Организация кода это важно и легко на основе Layer Architecture
Введение
Привет Хабр! Думаю многие читали кучу книжек по поводу Hexagonal, Onion, Clean, Layer Architecture и у вас могли остаться спорные вопросы как в сложности понимания материала, так и в реализации данных подходов в ваших проектах. Сегодня я хочу затронуть тему «Организации кода» и показать насколько это важно и легко одновременно на примере Layer Architecture (Слоистая архитектура).
Сразу оговорюсь: никого не призываю использовать свой подход, это лишь субъективный взгляд исходя из моего опыта разработки приложений на Python.
В каких случаях будет полезна данная статья?
Если вы не знаете как начать реализовывать проект
Если вы сталкиваетесь с проблемой при создании файла у себя в проекте
Если не хотите, чтобы через короткий промежуток времени ваш код превратился в спагетти
Если вам нравится аккуратность не только на рабочем столе компьютера, но и в написании кода
В статье будут описаны следующие темы:
Почему организация кода так важна и в чем заключается задача программиста
Вопрос довольно банальный, но после года разработки состояние кода иногда напоминает картинку снизу.

Превращение кода в «спагетти» несёт за собой бóльшие проблемы, чем нечитаемость или его скорость, а именно: время на реализацию бизнес задач, нахождение и исправление багов в проекте становится слишком большим.
Выбор архитектурного подхода — очень спорная тема. Работая в одной из компаний, я потратил много часов на обсуждения с командой, но в итоге мы пришли к тому, что ни одна из упомянутых во введении архитектур не реализовывалась в полной мере, везде требовались какие-то доработки и уточнения. Мы забыли, что одна из важнейших задач разработчика — писать код так, чтобы он был прост в чтении другими разработчиками и масштабируемым для быстрой реализации будущих бизнес задач.
Я пришёл к выводу, что основные архитектуры — это лишь базовые знания, на основе которых мы строим собственные архитектуры, которые, в свою очередь, должны решать требуемые задачи, а хорошо организованный код помогает увеличить скорость разработки.

Слоистая архитектура как базовый выбор
Любой проект начинается со сбора требований, проектирования диаграмм и т.д., но мы пропустим эти шаги, предполагая, что сделали все необходимое и приступаем к написанию кода.
Спроектированная диаграмма отображает входные точки в приложение, обработку бизнес правил, информации, а также взаимодействие с другими приложениями. Элементы диаграммы и есть те самые слои архитектуры, по которым передвигается ваша информация. Таким образом слоистая архитектура проста в использовании и легка для восприятия и понимания большинству разработчиков.
Но использование данной архитектуры может порождать множество абстракций, которые создают зависимости между слоями. Это произойдет, если допустить следующие ошибки в вашем приложении:
Слой входных точек
Рассмотрим пример реализации интерфейса в виде вызова «ручек», где пользователь отправляет запрос на создание сущности.
@router.post("/api/v1/entities/", name="create_entity", status_code=status_code.HTTP_201_CREATED)
def create(self, entity: api_schemas.DTO()) -> api_schemas:
return api_schemas.from_business_layer(business_layer.create(entity=entity.to_service_model())) # обращение к слою сервисов с преобразованием моделейПочему реализовано именно так? Да всё очевидно! Во время тестирования интерфейса «общения с клиентом» происходит инкапсуляция бизнес логики, что позволяет проводить тестирование в рамках только этого слоя, а также гибко управлять типами интерфейсов будь то API, CLI или Crontab Task. Интерфейс — это входная точка в наше приложение, которая организует канал связи между клиентом и бизнес логикой, и как раз на ней лежит ответственность за преобразование моделей.
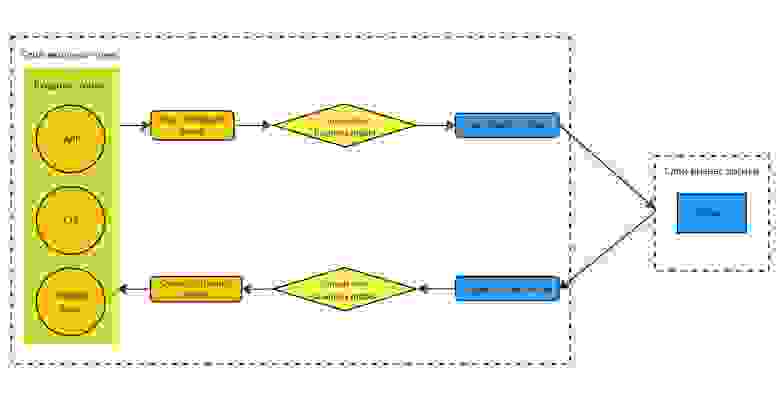
Слой входных точек
Задачи слоя:
Организация канала связи между клиентом и бизнес логикой
Валидация, сериализация, десериализация входных-выходных данных, применение различных middleware
Слой бизнес логики
Данный слой отвечает за управление информацией на основе бизнес правил. Рассмотрим пример:
def create(dto: bll_schemas.DTO()) -> bll_schemas.dto:
with database.start_session():
if database.get(**object):
raise bll_exc.DuplicateError("Object is already created")
database_entity = database_models.Entity(**object.model_dump())
database.create(session=session, object=database_entity)
return self.service_schema.from_orm(database_entity)Как вы можете заметить в примере есть правило, что сущность необходимо создать, если ее не существует. Для этого мы идём в БД за информацией на основе входных данных и проверяем есть ли там эта сущность. Работа с БД, соответственно, инкапсулирована. Это необходимо для того, чтобы тестировать только бизнес правила и то, как они влияют на управление сущностями, но не тестировать работу базы данных. Такое разделение позволяет описывать бизнес правила в одном месте и не размазывать их по всему приложению.
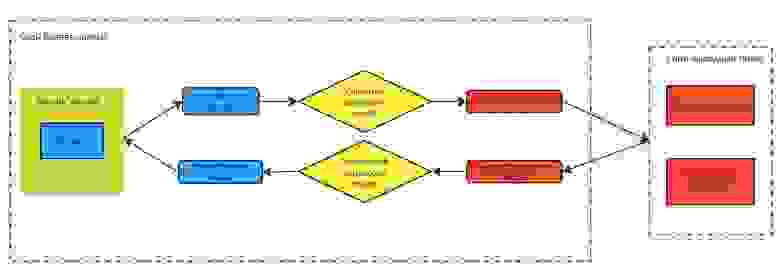
Слой бизнес логики
Задачи слоя:
Применение бизнес правил
Вызов слоя передачи/получения информации
Валидация, сериализация, десериализация входных-выходных данных
Слой выходных точек
Он отвечает за организацию и настройку канала связи с внешним источником данных. Пример:
def create(entity: Entity, session: Session) -> Entity:
try:
session.add(entity)
session.commit()
session.refresh()
except DatabaseException as exc:
session.rollback()
raise exc
return entityВыше мы описали как бы мог выглядеть create из бизнес логики для БД. Мы спрятали всю сложность управления БД в отдельный метод интерфейса, упростив бизнес логику.
При физическом управлении информацией, используя каналы взаимодействия, мы начинаем передавать информацию вовне и управлять этим каналом.
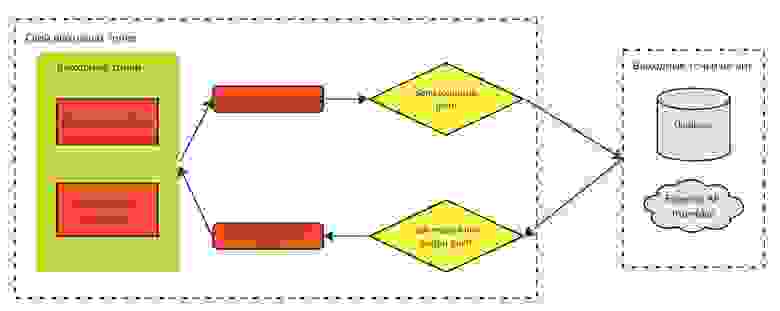
Слой выходных точек
Задачи слоя:
Организация канала связи с внешним источником информации
Управление каналом связи
Масштабируемость и немного о unit тестировании
Бывают ситуации, когда с появлением новых требований к проекту рассмотренных выше слоев уже недостаточно для решения задач, поэтому они становятся всё более сложными и большими.
Описание примера
Представим, что в нашем приложении уже есть ручки Create и Delete, которые позволяют создавать и удалять определенный объект. К нам приходит бизнес и просит ручку для пересоздания объекта (Recreate). Так как у нас есть часть готового функционала, то для этого нам необходимо вызвать сначала Delete, а затем Create. Кроме этого могут появиться дополнительные условия, из-за которых придется обращаться в другие приложения, поэтому нам нужно будет описать дополнительную обработку данных. В итоге задача будет реализована, но каждая такая фича ведет к разрастанию размера кода как внутри ручек, так и в бизнес логике, чего хотелось бы избегать, чтобы код оставался более лаконичным и легким для восприятия.
Поэтому ниже представлю вам описание дополнительных слоев, которые помогают сделать код более читаемым, а масштабирование менее болезненным.
При использовании нескольких методов бизнес логики добавляется слой композит, который отвечает за создание различных сессий и вызовы этих методов, что позволяет избежать сложного кода в слое входных точек и не давать ему ответственность за управление сессиями.
Множество обращений в другие приложения решаются внутренними функциями бизнес логики, но для каждого такого обращения необходима дополнительная обработка информации, поэтому чтобы бизнес логика не разрасталась, можно выделить обработку данных в отдельный слой.
Немного о Unit-тестах. В каждой команде по-разному договариваются о том как покрывать код тестами. Часто 100% покрытие не приносит никакой пользы, а только увеличивает кодовую базу и добавляет рутины в написании тестов. Так как некоторый функционал меняется редко, его можно протестировать и вручную, а есть вещи которые в рамках Unit-тестов проверять и вовсе не нужно, например, прямое взаимодействие с БД. Поэтому полезной практикой является тестирование бизнес логики с заглушками внешних вызовов, так как там кроется основная часть логики приложения, которую необходимо разрабатывать и часто менять.
Заключение
В конечном итоге, если воспользоваться рекомендациями выше, то получится диаграмма ниже (исключил конвертацию данных у каждого слоя для простоты):
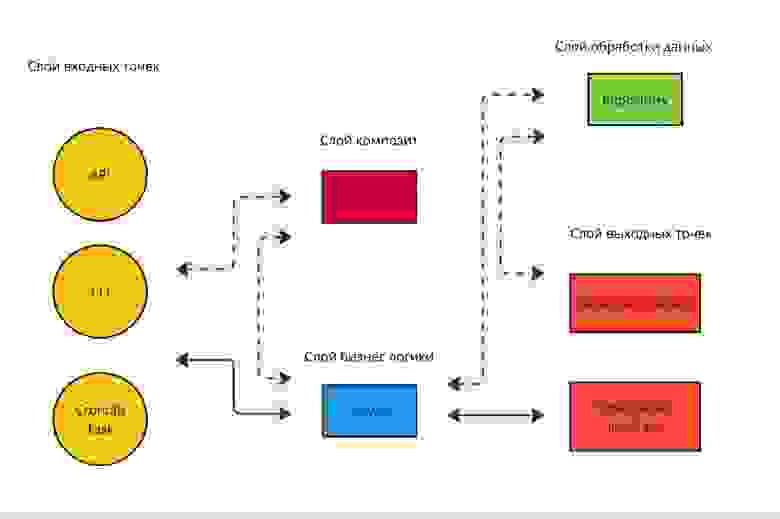
Это база, от которой можно отталкиваться для выработки своей собственной архитектуры и паттернов в команде. Данная архитектура дает гибкость разработки, более чистый код, явное распределение ответственности и более высокую скорость разработки проекта.
Как маленький бонус рекомендую книги, которые помогли в моем пути разработчика:
Паттерны разработки на Python: TDD, DDD и событийно-ориентированная архитектура. Боб Грегори, Гарри Персиваль
Чистая архитектура. Искусство разработки программного обеспечения. Мартин Роберт
Микросервисы. Паттерны разработки и рефакторинга Ричардсон Крис
