Оптимизация сайта. Диагнозы и курсы лечения
Иван Михеев (AGIMA)

Сегодня мы поговорим, как ясно из названия доклада, про оптимизацию. Вообще, приходилось кому-то оптимизировать сайты? Приходилось. На этом пути нас встречает много интересностей, от того, как к нам приходит непонятный код — от предыдущего подрядчика, например, или свой код, который нам приходится потом переосмысливать — и возникают проблемы, которые при определенных нагрузках начинают нас дико беспокоить.

Если вы пришли за каким-то диким хардкором, вы в этом докладе его, к сожалению, не увидите, а может, и к счастью. То, что я буду сегодня рассказывать — это, вообще, никакой не Rocket Science, ничего сложно, это те инструменты, которые вы можете получить даже на виртуальном хостинге, если у вас на highload«е используется, допустим, виртуальный хостинг. Расскажу про инструменты, о том, какие примеры оптимизации были у нас в компании, и немножко затронем масштабирование, т.к. это тоже из оптимизации, но немного уже в другом разрезе.

Первый печальный вывод, который я сделал для себя на пути моей истории разработки — это то, что серебряной пули, вообще, нигде не существует. Т.е. нет какого-то универсального решения, универсального подхода или инструмента, который избавил бы всех от головной боли, которую мы встречаем на пути оптимизации. Поэтому вот такой вывод — серебряной пули нет.

Также по опыту я понял со временем, что если у вас вчера был день обновлений, и вчера же у вас упал сайт, то тут тоже никакой особой науки нет — дело именно в обновлении. Что мы делаем? Мы откатываем обратно и начинаем разбираться, что произошло, что было в релизе не так. Важно это понять сразу, что у вас что-то произошло не так.

Давайте поговорим о более-менее приближенной к реальности ситуации. Например, у вас растет нагрузка на сайт. Возможно, она растет равномерно, но, скорее всего, она у вас растет неравномерно, а какими-то пиками. И в эти пики вашему сайту становится дико плохо. Он начинает бесконечно отдавать страницы, у вас белый экран, вместо контента, различные случайные ошибки 500-ые и не 500-ые, вы часто замечаете оборванное от сервера соединение, или, вообще, у вас страницы загружаются наполовину, половина картинок не прогрузилась, и, вообще, там какое-то мясо творится. Эти все симптомы говорят о том, что вам пора задуматься об оптимизации вашего портала или сайта и уже начинать предпринимать какие-то шаги на пути к улучшению.

Чтобы структурировать доклад, рассмотрим типичные компоненты приложения — из чего оно, вообще, состоит? Обычно на любом языке есть какой-то front-end, где непосредственно расположен user интерфейс, т.е. если сайт, то это браузер, если приложение, то какой-то интерфейс. Есть application, на котором вертится ваше приложение, вертится вся бизнес-логика. И есть слой данных — это может быть СУБД, это может быть, не дай бог, XML, это могут быть любые данные, которые должны приходить к вам каким бы то ни было способом в application. И имея эту структуру, возвращаемся к проблеме — у нас тупит сайт, он долго грузится, есть какие-то проблемы. С чего начать? Как к этому делу подойти, что же нам делать?

Первое, что напрашивается — это посмотреть на ваш front-end, потому что это поможет вам отбросить сразу несколько вариантов того, в какую сторону вам двигаться.

Основные проблемы на этом этапе — именно проблемы, связанные с тем, почему тормозит ваш сайт. Это у вас неадекватно долго грузится страница, т.е. вы понимаете, что скрипт отработал максимально быстро, но доставка контента клиенту в браузер происходит очень долго. У вас блокируется исполнение CSS. Это про то, что если у вас, например, пользователь видит сначала белый экран, а потом это как-то неожиданно превращается для него в что-то красивое — это ситуация не очень… Когда вы видите частичную загрузку контента, т.е. картинка у вас грузится нереально долго, или у вас прорисовывается модель очень долго — это тоже не очень то ситуация. Ну и, задержка исполнения JS-скриптов, когда у вас какой-то скрипт подключается 80-м в списке всех Javaскриптов, и вы понимаете, что он отрабатывает не так, как нужно, то здесь тоже нужно что-то оптимизировать.

Для диагностики существуют достаточно простые инструменты, которые есть в каждом браузере, наверное, и не в браузере.
Первое, что напрашивается — Firebug. Все знают, как им пользоваться — нажали на F12, и даже в самом старом ie он точно имеется. Воткнули Firebug, посмотрели, какие у вас там запросы, сколько страниц отдается, когда контент загрузился, и когда исполнялся какой-то скрипт. Это, вообще, бесплатно, просто посмотрели статистику, заняло это у вас 5 минут — ну, дотянуться до клавиши F12 + пара минут. Все, у вас есть вся статистика, уже есть какое-то понимание, в какую сторону двигаться дальше.
Есть очень интересный инструмент — YSlow. Он, кроме каких-то метрик, может вам еще рассказать словами, что вам нужно исправить. Этот инструмент для меня некое открытие.
Еще есть Google PageSpeed, который вам еще скажет, как повысить ранжирование вашего сайта на основании того, что вам нужно что-то на фронте поменять. Здесь, кстати, фронт рассматривают с точки зрения клиента как браузера.
Таким образом, воткнули эти инструменты, посмотрели, что у нас сломалось, и начинаем уже что-то исправлять.

На что нужно обращать внимание, когда вы смотрите эти метрики?
Первое и ключевое, большинство контентных сайтов грешат этим — это скорость отрисовки DOM. Есть такие сайты, у которых DOM содержит ну очень много элементов — больше 10 тыс. — это уже становится проблемой для того, чтобы это рендерить, при скроллинге начинают сайты тупить, если вы открываете его на телефоне, то это еще большей проблемой становится. Итак, стоит посмотреть, сколько у вас, вообще, отрисовывается с трудом.
Второе — это наличие внешних JS и CSS. Это, вообще, отдельная тема, потому что если у вас какой-то JS, который лежит не у вас на сервере, запрашивается, причем, вы иногда не знаете, какого в итоге он будет размера, потому что есть какие-то внешние библиотеки, а с ними все сложно. И у вас, конечно же, начинает блокироваться загрузка этих скриптов, т.е. он ждет, пока загрузится один какой-то скрипт, только потом начинает грузить еще что-то. То же самое с CSS, т.е. тут нужно грамотно выделять такие скрипты и, наверное, речь уже не только о доступности сервиса, которого забирает у вас этот JS, но и об этом тоже.
У нас, например, был такой случай, когда мы выкатывали сайт одного достаточно известного фитнес-клуба. Там был некий внешний скрипт, который подключался и делал некие операции. Разработчики разрабатывали, все у них было круто, они не учли лишь то, что он у них закэшировался на браузере, и когда они в прод его вкатили, то этот скрипт у них там весил полметра. Что такое 500 Кб в рамках переброса между дисками? Это не очень большие цифры, но когда это начинает грузиться — не очень круто, когда у вас прелоады грузятся секунды. Плюс там еще было очень много графического контента, который тоже закэшировался у разработчиков, а они как бы не спросили кэш. В общем, много исследований проводили, пока в итоге не поняли, что дело это можно было бы в Firebug посмотреть и все.
Ну, и время установки соединения с сервером. Здесь все интересно, потому что тут важно понимать, реально у вас фронт тупит, или у вас просто интернет-канал какой-то очень слабенький. Такие проблемы тоже случаются, и тут скорее нужно идти разбираться с вашим провайдером сети, а не копать ваш код.

Какие же можно применить методы оптимизации фронта?
Минификация, объединение, сжатие — все это влияет лишь на два фактора — на вес и количество файлов при загрузке. Когда у вас грузятся 10 Javascript«ов, и некоторые из них из внешних сервисов, это не очень хорошо сказывается на фронтенде, потому что браузер, по-моему, может поддерживать пять одновременных соединений (зависит от версии), а все остальное блокируется. Если вы, конечно, грузите синхронно. Объединение в каком-то моменте вам помогает этого избежать — у вас из 10 файлов формируется один. И естественно, один в 30 Кб загрузится быстрее, чем 30 в 1 Кб. Это нужно понимать.
Но здесь есть следующий момент с точки зрения минификации (особенно CSS). Когда у вас идет момент отладки, то на проде некоторые открывают девелоперскую панель и начинают менять циферки, как это все поменялось, и они там еще указывают строчку. Так вот, в случае сжатых файлов, они укажут вам строчку »1», только кроме тех случаев, если у вас нет сурс мэпперов на этих минификаторах. Но и так с ними не все так однозначно, потому что иногда некоторые сурс мэпперы тоже вам только какой-то ключевой, главный элемент показывают, где начинается. А где конкретно в коде, может быть очень сложно. Тут тоже нужно очень грамотно применять подход, потому что в отладке это может сыграть с вами злую шутку.
Сжатие. Тут все, наверное, прозрачно, потому что медиаконтент нужно точно сжимать и не грузить в контейнер 100 на 100 пикселей какую-то Full HD картинку. Сейчас до сих пор встречаются случаи, когда вроде бы картиночка маленькая, а туда Full HD загоняют, и клиент говорит: «А почему так долго?». Такой момент тоже нужно учитывать.
Вторая группа инструментов для оптимизации — рефакторинг вашего JS-кода, потому что часто именно он тупит, потому что он так написан. Особенно, если вы используете какие-то фреймворки, которые вам не до конца понятны, а еще у вас DOM состоит из нескольких тысяч элементов, а еще у вас какие-то события на jQuery и т.д. Короче, все будет на самом деле не очень быстро работать.
Ну, и оптимизация DOM — это тоже важная вещь. Когда, если помнит кто, выходил iPad 1 или 2, то у них была проблема, когда они грузили всякие контентные сайты, например, новостные порталы типа woman.ru или еще какие-то такие. У них исторически сложилось, что DOM была очень сложной, т.е. очень много элементов, и просто iPad это не переваривал. Вы открывали сайт, он как бы его рендерил-рендерил, рендерил-рендерил, но это не доходило ни до ничего особо, и тогда они очень сильно по этой теме должны были оптимизироваться. Заняло, наверное, очень много времени.
Эти все пункты приведут просто к ускорению работы вашего сайта.

И бесплатный совет, который относится уже не к клиентам, а больше к фронту вашего прокси или nginx сервера — статику надо отдавать через nginx. До сих пор мы встречаемся с такими случаями, когда статика не через nignx идет, и это на диске сказывается не очень хорошо, поэтому, если у вас сайт тупит, и вы считаете, что в остальном все нормально, проверьте статику — у вас через nginx отдается или нет?

Перейдем к более интересной части, это Application и DB. Та часть, на которой на самом деле встречается большинство ошибок и которая дает вам просто полигон для оптимизации.

Если у вас медленно формируются страницы, хреново исполняется скрипт, формируется html, часто встречаются ошибки 500-ые, любые… Любая 500-ая — это уже звоночек. Если вы наблюдаете через вашу систему мониторинга какие-то простои сайта, то тут, если не нужно бить тревогу, то точно стоит задуматься, все ли у вас, вообще, в порядке. Если это какой-то единичный случай, то можно подумать, посмотреть, разобрать его, если же это череда таких случаев, то тут уже точно нужно подходить комплексно к этой задаче.

Какие у нас варианты, когда тормозит Application или DB? На самом деле таких ключевых блока три:
- у вас сервер исчерпал свой ресурс,
- программисты сделали какой-то не очень качественный код,
- или что-то неладное творится в базе.
Как в этом всем, вообще, разобраться?

Первое, что приходит в голову — это не устанавливать никакие там профилировщики, не выдумывать какую-то непонятную вещь, а просто зайти в ваш терминал и воспользоваться обычными инструментами ОС.
Есть у вас команда top, которая вам поможет понять, сколько у вас осталось памяти на сервере. Есть strace, lsof и т.д. Все эти команды есть в ОС линуксовой, под винду тоже есть подобные команды, т.е. вы ничего такого не делаете, у вас все есть под рукой, вы просто смотрите, каково текущее состояние вашего сервера. И здесь вообще нет ничего страшного.
Был случай у нас с одним ритейлером. У них есть такие вещи как каталоги, может, знаете, их в pdf выкачивают. И интересно, что в день, когда они их выкладывают, почему-то очень много людей их начинает скачивать. Не знаю, для какой цели, но там реально 2000 человек почему-то идут на этот портал и начинают качать именно каталоги. И у нас сайт прибыл чуть-чуть. Начали разбираться. Системный администратор просто воткнул laptop и понял, что все файлики отдавались через apache по access_log«ам. Но, конечно, отдавать файлики pdf через apache не очень хорошо. Просто переключили конфиг на nginx (опять же, совет помним? — статику через nginx), все залетало. Т.е. здесь явный пример — мы потратили на это 5 минут, просто воткнули laptop, посмотрели, что с дисками происходит, посмотрели access_log, все. И все сразу стало понятно, поправили.
Если даже у вас еще круче — есть система мониторинга, то вам даже в ОС особо ходить не нужно, вы из них можете это все понять. Т.е. есть различные метрики, по которым вы понимаете, где в каком месте у сервера наступил небольшой кризис.

Второй момент — это slow логи. Slow логи есть почти везде, они вам помогают определить места и время, когда произошел тот или иной запрос, или скрпит выполнялся необычайно долго. Основная тема со slow логами, может, проблема, или не проблема даже, а просто повод поспорить, поговорить — это время определения медленного запроса. Тут все на самом деле еще проще. Вы — владелец вашей системы и вы знаете, какое время запроса выполнения скрипта для вас является оптимальным или допустимым. Просто настраиваете slow лог таким образом, чтобы все критические запросы у вас писались, а все некритические не писались, т.е. вам важно понимать, какое время для вас является критичным, чтобы не считать, если два запроса выполняются больше трех секунд, то это уже все. Потому что есть такая вещь как статистика, расчеты или отчеты, а там как бы и 5 секунд на выполнение запроса в целом нормально.

Еще один совет — лучше slow логи включать сразу в начале разработки. Это вас спасет от неожиданных пиков нагрузки и последующих разборов полетов типа «что у нас случилось?». Потому что с тем же обновлением, когда вы выкатываете на прод, и у вас начинает нагрузка очень неравномерно скакать именно на сервере, то тут вам же нужно быстро откатиться и вернуть состояние. А если у вас slow лог не был включен, вам будет очень сложно собрать какую-то статистику или метрики. Если же у вас он были включен, то вы просто смотрите метрики, потом все решаете, возможно, проводите какое-то нагрузочное тестирование. Собственно, вот и все.
Также у нас есть различные логи — это error_log и access_log, т.е. все инструменты сервера, который есть в нашем распоряжении, их можно использовать, не применяя никаких дополнительных инструментов. Это то, что у вас есть в коробке ОС, плюс мониторинг. Но мониторинг нужно уже настраивать.

Следующий шаг на пути к более быстрому пониманию вашего приложения, а если оно не ваше, то это еще более интересный для вас инструмент — это профилировщики. Профилировщики есть почти что под каждый язык, мне кажется, они есть под каждый язык. И каждый уважающий себя профилировщик отмечен некими плюсами, которые, в принципе, для любого профилировщика одинаковые. Это простота использования, т.е. вы просто определяете, с какого момента вы можете стартовать, где ему нужно закончить, пишите в настройки, что он должен писать, какие поведенческие характеристики и все. На выходе вы получаете callstack всех исполненных функций за время профилирования, т.е. вы видите, какая функция сколько исполнялась, у вас есть понимание, сколько эта функция исполнялась сама по себе, сколько исполнялись ее вложенные функции, есть понимание, сколько памяти она потребляет. А логи профилировщика еще вам позволяют callgraph построить, чтобы вы могли проследить маршрут какого-то действия, которое является высоконагруженным, в данном случае, в котором время выполнения больше n-го числа секунд.

Например, есть Xhprof. Мы разрабатываем на PHP, и у нас есть Xhprof. Это то, как он выглядит. Мне кажется, у многих профилировщиков похожий интерфейс — есть некая таблица с callsteck, и есть некий граф, который вам показывает, откуда начинался какой-то сложный запрос и где он заканчивался.
Есть также Visual Studio профайлер, еще разные, на многие языки легко гуглятся любые профилировщики.
Дальше, чтобы нам лучше понимать, что же нам нужно сделать, предлагаю рассмотреть небольшой пример. Начнем с симптома.

Мы вдруг понимаем, что наш сайт очень тормозит. В данном случае высокое время исполнения скрипта именно на сервере, т.е. мы поняли, что у нас на фронте все норм, но при формировании скрипта возникают какие-то проблемы. Все, что нам нужно, это профилировщик или slow логи — кому как нравится, у кого что есть, кто что может настроить.
И такая небольшая штука — команда EXPLAIN. В дальнейшем поймете, почему.

Втыкаем профилировщик и видим вот такую штуку, что у нас 14 вызовов MySQL_query выполняются за 1 секунду. Не очень хороший показатель.
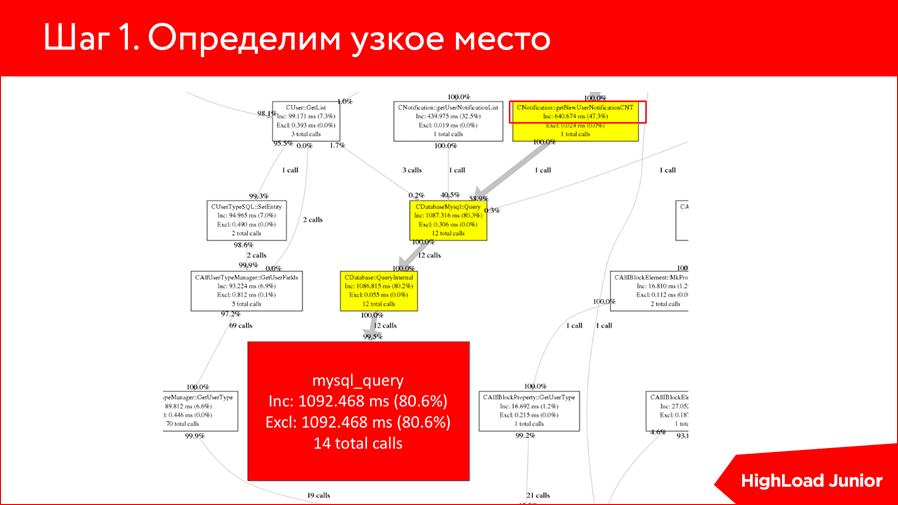
Если мы проследим немного выше, то мы понимаем, что некая функция с именем getNewUserNotificationCNT выполняется лишь 640 миллисекунд и, скорее всего, из этих 640, она 620 выполняет запрос. Т.е. можно просто предположить и понять, что здесь профилировщик отработал, и эта функция является нашим узким местом. Все, что нам нужно — пойти в эту функцию и посмотреть, что она за запрос выполняет.

Видим, что запрос весьма тривиален — это выбор количества новых, непрочитанных уведомлений. На самом деле тут, возможно, уже сразу понятно, в чем проблема, что с этим запросом не так, но чтобы проверить наши опасения, мы делаем EXPLAIN этого SELECT«а:

Мы понимаем, что этот SELECT, который хочет у пользователя выбрать все непрочитанные уведомления, пробегает по таблице с миллионом строк. Согласитесь, ситуация не очень. Я хочу выбрать отдельного юзера, у меня там, дай бог, каких-то 10 уведомлений, а он мне по всему миллиону их отбирает. Плюс, COUNT (*) — достаточно нагруженная операция. Короче, что-то здесь не так. И мы видим из этого EXPLAIN, что на этих таблицах вообще нет никаких индексов, и в данном плане он явно ничего не хочет использовать.

Мы переходим дальше. Делаем простой ALTER TABLE, добавляем INDEX по USER_ID и по прочитанным. И что мы видим? Что у нас с миллиона записей количество сократилось до двух. Мне кажется, восхитительная работа индексов с 1 млн. строчек пробегаться до двух.
Данный пример показывает, что мы воткнули EXPLAIN, посмотрели, что у нас необычайно огромное количество строк задействовано, и поняли, что нужно накатить какие-то индексы.
С индексами тоже нужно быть осторожными. И с EXPLAIN. Потому что если у вас EXPLAIN в одной версии отрабатывает по-одному, то не факт, что он отработает в такой же базе, но в другой версии, потому что EXPLAIN задействует и планировщики, и оптимизаторы, и от версии к версии стратегии планирования могут меняться. Поэтому с ними тоже нужно быть осторожным, и не факт, что индекс, который вы накатили на одной СУБД, он как бы норм для другой. Здесь очень тривиальный примерчик, но в принципе его можно скиллить на разные более сложные запросы и смотреть.
Если бы у нас были еще какие-то join«ны или еще какие-нибудь таблицы, EXPLAIN бы показал здесь еще несколько строк и сказал вам, что он использовал бы — where или индекс — и сколько строк из каждой таблицы было бы задействовано. Интересный инструмент, который, мне кажется, нужно использовать в любой диагностике запросов, он вам поможет очень много всего объяснить.

В результате у нас выполнение запросов с 1 с сократилось до 300 мс. Мне кажется, хороший показатель в целом. Если говорить по загрузке страницы, то до этой операции с индексом одной строчки кода она выполнялась за 2,5 с, после этой оптимизации — 700 мс. Т.е. ничего себе такая оптимизация, это без кэша еще.
Какие проблемы могут быть еще на нашем пути? Здесь собран некий топ логических ошибок программистов:

Первое, что встречается — выполнение запросов к СУБД в цикле. Это, когда у вас есть некий селект из какой-то таблицы, а потом внутри другого цикла, когда он идет по строчкам этого селекта, делается еще один селект, в принципе, однотипный, который можно было бы вынести в первый, через join«ы какие-то добирается дополнительная информация. Для Битрикс-разработчиков достаточно распространенная проблема, потому что они делают свой get list, по get list«у форычем идут и еще какой-то get list забирают. Не очень круто это сказывается на производительности.
Вторая проблема — это бесконечные циклы в коде, т.е. какая-то логическая ошибка, где у вас while должен идти до какого-то значения, пять раз отработать, а он у вас просто колбасит его бесконечное количество раз. Это не очень хорошо сказывается на вашем приложении, и оно просто ничего не отдает в итоге.
Также встречаются такая ошибка (с помощью профилировщика она очень хорошо определяется) — ненужные вызовы функции. Это когда у вас вместо того, чтобы запихать значение какого-то исполнения функции в переменную, эта функция подставляется вместо переменной, и она вызывается дикое количество раз, особенно при работе со строками. Такой момент, который в теории может обломать вашу систему.

Что с этим делать? Тут, как мне кажется, нет вариантов, только делать какой-то рефакторинг, исправлять ошибки в коде и в следующем делать code review более корректно.

Но в этом мире существуют еще и другие процессы, которые не являются ошибкой разработчика, скорее являются ошибкой недооцененности вашего приложения. Когда вы думали, что этот процесс не должен затрагивать большое количество ресурсов, а в итоге он просто колбасит миллионы строк — для вас это неожиданность. Есть практики и для этих вещей. Если у вас есть какой-то процесс, который не очень вам критичен в real time выполнять, просто выносите его в cron, в планировщик, либо делаете какой-то пошаговый скрипт, либо вводите понятие очередей, если нужно какую-то нагруженную операцию сделать, и потом достаточно быстро отдать контент пользователю.

Примеры таких операций типичны. Это либо импорт товаров, который явно не должен проводиться на хитах, а должен проводиться глубокой ночью, когда никого нет на сайте. Отправка почты — тоже достаточно показательный пример, потому что если у вас большой поток отправки сообщений, то это может нагрузить ваш сервер, лучше для таких вещей делать очереди. У нас были такие примеры, когда клиенту нужно было формировать отчетность в excel, и там очень много было строк, но ему было нужно, чтобы по клику показался отчет. Тут мы вводили пошаговое создание или тоже переводили в очереди, т.е. он там нажимал, ему говорили: «Скоро у тебя появится отчет, зайди через 5 минут», и потом этот отчет формировался и отдавался. Такие методики применимы и достаточно эффективны на любой платформе.

Подходим к тому вопросу, что если у вас все хорошо, если код у вас вылизан, если индексы в базе настроены, если у вас на фронте, вообще, ничего критичного нет, и вы понимаете, что сайт должен, в принципе, быстро работать, а он все равно тормозит.
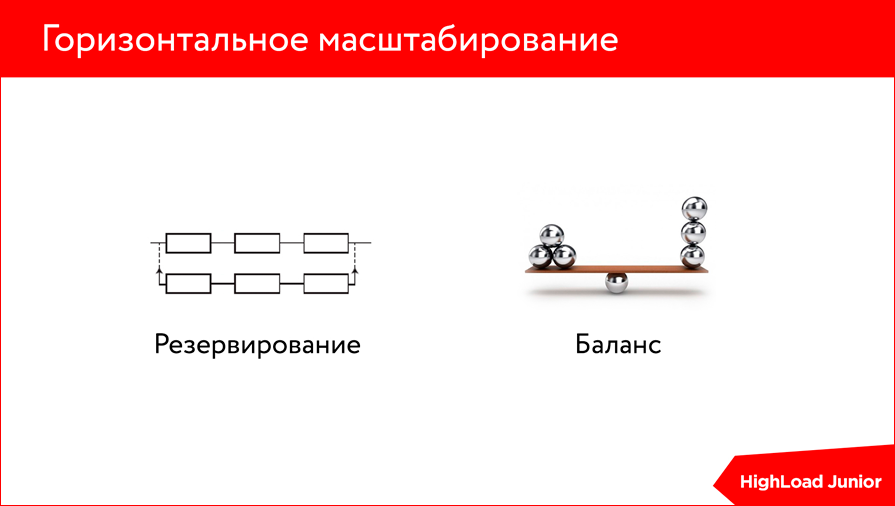
Тут нам на помощь приходит горизонтальное масштабирование, потому что любая оптимизация рано или поздно заходит в тупик — она ограничена ресурсами вашего сервера так или иначе. Т.е. сколько бы вы не вылизывали ваш код, сколько бы не разрабатывали различных подходов к формированию индексов, так или иначе у вас все когда-то упрется в ресурсы сервера.
И тут у вас есть два варианта:
- либо вы апгрейдите ваш сервер — втыкаете еще один слот оперативной памяти, делаете диски побыстрее, или просто мощность процессора увеличиваете;
- либо вы переходите к горизонтальному масштабированию, что в принципе решает две задачи. Первая — это резервирование, т.е. вы всегда имеете какой-то резерв на случай, если у вас отпал первый сервер, мастер, и у вас есть некий баланс нагрузки, т.е. ваша нагрузка концентрируется уже не на одном сервере, а распределяется на несколько, что положительно сказывается на скорости вашего приложения.
Но тут важно понимать, что это все клево, когда у вас код рабочий. Если у вас ошибки какие-то в приложении, то его и 10 серверов могут не спасти. У вас просто будет на все эти сервера какая-то нагрузка бешеная, и вы вместо того, чтобы со 100 пользователей до 1 млн. увеличиться, со 100 дойдете только до 150. Здесь важно тоже границу эту понимать.

Если подводить итог, то в принципе, не ищите универсальных способов, потому что их нет, каждая задача уникальна. Для какой-то оптимизация — достаточно прямо здесь и сейчас воткнуть слот оперативной памяти и больше вам ничего не нужно. На первое время это вам даст отсрочку до момента, пока вы будете производить рефакторинг, это не очень дорого — сделать апгрейд вашего сервера, дополнительный процессор купить, память.
В первую очередь определите узкое место, т.е. перед тем, как что-то делать, лучше провести диагностику, чтобы точно знать, в каком месте у вас реально баг.
Используйте простые инструменты, т.е. не нужно выдумывать каких-то мега решений, есть операционная система, есть ее инструменты, есть различные профилировщики — используйте их.
Купите ОЗУ — это тоже оптимизация. Здесь тоже про то, что иногда вопрос стоит не в оптимизации кода или приложения, а просто в покупке дополнительного слота оперативной памяти, что решит львиную долю ваших проблем.
И не бойтесь грядущего горизонтального масштабирования. Рано или поздно, если вы планируете, что у вас сайт будет все еще жить, вы к этому так или иначе придете, потому что нагрузка будет возрастать, будут возрастать какие-то процессы на сайте, и вам придется все равно его горизонтально масштабировать.
Контакты
miheev@agima.ru
Этот доклад — расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем HighLoad++ Junior. Сейчас мы активно готовим старшего брата HighLoad++ Junior — конференцию разработчиков высоконагруженных систем HighLoad++ 2016 года — в этом году HighLoad++ пройдёт в Сколково, 7 и 8 ноября.Разница между конференциями важна — Junior — это не для детей. Это про highload в условиях ограниченных ресурсов (временных, денежных, квалификационных). HighLoad для дизайн-студий — как выдержать высокую посещаемость в реальных условиях, без разработки собственных модулей к nginx:)
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Комментарии (1)
 fishca
fishca
30 сентября 2016 в 20:19
+1↑
↓
И мы видим из этого EXPLAIN, что на этих таблицах вообще нет никаких индексов
За это надо сразу руки отрывать таким разработчикам СУБД
