Оптимизация при работе с MySQL — экономия на спичках или с миру по нитке?
База данных — краеугольный камень любого программного продукта. Ее сложнее всего масштабировать, она представляет наибольшую ценность и потребляет больше всего ресурсов: как вычислительных, так и ресурсов в виде внимания инженеров на ее оптимизацию, поддержку и мониторинг.

Базу данных можно назвать душой проекта — она живет и развивается вместе с ним, увеличивается в объеме и из-за этого изменяет свои свойства. Но даже небольшие ошибки при проектировании баз данных, которые неизбежно возникают при хаотичном начале любого проекта (детские травмы), в последующем часто оборачиваются сильной головной болью и издержками.
Меня зовут Максим Таисов, я разработчик в компании СберЗдоровье. В этой статье я собрал несколько примеров организации баз данных, которые позволяют немного сэкономить на дисковом пространстве и скорости исполнения запросов. Все описанные кейсы хорошо известны в узких кругах — я не претендую на новаторство, но считаю важным, чтобы инженеры больше задумывались над структурой баз данных до того, как она становится неповоротливой и неэффективной.
Справка: Все измерения были проведены в MySQL 8.0 из коробки (если немного подкрутить настройки, можно ускорить некоторые показатели значительно). Среда — виртуальная машина с двумя 2 ГГц ядрами, 4 Гб оперативной памяти и дешевыми HDD. Для проведения запросов и оценки времени использовалась утилита mysqlslap и немного скриптов
Пример №1
Для хранения небольших строк нерегламентированной длины лучше использовать VARCHAR, а не CHAR.
Обусловлено это тем, что CHAR занимает на диске всю указанную ему длину, тогда как VARCHAR займет ровно столько, сколько занимает сама строка, записанная в колонку.
Например, возьмем две таблицы с одинаковой структурой.
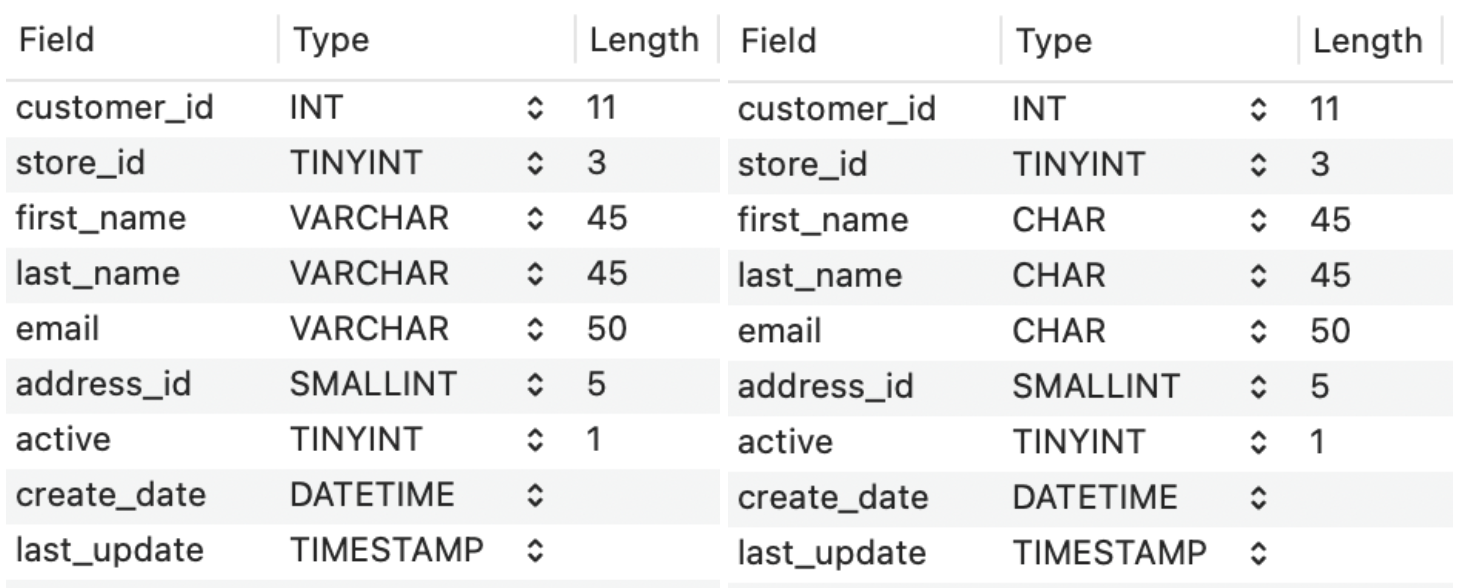
Структуры таблиц с VARCHAR и CHAR
Для полей `first_name`, `last_name` и `email` в одной используем VARCHAR, а в другой — CHAR. Средняя длина полей first_name и last_name — 6 символов, а email — 30 символов.
Размер таблицы с VARCHAR | Размер таблицы с CHAR | |
100к строк | 13.5 MiB | 28.6 MiB |
1 млн строк | 92.6 MiB | 213.7 MiB |
10 млн строк | 783.0 MiB | 1.7 GiB |
100 млн строк | 7.6 GiB | 17.0 GiB |
По результатам замеров видно, что разница существенная — использование VARCHAR экономит место.
Пример №2
Для некоторых таблиц выгодно использовать TINYINT (1) вместо INT (11).
Например, есть таблица entity_dictionary, в которой заведомо будет небольшое количество строк. Идентификаторы из entity_dictionary используются в таблице users, у которых очень большое количество строк. Какое количество дискового пространства можно сэкономить, если использовать TINYINT (1) вместо INT (11)? Давайте посмотрим.
Размер таблицы users с entity_dictionary.id INT (11) | Размер таблицы users с entity_dictionary.id TINYINT (1) | |
2 млн строк | 357 MiB | 349 MiB |
20 млн строк | 2573 MiB | 2513 MiB |
200 млн строк | 26705 MiB | 26081 MiB |
Разница всего 2.6% или примерно 700 мегабайт. На первый взгляд показатель незначительный, но такое мнение ошибочно, особенно если на entity_dictionary.id ссылается множество таблиц — сэкономленное дисковое пространство может быть кратно больше.
Так же не нужно забывать, что бэкапы выполняются ежедневно и хранятся минимум в течение месяца. У нас в компании есть похожий кейс — в нашем случае использование INT (11) вместо TINYINT (1) всего для одной системной сущности требовало дополнительных 500 Гб дискового пространства в месяц, за которые пришлось бы регулярно платить. Переход на TINYINT (1) позволил нам cэкономить — да, на спичках, но про это и речь.
Пример №3
Не стоит забывать, что в MySQL, помимо стандартного InnoDB, есть много других движков хранения данных. Для специфичных случаев, могут хорошо подойти движки Memory и Archive.
Если вам не нужна персистентность, а нужна скорость — используйте Memory. Обработка запросов будет быстрой, но размер такой таблицы ограничен, и все данные будут утеряны при рестарте сервера.
Если хочется занимать меньше места на диске, используйте Archive. Движок занимает, как минимум в 2 раза меньше места, чем InnoDB, но не поддерживает транзакции и индексы.
Рассмотрим интересный пример использования Memory таблицы для ускорения JOIN запроса.
Запрос A в обычную InnoDB таблицу:
CREATE TABLE `address` (
`address_id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`address` varchar(50) NOT NULL,
`district` varchar(20) NOT NULL,
`city_id` smallint(5) unsigned NOT NULL,
`postal_code` varchar(10) DEFAULT NULL,
`phone` varchar(20) NOT NULL,
`location` geometry NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`address_id`),
KEY `idx_fk_city_id` (`city_id`),
SPATIAL KEY `idx_location` (`location`),
CONSTRAINT `address_ibfk_1` FOREIGN KEY (`city_id`) REFERENCES `city` (`city_id`) ON UPDATE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;/** Запрос A */
SELECT c.last_name, c.first_name, a.district
FROM `customer` AS c
LEFT JOIN `address` as a ON a.address_id = c.address_id
WHERE c.customer_id=FLOOR(RAND()*30000));Запрос B в Memory таблицу:
CREATE TABLE `address_district_memory` (
`address_id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`district` varchar(20) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`address_id`)
) ENGINE=MEMORY DEFAULT CHARSET=utf8mb4;/** Запрос B */
SELECT c.last_name, c.first_name, a.district
FROM `customer` AS c
LEFT JOIN `address_district_memory` as a ON a.address_id = c.address_id
WHERE c.customer_id=FLOOR(RAND()*30000));Среднее время выполнения Запроса А (1000 запросов в 20 потоков) | Среднее время выполнения Запроса Б (1000 запросов в 20 потоков) | |
В таблице с адресами 1000 строк | 67.148 seconds | 22.387 seconds |
В таблице с адресами 10 млн строк | 85.583 seconds | 24.430 seconds |
Снова разница очевидна. Но стоит отметить, что при таком сценарии могут появляться и дополнительные сложности, особенно с учетом ограниченного размера Memory-таблиц.
Пример №4
Как эффективно хранить UUID-ов для идентификаторов сущностей?
Об этом говорят давно и для этого есть две основные причины: привычные INT с AUTO_INCREMENT занимают заметно меньше места в памяти и на диске, а также немного быстрее строятся.
В статье Storing UUID Values in MySQL давно проводилось сравнение различных вариантов хранения. С выводами статьи относительно разницы в размере занимаемых данных на диске и в памяти не поспорить — действительно можно сэкономить много места, особенно если идентификатор сущности прокидывается в много других таблиц. Похожую историю я уже рассматривал в примере №2.
А вот что касается скорости вставки, давайте посмотрим — у меня не получилось воспроизвести результаты этой статьи.
Замерим скорость вставки для трех таблиц:
Таблица A: первичный ключ BIGINT () с AUTO_INCREMENT
Таблица B: первичный ключ CHAR (36)
Таблица С: первичный ключ BINARY (16) — при вставке и выборке используем функции UUID_TO_BIN ()/BIN_TO_UUID () (эти функции доступны только начиная с mysql 8.0)
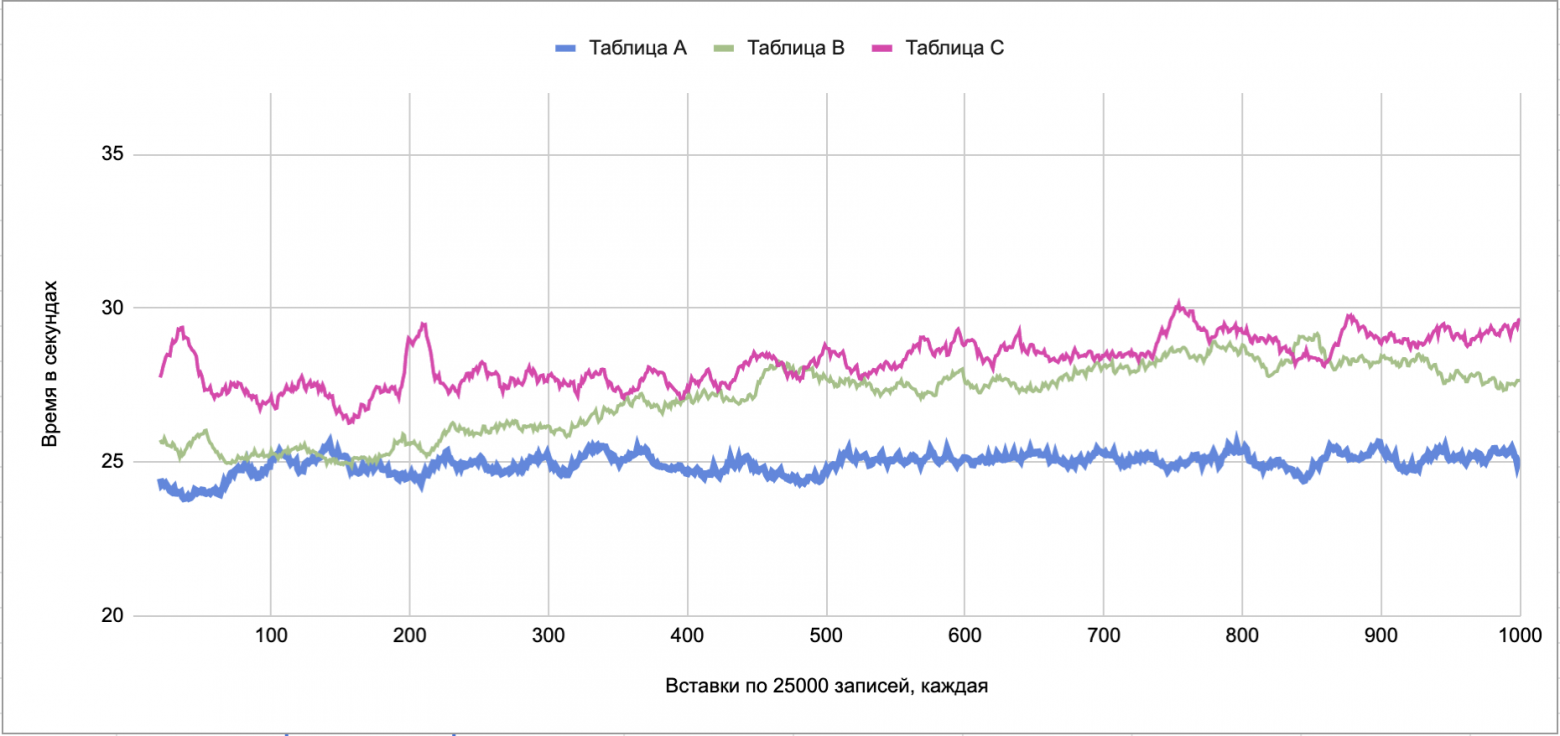
Как видно по графикам, заметной разницы между таблицами B и С нет. Да и таблица A со старым-добрым AUTO_INCREMENT выигрывает не сильно и только после 400 вставок по 25000 (когда таблица перерастает 10 млн записей). По моему мнению мучатся с BINARY (16) только для ускорения времени вставки — действительно «экономия на спичках».
Больше о работе с BINARY (16) можно почитать тут.
Пример №5
Известно, что запрос с сортировкой и OFFSET начинает работать медленнее с увеличением OFFSET. Если offset стоит на миллион, то базе данных придется вычитать из диска миллион строк плюс лимит, а потом отдать только лимит. Поэтому такие запросы начинают выполнятся по несколько секунд.
Для следующей структуры:
CREATE TABLE `customer` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '',
`store_id` int NOT NULL,
. . .
CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `first_name` (`first_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;Если делать запрос с большим OFFSET, например, таким образом, то запрос будет выполняться, как минимум 10 секунд, а то и все 20:
SELECT * FROM `customer` ORDER BY `first_name` LIMIT 1000000, 10;Но если сделать вместо одного запроса два, то можно уложиться в несколько миллисекунд:
SELECT `id` FROM `customer` ORDER BY `first_name` LIMIT 1000000, 10;
SELECT * FROM `customer` WHERE `id` IN (...);Здесь не стоит забывать, что WHERE IN изменит порядок записей, поэтому его придется запоминать из первого запроса.
Структуры запросов с сортировкой очень похожи, отличается только то, что во втором случае мы вытаскиваем только id, которые уже содержатся в отсортированном индексе. Поэтому это работает гораздо быстрее — mysql не нужно обращаться к диску для первого запроса. Так же стоит помнить, что mysql очень хорошо работает с запросами WHERE field IN (…) за счет наличия кластерного индекса.
На эту тему есть очень хорошая старая статья, которую можно почитать здесь.
Пример №6
Использование NULL для обозначения отсутствия значения может немного сохранить место, особенно для числовых типов полей, но и увеличить время выборки, если поле необходимо индексировать.
Для наглядности рассмотрим на примере.
Таблица customer из Примера №5 c 10 млн записей будет весить 973 MiB, если половина записей одного store_id будет 0. Если же сделать поле store_id IS NULL и выставить половину строк store_id=NULL вместо 0, то размер таблицы будет 953 MiB. Крошечная разница, но давайте посмотрим на разницу в производительности по выборке.
Напомню, что в наших таблицах есть индекс на поле store_id.
В некоторые источниках утверждается (например, здесь и здесь), что наличие NULL в индексированном поле увеличивает время выборки по такому индексу.
Посмотрим разницу выполнения запроса:
SELECT id FROM customer WHERE store_id=FLOOR(RAND()*50000) LIMIT 1;В случае, когда мы использовали NOT NULL для store_id выполнение 500 таких запросов (в 10 потоков) в среднем занимает 5 секунд.
В случае же, когда store_id было NULLable и половина строк была помечена как NULL — те же запросы выполняются в среднем 10 секунд.
При этом explain для двух таблиц будет выглядеть почти одинаково:

explain запроса по NOT NULL полю

explain запроса по NULLable полю
Единственная разница в размере индекса — для NULLable полей он на один байт больше.
Получается разница в скорости выборки в 2 раза. Но здесь надо понимать, что NULLable поля редко имеет смысл индексировать из-за низкой селективности индекса. Но, если это ваш случай, имейте ввиду — лучше немного больше занять места на диске, но ускорить выборку за счет значения по умолчанию вместо NULL.
Заключение
Проектирование базы данных — это вечная борьба за оптимизацию и, соответственно, вечный компромисс между скоростью работы, занимаемым местом. И чем больше базы данных, тем тяжелее их оптимизировать.
Приведенные примеры — ни в коем случае не панацея, а лишь малая часть практик, следование которым поможет «сэкономить как можно больше спичек» в самом начале пути и, как результат, позволит повысить стабильность баз данных, упростить их масштабирование и сократить расходы бизнеса на организацию хранилищ.
А вы придерживаетесь этих рекомендаций? Что можете предложить еще?
