Основы индексирования и возможности EXPLAIN в MySQL
Темой доклада Василия Лукьянчикова является индексирование в MySQL и расширенные возможности EXPLAIN, т.е. нашей задачей будет ответить на вопросы: что мы можем выяснить с помощью EXPLAIN’а, на что следует обращать внимание?
Многие ограничения EXPLAIN’а связаны с оптимизатором, поэтому мы предварительно посмотрим на архитектуру, чтобы понять, откуда следуют ограничения и что, в принципе, с помощью EXPLAIN’а можно сделать.
По индексам мы пройдемся очень кратко, исключительно в плане того, какие нюансы есть в MySQL, в отличие от общей теории.
Доклад, таким образом, состоит из 3х частей:
- Архитектура;
- Основы индексирования;
- EXPLAIN (примеры).
Василий Лукьянчиков (Станигост)

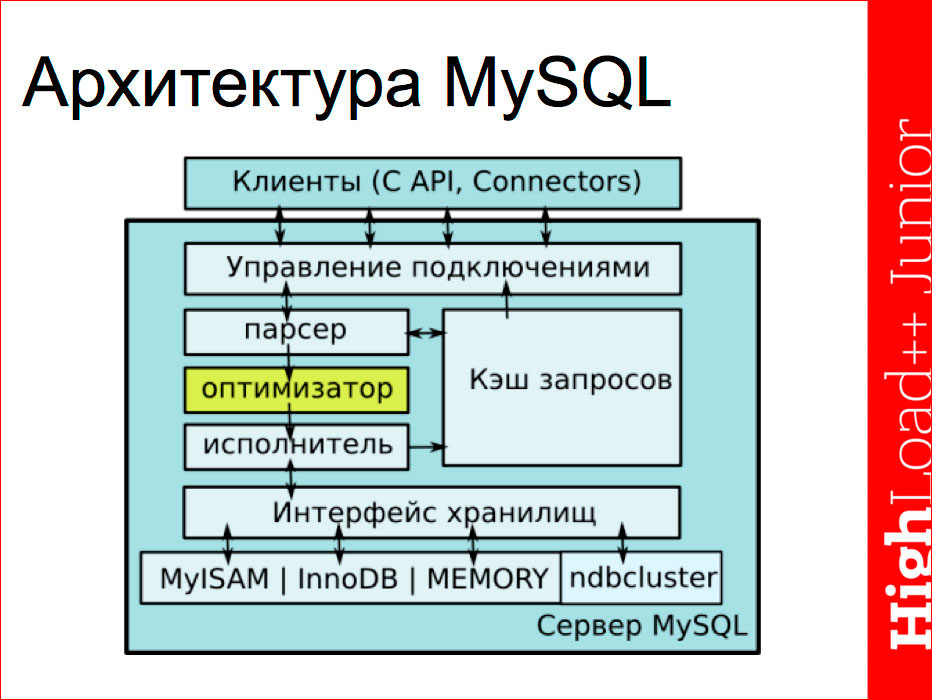
Архитектура MySQL
Схематически сервер можно представить так:
Первый блок — клиенты, которые обращаются к серверу через функции соответствующего коннектора или C API по протоколу TCP/IP либо UNIX Socket, как правило. Они попадают на блок управления подключениями, где, собственно, происходит авторизация клиента в этот момент, и запуск процесса авторизации и исполнения. Каждый клиент работает в своем независимом потоке. Лишние потоки могут кэшироваться сервером и потом использоваться.
Про кэш запросов нужно отметить, что он представлен одним общим потоком для всех клиентов и в ряде случаев может оказаться узким местом, если у нас многоядерная архитектура и очень простые запросы к базе. База их быстро выполняет, время обращения к кэшу может стать узким местом, поскольку это единственный поток, и все к нему выстраиваются в очередь.
С управления подключениями запрос попадает на основной конвейер, который состоит их трех частей — парсер, оптимизатор и исполнитель. Собственно, эта часть и превращает полученный SQL-запрос в выборку данных. Эта часть общается с интерфейсом хранилищ, каждая по своим задачам:
- парсер проверяет синтаксис запроса, запрашивает у хранилищ наличие данных таблиц и полей, права доступа непосредственно к этим полям и проверяет наличие
ответа в кэше запросов, после чего передает распарсенный запрос оптимизатору; - оптимизатор запрашивает в интерфейсе хранилищ статистику по индексам, на основании которой он строит план запроса, который передает исполнителю;
- исполнитель обращается по полученному плану непосредственно за данными в хранилище, передает ответ клиенту через интерфейс и, при необходимости, меняет в
кэше обновления (либо сам результат, либо обнуляет, если был запрос на обновления).
Здесь нужно отметить ключевую особенность, связанную с MySQL, — это интерфейс подключаемых хранилищ, т.е. вы можете в своей компании разработать свое собственное хранилище (интерфейс стандартный) и подключить его. Таким образом, вы можете сделать, чтобы данные хранились наиболее удобным вам образом с учетом различных нюансов.
Обратной особенностью является то, что оптимизатор очень слабо связан с хранилищами, он не знает и не учитывает отдельные нюансы исполнения части запроса тем или иным хранилищем. Причем, что странно, это так же плохо происходит для основных хранилищ, которые разрабатывают непосредственно разработчики MySQL, и данная ситуация стала улучшаться только в последних версиях. Этот момент нужно учитывать.
Еще тут стоит отметить то, что индексы в MySQL реализованы именно на уровне хранилищ, они не стандартизированы. Поэтому нужно следить за тем, какой тип индекса — полнотекстовый, B-Tree, пространственный и др. — используется тем или иным хранилищем. И самое главное: один и тот же индекс в разных хранилищах — это может быть совершенно разная структура. Например, B-Tree индекс в MyISAM хранит указатель на сами данные, а в InnoDB он хранит указатель на первичный ключ; в MyISAM происходит сжатие префиксных индексов, а в InnoDB этого не происходит, но зато там есть кэширование и данных, и индексов.
Существует масса нюансов, которые нужно учитывать при работе, т.е. какие-то запросы будут быстрее выполняться в одном хранилище, какие-то — в другом, т.к. они по-разному хранят статистику. Например, запрос count (*) в случае MyISAM может выполняться очень быстро без обращения к самим данных, т.к. там хранится именно статистика в метаданных, это, правда, для частных случаев, но, тем не менее, такие нюансы есть.
Сразу скажем про план запроса. Его делает оптимизатор, и это не какой-то исполняемый код, а набор инструкций, который он передают исполнителю. Это некое предположение о том, как запрос будет выполняться. После того, как исполнитель сделает запрос, могут появиться какие-то отличия и, в отличие от PostgreSQL, MySQL не показывает то, что было сделано, т.е., когда мы смотрим EXPLANE в MySQL, у нас нет EXPLANE ANALYSE. Точнее, оно появилось совсем недавно в версии 10.1 Maria, которая еще beta, и, естественно, пока не используется. Поэтому нужно учитывать, что когда мы смотрим EXPLANE в MySQL, это некие предположения.
Часто возникает такая ситуация, что у нас один и тот же план, но разная производительность. Тут надо отметить тот момент, что сам оптимизатор в плане EXPLANE дает очень мало вещей. Например, у нас запросы select (*) из таблицы и select пары полей из таблицы будут иметь одинаковый план, но в одном случае у нас будет выбрано несколько Кб для каждой записи, а в другом — может быть несколько Мб, если у нас записи огромные. Естественно, производительность этих запросов будет различаться на порядки, но план этого никак не покажет. Или же у нас может быть одинаковый план, один запрос, но выполняться на разных машинах он будет по-разному, потому что в одном случае индекс читается из памяти, в другом, если буфер маленький, индекс берется с диска. Опять при одинаковом плане производительность будет различаться. Поэтому в дополнение к EXPLANE’у нужно на разные вещи смотреть, в первую очередь — на параметры сервера (show status).
Здесь уместно обратиться к прошедшей конференции РИТ++, на которой был доклад Григория Рубцова по ботаническому определителю MySQL — для тех, кто не умеет гипнотизировать сервер и сразу навскидку определять узкое место, там выстроена целая последовательная схема: посмотрели на такой-то параметр — пошли туда. Как в классическом ботаническом определителе, когда велся поиск определения растений, смотрели на количество листьев, на форму и т.д. и так пришли к ответу. Там именно такая структура — куда последовательно смотреть, что делать, чтобы найти узкие места.
Перейдем к индексам в MySQL.

Мы не будем рассматривать и перечислять все типы индексов — они более-менее стандартны для каждой базы. Говоря о MySQL, нам нужно отметить следующее: MySQL никак не управляет дублированными индексами, т.е. если мы создаем таблицу так, как представлено, это не означает, что у нас будет создан primary index уникальный на колонку 1. Это означает, что у нас будет создано три одинаковых индекса на одну колонку. Они все три будут занимать место, будут обновляться, будут учитываться оптимизатором, и MySQL сам не выдаст никакого предупреждения, т.е. это нужно смотреть самостоятельно.
Говоря об индексах (в основном мы будем говорить о b-tree, как о наиболее используемых), чтобы не вдаваться в подробности и дерево не рисовать, индекс очень удобно представлять в виде алфавитного указателя. Например, адресная книга — это таблица, алфавитный указатель к ней — это и есть индекс. Применив такую аналогию, мы можем представить, как происходит работа с индексом, за счет чего там быстрее выбираются данные и пр. Но здесь есть некое отличие в самом MySQL, поскольку MySQL всегда идет по индексу, он использует индекс только слева направо последовательно, без фокусов, это может вызвать вопросы.

Например, если нам нужно в алфавитном указателе найти какие-то имена. «Руками» мы будем искать следующим образом: посмотрим первую фамилию, найдем нужные имена, пролистнем до следующей фамилии. Это не ограничение b-tree дерева, это ограничение реализации b-tree дерева непосредственно в MySQL. Другие базы так умеют делать — использовать не первую колонку, например, в случае WHERE B=3 индекс в MySQL использоваться, вообще, не будет. Только в частном случае, если мы попросим минимум и максимум от этой колонки, но это, скорее, исключение.
На слайде выше представлены различные варианты, и стоит отметить, что индекс обрывается на первом же неравенстве, т.е. он используется последовательно слева направо до первого неравенства. После неравенства дальнейшая часть индекса уже не используется. Т.е. в условии А — константа, В — диапазон, будут использованы первые две части. Во втором случае будет использован целиком индекс. В третьем случае индекс тоже будет использован целиком, т.к. порядок констант в условии не имеет значения, и сервер может их переставить местами. В случае В=3 индекс, вообще, использован не будет. В случае константы и неравенства будет использован индекс только на первые две части, на третью часть индекс уже не сможет использоваться. В случае А — константа и сортировка по последнему, будет только на первую часть использован индекс, потому что пропускается вторая часть, предпоследний индекс будет целиком использован. И в последнем варианте, опять же, индекс будет использован только на первую часть, потому что для сортировки индекс может использоваться только лишь, когда в одном направлении идет.
Это связано с тем, что составной индекс в MySQL — это, по сути, обычный b-tree индекс над конкатенацией входящих столбцов, соответственно, он может двигаться либо по возрастанию всего кортежа, либо по его убыванию. Поэтому сказать: «двигаемся по возрастанию В и по уменьшению С» по индексу мы не сможем. Это ограничение, характерное именно для MySQL.
Здесь есть такой нюанс. Например, A in (0,1) и А between 0 and 1 — это эквивалентные формы, это диапазон и там, и там, но в случае, когда это A in (0,1) — список, он понимает, что это не диапазон, а заменяет на множественное условие равенства. В этом случае он будет использовать индекс. Это еще один нюанс MySQL, т.е. нужно смотреть, как писать — либо списком, либо ставить <>. Он это различает.
Пара слов про избыточный синтаксис. Если у нас есть index (A) и index (A, B), то index (A) будет лишним, потому что в случае index (A, B) часть А может использоваться в нем. Поэтому нам нужно следить, чтобы избыточных индексов не было и самостоятельно их удалять. Понятно, это относится и к случаю, когда оба индекса b-tree, но, если, например, index (A) — это full-text, то, естественно, он может быть необходим.
Вернемся к нюансу на списке. Мы можем делать здесь более широкий индекс уникальным. Например, если мы сделаем index (A, B), то просто условие В использовать не будем, но мы можем в приложении сделать так, чтобы оно самостоятельно подставляло пропущенное условие, если там небольшой возможный вариант списка. Но с этой рекомендацией нужно быть очень осторожными, т.к., несмотря на то, что при наличии списка дальнейшее использование индекса не отбрасывается, он не может быть использован для сортировки, т.е. только на равенство. Поэтому, если у нас есть запросы на сортировку, то нам придется запрос перестраивать через union all, чтобы не было списков, дабы использовать сортировку. Естественно, это не всегда возможно и не всегда удобно. Если расширение индекса нам, например, позволит сделать индекс покрывающим (имеется в виду, что все поля, которые выбираются и используются в запросе, присутствуют в индексе), тогда сервер понимает, что лезть в таблицу за данными ему совсем не обязательно и он целиком обращается к индексу для формирования результата. Т.к. индекс более упорядочен, компактен и хранится чаще всего в памяти кэшированной, это более удобно. Поэтому мы при составлении индекса смотрим всегда, можем ли мы как-то подобрать покрывающий индекс для нашего запроса.
Далее рассмотрим случаи, когда индексы не используются.

Здесь есть общие нюансы с другими базами, например, когда индекс является частью выражения, как и в PostgreSQL, он не сможет его преобразовать, поэтому, если у нас в запросе id + 1 = 3, индекс на id использован не будет. Мы должны сами переносить. Если индекс является частью какого-то выражения, мы должны смотреть, можем ли мы его преобразовать так, чтобы индекс вынести в левую часть в явном виде.
Аналогично, за счет того, что он не производит преобразований (это не только математические, это могут быть несоответствие кодировок, преобразование типов), индекс тоже не будет использован. Индекс не используется, когда пропускается первая часть, когда идет поиск по суффиксу. Ну и, естественно, индекс не будет использован, когда идет сравнение с полями сходной таблицы, потому что в этом случае ему сначала будет нужно прочитать запись из таблицы, чтобы сравнить.
До этого я упоминал покрывающие индексы, и чем они хороши. Вернемся к слайду с архитектурой:
Происходит так: исполнитель запрашивает данные (условие WHERE) у хранилища, соответственно, если у нас есть условие WHERE на несколько позиций, то они все могут быть обработаны внутри самого хранилища. Это оптимальный вариант. Может быть вариант, когда часть условий будет обработано на уровне хранилищ по индексу, строки, переданные на уровень вверх, сервер будет применять, а дальнейшие условия отбрасывать. Понятно, это будет медленнее, т.к. будет идти передача самих записей из хранилища в исполнитель. Поэтому покрывающие индексы, если они у нас применяются только для тех полей, которые в запросе, выгоднее, т.к. мы выбираем уже меньше строк.
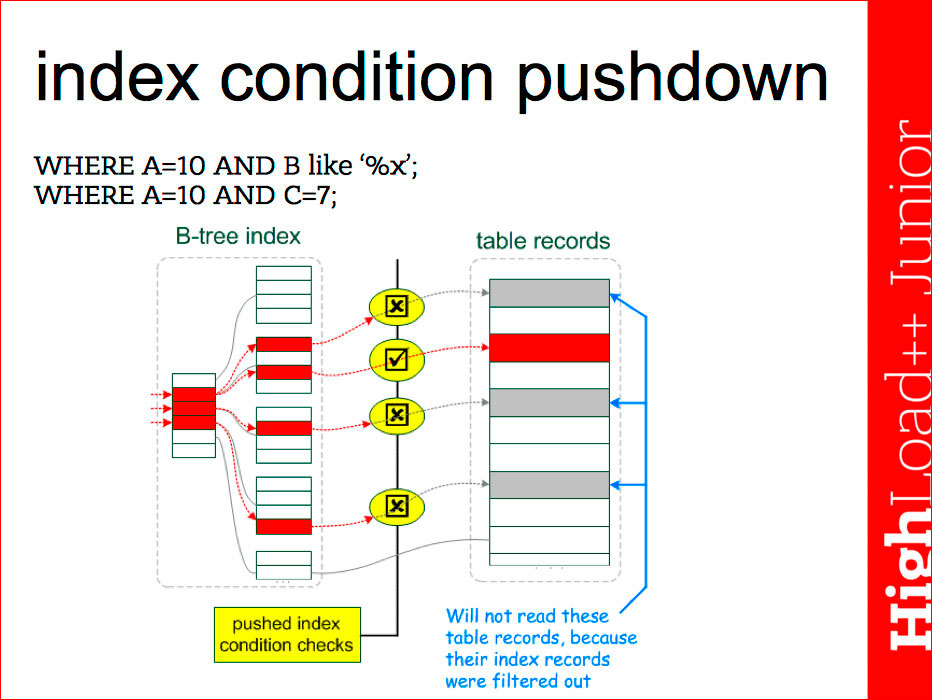
Вот, к примеру, подобная оптимизация, называемая index condition pushdown:

Имеется в виду следующее. У нас есть индекс на три поля — А, В, С. В таких условиях мы можем использовать только часть первого. Казалось бы, мы можем в самом хранилище проверить индексы, но раньше (до версии MySQL 5.6, MariaDB 5.3) сервер этого не делал, поэтому нужно внимательно смотреть на конкретные релизы — что умеет делать сервер. В новых версиях сервер производит поиск по первой части индекса, только по колонке А, выбирает данные и, прежде чем передавать записи исполнителю, он проверяет условие на вторую и третью части и смотрит, нужно ли выбирать целиком записи или нет. Это естественно уменьшает количество тех записей, которые нужно считывать с диска.
Особенность ключей в InnoDB — это то, что вторичные ключи ссылаются на первичный ключ, поэтому фактически вторичный ключ в InnoDB представляет собой вторичный ключ + указатель на первичный ключ.

Такой длинный индекс имеет невидимый «хвост». Невидимый в том смысле, что раньше оптимизатор его в своих действиях не учитывал.
Вот, у нас есть primary (A, B) составной, соответственно, вторичный ключ — это будет составной ключ на (C, A, B) и по нему уже можно проводить поиск.
Таким образом, когда вы работаете с таблицами InnoDB и делаете индексы, вы всегда должны учитывать, что длинный первичный ключ — это может быть либо хорошо, либо плохо в зависимости от того, какие у вас запросы, потому что он будет добавляться ко всем индексам.
Здесь следующий нюанс — эта оптимизация будет учитываться только для фильтрации строк. У нас в отсортированном виде хранятся только значения вторичного ключа, а указатели на первичный ключ не отсортированы, поэтому такой длинный невидимый «хвост» сервер сможет использовать только для условий равенства фильтрации строк. Это доступно в MariaDB 5.5, MySQL 5.6.
Ключевые ограничения оптимизатора — это то, что он исторически использует очень мало статистики. Он запрашивает у хранилищ данные. Вот здесь указано подробнее, что учитывает сервер:
Он может учитывать результаты вводимых команд, поля, количество строк, т.е. довольно-таки мало данных. Особенность в том, что изначально статистика вычисляется следующим образом: мы запускаем сервер или делаем какую-то команду типа ALTER, у нас статистика обновляется, потом таблица живет некоторое время, какой-то процесс вдруг меняется, потом статистика вновь обновляется. Т.е. бывает, что сама статистика не соответствует распределению данных.
Опять же, каждое хранилище выбирает статистику по-своему — где-то больше, где-то меньше. В последних версиях реализуется идея независимой статистики, т.е. статистики на уровне сервера — выделяются служебные таблицы, в которых единым образом уже независимо от механизмов хранения собирается статистика для всех таблиц, причем, если в Percona 5.6. это сделано только для индексов в InnoDB, то в Maria 10 пошли дальше и собирают ее даже для неиндексированных столбцов, за счет чего оптимизатор может выбирать более оптимальные планы выполнения, поскольку лучше понимает распределение данных.
Оптимизатор не учитывает особенности хранилищ — когда мы передаем запрос в хранилище, то, понятно, что в InnoDB поиск по вторичному ключу будет идти дольше, потому что мы пройдемся по вторичному ключу, получим указатели на первичный ключ, возьмем эти указатели, пойдем за данными, т.е. у нас будет двойной проход, а в MyISAM, например, будут сразу указатели непосредственно на сами строки. Вот подобных нюансов относительного быстродействия тех или иных частей (у нас запрос может одновременно обращаться к разным хранилищам) оптимизатор и не учитывает. Он также не учитывает очень много вопросов, связанных с оборудованием, т.е. какие данные у нас закэшированы, какие буферы…
Метрика. Понятно, что оптимизатор выбирает самый дешевый план, но дешевый план с точки зрения оптимизатора — это план с наименьшей стоимостью, а вопрос стоимости — это некоторая условность, которая может не совпадать с нашими представлениями о ней. Опять же, сложность выбора — это когда много таблиц и нужно их по-разному перемещать и смотреть.
Еще он использует правила, т.е. если он, например, понимает, что нужно использовать full text index, то он использует его, даже несмотря на то, что у нас может быть условие на первичный ключ, которое однозначно выдаст одну колонку.
Есть еще такой нюанс — эти две записи с нашей точки зрения эквивалентны:
where a between 1 and 4
where a >0 and a < 5
, но с точки зрения сервера MySQL — нет. В случае, когда а>0 и а<0 он будет использовать поиск по диапазону, а в случае, когда мы напишем то же самое через «between», он может это преобразовать в список и использовать условие на множественные равенства.
Такие нюансы не позволяют писать запросы, опираясь на здравый смысл, но с другой стороны удобно тем, что повышает востребованность специально обученных людей по оптимизации MySQL. :)
Коротко о том, как работает оптимизатор.
Он проверяет запрос на тривиальность, т.е. может ли он, вообще, сделать запрос, опираясь только на статистику индексов. Может быть, мы запрашиваем отрицательные значения для колонки ID, которая определена положительно. Тогда он сразу понимает, что мы запрашиваем за пределами диапазона. Это очень эффективный вариант с точки зрения быстродействия — выбирает самый дешевый план.
Казалось бы, оптимизатор может делать очень мало вещей, на самом же деле при математическом преобразовании запроса он применяет различные техники, например, подзапросы может либо ухудшить, как в старых версиях, сделав независимое зависимым, либо улучшить, как в новых. Список техник очень велик.
Это начало таблицы из документации на MariaDB:
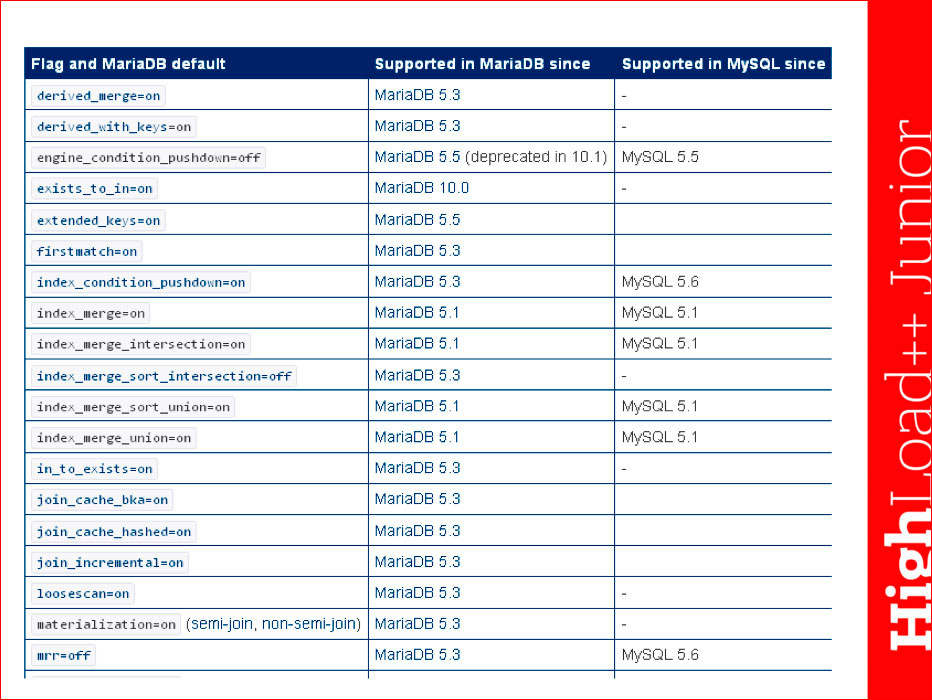
Нужно знать, что скрывается за всеми этими словами, поэтому я рекомендую смотреть документацию на MariaDB, т.к. она снабжена понятными картинками-иллюстрациями, и по ним можно понять, что к чему относится.
Как мы можем влиять на оптимизатор:

- Переписать запрос — это либо использовать эквивалентную форму записи, т.е., например, подзапрос заменить на join, либо же переписать запрос кардинально,
разбив на части, записывая какие-то данные во временные промежуточные таблицы, или же, вообще, денормализовать таблицу и избавиться от join’ов. - Индексы — мы можем либо добавлять необходимые индексы, либо смотреть, может, нам достаточно обновить статистику.
- Подсказки оптимизатору — use/force/ignore index — можем ему явно указать, какие индексы стоит использовать для каких операций — для сортировки,
группировки и пр. - straight_join — мы можем задать жесткий порядок объединения таблиц, чтобы он не перебирал различные варианты. Нам известны особенности распределения
данных и известно, в каком порядке нужно работать, поэтому явно на это указываем. - @@optimizer_switch — включение/отключение всех конкретных добавочных методик оптимизации через эту переменную.
- Переменные optimizer_prune_level и optimizer_search_depth определяют, как сервер выбирает оптимальный план — перебирает все возможные варианты или
отбрасывает. Понятно, что когда у нас много таблиц join’ится, и сервер будет несколько миллионов перестановок анализировать, он может уйти на четверть часа
в задумчивость, а потом за долю секунды выполнить. Такие ситуации встречаются, поэтому все эти переменные по умолчанию ограничивают время выполнения, что
приводит к тому, что план может быть выбран неоптимальный. Когда мы производим оптимизацию, в режиме тестирования мы можем изменить эти переменные, чтобы
сервер выбирал все варианты, и посмотреть, может, будет выбран более оптимальный план.

SQL_CALC_FOUND_ROWS — это страшное слово, которое напрочь убивает оптимизацию. На практике идея состоит в том, что если у нас есть запрос LIMIT, мы можем включить ключевое слово в запрос, и сервер нам при этом отдаст в ответе, в том числе, и общее число, которое было бы выбрано без лимита. Это удобно, например, когда мы делаем пагинацию страниц, и этим грешат все автоматические системы. Это плохо, потому что запросы на COUNT MySQL умеет оптимизировать очень хорошо, но в сложных случаях, когда у нас есть join’ы, группировки и пр., отдельно посчитать количество строк, мы можем переписать запрос так, что часть объединений, join’ов нам не потребуется, часть группировок тоже, чтобы получить ответ об общем количестве страниц.
Сервер использует на один запрос только один метод. Когда мы добавляем FOUND_ROWS, он решает две задачи одним методом, т.е. он на самом деле выбирает все строки, как если бы не было LIMIT, из хранилища вытаскивает данные — все длинные записи, считает, отбрасывает лишние… Это очень плохо. Здесь нужно понимать, что тот же COUNT (*) не читает сами строки, он просто просматривает их на факт наличия, не передавая данные в читалку.
На таком уровне нужно знать детали, чтобы понимать, иначе просто смотреть на EXPLAIN будет не очень осмысленно.

Недостатки EXPLAIN следуют из недостатков оптимизатора. Бывают случаи, когда он, вообще, пишет не то, что делает, выдает очень мало информации, когда мы говорим, что EXPLAIN не выполняет запрос, а просто составляет план. В старых версиях он выполнял from подзапросы, т.к. from подзапросы он материализовал во временную подтаблицу и если они тяжелые, то выполнение этих from подзапросов занимало очень много времени. И была даже коллизия с тем, что from подзапрос может содержать пользовательскую функцию, которая будет менять данные, тогда сам EXPLAIN тоже бы менял данные. Непонятно, зачем это нужно, но на практике люди придумывают иногда очень странные вещи.

Виды EXPLAIN.
Если используем ключевое слово PARTITIONS, тогда он будет показывать, какие секции использует наш запрос.
Ключевое слово EXTENDED удобно тем, что он при этом формирует SQL-запрос, который восстанавливает из плана выполнения. Это не исходный SQL-запрос, исходный SQL-запрос преобразован в план, а потом из плана уже оптимизатором синтезируется новый SQL-запрос, который содержит ряд подсказок, по которым мы можем понять, что у нас происходит. Формирование временной таблицы с ключами, кэширование каких-то кусков запроса — все эти нюансы хорошо описаны в документации и они помогают понять, что делает сервер, как преобразовывает наш запрос.
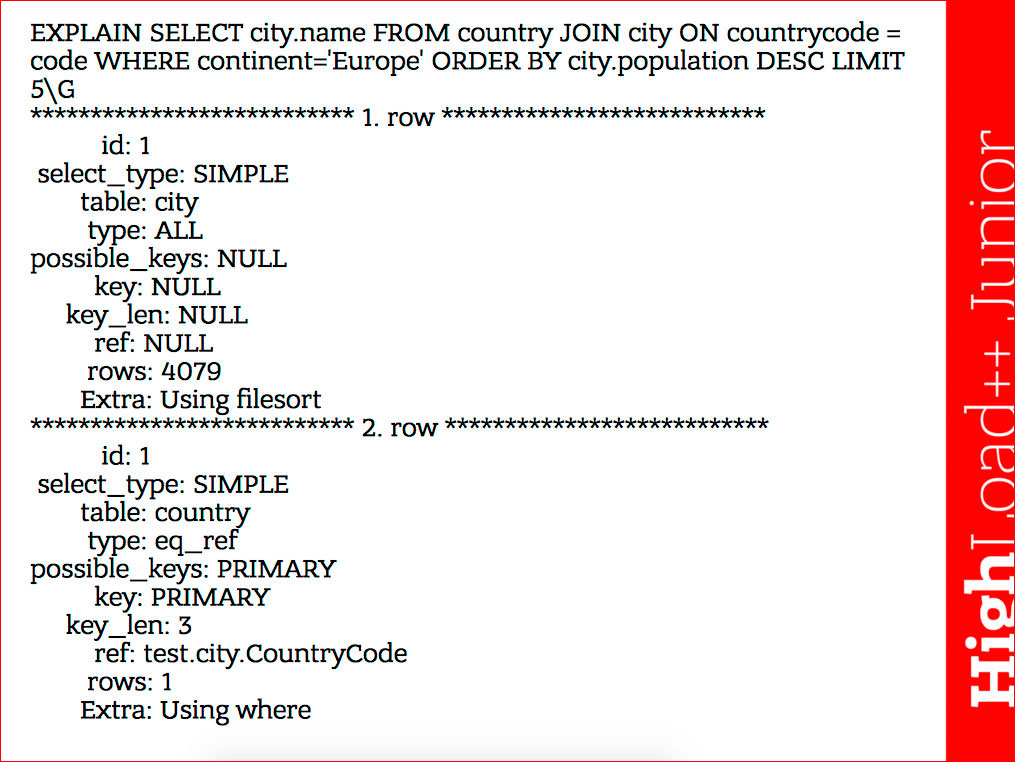
Это, собственно, EXPLAIN простейшего запроса.
Здесь нужно смотреть на следующее:
- тип доступа, который используется. В первом случае это ALL — идет сканирование всей таблицы. Во втором случае eq_ref — это поиск непосредственно по
ключу, формирует одну запись. - количество строк, которое ожидается, учитывая, что это некая условность.
- possible_keys — это ключи, которые оптимизатор планирует использовать, а key — ключ, который он выбрал. Возможен вариант, если у вас, например,
possible_key: NULL, а в значении key стоит какой-то ключ. Это происходит в тех случаях, когда, например, SELECT FROM таблицы никаких условий WHERE нет.
Оптимизатор видит, что, вроде как, никаких ключей использовать не надо, а потом смотрит, что столбцы являются частью ключа и, в принципе, можно их выбрать
именно по индексу и тогда делать покрывающий индекс. Так может получиться, что possible_key: NULL, а key — покрывающий индекс, это значит, что он будет
использовать именно индекс. - key_len — это длина индекса, которую он использует, т.е., если у нас составной индекс, то взглянув на key_len, мы можем понять, какую часть индекса он
использует.
Далее мы не будем рассматривать подробно все возможные варианты — это хорошо описано в документации.
Понятно, что он формирует по одной строке для каждой таблицы, которая встречается в запросе, и исполняет запрос в той последовательности, в какой выводится таблица, т.е. глядя на EXPLAIN, мы можем сразу понять, что был выбран следующий порядок доступа к таблицам — сначала выбирает таблицу city, потом выбирает таблицу country. Здесь все просто.
Но, когда у нас есть такой сложный навороченный EXPLAIN, который включает разные UNION, FROM подзапросы и пр., и выводится длинная «простыня»:

Возникает вопрос — как ее читать?
Идея очень проста: мы нумеруем все SELECT’ы, которые встречаются в запросе, и номер SELECT’а будет соответствовать номеру идентификатора, который в EXPLAIN’е.

Я выделили разными цветами для наглядности.
Второй нюанс — мы можем смотреть на номера. Например, номер 6 — DERIVED — это FROM подзапрос. Следующий идет с бОльшим идентификатором. Это означает, что он относится к тому же подзапросу FROM, т.е. пойдет в ту же временную таблицу. Таким образом, глядя только на идентификаторы, уже можно сделать много выводов.
Существует неудобство: я говорю, что строки выполняются последовательно, на самом же деле, когда есть такие вещи как производные таблицы, это не совсем так. Т.е. запросы с UNION’ами удобно читать таким образом — один UNION у нас 4, и это означает, что строки с 1й по 4ю относятся к одной части UNION’а, а с 4й по последнюю — ко второй части. Т.е. мы можем посмотреть последнюю строчку и перейти вверх, и так разбивать запросы. Собственно, ничего сложного в этом нет, нужен только навык.
Есть утилиты, которые сразу строят графические представления EXPLAIN’а, но мы их не будем рассматривать, тем более, что в случае сложных запросов их тоже не так-то просто понять. Это на любителя.
Пример, когда EXPLAIN врет.

У нас есть запрос с подзапросом в части in. Подзапрос независимый, тем не менее MySQL до MariaDB 5.3 и MySQL 5.6 эти запросы часто выполнял как зависимые. Мы видим тип запроса — зависимый, но с другой стороны мы видим type: index_subquery — это означает, что на самом деле подзапрос не выполняется, а заменяется на функцию просмотра индекса. Т.е. эти строчки между собой конфликтуют, они говорят о противоположных вещах.
Возникает вопрос —, а что же на самом деле там происходит, т.к. EXPLAIN выдает противоречивую информацию?
Мы можем сделать профайлинг запроса и посмотреть:
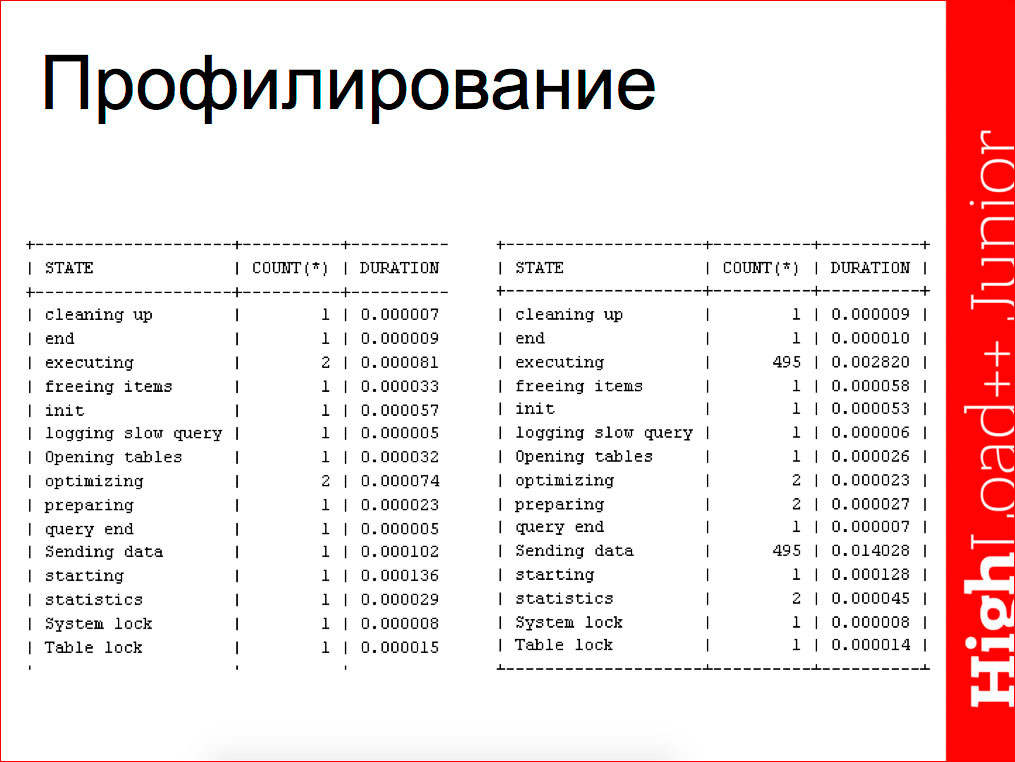
В случае, когда запрос выполняется зависимый, как справа, у нас часть исполнения запроса — передача данных — будет многократна, будет дублирована. В случае, когда запрос выполняется независимо, эти значения дублироваться не будут.
Кроме того, профайлинг удобен для определения таких нюансов, как передача больших данных, подсчет статистики и др.
Сортировка.

Когда ORDER BY id LIMIT 10000, 10 — это плохо, т.к. сервер будет выбирать все 10 тыс. строк + еще 10, потом 1001-ю отбрасывать и только 10 выдавать. Такие вещи надо каким-то образом менять. Либо ID больше 10 000, LIMIT 10. Когда у нас offset большое число — с точки зрения того, что делает сервер, это плохо.
Нельзя использовать ORDER BY rand (), т.к. эта структура делает копию всех наших данных, загоняет во временную таблицу, добавляет туда еще один столбец, куда записывает результат функции rand и потом файловую сортировку всего этого огромного массива. Поэтому, если мы хотим выбрать случайную строку, ORDER BY rand () можно применять лишь на небольших объемах данных, на больших это сразу убьет всю производительность.
Группировка по умолчанию делает и сортировку, поэтому, если нам сортировка не нужна, то мы должны указать в явном виде — ORDER BY null.
Остальное мы уже выше рассмотрели.
Такой пример:
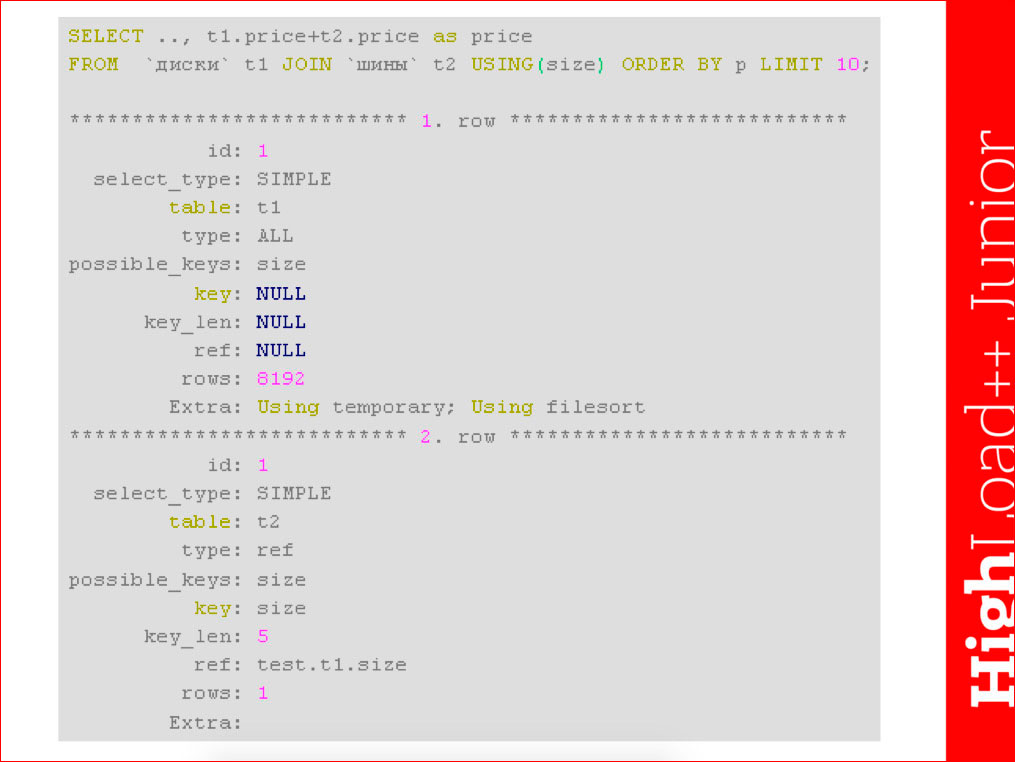
Есть таблица дисков и таблица шин в интернет-магазине автозапчастей. Мы хотим показать клиенту 10 наиболее дешевых комплектов, т.е. шины к каким дискам подходят, и выбрать наиболее дешевый комплект. Понятно, что запрос «в лоб» мы просто join’им и сортировку производим по вычисляемому полю. Мы видим: полное сканирование первой таблицы плюс выбираются данные из второй. Никаким добавлением индексов мы сделать здесь ничего не сможем. В таких случаях нужно смотреть, как мы можем переписать запрос.
Можем схитрить и сказать, что 10 самых дешевых комплектов — это 10 самых дешевых колес + соответствующие им диски, прибавить 10 самых дешевых шин + соответствующие им колеса. Это некая условность, т.к. это не совсем эквивалентно и можно подобрать такое распределение данных, когда это не будет выполняться. На практике это, как правило, не происходит. Если нам не очень важна точность, то мы можем усложнить запрос в явном виде, и мы увидим, что план, несмотря на то, что он стал гораздо больше, каждый раз он выбирает по индексу, и сортировки внутренние происходят не без Using filesort, файловой сортировки. А конечная строка Using filesort’а — небольшое число значений.

Основная стратегия, когда мы видим сортировку: смотрим, можем ли как-нибудь избавиться от файловой сортировки, загнав ее вглубь запроса. Если не можем, то можем ли как-то ограничить количество строк, которые мы вынуждены делать файловой сортировкой.
Здесь еще стоит обратить внимание на то, что в самих частях UNION’а еще делается вложенный from подзапрос и сортировка переносится вглубь. Если этого не сделать, то сервер ошибочно не будет использовать файловую сортировку, т.е. отдельно, без части UNION’а, диски+колеса сортировка сделает по индексу, а внутри он уже не понимает. Надо учитывать, что оптимизатор в таких сложных вещах может ошибаться, и следить за этим.
В продолжение про ORDER BY + LIMIT запрос, который делает WordPress.

Большинство проблеем с производительностью — это такие ужасные запросы, где сервер выбирает абсолютно все записи, т.е. все текстовые строки, сортирует этот большой массив и в конце выдает только 3 записи. При этом, естественно, здесь будет Using filesort по огромному количеству записей. Т.к. мы не можем использовать способ, аналогичный предыдущему, т.е. уменьшить количество строк для сортировки, мы можем уменьшить ширину записей для сортировки и сначала отсортировать, выбрать на первом этапе не сами записи, а только их идентификаторы, т.е. разбить запрос на 2 части.

Мы делаем временную таблицу, где выбираем только идентификаторы. Глядя на этот запрос, мы увидим, что группировка в этом запросе совершенно не нужна, потому что возможное дублирование удаляется условием category_ID=1, поэтому, когда мы переписываем запрос, мы лишние группировки и пр. убира
