Оркестратор бесконечных задач

В данной статье мы поговорим о том, как реализовать оркестратор бесконечных задач с использованием очередей. Как конечная цель- нам необходимо реализовать систему, способную управлять задачами с длительным сроком жизни, систему распределённую, где группа задач хостятся на определенном сервере и в случае отказа этого сервера, задачи автоматически перераспределяются на свободные.
В большинстве случаев вся enterprise разработка сводится к выполнению одних и тех же требований: создается заявка, в зависимости от типа заявки у нее есть какой-то жизненный цикл, по завершению жизни заявки мы получаем (…или не получаем) желаемое. Под заявкой мы можем подразумевать все что угодно, начиная с покупки в интернет-магазине товара, денежного перевода или расчета траектории баллистической ракеты. У каждой заявки есть свой жизненный путь и что важно отметить — время жизни, и чем меньше это время, тем лучше. Иными словами, чем быстрее мой банковский перевод осуществится, тем лучше. Требования тоже схожи, побольше RPC operations per second, поменьше Latency, система должна быть отказоустойчивой, масштабируемой и должна быть готова вчера. Есть миллион инструментов, сотни баз данных, различные подходы и паттерны. И все уже давно написано, нам остается лишь правильно использовать готовые технологии в наших проектах.
Тема оркестрации задач не нова, но к моему удивлению, готовых решений по управлению бесконечными задачами (время жизни которых неограниченно велико), с возможностью перераспределения задач по активным серверам, попросту нет. Поэтому реализуем собственное решение. Но обо всем по порядку….
Давайте сначала поймем, что значит бесконечная задача и где в природе такое вообще может встречаться. Бесконечная задача — это некий процесс (Job), который выполняет работу до тех пор, пока ему не скажут прекратить это. Аналогию можно провести с бесконечными циклами. В природе же подобное встречается, когда нам нужны «наблюдатели», которые следят и реагируют на определённые события. Например: нам необходимо следить за изменениями цен на бирже, повышением или понижением цены актива. Представим нам нужно следить за всеми валютами, всеми активами, на разных биржах, тогда количество наблюдателей может превышать десятки тысяч единиц. Что же из себя может представлять «наблюдатель»- это может быть отдельное WebSocket соединение, которое должно быть постоянно connected. Этот наблюдатель, может получать данные, денормализовывать, производить расчеты, сохранять и много чего еще. Для удобства, «наблюдателем» я буду называть не Observer из известного паттерна, а модуль, который постоянно в работе и бесконечно долго выполняет полезную работу.
Очевидно, нам нужна распределенная система, так как на ноутбуке ее явно не запустишь. Сформулируем требование для наших наблюдателей:
Наблюдатели должны быть управляемы, то есть мы можем как добавить нового, так и прекратить работу существующего.
Наблюдатели должны быть изолированными, работа одного, никак не должна сказываться на работе других.
Система должна быть отказоустойчивой, и горизонтально масштабируемой, мы должны иметь возможность распределить всех наблюдателей на разных серверах. Причем при отказе одного сервера, наблюдатели, которые на нем находились, должны перераспределиться на другие, работающие сервера.
Сервис/приложение, должно иметь ограничение на количество наблюдателей, которые могут быть в работе и задаваться данное значение должно через файл конфигурации или рассчитываться исходя из мощности сервера (количество ядер, RAM и т.д.), на котором сервис работает.
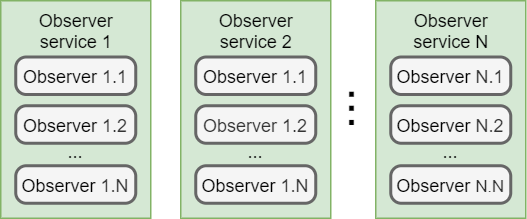
Упрощенно: имеем N Сервисов, каждый сервис имеет несколько наблюдателей. Пока не будем задаваться вопросом о том, как это все работает и каким образом компоненты взаимодействуют, разберем это чуть позднее.
Статья описана в 3 актах. Все листинги с кодом на С#, но в процессе написания старался уделять меньше внимания примерам с кодом и больше самой идеи. Поэтому листинги должны быть понятны даже тем людям, которые вообще не писали на C# и не знакомы с .Net.
Все есть Task. Тут мы поговорим о теории и некоторых базовых концепциях. Разберем что есть Task и что общего между таской и «наблюдателем».
Schedulers. Возьмем готовое решение, разберем его и проанализируем. Понимание концепции работы планировщика с возможностью запуска задач на удаленных серверах, может нам лучше понять, что будет происходить в третей части.
Очередь, которая думает, что она планировщик. Финальная часть статьи, где мы реализуем систему оркестрации задач через очереди сообщений. Я использовал RabbitMq, и как Framework — MassTransit, поэтому все примеры будут тесно связаны с данными инструментами. Но принцип будет оставаться тот же.
Всё есть Task
Наш наблюдатель это ни что иное как Task. И что делать если мы хотим запустить и контролировать таску, не дожидаясь получения результата (ведь если наша таска будет работать бесконечно, то она и не даст нам никогда результат).
Рассмотрим на простом примере. Возьмём метод, который пишет «Hello Word» в консоль отправляет письмо:
public async Task SendEmailAsync(Email email, CancellationToken token)
{
// отправляем письмо
}Чтобы отправить письмо, не дожидаясь получения результата, нам достаточно просто забыть поставить await перед вызовом SendEmailAsync.
foreach (var email in emails
{
if(token.IsCancellationRequested)
break;
_emailSender.SendEmailAsync(email, token); //нет await
} Минусов у данного подхода много:
Мы никак не гарантируем выполнение отправки письма.
FireAndForget и как следствие о возникновении Exception мы не узнаем.
Так же не узнаем и о выполнении.
Многие считают, что это грех большой, вообще антипаттерн и я с ними согласен.
Более детально о том почему желательно рано или поздно await-ить таску, можно почитать про async/await антипаттерны .
Наша задача во многом похожа на отправку email, только внутри у нас будет подобие бесконечного цикла и метод закончит работу естественным путем только тогда, когда будет вызван CancellationToken. Мы можем, конечно, написать свои костыли, которые позволят нам отслеживать состояние задачи и уведомлять, когда она завершилась. У нее будут RetryPolicy и много чего ещё, но зачем?! Когда есть уже готовые планировщики задач, которые заточены под данные требования.
Schedulers
На .NET есть как минимум два планировщика задач с промежуточным хранением задач в базе данных, поддержкой отложенного выполнения и возможностью распределенного выполнения на разных серверах.
Тут есть неплохое сравнение планировщиков. Больше всего нас интересует возможность иметь неограниченное количество серверов, (тут может быть недопонимание, сервер — это не физическая машина, где выполняется наше приложение, это instance планировщика) где будут исполнятся наши задачи/Tasks. Лично я отдал предпочтение Hangfire, по большей части из-за хорошо описанной документации и встроенного UI, который позволяет не только отображать метрики по задачам, но и вручную запускать их. Всё это весьма приятные бонусы.
А теперь посмотрим на то, как отправить наше письмо с использованием Hangfire. В этом нам поможет статический метод BackgroundJob.Enqueue (Expression
var jobIds = new List();
foreach (var email in emails)
{
if(token.IsCancellationRequested)
break;
jobIds.Add(BackgroundJob.Enqueue(
async () => await _emailSender.SendEmailAsync(email, token)));
} Мы не дожидаемся отправки всех писем, а кладем их в очередь и можем не переживать за выполнение, обо всем позаботиться планировщик. Есть настройка RetryPolicy , через которую мы можем задать количество повторений вызова метода в случае ошибок. В итоге мы знаем сколько задач было выполнено успешно, сколько с ошибками, сколько времени потребовалось на выполнение каждой.
Но нас же интересует не просто запустить задачу и гарантировать ее исполнение, а иметь возможность запустить ее на другом сервере. Забудем уже про отправку писем и представим, что наш «наблюдатель» запускается через вызов метода:
_observer.DoWork(observerArg, new CancellationToken())
Мы передаем какие-то аргументы для работы и главное, передаем токен отмены. Для этого нам потребуется указать еще имя очереди в созданном BackgroundJobClient.
var client = new BackgroundJobClient(JobStorage.Current);
//задаем имя очереди, где будет хоститься задача.
var state = new EnqueuedState("unique-queue-name”);
client.Create(() =>_observer.DoWork(observerArg, new CancellationToken()), state);И конечно же мы должны иметь сервис, который займется обработкой данной очереди. В настройках которого будет указано имя той самой очереди- unique-queue-name.
// Настраиваем instance hangfire сервера.
_server = new BackgroundJobServer(new BackgroundJobServerOptions()
{
WorkerCount = 10,
Queues = new[] { "unique-queue-name” },
ServerName = _serverOptions.ServerName
}); WorkerCount — отвечает за то, сколько сервер может одновременно обрабатывать задач. Запомним ее, так как в последствии мы о ней будем много говорить.
Теперь у нас есть возможность запускать любое количество задач на разных серверах, указывая очередь, которую слушает сервис. Пока нам не хватает только одного: возможности мониторинга. Мы должны понимать какой сервер свободен, а какой нет и запускать задачи на свободном. Для этого в Hangfire есть статический класс, которой предоставляет все метрики, начиная с того сколько серверов сейчас активно и заканчивая информированием о том сколько раз задача была выпалена с ошибкой.
_monitoringApi = JobStorage.Current.GetMonitoringApi(); Наша система с планировщиком теперь будет выглядеть следующим образом:
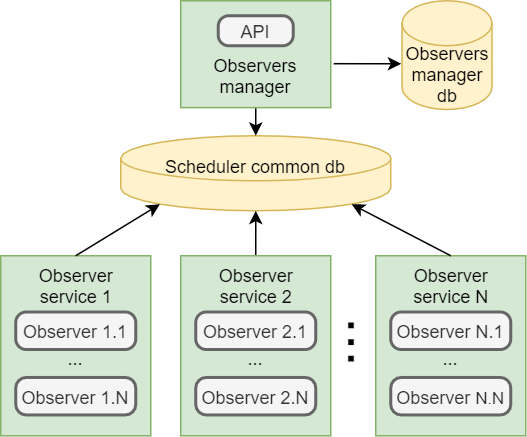
Observer-service — сервис, который может выполнять одновременно несколько задач, количество задается через конфиг или рассчитывается с учетом количества ядер и мощности сервера (В HangFilre это WorkerCount ).
Observer-manager — сервис, который отвечает за… наблюдателей. Валидирует запросы, решает на каком сервисе будет запущен наблюдатель, а также имеет возможность удалить его. Он знает сколько сейчас доступно сервисов и на сколько каждый из них загружен.
Scheduler common db — псевдо-очередь и хранилище всей информации по задачам, Hangfire поддерживает как MsSql, так PostgreSql и даже Redis.
Отправка задачи в очередь — это сохранение в базу данных с предварительной сериализацией ее вместе со значениями входных параметров. Поэтому менеджер и сервис должны иметь доступ к одной сборке с кодом нашего «наблюдателя».
Если зависимости, при проектировании системы в общей сборке, имплементированы в сервисе, то их не обязательно копировать со всем функционалом в менеджер, достаточно имплементировать как заглуши, без логики, ведь исполняться они будут на стороне сервиса.
С помощью планировщика мы можем запускать задачи на удаленных сервисах, мониторить состояние задач и останавливать их, когда нам это потребуется. Но поговорим о проблемах, с которым столкнулся и подведем итог с учетом наших изначальных требований. Так же перед использованием планировщика обязательно прочитайте статью о поддержке очередей в Hangfire. Так вот:
1) Общая сборка для менеджера и сервиса. Не могу сказать, что это прям минус, главное помнить это при проектировании системы.
2) Высокая нагрузка на сервер. Каждый сервис опрашивает базу данных на предмет изменений. Можно, конечно, увеличить интервал между запросами, но это ухудшит отклик системы.
3) Добавление задачи в очередь возвращает числовой идентификатор и идентифицировать задачу можно только по нему. Нельзя задать свой custom-id, например поиск по названию. Поэтому получив идентификатор задачи нужно сохранить связку идентификатор-название в собственное хранилище.
4) В случае ошибки во время исполнения задачи, она автоматически будет перемещена в «default» очередь. Крайне неприятный момент, о котором узнал уже на этапе тестирования, так как в документации о таком не рассказали. Решается через job-filters или через атрибуты. Второй вариант делает код более связанным и не подходит, так как значение атрибута не может задаваться динамически.
5) В случае если сервер откажет, задачи, которые на нем исполнялись, не будут перераспределены между работающими. Можно, конечно, реализовать данную логику в менеджере и сделать его ответственным за это, но хотелось бы чтобы framework умел это из коробки.
6) Отсутствие транзакционности, Ведь Hangfire универсален как для MsSql, так и для Redis, а в нем транзакции не предусмотрены.
На протяжении всей разработки, меня не покидало ощущение что систему можно реализовать гораздо проще. Некоторые фичи, такие как перераспределение задач, не предусмотрены в планировщике, приходилось обходить ограничение, путем добавления собственных костылей и посему было принято решение реализовать собственное решение.
Очередь, которая думает, что она планировщик
Намучившись, пытаясь использовать верблюда как лошадь, перейдем к описанию того, как это можно сделать через очередь. Но сперва зададимся вопросом. Что мы знаем о планировщиках? Мы знаем, что планировщики — это системы, которые выполняют задачи с учетом заданных правил, расписания. А что мы знаем об очередях, шинах данных? Мы используем очереди как транспорт данных, как средство доставки сообщений. Конечно же это все очень абстрактно, и тут можно говорить часами, но пока ограничимся этим. Давай те изменим шаблонное мышление и на время представим, что очередь тоже может быть планировщиком.
Как же сделать из очереди сообщений планировщик задач? Хотя тут корректней был бы термин «оркестратор». Весь вышеописанный функционал решается использованием только одной настройки- PrefetchCount и особенностью обработки сообщений.
Когда сообщение попадает в очередь оно имеет состояние Ready.
Когда Conumer обрабатывает сообщение, оно переходит в состояние Unacked. И другой Consumer может взять следующие сообщение из очереди.
Если в момент обработки сообщения происходит ошибка, оно помещается в _Error очередь.
Если сообщение после обработки не было acknowledged, то оно возвращается обратно в очередь и его может прочитать любой другой Consumer.
И теперь главное — PrefetchCount это количество одновременно обрабатываемых сообщений в очереди, а если сообщение никогда не будет дочитано (бесконечно обрабатывается), то его можно воспринимать как WorkerCount, прям как у Hangfire.
Разберем на пальцах:
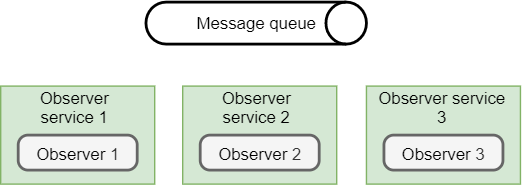
На данной схеме у нас есть три Observer-services, каждый из них слушает очередь в ожидании поступления сообщения. PrefetchCount у каждого стоит 1. Это значит, что за раз каждый сервис будет обрабатывать одно сообщение. А так как мы знаем, что сообщение это запуск бесконечной задачи, то оно никогда не прочитается и всегда будет в состоянии Unacked.
Дадим команду на создание двух «наблюдателей», таким образом в очереди у нас окажется два сообщения:
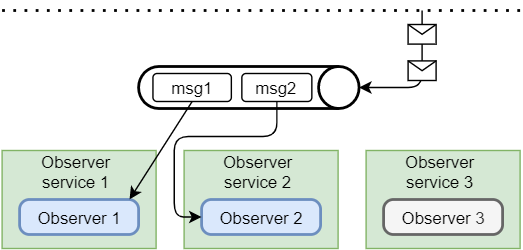
Так как Observer-services слушают одну и ту же очередь, то сообщения между ними будут распределятся равномерно, через Round-robin.
msg1 поступает в очередь. Его начинает обрабатывать один из свободных консьюмеров, допустим «Observer 1». Сообщение переходит в состояние Unacked и теперь новые сообщения, которые поступят в очередь будут доступны для других консьюмеров.
msg2 поступает в очередь. «Observer 1» у нас уже занят, и поэтому сообщение на обработку достанется всем свободным консьюмерам, в данном случае оно достается «Observer 2».
Давайте теперь представим, что «Observer-service 1» у нас сломался, например он находится на отдельном сервере и сервер вышел из строя (самый популярный контраргумент — »а что… если свет вырубили?»).
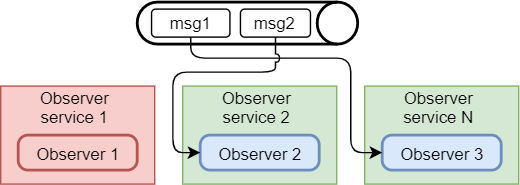
Ошибка произошла не в самом консьюмере, и поэтому сообщение, по которому не было acknowledgement попадает обратно в очередь и переходит из статуса Unacked в Ready. Теперь его может считать любой свободный консьюмер. Второй у нас занят, первый умер, свободен только третий и поэтому ему задача и достаётся.
Резонным будет замечание — что будет если ошибка произойдет в самом консьюмере, в процессе обработки сообщения. Оно в таком случае прейдёт в очередь с пометкой _Error, чтобы этого избежать можем настроить RetryPolicy. И тогда в случае ошибки сообщение не попадет обратно в очередь, а консьюмер попытается заново обработать это сообщение.
Правила для RetryPolicy могут быть гибкими:
Попробовать 1000 раза и положить в очередь ошибок.
Попробовать 5 раз с интервалом 1,4,10… минут и потом положить в очередь ошибок.
Вообще попробовать int.MaxValue раз.
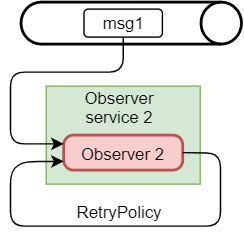
Что же мы имеем в итоге? Мы можем иметь абсолютно любое количество «наблюдателей», каждый из которых смотрит на одну очередь и каждый обрабатывает свою задачу/сообщение. Мы можем увеличить PrefetchCount, допустим до 10, и тогда у сервиса будет 10 свободных консьюмеров, которые будут ждать команды на работу. Сервисы можно распределять по разным серверам и если мы допускаем что кой-то сервер может выйти из строя, нужно просто иметь свободный сервис, который в случае поломки возьмет задачи больного. Например, если у нас есть 10 серверов, мощностей каждого из которых достаточно для обработки 5 «наблюдателей», и шанс того, что один процент из них может выйти из строя, нужно задеплоить один 11-ый сервер с той же мощностью, который будет на подстраховку.
А как же консистентность? Да и как вообще всем этим управлять? Да, мы можем добавить сообщения в очередь, но как убрать их оттуда… не очищать же очередь вручную?! Тем более, в идеале, наши «наблюдатели» должны закончить свою жизнь естественным образом, то есть через вызов CancellationToken.
И тут нам снова потребуется Manager. Менеджеру неплохо бы знать об активных сервисах в системе. Это позволит понимать, перед запуском задачи, сколько свободных сервисов и может ли один из них взять в работу новую задачу. Так же это даст возможность отображать сколько их в системе, на сколько каждый из них загружен и какие задачи обрабатывает. Поэтому, когда сервис только поднимается он отправляет сообщение о своем рождении, которое содержит:
Id (Идентификатор) — Guid генерируемый при рождении.
Name (Имя), которое мы сами дали ему, когда сервис деплоили, оно уникальное для каждого сервиса.
CreatedAt/ModifyAt (Дата создания/Дата изменения).
WorkersCount, это будет PrefetchCount — его мощность, сколько он может обрабатывать задач одновременно.
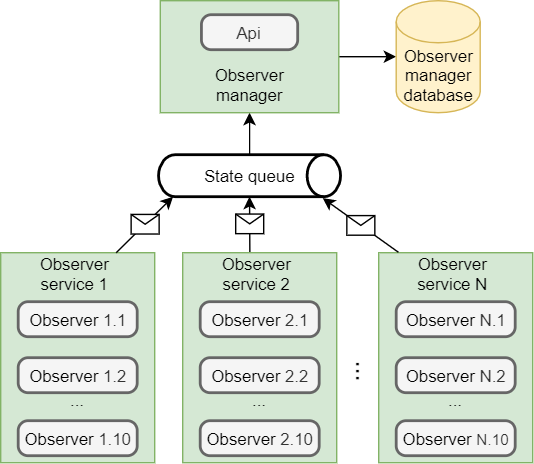
Manager принимает эти сообщения с делает записи в базу данных о новых активных сервисах.
Id | Name | WorkerCount | CreatedAt | ModifyAt | IsDeleted |
{Unique id} | Observer service 1 | 10 | {some date} | null | false |
{Unique id} | Observer service 2 | 10 | {some date} | null | false |
{Unique id} | Observer service 3 | 10 | {some date} | null | false |
И нам не важно работает ли менеджер или мы вообще забыли его задеплоить. В тот момент, когда он заработает ему сразу придет информация о том, что в системе есть 3 сервиса с такими-то параметрами.
Перед отключением сервисы так же отправят сообщения о том, что они закончили работать и больше недоступны, менеджер будет знать, что теперь на N сервисов у него меньше в строю. Тем самым он сделает пометку в базе данных и проставит каждому удаленному значение IsDeleted=true.
Есть вероятность с тем, что сервис может не успеть отправить свое последнее сообщение о прекращении работы (Kill –9, все тот же свет вырубили). За работоспособность компонентов у нас должна отвечать инфраструктура, например Docker. Мы должны быть уверены, если сервис непредвиденно прекратил работу, контейнер пере поднимется и сервис заново начнет работу. В таком случае при «рождении», он заново отправит сообщение, но уже с новым идентификатором, но старым именем. Менеджеру достаточно будет данной информации чтобы привести данные в консистентное состояние и понять, что со старым сервисом случилось что-то …страшное.
А теперь попробуем создать нового «наблюдателя» через API. Отправляем команду на создание (Мы должны позаботиться о том, что менеджер в процессе инициализации прочитает все сообщения из «State queue» и будет содержать последние актуальные данные о состоянии сервисов). Менеджер проверяет есть ли «наблюдатель» с таким именем уже, если нет, он проверяет наличие свободных сервисов, а они пока все свободны, далее он дает команду на создание — кладет сообщение в очередь.
Мы уже знаем, как распределится данное сообщение, оно просто достанется одному из «наблюдателей». И тогда, когда он его получит, задача будет запущена и наблюдатель отправит сообщение в очередь состояний о том, что он получил на обработку определенную задачу, указав метаданные задачи и сервиса в рамках которого она работает.
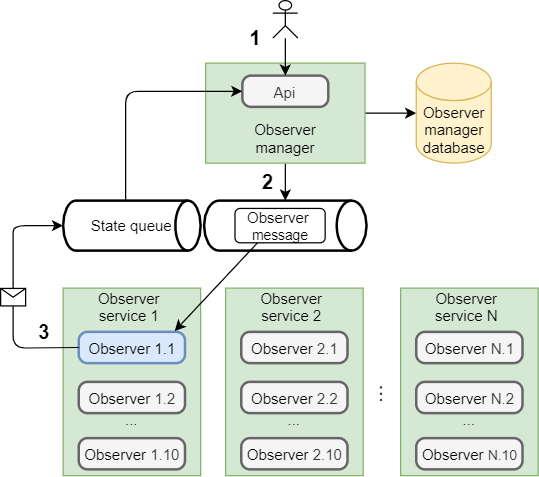
Менеджер при отправке сообщения делает пометку в базу данных, записывая информацию о том, что был создан новый «наблюдатель» и находится в статусе Created.
Id | Name | CreatedAt | ModifyAt | ServiceId | Status |
{Observer id} | My_new_observer | {created date} | null | null | Created |
Менеджер, дождавшись ответа от сервиса, которому досталась задача, изменяет статус на Processing и связывает задачу с сервисом.
Id | Name | CreatedAt | ModifyAt | ServiceId | Status |
{Observer id} | My_new_observer | {created date} | {modify date} | {Observer service 1 id} | Processing |
Мы можем получить список всех «наблюдателей» и узнать кто на каком сервисе работает и в каком статусе находится.
Перечень статусов:
Created
Processing
OnDeleting
Deleted
Разберем теперь как удалить «наблюдателя», тут можно пойти двумя путями:
1) направить конкретному сервису сообщение о том, что нужно найти у себя наблюдателя с указанным идентификатором и вызвать CancellationToken.
2) Направить сообщение всем доступным сервисам, через FanOut. Сервис, у которого есть «наблюдатель» с нужным идентификатором будет удален, а все остальные сервисы просто проигнорируют это сообщение.
Лично я отдал предпочтение второму варианту, одна из причин — это то, что нет необходимости хранить адрес сервиса…но тут как говорится «ап ту ю».
Каждый Observer-service имеет свою очередь, где он ожидает получить команду на остановку работы наблюдателя. Когда приходит такая команда, сервис проверяет наличие такого «наблюдателя» и в случае обнаружения вызывает CancellationToken. Тем самым завершая работу «наблюдателя» естественным путем.

Пошагово завершение работы «Наблюдателя» выглядит следующим образом. Пользователь отправляет команду на завершение работы, для этого ему нужно знать лишь id наблюдателя. Менеджер проверят если ли такой наблюдатель в системе, и его статус.
Если Created, пользователю возвращается ответ что «наблюдатель» еще не активирован. Из-за гонки условий сообщений об удалении может прийти раньше, чем сервису придет сообщение о запуске «наблюдателя».
Если OnDeleting или Deleted, то возвращается ответ — запрос на удаление уже был отправлен или «наблюдатель» удален, соответственно.
Если Processing, то менеджер переводит «наблюдателя» в статус OnDeleting и отправляет сообщения на удаление в очередь. Сообщение броадкастится всем сервисам. Сервис, у которого был нужный «наблюдатель», вызывает CancellationToken и оправляет сообщение в «state queue». Менеджер же, получив данное сообщение актуализирует данные и делает пометку переводя из OnDeleting в Deleted.
Id | Name | CreatedAt | ModifyAt | ServiceId | Status |
{Observer id} | My_new_observer | {created date} | {modify date} | {Observer service 1 id} | Deleted |
Рассмотрим критичные сценарии:
1) Отказала шина данных.
Вся инфраструктура, будь то шина данных или база данных должна находится опосредованно от нашей системы и быть кластеризированной. От себя добавлю следующий тезис, который как бритва Оккама отсечет ряд критичных сценариев — MsSql, RabbitMq, Kafka, даже Kubernetes сюда можно добавить, все это надежные системы, и при соблюдении SLA будут работать без отказа. За спиной у них огромные компании или комьюнити, сотни разработчиков. А вот собственную систему нужно воспринимать как что-то ненадежное, где любой компонент в любой момент времени может выйти из строя.
2) Полный blackout, везде нет света.
Тогда, когда свет все-таки включат, докер поднимет все контейнеры, а вместе с ними сервисы, каждый сервис сообщает о том, что он заново родился и начинает разбирать из очереди свободные сообщения, запускает «наблюдателей», они отправляют метаданные в менеджер. Менеджер актуализирует информацию о «наблюдателях», когда они были созданы и на каких сервисах они теперь расположены. (Сообщения записаны на диск, поэтому никуда не делись.)
3) Вылетел один сервер.
Сценарий мы уже описывали выше, «наблюдатели», которые выполнялись на нем просто перераспределятся по всем свободным сервисам. Когда менеджеру придут сообщения от новых «наблюдателей», которые были перераспределены, он запишет на каких сервисах они теперь работают.
4) Отказал менеджер. В процессе того пока он был неактивен, ломались сервера с «наблюдателями».
Сервисы будут класть сообщения в очередь о своем состоянии. Когда менеджер все-таки придет в себя, он примет сразу пачку сообщения, и в конце концов дойдет до консистентного состояния.
5) Попытка удалить конкретного «наблюдателя», в том момент, пока он перераспределяется.
Есть маленькое окно, когда пользователь отправляет команду на удаление, «наблюдатель» может перераспределяться. Тем самым его нет в моменте на конкретном сервисе. И сообщение об удалении может быть проигнорировано сервисами. В таком случае, менеджер, не получив ответа, по истечению времени, отправляет сообщение на удаление, повторно.
Итог
Мы реализовали оркестратор задач, на базе механизма отправки сообщений. Где сообщение это задача, с двумя статусами, в работе — Unacked, и в ожидании работы — Ready. Очередь сама распределяет задачи между исполнителями, делая это событийно, а не через polling состояния, как это делают планировщики. Система масштабируемая — мы можем иметь неограниченно количество «наблюдателей», которые могут быть распределены на разных серверах. Более того мы можем масштабировать как горизонтально, так и вертикально, увеличивая количество одновременно обрабатываемых сервисом задач, просто увеличивая PrefetchCount. И последнее, время на разработку оказалось меньше, чем время на изучение и внедрение планировщика.
