Определение победителей матчей регулярного чемпионата КХЛ методами классического ML

Всем привет!
Давно хотел применить методы машинного обучения в области спортивной индустрии. Данное желание обусловлено интересом к самому спорту и к тому, насколько хорошо математические модели могут предсказывать исходы различных спортивных событий. Возможность реализации задуманного представилась на выпускном проекте курса «Machine Learning. Professional» в Otus. Можно было взять любую интересующую тему, и я выбрал определение победителей матчей регулярного чемпионата КХЛ. Так как курс был по ML, для решения задачи рекомендовалось применять классические методы без использования нейросетевых моделей. Дав волю своему экспериментаторскому началу, я принялся за дело.
Исходные данные
Исходные данные для обучения и тестирования моделей парсились с сайта khl.ru. В расчёт бралась информация по 4 последним завершенным сезонам — 2018/2019, 2019/2020, 2020/2021 и 2021/2022.
Парсинг состоял из двух частей:
сбор ссылок на элементы информации (резюме, протокол, текстовую трансляцию и видео ключевых моментов) по каждому матчу;
# ссылки страниц с информацией по каждому сезону page_links = ['https://www.khl.ru/calendar/1097/00/', 'https://www.khl.ru/calendar/1045/00/', 'https://www.khl.ru/calendar/851/00/', 'https://www.khl.ru/calendar/671/00/'] section_names = [] for link in page_links: response = requests.get(link, headers={'User-Agent': UserAgent().chrome}) soup = BeautifulSoup(response.content, 'html.parser') sections = soup.findAll('a', attrs={'class':'card-game__hover-link_small'}) for i in sections: section_names.append(i.attrs['href']) # выбираем необходимые ссылки для сбора статистики матчей и добавляем к ним доменное имя links = ['https://khl.ru' + element for element in section_names if 'protocol' in element]парсинг интересующей информации по ссылкам на резюме и протоколы матчей.
# функция подключения к веб-странице
def connect(link):
response = requests.get(link, headers={'User-Agent': UserAgent().chrome})
if not response.ok:
return response.status_code
soup = BeautifulSoup(response.content, 'html.parser')
return soup
# функция очистки содержимого веб-страниц от пустых строк и пробелов
def stats_cleaner(data):
data = [x.strip('\n').strip(' ') for x in data]
return data
all_stats, matches_missing = [], []
for link in tqdm_notebook(links):
match_stats = []
# часть статистики матча в его протоколе
soup_protocol = connect(link)
# находим необходимую статистику матчей из протокола
statistics_protocol = soup_protocol.findAll('div', attrs={'class':'fineTable-totalTable d-none_768'})
# часть матчей не игралась, но ссылки на пустые протоколы есть - выбираем не пустые протоколы
if statistics_protocol != []:
goals = soup_protocol.findAll('p', attrs={'class':'preview-frame__center-score roboto-condensed roboto-bold color-white title-xl'})[0].contents
# часть статистики матча в его резюме
soup_resume = connect(link.replace('protocol', 'resume'))
# находим необходимую статистику матчей из резюме
statistics_resume = soup_resume.findAll('p', attrs={'class':'roboto-condensed'})[1:21]
# номер матча для его идентификации
match_number_resume = soup_resume.findAll('h2', attrs={'class':'roboto-condensed roboto-bold title-md color-dark title-btns__title'})
# находим даты проведения матчей
soup_preview = connect(link.replace('protocol', 'preview'))
date_preview = soup_preview.findAll('div', attrs={'class':'card-infos__item-info'})
# добавляем в список статистики дату, время проведения и номер матча
try:
match_stats.append(stats_cleaner(date_preview[0].contents[1].contents)[0])
except IndexError:
match_stats.append(np.NaN)
match_stats.append(match_number_resume[0].contents[0].split('№')[1].replace(' ', ''))
# добавляем в список статистики основную информацию
for stat in statistics_resume:
clean_stat = stats_cleaner(stat.contents)
if clean_stat != [''] and clean_stat != ['n/a']:
match_stats.append(clean_stat[0])
else: pass
# добавляем в список статистики дополнительную информацию
if len(statistics_protocol[len(statistics_protocol)-2].contents) == 11 and 'Всего' in str(statistics_protocol[1].contents[9].contents[7].contents[1]):
for stat in statistics_protocol[1].contents[9].contents:
if stat != '\n':
clean_stat = stats_cleaner(stat.contents[1].contents)
match_stats.append(clean_stat[0])
else: pass
elif len(statistics_protocol[len(statistics_protocol)-2].contents) == 11 and 'овертайм' in str(statistics_protocol[1].contents[9].contents[7].contents[1]):
for stat in statistics_protocol[2].contents[9].contents:
if stat != '\n':
clean_stat = stats_cleaner(stat.contents[1].contents)
match_stats.append(clean_stat[0])
else: pass
elif len(statistics_protocol) == 3 and len(statistics_protocol[len(statistics_protocol)-2].contents) == 13:
for stat in statistics_protocol[1].contents[11].contents:
if stat != '\n':
clean_stat = stats_cleaner(stat.contents[1].contents)
match_stats.append(clean_stat[0])
else: pass
else:
for stat in statistics_protocol[2].contents[11].contents:
if stat != '\n':
clean_stat = stats_cleaner(stat.contents[1].contents)
match_stats.append(clean_stat[0])
else: pass
# для идентификации овертаймов
if len(statistics_protocol[len(statistics_protocol)-2].contents) == 11 and ('овертайм' not in statistics_protocol[0].contents[9].contents[7].contents[1].contents[0].replace(' ', '').replace('\n', '')):
match_stats.append('main_time')
else: match_stats.append('add_time')
# добавляем информацию о кол-ве заброшенных шайб с учетом буллитов
if goals[0] != '\n':
try:
goal_h = goals[0].replace(' ', '').replace('\n', '')
except TypeError:
goal_h = goals[0].contents[0]
try:
goal_a = goals[3].replace(' ', '').replace('\n', '')
except IndexError:
pass
except TypeError:
goal_a = goals[3].contents[0]
else:
goal_h = goals[1].contents[0]
goal_a = goals[4].replace(' ', '').replace('\n', '').replace('Б', '').replace('OT', '')
match_stats.append(goal_h)
match_stats.append(goal_a)
# проверка наличия данных о пройденной дистанции и времени владения шайбой (есть не во всех матчах, удаляется)
if len(match_stats) == 32:
del match_stats[15:19]
else: pass
all_stats.append(match_stats)
else: matches_missing.append(link)
time.sleep(0.5)
За 4 рассматриваемых сезона в рамках регулярного чемпионата КХЛ было сыграно 2789 матчей.
Из спарсенных данных построен датасет, фрагмент которого представлен в таблице ниже.
data = pd.DataFrame(all_stats, columns=['date', 'match', 'team_h', 'score_h', 'ppp_h', 'ppp_a', 'ppk_h', 'ppk_a', 'numa_h', 'numa_a', 'wt_h', 'wt_a', 'pt_h', 'pt_a', 'sog_h', 'sog_a', 'team_a', 'score_a', 'bs_h', 'pm_h', 'at_h', 'tot', 'bs_a', 'pm_a', 'at_a', 'end', 'final_score_h', 'final_score_a'])
# сортируем признаки по принадлежности к командам
data_sorted = data.iloc[:, [0,1,2,16,3,17,4,6,8,10,12,14,18,19,20,5,7,9,11,13,15,22,23,24,25,26,27,21]]
date | match | team_h | score_h | ppp_h | ppp_a | ppk_h | ppk_a | numa_h | numa_a | wt_h | wt_a | pt_h | pt_a | sog_h | sog_a | team_a | score_a | bs_h | pm_h | at_h | tot | bs_a | pm_a | at_a | end | final_score_h | final_score_a | |
0 | 14.01.2022 12:30 | 589 | Адмирал | 3 | 1 | 1 | 0 | 0 | 4 | 5 | 29 | 29 | 10 | 8 | 16 | 32 | Сибирь | 2 | 29 | 7 | 10:35 | Всего | 10 | 16 | 15:06 | main_time | 3 | 2 |
1 | 13.01.2022 17:00 | 582 | Автомобилист | 5 | 2 | 0 | 0 | 0 | 5 | 4 | 37 | 20 | 8 | 10 | 40 | 33 | Северсталь | 2 | 12 | 15 | 16:34 | Всего | 16 | 5 | 14:13 | main_time | 5 | 2 |
2 | 13.01.2022 19:30 | 588 | СКА | 2 | 0 | 0 | 0 | 0 | 4 | 2 | 31 | 19 | 4 | 8 | 33 | 21 | ХК Сочи | 1 | 10 | 6 | 21:07 | Всего | 22 | 10 | 09:13 | main_time | 2 | 1 |
3 | 12.01.2022 12:30 | 578 | Адмирал | 2 | 0 | 0 | 0 | 1 | 2 | 1 | 24 | 35 | 4 | 6 | 30 | 27 | Сибирь | 1 | 27 | 10 | 12:54 | Всего | 22 | 17 | 13:11 | main_time | 2 | 1 |
4 | 12.01.2022 19:00 | 580 | Нефтехимик | 4 | 0 | 0 | 0 | 0 | 2 | 1 | 27 | 31 | 2 | 4 | 26 | 24 | Трактор | 2 | 23 | 13 | 10:02 | Всего | 9 | 13 | 16:40 | main_time | 4 | 2 |
Собрана следующая информация о проведенных матчах:
дата и время проведения матча (date);
номер матча на сайте (match);
название команды (team);
кол-во забитых командой шайб без учета буллитов (score);
кол-во шайб, забитых в большинстве (ppp);
кол-во шайб, забитых в меньшинстве (ppk);
численные преимущества (numa);
выигранные вбрасывания (wt);
штрафное время, минут (pt);
броски по воротам (sog);
блокированные броски (bs);
силовые приемы (pm);
время в атаке, минут (at);
признак для проверки корректности работы парсинга (tot);
вариант окончания матча — в основное или дополнительное время (end);
кол-во забитых командой шайб с учетом буллитов (final_score).
Статистика домашней команды обозначалась суффиксом »_h», гостевой — суффиксом »_a». Индексом является порядковый номер строки исходного датасета.
Подготовка данных
Проверена корректность работы парсинга по признаку tot, в котором было одно уникальное значение «Всего» — своего рода метка на веб-странице, соответствующая окончанию блока с необходимой для работы информацией.
В исходных данных содержалась ненужная информация о матчах всех звезд, которая в ходе препроцессинга была удалена.
Имелись пропуски по ряду матчей в блокированных бросках и силовых приемах у гостевых команд, которые заполнялись значениями аналогичных показателей домашних команд.
Также добавлен целевой признак, которым являлась победа домашней команды (home_win). Соответственно, значение 1 в данном признаке — победа домашней команды, 0 — победа гостевой команды. Таким образом, данная работа сводилась к решению задачи бинарной классификации.
data_sorted['home_win'] = np.where(data_sorted.final_score_h > data_sorted.final_score_a, 1, 0)Помимо целевого в датасет добавлены следующие признаки:
порядковый номер сезона (season);
data_sorted['season'] = np.where(data_sorted['date'] < pd.Timestamp('2019-06-01 00:00:00'), 1, np.NaN) data_sorted['season'] = np.where((data_sorted['date'] > pd.Timestamp('2019-08-01 00:00:00')) & (data_sorted['date'] < pd.Timestamp('2020-06-01 00:00:00')), 2, data_sorted['season']) data_sorted['season'] = np.where((data_sorted['date'] > pd.Timestamp('2020-08-01 00:00:00')) & (data_sorted['date'] < pd.Timestamp('2021-06-01 00:00:00')), 3, data_sorted['season']) data_sorted['season'] = np.where((data_sorted['date'] > pd.Timestamp('2021-08-01 00:00:00')), 4, data_sorted['season'])кол-во очков у каждой команды (tp);
# добавляем очки домашней команды по результатам матча data_sorted['points_h'] = np.where(data_sorted.home_win == 1, 2, np.NaN) data_sorted['points_h'] = np.where((data_sorted.home_win == 0) & (data_sorted.end == 'add_time'), 1, data_sorted['points_h']) data_sorted['points_h'] = np.where((data_sorted.home_win == 0) & (data_sorted.end == 'main_time'), 0, data_sorted['points_h']) # добавляем очки гостевой команды по результатам матча data_sorted['points_a'] = np.where(data_sorted.home_win == 0, 2, np.NaN) data_sorted['points_a'] = np.where((data_sorted.home_win == 1) & (data_sorted.end == 'add_time'), 1, data_sorted['points_a']) data_sorted['points_a'] = np.where((data_sorted.home_win == 1) & (data_sorted.end == 'main_time'), 0, data_sorted['points_a']) data_sorted[['tp_h', 'tp_a']] = np.NaN # создаем колонки для подсчета очков индивидульно по каждой команде for team in data_sorted.team_h.unique(): data_sorted['p_{}'.format(team)] = np.NaN # создаем пустой датафрейм для добавления очков по каждому сезону d = {} for i in range(len(data_sorted.dtypes)): d[data_sorted.dtypes.index[i]] = pd.Series(dtype=data_sorted.dtypes.values[i]) data_sorted_v1 = pd.DataFrame(d) for season in data_sorted['season'].unique(): df = data_sorted[data_sorted['season'] == season] for team in data_sorted.team_h.unique(): df['p_{}'.format(team)] = np.where(df.team_h == team, pd.Series(np.where(df.team_h == team, df.points_h, np.where(df.team_a == team, df.points_a, 0)).cumsum()).shift().fillna(0), df['p_{}'.format(team)]) df['p_{}'.format(team)] = np.where(df.team_a == team, pd.Series(np.where(df.team_a == team, df.points_a, np.where(df.team_h == team, df.points_h, 0)).cumsum()).shift().fillna(0), df['p_{}'.format(team)]) df['tp_h'] = np.where(df.team_h == team, df['p_{}'.format(team)], df['tp_h']) df['tp_a'] = np.where(df.team_a == team, df['p_{}'.format(team)], df['tp_a']) data_sorted_v1 = pd.concat([data_sorted_v1, df]) data_sorted_v1.drop(columns=data_sorted_v1.columns[-29:-27].to_list() + data_sorted_v1.columns[-25:].to_list(), inplace=True)число, месяц, день недели проведения матча и является ли день выходным (day, month, day_of_week, weekend);
data_sorted_v1['day'] = data_sorted_v1.date.dt.day data_sorted_v1['month'] = data_sorted_v1.date.dt.month data_sorted_v1['day_of_week'] = data_sorted_v1.date.dt.day_of_week data_sorted_v1['weekend'] = np.where((data_sorted_v1['day_of_week'] == 5) | (data_sorted_v1['day_of_week'] == 6), 1, 0)наличие переезда у команд перед матчем (reloc);
teams = data_sorted_v1.team_h.unique().tolist() # список городов, в которых играют команды cities = ['Казань', 'Челябинск', 'Магнитогорск', 'Екатеринбург', 'Москва', 'Москва', 'Череповец', 'Ярославль', 'Хельсинки', 'Нижний Новгород', 'Нижнекамск', 'Сочи', 'Санкт-Петербург', 'Рига', 'Братислава', 'Омск', 'Минск', 'Подольск', 'Новосибирск', 'Москва', 'Хабаровск', 'Нур-Султан', 'Уфа', 'Пекин', 'Владивосток'] d_cities = dict(zip(teams, cities)) data_sorted_v1['city_h'] = data_sorted_v1['team_h'].map(d_cities) data_sorted_v1[['reloc_h', 'reloc_a', 'rest_h', 'rest_a', 'intense_h', 'intense_a']] = np.NaN for team in data_sorted_v1.team_h.unique(): index = data_sorted_v1[(data_sorted_v1['team_h'] == team) | (data_sorted_v1['team_a'] == team)].index # определяем наличие переезда у домашней команды data_sorted_v1.loc[index, 'reloc_h'] = np.where( data_sorted_v1.loc[index, 'team_h'] == team, np.where((data_sorted_v1.loc[index, 'season'] - data_sorted_v1.loc[index, 'season'].shift()).isna() | (data_sorted_v1.loc[index, 'season'] - data_sorted_v1.loc[index, 'season'].shift() == 1), 0, np.where(data_sorted_v1.loc[index, 'city_h'] == data_sorted_v1.loc[index, 'city_h'].shift(), 0, 1)), data_sorted_v1.loc[index, 'reloc_h']) # определяем наличие переезда у гостевой команды data_sorted_v1.loc[index, 'reloc_a'] = np.where( data_sorted_v1.loc[index, 'team_a'] == team, np.where((data_sorted_v1.loc[index, 'season'] - data_sorted_v1.loc[index, 'season'].shift()).isna() | (data_sorted_v1.loc[index, 'season'] - data_sorted_v1.loc[index, 'season'].shift() == 1), 1, np.where(data_sorted_v1.loc[index, 'city_h'] == data_sorted_v1.loc[index, 'city_h'].shift(), 0, 1)), data_sorted_v1.loc[index, 'reloc_a'])кол-во дней отдыха у команд между играми (rest);
# определяем макс. кол-во дней отдыха среди команд в рамках одного сезона (исключаем команду Слован, т.к. она играла только в 1м сезоне, и команду Адмирал - не играла в 3м сезоне) max_rest = [] for season in data_sorted_v1['season'].unique(): for team in data_sorted_v1.team_h.unique()[np.where((data_sorted_v1.team_h.unique() != 'Слован') & (data_sorted_v1.team_h.unique() != 'Адмирал'))]: df = data_sorted_v1[((data_sorted_v1.team_h == team) | (data_sorted_v1.team_a == team)) & (data_sorted_v1.season == season)] max_rest.append(round((df.date[1:] - df.date.shift()[1:]).max().days + (df.date[1:] - df.date.shift()[1:]).max().seconds/86400)) # определяем кол-во дней отдыха у домашней команды data_sorted_v1.loc[index, 'rest_h'] = np.where( data_sorted_v1.loc[index, 'team_h'] == team, np.where((data_sorted_v1.loc[index, 'season'] - data_sorted_v1.loc[index, 'season'].shift()).isna() | (data_sorted_v1.loc[index, 'season'] - data_sorted_v1.loc[index, 'season'].shift() == 1), max(max_rest), # для первых матчей проставляем макс. кол-во дней отдыха в течение сезона (data_sorted_v1.loc[index, 'date'] - data_sorted_v1.loc[index, 'date'].shift()).dt.total_seconds()/86400), data_sorted_v1.loc[index, 'rest_h']) # определяем кол-во дней отдыха у гостевой команды data_sorted_v1.loc[index, 'rest_a'] = np.where( data_sorted_v1.loc[index, 'team_a'] == team, np.where((data_sorted_v1.loc[index, 'season'] - data_sorted_v1.loc[index, 'season'].shift()).isna() | (data_sorted_v1.loc[index, 'season'] - data_sorted_v1.loc[index, 'season'].shift() == 1), max(max_rest), # для первых матчей проставляем макс. кол-во дней отдыха в течение сезона (data_sorted_v1.loc[index, 'date'] - data_sorted_v1.loc[index, 'date'].shift()).dt.total_seconds()/86400), data_sorted_v1.loc[index, 'rest_a'])наличие предыдущего напряженного матча — завершившегося в овертайме или по буллитам (intense);
# определяем наличие напряженного матча у домашней команды data_sorted_v1.loc[index, 'intense_h'] = np.where( data_sorted_v1.loc[index, 'team_h'] == team, np.where((data_sorted_v1.loc[index, 'season'] - data_sorted_v1.loc[index, 'season'].shift()).isna() | (data_sorted_v1.loc[index, 'season'] - data_sorted_v1.loc[index, 'season'].shift() == 1), 0, np.where(data_sorted_v1.loc[index, 'end'].shift() == 'add_time', 1, 0)), data_sorted_v1.loc[index, 'intense_h']) # определяем наличие напряженного матча у гостевой команды data_sorted_v1.loc[index, 'intense_a'] = np.where( data_sorted_v1.loc[index, 'team_a'] == team, np.where((data_sorted_v1.loc[index, 'season'] - data_sorted_v1.loc[index, 'season'].shift()).isna() | (data_sorted_v1.loc[index, 'season'] - data_sorted_v1.loc[index, 'season'].shift() == 1), 0, np.where(data_sorted_v1.loc[index, 'end'].shift() == 'add_time', 1, 0)), data_sorted_v1.loc[index, 'intense_a']) data_sorted_v1.drop(columns=['city_h'], inplace=True)кол-во побед дома у домашней команды и кол-во побед в гостях у гостевой команды на момент проведения матча (win);
data_sorted_v1[['win_h', 'win_a']] = np.NaN for season in data_sorted_v1.season.unique(): for team in data_sorted_v1.team_h.unique(): index_h = data_sorted_v1[(data_sorted_v1['team_h'] == team) & (data_sorted_v1['season'] == season)].index index_a = data_sorted_v1[(data_sorted_v1['team_a'] == team) & (data_sorted_v1['season'] == season)].index # кол-во побед дома у домашней команды data_sorted_v1.loc[index_h, 'win_h'] = np.where((data_sorted_v1.loc[index_h, 'season'] - data_sorted_v1.loc[index_h, 'season'].shift()).isna() | (data_sorted_v1.loc[index_h, 'season'] - data_sorted_v1.loc[index_h, 'season'].shift() == 1), 0, data_sorted_v1.loc[index_h, 'home_win'].shift().cumsum()) # кол-во побед в гостях у гостевой команды data_sorted_v1.loc[index_a, 'win_a'] = np.where((data_sorted_v1.loc[index_a, 'season'] - data_sorted_v1.loc[index_a, 'season'].shift()).isna() | (data_sorted_v1.loc[index_a, 'season'] - data_sorted_v1.loc[index_a, 'season'].shift() == 1), 0, (1 - data_sorted_v1.loc[index_a, 'home_win'].shift()).cumsum())кол-во побед команд в очных противостояниях, начиная с 1 рассматриваемого сезона (ftf);
data_sorted_v1[['ftf_h', 'ftf_a']] = np.NaN for team_h in data_sorted_v1.team_h.unique(): for team_a in data_sorted_v1.team_a.unique(): index = data_sorted_v1[((data_sorted_v1.team_h == team_h) & (data_sorted_v1.team_a == team_a)) | ((data_sorted_v1.team_h == team_a) & (data_sorted_v1.team_a == team_h))].index # кол-во очных побед дома у домашней команды data_sorted_v1.loc[index, 'ftf_h'] = np.where( data_sorted_v1.loc[index, 'team_h'] == team_h, pd.Series(np.where(data_sorted_v1.loc[index, 'team_h'] == team_h, data_sorted_v1.loc[index, 'home_win'], (1-data_sorted_v1.loc[index, 'home_win'])).cumsum()).shift().fillna(0), pd.Series(np.where(data_sorted_v1.loc[index, 'team_h'] == team_a, data_sorted_v1.loc[index, 'home_win'], (1-data_sorted_v1.loc[index, 'home_win'])).cumsum()).shift().fillna(0)) # кол-во очных побед дома у гостевой команды data_sorted_v1.loc[index, 'ftf_a'] = np.where( data_sorted_v1.loc[index, 'team_a'] == team_a, pd.Series(np.where(data_sorted_v1.loc[index, 'team_a'] == team_a, (1-data_sorted_v1.loc[index, 'home_win']), data_sorted_v1.loc[index, 'home_win']).cumsum()).shift().fillna(0), pd.Series(np.where(data_sorted_v1.loc[index, 'team_a'] == team_h, (1-data_sorted_v1.loc[index, 'home_win']), data_sorted_v1.loc[index, 'home_win']).cumsum()).shift().fillna(0))среднее кол-во очков оппонентов, против которых играли команды до рассматриваемого матча (mop).
data_sorted_v1[['mop_h', 'mop_a']] = np.NaN
for season in data_sorted_v1.season.unique():
for team in data_sorted_v1.team_h.unique():
index_h = data_sorted_v1[(data_sorted_v1['team_h'] == team) & (data_sorted_v1['season'] == season)].index
index_a = data_sorted_v1[(data_sorted_v1['team_a'] == team) & (data_sorted_v1['season'] == season)].index
# создаем массив из очков гостевых команд при игре дома и очков домашних команд при игре в гостях
tp = pd.concat([data_sorted_v1.loc[index_a, 'tp_h'], data_sorted_v1.loc[index_h, 'tp_a']]).sort_index()
# создаем датафрейм из кол-ва проведенных игр
games_count = pd.DataFrame(index=tp.index, columns=['number_of_games'], data=np.ones(len(tp.index)))
# среднее кол-во очков оппонентов домашней команды
data_sorted_v1.loc[index_h, 'mop_h'] = np.where(((data_sorted_v1.loc[tp.index, 'season'] - data_sorted_v1.loc[tp.index, 'season'].shift()).isna() | (data_sorted_v1.loc[tp.index, 'season'] - data_sorted_v1.loc[tp.index, 'season'].shift() == 1)).loc[index_h], 0, tp.shift().cumsum()[index_h] / games_count.shift().cumsum().loc[index_h, 'number_of_games'].values)
# среднее кол-во очков оппонентов гостевой команды
data_sorted_v1.loc[index_a, 'mop_a'] = np.where(((data_sorted_v1.loc[tp.index, 'season'] - data_sorted_v1.loc[tp.index, 'season'].shift()).isna() | (data_sorted_v1.loc[tp.index, 'season'] - data_sorted_v1.loc[tp.index, 'season'].shift() == 1)).loc[index_a], 0, tp.shift().cumsum()[index_a] / games_count.shift().cumsum().loc[index_a, 'number_of_games'].values)
Также проверено соответствие количества матчей, по которым спарсена информация, нумерации матчей на сайте (признак match).
def empty_matches_count (season, matches_missing):
if season == 1:
text = '/671/'
elif season == 2:
text = '/851/'
elif season == 3:
text = '/1045/'
else:
text = '/1097/'
return len([x for x in matches_missing if text in x])
for season in range(1, 5):
if data_sorted_v1[data_sorted_v1.season == season].match.max() != data_sorted_v1[data_sorted_v1.season == season].match.shape[0] + empty_matches_count(season, matches_missing):
print('По {} сезону есть несоответствие между кол-вом матчей, по которым спарсена информация, и фактической нумерацией матчей'.format(season))
else:
pass
По 4 сезону было несоответствие, обусловленное пропусками в нумерации матчей на сайте, при этом информация по всем фактически проведенным играм спарсена корректно.
Удалены не нужные для дальнейшей работы признаки (tot, date, match, score, end).
Проверено наличие сильных корреляций между признаками, результаты проверки представлены в таблице ниже.
features_correlation = pd.DataFrame(columns=['feature_1', 'feature_2', 'correlation_pearson', 'correlation_spearman'])
index = 0
for i in range(3, len(data_sorted_v1.columns)):
for a in range (i+1, len(data_sorted_v1.columns)):
features_correlation.loc[index, 'feature_1'] = data_sorted_v1.columns[i]
features_correlation.loc[index, 'feature_2'] = data_sorted_v1.columns[a]
features_correlation.loc[index, 'correlation_pearson'] = data_sorted_v1[data_sorted_v1.columns[i]].corr(data_sorted_v1[data_sorted_v1.columns[a]], method='pearson')
features_correlation.loc[index, 'correlation_spearman'] = data_sorted_v1[data_sorted_v1.columns[i]].corr(data_sorted_v1[data_sorted_v1.columns[a]], method='spearman')
index += 1
feature_1 | feature_2 | correlation_pearson | correlation_spearman | |
609 | tp_h | tp_a | 0.79079 | 0.83210 |
621 | tp_h | win_h | 0.96445 | 0.96560 |
622 | tp_h | win_a | 0.70637 | 0.75680 |
625 | tp_h | mop_h | 0.87699 | 0.89812 |
626 | tp_h | mop_a | 0.87744 | 0.89833 |
638 | tp_a | win_h | 0.76446 | 0.80477 |
639 | tp_a | win_a | 0.94854 | 0.95138 |
642 | tp_a | mop_h | 0.88491 | 0.90452 |
643 | tp_a | mop_a | 0.88395 | 0.90257 |
689 | day_of_week | weekend | 0.79452 | 0.78122 |
768 | win_h | mop_h | 0.84281 | 0.86428 |
769 | win_h | mop_a | 0.84571 | 0.86598 |
772 | win_a | mop_h | 0.78235 | 0.81468 |
773 | win_a | mop_a | 0.78300 | 0.81395 |
779 | mop_h | mop_a | 0.98748 | 0.98940 |
Зависимости между очками играющих команд нет (признаки tp_h, tp_a) — сильная корреляция объясняется набором очков по ходу сезона. Тем же объясняется сильная корреляция в комбинациях признаков tp, win и mop. Указанные признаки оставлены без изменений.
Между днем недели и наличием выходного (признаки day_of_week, weekend) связь очевидна — признак weekend удален.
Проведена проверка матчей на наличие выбросов, аномалий, ошибок и обнаружены следующие:
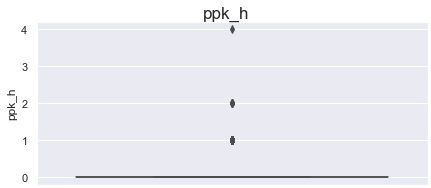
в матче с ppk_h равным 4 — ошибка, все шайбы заброшены в равных составах;
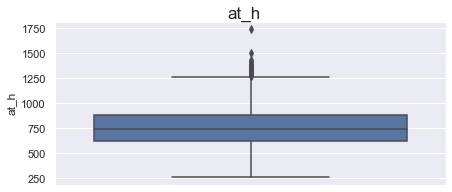
в матче с at_h равным 1740 — ошибка, во втором периоде у домашней команды время владения шайбой в атаке составило 19:52 и является нереальным значением. Макс время в атаке за весь матч у игрока данной команды составляет 17:22, т.е. вероятное время в атаке команды во 2 м периоде составляет 9:52 — значение at_h скорректировано с учетом данной информации;
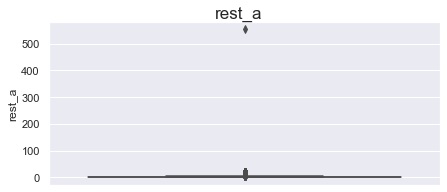
в матче с rest_a равным 554 — значение появилось из-за отсутствия команды «Адмирал» в 3 сезоне. Значение заменено на 20 (макс. кол-во дней отдыха).
Генерация датасетов
Частью данной работы являлось исследование влияния вариантов формирования датасетов (с учетом метода масштабирования, т.к. значения разных признаков находились в разных диапазонах) на качество обучаемых моделей. В качестве данных для обучения моделей была информация по предшествующим матчам играющих команд. Т.к. по ходу сезона форма команд меняется, брать в расчет большое кол-во предшествующих игр виделось нецелесообразным — в итоге их кол-во составило 1, 3, и 5.
При 1 матче формировалось 3 исходных датасета без масштабирования:
из статистики каждой команды в предшествующем матче (df_1);
из разности статистики рассматриваемой команды и её оппонента в предшествующем матче (df_2);
из разницы разностей статистики играющих команд, полученной из датасета df_2 (df_3).
При 3 матчах формировалось 6 исходных датасетов без масштабирования:
из средней и медианной статистики каждой команды в 3 предшествующих матчах (df_4, df_5);
из средней и медианной разности статистики рассматриваемой команды и её оппонентов в 3 предшествующих матчах (df_6, df_7);
из разницы средней и медианной разностей статистики в 3 предшествующих матчах, полученной из датасетов df_6, df_7 (df_8, df_9).
При 5 матчах формировалось 6 исходных датасетов без масштабирования:
из средней и медианной статистики каждой команды в 5 предшествующих матчах (df_10, df_11);
из средней и медианной разности статистики рассматриваемой команды и её оппонентов в 5 предшествующих матчах (df_12, df_13);
из разницы средней и медианной разностей статистики в 5 предшествующих матчах, полученной из датасетов df_12, df_13 (df_14, df_15).
Для формирования 15 исходных датасетов (точнее групп датасетов с учетом обучающих и тестовых наборов признаков) написана функция df_creator с масштабированием циклических временных значений (признаки day, month, day_of_week) через sin и cos для приведения их к сопоставимой значимости, разделением на обучающую, тестовую выборки и делением их на обучающие и целевой признаки. Деление на обучающую и тестовую выборки выполнялось по сезонам — первые 3 шли в обучение, 4 — на тест.
# df - исходный датасет
# match_count - кол-во матчей, которые берутся в расчёт
# type_of_calculation - тип расчета (None - в расчёт берется исходная статистика, 'diff' - разность статистики для каждой команды по предыдущим матчам, 'diff_diff' - разница разностей статистики для каждой команды по предыдущим матчам)
# mean_median - опция расчета среднего или медианы по нескольким матчам (доступна для кол-ва матчей 3 и 5)
def df_creator(df, match_count, type_of_calculation=None, mean_median=None):
# делаем копию исходного датасета для трансформации
df_main = df.copy()
if type_of_calculation == None:
# определяем столбцы для сдвига и вставки у домашней команды
columns_to_shift_paste_h = ['ppp_h', 'ppk_h', 'numa_h', 'wt_h', 'pt_h', 'sog_h', 'bs_h', 'pm_h', 'at_h', 'final_score_h']
# определяем столбцы для сдвига и вставки у гостевой команды
columns_to_shift_paste_a = ['ppp_a', 'ppk_a', 'numa_a', 'wt_a', 'pt_a', 'sog_a', 'bs_a', 'pm_a', 'at_a', 'final_score_a']
elif type_of_calculation == 'diff' or type_of_calculation == 'diff_diff':
column_prefix = ['ppp', 'ppk', 'numa', 'wt', 'pt', 'sog', 'bs', 'pm', 'at', 'final_score', 'tp', 'reloc', 'rest', 'intense', 'win', 'ftf', 'mop']
columns_to_shift_paste_h, columns_to_shift_paste_a = [], []
# считаем разности статистик, которые будут сдвигаться
for pref in column_prefix[:10]:
df_main['d_' + pref + '_h'] = df_main[pref + '_h'] - df_main[pref + '_a']
df_main['d_' + pref + '_a'] = df_main[pref + '_a'] - df_main[pref + '_h']
df_main.drop(columns=[pref + '_h', pref + '_a'], inplace=True)
# определяем столбцы для сдвига и вставки у домашней команды
columns_to_shift_paste_h.append('d_' + pref + '_h')
# определяем столбцы для сдвига и вставки у гостевой команды
columns_to_shift_paste_a.append('d_' + pref + '_a')
else:
raise TypeError(f'Type of calculation "{type_of_calculation}" does not exist')
def stat_shifter(team, df_team, columns_to_shift_paste):
# определяем группу статистик (домашняя или гостевая), которые будут рассчитываться для команды
if 'ppp_h' in columns_to_shift_paste or 'd_ppp_h' in columns_to_shift_paste:
sec_columns_set = columns_to_shift_paste_a
home_away_team = 'team_h'
else:
sec_columns_set = columns_to_shift_paste_h
home_away_team = 'team_a'
if match_count == 1 and mean_median == None:
df_main.loc[df_team.index, columns_to_shift_paste] = np.where((df_main.loc[df_team.index, [home_away_team]*10] == team), df_team.drop(columns=['season']).shift(), df_main.loc[df_team.index, columns_to_shift_paste])
elif (match_count == 3 or match_count == 5) and mean_median == 'mean':
df_main.loc[df_team.index, columns_to_shift_paste] = np.where((df_main.loc[df_team.index, [home_away_team]*10] == team), df_team.drop(columns=['season']).rolling(window=match_count).mean().shift(), df_main.loc[df_team.index, columns_to_shift_paste])
elif (match_count == 3 or match_count == 5) and mean_median == 'median':
df_main.loc[df_team.index, columns_to_shift_paste] = np.where((df_main.loc[df_team.index, [home_away_team]*10] == team), df_team.drop(columns=['season']).rolling(window=match_count).median().shift(), df_main.loc[df_team.index, columns_to_shift_paste])
else:
raise TypeError(f'Parameter mean_median with value "{mean_median}" does not exist, match count ({match_count}) is not set correctly (must be 1, 3 or 5) or their combination is set incorrectly')
for team in df_main.team_h.unique():
# создаем отдельный датасет с матчами рассматриваемой команды
df_team = df_main[(df_main['team_h'] == team) | (df_main['team_a'] == team)]
# оставляем только статистику рассматриваемой команды
df_team.drop(columns=['home_win', 'tp_h', 'tp_a', 'delta_p', 'day', 'month', 'day_of_week', 'reloc_h', 'reloc_a', 'rest_h', 'rest_a', 'intense_h', 'intense_a', 'win_h', 'win_a', 'ftf_h', 'ftf_a', 'mop_h', 'mop_a'], inplace=True)
columns_h = ['ppp_h', 'ppk_h', 'numa_h', 'wt_h', 'pt_h', 'sog_h', 'bs_h', 'pm_h', 'at_h', 'final_score_h']
columns_a = ['ppp_a', 'ppk_a', 'numa_a', 'wt_a', 'pt_a', 'sog_a', 'bs_a', 'pm_a', 'at_a', 'final_score_a']
df_team[columns_to_shift_paste_h] = np.where(df_team[['team_a'] * 10] == team, df_team[columns_to_shift_paste_a], df_team[columns_to_shift_paste_h])
df_team.drop(columns=columns_to_shift_paste_a + ['team_h', 'team_a'], inplace=True)
stat_shifter(team, df_team, columns_to_shift_paste_h)
stat_shifter(team, df_team, columns_to_shift_paste_a)
# метим кол-во матчей, на которое производится сдвиг, по каждому сезону у всех команд для последующего удаления
index_first_games = df_team[((df_team.season - df_team.season.shift(match_count)).isna()) | ((df_team.season - df_team.season.shift(match_count)) > 0)].index
for i in index_first_games:
if df_main.loc[i, 'team_h'] == team:
df_main.loc[i, 'team_h'] = np.nan
else: df_main.loc[i, 'team_a'] = np.nan
# удаляем первые матчи команд
df_main.dropna(subset=['team_h', 'team_a'], inplace=True)
# считаем разницу разностей между статистиками играющих команд для 3 типа датасетов
if type_of_calculation == 'diff_diff':
for pref in column_prefix[:10]:
df_main['dd_' + pref + '_ha'] = df_main['d_' + pref + '_h'] - df_main['d_' + pref + '_a']
df_main.drop(columns=['d_' + pref + '_h', 'd_' + pref + '_a'], inplace=True)
for pref in column_prefix[-7:]:
df_main['dd_' + pref + '_ha'] = df_main[pref + '_h'] - df_main[pref + '_a']
df_main.drop(columns=[pref + '_h', pref + '_a'], inplace=True)
df_main.drop(columns=['delta_p'], inplace=True)
else:
pass
# приводим к сопоставимой значимости циклические временные значения ('day', 'month', 'day_of_week') с помощью тригонометрических функций. Используем sin и cos, чтобы они уравновешивали друг друга и не было перекоса в данных
df_main['day_of_week_cos'], df_main['day_of_week_sin'] = np.cos(2 * np.pi * df_main['day_of_week'] / 6), np.sin(2 * np.pi * df_main['day_of_week'] / 6)
df_main['month_cos'], df_main['month_sin'] = np.cos(2 * np.pi * df_main['month'] / 12), np.sin(2 * np.pi * df_main['month'] / 12)
df_main['day_cos'], df_main['day_sin'] = np.cos(2 * np.pi * df_main['day'] / 31), np.sin(2 * np.pi * df_main['day'] / 31)
# удаляем более не нужные столбцы
df_main.drop(columns=['team_h', 'team_a', 'day', 'day_of_week', 'month'], inplace=True)
# делим датасет на обучающую и тестовую выборки
df_train, df_test = df_main[df_main.season < 4], df_main[df_main.season == 4]
# удаляем ненужный столбец season
df_train.drop(columns=['season'], inplace=True)
df_test.drop(columns=['season'], inplace=True)
x_train, y_train = df_train.drop(columns=['home_win']), df_train['home_win']
x_test, y_test = df_test.drop(columns=['home_win']), df_test['home_win']
return x_train, y_train, x_test, y_test
Сформировав 15 групп датасетов и проверив качество разделения на обучающие и тестовые выборки (для одно- и трехматчевых вариантов в обучающие выборки попали 74% наблюдений, для пятиматчевых — 75%), было необходимо смасштабировать данные, не относящиеся к категориальным признакам. Масштабирование, также как и формирование датасетов, было вариативным для оценки наилучшего варианта. Для каждого датасета применено 3 варианта масштабирования:
минимакс (MinMaxScaler);
стандартизация (StandardScaler);
нормализация (Normalizer).
Масштабирование исходных 15 групп датасетов выполнялось с помощью функции scaler.
def scaler(df_train, df_test):
cat_columns = ['reloc_h', 'reloc_a', 'intense_h', 'intense_a']
time_columns = ['day_of_week_cos', 'day_of_week_sin', 'month_cos', 'month_sin', 'day_cos', 'day_sin']
# убираем из масштабируемых датасетов категориальные признаки (присутствуют не во всех датасетах) и смаштабированные временные значения
try:
df_train_wo_cat_mm, df_train_wo_cat_st, df_train_wo_cat_norm = df_train.drop(columns=cat_columns+time_columns), df_train.drop(columns=cat_columns+time_columns), df_train.drop(columns=cat_columns+time_columns)
df_test_wo_cat_mm, df_test_wo_cat_st, df_test_wo_cat_norm = df_test.drop(columns=cat_columns+time_columns), df_test.drop(columns=cat_columns+time_columns), df_test.drop(columns=cat_columns+time_columns)
i = 0
except KeyError:
df_train_wo_cat_mm, df_train_wo_cat_st, df_train_wo_cat_norm = df_train.drop(columns=time_columns), df_train.drop(columns=time_columns), df_train.drop(columns=time_columns)
df_test_wo_cat_mm, df_test_wo_cat_st, df_test_wo_cat_norm = df_test.drop(columns=time_columns), df_test.drop(columns=time_columns), df_test.drop(columns=time_columns)
i = 1
mm_scaler = MinMaxScaler()
df_train_wo_cat_mm.loc[:, :] = mm_scaler.fit_transform(df_train_wo_cat_mm)
df_test_wo_cat_mm.loc[:, :] = mm_scaler.transform(df_test_wo_cat_mm)
st_scaler = StandardScaler()
df_train_wo_cat_st.loc[:, :] = st_scaler.fit_transform(df_train_wo_cat_st)
df_test_wo_cat_st.loc[:, :] = st_scaler.transform(df_test_wo_cat_st)
# особенностью работы нормалайзера является масштабирование по строкам, поэтому сначала объединяем train и test, транспонируем, совместно нормализуем, потом снова транспонируем и разбиваем на train и test
norm_scaler = Normalizer()
index = min(df_test.index)
df_train_test_wo_cat_norm = pd.concat([df_train_wo_cat_norm, df_test_wo_cat_norm])
df_train_test_wo_cat_norm = df_train_test_wo_cat_norm.transpose()
df_train_test_wo_cat_norm.loc[:, :] = norm_scaler.fit_transform(df_train_test_wo_cat_norm)
df_train_test_wo_cat_norm = df_train_test_wo_cat_norm.transpose()
df_train_wo_cat_norm = df_train_test_wo_cat_norm[df_train_test_wo_cat_norm.index < index]
df_test_wo_cat_norm = df_train_test_wo_cat_norm[df_train_test_wo_cat_norm.index >= index]
# добавляем к смасштабированным данным категориальные признаки (если имеются) и смаштабированные временные значения
if i == 0:
df_train_mm = pd.merge(df_train_wo_cat_mm, df_train[cat_columns+time_columns], left_index=True, right_index=True)
df_test_mm = pd.merge(df_test_wo_cat_mm, df_test[cat_columns+time_columns], left_index=True, right_index=True)
df_train_st = pd.merge(df_train_wo_cat_st, df_train[cat_columns+time_columns], left_index=True, right_index=True)
df_test_st = pd.merge(df_test_wo_cat_st, df_test[cat_columns+time_columns], left_index=True, right_index=True)
df_train_norm = pd.merge(df_train_wo_cat_norm, df_train[cat_columns+time_columns], left_index=True, right_index=True)
df_test_norm = pd.merge(df_test_wo_cat_norm, df_test[cat_columns+time_columns], left_index=True, right_index=True)
else:
df_train_mm = pd.merge(df_train_wo_cat_mm, df_train[time_columns], left_index=True, right_index=True)
df_test_mm = pd.merge(df_test_wo_cat_mm, df_test[time_columns], left_index=True, right_index=True)
df_train_st = pd.merge(df_train_wo_cat_st, df_train[time_columns], left_index=True, right_index=True)
df_test_st = pd.merge(df_test_wo_cat_st, df_test[time_columns], left_index=True, right_index=True)
df_train_norm = pd.merge(df_train_wo_cat_norm, df_train[time_columns], left_index=True, right_index=True)
df_test_norm = pd.merge(df_test_wo_cat_norm, df_test[time_columns], left_index=True, right_index=True)
return df_train_mm, df_train_st, df_train_norm, df_test_mm, df_test_st, df_test_norm
После масштабирования получено 45 наборов датасетов, которые были собраны в одном словаре для удобства дальнейшей работы с ними.
total_df_dict = {'1':[[df_1_x_train_mm, df_1_y_train, df_1_x_test_mm, df_1_y_test], [df_1_x_train_st, df_1_x_test_st], [df_1_x_train_norm, df_1_x_test_norm]],
'2':[[df_2_x_train_mm, df_2_y_train, df_2_x_test_mm, df_2_y_test], [df_2_x_train_st, df_2_x_test_st], [df_2_x_train_norm, df_2_x_test_norm]],
'3':[[df_3_x_train_mm, df_3_y_train, df_3_x_test_mm, df_3_y_test], [df_3_x_train_st, df_3_x_test_st], [df_3_x_train_norm, df_3_x_test_norm]],
'4':[[df_4_x_train_mm, df_4_y_train, df_4_x_test_mm, df_4_y_test], [df_4_x_train_st, df_4_x_test_st], [df_4_x_train_norm, df_4_x_test_norm]],
'5':[[df_5_x_train_mm, df_5_y_train, df_5_x_test_mm, df_5_y_test], [df_5_x_train_st, df_5_x_test_st], [df_5_x_train_norm, df_5_x_test_norm]],
'6':[[df_6_x_train_mm, df_6_y_train, df_6_x_test_mm, df_6_y_test], [df_6_x_train_st, df_6_x_test_st], [df_6_x_train_norm, df_6_x_test_norm]],
'7':[[df_7_x_train_mm, df_7_y_train, df_7_x_test_mm, df_7_y_test], [df_7_x_train_st, df_7_x_test_st], [df_7_x_train_norm, df_7_x_test_norm]],
'8':[[df_8_x_train_mm, df_8_y_train, df_8_x_test_mm, df_8_y_test], [df_8_x_train_st, df_8_x_test_st], [df_8_x_train_norm, df_8_x_test_norm]],
'9':[[df_9_x_train_mm, df_9_y_train, df_9_x_test_mm, df_9_y_test], [df_9_x_train_st, df_9_x_test_st], [df_9_x_train_norm, df_9_x_test_norm]],
'10':[[df_10_x_train_mm, df_10_y_train, df_10_x_test_mm, df_10_y_test], [df_10_x_train_st, df_10_x_test_st], [df_10_x_train_norm, df_10_x_test_norm]],
'11':[[df_11_x_train_mm, df_11_y_train, df_11_x_test_mm, df_11_y_test], [df_11_x_train_st, df_11_x_test_st], [df_11_x_train_norm, df_11_x_test_norm]],
'12':[[df_12_x_train_mm, df_12_y_train, df_12_x_test_mm, df_12_y_test], [df_12_x_train_st, df_12_x_test_st], [df_12_x_train_norm, df_12_x_test_norm]],
'13':[[df_13_x_train_mm, df_13_y_train, df_13_x_test_mm, df_13_y_test], [df_13_x_train_st, df_13_x_test_st], [df_13_x_train_norm, df_13_x_test_norm]],
'14':[[df_14_x_train_mm, df_14_y_train, df_14_x_test_mm, df_14_y_test], [df_14_x_train_st, df_14_x_test_st], [df_14_x_train_norm, df_14_x_test_norm]],
'15':[[df_15_x_train_mm, df_15_y_train, df_15_x_test_mm, df_15_y_test], [df_15_x_train_st, df_15_x_test_st], [df_15_x_train_norm, df_15_x_test_norm]]}
Сильного дисбаланса классов в целевом признаке не было — для датасетов с 1 матчем было 55% наблюдений с положительным классом, для датасетов с 3 и 5 матчами — 54%. Метрикой качества выбрана ROC AUC, не требующая подбора порога для разделения прогнозируемых моделью вероятностей.
Для оценки качества обучаемых моделей определено значение метрики базовой модели, прогнозирующей победу домашней команды во всех матчах — для всех вариантов датасетов оно составило 0.50.
Моделирование
В обучении участвовало 5 моделей — LogisticRegression, RandomForestClassifier, XGBClassifier, LGBMClassifier, CatBoostClassifier, каждая из которых обучалась с перебором гиперпараметров.
# делаем 10 фолдов, т.к. обучающих данных немного
folds = KFold(n_splits=10, shuffle=True, random_state=800)
# LogisticRegression
lr_param = [{'solver': ['newton-cg'], 'penalty': ['l2', 'none'], 'C': [1e-5, 1e-3, 1e-1, 1, 10], 'max_iter': [100, 500, 1000]},
{'solver': ['lbfgs'], 'penalty': ['l2', 'none'], 'C': [1e-5, 1e-3, 1e-1, 1, 10], 'max_iter': [100, 500, 1000]},
{'solver': ['liblinear'], 'penalty': ['l1', 'l2'], 'C': [1e-5, 1e-3, 1e-1, 1, 10], 'max_iter': [100, 500, 1000], 'random_state': [800]},
{'solver': ['sag'], 'penalty': ['l2', 'none'], 'C': [1e-5, 1e-3, 1e-1, 1, 10], 'max_iter': [100, 500, 1000], 'random_state': [800]},
{'solver': ['saga'], 'penalty': ['l1', 'l2', 'elasticnet', 'none'], 'C': [1e-5, 1e-3, 1e-1, 1, 10], 'max_iter': [100, 500, 1000], 'random_state': [800]}]
lr_model = LogisticRegression()
lr_model_grid = GridSearchCV(estimator=lr_model,
param_grid=lr_param,
scoring='roc_auc',
n_jobs=-1,
cv=folds,
verbose=1,
return_train_score=True)
# RandomForestClassifier
rfc_param = {'n_estimators': [200, 500],
'max_depth': [5, 10],
'min_samples_split': [2, 5],
'min_samples_leaf': [1, 3],
'max_features': [0.5, 0.7],
'max_samples': [0.5, 0.7]}
rfc_model = RandomForestClassifier(criterion='log_loss', bootstrap=True, random_state=800)
rfc_model_grid = GridSearchCV(estimator=rfc_model,
param_grid=rfc_param,
scoring='roc_auc',
n_jobs=-1,
cv=folds,
verbose=1,
return_train_score=True)
# XGBClassifier
xgb_param = {'eta': [0.001, 0.01],
'n_estimators': [200, 500],
'max_depth': [5, 10],
'subsample': [0.5, 0.7],
'min_
