Опыт построения инфраструктуры на микросервисной архитектуре

За последний год публикаций о микросервисах стало так много, что рассказывать что это и зачем нужно было бы пустой тратой времени, так что дальнейшее изложение будет сконцентрировано на вопросе — каким способом бы реализовали эту архитектуру и почему именно так и с какими проблемами столкнулись.
У нас в небольшом банке были большие проблемы: 3 python монолита связанных чудовищным количеством синхронных RPC взаимодействий с большим объемом legacy. Что бы хотя бы отчасти решить все возникающие при этом проблемы было принято решение перейти на микросервисную архитектуру. Но прежде чем решиться на такой шаг нужно ответить на 3 основных вопроса:
- Как разбить монолит на микросервисы и какими критериями следует при этом руководствоваться.
- Каким образом микросервисы будут взаимодействовать?
- Как осуществлять мониторинг?
Собственно кратким ответам на эти вопросы и будет посвящена данная статья.
Как разбить монолит на микросервисы и какими критериями следует при этом руководствоваться.
Этот, казалось бы простой вопрос, определил в конечном итоге всю дальнейшую архитектуру.
Мы — банк, соответственно вся система крутиться вокруг операций с финансами и различными вспомогательными вещами. Перенести финансовые ACID транзакции на распределенную систему с сагами безусловно можно, но в общем случае крайне трудно. Таким образом мы выработали следующие правила:
- Соблюдать S из SOLID применительно к микросервисам
- Транзакция должна целиком осуществляться в микросервисе — никаких распределенных транзакций на уроне БД
- Для работы микросервису в нужна информация из его собственной базы данных или из запроса
- Стараться обеспечить чистоту (в смысле функциональных языков) для микросервисов
Естественно одновременно и полностью удовлетворить их оказалось невозможным, но даже частичная реализация сильно упрощает разработку.
Каким образом микросервисы будут взаимодействовать?
Вариантов множество, но в конечном итоге их всех можно абстрагировать простым «микросервисы обмениваются сообщениями», но если реализовать синхронный протокол (например RPC через REST) то большинство недостатков монолита сохранятся, а вот достоинств микросервисов почти не появится. Так что очевидным решением было взять любой брокер сообщений и начать работать. Выбирая между RabbitMQ и Кафкой остановились на последней и вот почему:
- Кафка проще и предоставляет единственную модель передачи сообщений — Publish–subscribe
- Можно сравнительно просто получить данные из кафки второй раз. Это чрезвычайно удобно для отладки или исправления багов при некорректной обработке, а также для мониторинга и логирования.
- Понятный и простой способ масштабирования сервиса: добавили партиций в топик, запустили больше подписчиков — остальное сделает кафка.
Дополнительно хочу обратить внимание на очень качественное и детальное сравнение.
Очереди на кафке+асинхронность позволяют нам:
- Ненадолго выключать любой микросервис для обновлений без заметных последствий для остальных
- Надолго выключать любой сервис и не возиться с восстановлением данных. Например недавно падал микросервис фискализации. Починили через 2 часа, он забрал необработанные счета из кафки и всё обработал. Не нужно было как раньше по HTTP логам и по отдельной таблице в БД восстанавливать что там должно было произойти и вручную проводить.
- Запускать тестовые варианты сервисов на актуальных данных с прода и сравнивать результаты их обработки с версией сервиса на проде.
В качестве системы сериализации данных мы выбрали AVRO, почему — описано в отдельной статье.
Но вне зависимости от выбранного способа сериализации важно понимать как будет проходить обновление протокола. Хотя AVRO и поддерживает Schema Resolution мы этим не пользуемся и решаем чисто административно:
- Данные в топики пишутся и читаются только через AVRO, название топика соответствует названию схемы (а у Confluent другой подход — они в старшие байты сообщения пишут ID AVRO схемы из реестра, таким образом в одном топике у них могут быть сообщения разного типа
- Если нужно дополнить или изменить данные, то создается новая схема с новым топиком в кафке, после чего все продюсеры переключаются на новый топик, а за ними — подписчики
Сами же схемы AVRO мы храним в git-субмодулях и подключаем ко всем кафка-проектам. Централизованный реестр схем решили пока не внедрять.
P.S.: Коллеги сделали opensource вариант, но только с JSON-schema вместо AVRO.
Некоторые тонкости
Каждый подписчик получает все сообщения из топика
Это специфика модели взаимодействия Publish–subscribe — будучи подписаны на топик подписчик получит их все. В результате если сервису нужны лишь некоторые из сообщений — ему придется их отфильтровать. Если же это станет проблемой то можно будет сделать отдельный сервис-роутер, который будет раскладывать сообщения по нескольким разным топикам, тем самым реализовывать часть функционала RabbitMQ, отсутствующего в кафке. Сейчас у нас один подписчик на питоне в один поток обрабатывает примерно 7–5 тыс сообщений в секунду, если же запускать с через PyPy то скорость вырастает до 11–15 тыс/сек.
Ограничение времени жизни указателя в топике
В настройках кафки есть параметр ограничивающие время, которые кафка «помнит» на каком месте читатель остановился — по умолчанию 2 дня. Хорошо бы поднять до недели, чтобы если проблема возникает в праздники и 2 дня не будет решена, то это не привело бы к потере позиции в топике.
Ограничение времени на подтверждение чтения
Если читатель кафки не подтверждает чтение за 30 сек (настраиваемый параметр) то брокер считает что что то пошло не так и при попытке подтвердить чтение возникает ошибка. Чтобы избежать этого мы при длительной обработке сообщения Отправляем подтверждения чтения без смещения указателя.
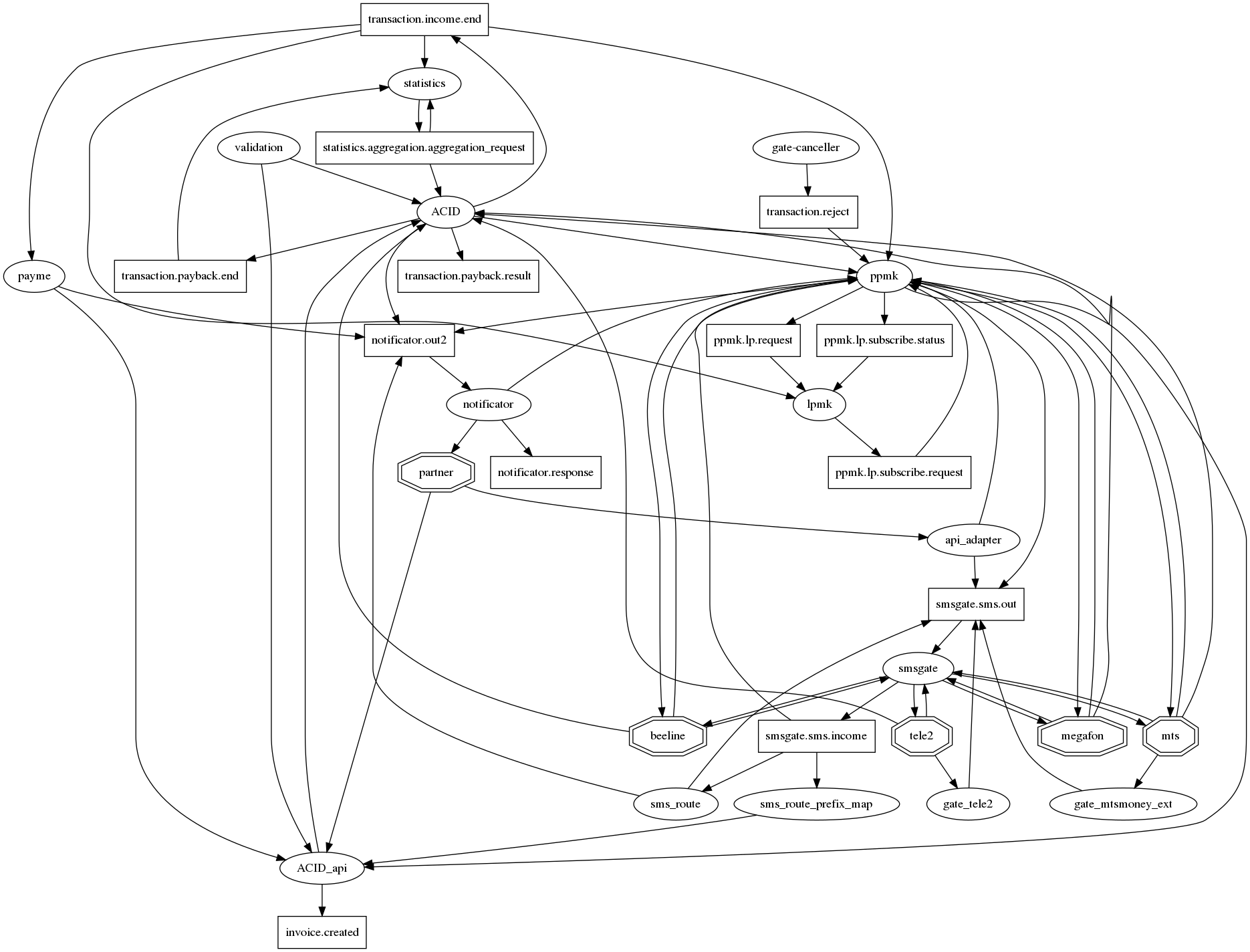
Граф связей получается трудным для восприятия
Если по-честному нарисовать все взаимосвязи в graphviz то возникает традиционный для микросервисов ёжик апокалипсиса с десятками связей в одном узле. Чтобы хоть как то сделать его (граф связей) читаемым мы договорились о следующей нотации: микросервисы — овалы, топики кафки — прямоугольники. Таким образом на одном графе удаётся отобразить и факт взаимодействия и его тип. Но, увы, становится не сильно лучше. Так что этот вопрос всё ещё открыт.
Как осуществлять мониторинг?
Ещё в рамках монолита у нас были логи в файлах и Sentry Но по мере перехода на взаимодействие через кафку и развертывания в k8s логи переместились в ElasticSearch и соответственно сначала мониторили читая логи подписчика в Эластике. Нет логов — нет работы.
За тем начали использовать Prometheus и kafka-exporter немного модифицировали его дашборд: https://github.com/kkirsanov/articles/blob/master/2019-habr-kafka/dashboard.json
В результате получаем вот такие картинки: 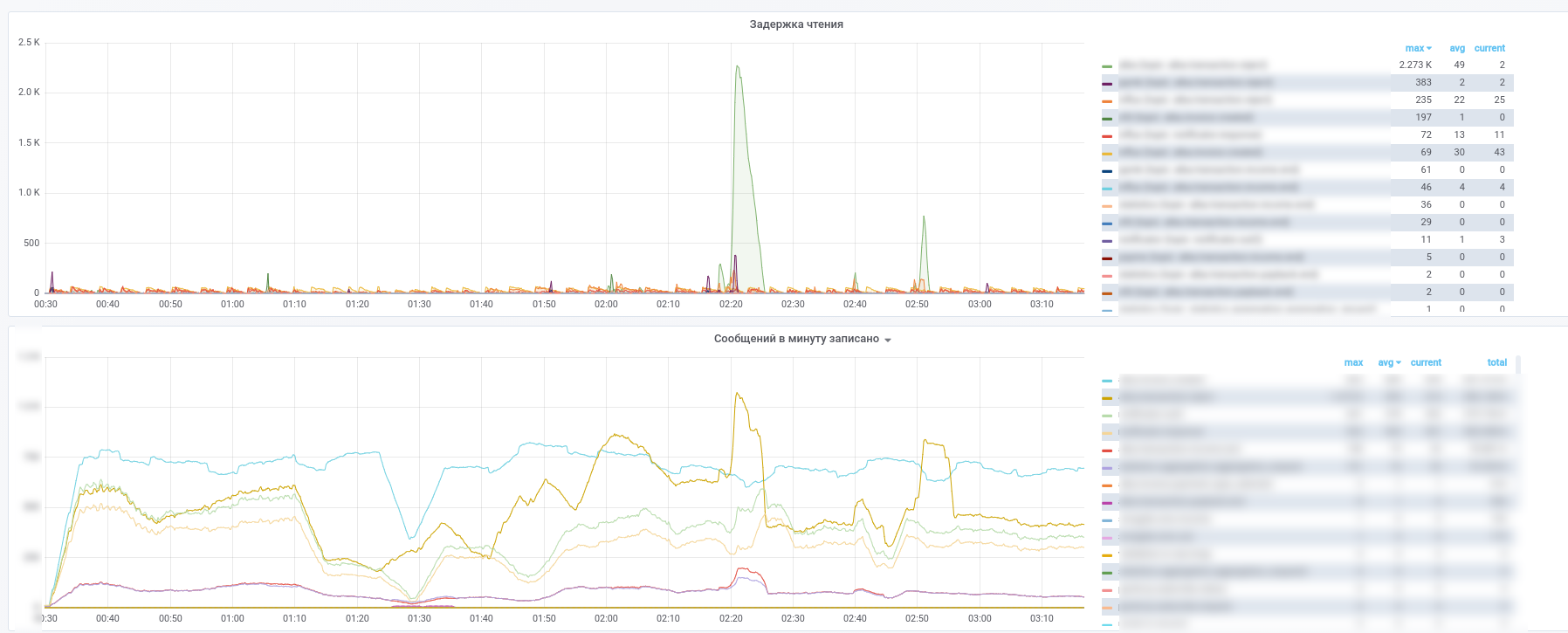
Срезу видно какой сервис какие сообщения перестал обрабатывать.
Дополнительно все сообщения из ключевых (платежные транзакции, нотификации от партнеров и т.п.) топиков копируются в InfluxDB, заведенную в ту же grafana. Так что мы можем не только фиксировать сам факт передачи сообщений, но делать разнообразные выборки по содержимому. Так что ответы на вопросы вида «каково среднее время задержки ответа от сервиса» или «Сильно ли отличается поток транзакций сегодня от вчерашнего по этому магазину» всегда под рукой.
Так же для упрощения разбора инцидентов мы используем следующий подход: каждый сервис при обработке сообщения дополняет его метаинформацией содержащей UUID выданный при появлении в системе и массив записей типа:
- название сервиса
- UUID процесса обработки в данном микросервисе
- timestamp начала процесса
- длительность процесса
- набор тегов
В результате по мере прохождения сообщения через вычислительный граф сообщение обогащается информацией о пройденном на графе пути. Получается аналог zipkin/opentracing для MQ, позволяющий получив сообщение легко восстановить его путь на графе. Особую ценность это приобретает в тех случаях, когда на графе возникают циклы. Помните пример с маленьким сервисом, доля в платежах которого составляет всего 0.0001% Анализируя мета-информацию в сообщении он может определить — являлся ли они инициатором платежа, не обращаясь при этом в БД для сверки.
