Опыт внедрения Service Mesh на Nomad и Consul
В этой статье мы расскажем, как развернули Service Mesh, решили часть проблем микросервисной архитектуры и уменьшили нагрузку на разработчиков и инженеров инфраструктуры.
Почему нам был нужен Service Mesh
Service Mesh сейчас набирает популярность. Думаю, не имеет смысла в очередной раз давать определение и описывать все, зачем он может пригодиться. Если вы не знаете, о чем речь, но в вашей компании много команд, сервисов или вы собираетесь разделять монолит, то стоит ознакомиться с предметом. Можно начать с перевода статьи, написанной создателем первого Service Mesh-проекта Уильямом Морганом.
За последний год количество продуктовых команд в компании выросло в 1,5 раза. На момент написания этой статьи у нас больше 20 команд, почти в каждой есть разработчики. С увеличением их числа разработка монолита не стала проще, поэтому мы начали активнее двигаться к микросервисной архитектуре. Пока мы, скорее, в начале пути, однако уже 3–4 года назад у нас с приличной скоростью начали плодиться сервисы разного назначения.
Разумеется, чем больше сервисов, тем сложнее за ними уследить, труднее управлять ими и инфраструктурной конфигурацией. Особенно сложно это было бы в условиях традиционной системы, в которой между разработчиками и админами стоит стена. Поэтому одновременно с созданием микросервисов мы начали отдавать большую часть ответственности за запуск и эксплуатацию сервиса разработчикам, предоставляя Ops-экспертизу как сервис. Однако всех тонкостей настройки инфраструктуры разработчики, конечно, не знают.
Service Mesh как раз очень удачно объединяет в себе и абстрагирует от разработчиков такие вещи, как:
- Service Discovery;
- Distributed tracing;
- Circuit Breaking / Retries / Timeouts;
- Мониторинг / телеметрию взаимодействия и многие другие.
Прежде всего надо отметить, что мы деплоимся в облако, упаковывая сервисы в Docker-контейнеры. Оркестрирует контейнеры Nomad, который используется в связке с Consul. Этот выбор был сделан, когда Kubernetes был еще не слишком популярным и стабильным, но уже тогда был сильно сложнее Nomad в эксплуатации и настройке.
Для тех, кто знаком только с Kubernetes, дам небольшие разъяснения по поводу того, как все устроено в HashiCorp-стеке.
Nomad отвечает за оркестрацию Docker-контейнеров (умеет также QEMU, raw/isolated fork/exec и Java). Consul отвечает за Service Discovery и может выполнять роль DNS-сервера.
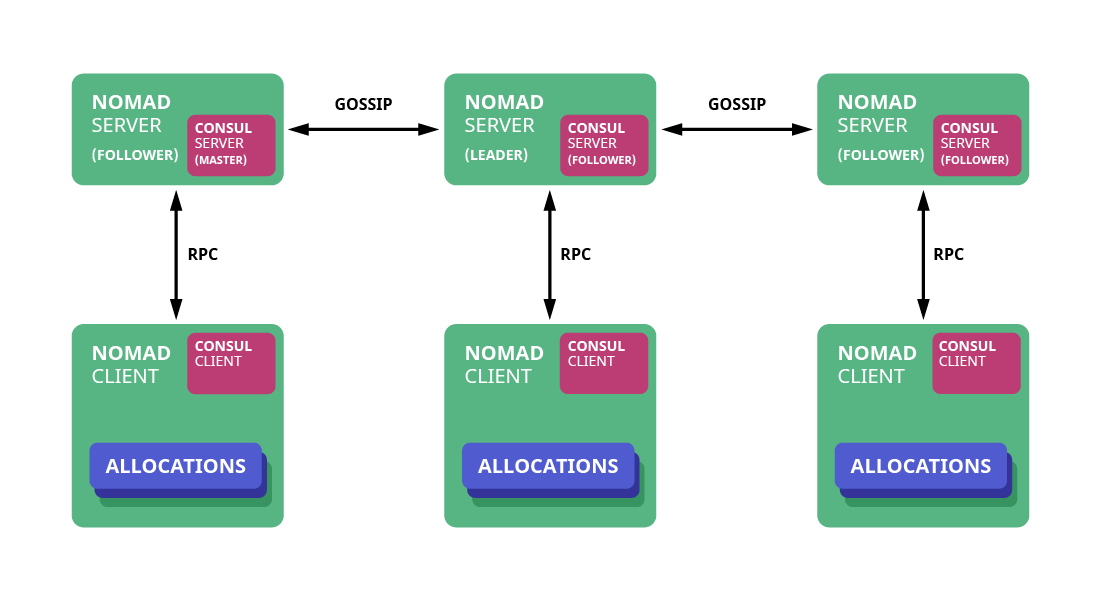
На каждом хосте в облаке устанавливаются Nomad- и Consul-агенты. Кроме того еще есть несколько мастер-серверов (обычно три или пять), которые собираются в кворум и отвечают за координацию.
Nomad и Consul тесно интегрированы. Consul следит, жив ли агент (node), проходят ли healthcheck сервиса. У сервиса может быть сразу несколько чеков (TCP, HTTP, gRPC, script). Также в спецификации Nomad можно использовать интерполяцию из key-value Consul или из секретов Vault, например, для задания переменных окружения внутри контейнера или создания файлов-шаблонов. Для этого Nomad использует consul-template.
И Nomad, и Consul предоставляют HTTP API, с помощью которого, например, из Nomad можно получить все данные о состоянии выполняемых задач, а из консула — список ip-port для какого-то сервиса с учетом healthcheck. То, что в k8s называется Pod, в номаде называется Allocation, ниже я буду использовать этот термин.
Долгое время у нас в компании существует подход, исключающий наличие такой позиции, как operations engineer. Иначе говоря, мы хотим, чтобы разработчики были максимально самодостаточны: сами написали, сами задеплоили, сами следят.
Для этого уже довольно давно используем самописный фронтенд для HashiCorp-стека, где разработчики сами накликивают сервисы и деплоят их на стейдж или в продакшн. Service Mesh интегрирован с этой системой таким образом, что разработчики в состоянии сами решить тривиальные кейсы вроде добавления Redis для своего сервиса или подключения одного сервиса к другому.
О прокси в Service Mesh
В Service Mesh есть две так называемые плоскости: плоскость данных и плоскость управления (data plane и control plane). Data plane обычно выполняется в виде прокси, которые каким-то образом распределены по хостам. Конфигурируются прокси через control plane, который обычно централизован. Межсервисное взаимодействие происходит через эти самые прокси.
Самые распространенные варианты развертывания прокси — один на хост или sidecar (специализированный контейнер в Pod«e/аллокации). Возможно еще разворачивать прокси на выделенном хосте, но в этом случае становятся заметными сетевые задержки.
Разные реализации Service Mesh используют разные прокси. В Linkerd используется linkerd-proxy, а Consul Connect и Istio позволяют использовать third-party прокси. В основном в этой роли выступает Envoy от Lyft. Это open source прокси, который изначально разрабатывался для такого применения.
Почему готовые реализации нам не подходили
Мы не воспользовались готовыми реализациями, и вот почему:
- На момент начала нашего перехода на Service Mesh в начале 2018 года эта концепция была новой и еще сырой. Для перехода неизбежно пришлось бы возиться с реализацией прокси, минуя абстракцию.
- Для наших целей реализации были перегруженными.
- Централизованный control plane не подходил нам.
Реализация
Отказ от централизованного control plane
В первом приближении мы пытались сделать свой централизованный control plane — отдельный сервис, который бы позволял гибко конфигурировать Service Mesh для разработчиков. Довольно скоро стало понятно, что одновременно следить и за деплоем, и за раутингом у разработчиков бы не получилось. Также интеграция этих двух систем не самая тривиальная вещь и, по прогнозам, заняла бы довольно много времени.
Решили интегрировать управление Service Mesh в систему деплоя таким образом, что при редактировании конфигурации приложения обновляется и часть Mesh, которая покрывает это приложение. Количество крутилок для Envoy при этом, конечно, уменьшили, чтобы не пугать разработчика.
Envoy в качестве data plane
Envoy запускаем sidecar-контейнерами рядом с основным контейнером приложения. Мы выбрали именно sidecar-контейнеры, а не один прокси на хост. Таким образом обеспечивается точечное конфигурирование прокси разных приложений и масштабирование получается само собой. Прокси на входящие запросы (ingress) прикидывается самим сервисом с точки зрения Consul, а на исходящие (egress) соединения открывает у себя по одному порту на каждый сервис-зависимость. Конфигурация в основном статическая, где указано, какие есть исходящие сервисы и настройки для взаимодействия с конкретным сервисом, такие как таймауты и лимит количества попыток.
Связь между сайдкарами настраивается просто: Nomad предоставляет переменные окружения с адресами соседей во все контейнеры аллокации.
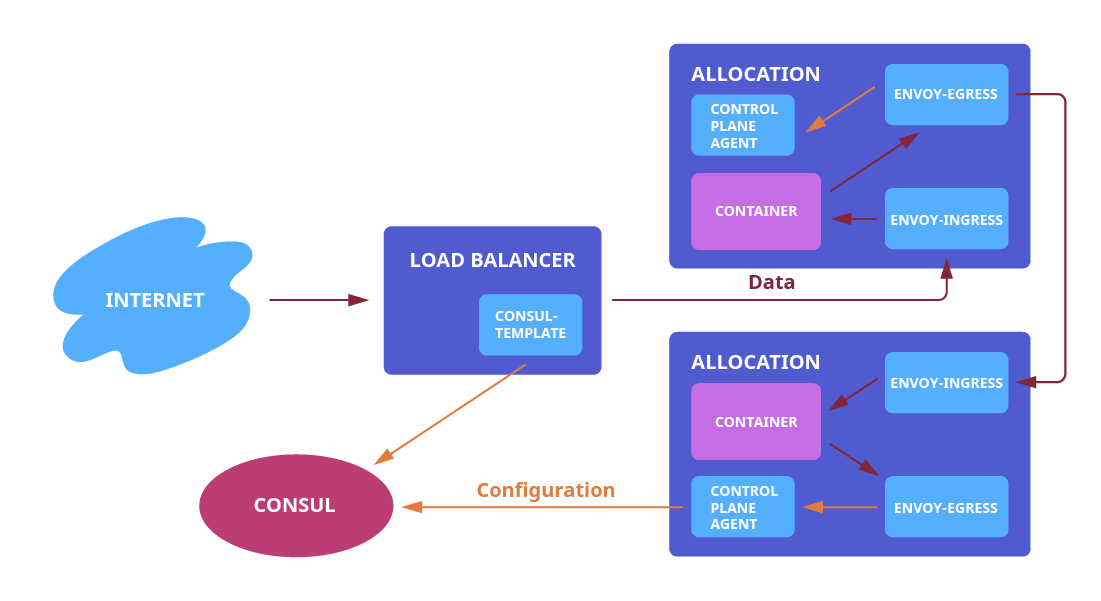
Service Discovery
Но как же Service Discovery? Как исходящему прокси узнать, где другие сервисы? Для этого мы запускаем еще один sidecar, самописный control plane agent, который по функционалу представляет из себя маленькое подмножество полноценного control plane API, отвечающий за преобразование API Consul в API Envoy. Мы реализовали только часть endpoint discovery (EDS). Агент подписывается на все обновления списка «здоровых» экземпляров сервиса-зависимости в Consul. Envoy периодически опрашивает агента, чтобы узнать актуальные адреса зависимостей.
Бонусы
Телеметрия и визуализация трафика
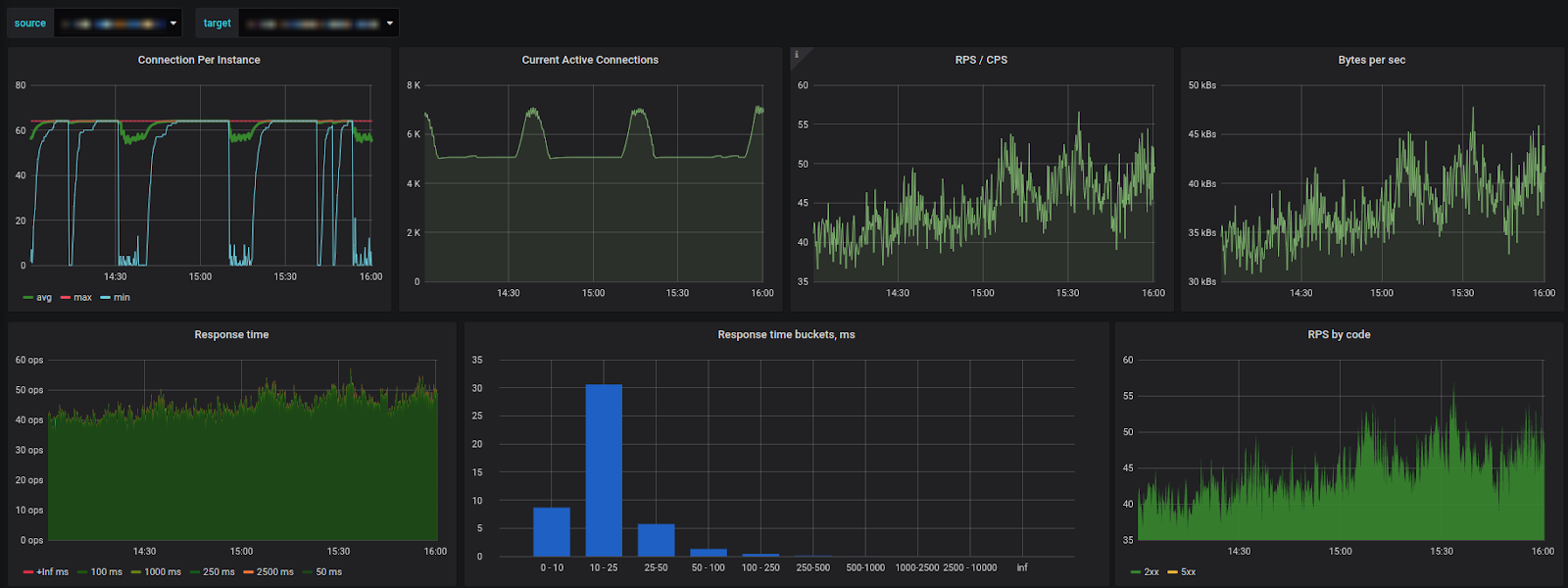
Для сбора телеметрии мы используем Prometheus. Envoy как раз предоставляет подробные метрики вроде количества запросов в секунду, количества активных соединений, статистику срабатываний Circuit Breaker и многое-многое другое. В итоге из этого собираем дешборды вроде такого:
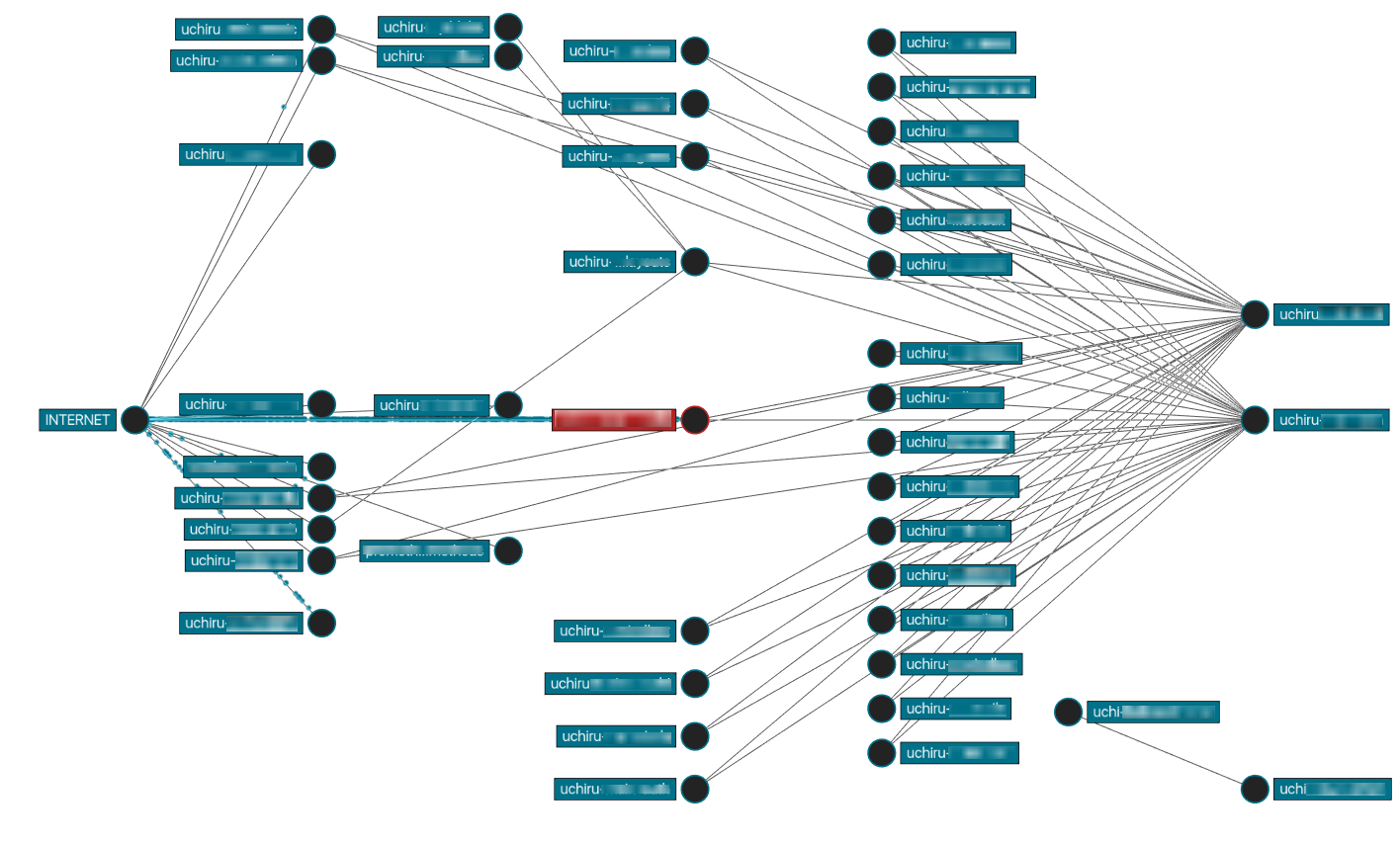
Еще у нас есть сервис, который на основе телеметрии из Прометея строит граф зависимостей сервисов и визуализирует интенсивность трафика, используя Vizceral от Netflix:
Отслеживание пути запроса
Телеметрия — это прекрасно, сильно выручает. Однако картина была бы неполной, если невозможно проследить путь какого-то определенного запроса. К счастью, Envoy поддерживает технологию Distributed tracing в формате Zipkin/Jaeger (X-b3-headers).
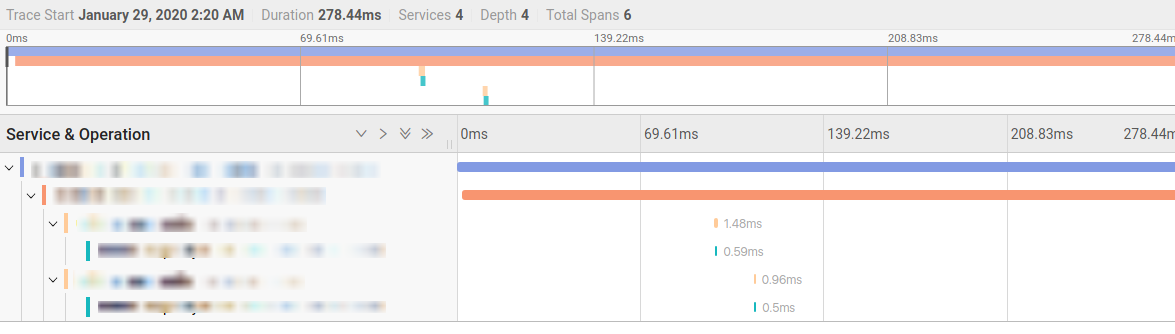
Однако должен заметить, что мы хоть и не полностью, но ушли от Jaeger в сторону Elastic APM (Application Performance Management). Этот сервис аналитики — часть Kibana, которую мы сами хостим. Продукт от Elastic пока, на наш взгляд, более комплексное решение, чем Jaeger, которое объединяет логи, APM и Distributed tracing. Jaeger-трейсинг, собираемый Envoy, несмотря на то, что он не позволяет заглянуть внутрь приложения, уже не раз выручал нас и сейчас применяется в сервисах на сторонних образах, где нет возможности добавить Elastic APM. В случае и с Jaeger, и с Elastic APM в код приложений пришлось запустить руки, чтобы они могли передавать HTTP-заголовки по цепочке и писать trace-id в логи. В случае с Jaeger это самописная библиотека, а Elastic предоставляет агент для всех языков, которые мы используем.
Итог реализации и дальнейшие шаги
На данный момент Service Mesh покрывает у нас все сетевое взаимодействие внутри каждой из наших виртуальных сетей. Речь идет только о сервисах команд разработки — инфраструктурные сервисы решили пока не покрывать. Это в основном HTTP/1, но есть еще немного TCP или Redis. Межсетевого взаимодействия через Mesh пока еще нет, но мы упакуем и его. Это касается и того, как сейчас у нас конфигурируются внешние балансировщики нагрузки. В них пока слишком много логики раутинга, который гораздо естественнее укладывался бы в Service Mesh.
Инвестиции в Ops-экспертизу в рамках конкретных команд позволят более полно раскрыть возможности Mesh: разделение трафика, моделирование отказов, более продвинутые Canary, чем у нас есть сейчас. Скорее всего, мы перейдем на индустриальный стандарт вроде Istio и централизованную конфигурацию.
Плюсы и минусы нашего Service Mesh
Итак, для себя выделяем следующие плюсы подхода нашей реализации Service Mesh:
- В момент деплоя сервиса меняется конфигурация его и только его прокси — нет возможности капитально сломать всю сеть.
- Service Discovery становится значительно компактнее, так как нужно следить лишь за сервисами-зависимостями конкретного сервиса. Потребление памяти c-plane около 10 Мб и, конечно, варьируется от количества сервисов, которые указаны как зависимости конкретного сервиса, но незначительно. Скажем, десяток зависимостей не добавит даже нескольких мегабайт. Envoy при этом у нас можно сконфигурировать максимально на 150 Мб RAM, чего хватает на самые нагруженные наши сервисы. Сервисы, которым нужно держать меньше 100 RPS, укладываются в 30 Мб.
- Достигнута простота для разработчика. С помощью одной галки и 2–3 крутилок они получают настроенный прокси на входящие и исходящие запросы и трейсинг.
- Решение не требует ручного вмешательства — с тех пор как оно в продакшене, ни разу не пришлось на него отвлекаться.
Минусы:
- Не очень гибкая конфигурация, так как мы сознательно уменьшили количество настроек для прокси.
- Чтобы начать использовать какие-то новые возможности Envoy, придется залезать в код системы самописного фронтенда.
- Чтобы централизованно обновить прокси, придется делать массовый передеплой (с другой стороны, процесс проще контролировать).
