Организация шинной инфраструктуры, соединяющей агенты системного интерфейса STI версии 1.0
В статье изложены принципы построения инфраструктуры локальной системной шины, соединяющей агенты одного сегмента стыка простого исполнителя STI версии 1.0 в объёме кристалла СБИС или ПЛИС. Рассмотрена организация дешифратора адреса, коммутаторов шин чтения данных и выборки исполнителя. Приведен пример описания шинной инфраструктуры сегмента STI на языке Verilog. Предложены варианты подключения исполнителей к сегментам шины с меньшей разрядностью данных.
Стык простого исполнителя — Simple Target Interface (далее — STI) представляет собой набор логических сигналов и протокол взаимодействия, обеспечивающий соединение нескольких функциональных блоков в объёме одного проекта конфигурации ПЛИС или кристалла СБИС (далее — проекта). Спецификация интерфейса STI версии 1.0 была опубликована в статье [1].
В спецификации была введена используемая далее терминология и определены базовые принципы подключения исполнителей STI к инициатору в рамках одного сегмента.
В качестве примера предлагается рассмотреть сегмент 64-р шины STI, объединяющий инициатор и четыре исполнителя. При этом два исполнителя имеют разрядность данных 32 и 8 бит. Структурная схема такого сегмента STI представлена на рис. 1.

Рис. 1. Структурная схема сегмента STI
В состав каждого исполнителя входят ресурсы, доступные для приёма данных при записи и генерации данных при чтении. Эти ресурсы могут быть представлены регистрами, блоками памяти, мостами интерфейсов. Каждый такой ресурс имеет свой адрес в соответствующем адресном пространстве. Блоки памяти, регистровые файлы и интерфейсные мосты могут занимать диапазон последовательных адресов из адресного пространства.
Рассмотрим пример, в котором четыре исполнителя имеют ресурсы в пространстве адресов ввода-вывода и памяти. Распределение адресных диапазонов по исполнителям приведено в табл. 1.
Таблица 1.
| Исполнитель | Адресное пространство | ADDR[25] | ADDR[24] | ADDR[23] | ADDR[22] | ADDR[21] | ADDR[20] | ADDR[19] | ADDR[18] | ADDR[17] | ADDR[16] | Ёмкость, байт | DC_1 | DC_2 | DC_3 | DC_4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Target_A | Память | 1 | 0 | 0 | X | X | X | X | X | X | X | 8М | 1 | 0 | 0 | 0 |
| Target_B | Память | 0 | 0 | 0 | 0 | X | X | X | X | X | X | 4М | 0 | 1 | 0 | 0 |
| Target_C | Память | 1 | 0 | 1 | 1 | X | X | X | X | X | X | 4М | 0 | 0 | 1 | 0 |
| Target_D | Память | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 64К | 0 | 0 | 0 | 1 |
| Target_D | В/В | 1 | 0 | 0 | X | X | X | X | X | X | X | 8М | 0 | 0 | 0 | 1 |
| Target_C | В/В | 0 | 0 | 0 | 0 | X | X | X | X | X | X | 4М | 0 | 0 | 1 | 0 |
| Target_B | В/В | 1 | 0 | 1 | 1 | X | X | X | X | X | X | 4М | 0 | 1 | 0 | 0 |
| Target_A | В/В | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 64К | 1 | 0 | 0 | 0 |
Функциональная схема организации шинной инфраструктуры сегмента STI показана на рис. 2.
Выборку исполнителя согласно текущему адресу и коду команды (команда определяет адресное пространство) выполняет дешифратор адреса — address decoder. Единица на первом выходе дешифратора адреса сигнализирует обращение к исполнителю-A, единица на втором выходе — к исполнителю-B, и т.д. Двоичный код на выходе дешифратора показан в табл. 1.
Выходы дешифратора адреса управляют сигналами выборки исполнителей: FB1_EN, FB2_EN, FB3_EN и FB4_EN для Target-A, Target-B, Target-C и Target-D, соответственно. Каждый из этих сигналов подаётся на логический вентиль-И, разрешающий проход сигнала запроса S_EX_REQ на выбранный исполнитель, а также подаётся на коммутирующий узел — мультиплексор (MUX).
Мультиплексор коммутирует выходные сигналы исполнителей (S_EX_ACK и S_D_RD) на входы инициатора. При этом в каждый момент времени на инициатор должны поступать сигналы только от одного исполнителя (выбранного дешифратором), либо подаваться все единицы. Последнее требование обусловлено тем, что обращение инициатора по адресу, не принадлежащему ни одному исполнителю, не должно приводить к «зависанию» системы из-за наличия нуля на входе S_EX_ACK. Чтение данных из несуществующего ресурса в большинстве систем возвращает комбинацию из всех единиц.
Дешифратор и мультиплексор являются комбинационными логическими схемами, срабатывающими в пределах одного такта синхросигнала (между соседними восходящими фронтами).
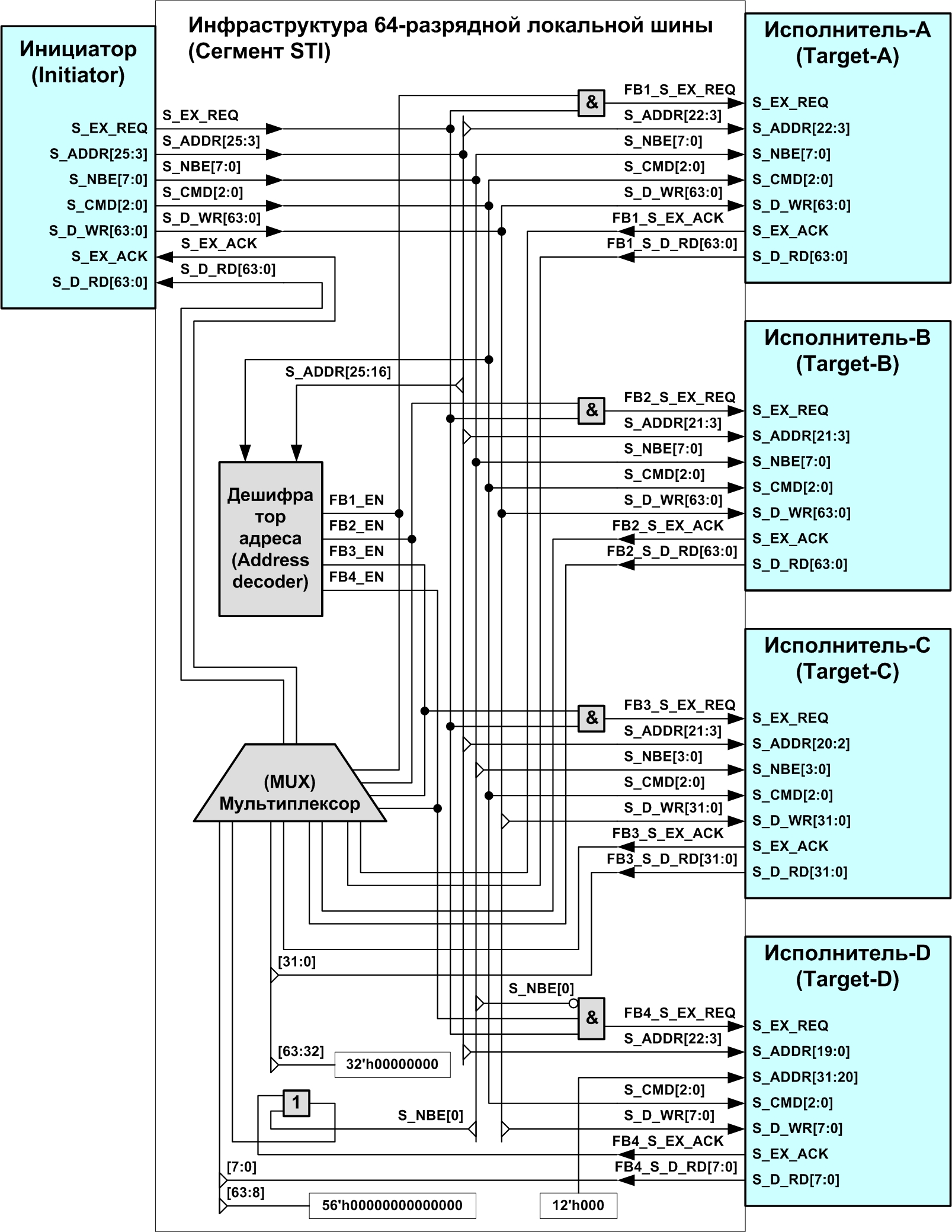
Рис. 2. Функциональная схема организации шинной инфраструктуры сегмента STI
Следует отдельно отметить, что исполнитель-D не имеет входа выборки байтов S_NBE, так как оснащён 8-разрядным интерфейсом STI. Вследствие этого выборка исполнителя-D осуществляется с учётом активности байта шины данных, к которому подключен этот исполнитель. Из функциональной схемы видно, что использован младший байт шин данных, поэтому исполнитель-D доступен только при условии активности младшего байта данных: S_NBE[0] = »0». Логический вентиль ИЛИ на выходе S_EX_ACK этого исполнителя пропускает сигнал готовности на мультиплексор также при условии S_NBE[0] = »0». В противном случае на мультиплексор поступает высокий уровень, предотвращающий «зависание».
Подключение 32-разрядного исполнителя-C к 64-разрядному сегменту STI реализовано с использованием младшей половины шин данных [31:0]. За байты со смещение адреса 0, 1, 2 и 3, передаваемые по этим линиям данных, отвечают сигналы разрешения байтов S_NBE[3:0]. В данном случае сигналы разрешения байтов не участвуют в формировании сигнала активации исполнителя FB3_S_EX_REQ, потому что циклы обращения к старшей половине шины данных (байтам со смещением адреса 4, 5, 6 и 7) вызовут пустой цикл на 32-разрядном интерфейсе исполнителя-C, при котором все четыре младших байта деактивированы. Исполнитель STI обязан корректно отвечать на такой цикл.
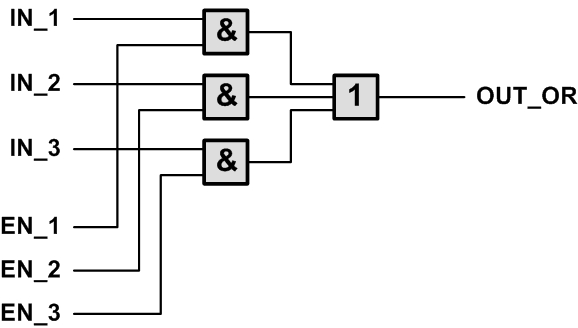
а,
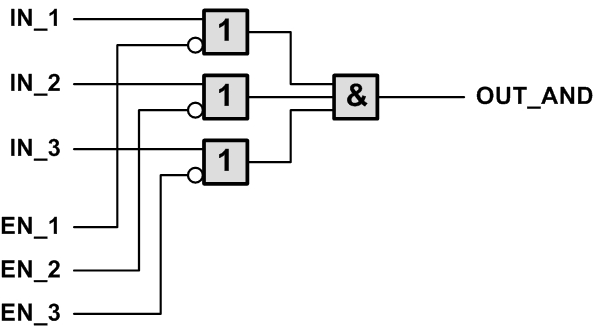
б,
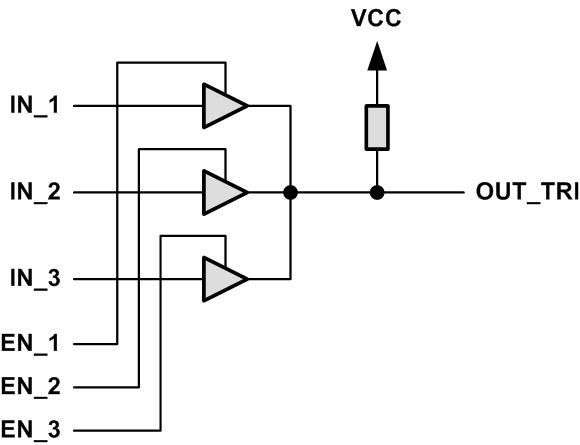
в
Рис. 3. Логическая организация мультиплексора
Рассмотрим организацию мультиплексора, коммутирующего выходные сигналы исполнителей на входы инициатора. Каноническая схема мультиплексора строится по принципу ДНФ (дизъюнктивной нормальной формы преставления функции в двоичной алгебре). Схема на основе ДНФ состоит из двух каскадов. Первый каскад включает вентили И (конъюнкции в формуле ДНФ), а второй каскад — объединяющий элемент ИЛИ (дизъюнкции в ДНФ). Такая схема для трёхвходового мультиплексора показана на рис. 3, а. Принцип действия мультиплексора на основе ДНФ заключается в пропускании единиц первым каскадом только с выбранного входа. Когда ни один из входов мультиплексора не выбран, такая схема даст на выходе низкий уровень, что не соответствует вышеизложенным требованиям для коммутатора сигнала S_EX_ACK.
Второй вариант организации мультиплексора показан на рис. 3, б. Эта схема построена по принципу КНФ (конъюнктивной нормальной формы) и состоит из двух каскадов, первый из которых включает вентили ИЛИ, пропускающие логический ноль только с выбранного входа, а второй каскад содержит объединяющий элемент И, работающий по принципу: хотя бы один ноль — на выходе ноль. Нетрудно заметить, что при наличии всех нулей на входах разрешения, когда не выбран ни один исполнитель, такой мультиплексор выдаёт на выходе единицу, удовлетворяя требованиям сигнала S_EX_ACK на входе инициатора.
Именно мультиплексор на основе КНФ рекомендуется использовать при описании инфраструктуры шины стыка простого исполнителя — STI.
В некоторых базисах элементов СБИС и ранних архитектурах ПЛИС допускается использовать элементы с тремя состояниями на выходе (тристабильные буферы) не только в блоках ввода-вывода, но и в ядре. Тристабильный буфер в примере на рис. 3, в передаёт сигнал IN_x на выход при наличии единицы на управляющем входе EN_x, иначе выход находится в третьем состоянии — «Z». Коммутатор, основанный на разделяемой линии связи S_EX_ACK, которой управляют тристабильные буферы, показан на рис. 3, в. Подтягивающий резистор задаёт значение сигнала на разделяемой линии связи, в том случае, когда все буферы выключены (не выбран ни один исполнитель). Резистор Pull-Up формирует логическую единицу в положительной логике. Таким образом, выполняется требование к коммутатору сигнала S_EX_ACK.
Следует отметить, что с точки зрения двоичной логики схемы на рис. 3, б и рис. 3, в идентичны на том наборе входных комбинаций, когда единица на разрешающих входах EN_x присутствует не более чем в одной позиции. В коммутаторе исполнителей STI может быть выбран только один исполнитель, либо не выбран ни один, что соответствует требованию для схемы на рис. 3, в. Схема подобная рис. 3, б формируется многими синтезаторами HDL автоматически из RTL-модели, аналогичной рис. 3, в.
Неиспользуемые старшие разряды данных на шинах чтения исполнителей C и D, дополняющие разрядность до 64 бит, установлены в нули постоянным соединением с цепью «цифровой земли» — GND.
Ещё один интересный момент в функциональной схеме на рис. 2 связан с шиной адреса исполнителя-D. В некоторых случаях к локальной системной шине требуется подключить разработанный ранее библиотечный блок, обладающий некоторой универсальностью. Например, блок памяти определённой ёмкости, требующей соответствующего адресного диапазона, или мост интерфейса, рассчитанный на полный формат адреса — 32 бита. В случае, если этот блок в текущей конфигурации системы использует не полный диапазон адресов, на старшие незадействованные биты входа S_ADDR следует подать константы. В нашем примере на неиспользованные входы S_ADDR[31:20] исполнителя -D поданы нули.
При подключении исполнителя с меньшей разрядностью данных к сегменту с большей разрядностью появляется эффект чередования адресов ресурсов этого исполнителя с неиспользованными адресами. Это обусловлено особенностью байтовой адресации. Байты, адрес которых заканчивается на »000» всегда будут передаваться по разрядам [7:0] 64-разрядных шин данных, для байтов с адресами, заканчивающимися на »001» используются разряды [15:8], и т.д.… для байтов с адресом, содержащим в младших разрядах »111» задействуются линии данных [63:56]. Таким образом, адреса, соответствующие неиспользованным линиям шин данных, будут чередоваться с адресами ресурсов исполнителя, доступных по остальным линиям.
Исходя из вышесказанного, ресурсы исполнителя-C будут располагаться по адресам, шестнадцатиричное представление которых заканчивается цифрами 0…3 и 8…B, а между «соседними» ресурсами исполнителя-C будет 4 неиспользованных байта, доступ к которым выполняется по линиям данных [63:32].
Аналогично ресурсы исполнителя-D будут доступны по адресам, заканчивающимся на 0h и 8h, с шагом +8.
Следует отметить, что подключение исполнителей C и D реализовано со сдвигом шины адреса на 1 и 3 бита соответственно. Иными словами, адрес 32-разрядного слова данных для исполнителя-C становится адресом 64-разрядного слова данных в сегменте STI, и адрес байта в объёме исполнителя-D тоже становится адресом 64-разрядного слова в сегменте STI.
Для того чтобы подключить к сегменту STI исполнитель с меньшей разрядностью шин данных, так, чтобы его ресурсы располагались в адресном пространстве системы (процессора) последовательно и непрерывно, нужно использовать дополнительны функциональный блок — мост, разбивающий цикл обращения с большей разрядностью данных на 2 и более цикла с разрядностью данных исполнителя обмена. Организация такого моста выходит за рамки темы этой статьи.
Ниже приведён пример описания инфраструктуры сегмента STI, показанной на рис. 2, на языке Verilog:
`timescale 1ns / 1ps
////////////////////////////////////////////////////////////////////////
// Engineer: FPGA-Mechanic
//
// Create Date: 09:38:35 03/03/2017
// Design Name: Argon SoC Proto
// Module Name: STI_EXAMPLE
// Project Name: Argon Otd.23 Projects
// Target Devices: Any FPGA or ASIC
// Tool versions: Xilinx 14.7
// Description: Test-purpose synthesizable STI module
//
////////////////////////////////////////////////////////////////////////
module STI_EXAMPLE(
input CLK,
input RST
);
// Internal signals declaration:
// STI-64:
wire S_EX_REQ,
wire [25:3] S_ADDR,
wire [7:0] S_NBE,
wire [2:0] S_CMD,
wire [63:0] S_D_WR,
wire S_EX_ACK,
wire [63:0] S_D_RD,
//------------------------------------------
// Initiator:
STI_64b_Initiator INITR(
.CLK(CLK),
.RST(RST),
.S_EX_REQ(S_EX_REQ),
.S_ADDR(S_ADDR),
.S_NBE(S_NBE),
.S_CMD(S_CMD),
.S_D_WR(S_D_WR),
.S_EX_ACK(S_EX_ACK),
.S_D_RD(S_D_RD)
);
//------------------------------------------
// STI Bus Infrastructure:
reg FB1_EN, FB2_EN, FB3_EN, FB4_EN;
wire FB1_S_EX_REQ, FB2_S_EX_REQ, FB3_S_EX_REQ, FB4_S_EX_REQ;
wire [63:0] FB1_S_D_RD, FB2_S_D_RD, FB3_S_D_RD, FB4_S_D_RD;
wire FB1_S_EX_ACK, FB2_S_EX_ACK, FB3_S_EX_ACK, FB4_S_EX_ACK;
always @ (S_ADDR[25:16], S_CMD)
if((~S_CMD[2] & S_CMD[0]) | (S_CMD[2] & ~S_CMD[1] & S_CMD[0])
| &(S_CMD[2:1])) // Memory CMD: 0X1,101,11X
case(S_ADDR[25:23])
3'b100 : // 100XXXXXXX
begin
FB1_EN <= 1'b1; FB2_EN <= 1'b0; FB3_EN <= 1'b0; FB4_EN <= 1'b0;
end
3'b000 : // 000XXXXXXX
if(S_ADDR[22] == 1'b0) // 0000XXXXXX
begin
FB1_EN <= 1'b0; FB2_EN <= 1'b1; FB3_EN <= 1'b0; FB4_EN <= 1'b0;
end
else // No Resource
begin
FB1_EN <= 1'b0; FB2_EN <= 1'b0; FB3_EN <= 1'b0; FB4_EN <= 1'b0;
end
3'b101 : // 101XXXXXXX
if(S_ADDR[22]) // 1011XXXXXX
begin
FB1_EN <= 1'b0; FB2_EN <= 1'b0; FB3_EN <= 1'b1; FB4_EN <= 1'b0;
end
else if(S_ADDR[21:16] == 6'b001011) // 1010001011
begin
FB1_EN <= 1'b0; FB2_EN <= 1'b0; FB3_EN <= 1'b0; FB4_EN <= 1'b1;
end
else // No Resource
begin
FB1_EN <= 1'b0; FB2_EN <= 1'b0; FB3_EN <= 1'b0; FB4_EN <= 1'b0;
end
default : // No Resource
begin
FB1_EN <= 1'b0; FB2_EN <= 1'b0; FB3_EN <= 1'b0; FB4_EN <= 1'b0;
end
endcase
else // IO CMD: 0X0,100
case(S_ADDR[25:23])
3'b100 : // 100XXXXXXX
begin
FB1_EN <= 1'b0; FB2_EN <= 1'b0; FB3_EN <= 1'b0; FB4_EN <= 1'b1;
end
3'b000 : // 000XXXXXXX
if(S_ADDR[22] == 1'b0) // 0000XXXXXX
begin
FB1_EN <= 1'b0; FB2_EN <= 1'b0; FB3_EN <= 1'b1; FB4_EN <= 1'b0;
end
else // No Resource
begin
FB1_EN <= 1'b0; FB2_EN <= 1'b0; FB3_EN <= 1'b0; FB4_EN <= 1'b0;
end
3'b101 : // 101XXXXXXX
if(S_ADDR[22]) // 1011XXXXXX
begin
FB1_EN <= 1'b0; FB2_EN <= 1'b1; FB3_EN <= 1'b0; FB4_EN <= 1'b0;
end
else if(S_ADDR[21:16] == 6'b001011) // 1010001011
begin
FB1_EN <= 1'b1; FB2_EN <= 1'b0; FB3_EN <= 1'b0; FB4_EN <= 1'b0;
end
else // No Resource
begin
FB1_EN <= 1'b0; FB2_EN <= 1'b0; FB3_EN <= 1'b0; FB4_EN <= 1'b0;
end
default : // No Resource
begin
FB1_EN <= 1'b0; FB2_EN <= 1'b0; FB3_EN <= 1'b0; FB4_EN <= 1'b0;
end
endcase
and (FB1_S_EX_REQ, FB1_EN, S_EX_REQ);
and (FB2_S_EX_REQ, FB2_EN, S_EX_REQ);
and (FB3_S_EX_REQ, FB3_EN, S_EX_REQ);
and (FB4_S_EX_REQ, FB4_EN, S_EX_REQ, ~S_NBE[0]);
// Acknowledge MUX:
assign S_EX_ACK = (~FB1_EN | FB1_S_EX_ACK) &
(~FB2_EN | FB2_S_EX_ACK) &
(~FB3_EN | FB3_S_EX_ACK) &
(~(FB4_EN) | S_NBE[0] | FB4_S_EX_ACK);
// Read Data MUX:
assign S_D_RD = (~{64{FB1_EN}} | FB1_S_D_RD) &
(~{64{FB2_EN}} | FB2_S_D_RD) &
(~{64{FB3_EN}} | FB3_S_D_RD) &
(~{64{FB4_EN}} | FB4_S_D_RD);
//------------------------------------------
// Target-A:
STI_64b_Target_A TARGET_A(
.CLK(CLK),
.RST(RST),
.S_EX_REQ(FB1_S_EX_REQ),
.S_ADDR(S_ADDR[22:3]),
.S_NBE(S_NBE),
.S_CMD(S_CMD),
.S_D_WR(S_D_WR),
.S_EX_ACK(FB1_S_EX_ACK),
.S_D_RD(FB1_S_D_RD)
);
//------------------------------------------
// Target-B:
STI_64b_Target_B TARGET_B(
.CLK(CLK),
.RST(RST),
.S_EX_REQ(FB2_S_EX_REQ),
.S_ADDR(S_ADDR[21:3]),
.S_NBE(S_NBE),
.S_CMD(S_CMD),
.S_D_WR(S_D_WR),
.S_EX_ACK(FB2_S_EX_ACK),
.S_D_RD(FB2_S_D_RD)
);
//------------------------------------------
// Target-C:
STI_32b_Target_C TARGET_C(
.CLK(CLK),
.RST(RST),
.S_EX_REQ(FB3_S_EX_REQ),
.S_ADDR(S_ADDR[21:3]),
.S_NBE(S_NBE[3:0]),
.S_CMD(S_CMD),
.S_D_WR(S_D_WR[31:0]),
.S_EX_ACK(FB3_S_EX_ACK),
.S_D_RD(FB3_S_D_RD[31:0])
);
assign FB3_S_D_RD[63:32] = {32{1'b0}};
//------------------------------------------
// Target-D:
STI_8b_Target_D TARGET_D(
.CLK(CLK),
.RST(RST),
.S_EX_REQ(FB4_S_EX_REQ),
.S_ADDR({12'h000, S_ADDR[22:3]}),
.S_CMD(S_CMD),
.S_D_WR(S_D_WR[7:0]),
.S_EX_ACK(FB4_S_EX_ACK),
.S_D_RD(FB4_S_D_RD[7:0])
);
assign FB4_S_D_RD[63:8] = {56{1'b0}};
//------------------------------------------
//------------------------------------------
//------------------------------------------
//------------------------------------------
//------------------------------------------
endmodule
Собственно сама инфраструктура сегмента STI описана в блоке кода, ограниченном комментарием «STI Bus Infrastructure».
Интерфейс STI позволяет подключить исполнители с большей шириной шины данных к сегменту с меньшей разрядностью. Рассмотрим пример подключения 64-разрядного исполнителя к сегменту с 16-разрядными шинами данных. Функциональная схема такого подключения приведена на рис. 4.

Рис. 4. Подключение 64-разрядного исполнителя к 16-разрядному сегменту STI
При подключении исполнителя с большей разрядностью данных нет необходимости в сдвиге разрядов шины адреса. Вместо этого, неиспользуемые исполнителем младшие биты адреса управляют коммутирующими узлами, выбирающими ту часть шины данных, по которой по которой ведётся обмен по текущему адресу. При этом ресурсы исполнителя располагаются в адресном пространстве в том же порядке, как при подключении к сегменту равной шириной данных.
Коммутирующие узлы представлены демультиплексором (DMX), буферами, дублирующими шину записи данных сегмента S_D_WR на соответствующие равные группы битов шины записи исполнителя, и мультиплексором (MX) шины чтения данных.
Демультиплексор пропускает сигналы разрешения байтов S_NBE сегмента STI на соответствующие входы разрешения байтов исполнителя на основании младших битов адреса. В рассматриваемом примере младшими битами адреса, управляющими коммутацией, являются S_ADDR[2:1]. На выходах демультиплексора, которые не выбраны текущей комбинацией S_ADDR[2:1] формируются логические единицы, запрещающие обращения к байтам, адрес которых на 16-разрядной шине не соответствует текущему адресу.
Функциональная схема демультиплексора, соответствующая конфигурации на рис. 4, показана на рис. 5.

Рис. 5. Функциональная схема демультиплексора
Мультиплексор представляет собой стандартный логический комбинационный узел, коммутирующий один из входных сигналов на выход в зависимости от управляющей комбинации — младших битов адреса. Так при S_ADDR[2:1] = 0h на выход S_D_RD[15:0] транслируются сигналы S_D_RD[15:0] исполнителя, при S_ADDR[2:1] = 1h — сигналы S_D_RD[31:16], при S_ADDR[2:1] = 2h — сигналы S_D_RD[47:32], при S_ADDR[2:1] = 3h — сигналы S_D_RD[63:48].
Немного отличается подключение 16,32 и 64 разрядных исполнителей к 8-разрядному сегменту STI, ибо в таком сегменте нет сигнала выборки байтов S_NBE. Если к определённому байту обращение не производится, на 8-разрядном сегменте не формируется соответствующий цикл обмена.
Пример подключения 16-разрядного исполнителя к 8-разрядному сегменту иллюстрирует рис. 6.
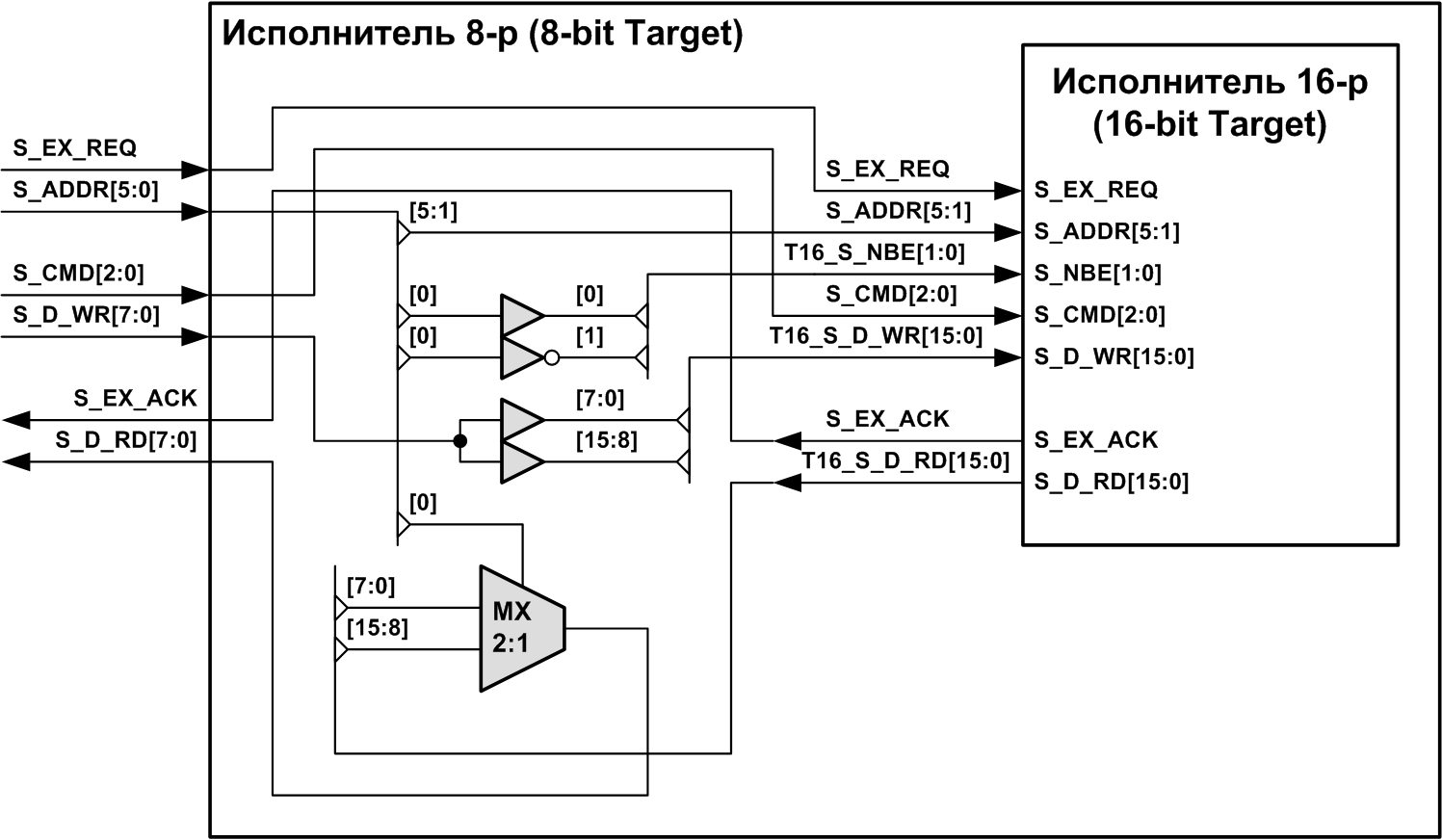
Рис. 6. Подключение 16-разрядного исполнителя к 8-разрядному сегменту STI
Сигналы разрешения байтов S_NBE для 16-разрядного исполнителя формирует дешифратор адреса 1:2, построенный на буфере и инверторе. При обращении к младшему (чётному) байту бит адреса S_ADDR[0] содержит ноль, проходящий через буфер на вход исполнителя S_NBE[0]. Таким образом, разрешается обмен данными по линиям [7:0]. Одновременно на входе S_NBE[1] формируется единица, запрещающая обмен по линиям данных [15:8]. При обращении к старшему (нечётному) байту исполнителя бит адреса S_ADDR[0] содержит единицу, что приводит к противоположной ситуации, когда обмен ведётся по линиям [15:8].
Мультиплексор — MX коммутирует на 8-разрядную шину чтения данных S_D_RD один из двух байтов выхода чтения исполнителя следующим образом: при нуле в бите адреса S_ADDR[0] на выход S_D_RD передаются данные [7:0] с выхода исполнителя, а при единице — данные [15:8].
Данные для записи дублируются на оба байта входа S_D_WR исполнителя, но производится запись только одного байта в зависимости от S_ADDR[0] и S_NBE[1:0], соответственно.
При подключении к 8-разрядному сегменту STI 32-разрядного исполнителя дешифратор адреса имеет формат 2:4 (с инверсными выходами) и конвертирует биты адреса S_ADDR[1:0] в S_NBE[3:0]. Мультиплексор при этом имеет формат 4:1 и управляется также битами адреса S_ADDR[1:0]. При подключении 64-разрядного исполнителя дешифратор 3:8 (с инверсными выходами) конвертирует биты адреса S_ADDR[2:0] в сигналы разрешения байтов S_NBE[7:0]. Мультиплексор 8:1 коммутирует байты на шине чтения данных согласно комбинации трех младших битов адреса.
Выводы.
Интерфейс стыка простого исполнителя STI использует простую и удобную в описании на языках Verilog и VHDL инфраструктуру шины, объединяющую инициатор и исполнители STI в рамках одного сегмента.
Описание дешифратора адреса на поведенческом уровне абстракции с использованием условных операторов if/case позволяет избежать трудоёмкого синтеза комбинационных цепей методами булевой алгебры.
Протокол взаимодействия агентов STI позволяет использовать исполнители с различной разрядностью шин адреса и данных в одном сегменте шины.
Список литературы
1. Борисенко Н.В. Синхронный системный интерфейс взаимодействия вычислительных ядер с периферийными блоками кристалла СБИС. «Компоненты и технологии» №10.2016.
2. RTL Hardware Design Using VHDL: Coding for Efficiency, Portability, and Scalability. By Pong P.Chu. John Wiley & Sons, Inc. 2006.
3. Борисенко Н.В. Подходы к организации унифицированного ряда синтезируемых моделей буферов FIFO, реализуемых в различных семействах программируемой логики. Часть 1. «Компоненты и технологии» №12.2012.
4. Борисенко Н.В. Схемы включения буферов FIFO с унифицированным интерфейсом в тракт данных между источником и приёмником информации. «Компоненты и технологии» №2.2013.
5. Борисенко Н.В. Организация синхронных буферов FIFO с унифицированным интерфейсом, построенных на регистрах общего назначения в объёме микросхем программируемой логики. «Компоненты и технологии» №8.2016.
