Оптимизация хранения данных в Greenplum

В мире современной аналитики данных, где информация — это ключевой актив организации, база данных должна быть не только масштабируемой, но и высокоэффективной. В этом контексте Greenplum, мощная и распределенная система управления базами данных, стоит в центре внимания. Greenplum предоставляет подходящие возможности для хранения и анализа огромных объемов данных, но, чтобы добиться максимальной производительности и оптимальной управляемости, необходимо грамотно оптимизировать хранение данных.
Данная статья в первую очередь для тех, кто только начинает знакомство с оптимизацией в Greenplum и хочет разобраться на что стоит обратить внимание в первую очередь. Будут рассмотрены три ключевых аспекта: компрессию данных, распределение и партиционирование. Узнаем — как правильно применять эти стратегии, чтобы улучшить производительность запросов, снизить потребление ресурсов и повысить эффективность работы базы данных.
СЖАТИЕ ДАННЫХ
Сжатие — или компрессия данных — это операция, позволяющая выполнить алгоритмическое преобразование данных с целью уменьшить занимаемое место под их хранение. При выполнении этой операции необходимо соблюдать баланс между производительностью и экономией на занимаемом объеме хранения данных. Сжатие доступно только для append-optimized таблиц. В ADB доступны два типа сжатия данных:
Сжатие данных на уровне таблицы (table-level) — применяется ко всей таблице. Доступно для таблиц как со строковой (row‑oriented), так и с колоночной (column-oriented) ориентацией данных;
Сжатие данных на уровне столбца (column-level) — применяется к отдельному столбцу. Позволяет использовать различные алгоритмы сжатия для разных столбцов одной таблицы. Этот тип сжатия доступен только для таблиц с колоночной ориентацией данных (column-oriented).
Алгоритмы сжатия:
ZSTD — обеспечивает как скорость, так и хорошую степень сжатия, которую можно сконфигурировать с помощью опции compresslevel;
ZLIB — по большей части используется для обратной совместимости. Как правило, ZSTD превосходит этот тип сжатия при обычных рабочих нагрузках;
RLE_TYPE — по сравнению с другими алгоритмами сжимает данные лучше в случаях, когда одни и те же значения данных встречаются во множестве последовательных строк. Но этот тип сжатия не подходит для таблиц, которые не содержат больших наборов повторяющихся данных (low cardinality).
Рассмотрим конкретный пример.
У нас есть таблица с пятьюдесятью колонками, в которой хранится 380 млн записей. На рисунке представлены 5 вариантов хранения: без сжатия, а также сжатая при помощи алгоритма ZSTD с compresslevel = 1, 5, 10 и 15.

Демонстрация сжатия алгоритмом ZSTD
Для хранения данных подобного объёма необходимо использовать алгоритмы сжатия, так как это значительно экономит место. Даже при использовании compresslevel = 1 таблица занимает в 7, 2 раза меньше места. Оптимальный уровень компрессии будет завить от конфигурации конкретного кластера и допустимого времени выполнения операций с витриной, но стоит заметить, что с более высоким compresslevel происходит незначительное уменьшение размера таблицы. На нашем проекте принято следующее правило: витрины, стоящие на расписании и обновляемые раз в день/неделю хранятся с использованием алгоритма ZSTD с уровнем компрессии 1. Витрины, которые НЕ стоят на регулярном расписании и загружаются по требованию (раз в несколько месяцев), хранятся с уровнем компрессии 5.
Проверим — как будет меняться время записи данных в витрину и время отработки select к таблице в зависимости от уровня компрессии данных.
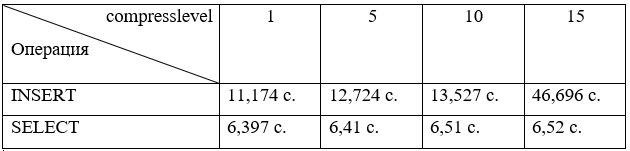
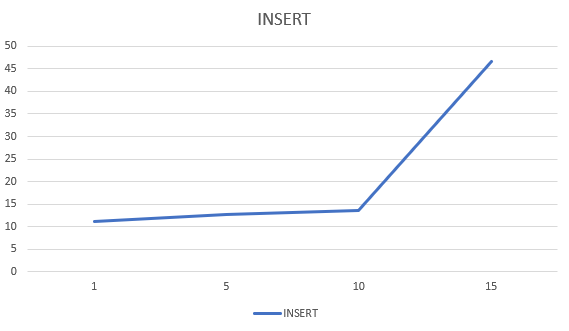
Для теста вставки данных использовалась выборка 34 млн записей. SELECT выполнялся с одним условием в WHERE. Из результатов можно сделать вывод: чем больше степень компрессии данных, тем дольше происходит запись в витрину. Для извлечения данных время практически неизменно. Однако стоит отметить, что тестирование проводилось на не загруженном кластере. Нагрузка на оперативную память будет выше при использовании более высокой степени компрессии, что повлечет увеличение времени на SELECT.
Compresslevel больше 10 стоит использовать в витринах, для которых не предполагается регулярное обновление. Экономия места при сравнении compresslevel 10 и 15 составляет примерно 4,5%, а время вставки данных различается практически в 3,5 раза.
РАСПРЕДЕЛЕНИЕ
Распределение данных (distribution) — это одна из ключевых концепций для эффективной работы Greenplum. Она предполагает хранение данных таблицы на различных сегментах кластера. При этом, чем более равномерно данные распределяются между сегментами, тем выше производительность всего кластера. Для этого сегменты должны содержать примерно одинаковые порции данных.
Сегменты Greenplum представляют собой инстансы PostgreSQL, поднятые на сервере. На одном сервере может быть несколько сегментов Greenplum.
Политики распределения данных:
DISTRIBUTED BY (column (-s)) — хеш-распределение. Конкретный сегмент выбирается на основе хешей, которые рассчитываются по указанным полям. Рекомендуется использовать для таблиц, имеющих первичные ключи (PRIMARY KEY), либо столбцы с уникальными значениями (UNIQUE) — эти столбцы могут быть использованы в качестве ключа распределения;
DISTRIBUTED REPLICATED — распределение данных, при котором копия таблицы сохраняется на каждом сегменте кластера. Рекомендуется для небольших таблиц (например, для справочника валют и т. д.). Позволяет избежать любых перемещений данных при JOIN-запросах;
DISTRIBUTED RANDOMLY — случайное распределение данных с использованием алгоритма round-robin. Поскольку система выбирает сегменты случайным образом, равномерность распределения данных между ними не гарантируется. Рекомендуется для иных случаев — когда в таблицах нет столбцов с уникальными значениями, а размер таблиц достаточно большой.
Допустим у нас есть таблица «комиссий», бизнес-ключом является поле «reference», однако ключ не является уникальным.
CREATE TABLE schema_name.commission (
date_document text,
reference text,
client_id int8,
inn text,
contract text,
tariff_id int8,
amount numeric,
operation_id
)
WITH (
appendonly=true,
orientation=column,
compresslevel=1
compresstype=zstd
)
DISTRIBUTED BY (reference);Проверим распределение по сегментам при помощи следующего запроса:
SELECT gp_segment_id, count(1) AS count
FROM scheme_name.table_name
GROUP BY gp_segment_id;Где gp_segment_id — id сегмента, на котором хранятся данные, а count — количество записей на сегменте. Результат распределения нашей таблицы показан на рисунке.
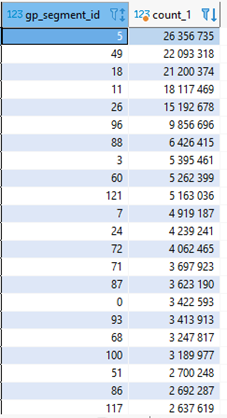
Результат распределения данных по ключу «reference»
Мы явно видим «перекос» по количеству записей между сегментами. «Перекосом» называют неравномерным распределение данных по сегментам кластера. Это может привести не только к большому времени выполнения запросов, но и к деградации производительности всего кластера в целом. Это происходит по причине того, что данные каждой таблицы распределены между всеми сегментами кластера и чем выше загруженность сегмента, тем больше времени требуется на обработку результата каждым отдельным сегментом кластера. Прежде, чем выдать результат, пользователю master node («мастер-нода»), необходимо ожидать ответа всех сегментов.
Это касается не только обращения к конкретной таблице с неравномерным распределением: любое обращение к сегменту будет занимать больше времени. Кластер работает со скоростью самого медленного сегмента, поэтому несбалансированное распределение данных (в одной таблице или во всей базе) снижает общую производительность кластера. Пересоздадим нашу таблицу с использованием распределения DISTRIBUTED RANDOMLY и для удобства агрегируем результаты:

Результат случайного распределения данных
При среднем количестве записей на сегменте чуть более трех миллионов максимальное и минимальное количество записей отличается всего на 9 тысяч. Процент перекоса составит 1.003, что является отличным результатом.
Рассмотрим пример с «перекосом» данных детальнее.
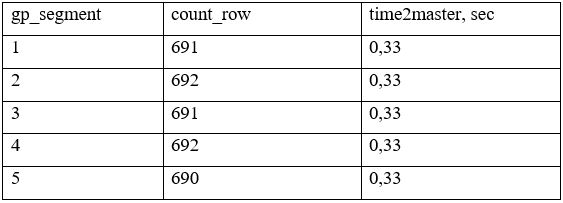
Мы имеем 5 сегментов (gp_segment) в кластере и таблицу с «перекосом» данных между сегментами. На 5 сегменте данных (count_row) — в 6,37 раз больше. Мастер кластера Greenplum сможет отдать результат потребителю только после получения данных со всех сегментов и это займет 1,41 секунд:
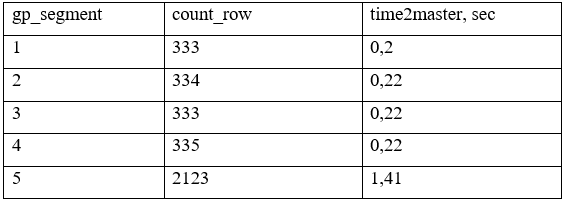
Также приведем пример с равномерным распределением данных. В данным случае Мастер вернет результат быстрее чем в случае с неравномерном распределением. Время ответа Мастером составит 0,33 секунд.
ПАРТИЦИОНИРОВАНИЕ
Партиционирование (partitioning) — это способ повышения производительности запросов за счет логического разбиения больших таблиц (например, таблиц фактов) на небольшие подтаблицы, называемые партициями (partitions). Это позволяет при выполнении запроса сканировать ограниченное число строк из общего набора данных путем обращения только к необходимым подтаблицам (partitions) на основе условий предикатов (where) вместо чтения всего набора данных.
Принадлежность каждой новой записи таблицы к той или иной партиции определяется на основе значения ключа партиционирования (partition key) — столбца (или набора столбцов в случае многоуровневого партиционирования), который выбирается при создании таблицы.
Партиционированная таблица представляет из себя набор подтаблиц, где каждая партиция это отдельная таблица. Партиция, в свою очередь, распределена по сегментам через дистрибьюцию.
Рассмотрим наглядный пример.
У нас есть таблица балансов, где данные хранятся с учётом даты «report_date». Количество данных, поступающих ежемесячно, приблизительно одинаково. Таблицу будем создавать на основе диапазонов (RANGE), с автоматическим созданием партиций в интервале от начала 2018 до начала 2025 года с шагом в один месяц. Другой способ партиционирования — на основе списков значений LIST.
CREATE TABLE schema_name.balance (
report_date date,
account_id int8,
account_number text,
deal_id int8,
client_id int8,
currency_number text,
account_out_sum numeric,
account_credit_sum numeric,
account_debet_sum numeric
)
WITH (
appendonly=true,
orientation=column,
compresslevel=1,
compresstype=zstd
)
DISTRIBUTED BY (account_id)
PARTITTION BY RANGE(report_date)
(
PARTITTION ym START ('2018-01-01'::date) END ('2025-01-01'::date) EVERY ('1 mon'::interval) WITH (appendonly=true, orientation=column, compresslevel=1, com-presstype=zstd)
COLUMN account_id ENCODING (compresslevel=1, compresstype=zstd, blocksize=32768)
COLUMN account_number ENCODING (compresslevel=1, compresstype=zstd, blocksize=32768)
COLUMN deal_id ENCODING (compresslevel=1, compresstype=zstd, blocksize=32768)
COLUMN client_id ENCODING (compresslevel=1, compresstype=zstd, blocksize=32768)
COLUMN currency_number ENCODING (compresslevel=1, compresstype=zstd, blocksize=32768)
COLUMN account_out_sum ENCODING (compresslevel=1, compresstype=zstd, blocksize=32768)
COLUMN account_credit_sum ENCODING (compresslevel=1, compresstype=zstd, blocksize=32768)
COLUMN account_debet_sum ENCODING (compresslevel=1, compresstype=zstd, blocksize=32768)
);
Количество данных за последние 6 месяцев
При выборе данных из таблицы SQL-запросы содержат прямое и простое ограничение с использованием неизменяемых операторов, таких как =, <, <=,>,> = или <>, следовательно, планировщик запросов решает сканировать только необходимые патриции, тем самым уменьшая время обработки запроса. Стоит также отметить, что выборочное сканирование распознает стабильные (STABLE) и неизменяемые (IMMUTABLE) функции в SQL-запросе, но не определяет изменчивые. Например, условие WHERE в выражении date>CURRENT_DATE заставит планировщик запросов применять Partition elimination (выборочно сканировать партиционированную таблицу). Но при использовании того же условия WHERE в выражении time>TIMEOFDAY этого НЕ произойдет, так как данная функция относится к изменчивым (VOLATILE). Поэтому важно убедиться, что SQL-запросы выборочно сканирую партиционированные таблицы, удаляя ненужные разделы. Это можно сделать, изучив план запроса EXPLAIN.
Также есть необходимость актуализировать данные за прошедшие месяцы путем удаления конкретных партиций и их полного перерасчёта. Обновление данных путем замены партиций в Greenplum самое быстрое, если сравнивать с операциями UPDATE и DELETE, но накладывает на время выполнения операции блокировку ACCESS EXCLUSIVE. Таким образом, партиционирование для данной витрины целесообразно и уменьшит время выполнения запросов к ней.
ИТОГИ
Какие выводы можно сделать:
Для хранения данных стоит использовать сжатие: для большинства задач подходит алгоритм ZSTD с уровнем сжатия данных 1 или 2;
Если в таблице есть первичный ключ, либо столбцы с уникальными значениями, то используем распределение DISTRIBUTED BY (column (-s)). В противном случае используем DISTRIBUTED RANDOMLY. DISTRIBUTED REPLICATED стоит использовать для небольших таблиц-справочников, например, справочник типов валют;
Партиционирование стоит применять если существует большая таблица фактов, в которой есть столбец, на основе которого можно разбить таблицу на примерно одинаковые части, иначе время выполнения запросов к таблице может остаться неизменным или даже увеличиться. А также в запросах к таблице используется ключ партиционирования в предикатах (where).
Данный список не является исчерпывающим и основан преимущественно на опыте эксперта. В статье мы постарались выявить наиболее критичные факторы, влияющие на производительность запросов, и кластера в целом. Более подробное описание по каждому из рассмотренных методов оптимизации будет представлено в отдельных статьях.
