Оптимизация производительности SharePoint
Введение
Три года назад мы начали использовать SharePoint Foundation 2010 SP2 в качестве системы электронного документооборота и контроля различных бизнес процессов. Как обычно бывает в начале все «летало». Первоначально, в первый год, развернул его на обычной машине (не серверные компоненты), назовем его условно SRV1, где вместе с ним крутился Active Directory, файл-сервер, шлюз интернета, DNS и DHCP. Характеристики SRV1: Процессор — Intel® Core™ i5–2500 CPU @ 3.30GHz
Память — 8 Гб
Материнская плата — Gigabyte GA-Z68P-DS3 (2 PCI, 2 PCI-E x1, 2 PCI-E x16, 1 mSATA, 4 DDR3 DIMM, Audio, Video, Gigabit LAN)
Винчестер — 2 Wetern Digital Caviar Blue 500 Гб RAID-1.
Сеть — Realtek RTL8168/8111 PCI-E Gigabit Ethernet Adapter PCI
Через год, мной было принято решение разграничить полномочия серверов и была куплена серверная стойка и блейд-сервер, собранный на серверных компонентах Intel, конкретно под нужды SharePoint, назовем его условно SRV2. Характеристики SRV2: Процессор — QuadCore Intel Xeon E3–1240 v2, 3400 MHz (34×100)
Память — 32 Гб
Материнская плата — Intel Beartooth Pass LC S1200BTL (1 PCI, 1 PCI-E x1, 3 PCI-E x8, 1 PCI-E x16, 4 DDR3 DIMM, Video, Dual LAN)
Винчестер — 2 Western Digital RE4 1TB RAID-1
Сеть — Intel® 82579LM Gigabit Network Connection
С этого момента прошел еще год и пользователи активно генерировали данные, программист накодил около дюжины кастомных решений для наших потребностей и нужд. Мне тогда показалось, что — все, ближайшие 2–3 года можно не беспокоиться о производительности SharePoint.Немного контекста
В SharePoint у нас есть список «Задачи», в котором хранятся задачи для каждого сотрудника. У задачи может быть от 0 до ∞ исполнителей. Задачи есть «большие» и «маленькие», т.е. скажем у сотрудника (ов) висит бессрочная задача, у этой задачи история (журнал версий) с длиной в год, в моем случае — это примерно 2500 комментариев к задаче. У маленьких задач, соответственно, раз в пять короче.Выявление узкого места
Первым делом включаем Панель разработчика в Sharepoint. Штука очень полезная и очень информативная. Запускаем Командную консоль SharePoint от имени администратора и наберем в ней следующее:
stsadm -o setproperty -pn developer-dashboard -pv on
Далее возвращаемся в браузер и обновляем страницу с задачей. Внизу страницы Вы увидите вывод панели разработчика. Нас интересует раздел Запросы баз данных. В частности у меня, в последней строке (см. скриншот ниже), по некоторым «большим» задачам в последней строке были значения около 150000 мс = 2.5 мин. Отсюда делаем вывод, что проблема в БД.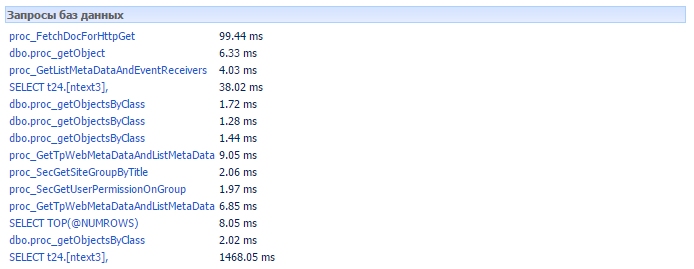 Если вы нажмете на последнюю строку, если запрос слишком длинный, то целиком вы его не увидите. А запрос нам нужен целиком, чтобы посмотреть где он «спотыкается» и вытаскивает 2500 строк больше двух минут.Второе. Отключаем всех пользователей от SharePoint. Далее запускаем SQL Server Profiler. Нажимаем File — New Trace. В открывшемся диалоговом окне на вкладе General выставляем значение параметра Use the template, выбираем Standart (default). В браузере идем на целевую страничку с задачей, которая тормозит и давим F5. Далее идем в SQL профайлер в колонке TextData ищем строки начинающиеся с exec sp_executesql 'N …, а уже в них среди них ищем конкретно наш запрос. Итак, на этой стадии мы подошли непосредственно к оптимизации.Оптимизация
Открываем SQL Server Managment Studio. Жмем New Query. Вставляем целевой запрос найденный при помощи SQL Profiler. На панели инструментов жмем Include Actual Execution Plan.
Если вы нажмете на последнюю строку, если запрос слишком длинный, то целиком вы его не увидите. А запрос нам нужен целиком, чтобы посмотреть где он «спотыкается» и вытаскивает 2500 строк больше двух минут.Второе. Отключаем всех пользователей от SharePoint. Далее запускаем SQL Server Profiler. Нажимаем File — New Trace. В открывшемся диалоговом окне на вкладе General выставляем значение параметра Use the template, выбираем Standart (default). В браузере идем на целевую страничку с задачей, которая тормозит и давим F5. Далее идем в SQL профайлер в колонке TextData ищем строки начинающиеся с exec sp_executesql 'N …, а уже в них среди них ищем конкретно наш запрос. Итак, на этой стадии мы подошли непосредственно к оптимизации.Оптимизация
Открываем SQL Server Managment Studio. Жмем New Query. Вставляем целевой запрос найденный при помощи SQL Profiler. На панели инструментов жмем Include Actual Execution Plan. Далее выполняем запрос, т.е. жмем Execute. После выполнения запрос, на вкладе Execution Plan я увидел следующее:
Далее выполняем запрос, т.е. жмем Execute. После выполнения запрос, на вкладе Execution Plan я увидел следующее: 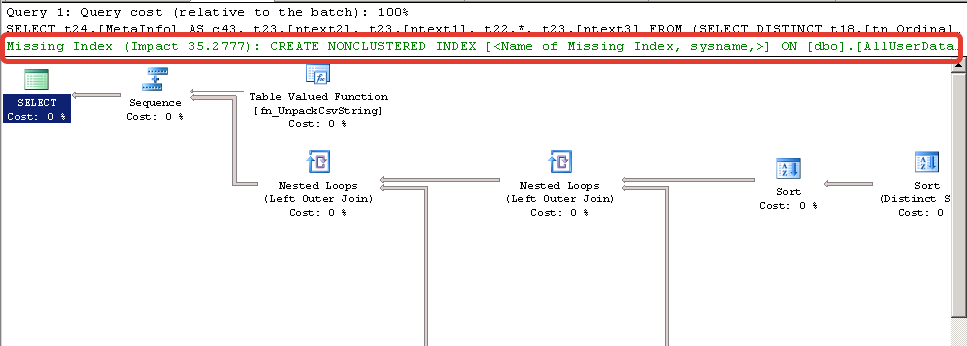 Если нажмем на вкладке Execution Plan на текст выделенный на скриншоте красным правой кнопкой мыши, далее выберем Missing Indexes Details… Откроется окно с закомментированным SQL запросом для создания индексов на нужные колонки:
/*
Missing Index Details from slow.sqlplan
The Query Processor estimates that implementing the following index could improve the query cost by 35.2777%.
*/
Если нажмем на вкладке Execution Plan на текст выделенный на скриншоте красным правой кнопкой мыши, далее выберем Missing Indexes Details… Откроется окно с закомментированным SQL запросом для создания индексов на нужные колонки:
/*
Missing Index Details from slow.sqlplan
The Query Processor estimates that implementing the following index could improve the query cost by 35.2777%.
*/
/*
USE [WSS_Content]
GO
CREATE NONCLUSTERED INDEX [
GO */ По умолчанию, SQL Management предлагает создать один индекс на все колонки. Мы сделаем иначе, вооружившись практикой и логикой, мы создадим на каждую колонку в таблице AllUserData свой индекс, потому что данные колонки очень активно используется при работе с списками в SharePoint. USE [WSS_Content] GO create nonclustered index AllUserData_tpID on dbo.AllUserData (tp_ID ASC) create nonclustered index AllUserData_tp_ListId on dbo.AllUserData ([tp_ListId] ASC); create nonclustered index AllUserData_tp_SiteId on dbo.AllUserData ([tp_SiteId] ASC); create nonclustered index AllUserData_tp_RowOrdinal on dbo.AllUserData ([tp_RowOrdinal] ASC); create nonclustered index AllUserData_tp_DeleteTransactionId on dbo.AllUserData ([tp_DeleteTransactionId] ASC); create nonclustered index AllUserData_tp_Level on dbo.AllUserData ([tp_Level] ASC); create nonclustered index AllUserData_tp_IsCurrentVersion on dbo.AllUserData ([tp_IsCurrentVersion] ASC); GO На этом все. Небольшие изыскания описанные в статье позволяют добиться скорости запроса вместо 150000 мс в 1468.05 мс, что вы можете сами посчитать, дает прирост в производительности почти в 100 раз.P/S/ Спасибо за время.P/P/S Вопрос оставшийся без ответа: почему в SharePoint индексы на эти колонки не добавлены по умолчанию?
