Оптимизация скриптов для витрин данных: от суток к часам
В 2022 году я присоединился к команде Газпромбанка в должности дата-инженера. В мои обязанности входила поддержка витрин данных для машинного обучения. Главной проблемой, с которой мне пришлось столкнуться, оказалось непомерно долгое время обработки данных при использовании устаревших скриптов. Например, расчет среза одной из витрин занимал более суток! Причина крылась в неоптимизированных скриптах, которые изначально разрабатывались для гораздо меньших объемов данных. Со временем объем обрабатываемой информации значительно увеличился, что закономерно привело к драматическому ухудшению производительности. В этой статье поделюсь своим опытом решения проблемы и расскажу о подходах, которые помогли сократить время выполнения с суток до нескольких часов.
Ключевые инструменты и инфраструктура
Для начала стоит обозначить технологический стек, с которым мне пришлось работать:
Apache Impala — основной движок для расчетов витрин, — механизм выполнения SQL-запросов к данным, хранящимся в Apache Hadoop (HDFS).
Cloudera Manager — инструмент мониторинга, собой сквозное приложение для управления кластерами CDP (Cloudera Data Platform). Этот инструмент использовался для просмотра общих метрик запросов.
Impala Coordinator — инструмент мониторинга, который использовался для просмотра графического плана запроса и получения детальных метрик для каждого шага.
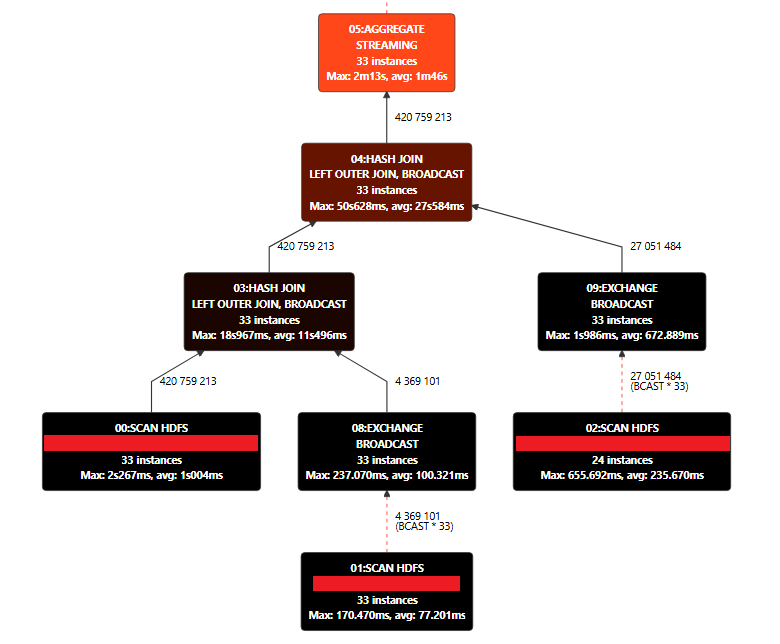

Основные метрики
Для оценки эффективности запросов использовался ряд ключевых метрик:
Время выполнения запроса;
Количество строк в результате выполнения запроса;
Объем считанной памяти;
Объем записанной памяти;
Пиковая нагрузка на ноду (узел сервера);
Спил по памяти.
Отдельно хочу остановиться на понятии «спил» (spill) — это механизм, при котором система вынуждена использовать для расчетов память физического накопителя вместо оперативной, когда превышен допустимый лимит RAM. Такой сценарий имеет два негативных последствия: во-первых, это существенно увеличивает время расчета (дисковые операции многократно медленнее работы с оперативной памятью), а во-вторых, значительно повышает нагрузку на хранилище данных, что может замедлить другие процессы в системе.
Основные проблемы и их решения
Проблема 1: Ограниченное влияние на источники данных
Первое, с чем пришлось столкнуться, это невозможность напрямую повлиять на структуру и организацию источников данных. В качестве используемых источников применялись представления (view) на слой «готовых данных», причем не всегда это были физические таблицы. Часто view представляла собой сложную конструкцию из соединения нескольких таблиц.
Кроме того, при создании временных таблиц не собиралась статистика по ним, вследствие чего в метаданных не обновлялась информация о состоянии таблиц. Это приводило к некорректному построению плана запроса координатором при обращении к таким таблицам.
Решение
Часть проблем при некорректном построении плана запроса удалось решить с помощью «хинтов» (подсказок для SQL-запроса), которые указывают координатору, как выстроить план запроса, минуя стандартные правила оптимизации.
Для эффективного применения хинтов потребовалось глубоко разобраться как в самих механизмах подсказок, так и в особенностях работы SQL-оптимизатора Impala.
Проблема 2: Спилящие запросы
Далее возникла проблема со «спилящими» запросами, что чаще всего происходило из-за превышения доступной памяти. Для понимания проблемы рассмотрим конкретный пример: допустим, для наших расчетов доступно 12 нод (узлов) с оперативной памятью по 5 Гбайт, то есть в сумме на весь расчет у нас есть около 60 Гбайт оперативной памяти.
Для выполнения расчета необходимо считать данные, обработать их и записать результаты. Каждая из этих операций использует определенный объем оперативной памяти. Для детального анализа расхода памяти нам помог Impala Coordinator, в котором можно было отслеживать графический план запроса, а также текстовый план с метриками для каждого шага.
Эти инструменты позволили оценить каждую операцию по используемым ресурсам, что дало возможность составить план оптимизации запросов. Удалось сделать прогноз, будут ли скрипты испытывать спил при дальнейшем увеличении объемов данных. Оценка производилась по параметру «пиковая нагрузка на ноду» по следующему принципу: если лимит на ноду составляет 5 Гбайт, то чем выше значение параметра при выполнении скрипта, тем выше вероятность спила. У всех спилящих скриптов этот параметр превышал 80% от лимита.
Одной из основных причин спила оказалось банальное превышение объема обрабатываемых данных для одного скрипта.
Решение
Для решения этой проблемы были созданы партицированные временные таблицы, а в условия запросов добавлено использование партиций в качестве фильтров.
Важно отметить, что партицирование может работать и во вред, если партиции сделать слишком маленькими. Оптимальный размер составляет примерно 1,5–2 Гбайт, хотя это зависит от конкретных данных и выбранного метода партицирования.
Партицирование может быть статичным (например, по дате) или динамичным (на основе входящих данных). В одном из случаев я использовал остаток от деления цифрового ключа на 10, что позволило получить равномерные по объему памяти партиции, хотя они и не несли информационной ценности сами по себе.
Главное преимущество партиций заключается в том, что Impala считывает их поэтапно и работает с каждой партицией по очереди, что позволяет существенно снизить нагрузку на оперативную память.
Проблема 3: Многократное использование одних и тех же источников
При анализе планов запросов был обнаружен еще один интересный факт: многократное обращение к одним и тем же источникам данных. При использовании в CTE (Common Table Expressions) конструкциях обращения к таблице и последующем неоднократном использовании результирующей таблицы в подзапросах, система вынуждена повторно считывать первичную таблицу.
Решение
Такие случаи пришлось выносить в отдельные временные таблицы. Оказалось гораздо эффективнее считать уже агрегированные данные, чем дважды проводить агрегацию и повторно считывать исходные данные.
Итоги и практические рекомендации
В результате удалось добиться впечатляющих результатов: скрипт, который ранее выполнялся более суток, стал работать за 4–6 часов. Не менее важно то, что он перестал создавать спил, объем которого до оптимизации мог достигать нескольких терабайт.
На основе опыта решения описанных проблем я сформулировал несколько практических советов, которые могут пригодиться при работе с большими объемами данных в Impala и подобных системах:
Боритесь со спилами путем разделения нагрузки
Если ваши запросы начинают спилить, разбейте сложные вычисления на несколько этапов. Создавайте промежуточные материализованные таблицы вместо попыток сделать все в одном запросе. Один огромный запрос почти всегда хуже нескольких последовательных меньшего размера.Используйте «хинты» для управления планом запроса
Когда оптимизатор принимает неоптимальные решения, не бойтесь использовать хинты, особенно для управления join-операциями. Это особенно полезно при работе с таблицами, где размеры сильно различаются или статистика неточна.Создавайте партиции разумного размера
Партицирование — мощный инструмент, но размер партиций критически важен. Старайтесь, чтобы размер партиции составлял 1.5–2 Гбайт. Слишком маленькие партиции могут создать излишнюю нагрузку на метаданные, а слишком большие не дадут нужного эффекта оптимизации.Собирайте статистику по временным таблицам
Никогда не пренебрегайте сбором статистики, особенно на временных таблицах. Даже 10 секунд, потраченных на сбор статистики, могут сэкономить часы расчета из-за более корректной работы координатора.Кэшируйте промежуточные результаты
Если в вашем запросе встречается многократное обращение к одним и тем же данным или повторное выполнение идентичных подзапросов, материализуйте результаты во временную таблицу. Это позволит избежать повторных чтений и вычислений.Мониторьте пиковую нагрузку на ноды
Если пиковая нагрузка на ноду превышает 80% от доступной памяти, запрос имеет высокий риск спила при дальнейшем росте данных. Такие запросы следует оптимизировать превентивно, не дожидаясь проблем.
Оптимизация существующих скриптов — задача, на которую редко выделяется достаточно времени в рамках текущих проектов. Однако лучше изначально писать код, который сможет эффективно функционировать в условиях постоянно растущих объемов данных.
Для превентивного решения подобных проблем мы разработали специальный инструмент, который оценивает параметры запроса еще на этапе его выполнения, позволяя заранее выявлять потенциально проблемные места. Но это, как говорится, уже совсем другая история, о которой я, возможно, расскажу в следующих статьях. Ранее моя коллега рассказала об оптимизации дашбордов в Superset рекомендую для ознакомления https://habr.com/ru/companies/gazprombank/articles/889408/
