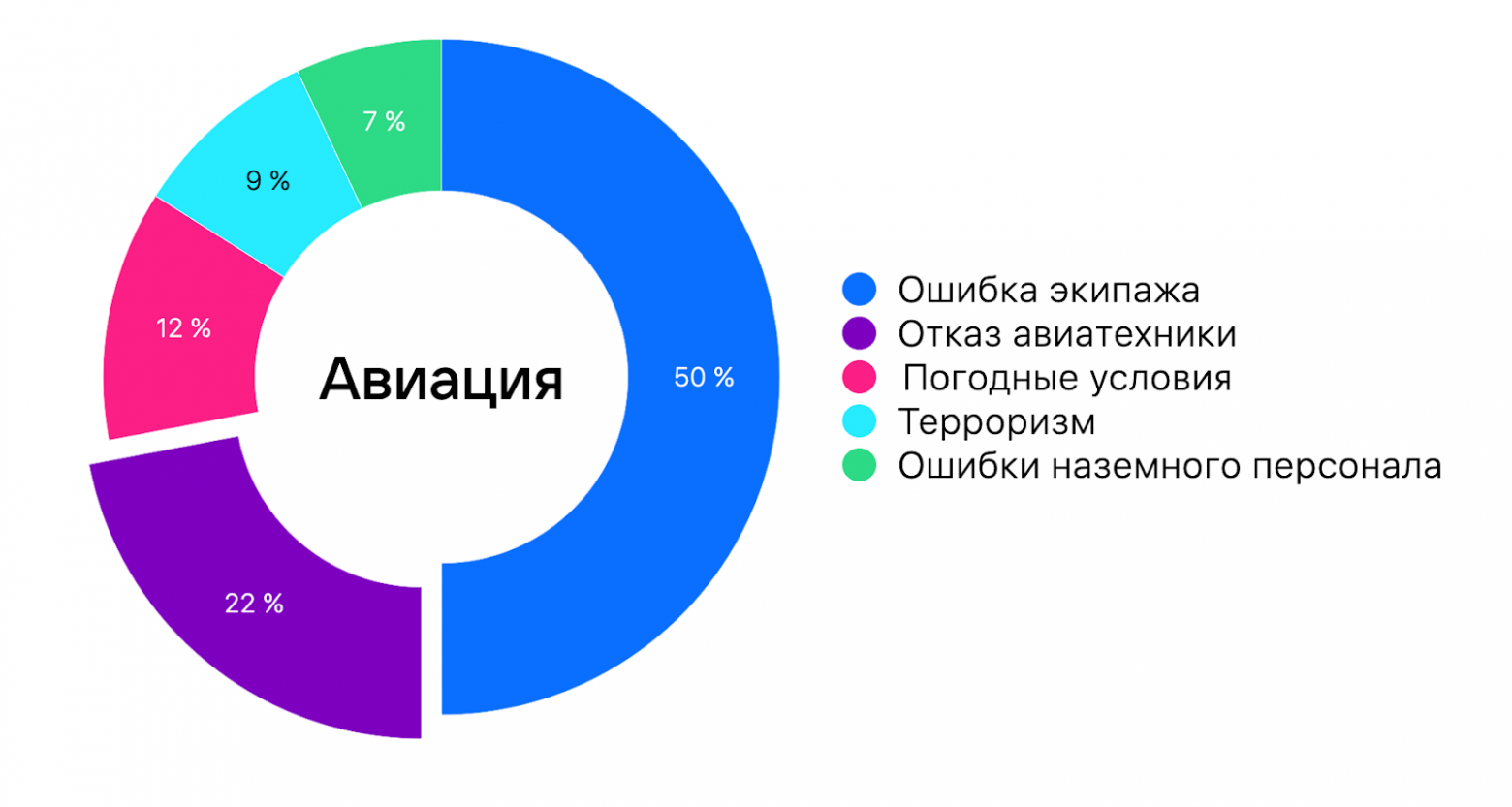
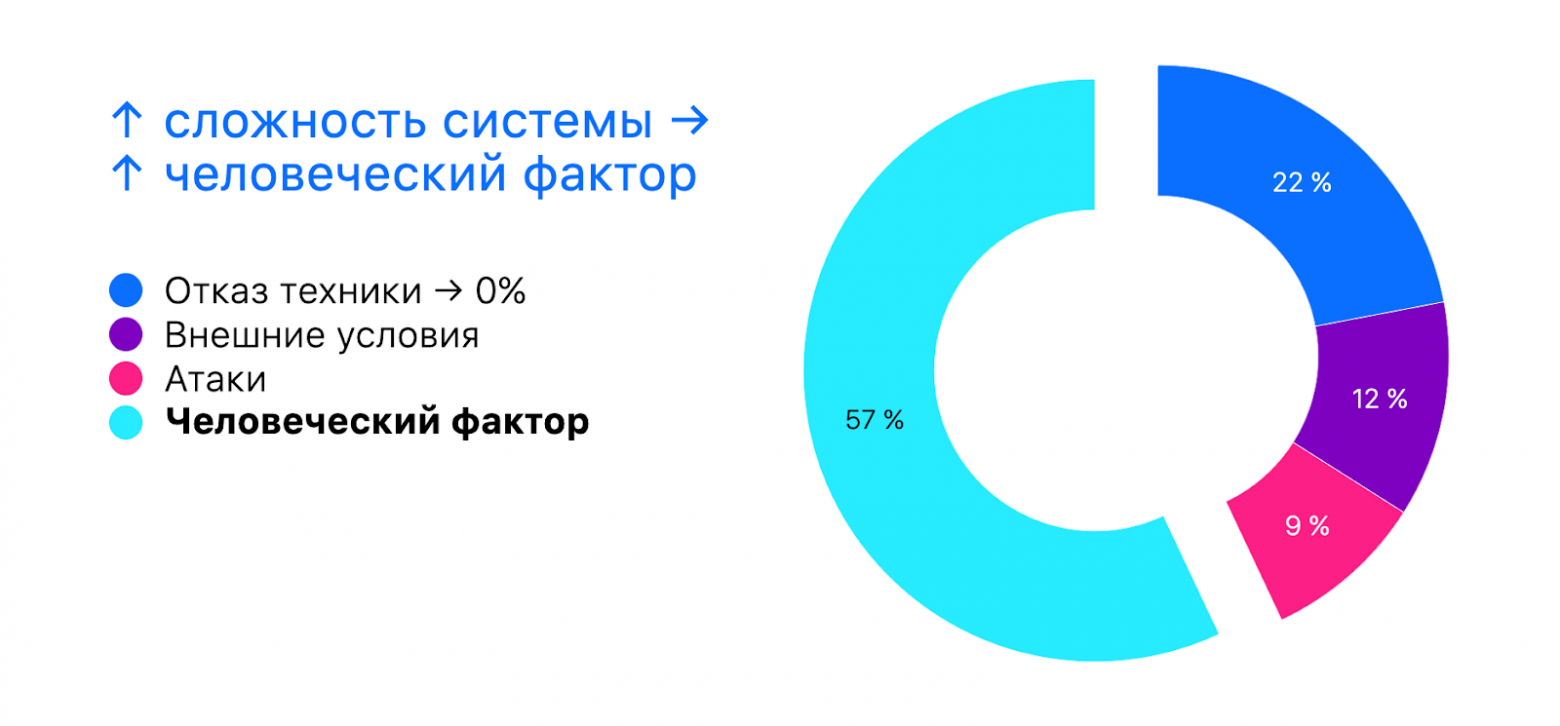
Но железо — это только часть проблем. Причиной аварий также может быть ПО и человеческий фактор, MTBF которого гораздо труднее определить. Из-за того, что компании редко раскрывают причины аварий и публикуют постмортемы, остаётся только догадываться, что привело к отказу: DDoS, атака или обычная ошибка. Однако опросы и косвенные исследования показывают, что от 22 до 75% аварий вызвано человеческим фактором (например, об этом пишут в исследованиях Ponemon Institute «Cost of Data Center Outages» и Uptime Institute).
Эти оценки хорошо согласуются со статистикой из авиации. Там причины происшествий всегда обнародуются, и в половине случаев это человеческий фактор. Отказ техники — то есть железа, если переводить на наши термины, — 22%, а терроризм — как DDoS и другие атаки для нас — 9%.
High Availability (доступность) vs Fault Tolerance (отказоустойчивость)
Говоря о доступности высоконагруженного сервиса, нельзя не затронуть понятие отказоустойчивости. В чём разница:
высокая доступность — свойство системы быть защищённой и быстро восстанавливаться после простоев; при этом высокодоступная система стремится как можно реже сталкиваться с простоями — как запланированными, так и форс-мажорными;
отказоустойчивость — свойство системы продолжать нормально работать в случае отказа одного или нескольких элементов, то есть отказоустойчивая система не допускает простоев.
High Availability — это когда вы не выходите за рамки SLA в случае аварии и допускаете запланированные остановки в работе сервиса. Аналогия: когда водоканал предупредил жителей, что воды не будет две недели, а внеплановых аварий не было или было мало — это всё ещё можно считать высокой доступностью. А если у вас есть несколько источников горячей воды и волшебный кран, который переключится на бойлер так, что вы ничего и не заметите, — это отказоустойчивость.

Для обеспечения High Availability нужно всегда иметь ресурсы на резервирование и масштабирование. Это может быть дорого, но позволит избежать больших простоев, так как переключиться обычно быстрее, чем полностью устранять проблемы. Отказоустойчивость подразумевает отсутствие простоев — так что всё должно быть зарезервировано в каждый момент времени, чтобы в любую секунду можно было перенаправить трафик. Это, естественно, ещё дороже.
Мы в VK Видео фокусируемся на построении отказоустойчивой системы.
Проблема единых платформ
Как у всех уважаемых крупных компаний, ещё недавно по разным проектам VK было пять видеоплатформ со своими решениями для транскодирования, хранения и воспроизведения видео. В 2021 году мы объединили инфраструктуру и технологии для видео ВКонтакте, Одноклассников, VK Клипов и VK Звонков в одну платформу — VK Видео. Прямо как одна другая компания с синей социальной сетью.

В чём проблема такого объединения? Допустим, в другой системе сервисы не сильно зависят друг от друга и пользователи могут решить свои задачи с помощью одного из них. Тогда, если какой-то сервис приляжет, люди расстроятся, но не сильно. Но если у сервисов есть общая инфраструктура — например, единая авторизация, — то проблемы одного задевают соседние и утягивают за собой всех. И это уже замечают все пользователи, СМИ строчат заметки, а в соцсетях ещё долго припоминают ненадёжность.
Когда у Google случился сбой в системе аутентификации, это задело YouTube, Gmail, Google Docs, Google Drive, Google Play, Google Meet и другие ресурсы. Заметили почти все владельцы Android, а итоговая availability упала до 99,99%.
Today [December 14, 2020], at 3:47 AM PT Google experienced an authentication system outage for approximately 45 minutes due to an internal storage quota issue. Services requiring users to log in experienced high error rates during this period. The authentication system issue was resolved at 4:32 AM PT.
Или случай с одной зарубежной социальной сетью: её падение в октябре 2021-го затронуло все сервисы компании, продолжалось шесть часов и снизило доступность за год до 99,93%. А заодно породило кучу статей с разборами и других материалов на тему BGP-протокола — например, я участвовал в подкасте по горячим следам.
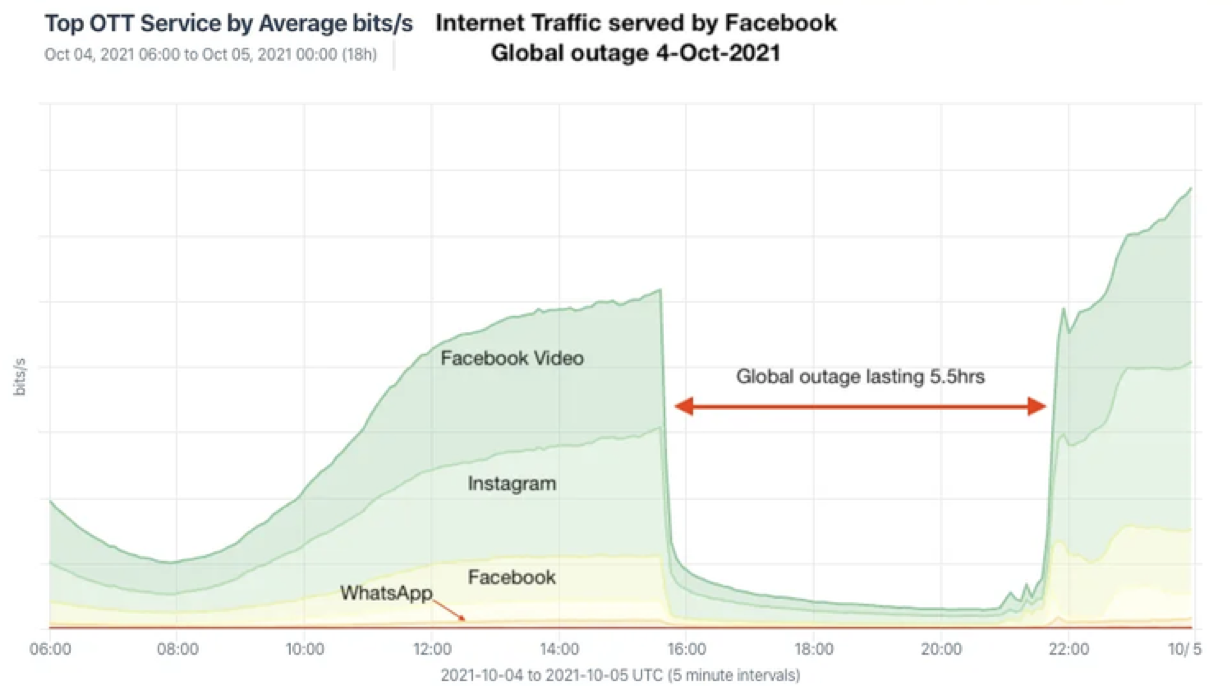 en.wikipedia.org/wiki/2021_Facebook_outage
en.wikipedia.org/wiki/2021_Facebook_outage
У нас тоже, к сожалению, случаются сбои — и реакция в СМИ не заставляет себя ждать.
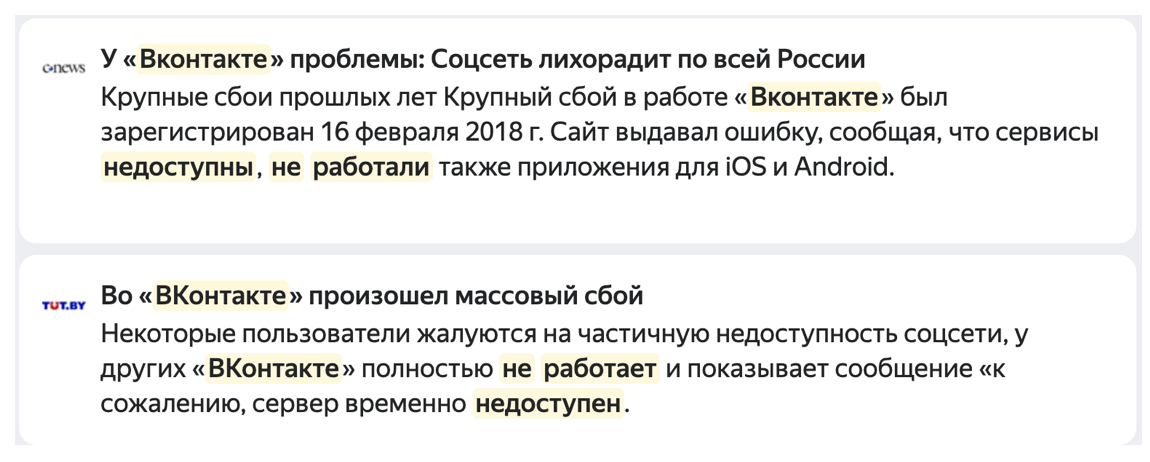
В субботу других новостей, видимо, не было — и о том, как ВКонтакте была недоступна 15 минут, не написал только ленивый. Падение — это не только прямые убытки, но и урон репутации. Поэтому мы, как и все крупные сервисы, действуем комплексно. Стараемся, с одной стороны, увеличивать mean time between failure с помощью тестирования, canary deployment и других практик отказоустойчивости. С другой, стремимся сокращать время реакции на инцидент и на восстановление.
Мы разобрали эти 15 минут по секундам, чтобы понять, где можем ускориться. Теперь обнаруживаем проблему за 10 секунд: агрегируем по 5 секунд и сравниваем, всё ли в порядке. Ещё 5–7 минут нам нужно, чтобы собрать и задеплоить фикс на 10 000 серверов. И мы продолжаем искать возможности подниматься ещё быстрее.
Архитектура высоконагруженной системы
«Любая работающая сложная система развивается на базе работающей простой системы. (…) Сложные системы, созданные с нуля, никогда не будут работать в реальном мире, поскольку в процессе разработки на них не влияли факторы отбора, присущие среде».
Джон Галл, исследователь в области общей теории систем и системного анализа
VK Видео соответствует этому утверждению — и, развивая платформу, мы стараемся сохранять простоту её архитектуры.
Архитектура VK Видео похожа на архитектуру любого контентного сервиса. Она состоит всего из нескольких блоков: контент нужно загрузить в систему; преобразовать в удобные для хранения и раздачи форматы — будь то фото, видео или файлы; сохранить в хранилище; доставить пользователям; плюс обычно ещё и показать.
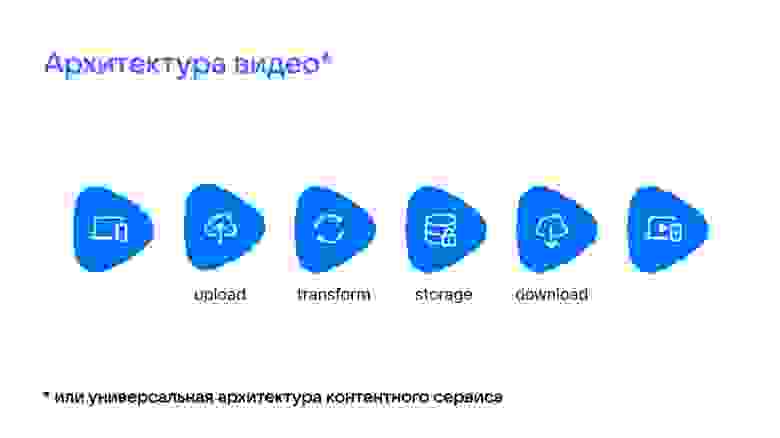
Upload (загрузка)
Загрузка файлов от пользователя на серверы компании обязательно должна быть отказоустойчивой и восстанавливаться после любых прерываний: неважно, произошли они на стороне сервера, клиента или в сети.
Загрузку можно реализовать на базе open-source компонентов: использовать библиотеку tus (open protocol for resumable file uploads), на всякий случай поставить на несколько серверов и привязать к распределённому S3-хранилищу. Возможно, это потребует доработок для обеспечения высочайшего качества сервиса, зато доступно для всех клиентов и быстро в реализации.
Наше решение в целом использует похожий подход, но мы написали его сами почти десять лет назад, когда готовых инструментов не было. Серверы распределены по нескольким дата-центрам. Через DNS GLSB URL загрузки резолвится на один из дата-центров, внутри него балансировщик направляет загрузку на конкретный сервер, а дальше данные сохраняются в распределённое хранилище.
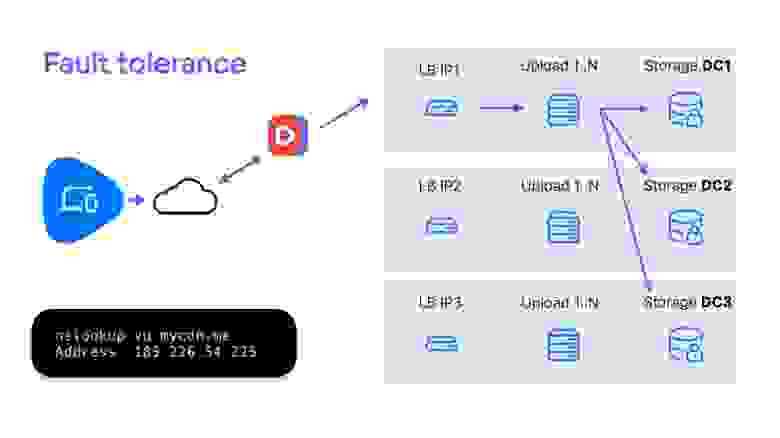
В случае технических работ и недоступности части серверов внутри дата-центра балансировщик перенаправит загрузку на оставшиеся — так, что это будет абсолютно незаметно для пользователя.
Если из строя выйдет целый дата-центр (тьфу-тьфу-тьфу), DNS GSLB перекинет процесс на другой дата-центр. В принципе, это уже не Fault Tolerance, а High Availability. Для полной отказоустойчивости нужно было бы постоянно держать два соединения с разными дата-центрами и загружать в оба. В нашем случае, скорее всего, понадобятся ретраи, чтобы получить новый IP, но загрузка возобновится с last known byte и на клиенте переключение не будет заметно.
Кроме того, храним path и URL на клиенте. Это позволит восстановить загрузку, если упадут браузер или приложение, а также если пропадёт соединение на стороне клиента. Вплоть до того, что можно выключить компьютер, а на следующий день возобновить upload.
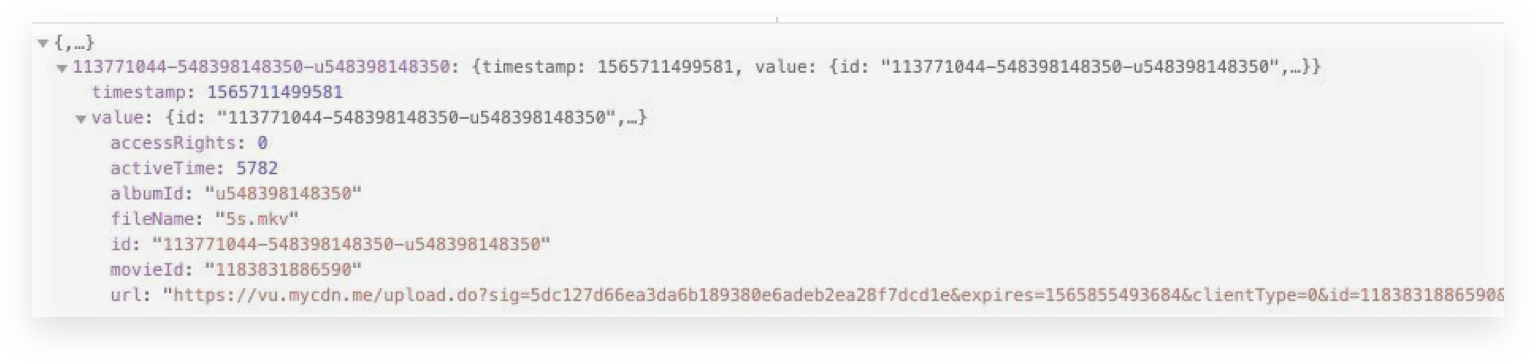 Информация о сессии загрузки в local storage браузера
Информация о сессии загрузки в local storage браузера
Transform (преобразование)
После загрузки контента на платформу и перед тем как сохранять файлы в хранилище, с ними бывает нужно что-то сделать: нарезать в разные разрешения фото или видео, протегировать контент, перекодировать аудио.
В VK Видео пользователи ежедневно загружают 8–14 млн новых видео в самых разных кодеках, контейнерах и разрешениях. Мы, в свою очередь, должны их показать на любых устройствах с любой сетью, а для этого преобразовать видео в такие форматы, кодеки и разрешения, которые покроют всё множество вариаций. Выглядит это так: видеофайл загружается в систему, по окончании загрузки попадает в очередь на транскодирование, а из очереди — на один из примерно 3 000 облачных контейнеров-transform«ов.
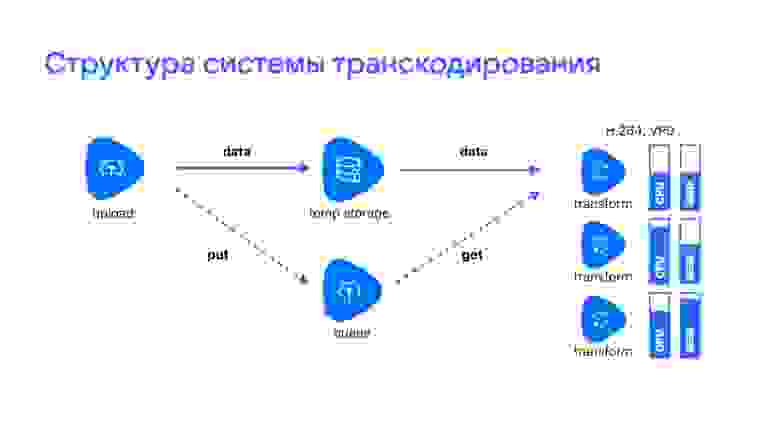
Если transform выходит из строя, то его задачи на транскодирование возвращаются в очередь и через небольшое время подхватываются другими контейнерами. Недоступность отдельных серверов или целого дата-центра (из-за аварии или профилактических работ) не повлияет на работоспособность сервиса транскодирования.
Очередь организуем с помощью собственного решения на leader election поверх ZooKeeper. Но это может быть и любой другой вариант, который позволит достаточно быстро восстановить очередь в другом месте и продолжить обслуживать ваши сервисы.
Здесь мы опять-таки не синхронизируемся постоянно, и это не полная Fault Tolerance. Но и без этого система восстановит работоспособность за считаные секунды: выберет другой сервер, получит статусы от всех серверов трансформации, пройдёт хранилище, узнает, где что лежит, и продолжит работать.
Что может пойти не так на этапе transform?
В один «прекрасный» момент мы увидели, как transform-серверы один за другим умирают. Оказалось, что к нам на платформу загрузили такое специальное видео, которое убивает программу-транскодер и вместе с ним сервер. Зловредная задача переходит на следующий сервер, ломает его и идёт дальше с эффектом домино — рестартом серверов тут не спасёшься.
В случае отказа всего транскодирования у нас есть резерв в несколько часов до переполнения загрузочной очереди с хранилищем и сбоя уже во всём сервисе. С помощью дедупликации по хешу мы смогли вычистить этот ролик и остановить волну сбоев. Обязательно сделайте такую проверку, если имеете дело с UGC-контентом: картинками, видео, аудио, чем угодно ещё. А также нужны лимиты на retry — если одна и та же задача возвращается в очередь больше n раз, то может быть разумно остановиться и перестать её брать.
Хранилище
Миллионы видео, которые ежедневно загружают к нам на платформу, нужно где-то хранить — поэтому у нас есть эксабайтное хранилище. Для простоты будем считать, что это 100 000 дисков по 10 Тбайт.
Прикинем availability одного диска на 10 Тбайт. Пусть скорость записи у него 500 Мбайт/с, а заявленная наработка на отказ составляет обычные 1 млн часов. Чтобы восстановить 10 Тбайт данных, понадобится 10×1 000×1 000 Мбайт/с ÷ 500 Мбайт/с = 20 000 c = 5,5 часов. Значит, availability = 99,9994% — отлично.
Но если у нас 100 тысяч дисков, то их восстановление займёт уже 600 000 часов, а вероятность состояния, когда все они одновременно исправно работают, падает до 40% (sic!). При этом оборудование выходит из строя неравномерно, и кроме самих дисков, есть ещё блоки питания, кулеры, контроллеры и другое. В итоге в среднем у нас 5–6 дисков находятся в состоянии repair.
Чтобы обеспечивать отказоустойчивость в ситуации, когда практически непрерывно какое-то оборудование не работает, у нас есть горячее и холодное хранилища.
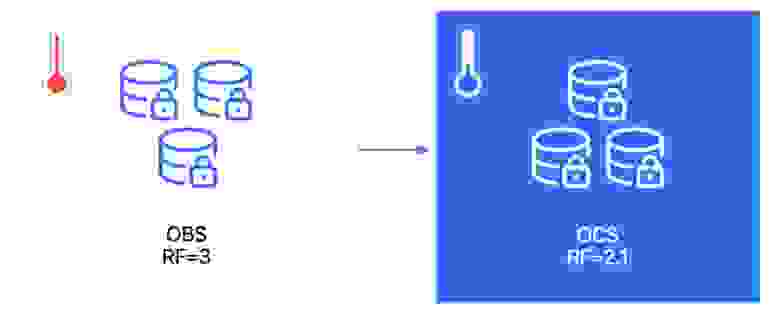
Горячее по принципу one blob имеет replication factor = 3, то есть мы одновременно записываем данные в какие-то три из пяти наших дата-центров. В холодном оптимизируем ресурсы и аккуратно уменьшаем объём данных для хранения с replication factor = 2,1. Подробнее про его устройство можно посмотреть в этом докладе.
Download (раздаём 100 Гбит/с с сервера)
С задачей высокой доступности сервиса рука об руку идёт проблема цены и производительности: чтобы экономить, надо эффективнее использовать железо.
Раньше скорость раздачи у нас была 40 Гбит/с с сервера. Но появилось более современное и мощное железо, и мы стали апгрейдить оборудование в надежде получить 100 Гбит/с. Не тут-то было. Сервер стал раза в два мощнее, а скорость раздачи при этом составила 46 Гбит/с.
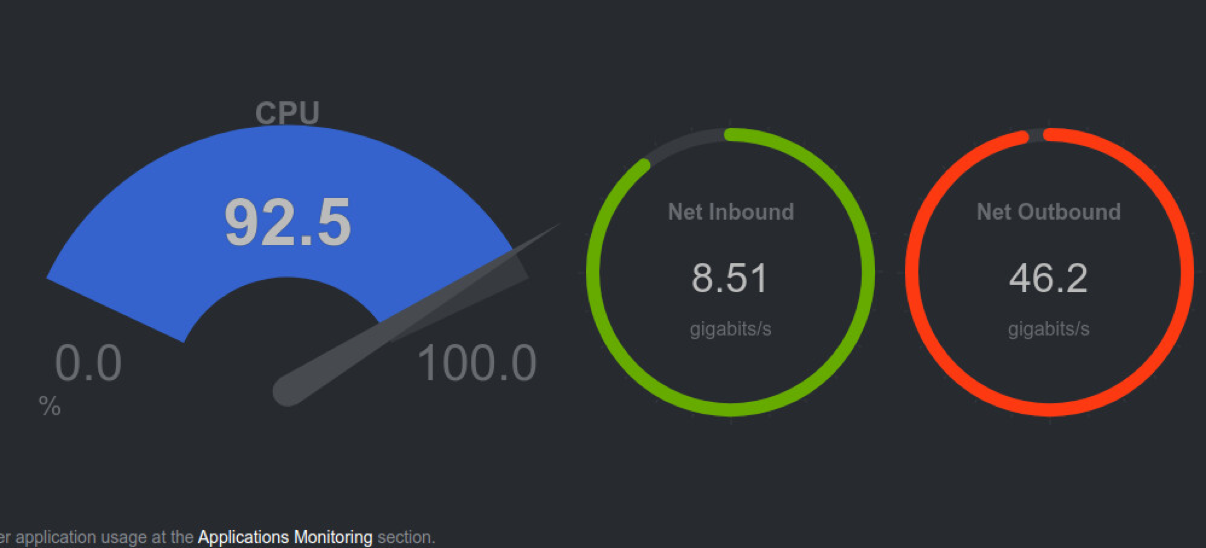
Здесь 80% CPU распределено между softirq и system. Если тоже видели такую странную утилизацию, когда большая часть ресурсов уходит системе и только малая — вашему коду, вооружайтесь perf и async-profiler (для Java) и читайте дальше, что можно сделать.
1. tcp_mem
Разберём на примере. Попробуем отправить 1 Мбайт через сокет по TCP и посмотрим, сколько на самом деле отправится и что вернёт функция:
ssize_t send(int sockfd, const void buf, size_t 1048576, int flags);Ответ: 16 Кбайт — размер SSL Record.
Обычно это решается с помощью селекторных систем на epoll: в них могут быть сотни тредов, которые обслуживают миллионы соединений. Когда в одно соединение ушло 16 Кбайт вместо тысячи, просто берётся новое — и следующие 16 Кбайт отправляются в него. Получается огромное количество context switching и очень неэффективная запись. Поэтому если нужно отправить большой блок данных по SSL в неблокирующем режиме при использовании OpenSSL, то лучше сделать несколько последовательных socket.send за одно пробуждение селектора.
Следующее, что может повлиять на скорость раздачи, — reclaim внутри TCP. Если вы объявили размер буфера, на который не хватило оперативной памяти, то операционная система всё исправит —, но это будет очень дорого. Нужно самостоятельно настроить лимиты. Мы увеличили tcp_mem до 20 Гбайт (ниже — объём памяти для TCP в страницах по 4 Кбайта, вектор: минимум, предел нагрузки, максимум):
net.ipv4.tcp_mem = 20000000 20000000 20000000
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 16384 4194304Сэкономить память может помочь параметр включения BBR и изменение параметра tcp_notsent_lowat в /etc/sysctl.conf:
net.ipv4.tcp_notsent_lowat=65536
net.core.default_qdisc = fq
net.ipv4.tcp_congestion_control = bbr
net.ipv4.tcp_notsent_lowat = 16384Результаты, которые можно получить, ниже на картинке.
 Подробнее в блоге Cloudflare: https://blog.cloudflare.com/http-2-prioritization-with-nginx/
Подробнее в блоге Cloudflare: https://blog.cloudflare.com/http-2-prioritization-with-nginx/
2. NUMA
Также, говоря о производительности, нельзя обойти стороной NUMA (Non-Uniform Memory Access).
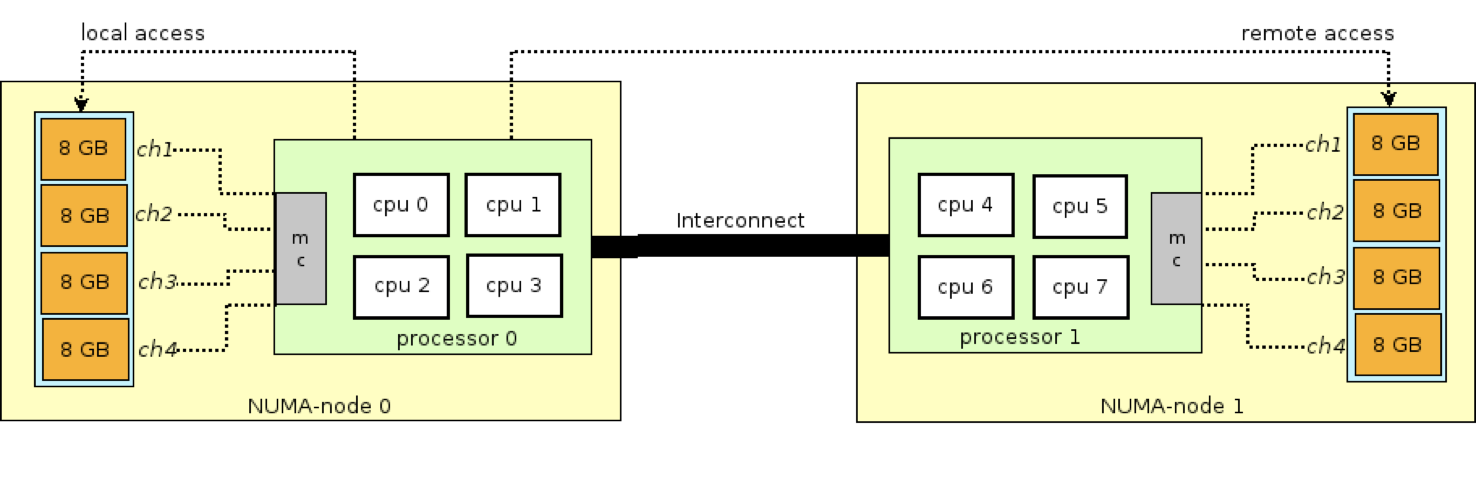
Наша рекомендация:
включить NUMA в ядре;
убрать
numactl --interleave=allпри запуске;добавить UseNUMA в Java-приложение и выключить numa_balancing (
sysctl kernel.numa_balancing = 0).
Используя NUMA, нужно иметь в виду: важно, как память распределяется по ядрам и серверам. И есть тонкость с тем, как вставлять планки: в идеале занять все слоты, пусть даже планками меньшего объёма.

3. Softirq
Попробовав раздавать на скорости в 100 Гбит/с, мы увидели, что очень много ресурсов уходит на softirq — мягкую обработку прерываний, которая к тому же может быть неравномерно распределена по ядрам.
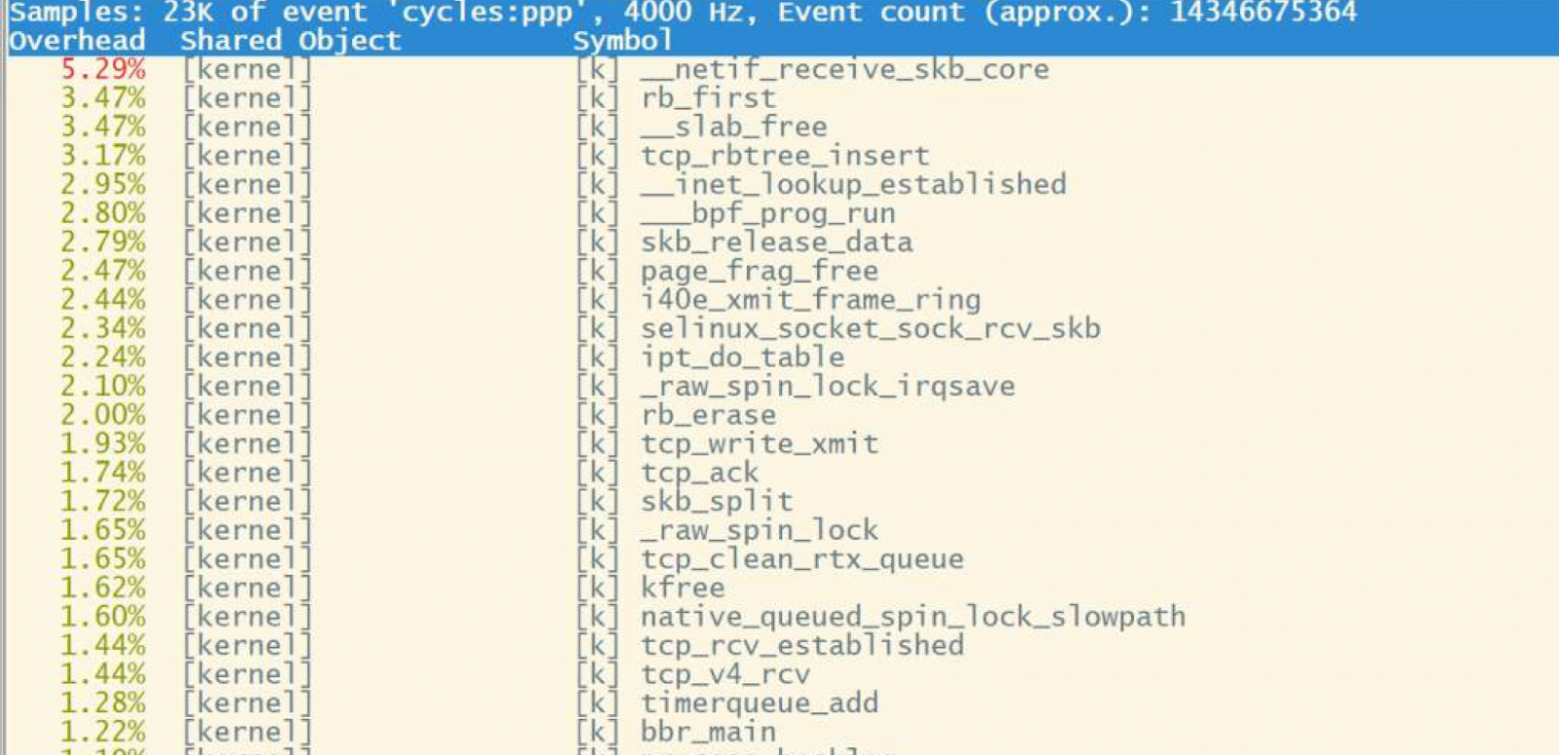 Горячие методы при большой нагрузке прерываниями
Горячие методы при большой нагрузке прерываниями
Чтобы избавиться от лишней нагрузки, надо распределить по ядрам обработку прерываний, приходящих на сетевую карту. Есть два способа: сделать это хардварно на уровне карты или обработать на software-уровне. Оба варианта подходят, лишь бы прибить прерывания к ядрам.
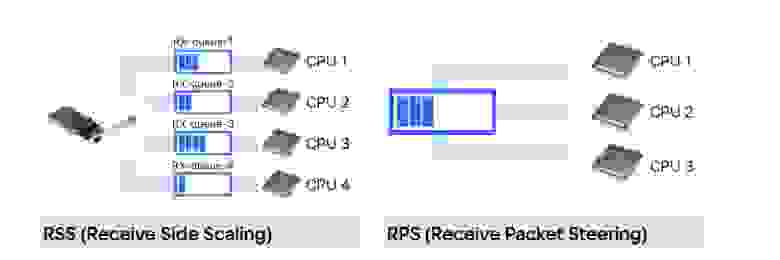
Но самое важное, за счёт чего можно убрать паразитный softirq — это RFS (Receive Flow Steering). RFS может гарантировать, что обработка программных прерываний и обработка приложений выполняются одним и тем же CPU. Это обеспечивает попадание в локальный кеш и повышает эффективность обработки.
Такие настройки позволяют избавиться от ненужного context switching:
увеличить размер хеша потоков в сокете RFS
echo 1000000 > /proc/sys/net/core/rps_sock_flow_entries;увеличить количество потоков до 10 240 на всех eth для всех очередей:
for i in /sys/class/net/eth{1,3,5,7}/queues/rx-/rps_flow_cnt;do echo 10240 > $i;done
В идеале один клиент обслуживается одной очередью на сетевой карте, одним CPU. Вы его вычитываете и отдаёте в одном треде на том же CPU.
RFS лучше использовать вместе с RPS (Receive Packet Steering).
4. OpenSSL 1.1 сontext
Если использовать один SSL-контекст, то в некоторых операциях (socket send / recv / accept) может произойти глобальный лок на контексте и получится вот такая картина.
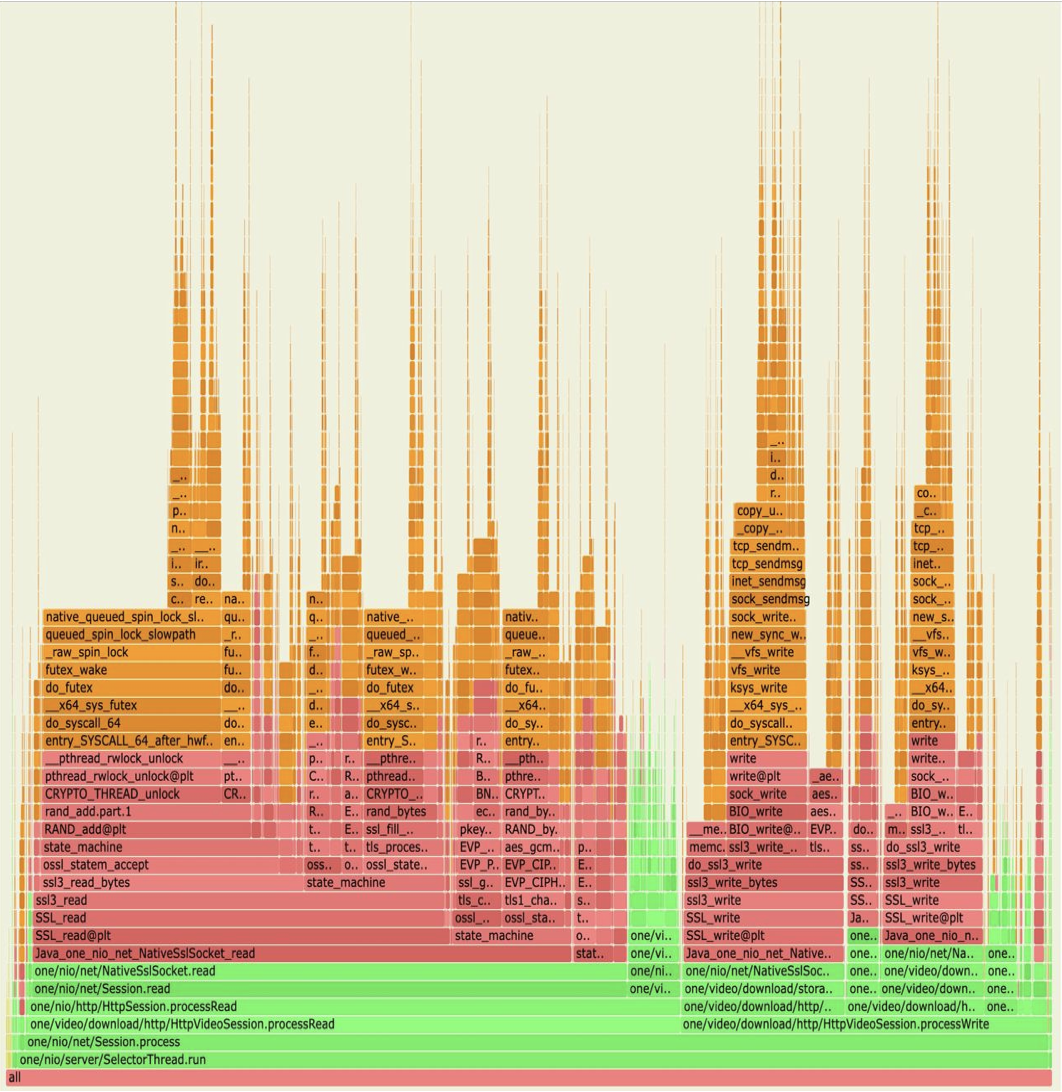 Flamegraph раздающего сервера под нагрузкой, пример с проблемой в блокировке при получении рандома
Flamegraph раздающего сервера под нагрузкой, пример с проблемой в блокировке при получении рандома
Поэтому не ограничивайтесь одним SSL-контекстом: открывайте несколько серверных сокетов через reuseport.
Но в случае нескольких контекстов ломается кеширование SSL-ключей — мы живём с этим. А Nginx запилил свою реализацию кеша и подсунул её в OpenSSL, чтобы избавиться от этой проблемы.
Ещё мы заменили генератор случайных чисел на RDRAND от Intel и на следующем нашем шаге экономим CPU на рандомайзере.
5. Garbage collector
Наш сервер раздачи написан на Java, поэтому у нас есть специфическое место для оптимизации — Garbage collector. Поэтому мы заменили GC с CMS на Shenandoah, ориентированный на низкие паузы, а заодно обновили Java до 17-й версии. В результате длительность safepoint-пауз снизилась до 2–3 мс.
Также используем jemalloc в качестве системного аллокатора.

Эти оптимизации позволили увеличить скорость отдачи до желаемых 100 Гбит/с с сервера, и при этом удержать нагрузку на CPU в пределах 50% при hitRate в 97%.
Мы также смотрим на io_uring и OpenSSL 3, но пока не получили результатов, которыми имеет смысл делиться.
QUIC
Раздача по QUIC статики, картинок и API позволила нам ускорить ВКонтакте в два раза. Как мы это запускали, как получили такие результаты и как это применить у себя — читайте в отдельной статье. Для видео результаты скромнее, но его мы тоже переводим на QUIC — ведь это плюс не только к скорости скачивания, но и к стабильности.
Google заявляет, что с QUIC на 18% реже возникает stall, то есть фризится видео или пользователь видит крутилку. К сожалению, по нашим тестам stall упали всего примерно на 3%. 50-й перцентиль по time to first byte и time to first frame снизился тоже на считаные проценты. 90-й перцентиль по time to first byte и time to first frame снизился на 20–25% в зависимости от платформы и типа контента, но в предельных случаях ускорение достигло и нескольких раз. Но пропускная способность сети с сервера для QUIC снизилась до 50 Гбит/с.
Теперь нас ждёт новый раунд увлекательного тюнинга, чтобы снова добиться высокой эффективности раздачи. Когда сетевой стек реализуется в User Space, TCP-хаки уже не подходят и нужно искать новые варианты.
Бонус: куда потратить свободные ресурсы
Мы сделали отказоустойчивую возобновляемую загрузку, транскодирование, хранение и раздачу со скоростью в 100 Гбит/с. При этом в нормальном состоянии в штатном режиме у нас, очевидно, остаются свободными резервные мощности. Утилизация серверов составляет примерно 60% днём и 10% ночью.
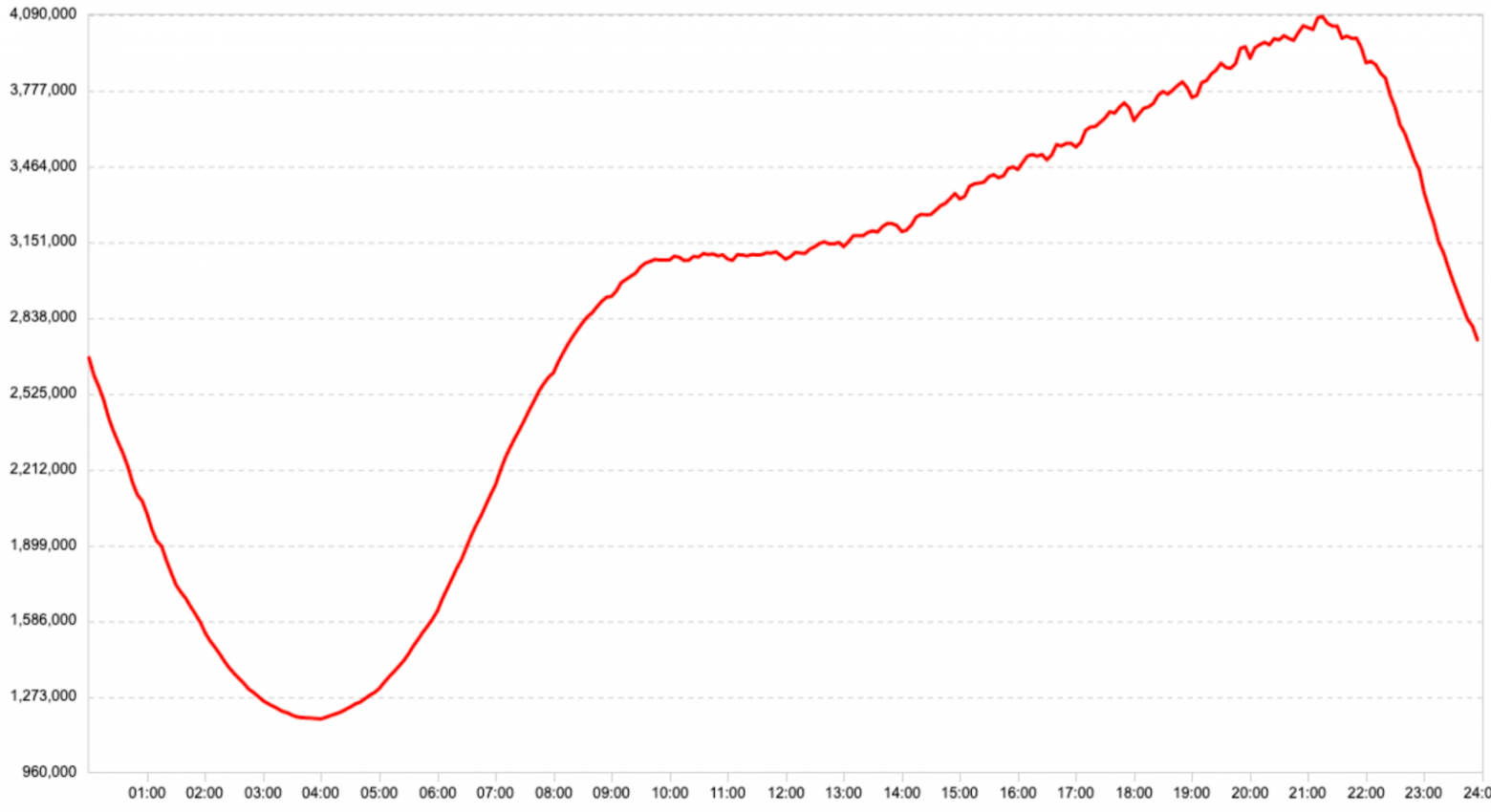 Трафик видео в Мбит/с
Трафик видео в Мбит/с
Если у вас есть свободные ресурсы, ML идёт к вам.
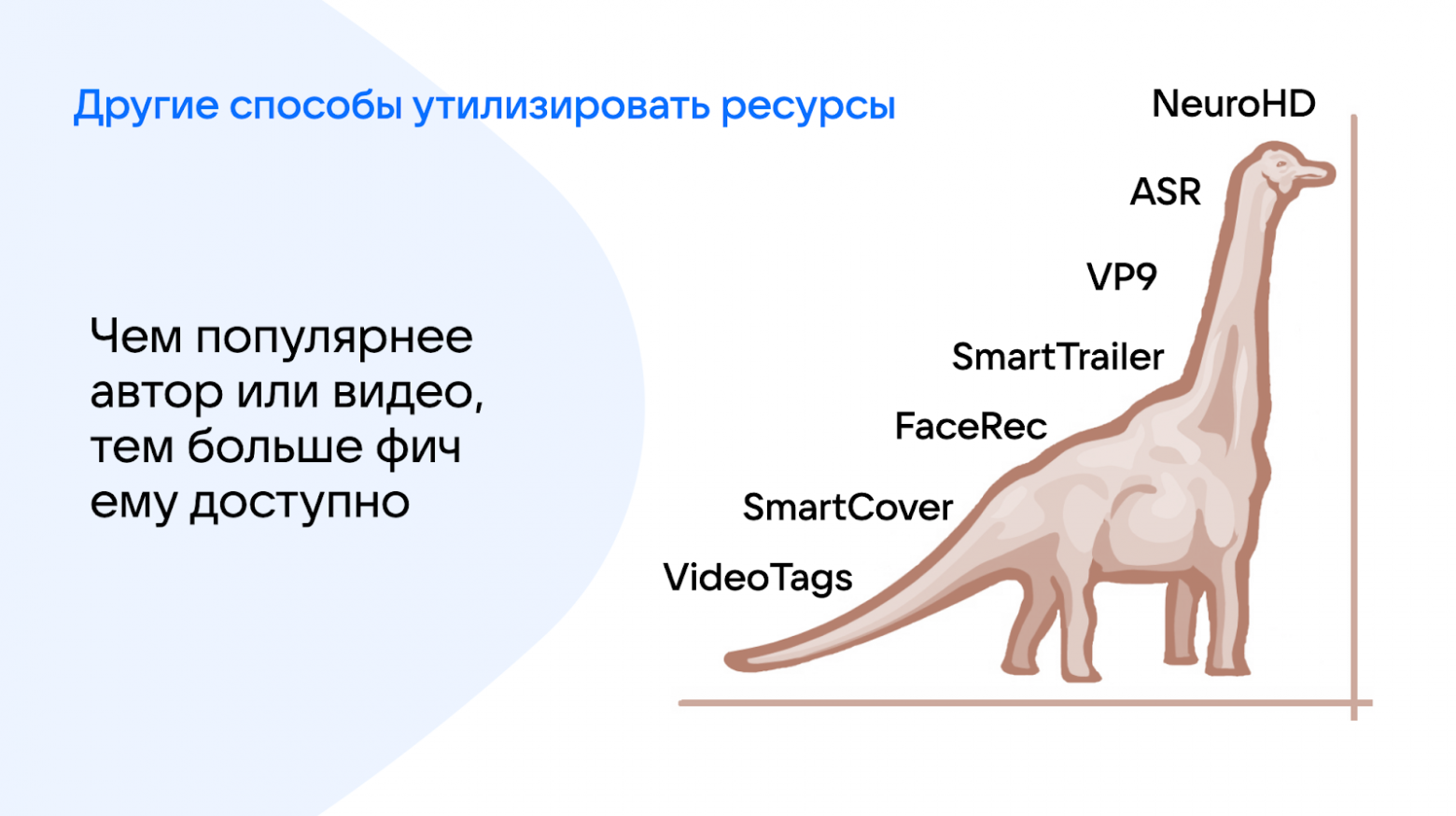
С помощью ML можно сделать кучу полезных или просто прикольных технологий для пользователей. Например, у нас есть нейросетевое тегирование для всего видео, умные обложки на многоруких бандитах и ML-превью, распознавание лиц, автосубтитры, технология автоулучшения видео NeuroHD и другие фичи.

Следите за этим блогом и новостями в сообществе vk.com/vkteam — скоро расскажем, как делаем такие штуки с точки зрения ML.
Вообще ML-технологиями можно занять сколько угодно вычислительных ресурсов. Но на практике они не безграничны, поэтому мы раскатываем фичи постепенно. А также проводим запросы на их применение через очередь — чтобы не перегрузить серверы и не повлиять на базовые функции. Например, автоулучшение качества сначала стало доступно отдельным сообществам. Теперь такую возможность получили все пользователи, но иногда им приходится подождать в очереди на обработку контента.
Выводы: унести с собой
В больших высоконагруженных сервисах всегда что-то в состоянии repair. Если у вас сотни или тысячи серверов, десятки тысяч дисков и подобное, что-то всё время будет сбоить — и к этому надо быть готовыми.
High Availability ≠ Fault Tolerance. В отказоустойчивом сервисе обслуживание не прерывается, а в высокодоступном время запланированных и форс-мажорных downtime не превышает заранее установленный порог.
Раздача на скорости 100 Гбит/с с сервера — это реально. Даже для Java-сервера. Но нужно потюнить настройки TCP, включить NUMA, равномерно занять все слоты оперативной памятью, прибить прерывания к ядрам, использовать несколько SSL-контекстов и для Java заменить GC.
Выхлоп от оптимизаций и резервные мощности всегда можно потратить на ML или майнинг битков — и сделать классные пользовательские фичи. Для этого даже не всегда нужно лезть в дебри нейронок: можно построить из готовых кубиков.
И последнее. На уровне архитектуры в fault-tolerance системе вероятность отказа стремится к нулю, выход из строя оборудования минимально влияет на общую работоспособность системы. Но по-прежнему остаются атаки, форс-мажоры и ситуации, к которым вы не можете быть полностью готовы. И, конечно, человеческий фактор: как и в авиации, он играет в нашей сфере очень существенную роль. Чем сложнее система, тем вероятнее, что человек станет её слабым звеном. Поэтому инцидент-менеджмент и работа с процессами — неотъемлемая часть любого сервиса. Но это уже совсем другая история.
Главная задача и секрет fault-tolerance системы — в простоте.
Продолжение следует. Уместить все особенности и лайфхаки VK Видео в одном материале невозможно — уж очень это большая платформа с почти десятилетней историей. Поэтому скоро опубликуем вторую статью, в которой сосредоточимся на скорости и пользовательском опыте. А попробовать наше решение у себя можно уже сейчас: вместо того, чтобы повторять наш многолетний путь, воспользоваться готовой инфраструктурой VK Видео и SDK плеера.
