Опыт разработки сервиса Refund Tool с асинхронным API на Kafka
Что может заставить такую большую компанию как Lamoda с отлаженным процессом и десятками взаимосвязанных сервисов существенно менять подход? Мотивация может быть совершенно разная: от законодательной до присущего всем программистам желания экспериментировать.
Но это вовсе не значит, что нельзя рассчитывать на дополнительную выгоду. В чем конкретно можно выиграть, если внедрить events-driven API на Kafka, расскажет Сергей Заика (fewald). Про набитые шишки и интересные открытия тоже обязательно будет — не может эксперимент без них обойтись.
Disclaimer: Это статья основана на материалах митапа, который Сергей провел в ноябре 2018 года на HighLoad++. Живой опыт Lamoda работы с Kafka привлек слушателей не меньше, чем на другие доклады из расписания. Нам кажется, это отличный пример того, что всегда можно и нужно находить единомышленников, а организаторы HighLoad++ и дальше будут стараться создавать располагающую к этому атмосферу.
Про процесс
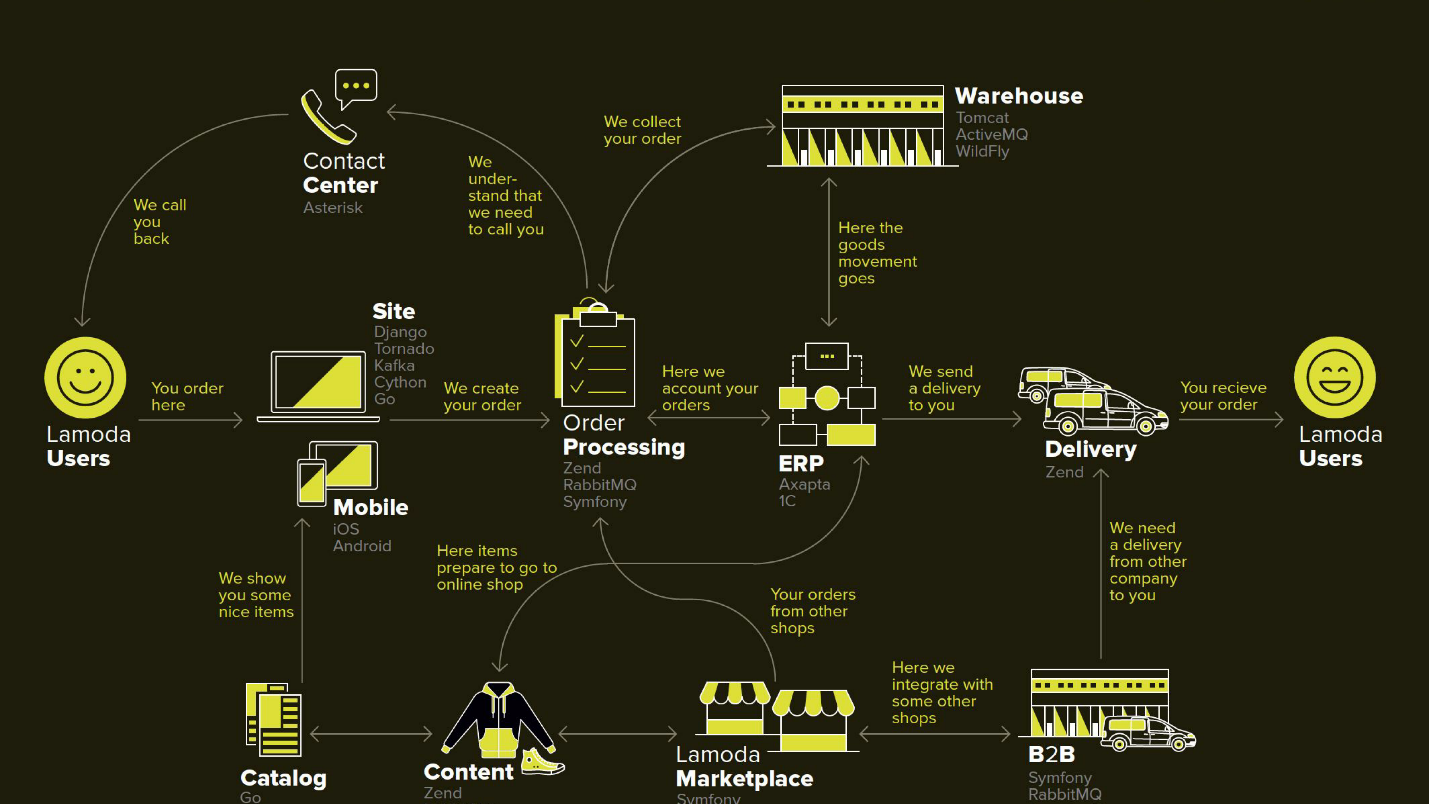
Lamoda — это крупная e-commerce платформа, у которой есть свой контакт-центр, служба доставки (и множество партнёрских), фотостудия, огромный склад и всё это работает на своем софте. Есть десятки способов оплаты, b2b-партнеры, которые могут пользоваться частью или всеми этими услугами и хотят знать актуальную информацию по своим товарам. К тому же, Lamoda работает в трёх странах помимо РФ и там всё немножко по-своему. Итого существует, наверное, больше сотни способов сконфигурировать новый заказ, который должен быть по-своему обработан. Все это работает с помощью десятков сервисов, которые общаются порой неочевидным образом. Ещё есть центральная система, чья главная ответственность это статусы заказов. Мы называем её BOB, я работаю с ней.
Refund Tool with events-driven API
Слово events-driven довольно заезжено, чуть дальше подробнее определим, что под этим понимается. Начну с контекста, в котором мы решили опробовать подход events-driven API в Kafka.

В любом магазине, помимо заказов, за которые покупатели платят, бывают моменты, когда от магазина требуется вернуть деньги, потому что клиенту товар не подошел. Этот сравнительно короткий процесс: уточняем информацию, если есть такая необходимость, и переводим деньги.
Но возврат усложнился в силу изменения законодательства, и нам пришлось реализовать под него отдельный микросервис.

Наша мотивация:
- Закон ФЗ-54 — кратко, закон требует сообщать в налоговую о каждой денежной операции, будь то возврат или приход, в довольно короткий SLA в несколько минут. Мы, как e-commerce, проводим довольно много операций. Технически это значит новую ответственность (а значит новый сервис) и доработки во всех причастных системах.
- BOB split — внутренний проект компании по избавлению BOB от большого числа непрофильных ответственностей и снижению его общей сложности.

На этой схеме нарисованы основные системы Lamoda. Сейчас большинство из них представляет собой скорее созвездие из 5–10 микросервисов вокруг уменьшающегося монолита. Они потихоньку растут, но мы стараемся делать их меньше, потому что деплоить выделенный в середине фрагмент страшно — нельзя допустить, чтобы он упал. Все обмены (стрелочки) мы вынуждены резервировать и закладываться на то, что любой из них может оказаться недоступным.
В BOB тоже довольно много обменов: системы оплаты, доставки, нотификации и т.д.
Технически BOB это:
- ~150k строк кода + ~100k строк тестов;
- php7.2 + Zend 1 & Symfony Components 3;
- >100 API & ~50 исходящих интеграций;
- 4 страны со своей бизнес-логикой.
Деплоить BOB дорого и больно, количество кода и решаемых им задач такое, что никто не может положить его в голову целиком. В общем, много поводов его упростить.
Процесс возврата
Изначально в процесс вовлечены две системы: BOB и Payment. Теперь появляются ещё две:
- Fiscalization Service, который возьмет на себя проблемы с фискализацией и общение с внешними сервисами.
- Refund Tool, в который просто выносятся новые обмены, чтобы не раздувать BOB.
Теперь процесс выглядит так:
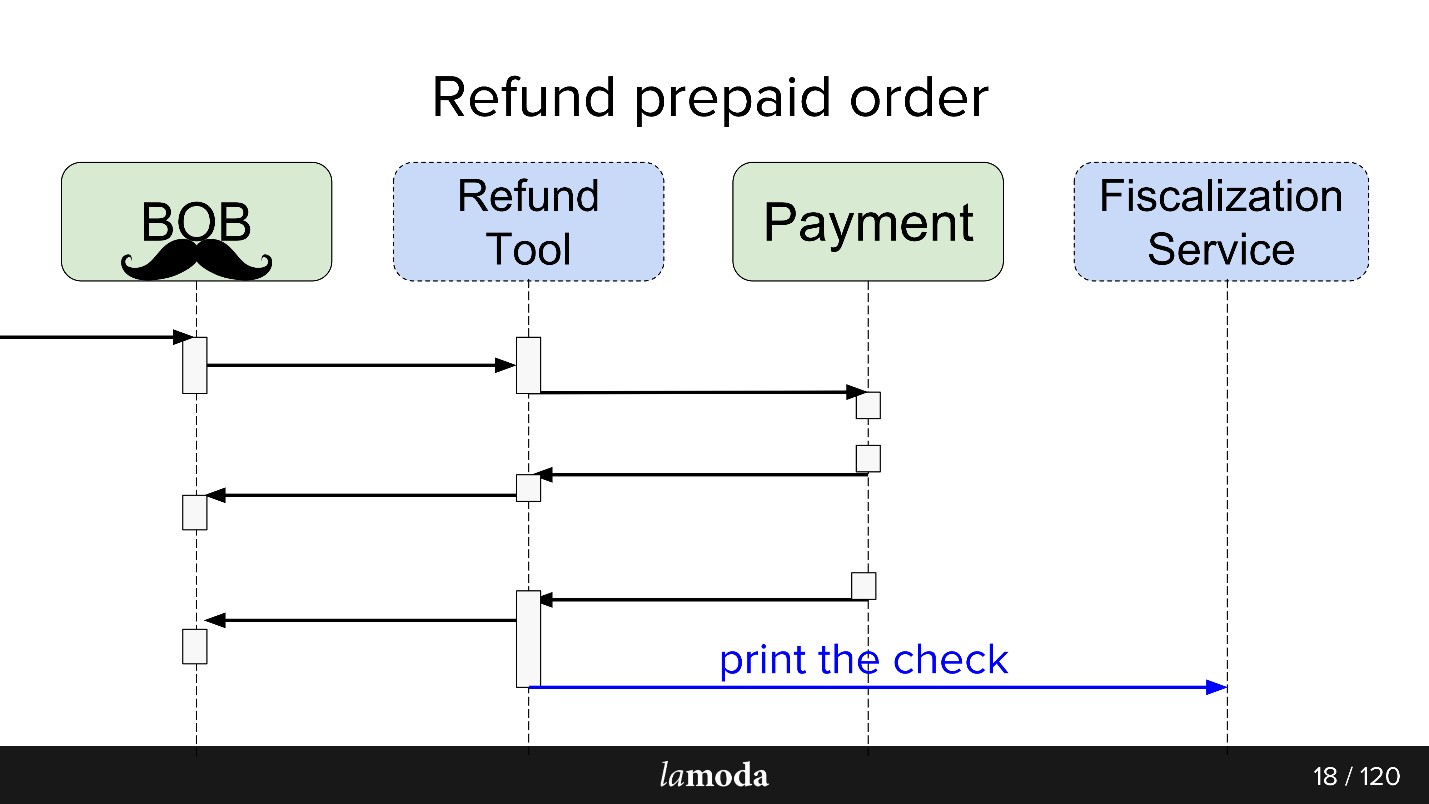
- К BOB приходит запрос на возврат денег.
- BOB говорит об этом Refund Tool.
- Refund Tool говорит Payment: «Верни деньги».
- Payment возвращает деньги.
- Refund Tool и BOB синхронизируют между собой статусы, потому что пока им обоим это нужно. Мы пока не готовы полностью переключиться в Refund Tool, поскольку в BOB есть UI, отчеты для бухгалтерии, и вообще много данных, которые так просто не перенесёшь. Приходится сидеть на двух стульях.
- Уходит запрос на фискализацию.
В итоге мы сделали на Kafka некую шину событий — event-bus, на которой все завязалось. Ура, теперь у нас есть единая точка отказа (сарказм).

Плюсы и минусы довольно очевидны. Мы сделали шину, значит, теперь все сервисы от неё зависят. Это упрощает проектирование, но привносит в систему единую точку отказа. Упадет kafka, процесс встанет.
Что такое events-driven API
Хороший ответ на этот вопрос есть в докладе Мартина Фаулера (GOTO 2017) «The Many Meanings of Event-Driven Architecture».
Кратко, что мы сделали:
- Завернули все асинхронные обмены через events storage. Вместо того, чтобы сообщать по сети каждому заинтересованному потребителю об изменении статуса, мы пишем в централизованное хранилище событие об изменении состояния, а заинтересованные в топике потребители читают оттуда всё, что появляется.
- Событие (event) в данном случаем — это уведомление (notifications) о том, что что-то где-то поменялось. Например, изменился статуса заказа. Потребитель, которому важны какие-то сопроводительные изменению статуса данные и которых нет в уведомлении, может узнать их состояние сам.
- Максимальный вариант — полноценный event sourcing, state transfer, при котором event содержит всю информацию, необходимую для обработки: откуда и в какой статус перешли, как именно поменялись данные и пр. Вопрос только в целесообразности и в объеме информации который вы можете себе позволить хранить.
В рамках запуска Refund Tool мы использовали третий вариант. Это упростило обработку событий, поскольку не нужно добывать подробную информацию, плюс исключило сценарий, когда каждое новое событие порождает всплеск уточняющих get-запросов от потребителей.
Сервис Refund Tool не нагруженный, поэтому Kafka там скорее проба пера, чем необходимость. Не думаю, что, если бы cервис возврата средств стал highload-проектом, бизнес был бы рад.
Async exchange AS IS
Для асинхронных обменов, PHP департамент обычно использует RabbitMQ. Собрали данные для запроса, положили в очередь, и консьюмер этого же сервиса его считал и отправил (или не отправил). Для самого API Lamoda активно использует Swagger. Проектируем API, описываем его в Swagger, генерируем клиентский и серверный код. Ещё мы используем чуть расширенный JSON RPC 2.0.
Кое-где используются esb-шины, кто-то живет на activeMQ, но, в целом, RabbitMQ — стандарт.
Async exchange TO BE
Проектируя обмен через events-bus, прослеживается аналогия. Мы похожим образом описываем будущий обмен данными через описания структуры event«а. Формат yaml, кодогенерацию пришлось делать самим, генератор по спецификации создает DTO и учит клиенты и серверы с ними работать. Генерация идет на два языка — golang и php. Это позволяет держать библиотеки согласованными. Генератор написан на golang, за что получил имя gogi.
Event-sourcing на Kafka — вещь типичная. Есть решение от главной enterprise версии Kafka Confluent, есть nakadi, решение от наших «братьев» по доменной области Zalando. Наша мотивация начать с vanilla Kafka — это оставить решение бесплатным, пока окончательно не решили будем ли повсеместно его использовать, а также оставить себе пространство для маневра и доработок: мы хотим поддержку своего JSON RPC 2.0, генераторы под два языка и посмотрим что ещё.
Иронично, что даже в таком счастливом случае, когда есть примерно аналогичный бизнес Zalando, который сделал примерно похожее решение, мы не можем его эффективно использовать.
Архитектурно на запуске паттерн такой: читаем напрямую из Kafka, но пишем только через events-bus. Для чтения в Kafka много готового: брокеры, балансировщики и она более-менее готова под масштабирование по-горизонтали, это хотелось сохранить. Запись же, мы захотели завернуть через один Gateway aka Events-bus, и вот почему.
Events-bus
Или автобус событий. Это просто stateless http gateway, который берет на себя несколько важных ролей:
- Валидация продьюсинга — проверяем, что события отвечают нашей спецификации.
- Мастер-система по событиям, то есть это главная и единственная система в компании, которая отвечает на вопрос, какие же events с какими структурами считаются валидными. В валидацию входят просто типы данных и enums для жесткой спецификации содержимого.
- Hash-функция для шардирования — структура сообщения Kafka это key-value и вот по хешу от key вычисляется, куда это класть.
Why
Мы работаем в большой компании с отлаженным процессом. Зачем что-то менять? Это эксперимент, и мы рассчитываем получить несколько выгод.
1: n+1 обмены (один ко многим)
С Kafka очень просто подключать к API новых потребителей.
Допустим у вас есть справочник, который нужно держать актуальным в нескольких системах сразу (и в каких-нибудь новых). Раньше мы изобретали bundle, который реализовывал set-API, а мастер-системе сообщали адреса потребителей. Теперь мастер-система шлёт обновления в топик, а все, кому интересно читают. Появилась новая система — подписали её на топик. Да, тоже bundle, но попроще.
В случае с refund-tool, который суть кусочек BOB, нам удобно через Kafka держать их синхронизированными. Payment говорит, что деньги вернули: BOB, RT об этом узнали, поменяли себе статусы, Fiscalization Service об этом узнал и выбил чек.

У нас есть планы сделать единый Notifications Service, который бы оповещал клиента о новостях по его заказу/возвратам. Сейчас эта ответственность размазана между системами. Нам будет достаточно научить Notifications Service вылавливать из Kafka релевантную информацию и реагировать на неё (и отключить в остальных системах эти уведомления). Никаких новых прямых обменов не потребуется.
Data-driven
Информация между системами становится прозрачной — какой бы «кровавый enterprise» у вас не стоял и каким бы пухлым не был ваш backlog. В Lamoda есть отдел Data Analytics, который собирает данные по системам и приводит их в переиспользуемый вид, как для бизнеса, так и для интеллектуальных систем. Kafka позволяет быстро дать им много данных и держать этот информационный поток актуальным.
Replication log
Сообщения не исчезают после прочтения, как в RabbitMQ. Когда event содержит достаточно информации для обработки, у нас появляется история последних изменений по объекту, и, при желании, возможность эти изменения применить.
Срок хранения replication log зависит от интенсивности записи в этот топик, Kafka позволяет гибко настроить пределы по времени хранения и по объему данных. Для интенсивных топиков важно чтобы все потребители успевали вычитывать информацию раньше, чем она исчезает, даже в случае кратковременной неработоспособности. Обычно получается хранить данные за единицы дней, что вполне достаточно для саппорта.
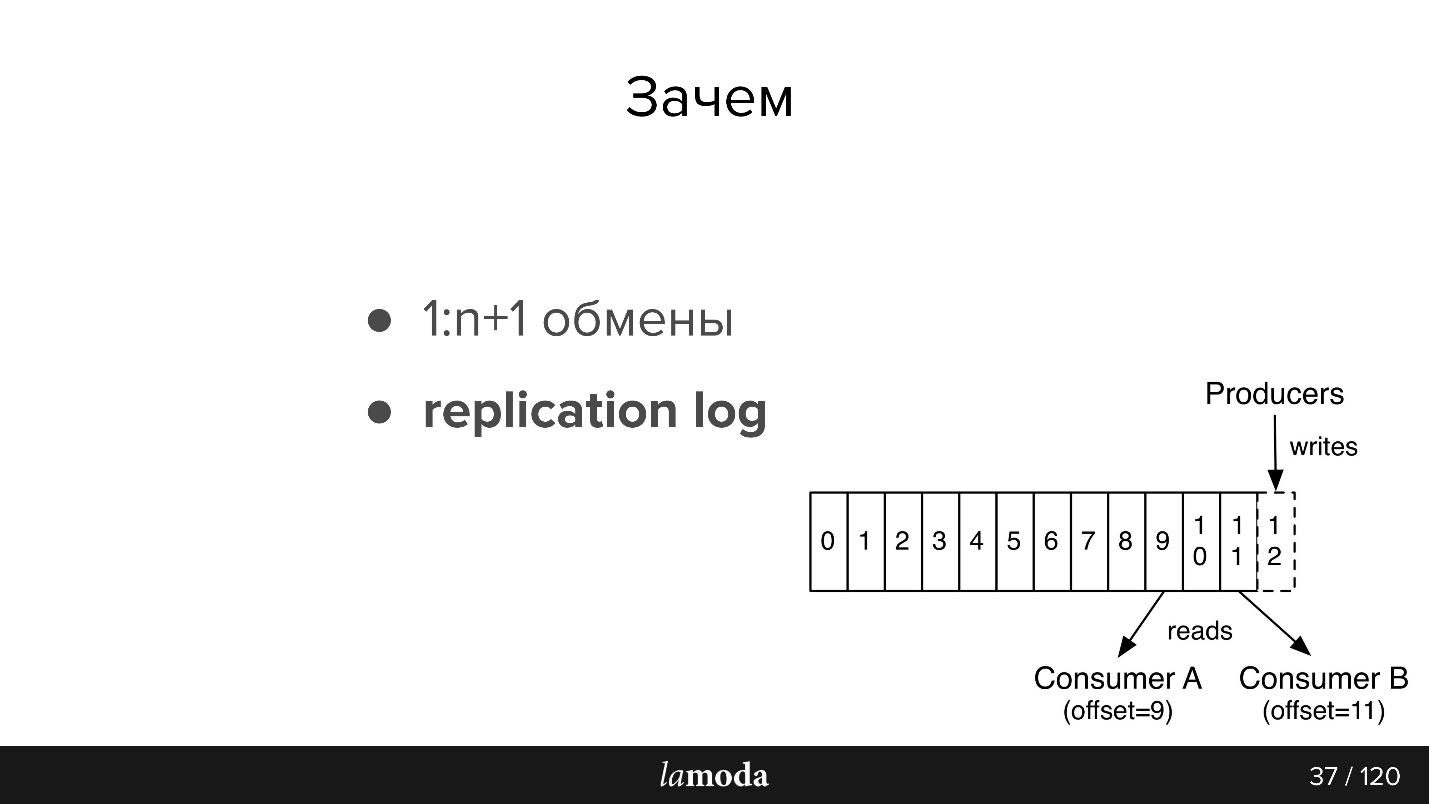
Дальше чуть-чуть пересказа документации, для тех кто с Kafka не знаком (картинка тоже из документации)
В AMQP есть очереди: пишем сообщения в очередь для консьюмера. Как правило, одну очередь обрабатывает одна система с одной и той же бизнес-логикой. Если нужно оповестить несколько систем, можно научить приложение писать в несколько очередей или настроить exchange с механизмом fanout, который сам их клонирует.
В Kafka есть похожая абстракция topic, в которую вы пишите сообщения, но они не исчезают после прочтения. По умолчанию, при подключении к Kafka, вы получаете все сообщения, и при этом есть возможность сохранить место, на котором вы остановились. То есть вы читаете последовательно, можете не отметить сообщение прочитанным, но сохранить id, с которого потом продолжите чтение. Id, на котором вы остановились, называется offset (смещение), а механизм — commit offset.
Соответственно, можно реализовать разную логику. Например, у нас BOB существует в 4 инстансах для разных стран — Lamoda есть в России, Казахстане, Украине, Белоруссии. Поскольку они деплоятся отдельно, у них немножко свои конфиги и своя бизнес-логика. Мы указываем в сообщении, к какой стране оно относится. Каждый консьюмер BOB в каждой стране читает с разными groupId, и, если сообщение к нему не относится, пропускают его, т.е. сразу коммитит offset +1. Если тот же топик читает наш Payment Service, то он делает это с отдельной группой, и поэтому offset не пересекаются.
Требования к событиям:
- Полнота данных. Хотелось бы, чтобы в событии было достаточно данных, чтобы его можно было обработать.
- Целостность. Мы делегируем Events-bus проверку того, что событие консистентное и он может его обработать.
- Порядок важен. В случае с возвратом мы вынуждены работать с историей. С нотификациями порядок не важен, если это однородные нотификации, email будет одинаковый независимо от того, какой заказ прибыл первым. В случае возврата есть четкий процесс, если поменять порядок, то возникнут исключения, refund не создастся или не обработается — мы попадем в другой статус.
- Согласованность. У нас есть хранилище, и теперь мы вместо API создаем events. Нам нужен способ, быстро и дешево передавать в наши сервисы информацию о новых events и об изменениях в уже существующих. Это достигается с помощью общей спецификации в отдельном git-репозитории и кодогенераторов. Поэтому клиенты и серверы в разных сервисах у нас согласованы.
Kafka в Lamoda
У нас есть три инсталяции Kafka:
- Logs;
- R&D;
- Events-bus.
Сегодня мы говорим только о последнем пункте. В events-bus у нас не очень большие инсталляции — 3 брокера (сервера) и всего 27 топиков. Как правило, один топик — это один процесс. Но это тонкий момент, и сейчас мы его коснемся.
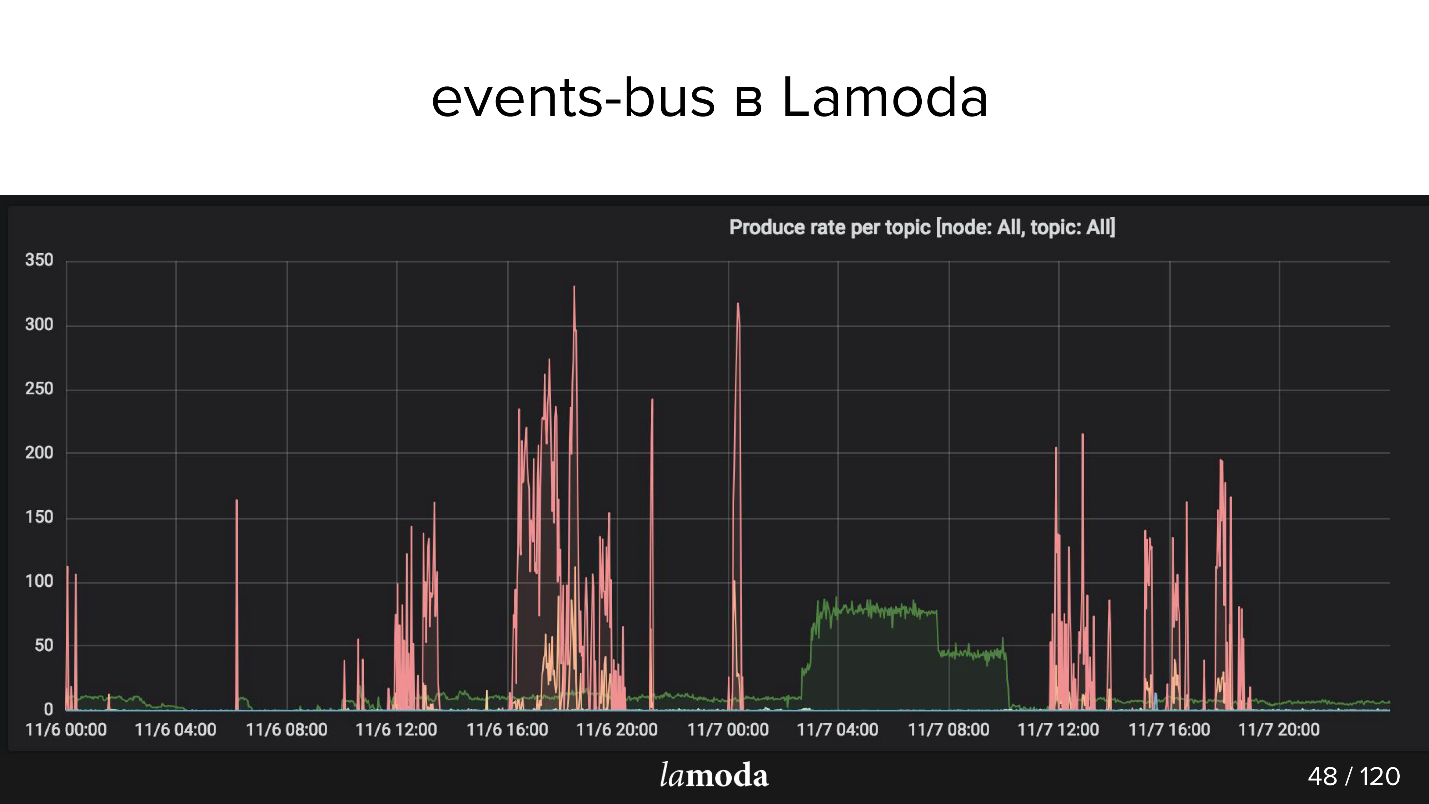
Выше график rps. Процесс refunds помечен бирюзовой линией (да-да, тот, лежащий на оси X), а розовым — процесс обновления контента.
Каталог Lamoda содержит миллионы товаров, причем данные все время обновляются. Одни коллекции выходят из моды, взамен них выпускаются новые, в каталоге постоянно появляются новые модели. Мы стараемся предсказать, что будет интересно нашим клиентам завтра, поэтому постоянно закупаем новые вещи, их фотографируем и обновляем витрину.
Розовые пики — это product update, то есть изменения по товарам. Видно, что ребята фотографировали, фотографировали, а потом раз! — загрузили пачку событий.
Lamoda Events use cases
Построенную архитектуру мы используем для таких операций:
- Отслеживание статусов возвратов: call-to-action и трекинг статусов от всех вовлеченных систем. Оплата, статусы, фискализация, нотификации. Тут мы опробовали подход, сделали инструменты, собрали все баги, написали документацию и рассказали коллегам, как этим пользоваться.
- Обновление карточек товара: конфигурация, мета-данные, характеристики. Читает одна система (которая отображает), а пишут несколько.
- Email, push и sms: заказ собрался, заказ доехал, возврат принят и т.д., много их.
- Сток, обновление склада — количественное обновление наименований, просто числа: поступление на склад, возврат. Нужно чтобы все системы, связанные с резервированием товара, оперировали максимально актуальными данными. Сейчас система обновления стока довольно сложна, Kafka позволит её упростить.
- Data Analysis (R&D-отдел), ML-инструменты, аналитика, статистика. Мы хотим, чтобы информация была прозрачна — для этого Kafka хорошо подходит.
Теперь более интересная часть про набитые шишки и интересные открытия, которые произошли за полгода.
Проблемы проектирования
Допустим, мы хотим сделать новую штуку — например, перевести на Kafka весь процесс доставки. Сейчас часть процесса реализуется в Order Processing в BOB. За передачей заказа в службу доставки, перемещением на промежуточный склад и прочим стоит статусная модель. Есть целый монолит, даже два, плюс куча API, посвященных доставке. Они знают о доставке гораздо больше.
Кажется, что это похожие области, но для Order Processing в BOB и для системы доставки статусы отличаются. Например, некоторые курьерские службы не отправляют промежуточные статусы, а только финальные: «доставили» или «потеряли». Другие, наоборот, очень подробно сообщают о перемещении товара. У всех свои правила валидации: для кого-то email валидный, значит его обработают; для других — не валидный, но заказ все равно будет обработан, потому что есть телефон для связи, а кто-то скажет, что такой заказ вообще обрабатывать не будет.
Поток данных
В случае с Kafka возникает вопрос организации потока данных. Эта задача связана с выбором стратегии по нескольким пунктам, пройдемся по ним всем.
В один топик или в разные?
У нас есть спецификация события. В BOB мы пишем, что такой-то заказ надо доставить, и указываем: номер заказа, его состав, какие-то SKU и бар-коды и т.д. Когда товар прибудет на склад, доставка сможет получить статусы, timestamps и все, что нужно. Но дальше мы хотим в BOB получать обновления по этим данным. У нас возникает обратный процесс получения данных из доставки. Это то же самое событие? Или это отдельный обмен, который заслуживает отдельного топика?
Скорее всего, они будут сильно схожи, и соблазн сделать один топик небезоснователен, потому что отдельный топик — это отдельные консьюмеры, отдельные конфиги, отдельная генерация всего этого. Но не факт.
Новое поле или новое событие?
Но если использовать те же события, то возникает другая проблема. Например, не все системы доставки могут сгенерировать такое DTO, которое сможет генерировать BOB. Мы отправляем им id, а они их не сохраняют, потому что им они не нужны, а с точки зрения старта процесса event-bus это поле обязательно.
Если мы вводим для event-bus правило, что это поле обязательно, то вынуждены в BOB или в обработчике стартового события ставить дополнительные правила валидации. Валидация начинает расползаться по сервису — это не очень удобно.
Еще одна проблема — это соблазн инкрементальной разработки. Нам говорят, что нужно что-то добавить в событие, и, может быть, если хорошо подумать, это должно было быть отдельное событие. Но в нашей схеме отдельное событие — это отдельный топик. Отдельный топик — это весь тот процесс, который я описал выше. У разработчика возникает соблазн просто внести в JSON схему еще одно поле и перегенерировать.
В случае refunds мы так за полгода приехали к событию событий. У нас было одно мета-событие, которое называется refund update, в котором было поле type, описывающие, в чем собственно этот update заключается. От этого у нас были «прекрасные» свичи с валидаторами, которые говорили, как надо валидировать это событие с этим type.
Версионирование событий
Для валидации сообщений в Kafka можно использовать Avro, но нужно было сразу закладывать на это и использовать Confluent. В нашем случае с версионированием приходится быть осторожным. Не всегда будет возможно перечитать сообщения из replication log, потому что модель «уехала». В основном, получается строить версии так, чтобы модель была обратно совместимой: например, сделать поле временно необязательным. Если различия слишком сильны, начинаем писать в новый топик, а клиенты пересаживаем, когда они дочитают старый.
Гарантия порядка чтения partitions
Топики внутри Kafka разбиты на partitions. Это не очень важно пока мы проектируем сущности и обмены, но важно, когда решаем, как это консьюмить и масштабировать.
В обычном случае вы пишите в Kafka один топик. По умолчанию используется один partition, и все сообщения этого топика попадают в него. А консьюмер соответственно последовательно читает эти сообщения. Допустим, теперь, нужно расширить систему так, чтобы сообщения читали два разных консьюмера. Если вы, например, отправляете СМС, то можно сказать Kafka сделать дополнительный partition, и Kafka начнет раскладывать сообщения на две части — половину туда, половину сюда.
Как Kafka их делит? У каждого сообщения есть тело (в котором мы храним JSON) и есть key. К этому ключу можно приложить хэш-функцию, которая будет определять, в какой partition попадет сообщение.
В нашем случае с refunds это важно, если мы берем два partition, то есть шанс, что параллельный консьюмер обработает второе событие раньше первого и будет беда. Хэш-функция гарантирует, что сообщения с одинаковым ключом попадут в один и тот же partition.
Events vs commands
Это еще одна проблема, с которой мы столкнулись. Event — это некое событие: мы говорим, что что-то где-то произошло (something_happened), например, item отменился или произошел refund. Если эти события кто-то слушает, то по «item отменился» сущность refund будет создана, а «произошел refund» запишется где-то в сетапах.
Но обычно, когда вы проектируете события, вы же не хотите писать их зря — вы закладываетесь на то, что их кто-то будет читать. Высок соблазн написать не something_happened (item_canceled, refund_refunded), а something_should_be_done. Например, item готов к возврату.
С одной стороны, это подсказывает, как событие будет использовано. С другой стороны, это гораздо меньше похоже на нормальное название события. К тому же, отсюда уже недалеко до команды do_something. Но у вас нет гарантии, что это событие кто-то прочитал;, а если прочитал, то прочитал успешно;, а если прочитал успешно, то сделал что-то, и это что-то прошло успешно. В тот момент, когда событие становится do_something, становится необходима обратная связь, и это проблема.

В асинхронном обмене в RabbitMQ, когда вы прочитали сообщение, сходили в http, у вас есть response — хотя бы, что сообщение было принято. Когда вы записали в Kafka, есть сообщение, что вы записали в Kafka, но о том, как оно обработалось, вы ничего не знаете.
Поэтому в нашем случае пришлось вводить ответное событие и настраивать мониторинг на то, что если вылетело столько-то событий, через такое-то время должно поступить столько же ответных событий. Если этого не произошло, то кажется, что-то пошло не так. Например, если мы отправили событие «item_ready_to_refund», мы ожидаем, что refund создастся, клиенту вернутся деньги, нам вылетит событие «money_refunded». Но это не точно, поэтому нужен мониторинг.
Нюансы
Есть довольно очевидная проблема: если вы читаете с топика последовательно, и у вас какое-то сообщение плохое, консьюмер падает, и дальше вы не уйдете. Вам нужно остановить все консьюмеры, коммитить offset дальше, чтобы продолжить читать.
Мы об этом знали, на это заложились, и все равно это произошло. А произошло это потому, что событие было валидным с точки зрения events-bus, событие было валидным с точки зрения валидатора приложения, но оно не было валидным с точки зрения PostgreSQL, потому что у нас в одной системе MySQL с UNSIGNED INT, а в свеженаписанной системе был PostgreSQL просто с INT. У него размер чуть поменьше, и Id не уместился. Symfony умер с исключением. Мы, конечно, исключение поймали, потому что заложились на него, и собирались коммитить этот offset, но перед этим хотели инкрементировать счетчик проблем, раз уж сообщение обработалось неудачно. Счетчики в этом проекте тоже лежат в базе, а Symfony уже закрыл общение с базой, и второе исключение убило весь процесс без шансов коммитить offset.
Какое-то время сервис полежал — к счастью, с Kafka это не так страшно, потому что сообщения остаются. Когда работа восстановится их можно будет дочитать. Это удобно.
У Kafka есть возможность через tooling поставить произвольный offset. Но чтобы это сделать, нужно остановить все консьюмеры — в нашем случае приготовить отдельный релиз, в котором не будет консьюмеров, redeployments. Тогда у Kafka через tooling можно сместить offset, и сообщение пройдет.
Другой нюанс — replication log vs rdkafka.so — связан со спецификой нашего проекта. У нас PHP, а в PHP, как правило, все библиотеки, общаются с Kafka через репозиторий rdkafka.so, а дальше идет какая-то обертка. Может быть, это наши личные трудности, но оказалось, что просто перечитать кусочек уже прочитанного не так-то просто. В общем, были программные проблемы.
Возвращаясь к особенностям работы с partitions, прямо в документации написано consumers >= topic partitions. Но я узнал об этом гораздо позже, чем хотелось бы. Если вы хотите масштабироваться и иметь два консьюмера, вам нужно как минимум два partitions. То есть, если у вас был один partition, в котором накопилось 20 тысяч сообщений, и вы сделали свежий, число сообщений выровняется поровну нескоро. Поэтому, чтобы иметь два параллельных консьюмера, надо разбираться с partitions.
Мониторинг
Думаю, по тому, как мы мониторим, будет еще понятнее, какие проблемы есть в существующем подходе.
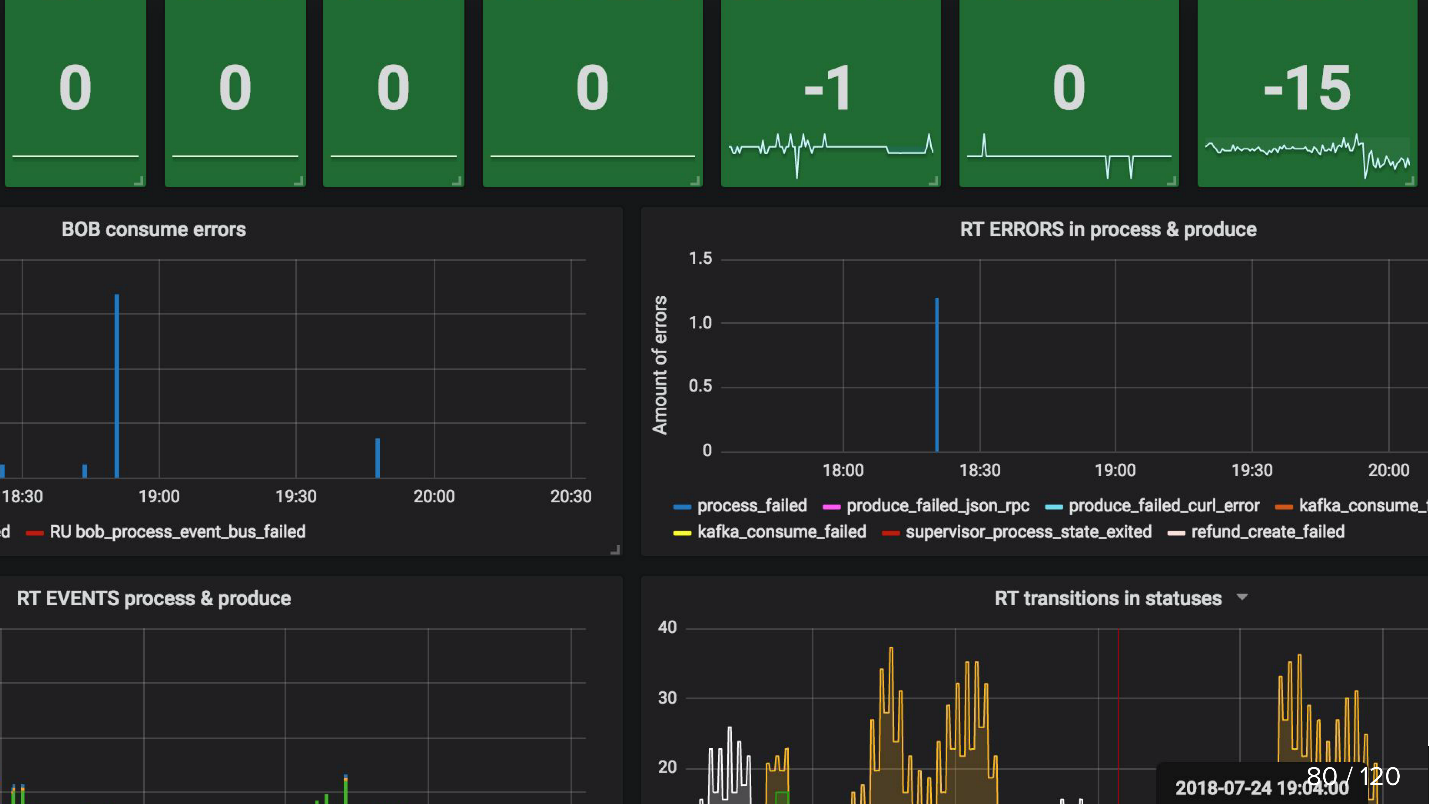
Например, считаем, сколько товаров в базе недавно изменили статус, и, соответственно, по этим изменениям должны были случиться события, и отправляем это число в свою систему мониторинга. Потом из Kafka мы получаем второе число, сколько на самом деле было прописано событий. Очевидно, разница между этими двумя числами всегда должна быть нулевой.

Кроме того, надо мониторить, как дела у продьюсера, принял ли events-bus сообщения, и как дела у консьюмера. Например, на графиках ниже у Refund Tool все хорошо, а у BOB явно какие-то проблемы (синие пики).

Я уже упоминал consumer-group lag. Грубо говоря, это количество непрочитанных сообщений. В целом консьюмеры у нас работают быстро, поэтому лаг обычно равен 0, но иногда может быть кратковременный пик. Kafka умеет это из коробки, но нужно задать некий интервал.
Есть проект Burrow, который даст вам больше информации по Kafka. Он просто по API по consumer-group отдает статус, как у этой группы дела. Помимо ОК и Failed там есть warning, и вы сможете узнать, что ваши консьюмеры не справляются с темпом продьюсинга — не успевают вычитывать то, что пишется. Система довольно умная, ее удобно использовать.
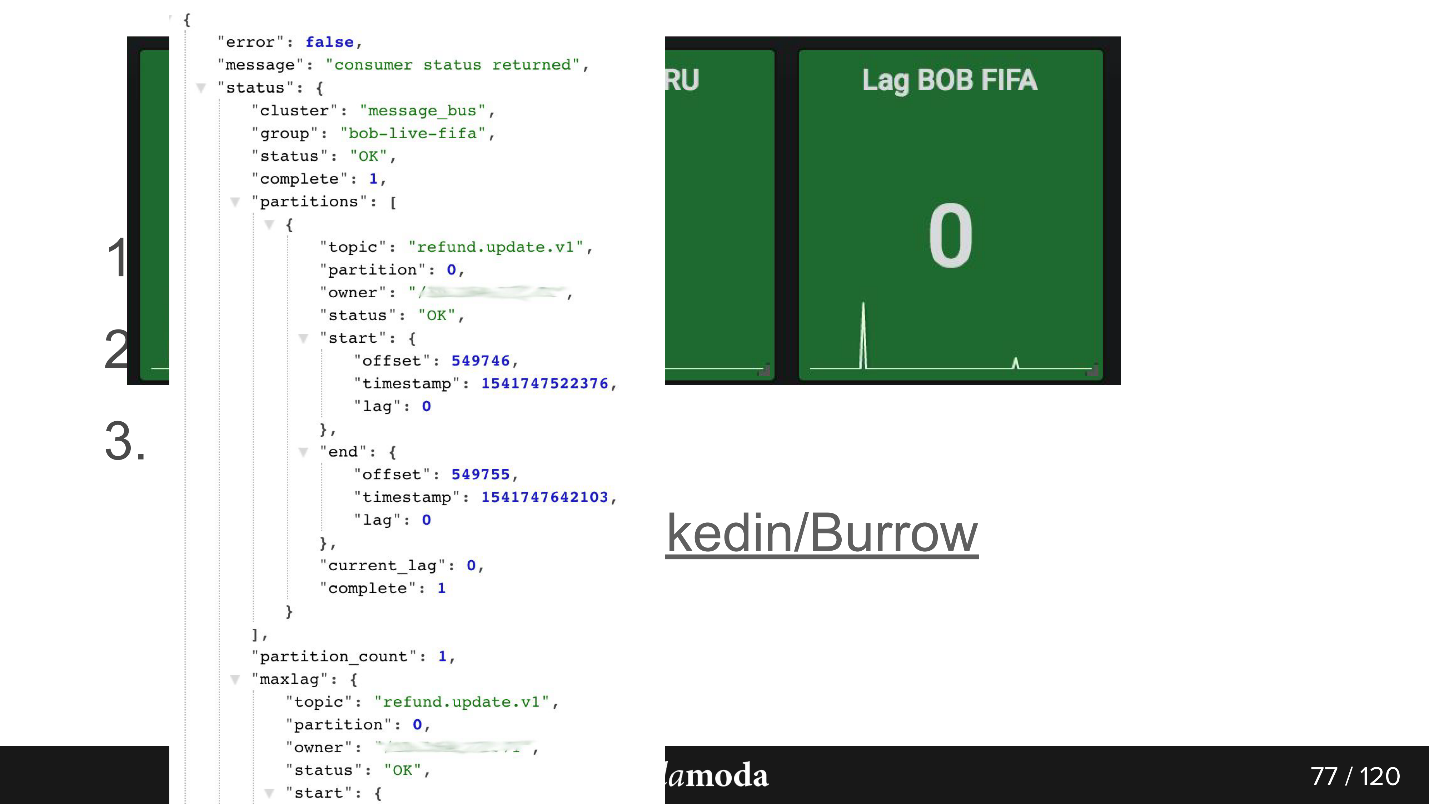
Так выглядит ответ по API. Здесь группа bob-live-fifa, partition refund.update.v1, статус ОК, lag 0 — последний конечный offset такой-то.
Мониторинг updated_at SLA (stuck) я уже упоминал. Например, товар перешел в статус, что он готов к возврату. Мы ставим Cron, который говорит, что если за 5 минут этот объект не перешел в refund (мы возвращаем деньги через платежные системы очень быстро), то что-то точно пошло не так, и это точно случай для саппорта. Поэтому просто берем Cron, который читает такие штуки, и если они больше 0, то присылает алерт.
Подводя итог, использовать события удобно, когда:
- информация нужна нескольким системам;
- не важен результат обработки;
- событий немного или события маленькие.
Казалось бы, у статьи вполне конкретная тема — асинхронный API на Kafka, но в связи с ней хочется сразу много всего порекомендовать.
Во-первых, следующий HighLoad++ на нужно ждать до ноября, уже в апреле будет его питерская версия, а в июне поговорим про высокие нагрузки в Новосибирске.
Во-вторых, автор доклада Сергей Заика входит в Программный комитет нашей новой конференции про управление знаниями KnowledgeConf. Конференция однодневная, пройдет 26 апреля, но программа у нее очень насыщенная.
А еще в мае будет PHP Russia и РИТ++ (с DevOpsConf в составе) — туда еще можно предложить свою тему, рассказать про свой опыт и пожаловаться на свои набитые шишки.
