Особенности партиционированния в PostgreSQL и Apache Hive
Часто специалисты, работающие с классическими реляционными базами данных, например, с PostgreSQL, испытывают затруднения в работе при переходе на систему хранения больших данных типа Apache Hive. Это связано с непониманием того, как можно использовать в новой среде уже наработанные подходы и методы работы с данными.
В данной статье рассмотрены некоторые особенности использования языка SQL в реляционных СУБД и Apache Hive. Кроме того, проведен сравнительный обзор возможностей и подходов, а также применение партиционирования на практике.
Материал будет полезен специалистам младших и средних грейдов, которые используют в своей практике SQL, но имеют мало опыта в Hive или Postgre.
В начале рассмотрим отличие подходов и применение рассматриваемых технологий.
Параметр | PostgreSQL v 14 | Apache Hive v 3 |
Направление использования | OLTP (учёт операций) | OLAP (анализ данных) |
Основа | Реляционные операции | MapReduce Framework / FS HDFS |
Ссылочная целостность | Полная поддержка | Отсутствует |
Применимость в Big Data | DWH | DataLake |
Цель | Аналитика для бизнес-решений | Экономичное хранилище больших данных |
Процесс | ETL | ELT |
Хранение данных | Табличные пространства | Файловая система HDFS |
Сжатие данных | Отсутствует | LZO, gZIP, Snappy |
Реляционные СУБД чаще всего используются в системах учета операций, где важна скорость записи изменений и транзакционный подход — система OLTP. Hive же чаще всего используется, как дешевая среда хранения большого объема данных, и проведение аналитических исследований над этими данными — OLAP подход.
Основой любой реляционной СУБД служит реляционная алгебра, отношения между кортежами и операции над ними. Этот подход позволяет хранить большие объёмы структурированной информации. К плюсам реляционных СУБД можно отнести: согласованность данных, их структурируемость, стандартные подходы к организации хранилища, высокая производительность. Минусы: высокие аппаратные требования, высокая стоимость хранения данных, трудная масштабируемость.
В свою очередь, Hive использует другой подход. В его основе лежит использование фреймворка MapReduce и Hadoop HDFS в качестве системы хранения. Такой подход позволяет совместить возможность распределенных вычислений и дешевого хранилища данных. Также следует выделить высокую надежность хранения данных, их распределение по нодам и простоту расширения кластера путем добавления новых нод. К минусам можно отнести отсутствие единой структуры хранения данных, полной поддержки ACID, а также ограничения по операциям DML и низкую скорость записи данных.
Отдельно стоит рассмотреть ссылочную целостность. Функционал реляционных СУБД предоставляют разработчику несколько вариантов реализации ссылочной целостности: мы можем заставить систему обновлять зависимые записи, удалять их или менять внешний ключ. После установки правил обновления данных система сама будет следить за соблюдением ссылочной целостности и содержать базу в согласованном состоянии. Hive такого функционала не имеет, и варианты обновления согласованных данных разработчик должен решать самостоятельно.
Что касается применения рассматриваемых систем в качестве основы хранилища больших данных, то Postgre подходит для построения DWH и аналитики бизнес-решений. И как следствие — мы обязаны использовать затратный ETL процесс, реализованный на отдельных серверах для подготовки данных перед загрузкой в DWH.
В отличие от DWH, в Hive можно реализовать DataLake, что позволяет производить все операции над данными непосредственно внутри хранилища и использовать ELT-процесс.
Рассмотрим хранение данных. Для определения места хранения данных в Postgre используются табличные пространства, которые позволяют, например, выбрать более производительные диски хранилища для горячих данных и дешевые хранилища — для холодных. В Hive есть возможность выбора директории хранения данных в HDFS. Также есть возможность выбрать формат хранения данных в HDFS: от выбора формата зависит возможность использования ACID и DML операций. При использовании сжатия данные можно сократить в пять раз.

Далее речь пойдет про особенности создания таблиц в рассматриваемых системах.
В Postgre создание таблиц реализовано по стандартам SQL. Мы можем задать описание полей, их ограничения и значение по умолчанию. Что касается создания таблиц в Hive, то тут есть некоторые отличия.
В Hive можно создать два типа таблиц: внешние (External) и управляемые (Managed), не считая Temp. Как было отмечено выше, от выбора типа таблицы зависят функциональные возможности, формат хранения и поддержка транзакций. В дополнении к тому, что таблицы External не поддерживают транзакции, нужно учесть, что обновление и удаление данных во внешних таблицах невозможно с использованием DML-операций UPDATE, MERGE, DELETE. Как в этом случае осуществить обновление или вставку данных, мы рассмотрим далее.
В качестве указателя места хранения данных в PostgreSQL используется параметрTABLESPACE, в Hive установка LOCATION в HDFS. Кроме того, в Hive есть возможность выбрать файл хранения данных и сжатие. В PostgreSQL и в Hive есть возможность указать партиционирование, о чем будет подробно разобрано далее. Обе системы позволяют создавать временные таблицы и осуществлять проверку на наличие уже существующей таблицы.
Параметр | PostgreSQL | Apache Hive |
Выбор места хранения данных | Табличные пространства TABLESPACE табл_пространство | Файловая система HDFS LOCATION hdfs_path |
Возможность выбора формата хранения | Отсутствует | Множество вариантов форматов хранения (ORC, Parquet и т.д.) STORED AS file_format |
Партиционирование | Отсутствует динамическое партиционирование Типы партиционирования, Range, List, Hash, составное партиционирование. | В Hive возможно динамическое партиционирование Тип партиционирования List. |
Временные таблицы | CREATE [TEMPORARY | TEMP] TABLE | CREATE TEMPORARY TABLE |
Проверка на существование таблицы | CREATE TABLE [ IF NOT EXISTS ] имя_таблицы (…) | CREATE [TEMPORARY | EXTERNAL] TABLE [IF NOT EXISTS] |
Очень часто в практике требуется узнать структуру таблицы, ее поля и другие данные. Для этого в СУБД реализованы отдельные SQL-команды и запросы.
Для PostgreSQL запрос к служебной таблице information_schema, который выведет поля таблицы, их типы и ограничения.
В Hive возможны несколько вариантов получения описания таблицы:
Команда DESCRIBE FORMATTED вернет описание полей таблицы в табличном представлении;
SHOW CREATE TABLE вернет DDL создания таблицы с указанием формата хранения и location.
Рассмотрим примеры.
PostgreSQL:
SELECT table_schema, table_name, column_name, data_type, is_nullable
FROM information_schema.columns
WHERE table_name = 'dim_account'; 
Apache Hive:
DESCRIBE FORMATTED dim_account
SHOW CREATE TABLE dim_account
Партиционирование таблиц.
При создании таблиц крайне важно сразу продумать способ разбиения таблиц на партиции. Это коренным образом влияет на производительность работы базы данных в целом, скорость выполнения запросов и возможности по модификации таблицы в будущем. Это справедливо как для реляционных СУБД, так для Hive.
Рассмотрим разные методы партиционирования и их особенности.
Партиция — это поименованный самостоятельный фрагмент памяти на дисках. Важно запомнить, что партиции влияют на физическое хранение данных. Партиционирование еще может называться секционированием.
Применяется для:
Повышения производительности работы SQL-запросов и DML-операций по модификации строк таблицы — за счет того, что операции чтения ограниченны партицией и ядру СУБД нет необходимости прочитывать всю таблицу на всех носителях;
Быстрого удаления значительного числа строк в больших таблицах за счет выполнения операции truncate секций;
Разбиения большой таблицы на оперативную и архивную части, в том числе выделения оперативной части на скоростные носители;
Снижения конкуренции за строки и индексы таблицы, в том числе уменьшения вероятности блокировок за счет физического разделения данных;
Обеспечения устойчивости функционирования таблиц, так как данные в таблице могут быть разнесены на разные хранилища, что значительно повышает надежность.
Бывают различны методы партиционирования: по диапазону ключа, списку ключа, хеш- партиционирование и составное партиционирование.
Рассмотрим на примере PostgreSQL.
Допустим, нам необходимо разбить таблицу счета (dim_account) на сегменты, где в первую очередь будут содержаться счета, открытые в определенную дату, с разбивкой по источнику данных. Таким образом, мы получаем первую разбивку по диапазону ключа, c ключом дата открытия счета. И вторая разбивка по списку ключа, с ключом система-источник.

На данный момент функционал PostgreSQL не позволяет создавать партиции автоматически, поэтому разработчику требуется самому позаботиться о создании партиций при проектировании ETL-процесса.
Чтобы создать секционированную таблицу, необходимо указать команду partition by и поле партиционирования.
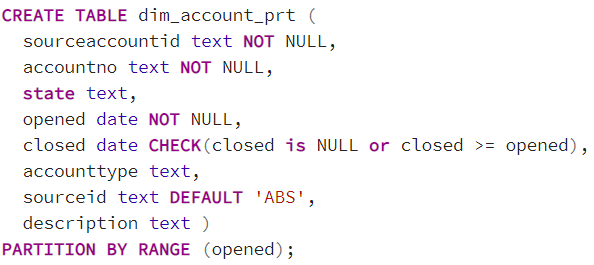
Далее нам необходимо создать дочерние таблицы, которые будут разбивать таблицу по интервалу. В данном случае два интервала: за даты 29.11.2022 и 30.11.2022. В описании интервала первое значение включается в интервал, а второе — нет.

В свою очередь, эти дочерние таблицы должны быть партиционированы по системе-источнику — полю sourceid. А значит, мы должны создать еще четыре дочерних таблицы секционирования по списку.

Таким образом, разбивка исходной таблицы на две даты и два источника потребует создания шести дочерних таблиц. В самой исходной таблице физически данные не будут содержаться, а фактически данные будут храниться только в конечных четырех таблицах.
В итоге мы получили структуру, представленную на рисунке: основная таблица, две партиционированные дочерние таблицы и четыре конечные таблицы хранения данных.

Рассмотрим пример вставки данных в исходную таблицу.

В условии where есть указание на партицию, указана дата открытия счета и система-источник. Фактически данные вставятся не в исходную таблицу, а в партицию abs_dim_account_2022_11_30.

Для того, чтобы просмотреть партиции исходной таблицы и количество записей, в них следует выполнить представленный скрипт.

Видим три партиции с данными у родительской таблицы.

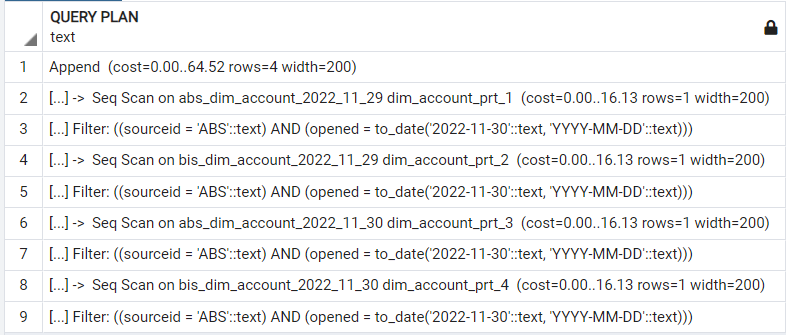
При обращении к исходной таблице в условии where мы должны указать ключи партиционирования. В этом случае запрос не будет просматривать всю таблицу, а сразу считает данные с конкретной партиции.

Если известно имя партиции, в которой содержатся нужные записи, то возможно обращение непосредственно к этой партиции по имени таблицы.

Два приведенных примера вернут одинаковый набор данных.

Как видим на примере плана запроса селекта к родительской таблице, по факту происходит обращение непосредственно к таблице партиции.

Если же мы выполним данный запрос без учета партиций, то увидим, насколько дольше он будет обрабатываться. СУБД проверит все партиции на условие. В этом и заключается прирост производительности при использовании партиций.
Способность обращения с партициями как с таблицами открывает возможность к манипуляции с данными целыми участками, без затрагивания основной таблицы.
Например, запрос TRUNCATE быстро очистит данные без использования затратной операции DELETE. Эту операцию можно использовать при повторной заливке данных.
DROP TABLE удалит партицию и все данные.
С помощью ALTER TABLE можно поменять TABLESPACE и перенести горячие данные на более производительные носители.

Рассмотрим на примере Hive.
Партиция (partiton) в Hive — это результат разделения таблицы на отдельные части, которые физически хранятся в разных файлах на HDFS.

Партиционирование в Hive является нативным функционалом и не требует создания подтаблиц как в случае PostgreSQL. Все партиции создаются автоматически и распределяются в каталогах HDFS.
Указав ключи партиционирования в блоке партиции, Hive в дальнейшем сам будет разделять поступающие данные по партициям.
Отдельно разберем плюсы и минусы партиционирования в Hive.
Плюсы:
Горизонтальное распределение вычислительной нагрузки по нодам кластера;
Время ответа на запрос сокращается до обработки небольшой части данных вместо поиска по всему набору данных;
Быстрое удаление значительного числа строк в больших таблицах;
Разбиение большой таблицы на оперативную и архивную части;
Возможность загрузки большого массива данных без блокировки доступа к основной таблице.
Минусы:
Ограничение по количеству партиций: не рекомендуется использовать более 10 тысяч партиций, что может привести к сильному замедлению работы кластера;
Партиции оптимизируют запросы, основанные на предложениях Where, но не эффективны при использовании группировки;
При обработке большого количества Mapreduce огромное количество разделов приведет к огромному количеству задач (которые будут выполняться в отдельной JVM), что создает большие накладные расходы на поддержку запуска и отключения JVM.
Рассмотрим варианты создания партиций в Hive.
Первый вариант — это загрузка данных из внешнего файла, когда таблицы в Hive нет. В данном случае Hadoop прочитает предложенный файл и разместит полученные данные в каталоге HDFS, выделенном для данной таблицы.

Второй вариант — загрузка данных из таблицы уже имеющейся в Hive. В данном случае есть два варианта загрузки, с добавлением данных в партицию или с перезаписью партиций. В случае, если нам надо перезаписать партицию полностью, например, при повторной выгрузке данных с источника, необходимо использовать конструкцию INSERT OVERWRITE TABLE. Тогда Hadoop перезапишет все файлы, находящиеся в каталоге партиции. Если же нам требуется добавить данные в существующую патрицию, то необходимо использовать конструкцию INSERT TABLE. В данном случае Hadoop допишет данные в существующий файл партиции.
Как мы уже знаем, Hive не поддерживает инструкции SQL UPDATE, MERGE, DELETE для External таблиц, а это большинство таблиц, используемых на практике. Тогда встает вопрос — как же тогда изменить часть данных внутри партиции? Для этого можно использовать вариант с перезаписью партиций совместно с вариантом добавления данных.
Рассмотрим пример.
Нам требуется за определенную дату для всех счетов, поступивших с источника ABS, прописать в description дату загрузки, филиал и указание на ABS.
Первым действием мы перезапишем нужную партицию, исключив из выборки все данные по источнику ABS.

Вторым действием допишем в уже обновленную партицию все записи по источнику ABS c указанием необходимого DESCRIPTION.
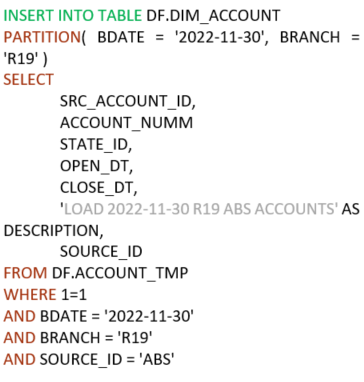
Таким образом, мы получим аналог UPDATE, реализованный двумя шагами. Так же можно реализовать и DELETE, просто исключив не нужные записи условием запроса.
Во всех приведенных выше примерах Hive, мы указывали — в какую конкретно партицию ему производить запись (PARTITION (BDATE = '2022–11–30', BRANCH = 'R19')). Но Hive поддерживает и динамическое партиционирование, когда на основе заданных ключей партиционирования и входных данных он сам решает — какие партиции следует создать и как распределить по ним данные.
Для этого необходимо указать соответствующие параметры для среды Hive. Они представлены на рисунке.

В данном случае в параметрах PARTITION мы указываем не конкретное значение, а только ключи партиционирования.

Если мы рассмотрим состояние партиций до вставки при помощи команды SHOW PARTITIONS, то увидим, что у таблицы только одна рабочая партиция бизнес-дата = 2022–11–30 и филиал R19, а также дефолтная партиция.

После выполнения INSERT в where, части которого мы указываем, все данные за дату больше 2023–01–01. Hive прочитает весь предложенный ему набор данных, сам выделит партиции на основе ключей партицонирования и распределит полученный набор на конечные партиции. В данном случае к таблице добавится еще три партиции.

Как и в случае с PostgreSQL, в Hive над партициями можно производить операции через команду SQL ALTER TABLE. Например, для переноса партиции в другую директорию HDFS необходимо указать SET LOCATION.

Бывают случаи, когда к таблице надо добавить существующие партиции. Например, при разборке инцидентов, когда данные переносятся с прода на тест. Тогда, зная директорию хранения партиции, ее легко можно добавить к существующей таблице.

Также партиции можно удалять через команду DROP PARTITION.

Рассмотрим пример запроса данных из партиционированной таблицы.

Имеется таблица счета, партиционированная по бизнес дате и филиалу. Следовательно, для того, чтобы запрос был максимально эффективным, мы эти поля должны указать в ограничении условия WHERE. Иначе Hive будет считывать все партиции, что приведет к значительному увеличению времени выполнения запроса.
Партиционирование является мощным инструментом для управления данными и ускорения выполнения запросов как для классических реляционных систем (PostgreSQL), так и в Hive.
Подведем итог
Мы рассмотрели некоторые особенности использования языка SQL применительно к классической реляционной схеме на примере PostgreSQL и системы обработки больших данных на основе Apache Hive. Несмотря на то, что эти системы изначально создавались для разных целей, именно возможности языка SQL позволяют нам работать в этих системах, не обращая внимания на архитектурные различия.
Язык SQL, появившийся в 1986 году, до сегодняшнего дня не утратил своей актуальности. Последний стандарт SQL принят в 2016 году, но помимо этого появляются новые СУБД, которые постоянно вносят свои фичи в развитие этого языка, о которых сложно рассказать в рамках одной статьи, поэтому стоит только пожелать вам не останавливаться в постижении глубин языка SQL.
