Освобождаем свои данные из корпоративного рабства. Концепция личного хранилища

Автор программы Mathematica Стивен Вольфрам около 40 лет ведёт цифровой лог многих аспектов профессиональной и личной жизни
Сейчас практически всем стала понятна сущность некоторых интернет-корпораций, которые стремятся получить от людей как можно больше личных данных — и заработать на этом. Они предлагают бесплатный хостинг, бесплатные мессенджеры, бесплатную почту — лишь бы люди отдали свои файлы, фотографии, письма, личные сообщения. Наши данные приносят огромные деньги, а люди стали продуктом. Поэтому техногиганты Google и Facebook — самые крупные корпорации в истории человечества. Это неудивительно, ведь в их распоряжении миллиарды единиц бесплатного «сырья», то есть «пользователей» (кстати, этим словом users называют людей только в двух областях: наркоиндустрии и индустрии программного обеспечения).
Настало время положить этому конец. И вернуть данные под свой контроль. В этом суть концепции личных хранилищ данных (personal data services или personal data store, PDS).
Нам нужны удобные программы, сервисы, базы данных и защищённые хранилища для фотографий, личных финансов, социального графа, данных о личной продуктивности, потреблению продуктов, истории всех чатов в онлайне и офлайне, личного дневника, медицинских данных (пульс, давление, настроение и проч.), прочитанной литературы и публицистических статей, просмотренных веб-страниц, фильмов и видеороликов, прослушанной музыки и так далее.
Разумеется, эти данные должны храниться за всю жизнь человека — в абсолютно надёжном хранилище, к которому нет доступа корпораций и посторонних лиц. Нужны удобные инструменты для анализа и статистики. Нужны персональные нейросети для обработки данных и предсказания личных решений (например, для рекомендации музыкальных групп, блюд кухни или людей для общения).
К сожалению, единого общепринятого и удобного подхода к созданию таких решений пока нет. Но идёт работа в нужном направлении.
Некоторые исследователи думают над концептуальным решением проблемы, то есть над тем, какой должна быть вся инфраструктура для персональных данных.
Например, разработчик @karlicoss описал концепцию такой инфраструктуры.
Основные принципы:
- Простота для людей, чтобы данные было легко просматривать и читать.
- Простота для машинного анализа, для манипулирования данными и взаимодействия.
Если подумать, второй принцип важнее. Потому что если мы создадим инфраструктуру, понятную для машин, то программисты смогут обработать данные и разработать интерфейсы, удобные для человека.
Что ещё предусмотреть в концепции PDS? Должны быть API для получения любых данных из персонального архива.
Логично, что самый простой способ работы с данными — когда они непосредственно лежат в вашей файловой системе. В реальности персональные данные разбросаны по десяткам разных сервисов и программ, что очень затрудняет работу с ними. Для начала желательно извлечь их оттуда и сохранить локально. Да, теоретически это необязательно, ведь продвинутые PDS могут поддерживать работу с разными источниками данных в разных форматах. Например, данные могут храниться в разных облачных хранилищах, извлекаться через сторонние API из других сервисов и программ. Правда, нужно понимать, что это ненадёжные хранилища.
Например, Twitter через свои API отдаёт 3200 последних твитов, Chrome хранит историю 90 дней, а Firefox удаляет её на основе хитрого алгоритма. Ваш аккаунт в облачном сервисе могут в любой момент закрыть, а все данные удалить. То есть сторонние сервисы никак не предполагают долговременное хранение данных.

Расчётный лист вавилонского рабочего, датирован 3000 г до н. э. Пример долговременного хранения личной информации
Экспорт данных в личное хранилище
В качестве промежуточного решения предлагается концепция зеркала данных (data mirror).
Это специальное приложение, которое непрерывно работает на клиентской стороне в фоновом режиме — и постоянно синхронизирует локальный архив со всеми внешними сервисами. Приложение как бы «высасывает» ваши данные из разных программ и веб-сервисов, сохраняя в открытый машиночитаемый формат вроде JSON/SQLite. По сути, оно строит на диске это самое личное хранилище, которое в будущем должно вместить в себя все виды персональной информации.
На самом деле ещё не создано такое универсальное приложение, которое бы автоматически высасывало информацию всех форматов и типов из всего разнообразия существующих сторонних приложений и сервисов — и сохраняло локально.
Эту работу приходится делать в полуручном режиме.
Речь о том, чтобы выполнять экспорт информации со всех сервисов и программ, которые это позволяют. Экспорт в максимально возможном универсальном формате — и хранение этих данных в архиве. В будущем появится возможность проиндексировать и удобно работать с этими данными, а сейчас наша главная задача — сохранить их, чтобы они не исчезли навсегда.
Люди понимают, насколько важно сохранить навсегда личные фотографии. Но мало кто осознаёт то же самое для истории чатов во всех мессенджеров, а ведь это поистине бесценная летопись жизни человека. Эта информация с годами стирается из человеческой памяти.
Например, чаты ICQ хранились в простом текстовом виде, так что не нужно было предпринимать особых усилий для их сохранения. Так вот, если сейчас прочитать свои чаты из 90-х годов, то вы откроете заново целый пласт личной истории, которую уже давно забыли. Пожалуй, это очень важная часть персонального архива.
Так же важны медицинские данные о состоянии здоровья, пульсе, давлении, времени сна и других характеристиках, которые сейчас измеряются в течение жизни фитнес-трекерами.

Визуализация более миллиона электронных писем, которые Стивен Вольфрам отправил с 1989 года, показывает нарушения сна в годы напряжённой работы
Чтобы упростить себе регулярный экспорт/скрапинг личных данных из разных программ @karlicoss написал ряд скриптов для Reddit, Messenger/Facebook, Spotify, Instapaper, Pinboard, Github и других сервисов, которыми он пользуется.
В идеале, эти программы позволяют найти любое сообщение или заметку, то есть практически любую вашу мысль из прошлого, где бы она ни была зафиксирована — в чате Telegram или Вконтакте, комментарии на Хабре, прочитанной книге или в коде, который вы писали. Вся информация хранится в единой базе с полнотекстовым поиском.
Вместо облачных корпоративных сервисов нужно переходить на локально-ориентированный софт (local-first software). Он так называется по контрасту с облачными приложениями.
Локально-ориентированный софт работает гораздо быстрее, с меньшей задержкой, чем облачные приложения, потому что здесь при нажатии одной кнопки пакеты не путешествуют по всему земному шару, а все данные хранятся локально.

Предусмотрена синхронизация локальных данных между всеми устройствами, полный контроль человека над его данными, работа в офлайне в первую очередь (движение Offline First), безболезненное решение конфликтов в совместной работе, максимальная защищённость информации, длительная сохранность данных для наших потомков, как тот расчётный лист вавилонского рабочего выше (кстати, в 2016 году расшифровка текста выявила, что труд вавилонского рабочего оплатили спиртным напитком, а конкретно пивом).
Таким образом, локально-ориентированный софт соответствует всем семи обозначенным принципам. По мнению специалистов, лучше всего для реализации такого программного обеспечения подходят структуры данных типа CRDT (conflict-free replicated data type). Эти структуры данных могут реплицироваться среди множества компьютеров в сети, причём реплики обновляются независимо и конкурентно без координации между ними, но при этом всегда сохраняется математическая возможность устранить несогласованность. Это модель сильной согласованности в конечном счёте (Strong Eventual Consistency).
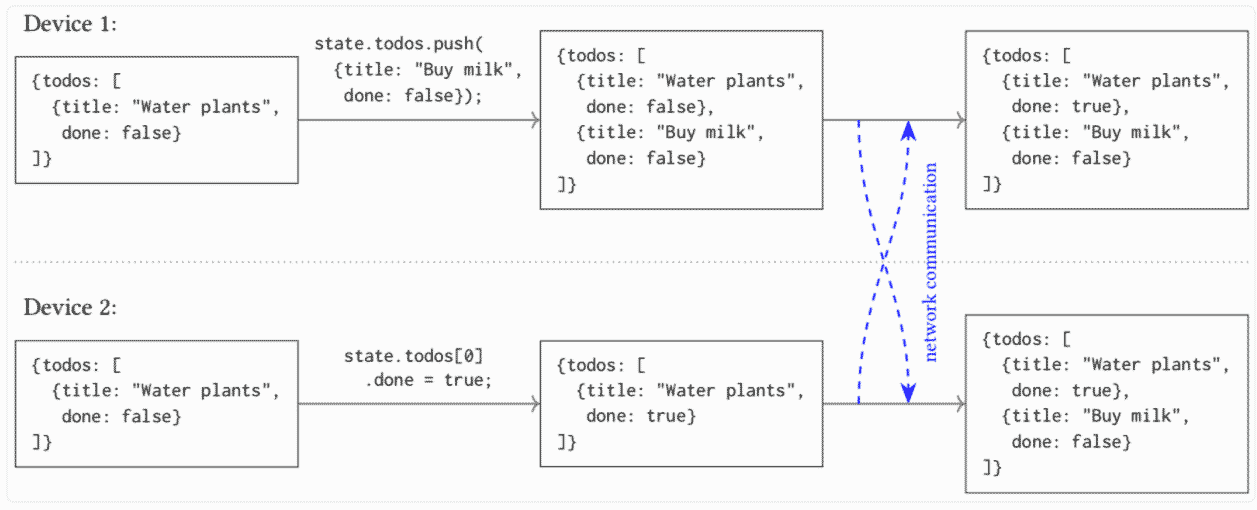
Благодаря такой модели согласованности структуры данных CRDT похожи на системы контроля версий типа Git. Для лучшего знакомства с CRDT можно почитать статью Алексея Бабулевича.
Гит-скрапинг
Идея освобождения личных данных из «корпоративного рабства» с долговременным локальным хранением в последнее время приобретает особую популярность. Жизнь показала, что от коммерческих веб-сервисов ничего хорошего ждать не приходится. Поэтому отдельные разработчики пытаются создать примеры личных информационных хранилищ.
Например, FOSS-разработчик и консультант Саймон Уиллисон работает над двумя инструментами Datasette и Dogsheep, которые весьма полезны для личных хранилищ.
Datasette — веб-приложение для обработки данных и публикации их в читаемом формате, в виде интерактивного веб-сайта (демо). Это лишь один элемент большой экосистемы Datasette — опенсорсных инструментов для сбора, анализа и публикации интересных данных. Экосистема делится на две части: инструменты для построения баз данных SQLite (для использования с Datasette) и плагины, которые расширяют функциональность Datasette.
Разные плагины позволяют комбинировать данные друг с другом. Например, накладывать координаты объектов из одной базы данных на географическую карту.
Уиллисон экспериментирует с регулярным скрапингом разных сайтов с публикацией данных в репозитории GitHub. Получается срез данных по изменению некоего объекта во времени. Он называет эту технику гит-скрапингом. В дальнейшем собранные данные можно преобразовать и Datasette.
См. примеры гит-скрапинга на Github. Это одна из ключевых техник для наполнения информацией личного хранилища данных — в стандартном открытом формате для долговременного хранения.
 Предстоит ещё долгий путь, чтобы освободить свои данные и создать инфраструктуру для надёжного и безопасного хранения личной информации. В будущем можно представить, что эта информация включит в себя также воспоминания и эмоции, которые снимаются с нейро-компьютерного интерфейса типа Neuralink, так что в совокупности хранилище будет практически полностью отражать личность владельца, представляя своеобразный «цифровой жизненный слепок» или аватар человека.
Предстоит ещё долгий путь, чтобы освободить свои данные и создать инфраструктуру для надёжного и безопасного хранения личной информации. В будущем можно представить, что эта информация включит в себя также воспоминания и эмоции, которые снимаются с нейро-компьютерного интерфейса типа Neuralink, так что в совокупности хранилище будет практически полностью отражать личность владельца, представляя своеобразный «цифровой жизненный слепок» или аватар человека.
Очень вдохновляют отдельные примеры героических усилий по цифровизации своей жизни, как у Стивена Вольфрама. На фотографии слева — домашний RIAD-массив с его хранилищем информации за 40 лет.
Стивен Вольфрам старается журналировать все события в своей работе. Главное — их сохранить. А сохранить их можно только под своим контролем, на собственном сервере. Человек должен полностью контролировать и железо, и программное обеспечение, и данные, которыми он владеет.
На правах рекламы
Закажите и сразу работайте! Создание VDS любой конфигурации в течение минуты, в том числе серверов для хранения большого объёма данных до 4000 ГБ, CEPH хранилище на основе быстрых NVMe дисков от Intel. Эпичненько :)

